デジタルトランスフォーメーション
セキュリティ
匿名加工情報作成ソフトウェア tasokarena(タソカレナ)
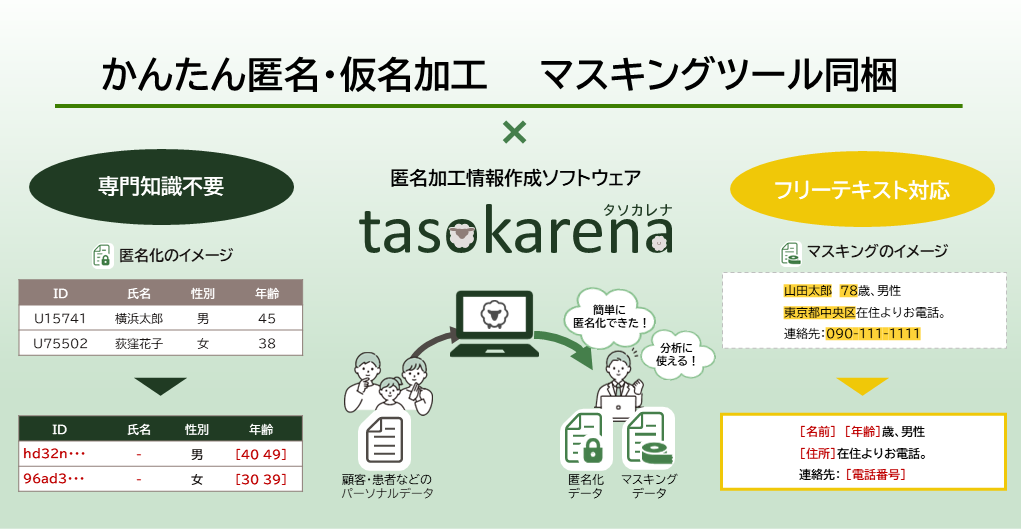

匿名加工情報を作成できる「匿名加工情報作成ソフトウェア tasokarena」とは
医療・ヘルスケア分野に限らず、金融、コールセンター、自治体などの分野でも利用されています。
改正個人情報保護法*1の全面施行(2017年5月30日)で、個人情報を匿名加工情報に加工すれば本人から同意を得なくても一定の条件を満たすことで目的外利用・第三者へ提供ができるようになりました。それに伴い個人情報の利活用への関心も高まっています。
tasokarenaは、個人情報を法令にしたがって適切に匿名加工情報※に加工することを支援するソフトウェアです。
加工ルールはユーザの手で調整可能であるため、次世代医療基盤法*2に基づいた認定医療情報等取扱受託事業者や、仮名加工情報*3の作成においても使用できます。
使用するデータの特性や利用目的に応じて最適な加工方法の選択と加工結果を評価する環境を提供します。
※「匿名加工情報」とは、特定の個人を識別することができないように加工して得られる個人に関する情報であって、当該個人情報を復元して特定の個人を再識別することができないようにしたものです。

新機能の特徴
昨今、国内DX(デジタルトランスフォーメーション)が加速し、データ利活用が注目されています。その中で、パーソナルデータ*4から特定の個人を識別できないように加工した匿名加工情報は、個人情報保護法や次世代医療基盤法などの関連する法整備と共に利活用が拡大しています。政府機関の個人情報保護委員会は、匿名加工情報の作成・提供に関する公表を行っている事業者が2020年3月時点で500社に上るとしています*5。
しかし、匿名加工情報の作成では、元のパーソナルデータの数が少ない場合にはデータの匿名性か有用性のどちらかが低下するという課題があったり、緻密な分析を行う際にはデータの有用性の観点から匿名加工情報よりも実際のパーソナルデータが活用されたりするのが現状です。NTTテクノクロスは、より高度なデータ利活用を実現するため、パーソナルデータの匿名性を維持したまま分析の精度や範囲を高めるためv4で搭載を開始した機能「合成データ生成」をさらに強化し、ベイジアンネットワークをもとに合成データを生成する機械学習的手法(差分プライバシー対応)を追加し、発売いたします。

![]() データとしての有用性を維持した架空のパーソナルデータを合成
データとしての有用性を維持した架空のパーソナルデータを合成
