カスタマーエクスペリエンス
AI
メディア
コミュニケーション
SpeechRec Server
Top -> SpeechRec Server




SpeechRec Serverは、音声・映像をオールインワンで扱うことができる、人間に近い情報処理機構を提供するAPIサーバ(ソフトウェア製品)です。お客様のアプリケーションにAPI呼び出しの処理を追加することで、SpeechRec Serverが提供する機能を利用することができます。
特長
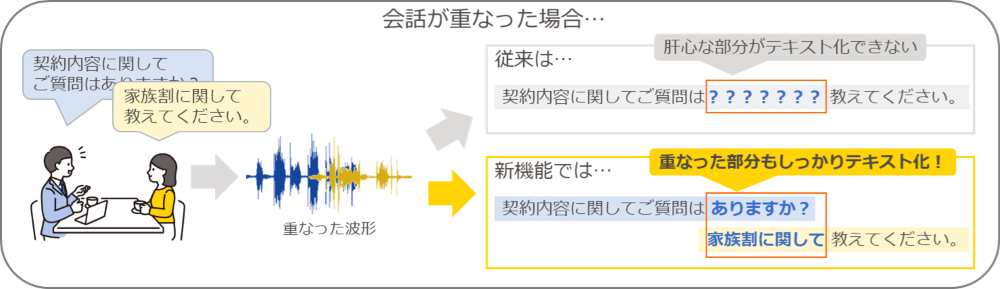
特長1:複数話者の発話が重なった部分もテキスト化できます!
対面シーンに多い重なり合った声を聞き分け、別々の人の発話としてテキスト化できます。
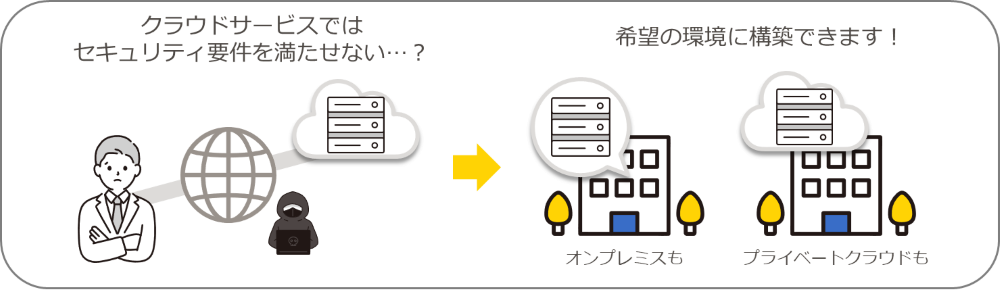
特長2:セキュアにシステム構築が可能です!
お客様の環境にインストールして使用するソフトウェア製品なので、オンプレミス、プライベートクラウドなど、ご希望の環境でご利用いただけます。
特長3:音声認識に加えて映像の解析機能も提供します!
音声/映像を統合的(マルチモーダル)に解析し、音声認識のほかにも感情・年齢・性別の推定や話者の聞き分けができます。
動作条件
● CPUの動作保証はIntel®製のみです。AVX2拡張命令に対応している必要があります。
● コンテナ化プラットフォーム(Docker)が動作する環境が必要です。
● 通信プロトコルはHTTP/1.1(WebSocket)です。SSL/TLSの終端は上位の機器やサービスで行ってください。
その他の詳細はお問い合わせください。
ライセンス種別と価格
開発ライセンスと運用ライセンスの2種類があります。
製品の価格については、利用目的や導入規模などにより御見積いたします。
詳細はお問い合わせください。
ご導入までの流れ
SpeechRec Serverは以下の流れでご導入いただけます。本製品はAPIサーバのため、利用側でアプリ等の開発が必要です。