ビッグデータのリアルタイム分析処理基盤「Jubatus」の商用サポート体制を確立~NTTテクノクロス株式会社にて2014年1月よりサポートサービス開始~
2013年12月19日
NTTソフトウェア株式会社(東京都港区、代表取締役社長:山田伸一、以下「NTTソフトウェア」)、 株式会社Preferred Infrastructure(東京都文京区、代表者:西川徹、以下「PFI」)、日本電信電話株式会社(東京都千代田区、代表取締役社長:鵜浦博夫、以下「NTT」)は、ビッグデータ分析に基づくビジネスソリューションにおいて、リアルタイム分析処理基盤Jubatus(ユバタス)(*1)の活用を積極推進するため、Jubatusにかかる技術内容の問い合わせに対して、有償で対応する初のサポート体制を確立しました。
Jubatusとは、フロー型のビッグデータ(*2)をリアルタイムに深く分析する技術として、2011年10月にNTTとPFIが共同開発しオープンソース公開しているものです。現在、Webサイトでは、一例として、顧客クラスタリングや不正検知、ソーシャルコミュニティ分析、株価予測、ECサイトの商品お勧め、検索サイトの連動広告などの利用シーンを想定する分析機能をオープンソースで公開しています。それ以来、本技術を利用したいというビジネスユーザから多くの技術に関する問い合わせや、商用導入にむけた初期導入コンサルティングの要望等が寄せられ、これらに対処するサポート体制を整備することが不可欠となっていました。
今回、NTTソフトウェアが、2014年1月15日から、公式サイトで公開しているオープンソースを対象に、ビッグデータの活用・分析とJubatusの適用方法、Jubatusの導入やシステム運用に関する情報提供、技術問い合わせへの対応、故障解析の対応など、Jubatusの活用に役立つ支援を提供していきます。ビッグデータ活用によるビジネスユーザの事業の加速にむけて、3社はJubatusの活用を通じてサポートしてまいります。

1.Jubatusの特徴とこれまでの実績
背景
現在、事業活動に「ビッグデータ分析」を取り込む動きが急速に広がっています。ビッグデータの分析により、収益化が見込めるビジネスの創出や収益化に有効な手法の適用が重要課題となっています。
Jubatusの特徴
ビッグデータ分析のためのツールや仕組みが数多くある中、Jubatusはフロー型ビッグデータに対するリアルタイム分析技術として2011年10月にNTTとPFIが共同開発しオープンソースとして公開したものです。オンライン機械学習を分散スケールする世界初のプロダクトです(図1、図2)。
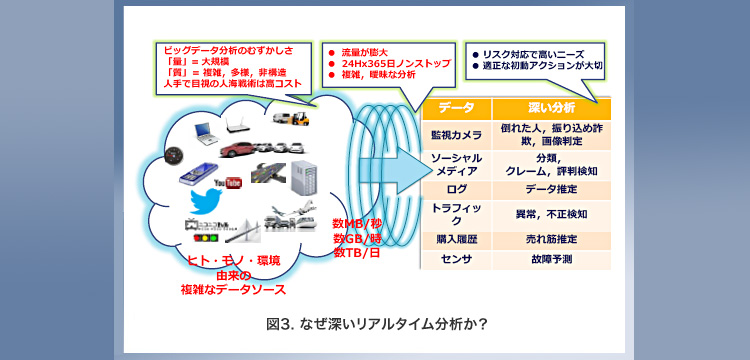
リアルタイムでの深い分析は、従来の大規模バッチ処理と異なる付加価値を創出します(図3)。
機械学習を採用した分析ロジックを強みに、24時間365日連続運転ですばやい処理が可能です。分類・推薦・異常検知・クラスタリング等をオンライン機械学習で実行しながら、データの流量・規模が増えた場合でも、サーバを多数並べるだけで負荷分散と可用性を同時に満たします。
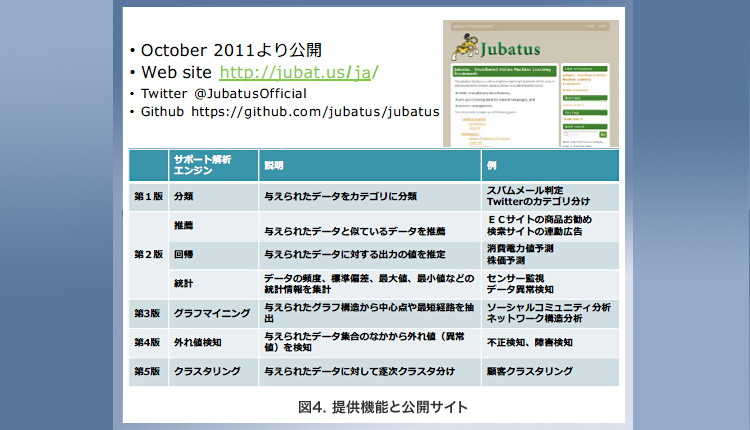
このようにオンライン機械学習を分散スケールする、他に類を見ない世界初のプロダクトです。提供機能と公開サイトを図4にまとめました。

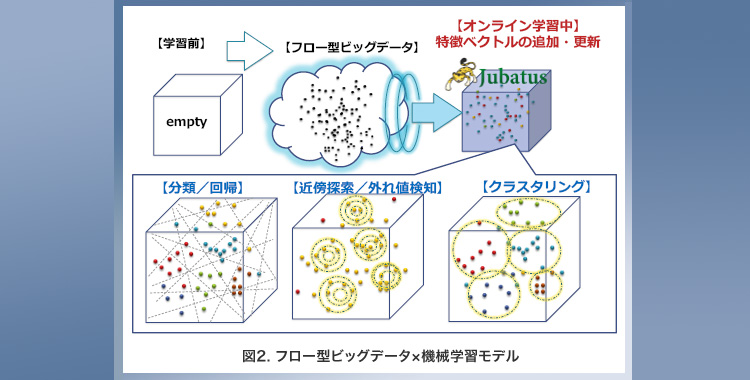
実績
