Elastic{ON} 2018 最終日レポート
Elastic{ON} 2018に参加してきます! 現地の状況を毎日速報でご紹介しますのでお楽しみに!




Step up Elastic Stack
- 2018年03月02日公開
最終日!
NTTテクノクロスの西園です。
あっという間にElastic{ON} 2018の最終日となってしまいました。
昨日の夜は懇親会の「Lucky Strike Night」で、文字通り「Lucky Strike」を達成したこともあり、高いテンションを維持したまま最終日を迎えることができました。
今日はなんといっても、注目度第一位の 「Elasticsearch SQL」 と 第二位の「Machine Learning in the Elastic Stack」 のセッションがありました!
最初はこちらから。
The State of Geo in Elasticsearch
Geo情報を活用する需要が高まっていることもあり、懇親会翌日の最初のセッションですが気合で参加してきました。
ブログ等で情報が少なかったCustom Mapの話があったので記載します。 Custom Mapは既存の地図を他のものに変更することができる機能です。
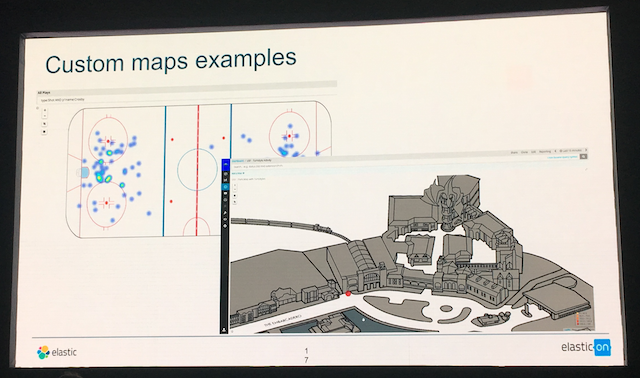
今日のセッションでは上記のように任意の背景の上に表示することが紹介されていました。
