WinActor(ウィンアクター)
教えて !! スーさん。
第4回「正規表現 vs WinActorノート で文字列を抽出する」の巻
目次
- 第4回「正規表現 vs WinActorノート で文字列を抽出する」の巻1(今回)
- 第4回「正規表現 vs WinActorノート で文字列を抽出する」の巻2
 スーさんと
スーさんと ムーさん、ふたりの会話を通してWinActorの利用方法をお伝えします。
ムーさん、ふたりの会話を通してWinActorの利用方法をお伝えします。
今回はムーさんから相談があるということですが、どのような内容でしょうか。
はい、よろしくお願いします。
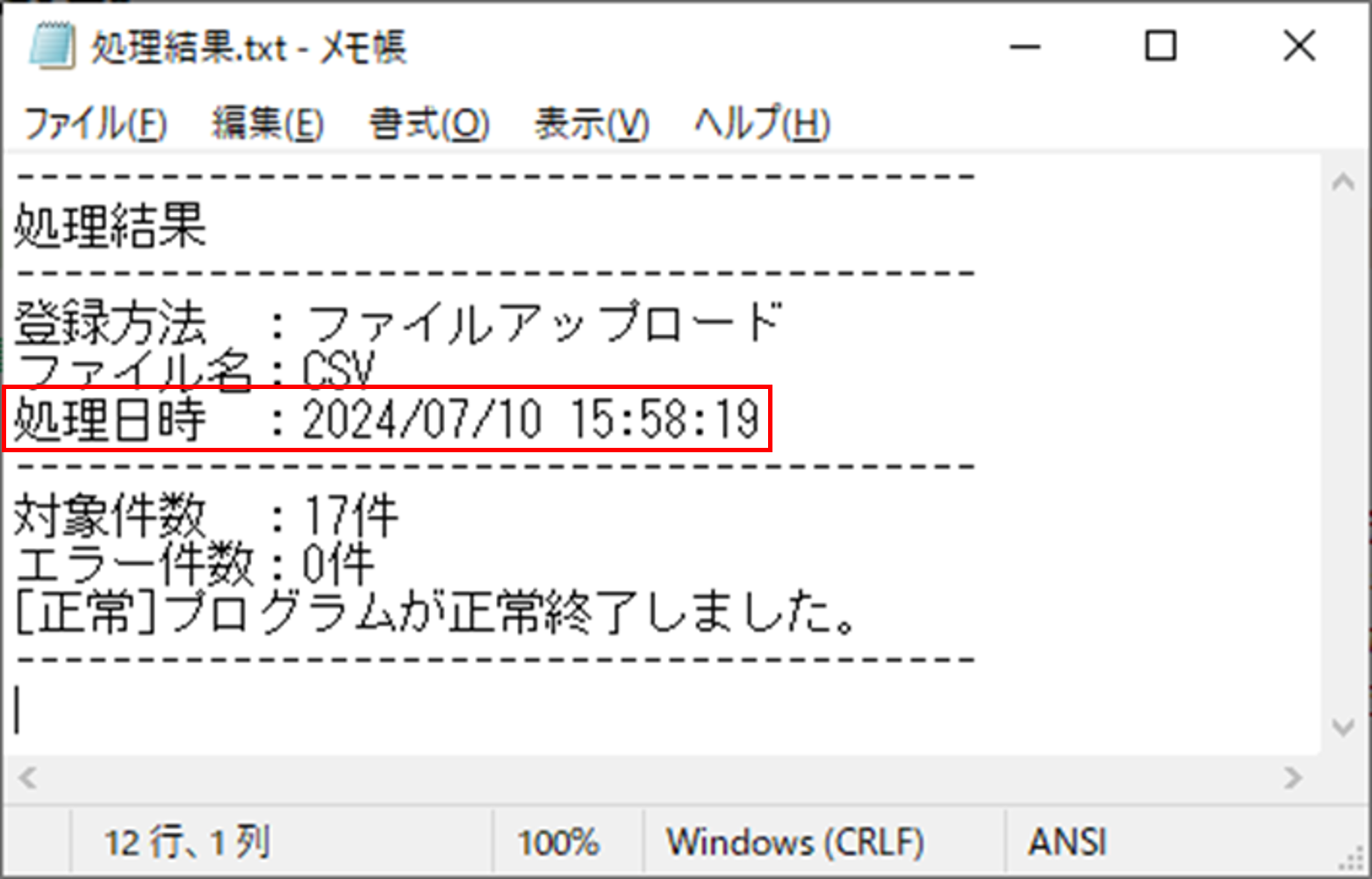
ブラウザであるシステムの操作を行った場合に、その処理結果がテキストファイル『処理結果.txt』に出力されます。
その処理結果の内容から、「処理日時」の部分を抽出したいのですが、どのような方法が考えられますでしょうか。