合成データ生成機能は、元のパーソナルデータから特徴量や統計量・分布などが類似するデータを生成し、実在しないが具体的なパーソナルデータ(合成データ)を作り上げます。匿名性やプライバシーを守りつつ、分析に必要な元のデータの性質を保持したデータを生成するため、従来の匿名加工情報作成ソフトウェアによるパーソナルデータの一般化*6や削除、ランダム化されたデータと比べて、例えば数値属性を維持したまま複数の属性の相関関係に関する統計分析等、より緻密なデータ分析が可能になります。また、少ないデータから匿名化された大量の合成データを生成できるため、膨大なデータを必要とするAIの学習や訓練などに活用できます。

![]() NTT研究所の合成データ生成技術(特許技術)を活用
NTT研究所の合成データ生成技術(特許技術)を活用
NTT社会情報研究所の特許技術である合成データ生成技術を活用しています。各属性の平均など統計値が元データとほぼ等しい合成データを生成する技術等を独自に開発し、これまでプライバシー保護技術では実現できなかった、分析に必要な複数の統計値を保持する多属性の合成データを生成することが可能になりました。NTT社会情報研究所は本技術の開発で培った知見を活用し、AI・機械学習分野における難関国際会議の匿名化技術を競うコンペティションで優勝*7しました。
基本機能
特長1:NTT独自技術含む豊富な加工技法を提供
![]() NTT研究所技術であるPk-匿名化*8を実用化
NTT研究所技術であるPk-匿名化*8を実用化
NTTが独自に開発した手法である「Pk-匿名化」を実用化し、本ソフトウェアに搭載しています。匿名性の代表的な指標であるk-匿名性*9を満たすようにノイズ(疑似データ)の付与やデータの入れ替えを行い、データの有用性が損なわれにくい匿名加工情報を作成します。

![]() 数十種類の加工技法から、加工するデータに合わせた技法を選択可能
数十種類の加工技法から、加工するデータに合わせた技法を選択可能
直観的な画面操作により、数十種類の加工技法の中から実行する加工技法を組み合わせ、匿名加工情報を作成することが可能です。本ソフトウェアはスタンドアロンPC上での動作が可能です。

![]() 履歴型データについてもk-匿名化、Pk-匿名化が可能
履歴型データについてもk-匿名化、Pk-匿名化が可能
受診履歴データや購買履歴データといった履歴型データについて、履歴型データ(1ユーザ複数レコード)の状態で、k-匿名化、Pk-匿名化を行うアルゴリズム(NTT独自技術)を実装し、受診履歴データや購買履歴データといった履歴型データについても加工と評価を実行することが可能です。
![]() フィルタ機能により、指定した属性に対して条件に合致したレコードの抽出が可能
