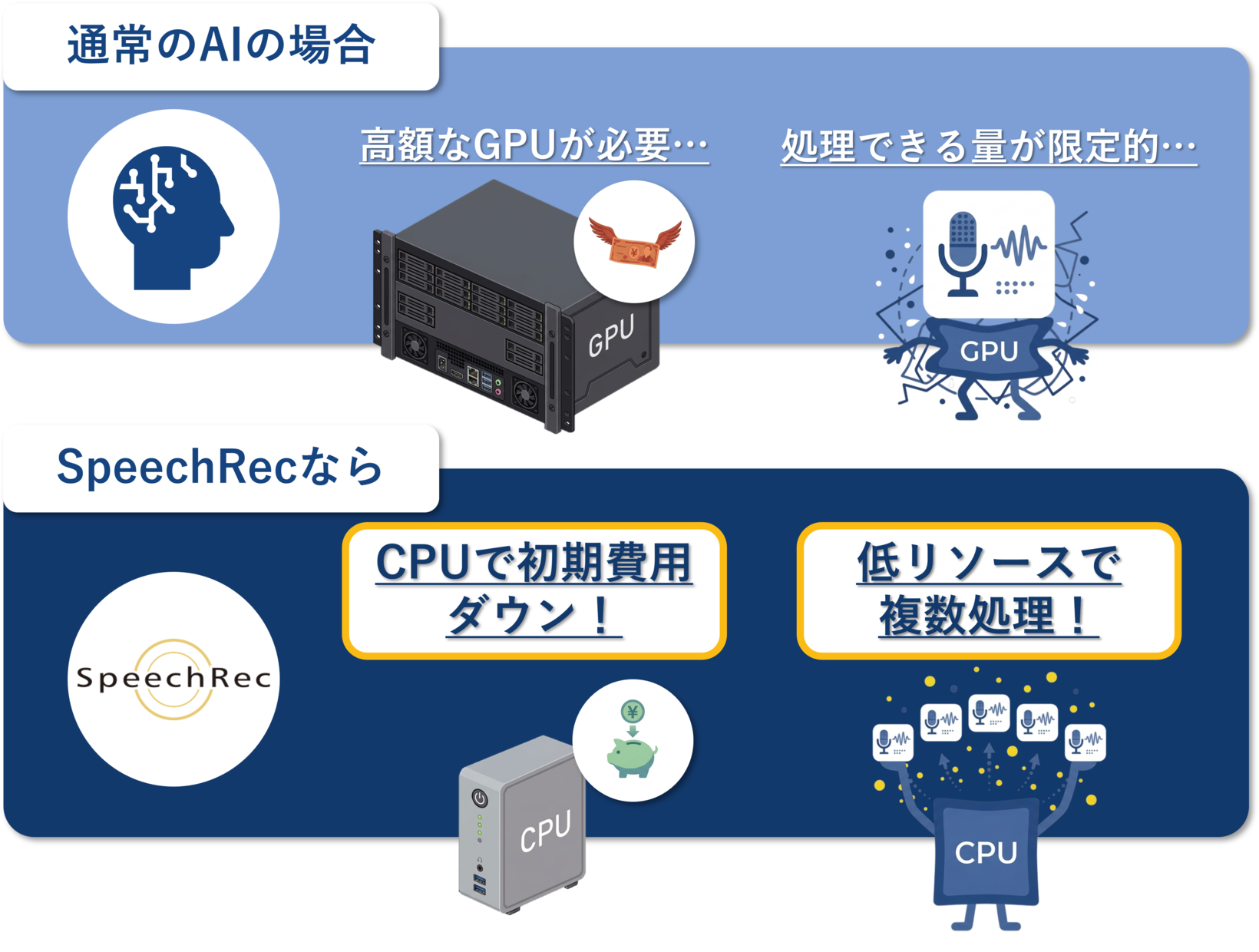
超軽量AIで低コストに
AI処理を実現
 GPU不要で初期費用を大幅カット
GPU不要で初期費用を大幅カット
1つのCPUで複数のAI処理ができるほど軽量
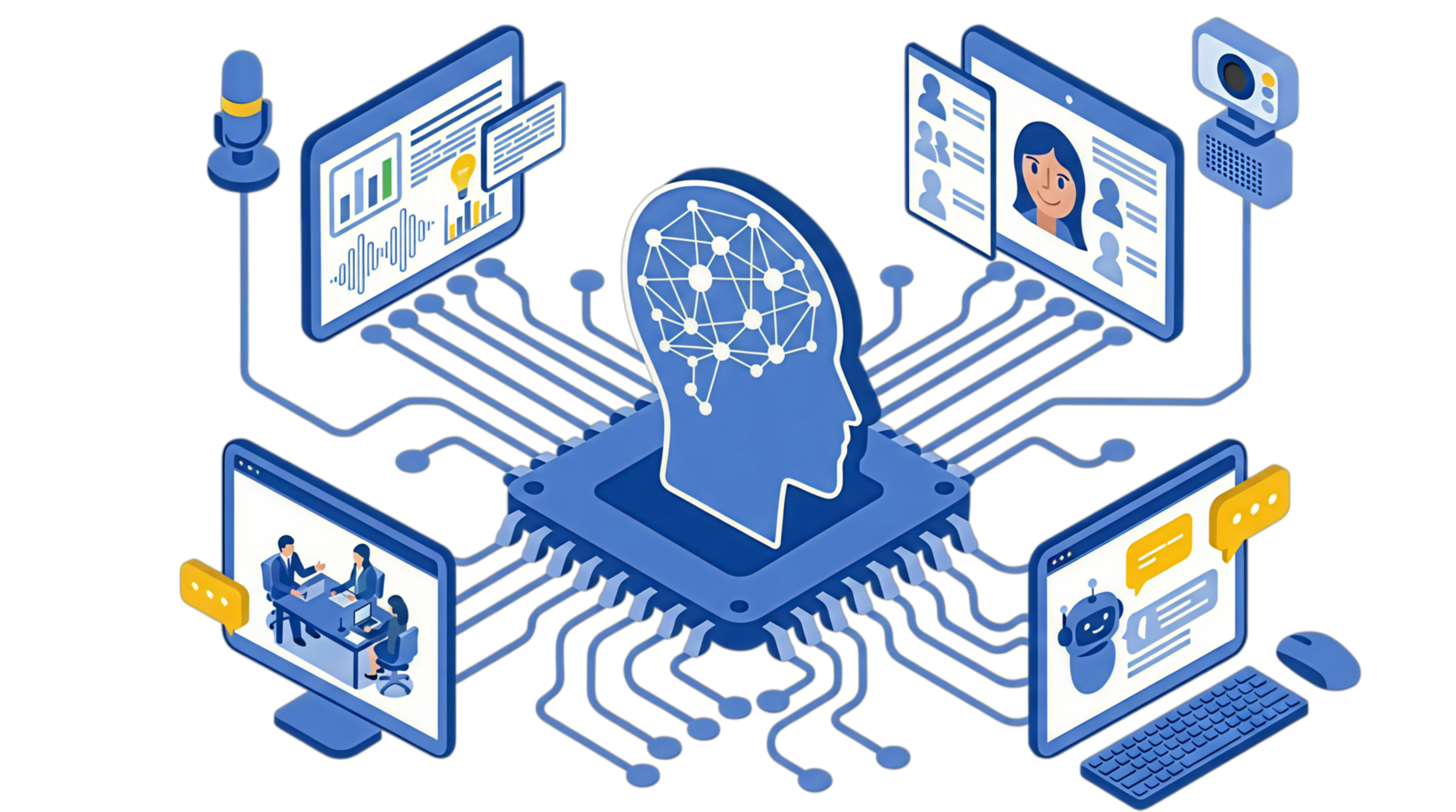
FEATURE音声/映像処理をオールインワンで
NTT研究所の『次世代メディア処理AI「MediaGnosis®」』を用いた、
音声、映像など複数メディアのAI処理を統合的に扱えるAPIサーバです。
SpeechRecを活用した「MediaGnosis®」のデモをこちらでお試しいただけます。
Point 1
信頼の国産技術と豊富な実績

