データ管理の最前線 ~一貫性とスケール性を両立した新たなDBMSについて~
データ管理を行う「データベース(DB)」領域にて近年注目を浴びているNewSQLとその具体的なOSSであるYugabyteDB, Tsurugiについて紹介します




はじめに
こんにちは、NTTテクノクロスの山口です。
今回は今話題のDBMSについて紹介したいと思います。
以前に本ブログでRDBとNoSQLを紹介しましたが、今回紹介するのは従来のRDBと
NoSQLのお互いの良い点を組み合わせたものです。

図1 様々なデータベースの種類と今回紹介するDBMS
具体的にはNewSQL(分散DB)とも呼ばれるものの1つであるYugabyteDBと、
国産OSS DBとして登場したTsurugiについて、実操作も交えながら取り上げたいと思います。
[参考] 別記事:NWシステムにおけるデータ管理 ~RDBとNoSQL比較~ (前編, 後編)
■ 目次
| 節番号 | 節タイトル |
| 1 | NewSQLとは ~RDBとNoSQLの課題の先へ~ |
| 2 | スケール性の考え方と本記事で紹介するDBMSについて |
| 3 | YugabyteDBについて |
| 4 | Tsurugiについて |
NewSQLとは ~RDBとNoSQLの課題の先へ~
NewSQL登場の背景に関連するRDBとNoSQLから、まずは紹介します。
上記2つの違いは一般的に以下の表のようになります。
| DBの種類 | 一貫性 | スケール性 | SQL準拠の操作 (複雑な操作可) |
[参考] 処理速度 (集約等の分析や書き込み処理) |
| RDB |
〇 |
× |
〇 |
× |
| NoSQL |
× |
〇 |
× |
〇 |
RDBはデータの一貫性を担保する為にACIDを満たすトランザクションという仕組みを利用します。
一方でこの仕組みは処理が重くスケールしづらい課題もあります。
その為、銀行の入金システムのようにデータ損失があってはならない処理には向いていますが、
ビッグデータ管理のように多くのデータを扱う処理では主に性能面で限界がありました。
そこで登場したのがNoSQLです。
NoSQLはデータの一貫性とSQLで実行可能な複雑な処理を割り切ったことで
より高い処理性能かつスケールアウトもしやすいアーキテクチャとなりました。
このようにRDBとNoSQLは長所・短所がトレードオフとなっています。
このトレードオフをある程度解消するのがNewSQLです。
つまりSQLによる複雑な処理に対応でき、データの一貫性を確保しながらスケールもしやすいDBMSとなります。
もう1つ、DBMSを評価する指標でよく言われるのが「CAP定理」です。
CAP定理とは「分散システムでは「C(一貫性)」「A(可用性)」「P(分断耐性)」のいずれか2つしか実現できない」という法則です。
それぞれの要素の意味を以下に記載します。
| キーワード | 意味 |
| C (一貫性) | 全ノードにて常に同じ結果が返される事。(常に最新の結果が返る事) |