フィルタ機能により、指定した属性に対して条件に合致したレコードの抽出が可能
加工対象のデータに含まれる各分野に存在する特異とされる条件(年度と病名の組み合わせ等)に該当するレコードのみに加工を行いたい場合、フィルタ機能を利用することで条件に合致したレコードのみを抽出し、加工することができます。例えば、医療分野において2015年に発生したエボラ出血熱感染症疑似症患者に関するレコードのみに加工を行いたい場合、フィルタ機能にて病名が「エボラ出血熱」と設定することで、条件に合致したレコードのみを抽出し、加工することができます。

![]() 履歴データの分析に必要な日付情報の価値を維持しながら加工
履歴データの分析に必要な日付情報の価値を維持しながら加工
履歴データを有効に利活用するために、日付の順序や期間など必要とするデータの価値を残したまま、日付をランダム化することができます。 例えば、医療業界において新薬や医療機器などの開発には、患者の病状に関する情報として病名のほか、入退院や投薬の日付といった情報が重要となります。しかし、これらの日付に関する情報は病名など具体的な情報と合わさって個人が特定される可能性があります。本ソフトウェアではこれらに対応した日付を加工する技法により、安全性と有用性両方を考慮した加工を実現します。

特長2:匿名性・有用性の評価機能
![]() 多様な評価技法によりデータの匿名性と有用性をグラフィカルに表示
多様な評価技法によりデータの匿名性と有用性をグラフィカルに表示
tasokarenaで作成した匿名加工情報は、15種類の評価技法により匿名性と有用性のバランスをグラフで確認することが可能です。このグラフを参考にしながら加工技法の組み合わせを変えることで、独自の加工ルールを設定していくことが可能になります。

特長3:選べる製品ラインナップ
![]() スタンダード版とエンタープライズ版を提供
スタンダード版とエンタープライズ版を提供
スタンドアロンで動作可能なスタンダード版と、コマンド実行、データベース連携、自動実行が可能なエンタープライズ版を提供します。

![]() 匿名加工機能を自社システムと連携可能(エンタープライズ版)
匿名加工機能を自社システムと連携可能(エンタープライズ版)
加工したい個人情報の取り込み方法としてCSVファイルに加えてデータベースにも対応する「データベース連携機能」と、さらにルール化した加工技法に従って自動的に匿名加工情報へと加工する「自動実行機能」を実装します。 例えば、医療分野における電子化されたカルテや明細書を一元的に管理しているシステムから匿名加工情報を作成したい場合は、データベース連携機能を使うことにより、システム間での連携が可能になります。 また本ソフトウェアの自動実行機能により、ユーザーによる操作を必要とせず匿名加工情報への加工が可能です。ユーザーの負担を最小限に抑え、加工の定期実行が可能です。