ブラウザであるシステムの操作を行った場合に、その処理結果がテキストファイル『処理結果.txt』に出力されます。
その処理結果の内容から、「処理日時」の部分を抽出したいのですが、どのような方法が考えられますでしょうか。
テキストファイルの内容から、ある特定の文字列を含む部分を抽出するということですね。
まず考えられるのが、正規表現を使って抽出する方法ですね。
まず考えられるのが、正規表現を使って抽出する方法ですね。
正規表現ですか。以前に少し触れたことはありますが、あまり馴染みがないです。
正規表現を使うとどのようなやり方になるのでしょうか。教えてください。
正規表現を使うとどのようなやり方になるのでしょうか。教えてください。
テキストファイルを変数に読込んで、「正規表現(文字列抽出)」ライブラリを使って抽出します。

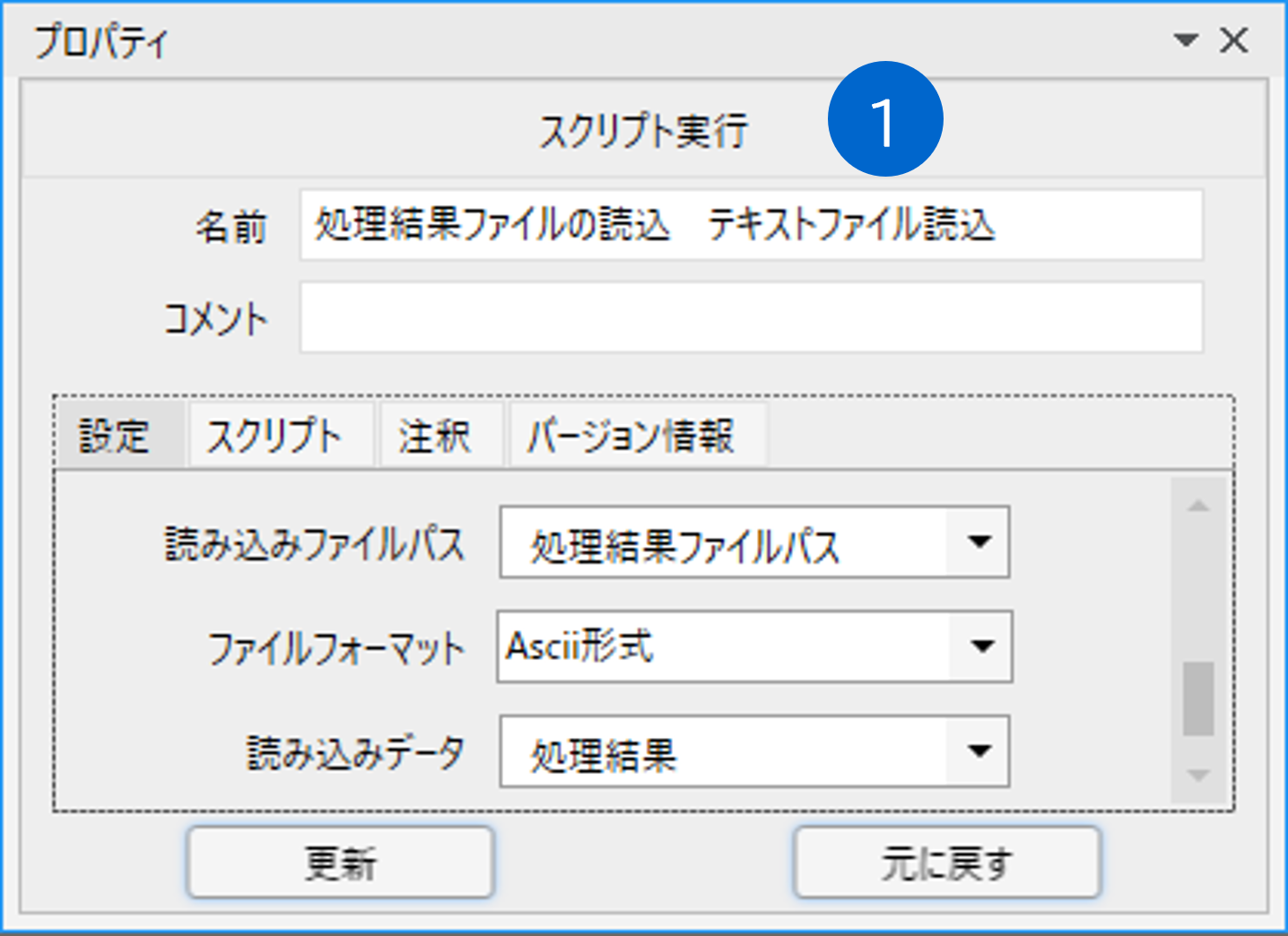
「テキストファイル読込」ライブラリで、処理結果のテキストファイルを「処理結果」変数に読込みます。