NTT研究所の最新技術
50年以上続くNTT研究所技術を採用。
多くの国際学会に採択された最新の技術

国産のAIエンジン
純国産(NTT研究所)のAIエンジンを採用。
安心してご利用可能

コンタクトセンターへの豊富な実績
IVRやコールセンター会話など、
コンタクトセンター領域に実績豊富
Point 2
オールインワンで使える様々な機能



Point 3
モデルと構築環境を柔軟にカスタマイズ



CASE様々なシーンでの音声や映像データの活用
録音・録画が手軽になり、会話データや映像データを活用できるシーンが増えています。
AIを活用して新しいスタイルを作りませんか。
対面会話の記録に
コールセンターの接客対応に
対面営業の応対品質確認に
対話ロボットの応対に

まずは見えるデータに
記録する余裕はないけれど覚えておきたい。
録音データはあるけれど聞き返すのは大変。
![]()
音声データに対応するテキストデータを作成。
同じ人の発言を区別しておくと、確認/検索が容易です。
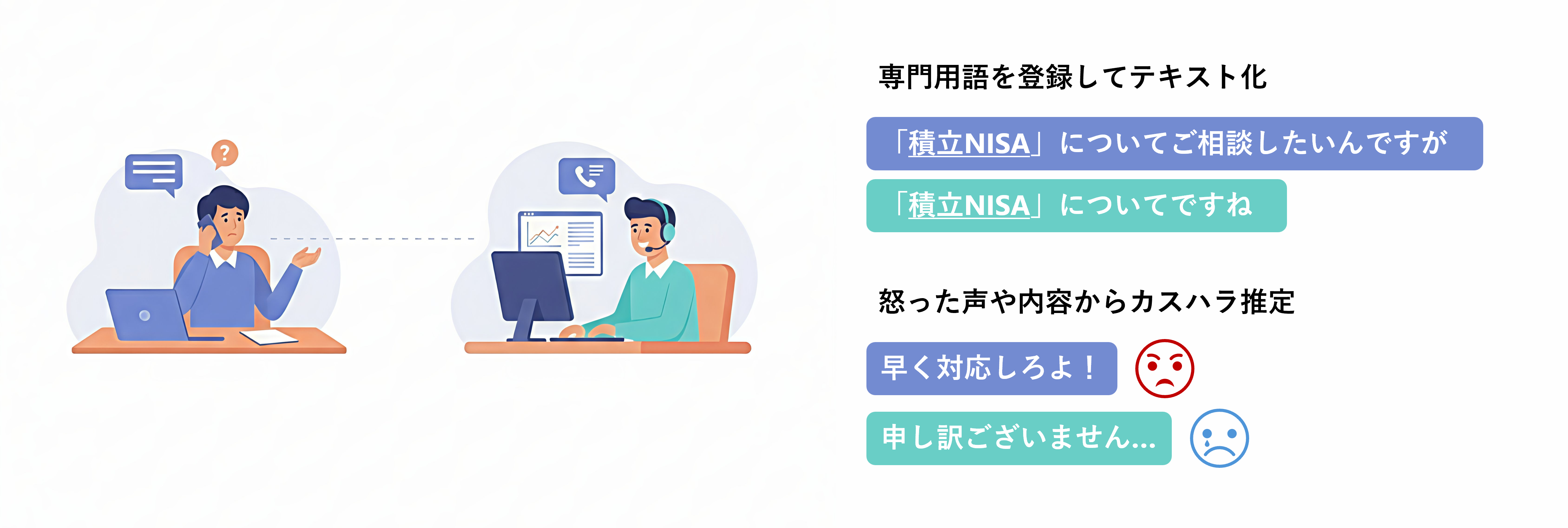
通話記録やカスハラ対策に
専門用語もちゃんと記録したい。
カスハラ対策を行いたい。
![]()
専門用語を登録してテキスト化。
感情の推定結果からカスハラ検知に活用。

感情推定で新たな気づきを
発言内容に問題はないはずなのに、
何故か相手にネガティブな印象を与えてしまう。
![]()
表情や発言から応対時の感情を推定。
推定結果を応対品質のチェックに活用。