| A (可用性) | 継続で使用できる事。(一部のノードが障害発生しても影響を受けない事) |
| P (分断耐性) | ノード間でNW分断が発生しても、継続して使用できる事。 |
RDBとNoSQLのトレードオフの観点(特に重要なポイント)と上記CAP観点も踏まえた比較表が以下です。
| DBの種類 | CAP | SQL準拠 (複雑な操作可) |
一貫性 (ACID) |
スケール性 | ||
| 一貫性 (分散) |
可用性 | 分断耐性 | ||||
| RDB | 〇 | 〇 | × | 〇 | 〇 | × |
| NoSQL | × | 〇 | 〇 | × | × | 〇 |
| NewSQL | 〇 | △ | 〇 | 〇 | 〇 | 〇 |
この表を見るとNewSQLは完璧なものに見えるかもしれませんが、懸念事項も存在します。
例えばまだ新しめの技術である為、成熟しきっていないという点があげられます。
また、NoSQLにも同じ事が言える事ですが、スケール対応はそれだけリソースが必要となる為、
設備コストは上がり、(分散処理となる為)ノードだけでなくノード間をつなぐNWも複雑かつ重要になります。
なお上記は一般的に言われていることであり、実際は使用するDBMSによる点は過去記事でも触れている通りです。
例えば過去記事でNoSQLに該当するInfluxDBがOSS版(コミュニティ版)ではスケールできないと言う注意点がありました。
このように最終的には使用するソフトによる為、そのソフトで実現したい要件を満たせるか確認する事が
重要となります。
スケール性の考え方と本記事で紹介するDBMSについて
前節でも触れたように、NewSQLはRDBとNoSQLの課題の先で登場した技術であり、
「SQL準拠」「一貫性(トランザクション機能有)」「スケール性」の3つを満たす事が
要点となりそうです。
前者2つはイメージしやすいかと思いますので、3つの目のスケール性を掘り下げてみましょう。
DBMSのスケール性が重視される理由は「性能」に直結する為です。
性能改善の方法はパラメータチューニングやクエリチューニング等もありますが、
より簡単かつダイレクトに効果が出やすいのは「スケール」となります。
この「スケール」には「スケールアウト」と「スケールアップ」の2つがあります。
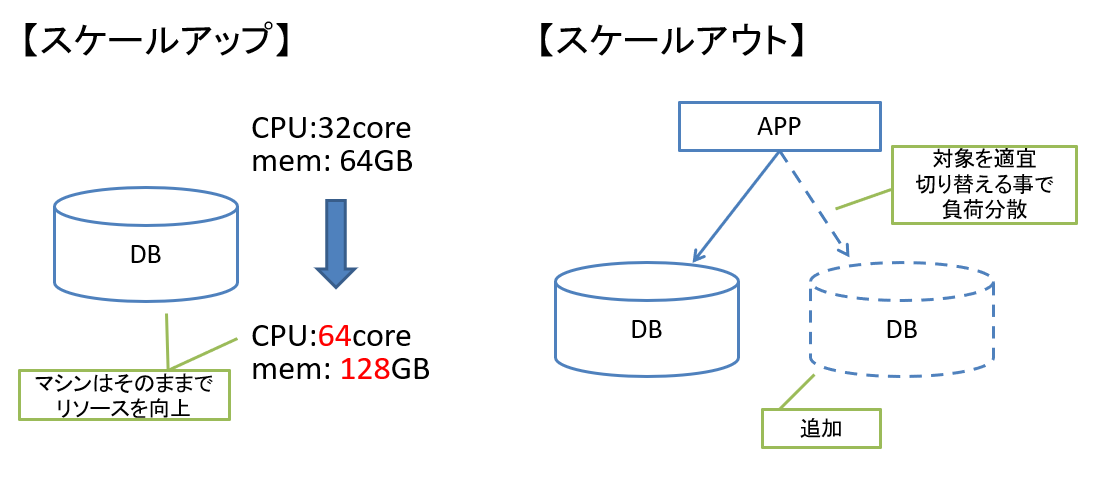 図2 スケールについて
図2 スケールについて
以降では従来のRDBよりスケールアウトしやすくなったDBMSの「YugabyteDB」と、
従来のRDBよりスケールアップが効きやすくなった「Tsurugi」を紹介します。
YugabyteDBについて
YugabyteDBはPostgreSQL、Apache Cassandra互換のNewSQLです。
NewSQLの特徴である「トランザクション機能有」「SQL準拠」「スケール性」を持ち合わせており、
従来のRDBであるPostgreSQLと比較するとスケールのしやすさがメリットと言えます。
例えばPostgreSQLでは以下の2つの機能がありますが、それぞれ制限があります。