特長4:マスキングツールで情報共有の安全性を向上
![]() 自由記述形式の文章に含まれる個人情報の削除
自由記述形式の文章に含まれる個人情報の削除
同一事業者内での情報共有の安全性を高める目的として、自由記述形式で記載された文章に含まれる個人情報を削除するマスキングツールを提供します。医師の所見や患者の診療記録、コールセンターの対応履歴データ等の文章に含まれる個人情報に対して、自然言語解析によって氏名や住所などを自動で判別し、削除することが可能です。これにより、ユーザーの作業負担を軽減しながら、情報共有における安全性の向上を実現します。

※マスキングツールAPIのご用意もございます。詳細はお問合せください。
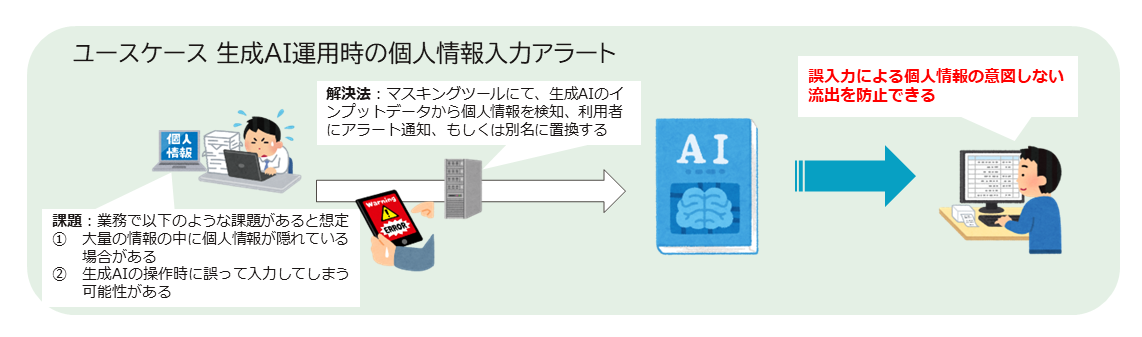
![]() 生成AI を利用する際の個人情報誤入力を検知して警告
生成AI を利用する際の個人情報誤入力を検知して警告
生成AIを利用する際の個人情報の誤入力を防ぐことを目的として、個人情報を検知しアラートを通知する機能の提供を検討中になります。生成AI に渡すデータを必ずtasokarena でチェックすることで、個人情報を検知した場合にはアラートを受けてデータ投入をキャンセルできるような機能を予定しております。
特長5:その他豊富なオプション
![]() AI機能により加工ルールの検討を支援
AI機能により加工ルールの検討を支援
tasokarenaの付属ツールとして加工ルール自動生成ツールを提供します。本ツールにパーソナルデータを入力・設定することにより、データの値から個人を特定できるかの危険性をAI機能が判別し、そのデータに対して適用を検討すべき加工ルールが提案されます。これにより、数十種類ある加工技法からどの技法を適用すればよいかをゼロから検討する手間が削減され、匿名加工情報を扱った経験が少ない医療の現場担当者や、あらゆるユーザーの負担軽減につながります。
![]() 手間なくレセプトデータの匿名加工が可能
手間なくレセプトデータの匿名加工が可能
医療向けパッケージ(別料金)として、自治体・医療機関・健康保険組合などの共通仕様になっているレセプトデータ*10をtasokarenaで読み込み可能にする変換ツールを提供します。レセプトデータのフォーマットはレコード識別情報の値によってレコード項目数や記録内容の形式が異なるため、匿名加工情報を作成する場合には、事前にユーザーによるデータの形式を合わせるなどのクレンジング処理が必要でした。変換ツールを使用することでユーザーによる手間が削減され、さらに変換後のレセプトデータから作成した匿名加工情報を再び元のレセプトデータのフォーマットに戻すことが可能になり、既存システムでも匿名加工情報を利活用できます。