FUNCTIONS利用シーンに合わせて機能を選択
高い精度の認識機能や推定機能を利用することができます。
WebSocketで接続し、非同期で解析結果を取得します。
音声処理
日本語音声認識
複数話者音声認識
句読点付与・フィラー除去
ユーザ辞書機能
話者ダイアライゼーション
疑問平叙推定
性別推定(音声)
年齢推定(音声)
感情推定(音声)
映像処理
性別推定(映像)
年齢推定(映像)
感情推定(映像)
表情・動作検出
SPECSスペック
SpeechRecに関するスペック情報です。
| CPU |
vCPU数2以上 ※ Intel®製CPUのみ。 ※ AVX2拡張命令に対応している必要があります。 ※ 使用する機能と同時接続数によって変動するため、別途お問い合わせください。 |
|---|---|
| メモリ |
2GB以上 ※ 使用する機能と同時接続数によって変動するため、別途お問い合わせください。 |
| システム空き容量 |
4GB以上 ※ 使用する機能と同時接続数によって変動するため、別途お問い合わせください。 |
| 動作環境 | コンテナ化プラットフォーム(Docker®)が動作する環境が必要です。 |
| 通信プロトコル |
HTTP/1.1(WebSocket) ※ SSL/TLSの終端は上位の機器やサービスで行ってください。 |
PRODUCTSpeechRecを活用した製品
SpeechRecを活用したNTTテクノクロスの製品ラインナップです。
ForeSight Voice Mining
金融・通信業界を中心に5.6万席以上の豊富な導入実績があるコールセンター向けAIソリューションです。