Jubatusは、2012年12月に開始したNTTデータ社の「Twitterデータ提供サービス」に使われているほか、すでにいくつかの商用実績や国家プロジェクトでの採用実績があり注目を集めています。また、PFIでは、自社製品にJubatusを組み込んでおり、すでに第一弾としてSedue for Big Data(以下、SFBD *3)を2013年6月に商品化しています。
2.課題とサポート体制確立の目的
これまでオープンソースとして機能拡充と品質強化開発を継続している過程で、 Jubatusの商用導入に向けた問い合わせが数多く寄せられています。商用システムへのオープンソース導入において、運用保守まですべて自己解決できるケースと、保守サポート体制をアウトソースするケースがありますが、特に後者の場合、ビジネスユーザの要望や問い合わせに対応するサービスがないことで、利用を見送られる事例があり、サポートサービス体制の整備が喫緊の課題でした。
そこで、安心してJubatusを商用利用いただけるよう、持続的なサポート体制への期待に答えるために、今回、NTTソフトウェア、PFI、NTTの3社は、商用導入にむけた初期導入コンサルティング、オープンソース公開中のプロダクトについての技術的な問い合わせ対応を中心とするサポート体制を確立いたします。
今回、新たに提供するサポートは、NTTソフトウェアが行います。これは、2012年8月にJubatusコミュニティ活動に参画して以来、Jubatusに関する数多くの情報発信とオープンソースの品質強化や各種機械学習の手法・アルゴリズムロジックの追加、定期的な提供を行い、SFBDの取り扱い実績も豊富なことによります。
3.サポートサービスのメニュー例
今回の体制が提供するJubatusのサポートサービスは大きく3つのメニューから構成します。
(1) ナレッジサービス(基本プラン)
(2) 保守サービス
(3) 個別支援サービス(いずれもオプションプラン)
以上の3項目について、企業の要望に合わせ、適切なサポートレベルを用意します(表1を参照)。サポートサービスを開始するにあたり、以下のURLで詳細を案内します(1月15日に公開予定)。
(/products/jubatus/)
| サポートサービスメニュー | ナレッジ サービス | 保守 サービス | 個別支援 サービス |
|---|---|---|---|
| ・アップデート情報、FAQなど基本的な情報の提供 |
○ |
○ |
○ |
| ・基本的な技術関連の問合せへの回答(ベーシック) |
○ |
○ |
○ |
| ・技術関連の問合せへの回答(アドバンス) |
○ |
○ |
|
| ・故障原因調査と回避策の提案 |
○ |
○ |
|
| ・故障対応暫定ソースプログラムの提供 |
○ |
||
| ・平日昼間対応 |
○ |
○ |
○ |
| ・365日24時間対応 |
○* |
||
| ・故障対応 :緊急時の高度技術者対応、オンサイト対応 |
○* |
||
| ・故障対応 :常時の高度技術者対応、オンサイト対応 |
○* |
||
| ・初期導入コンサル |
○* |
||
| ・構築支援 |
○* |
||
| ・検証代行 |
○* |
||
| ・故障復旧 |
○* |
*:お客様のご要望に基づいて対応
4.各社の方針と目標
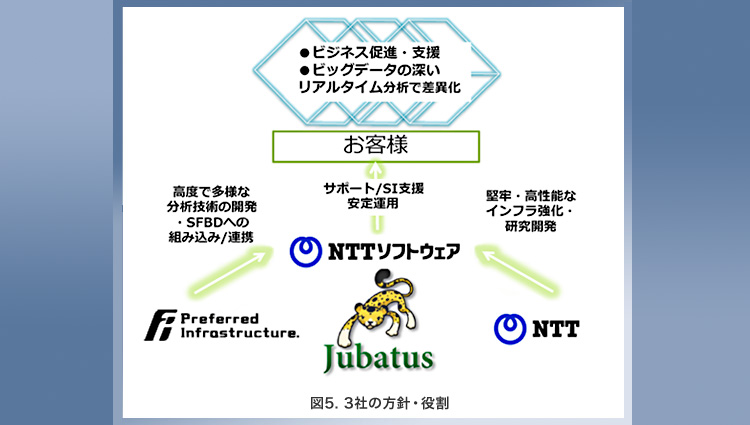
今回のサポートサービスについて、3社の方針と役割は以下のとおりです(図5)。
| (1) | NTTソフトウェアは、ビジネスユーザのビジネス成功にむけてビッグデータ活用の最適なソリューションを提案します。ビジネスユーザが保有するデータの分析・システム化検討から導入システムの運用・保守サポートまで、幅広いサービスメニューを提供し、ビッグデータの活用を支援します。 |