以前、弊社でも試したことがあり、以下のようなキーボードとマウスの押す回数を可視化したことがありました。(必ずしも地図である必要はないです)
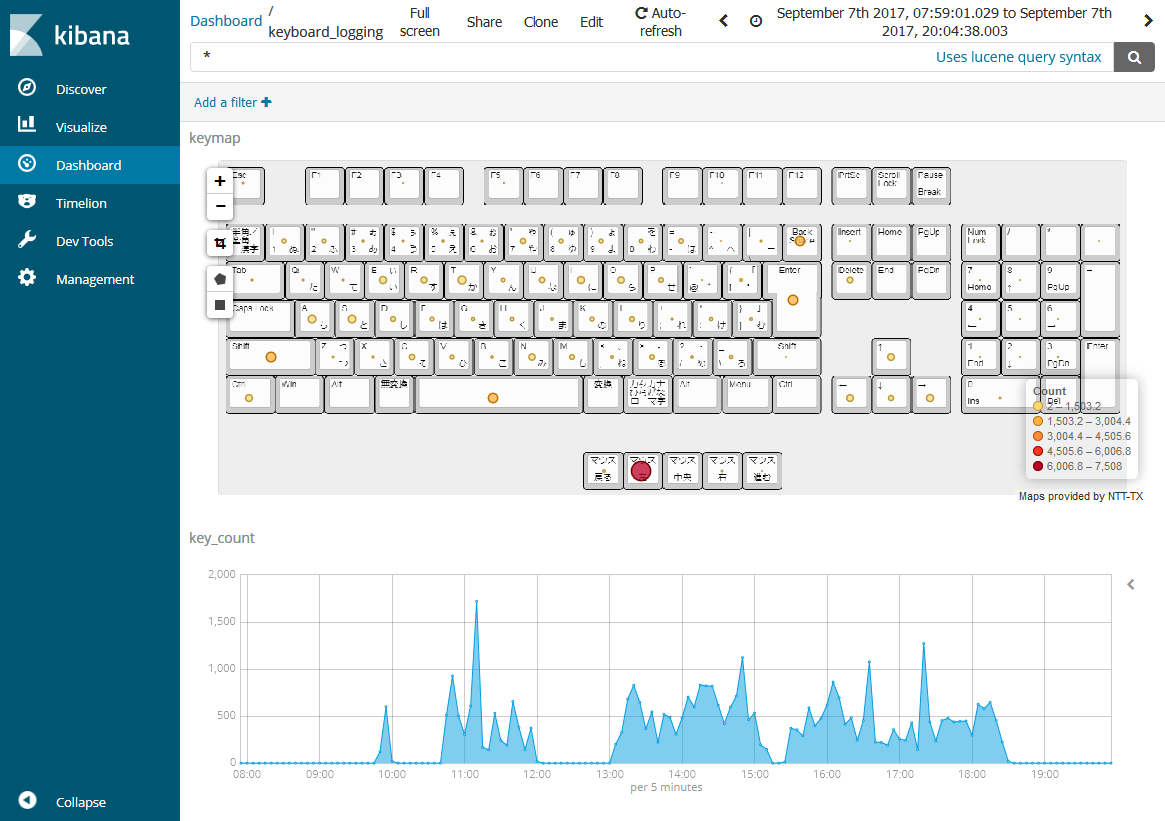
マウスの左ボタンクリックが一番多いのはご愛嬌・・・
Machine Learning in the Elastic Stack
Elastic StackでのMachine Learningのこれまでと新機能について話を聞いてきました。
これまで
まず、5系のMLは時系列データを対象として学習し、異常を検出、検出した異常をWatcherを使用してElastic Stackの管理ユーザに知らせる形が標準的な使用方法でした。
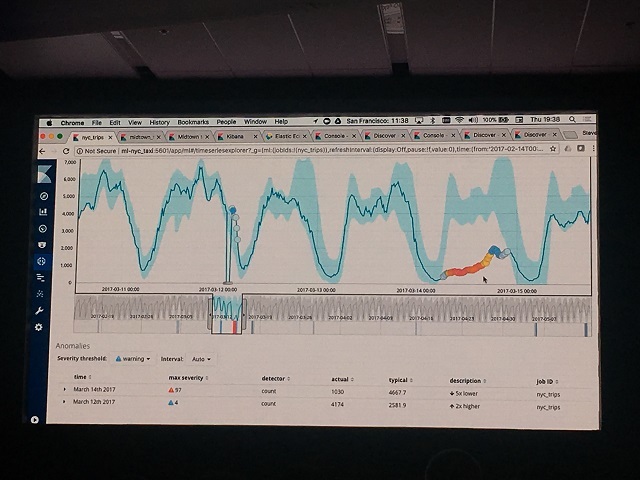
上記画像はニューヨークのタクシー乗客数についてSingle Metric Jobを利用して学習させて異常を検知した結果です。赤色系統の○が異常と判断した値となっています。
6系になると以下のような新機能が続々と追加されています。
未来を知りたい!
6.1で追加されたForecastを用いて、学習結果を元に指定した将来の日付までの予測が可能になりました。
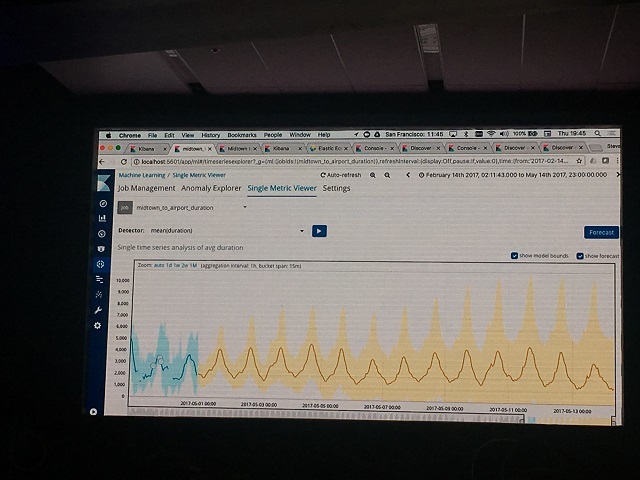
上記画像はニューヨークのタクシー乗客数について、2週間先までを予測した結果です。オレンジの折れ線が推定値で、塗りつぶし部分が正常値の範囲を示しています。
異常が学習されてしまった!