通話内容のテキスト化
※ デロイト トーマツ ミック経済研究所株式会社 「法人向けヘルスケアソリューション市場の実態と展望【2024年度版】」
健康管理ソリューション市場における従業員規模3000名以上の大手企業による売上高
PRICE料金
同時接続数単位の年間ライセンスでご提供します。
ご利用シーンに合わせて機能一覧に記載の機能を組み合わせて算出します。
詳細はお問い合わせください。
NEWS新着情報
- 2025年11月07日
- お知らせ
- SpeechRec Serverの新バージョン(V6.3)をリリースしました。
- SpeechRecは、NTTテクノクロス株式会社の商標です。
- その他会社名、製品名などの固有名詞は、一般に該当する会社もしくは組織の商標または登録商標です。
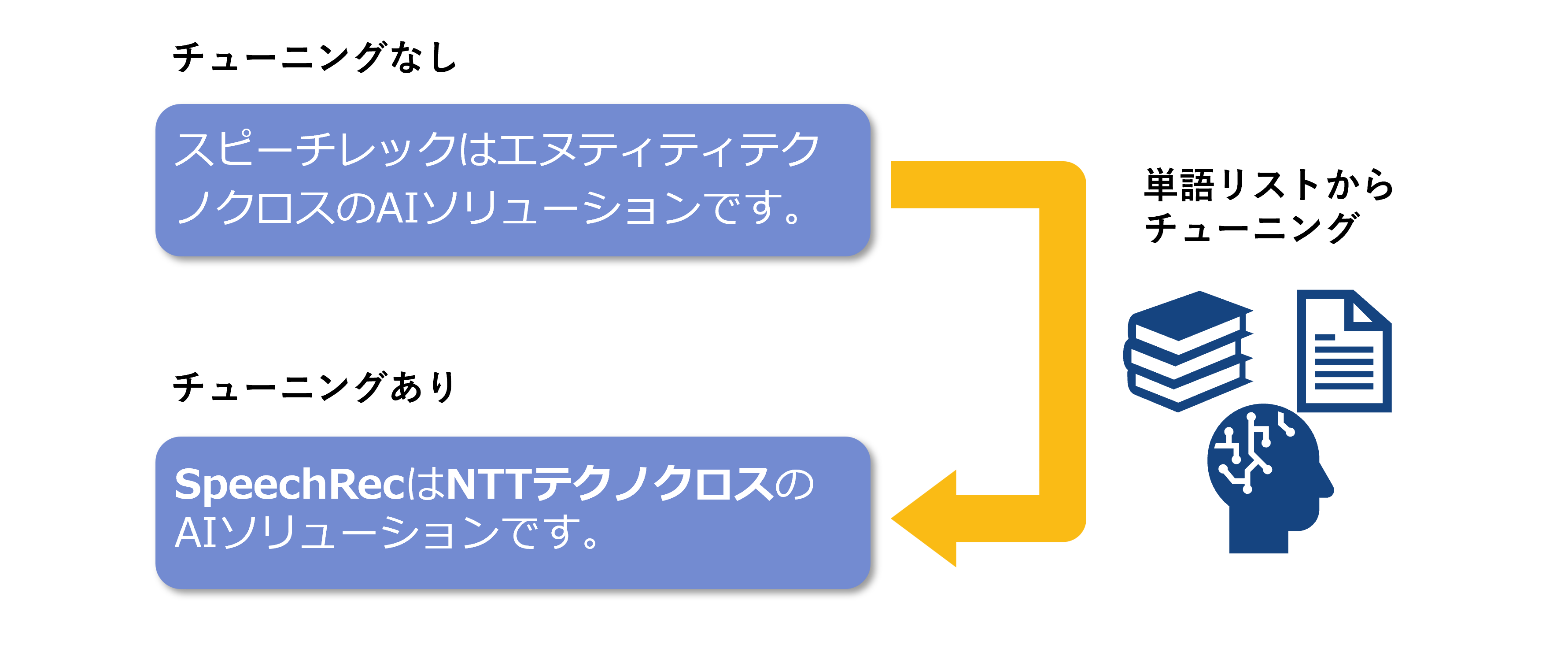
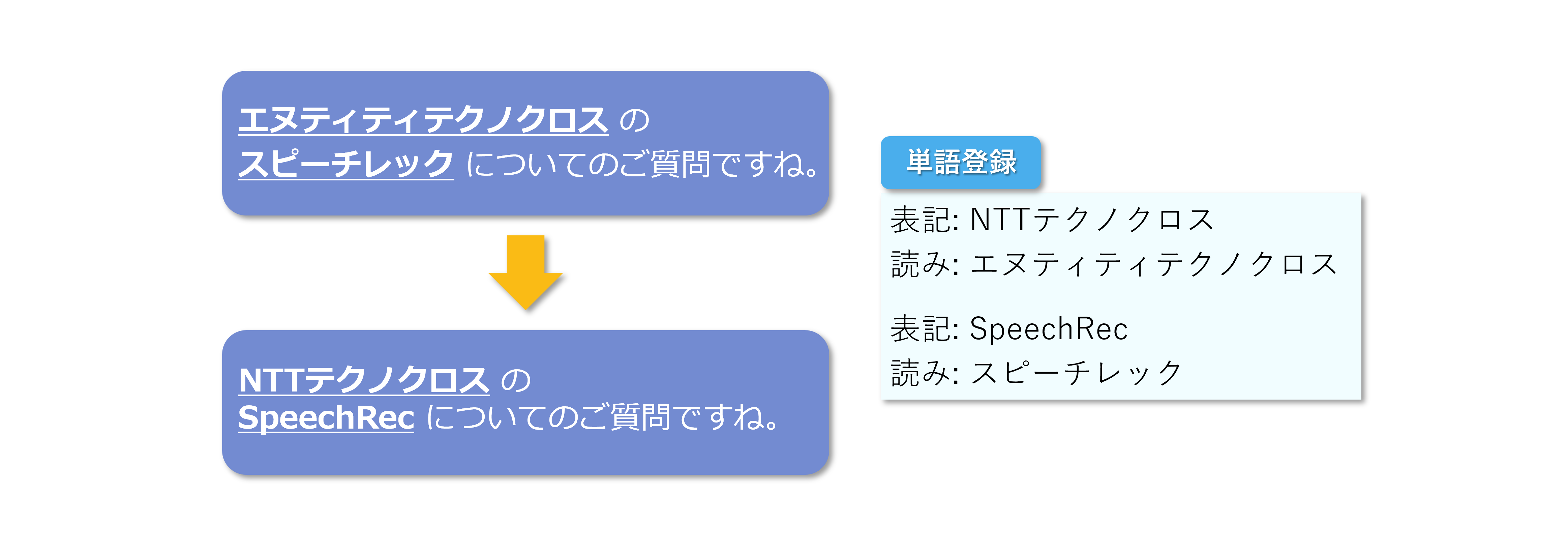
モデルチューニング
モデルチューニングをすることで、専門用語や時事用語を文脈を汲み取って認識できるようになります。
※ モデルチューニングが必要な際は別途お問い合わせください。
※ お客様で簡易的に単語登録可能な「ユーザ辞書機能」もご利用いただけます。
導入イメージ
クラウド上のサーバにSpeechRecをインストールし、お客様のアプリケーションにAPI呼出処理を追加することで、SpeechRec Server が提供する機能を利用することができます。
※ SpeechRecにはハードウェア/OS/Dockerエンジン、およびAPIの呼出元のアプリケーションなどは含まれていません。