![]() 国際的臨床試験データ標準(CDISC)フォーマットの匿名加工が可能
国際的臨床試験データ標準(CDISC)フォーマットの匿名加工が可能
匿名加工したデータセット間の整合性を維持できるよう、 データ削除ツールを提供します。CDISC標準のデータモデルは複数のデータセットで構成されています。 PhUSE*11の非特定化標準を基に、匿名加工したデータセット間の整合性を維持できるよう、指定したファイルを起点に削除対象レコードを特定し、紐づけされているデータセットに対して、削除処理を行います。データ削除ツールを使用することでデータセット間の不整合を防ぎ、データ利活用を遂行することができます。
【用語解説・注釈】
*1:2017年5月施行の改正個人情報保護法により、個人情報を「匿名加工情報」に加工し一定の条件を満たすことで、本人の同意なく柔軟な利活用が可能となりました。「匿名加工情報」とは、特定の個人を識別することができないように加工して得られる個人に関する情報であって、当該個人情報を復元して特定の個人を再識別することができないようにしたものです。
*2:「医療分野の研究開発に資するための匿名加工医療情報に関する法律(平成29年法律第28号)」の略称。
*3:2020年6月の改正個人情報保護法の公表により、氏名等を削除した『仮名加工情報』を創設、内部分析に限定する等を条件に、開示・利用停止請求への対応等の義務を緩和することが可能となりました。仮名加工情報とは、「他の情報と照合しない限り特定の個人を識別することができないように加工して得られる個人に関する情報」です。
*4:特定の個人を識別することができるかを問わず、個人に関する情報全体を指します。
*5:出典 パーソナルデータの適正な利活用の在り方に関する実態調査(令和元年度)報告書(個人情報保護委員会)
https://www.ppc.go.jp/files/pdf/personal_date_report2019_1.pdf
*6:パーソナルデータの個人情報が含まれる記述などについて、上位概念もしくは数値に置き換えること、または数値を四捨五入などして丸めることを指します。
例)生年月日を月までに丸めた記述に置き換える、年齢を10代に丸める など
*7:出典 日本電信電話株式会社の発表資料
*8:Pk-匿名化とは、データの一部分を確率的に書き換えるランダム化の処理と、元の状態を推定する再構築という処理により、理論的にk-匿名性を満たしつつ、元のデータの統計的性質をなるべく保った有用性の高いデータを作成する技術です。