| (2) | PFIは、高度で多様な分析技術の開発を継続し、Jubatusの機能拡張・高性能化を進めるとともにすでに導入しているSFBDをはじめとして、自社製品とサービスにJubatusを組み込んでいきます。 |
| (3) | NTTは、本サポートサービスと連携することで、より実践的な技術と用途の開発を進めます。とりわけ、高性能で堅牢なインフラ整備・強化にむけた研究開発を進めていきます。 |
3社の連携により、ビジネスユーザのすばやい意思決定や危機管理、適切な初動アクションにつながるユースケースを蓄積します。これにより、ビジネスユーザは、Jubatusのリアルタイムビッグデータ分析・活用が短期間で可能になります。
5.目標
3年間で3億円の売上を目標とします。
6.今後の展開
サポート体制の確立を契機に、Jubatus活用のビジネスメリットを企業や社会に広く普及していきます。例えば、表2のような効能が期待できます。
3社は、リアルタイムで深い分析を必要とするビジネスでの適用ノウハウと、他社と異なる付加価値の創出にむけたJubatusの活用技術を蓄積します。これにより、ビジネスユーザの事業成功に向けたサポートの充実化を図ります。また、ビッグデータ活用の積極的な推進と、リアルタイムビッグデータ分析の市場拡大に貢献していきます。
表2.Jubatusで期待できる効能
| 1. | 差異化した ビッグデータ分析 |
機械学習の組み合わせと正解データ提示による、対話操作でかつすばやいリードタイムで仮説モデルを構築できる |
|---|---|---|
| 2. | コスト削減 | 複雑な分析であって、1台で足りない性能と容量はコモディティサーバの単純な追加・増設で安価に高スケールできる |
| 3. | 適切な リスク管理 |
異常やコンセプトドリフトをリアルタイムに分析することで、リスク有無の判断と初動アクションを適切にとれる |
【用語解説】
*1:Jubatus(ユバタス)
NTTソフトウェアイノベーションセンタと株式会社Preferred Infrastructureが共同開発したビッグデータのリアルタイム分析基盤技術。Hadoop等がバッチ処理型のビッグデータ処理を主体とするのに対し、リアルタイム処理かつ機械学習分析を両立するのが特徴。 これまでに、分類・推薦・統計・異常検知・クラスタリング等の分析ロジックをオンライン機械学習として組み込み、大規模なデータ流量に合わせて、サーバ台数を1台、2台、10台、100台と増やすことで対応する仕組み(分散スケール)として実現し、オープンソース公開している。
URL: http://jubat.us/ja/
名前はネコ科の動物であるチーターの学術名「Acinonyx Jubatus」に由来する。
*2:フロー型のビッグデータ
TwitterやGPSの位置情報のような刻々と流れる膨大なデータ。Jubatusでは、これらのリアルタイムで深い分析が可能である
*3:Sedue for Big Data (セデュー フォー ビッグデータ)
非構造化データに対するリアルタイムビッグデータ処理を実現した全文検索エンジンSedueに大幅な改善を加えたPFI社の商用プロダクト。
URL: http://preferred.jp/product/sedue-for-bigdata/abstract/
※文中に記載した会社名、製品名などの固有名詞は、一般に該当する会社もしくは組織の商標または登録商標です。
【当社以外のお問い合わせ先】
株式会社 Preferred Infrastructure
お問い合わせはこちら
日本電信電話株式会社
サービスイノベーション総合研究所
企画部 広報担当
TEL:046-859-2032
E-Mail:お問い合わせはこちら