| 機能名 | 制限(代表例) |
| ストリーミングレプリケーション(SR) | プライマリーのみ更新処理が可能であり、 スレーブ側は参照のみ可能。 |
| ロジカルレプリケーション(LR) | パブリッシャ―もサブスクライバーも更新・参照可能。 |
一方でYugabyteDBは全てのノードで更新・参照処理が可能で、
どこで更新・参照処理をしても基本的には同じ結果となります。
その為、より処理の負荷分散がさせやすくなります。
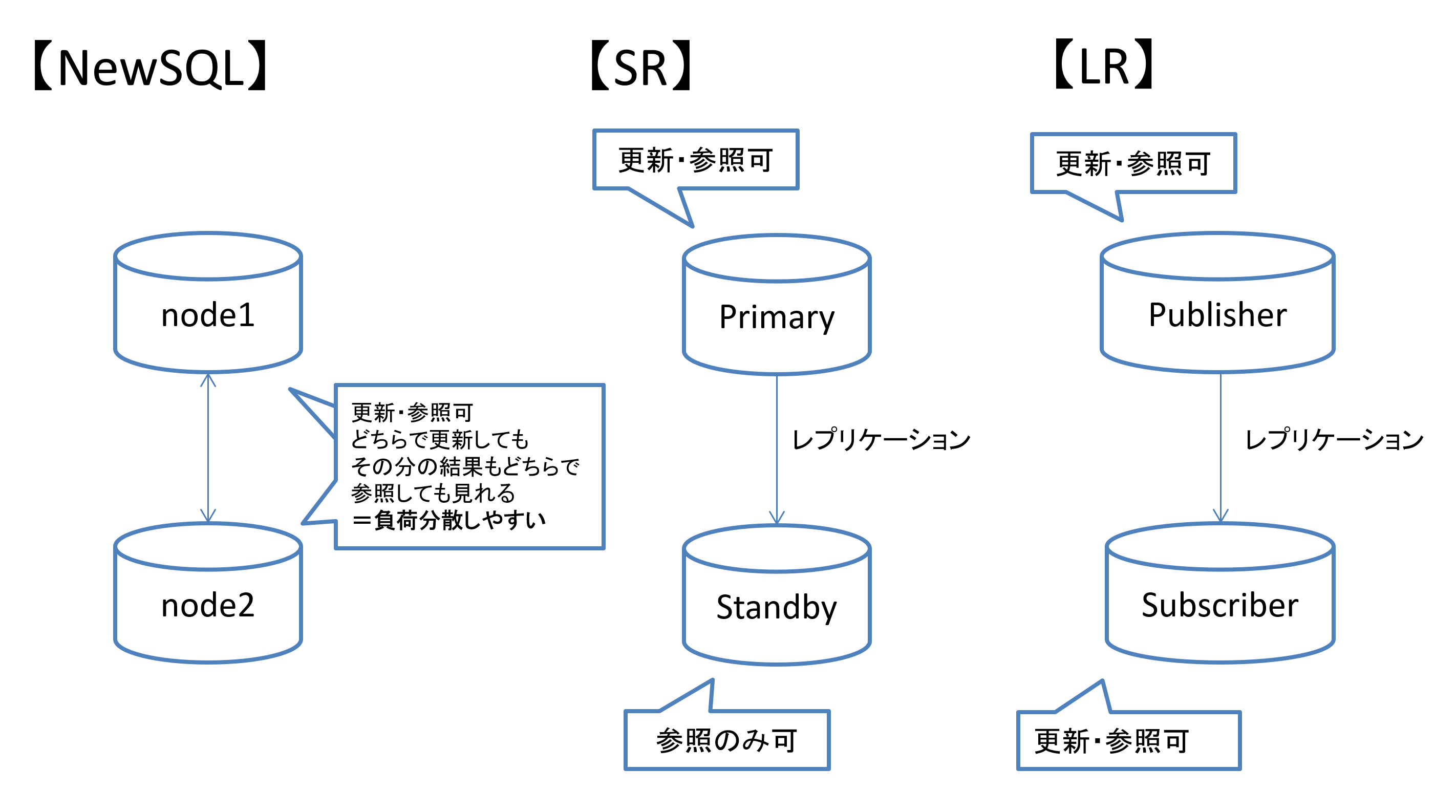
図3 負荷分散とスケール性について
YugabyteDBには以下の2つの役割の異なるコンポーネントが存在します。
それぞれのコンポーネントを同一ノードに配置する事も可能です。
| コンポーネント名 | 説明 |
| YB-Master |
クラスタ全体の管理、メタデータ管理等を行う。 |
| YB-Tserver |
クエリ処理やデータの格納を行う。 |
※ LEADERとFOLLOWERの選定にはRaftというアルゴリズムが使われています
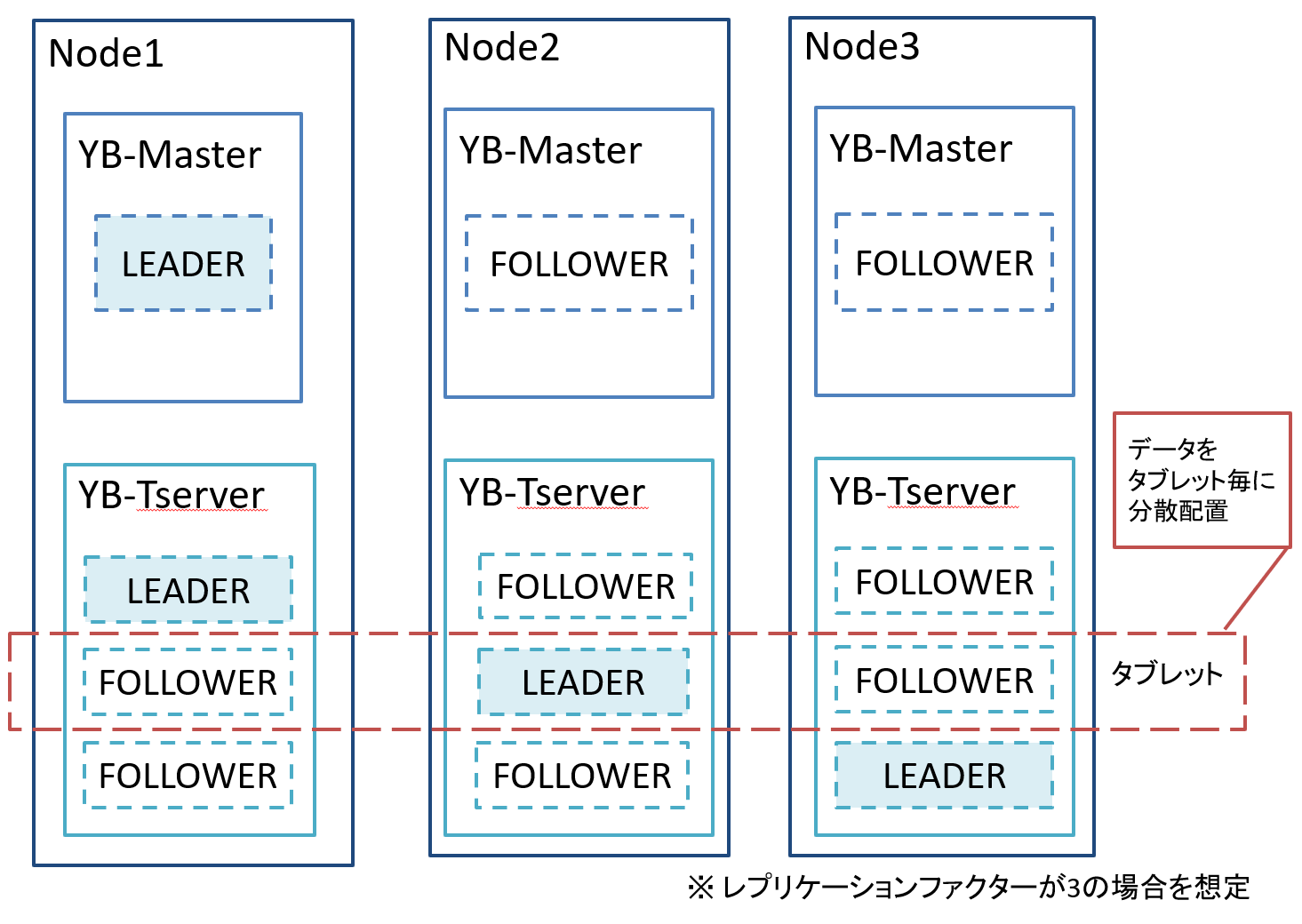
図4 YugabyteDBの構成イメージ
※ 上記図ではタブレットは3つとなる
また複数のノードにデータを複製する事で、一部ノードが機能不全に陥ってもサービスを継続可能です。
何個のノードにデータをコピーするかはレプリケーションファクターの数値により決まります。
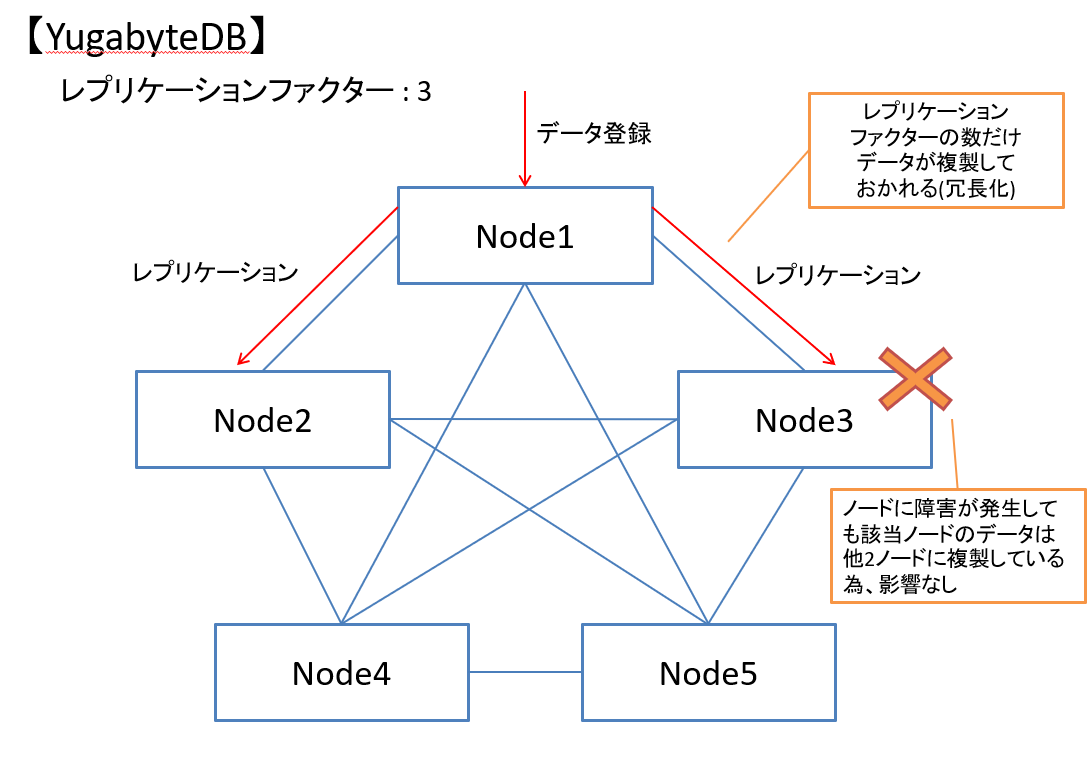
図5 データ複製のイメージ図
さて、では以降でYugabyteDBを実際に触ってみて「トランザクション機能有」「SQL準拠」
「スケール性」を持ち合わせていることを確認してみましょう。
基本的な操作
yugabyteDBはインストールした環境であれば「yugabyted start」で簡単に起動できます。
「--listen」を付与する事で受け付けるIPを指定できます。
また、2ノード目以降では「--join」をつける事で、クラスタとして合流するノードを指定できます。
今回はローカル環境ではありますが、例として2ノードで構成させる1クラスターを想定して見ていきたいと思います。
$ yugabyted start --base_dir='/home/yugabytedb01' --listen=127.0.0.4
+----------------------------------------------------------------------------------------------------------+
| yugabyted |
+----------------------------------------------------------------------------------------------------------+
| Status : Running. |
| Replication Factor : 1 |