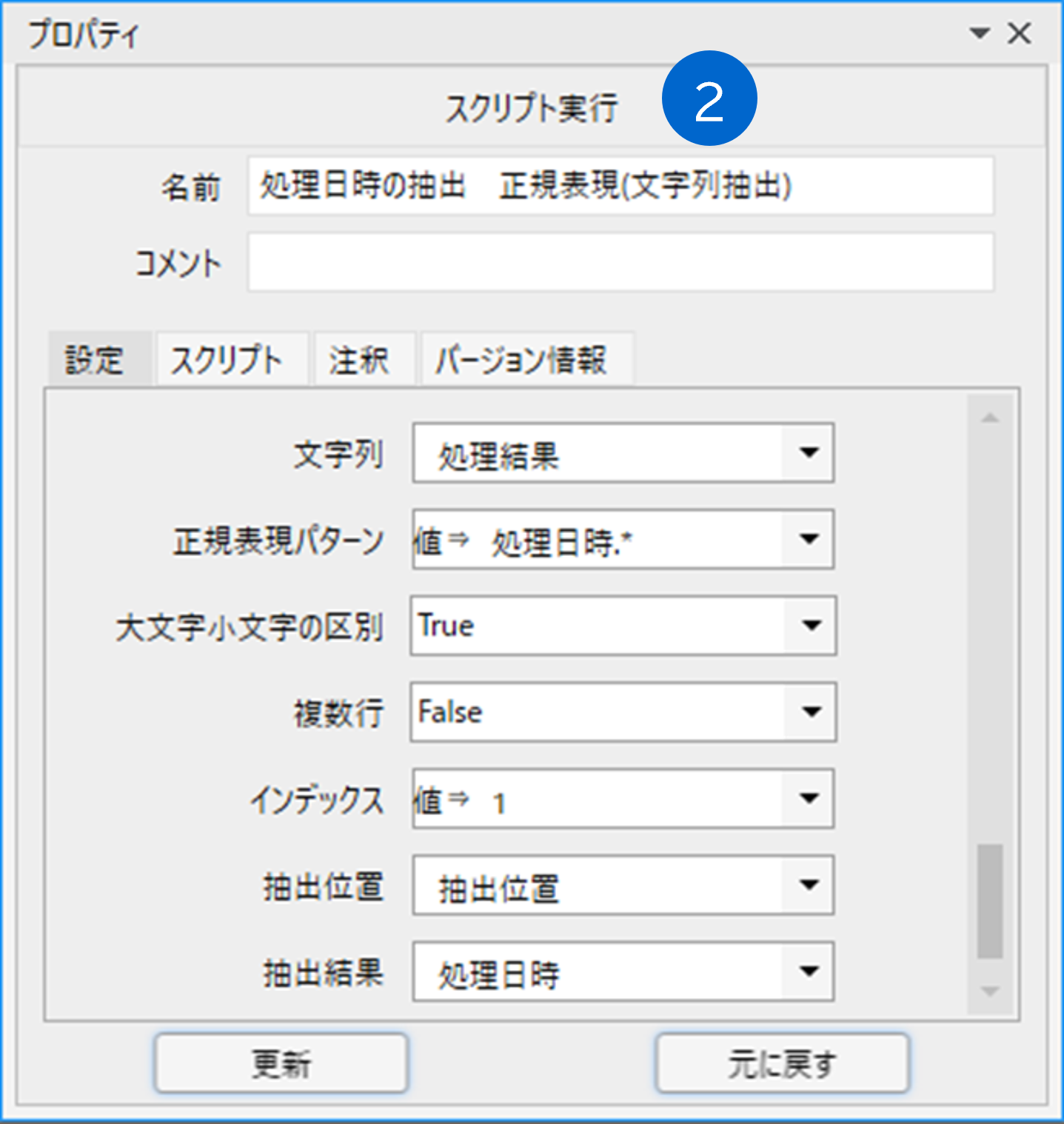
「07_文字列操作」→「02_切り出し・分割」の配下にある「正規表現(文字列抽出)」ライブラリで、「処理結果」変数から「処理日時」部分を抽出します。
正規表現パターンには「処理日時.*」を指定します。
抽出した結果が「処理日時」変数に格納されます。
正規表現パターンに指定した「処理日時.*」ですが、「.」は何でもいい1文字を示し、「*」は文字の連続を意味します。
つまり、「処理日時」の後に何でもいい文字が連続している部分が抽出対象となるわけです。
正規表現パターンには「処理日時.*」を指定します。
抽出した結果が「処理日時」変数に格納されます。
正規表現パターンに指定した「処理日時.*」ですが、「.」は何でもいい1文字を示し、「*」は文字の連続を意味します。
つまり、「処理日時」の後に何でもいい文字が連続している部分が抽出対象となるわけです。
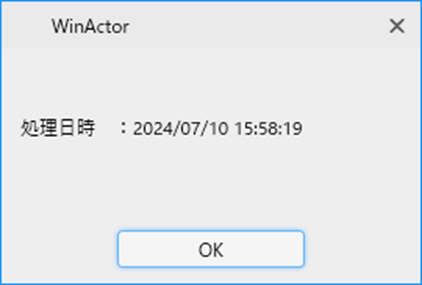