参考情報: ビッグデータ時代における新たなパーソナルデータ匿名化システムを開発
安全かつ有用な「匿名加工情報」の作成を支援するソフトウェアを開発
*9:k-匿名性とは、匿名化されたデータの安全性を示す指標の1つです。匿名化されたデータから少なくともk人以上にしか個人を識別できない(1/k未満の確率でしか個人を識別できない)とき、そのデータはk-匿名性をもつといいます。
*10:レセプト(診療報酬明細書)とは、医療費の請求明細のことで、保険医療機関・保険薬局が保険者に医療費を請求する際に使用するものです。電子レセプトとは、厚生労働省が定めた規格・方式(記録条件仕様)に基づきレセプト電算処理マスターコードを使って、CSV形式のテキストで電子的に記録されたレセプトのことを指します。
*11:Pharmaceutical Users Software Exchangeの略
*12:Wordは、米国Microsoft Corporationの米国およびその他の国における商標または登録商標です。
動作環境と価格
ソフトウェア動作環境
|
項目 |
要件 |
|
CPU |
Intel Core i5 1.8GHz 以上 |
|
メモリ |
8GB 以上 |
|
ディスク |
HDD 10GB 以上 |
|
画面の解像度 |
デフォルト1440×900 |
|
OS |
Windows |
|
クラウド環境 |
AWS、Azure |
| 連携先DBMS |
Oracle、PostgreSQL、MySQL |
※データ量や加工技法等によっては、よりハイスペックな環境をご用意頂く必要があります。
※詳細はお問い合わせください。
プランと価格
NTTテクノクロスでは、匿名加工、仮名加工、マスキングといったツールの提供にとどまらず、お客様のニーズに応じたシステム開発を含むトータルソリューションを提供しています。
例えばデータのクレンジングやデータ流通のための仕組み構築まで、一貫して対応可能です。
※価格についてはお問い合わせください。
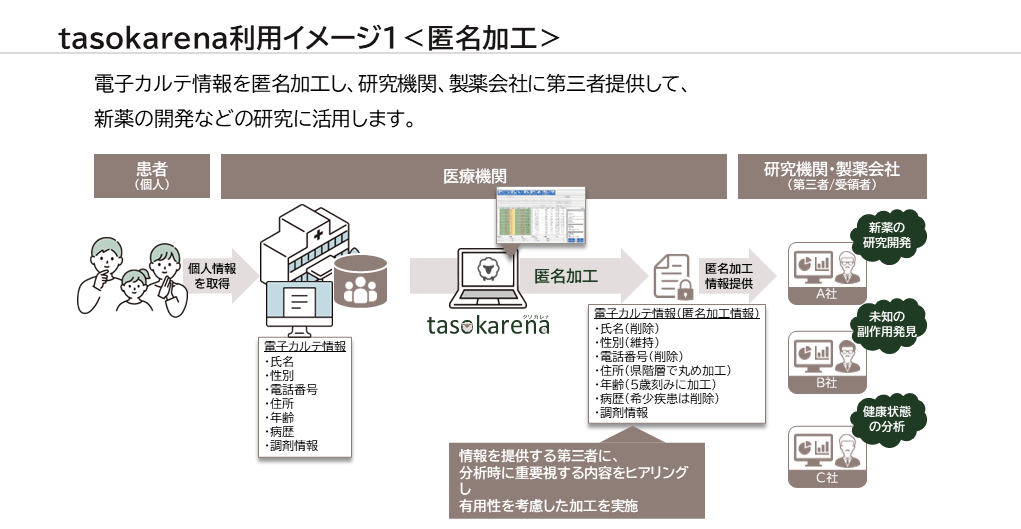
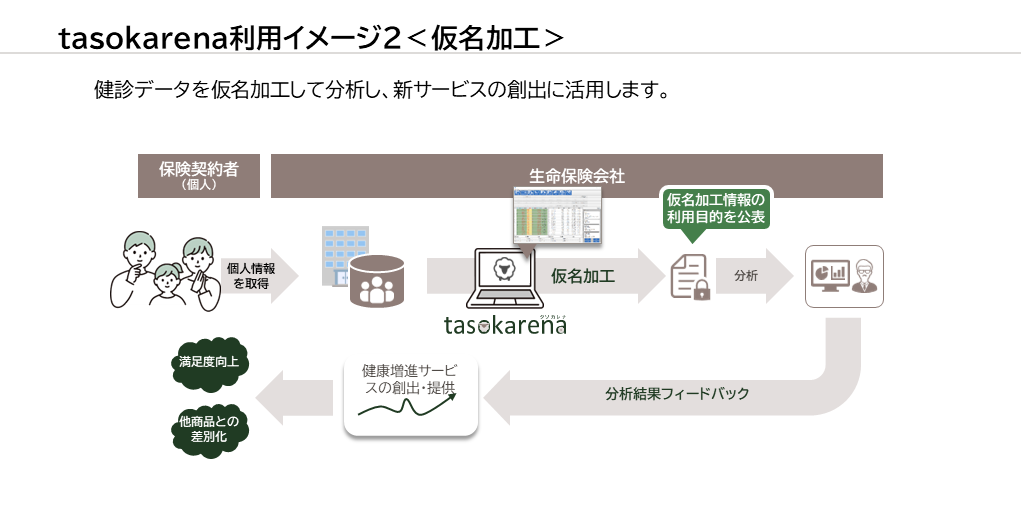
利用イメージ&導入事例
tasokarenaの利用イメージと導入事例を紹介します。
利用イメージ
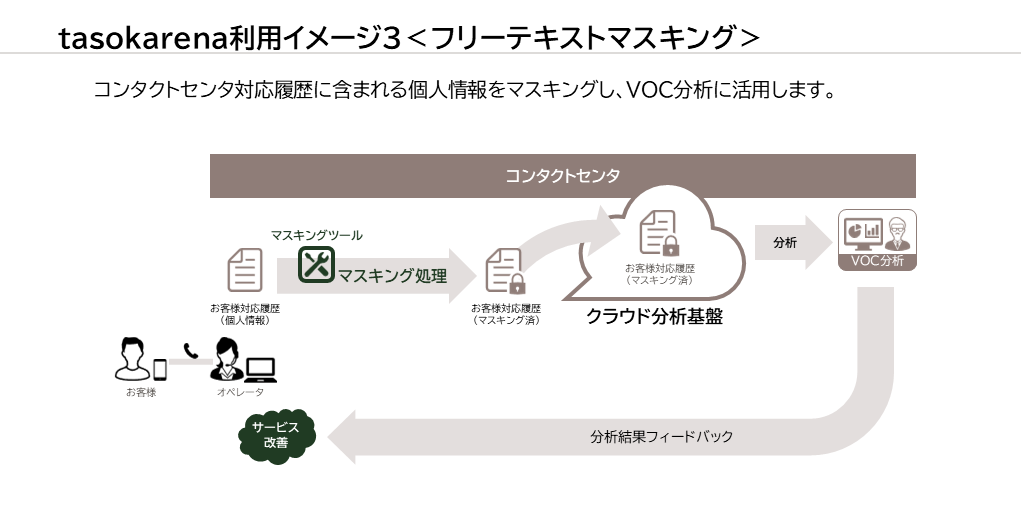
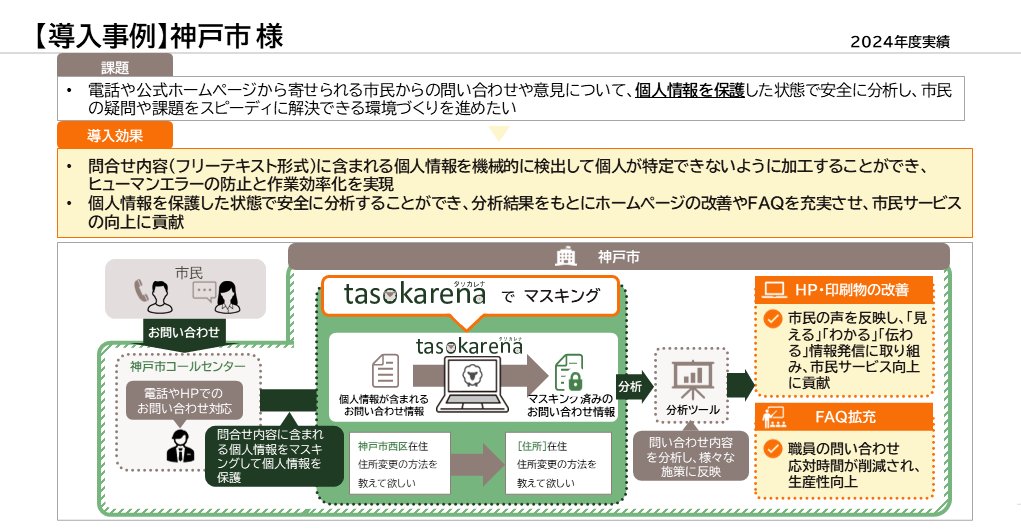
導入事例(1)神戸市 市民からの問い合わせ情報を匿名化して分析し、HP改善に活用
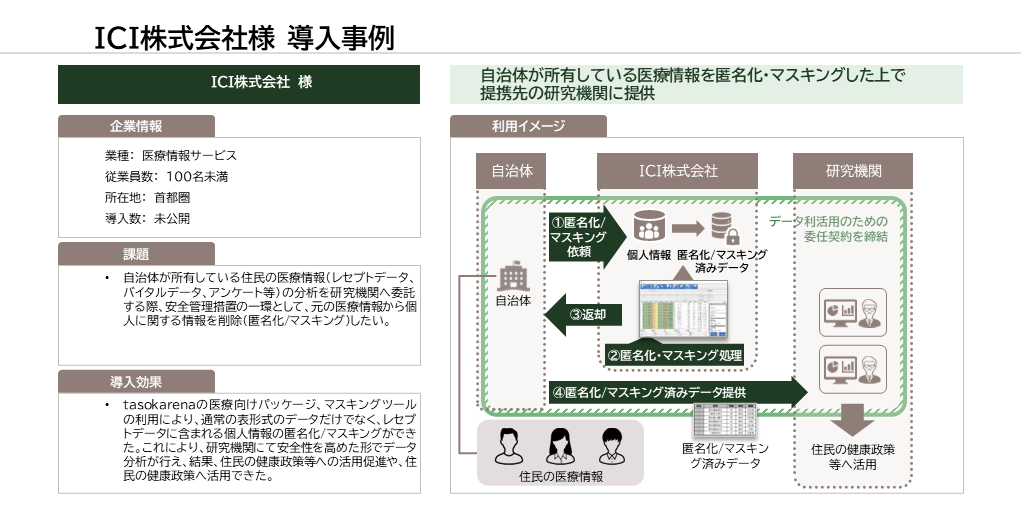