| YugabyteDB UI : http://127.0.0.4:15433 |
| JDBC : jdbc:postgresql://127.0.0.4:5433/yugabyte?user=yugabyte&password=yugabyte |
| YSQL : bin/ysqlsh -h 127.0.0.4 -U yugabyte -d yugabyte |
| YCQL : bin/ycqlsh 127.0.0.4 9042 -u cassandra |
| Data Dir : /home/yugabytedb01/data |
| Log Dir : /home/yugabytedb01/logs |
| Universe UUID : 3a5be264-c9ca-42a9-b44c-17aa8cc019be |
+----------------------------------------------------------------------------------------------------------+
$ yugabyted start --base_dir='/home/yugabytedb02' --listen=127.0.0.5 --join=127.0.0.4
+----------------------------------------------------------------------------------------------------------+
| yugabyted |
+----------------------------------------------------------------------------------------------------------+
| Status : Running. |
| Replication Factor : 1 |
| YugabyteDB UI : http://127.0.0.5:15433 |
| JDBC : jdbc:postgresql://127.0.0.5:5433/yugabyte?user=yugabyte&password=yugabyte |
| YSQL : bin/ysqlsh -h 127.0.0.5 -U yugabyte -d yugabyte |
| YCQL : bin/ycqlsh 127.0.0.5 9042 -u cassandra |
| Data Dir : /home/yugabytedb02/data |
| Log Dir : /home/yugabytedb02/logs |
| Universe UUID : 3a5be264-c9ca-42a9-b44c-17aa8cc019be |
+----------------------------------------------------------------------------------------------------------+