導入イメージ
オンプレミスなど閉域環境のサーバにSpeechRecをインストールし、お客様のアプリケーションにAPI呼出処理を追加することで、SpeechRec Server が提供する機能を利用することができます。
※ SpeechRecにはハードウェア/OS/Dockerエンジン、およびAPIの呼出元のアプリケーションなどは含まれていません。

日本語音声認識
日本語で音声をテキスト化します。

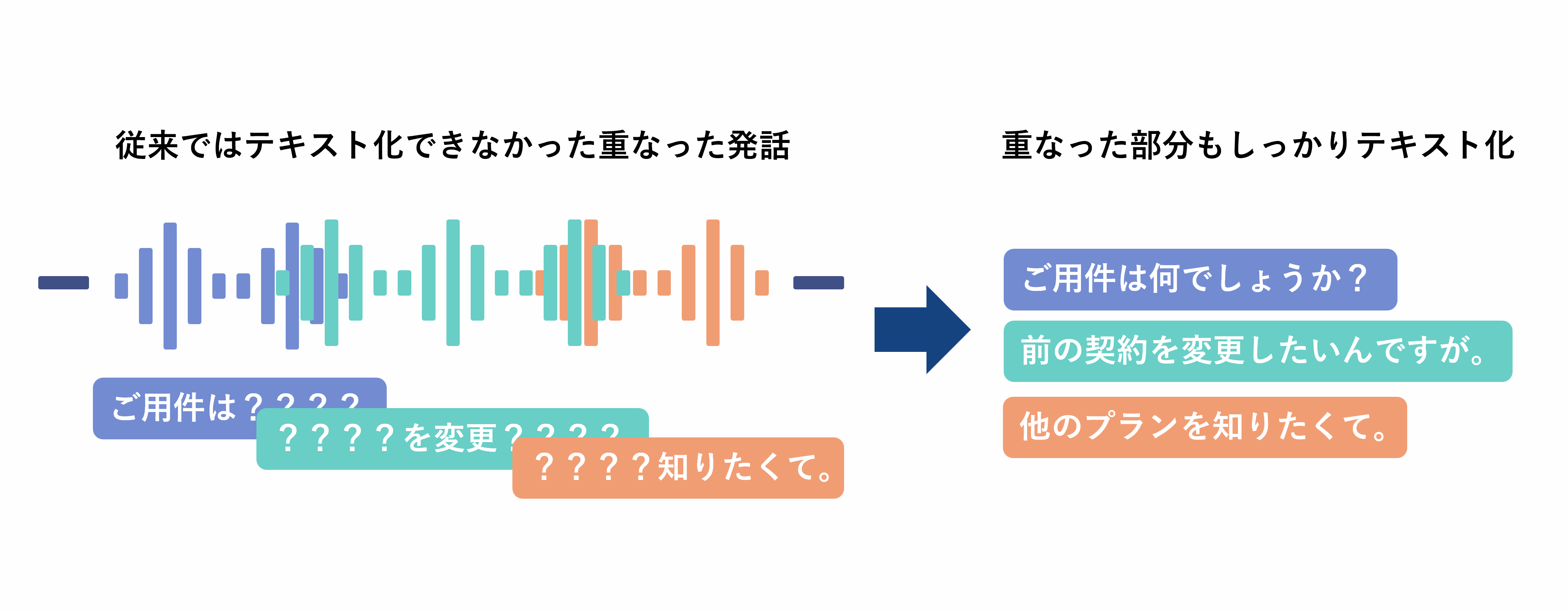
複数話者音声認識
対面シーンで多い重なり合った声を聞き分け、別々の人の発話としてテキスト化できます。