抽出結果の「処理日時」変数を待機ボックスで表示します。
確かに処理日時部分が抽出されていることがわかりますね。
確かに処理日時部分が抽出されていることがわかりますね。
なんと、正規表現を使うと簡単に抽出できちゃいますね。
処理日時の日時部分のみを抽出することもできますか。
処理日時の日時部分のみを抽出することもできますか。
日時部分のみを抽出することも可能です。
処理結果ファイルの読込は先ほどと同じです。
処理結果ファイルの読込は先ほどと同じです。
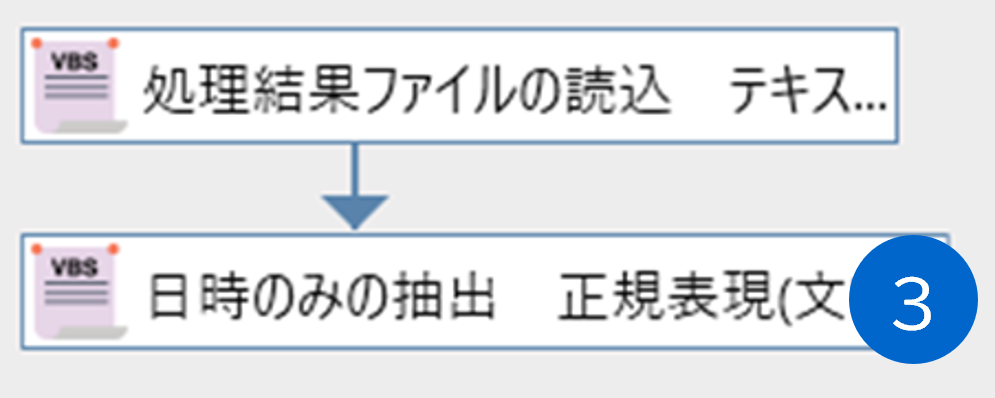
日時部分のみを抽出する場合の正規表現パターンは、
「\d{4}/\d{2}/\d{2} \d{2}:\d{2}:\d{2}」を指定します。
指定した正規表現パターンの「\d」は1つの数字、「{4}」は直前のパターンを4回繰り返すという意味なので、「\d{4}」で数字4桁を示すことになります。
「\d{4}/\d{2}/\d{2} \d{2}:\d{2}:\d{2}」は、