導入事例(2)ICI株式会社 自治体の医療情報を匿名化し、研究に活用
加工技法と評価技法
加工技法一覧
|
加工技法大分類 |
加工技法中分類 |
本ソフトウェアでの技法名称 |
|
秘匿 |
属性秘匿 |
属性削除 |
|
仮ID化 |
||
|
レコード、セルまたは属性値の一部の秘匿 |
レコード削除 |
|
|
セル削除 |
||
|
墨消し |
||
|
過多/過少履歴レコード削除 |
||
|
変更 |
一般化 |
文字列一般化 |
|
数値一般化 |
||
|
日付一般化 |
||
|
数値区分化(型維持) |
||
|
日付区分化(型維持) |
||
|
日付区分化(旬/週) |
||
|
コーディング |
トップコーディング |
|
|
ボトムコーディング |
||
|
トップボトムコーディング |
||
|
丸め処理 |
丸め単位指定数値四捨五入 |
|
|
数値四捨五入 |
||
|
数値切り捨て丸め |
||
|
k-匿名化 |
一般化&削除k-匿名化 |
|
|
削除k-匿名化 |
||
|
ミクロアグリゲーション |
MDAVミクロアグリゲーション |
|
|
Mondrianミクロアグリゲーション |
||
|
Pk-匿名化 |
基本Pk-匿名化 |
|
|
ノイズ付加ハイブリッドPk-匿名化 |
||
|
データ依存Pk-匿名化 |
||
|
属性ランダム化 |
単純ノイズ付与 |
|
|
ガウスノイズ付与 |
||
|
ラプラスノイズ付与 |
||
|
維持置換撹乱 |
||
|
ランダムスワッピング |
||
|
順序維持日付間隔ランダム化 |
||
|
順序維持日付ランダム加算 |
||
|
日付一律加算 |
||
|
並び順ランダム化 |
レコードシャッフル |
|
|
レコードサンプリング |
レコードサンプリング |
|
|
擬似データ生成 |
擬似データ生成 |
|
|
合成データ生成 |
合成データ生成 |
|
| その他アドオン | ||
評価技法一覧
| 種類 | 評価技法名 |
| メイン指標 | メイン指標 |
| 匿名性評価技法 | 照合可能性 |
| 照合可能性(数値のみ) | |
| k-匿名性 | |
| k-匿名性(マスター属性のみ) | |
| 有用性評価技法 | 最頻値 |
| 基本統計量 | |
| 相関係数 | |
| ヒストグラム | |
| クロス集計(誤差) | |
| クロス集計 | |
| レコード編集数 | |
| セル編集数 | |
| 再構築誤差 |
*tasokarenaはNTTテクノクロス株式会社の商標です。その他会社名、製品名などの固有名詞は、一般に該当する会社もしくは組織の商標または登録商標です。