最初は異常を検知できていたのに、その異常を学習してしまった(正常値と扱われるようになった)ため、後の時系列で同じ異常が発生しても、異常として検知できなくなるという事象がありました。
6.2からは異常と判断された期間を学習対象から外し、再度学習させることで、再検知ができるようになりました(いわゆる学習結果の忘却)。
また、元々異常が発生すると分かっている期間を学習対象から外すことで、余計な異常検知をさせないといった使用方法もあります。
もう、Grokに苦しむことはありません!
さて、このセッションで初めて発表された目玉機能があります。 その名も「Categorization Explorer」!
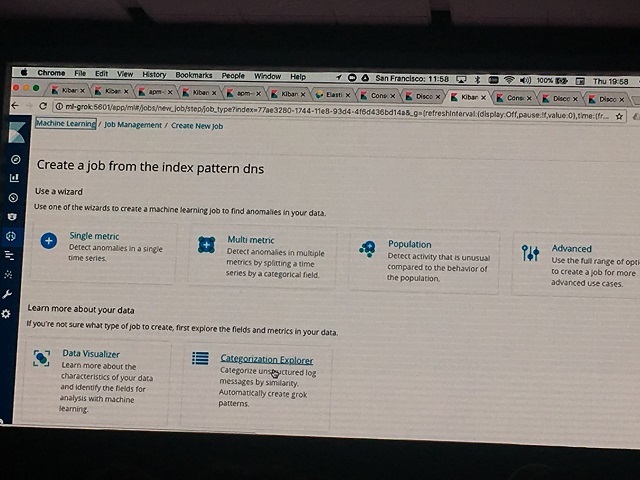
上記画像の中央下のアイコンが追加されています。
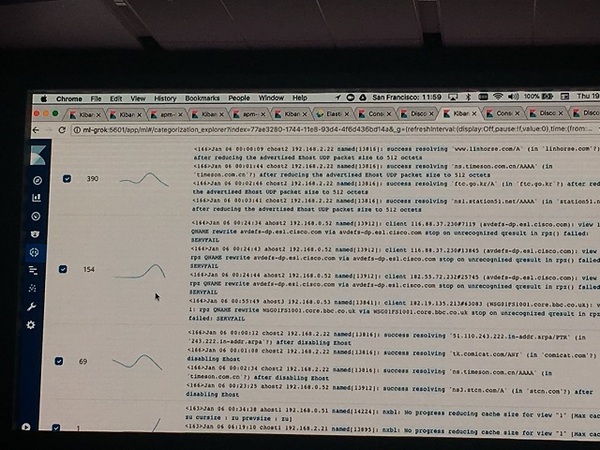
どのように使えるのかDNSのログを対象にデモがありました。
- 1. ログが登録されている
- 2. 登録されたログをカテゴライズする(DNSのログは処理によってフォーマットが異なる特徴があります)