「数字4桁/数字2桁/数字2桁 数字2桁:数字2桁:数字2桁」となっている部分を抽出することになります。
「\d{4}/\d{2}/\d{2} \d{2}:\d{2}:\d{2}」を指定します。
指定した正規表現パターンの「\d」は1つの数字、「{4}」は直前のパターンを4回繰り返すという意味なので、「\d{4}」で数字4桁を示すことになります。
「\d{4}/\d{2}/\d{2} \d{2}:\d{2}:\d{2}」は、
「数字4桁/数字2桁/数字2桁 数字2桁:数字2桁:数字2桁」となっている部分を抽出することになります。
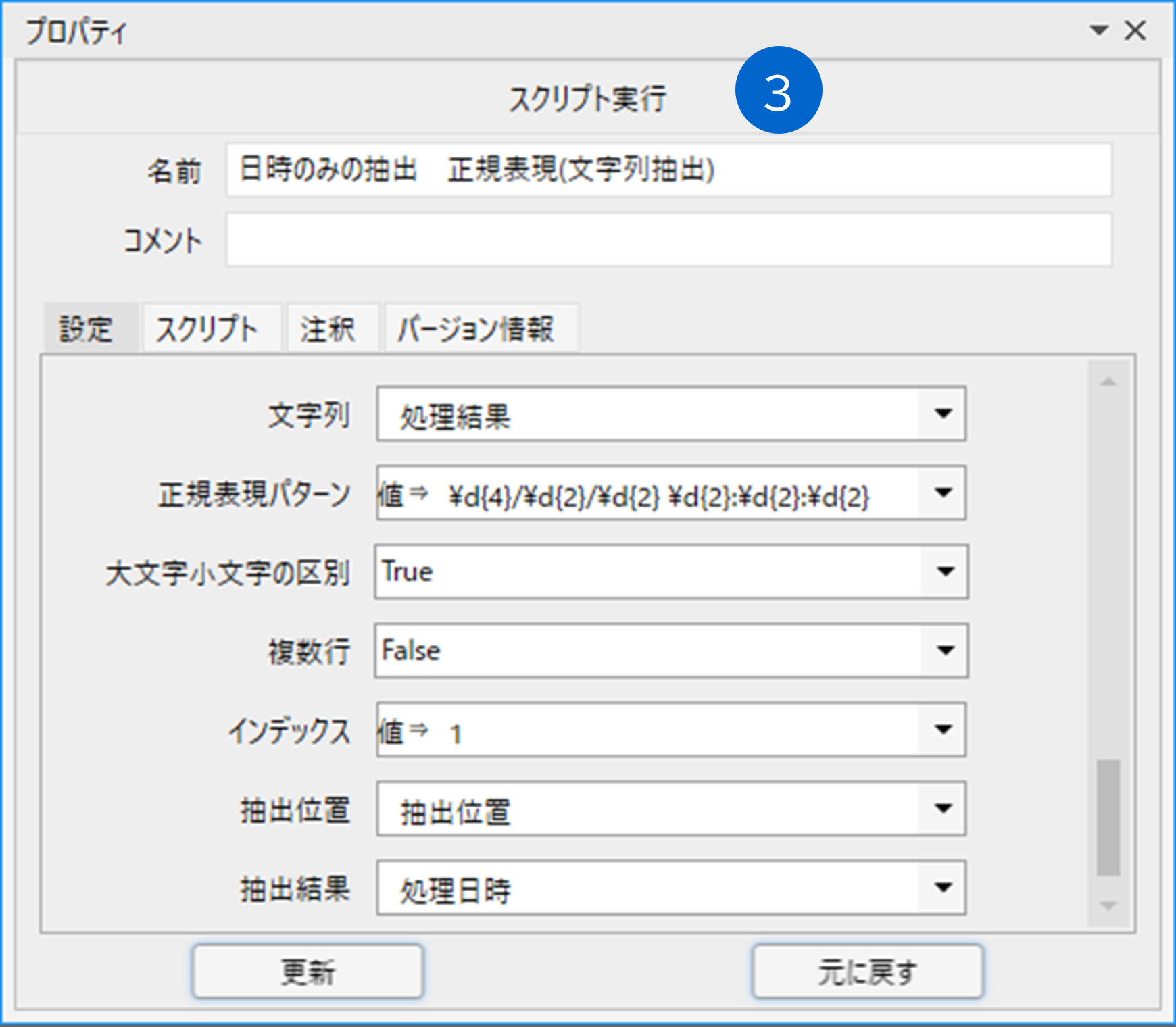
抽出結果の「処理日時」変数を待機ボックスで表示します。
確かに日時部分のみが抽出されていることがわかりますね。
確かに日時部分のみが抽出されていることがわかりますね。
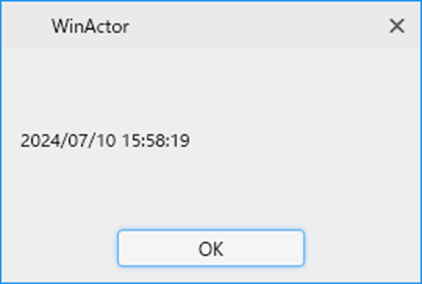
なんかすごいです。これも正規表現を指定すれば一発で抽出できちゃうんですね。
でも正規表現パターンを作り出すところが難しそうな感じがします。正規表現について学習する必要がありますね。
でも正規表現パターンを作り出すところが難しそうな感じがします。正規表現について学習する必要がありますね。
確かに正規表現に馴染みがないと、ちょっとすぐに使いこなすのは難しいかもしれません。
テキストファイルの内容から、ある特定の文字列を含む部分を抽出するということだと、他にはWinActorノートを使う方法が考えられます。
テキストファイルの内容から、ある特定の文字列を含む部分を抽出するということだと、他にはWinActorノートを使う方法が考えられます。
今度はWinActorノートですか。WinActorノートも使い方がよくわかっていないので、是非教えてください。
目次
- 第4回「正規表現 vs WinActorノート で文字列を抽出する」の巻1(今回)
- 第4回「正規表現 vs WinActorノート で文字列を抽出する」の巻2