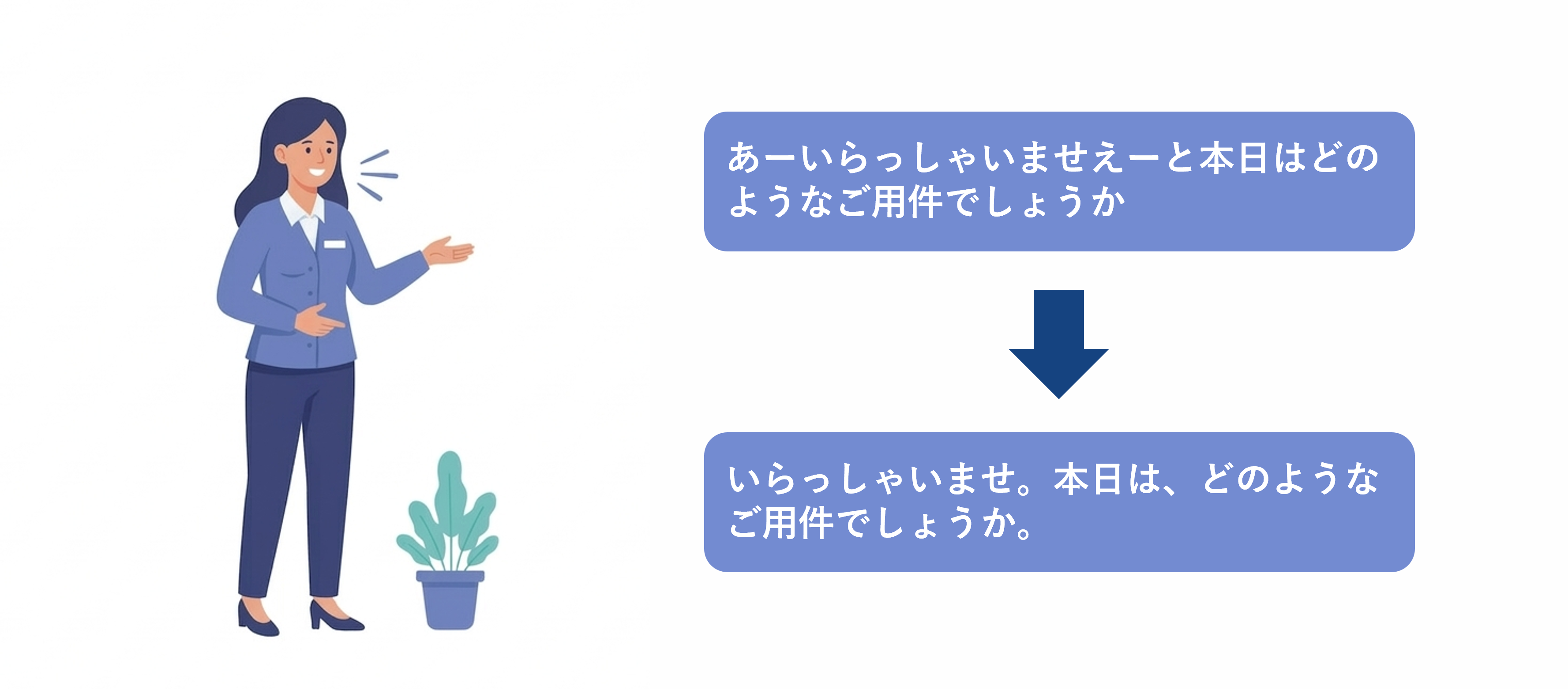
句読点付与・フィラー除去
「あー」や「えー」などのフィラーを除去したり、句読点を付与することで、
テキスト化結果を読みやすく整形します。
話者ダイアライゼーション
1チャンネルの音声に複数の話者が発話していた場合に、発話ごとに話者を分類してラベル付けします。

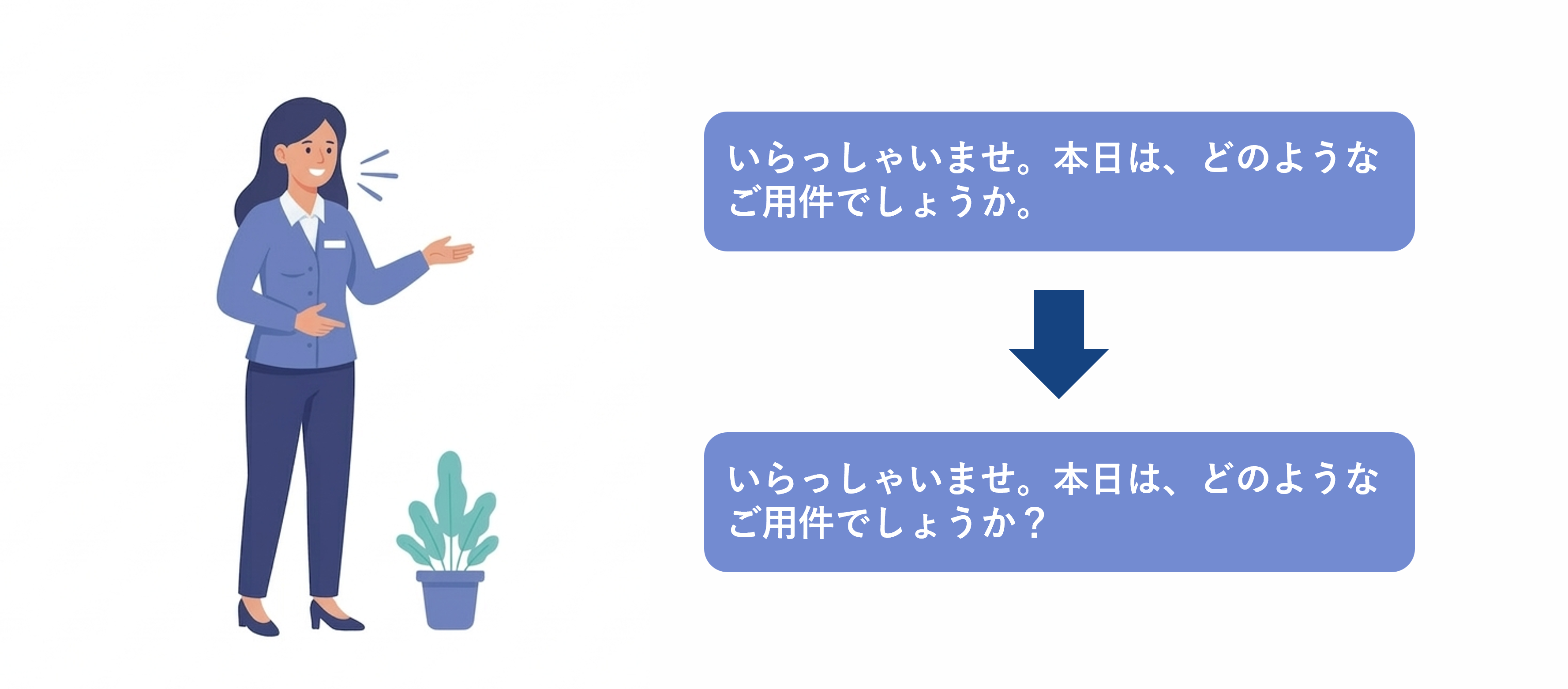
疑問平叙推定
音声の特徴から疑問文であるかどうかを推定します。
性別推定(音声)
入力された音声から、発話ごとに男声か女声かを推定します。