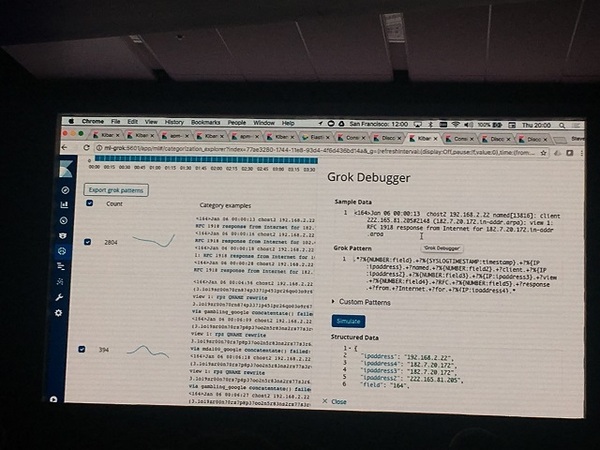
- 3. カテゴライズした中から,Grok Patternを自動生成する。(Export grok patternをクリックすると、右側の情報が表示されます)
- 4. 一度Indexingしたデータについて、Grok Patternを追加してReindexすることで、正しくNormalizeが行える。
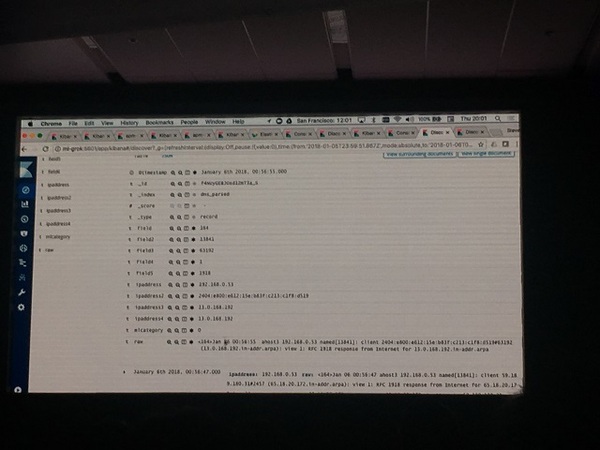
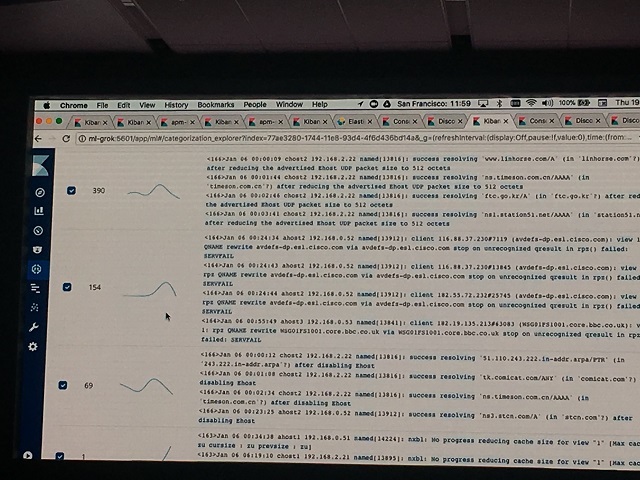
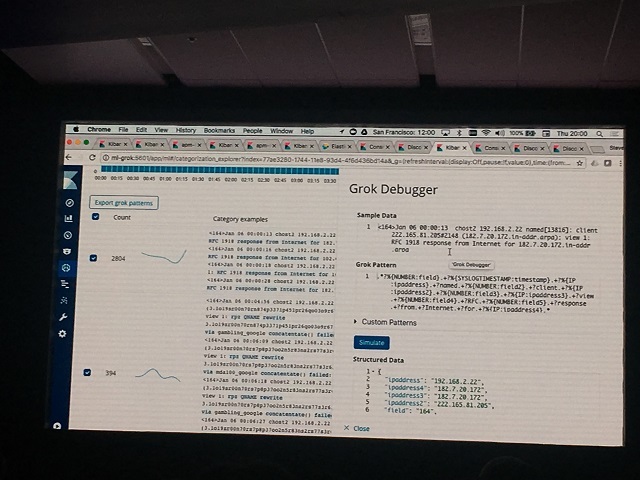
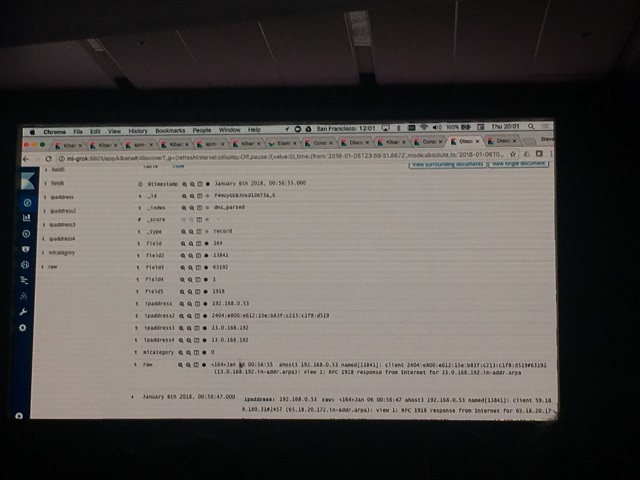
上記のようにお手軽にGrokを使用してログのNomarlizeができてしまうわけです。
ログのNomarlizeに苦しみ、何度もGrokを修正した苦い思い出がありますが、これで解放されると思うと本当にありがたい機能です!