Statusが「Running」である為、実行可能な状態です。
このようにコマンド実行だけで簡単にノード追加が行えます。
このクラスターのYB-MasterとYB-Tserverのステータスも確認してみましょう。
上記の確認には「yb-admin」を使用します。
$ bin/yb-admin -master_addresses 127.0.0.4,127.0.0.5 list_all_masters
Master UUID RPC Host/Port State Role Broadcast Host/Port
bc8b09aa771b4d38bd30792958b56203 127.0.0.4:7100 ALIVE LEADER 127.0.0.4:7100
a0fcaf62eaef4d3e883c3367a9ea9afd 127.0.0.5:7100 ALIVE FOLLOWER 127.0.0.5:7100
$ bin/yb-admin -master_addresses 127.0.0.4 list_all_tablet_servers
Tablet Server UUID RPC Host/Port Heartbeat delay Status Reads/s Writes/s Uptime SST total size SST uncomp size SST #files Memory Broadcast Host/Port
a639155e443b4db780a0be7f74007a09 127.0.0.5:9100 0.95s ALIVE 0.00 0.00 135 0 B 0 B 0 23.04 MB 127.0.0.5:9100
cd764f2d0625485c8e354587085265ef 127.0.0.4:9100 0.91s ALIVE 0.00 0.40 145 0 B 0 B 0 29.51 MB 127.0.0.4:9100
1コマンド目でYB-Masterのステータスを確認しており、ノード毎にMasterが存在し
どちらもALIVE、かつノード1(127.0.0.4)がLEADERである事がわかります。
また2コマンド目でYB-Tserverのステータスを確認しており、こちらもノード毎にTserverが存在し
どちらもALIVEである事がわかります。
YB-Tserverはタブレット毎にLEADER・FOLLOWERが設定される為、別途データ登録をしてからみてみましょう。
次にクエリ実行をしてみましょう。
クエリ実行の為の接続には「ysqlsh」を実行します。(PostgreSQLでいうpsql)
「-U」オプションでユーザ名を指定します。
$ bin/ysqlsh -h 127.0.0.4 -U yugabyte
ysqlsh (11.2-YB-2.19.3.0-b0)
Type "help" for help.
yugabyte=#
yugabyte=# \l
Name | Owner | Encoding | Collate | Ctype | Access privileges