年齢推定(音声)
入力された音声から、発話ごとに年齢を推定します。

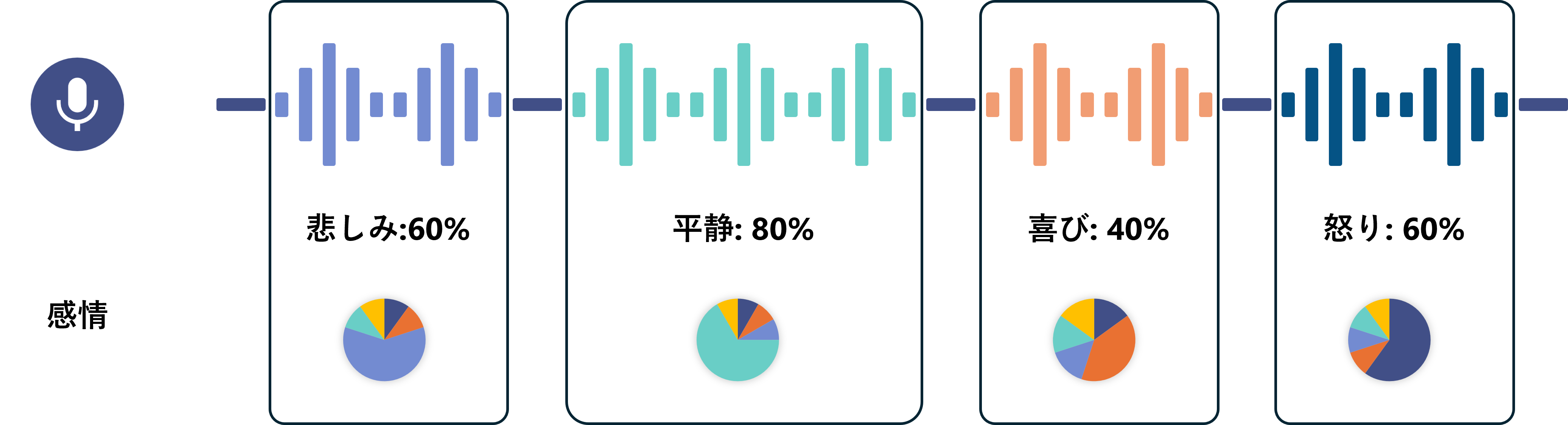
感情推定(音声)
入力された音声から、発話ごとに感情(平静/喜び/悲しみ/怒り/驚き)を割合で推定します。
性別推定(映像)
入力された映像から顔を検出して性別を推定します。
複数の顔が検出された場合は、それぞれについて推定します。
※ 処理する上限数は変更可能です。


年齢推定(映像)
入力された映像から顔を検出して年齢を推定します。
複数の顔が検出された場合は、それぞれについて推定します。
※ 処理する上限数は変更可能です。

感情推定(映像)
入力された映像から顔を検出して感情(平静/喜び/悲しみ/怒り/驚き)を割合で推定します。
複数の顔が検出された場合は、それぞれについて推定します。
※ 処理する上限数は変更可能です。

表情・動作検出
入力された映像から顔の視線方向、うなずき、まばたき、顔の向き、キーポイント(目/鼻/口の位置)を検出します。
複数の顔が検出された場合は、それぞれについて推定します。
※ 処理する上限数は変更可能です。