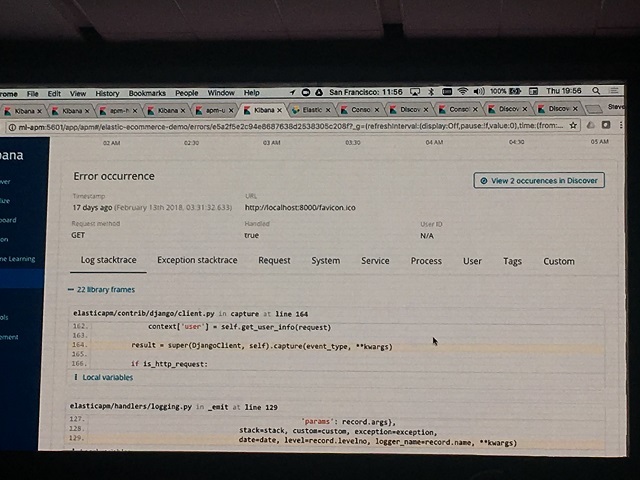
MLとAPMとの連携
最後にMLとAPMを連携させるデモがありました。APMについては昨日のセッションでも説明がありました。
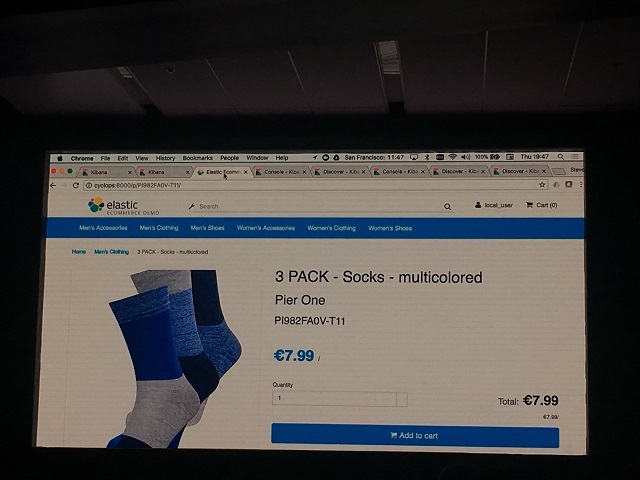
- 1. APMを使用してアプリケーション(今回のデモでは以下の画像のような疑似ECサイト)の性能情報のIndexを作成する。
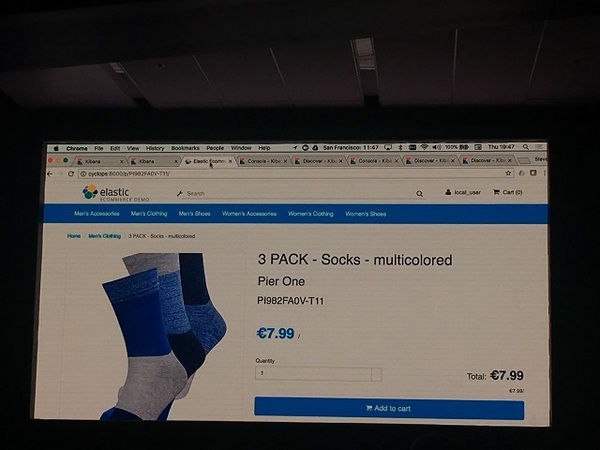
- 2. このIndexについてMLで学習させて、クライアントへのエラーレスポンス数などの異常を検出させる。
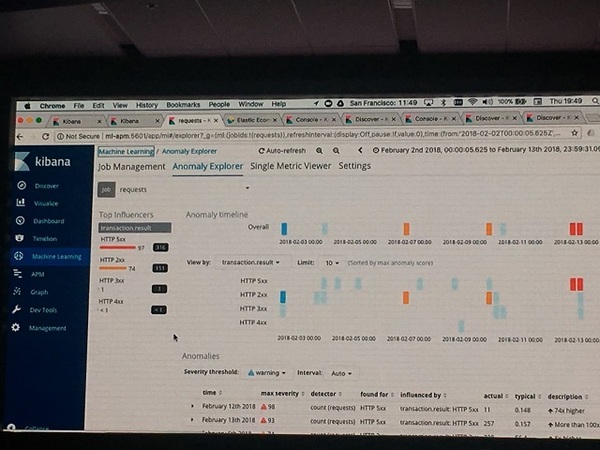