-----------------+----------+----------+---------+-------------+-----------------------
postgres | postgres | UTF8 | C | en_US.UTF-8 |
system_platform | postgres | UTF8 | C | en_US.UTF-8 |
template0 | postgres | UTF8 | C | en_US.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | C | en_US.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
yugabyte | postgres | UTF8 | C | en_US.UTF-8 |
PostgreSQL準拠と言う事もあり、クエリ実行モードではメタコマンドも使用できます。
上記ではメタコマンドでDB一覧を確認しています。
postgres データベースもあるので馴染みのあるこちらに切替えて、
テーブル作成を実行してみたいと思います。
筆者はNWシステムの開発に関わる事が多い手前、IPアドレス型(inet)を入れて試したいと思います。
yugabyte=# \c postgres
You are now connected to database "postgres" as user "yugabyte".
postgres=# create table tbl1 ( ip inet , note text ) ;
CREATE TABLE
postgres=# create table tbl2 ( ip inet , memo text ) ;
CREATE TABLE
postgres=# insert into tbl1 ( ip , note) values ( '192.168.10.1', 'IP1-1') ;
INSERT 0 1
postgres=# insert into tbl1 ( ip , note) values ( '192.168.10.2', 'IP1-2') ;
INSERT 0 1
postgres=# select * from tbl1 ;
ip | note
--------------+-------
192.168.10.2 | IP1-2
192.168.10.1 | IP1-1
(2 rows)
問題なくテーブル作成ができ、inet型含むデータ登録もできました。
NWに関連するシステムを作る際にも活用しやすそうです。
上記はノード1(127.0.0.4)で実行しましたが、
次はクラスタを組んでいるノード2(127.0.0.5)からも同じ情報が見えるか確認してみましょう。
postgres=# \q
$ bin/ysqlsh -h 127.0.0.5 -U yugabyte -d postgres
ysqlsh (11.2-YB-2.19.3.0-b0)
Type "help" for help.