- 3. 学習結果とAPMのダッシュボードを関連付ける。
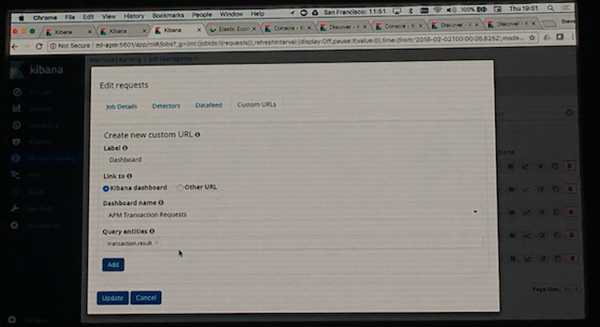
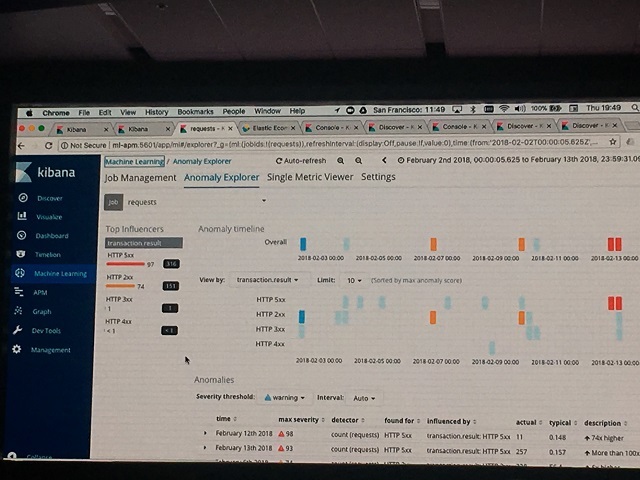
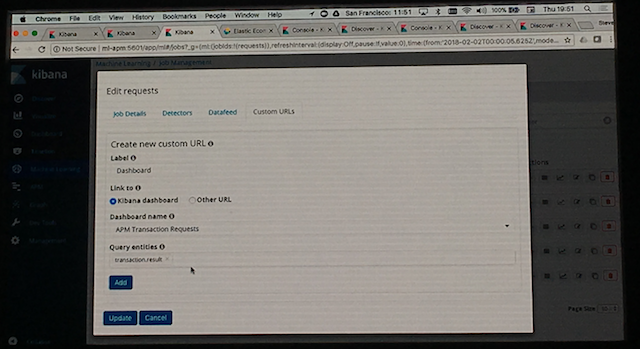
上記の操作の結果、検知した異常の詳細データからAPM上の該当データへ直接飛ぶことができるようになります、 その結果、異常の原因解析が容易にできるというわけです。とても便利です。
Elasticsearch SQL
最後のセッションとなった「Elasticsearch SQL」ですが、注目度が高く会場がほぼ埋め尽くされました。
それではセッションの内容をお伝えします。
「Elasticsearch SQL」ってなに?