postgres=# select * from tbl1 ;
ip | note
--------------+-------
192.168.10.2 | IP1-2
192.168.10.1 | IP1-1
(2 rows)
postgres=# insert into tbl1 ( ip , note) values ( '192.168.10.3', 'IP2-1') ;
INSERT 0 1
postgres=# select * from tbl1 ;
ip | note
--------------+-------
192.168.10.2 | IP1-2
192.168.10.3 | IP2-1
192.168.10.1 | IP1-1
(3 rows)
ノード1で投入したデータがノード2でも見れた他、ノード2でもデータ投入ができ、
ノード1で登録したものとあわせた結果を見る事ができました。
実行例は省略しますが、この後ノード1でselectを打っても同じ結果となります。
このようにどのノードでも挿入や参照が可能であり、全ノードのデータを組み合わせた出力がされる為、
負荷分散がしやすいメリットがあります。
データ登録もしたので、タブレットの情報も確認してみましょう。
postgres=# \q
$ bin/yb-admin -master_addresses 127.0.0.4 list_tablets ysql.postgres tbl1
Tablet-UUID Range Leader-IP Leader-UUID
455ea70b9c50485b8081643809e25653 partition_key_start: "" partition_key_end: "\200\000" 127.0.0.5:9100 a639155e443b4db780a0be7f74007a09
92467cc44b06467582a3a39fd7e911dd partition_key_start: "\200\000" partition_key_end: "" 127.0.0.4:9100 cd764f2d0625485c8e354587085265ef
$ bin/yb-admin -master_addresses 127.0.0.4 list_tablet_servers 455ea70b9c50485b8081643809e25653
Server UUID RPC Host/Port Role
a639155e443b4db780a0be7f74007a09 127.0.0.5:9100 LEADER
1つ目のyb-adminで、tbl1テーブルに関するタブレットの一覧を取得しており、
結果的に2つのタブレットが構成されていることがわかります。
このコマンドでタブレットの情報(Tablet-UUID)がわかった為、2つ目のyb-adminコマンドで
そのタブレット情報を指定する事で、該当タブレットの構成を確認しています。
現在はレプリケーションファクターが1の為、タブレット内の構成は1つのみ(=LEADERのみ。ここにデータが置かれている)と
なります。
レプリケーションファクターの数値を増やせば、複数ノードにデータが冗長配置される為、
構成も増えてLEADER・FOLLOWER構成となります。
上記数値を増やした際の結果は後述します。
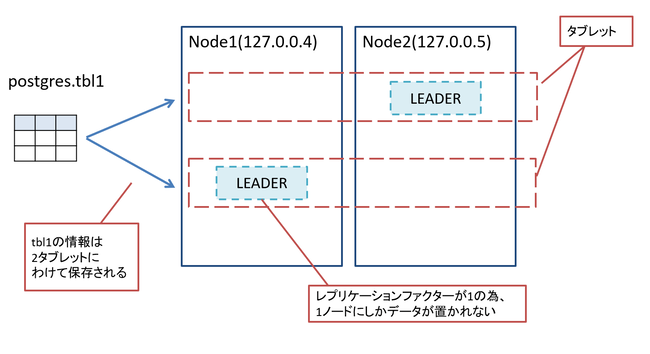 図6 現在までの検証環境の構成
図6 現在までの検証環境の構成
トランザクション機能の有無
次にトランザクションができる事を見ていきましょう。
まずはロールバックするケースです。
$ bin/ysqlsh -h 127.0.0.5 -U yugabyte -d postgres
postgres=# begin ;
BEGIN
postgres=# insert into tbl2 ( ip , memo ) values ('192.168.10.1', 'rollback') ;
INSERT 0 1
postgres=# select * from tbl2 ;
ip | memo
-------------+----------
192.168.0.1 | rollback
(1 row)
postgres=# rollback ;
ROLLBACK
postgres=# select * from tbl2 ;
ip | name
----+------
(0 rows)
問題なく1度登録したデータをロールバックにより戻す事ができました。
次はコミットした場合をみてみましょう。
postgres=# begin ;
BEGIN
postgres=# insert into tbl2 ( ip , memo ) values ('192.168.10.2', 'commit') ;
INSERT 0 1
postgres=# select * from tbl2 ;
ip | memo
--------------+--------
192.168.10.2 | commit
(1 row)
postgres=# commit ;
COMMIT
postgres=# select * from tbl2 ;
ip | memo
--------------+--------
192.168.10.2 | commit
(1 row)
コミットした場合はコミット後も変わらず、明示的トランザクション内で追加したデータが参照できました。
このことからトランザクション機能が有効であることがわかるかと思います。
ただし一部(create table等)はトランザクション対象外となるものも存在する点は注意点となります。
SQL準拠のクエリ確認
前述の例でcreate tableやinsert文を打っていますが、SQL準拠という観点でもう少し深堀りしてみましょう。
SQL準拠であるメリットは複雑な処理が可能であるという点となります。
NoSQLではDBMSごとにクエリ言語があります(CassandraならCQL, MongoDBならMQL, influxdbならinfluxQL)が
制約や条件がある事が多いです。
わかりやすい例としてCassandraのCQLではjoinをサポートしていません。
YugabyteDBではSQLをサポートしている為、joinも可能です。
以下で内部・外部・クロスジョインをそれぞれ試してみます。
postgres=# insert into tbl2 ( ip , memo ) values ('192.168.10.4', 'commit') ;
INSERT 0 1
postgres=# select * from tbl1 inner join tbl2 on tbl1.ip = tbl2.ip ;