名前だけだと色々想像ができてしまう「Elasticsearch SQL」ですが、どのようなものか以下に特徴を記載します。
- 読み込み専用(INSERT/UPDATE/DELETEには対応していない)
- 読み込みは複数のINDEXを対象に行える。ただし、Mappingの互換性がある場合に限る
- ANSI SQLに準拠していない。一部の関数はElasticsearch独自となる
- セッションのなかでは、「50%/50%」と表現していました。
- X-Packの一部として提供される
Elasticsearch SQLは「SQL」と謳っていますが、標準SQL規格(ANSI SQL)には準拠しきれていません。どんなSQLが使えるのかは、リリースされてからオンラインドキュメントとにらめっこですね。
いつから使えるの?
「Elasticsearch SQL」ですが、次のマイナーリリースである、6.3から使うことができます。もうすぐで、待ち遠しいです!

どんなクエリが書けるのか?
以下のようなクエリが書けると紹介がありました。JSONでゴリゴリ書いていたQuery DSLに比べると、Elasticsearchを知らない人でも何を実施するのか簡単に想像ができますね。
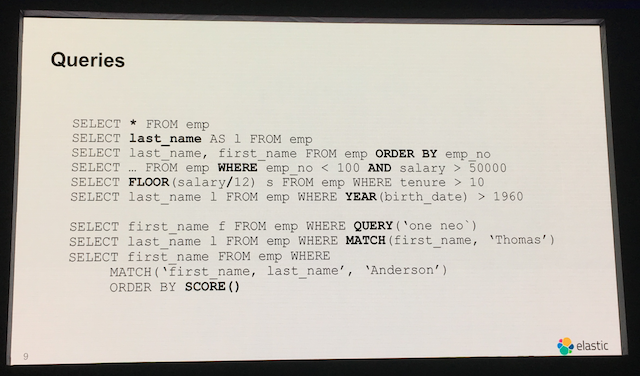
ただ、「QUERY()」や「MATCH()」「SCORE()」はElasticsearch独自の機能となるため気をつける必要があります。
どういう仕組みか?
以下の5つのステップで動作します。
- 1. Parse: SQLをパースします
- 2. Analysis: パースしたSQLの構文チェックを行います
- 3. Optimize: SQLを最適な実行形式に変換します
- 4. Query Plan: SQLからQuery DSLへ変換します
- 5. Query Execute: 実行します
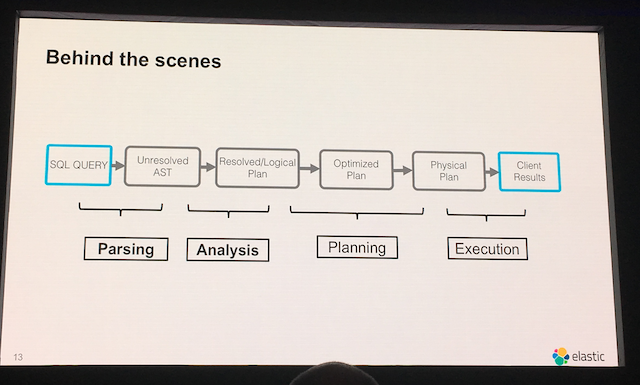
高速に動作するようですが、Query DSLを実行する場合と比べると処理が増えていますので、多少の性能劣化が考えられますがこのあたりは今後検証をしていきたいです。
どうやって使うのか?
非常に多くのクライアントが提供されていますので、ユースケースに応じて使い分けることが可能です。
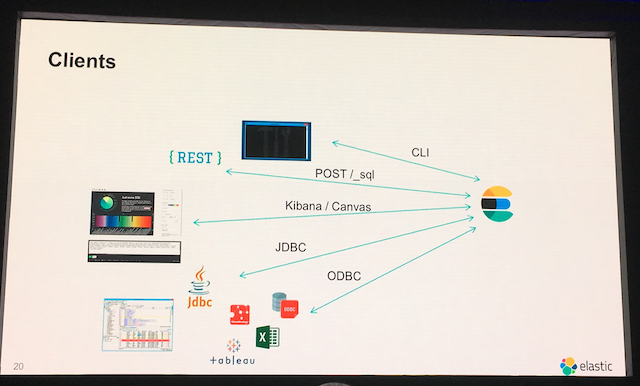
それぞれの実行イメージもあわせて紹介させていただきます。
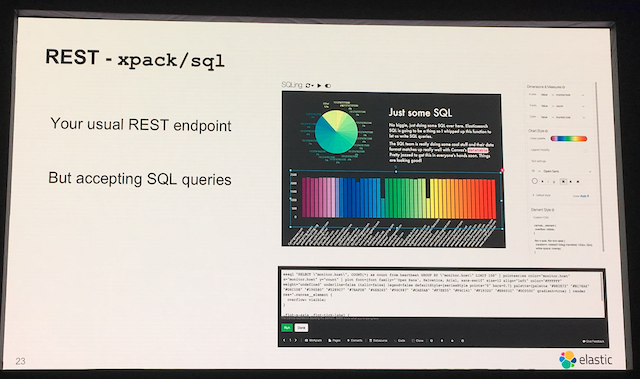
REST API

分かりづらいですが、以下のような形でSQLが実行できます。
POST _xpath/sql
{
"query": "SELECT ・・・"
}
Kibana Canvas
timelineに比べると、格段にわかりやすくなりましたね!
CLI
専用のCLIが用意されるようです。MySQLやPostgreSQLのCLIと似ているので、使いやすそうです。

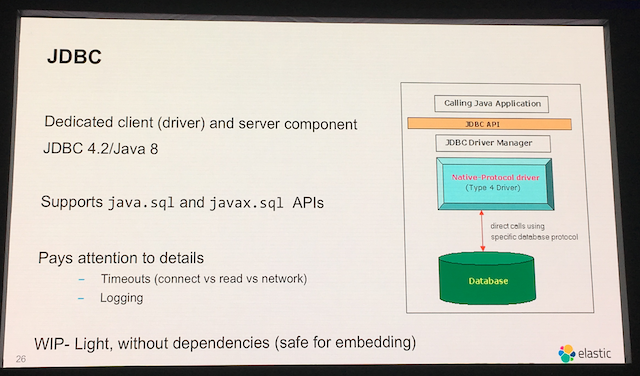
JDBC
JDBCからも使えますが、一点注意が必要です。 Java8 しか対応していないため、 Java9 は使わないようにしてください。
ODBC
ODBCは7.0以降に使用出来る予定です。

ロードマップ
ロードマップが紹介され、今後は以下を対応していくことがわかりました。
- GROUP BYの強化
- INTERVALの導入
- time関数の強化
- 日時計算
- オフセット・絶対時間指定・相対時間指定
- HISTOGRAMの導入
- Parent-Childのサポート
- Cross-Cluster SQL(Cross-Cluster Search対応)
- Geoサポート
- 副問合せのサポート
- JVMのアップデート
スケジュールは明言していませんでしたが、進化が早いElasticなので、早々にリリースされることを期待しています。
まとめ
楽しかったElastic{ON} 2018も本日で閉幕です。
Elastic StackはX-Packのソースコードが公開になり、続々と新機能が追加され、進化が止まりません。
私たちもその進化のスピードに負けないように力をつけ、日本の皆様に最新の情報を届けられるように努めていきますので今後共宜しくお願いします!
P.S. カンファレンス中は毎日アメリカンな食事だったので、日本に帰ってから体重計が怖いです・・・

(Elasticsearch SQLのセッション終了後に壇上にて)



NTTテクノクロス株式会社
クラウド&セキュリティ事業部
第二事業ユニット
![]()