ip | note | ip | memo
--------------+-------+--------------+--------
192.168.10.2 | IP1-2 | 192.168.10.2 | commit
(1 row)
postgres=# select * from tbl1 full outer join tbl2 on tbl1.ip = tbl2.ip ;
ip | note | ip | memo
--------------+-------+--------------+--------
192.168.10.1 | IP1-1 | |
192.168.10.2 | IP1-2 | 192.168.10.2 | commit
192.168.10.3 | IP2-1 | |
| | 192.168.10.4 | commit
(4 rows)
postgres=# select * from tbl1, tbl2 ;
ip | note | ip | memo
--------------+-------+--------------+--------
192.168.10.2 | IP1-2 | 192.168.10.4 | commit
192.168.10.2 | IP1-2 | 192.168.10.2 | commit
192.168.10.3 | IP2-1 | 192.168.10.4 | commit
192.168.10.3 | IP2-1 | 192.168.10.2 | commit
192.168.10.1 | IP1-1 | 192.168.10.4 | commit
192.168.10.1 | IP1-1 | 192.168.10.2 | commit
(6 rows)
あくまで一例ではありますが、このことから一定の複雑な処理も可能であるといえそうです。
冗長化とスケール性について
最後に冗長化とスケールアウトのしやすさについて触れたいと思います。
これまではレプリケーションファクターが1であった為、レプリケーションはされておらず、
1ノードダウンによる影響が大きい状態でした。
YugabyeDBではノードが3つ以上となると自動でレプリケーションファクターが3に切り替わります。
これによりデータは3か所でコピーされて保持されるため、冗長性が向上します。
上記確認をする為、3つ目のノードを追加してみましょう。
既にデータがある状態でも簡単にスケールアウトできる、という点が改めてわかるかと思います。
あわせて上記による変化したタブレット構成も確認してみましょう。
$ yugabyted start --base_dir='/home/yugabytedb03' --listen=127.0.0.6 --join=127.0.0.5
+----------------------------------------------------------------------------------------------------------+
| yugabyted |
+----------------------------------------------------------------------------------------------------------+
| Status : Running. |
| Replication Factor : 3 |
| YugabyteDB UI : http://127.0.0.6:15433 |
| JDBC : jdbc:postgresql://127.0.0.6:5433/yugabyte?user=yugabyte&password=yugabyte |
| YSQL : bin/ysqlsh -h 127.0.0.6 -U yugabyte -d yugabyte |
| YCQL : bin/ycqlsh 127.0.0.6 9042 -u cassandra |
| Data Dir : /home/yugabytedb03/data |
| Log Dir : /home/yugabytedb03/logs |
| Universe UUID : 3a5be264-c9ca-42a9-b44c-17aa8cc019be |
+----------------------------------------------------------------------------------------------------------+
$ bin/yb-admin -master_addresses 127.0.0.4 list_tablets ysql.postgres tbl1
Tablet-UUID Range Leader-IP Leader-UUID
455ea70b9c50485b8081643809e25653 partition_key_start: "" partition_key_end: "\200\000" 127.0.0.6:9100 ee7b9838c24b44bbb67c243cee0d21dd
92467cc44b06467582a3a39fd7e911dd partition_key_start: "\200\000" partition_key_end: "" 127.0.0.4:9100 cd764f2d0625485c8e354587085265ef
$ bin/yb-admin -master_addresses 127.0.0.4 list_tablet_servers 455ea70b9c50485b8081643809e25653
Server UUID RPC Host/Port Role
cd764f2d0625485c8e354587085265ef 127.0.0.4:9100 FOLLOWER
ee7b9838c24b44bbb67c243cee0d21dd 127.0.0.6:9100 LEADER
a639155e443b4db780a0be7f74007a09 127.0.0.5:9100 FOLLOWER
1つ目のyb-adminコマンドで再度tbl1を構成するタブレット一覧を確認しています。
2タブレットで構成する点はtbl1のデータ構成が変わっていない事もあり変化なしですが、
ノードが追加された事でタブレット内の構成が変わりLEADERが変わったことがわかります。
(前はLEADERは127.0.0.4と127.0.0.5でした)
また2つ目のyb-adminコマンドで1つ目のタブレットの構成を確認しています。
レプリケーションファクターが1の時は1構成でしたが、3となったことで3構成となった事、
またどのノードがLEADER・FOLLOWERとなっているかがわかるかと思います。
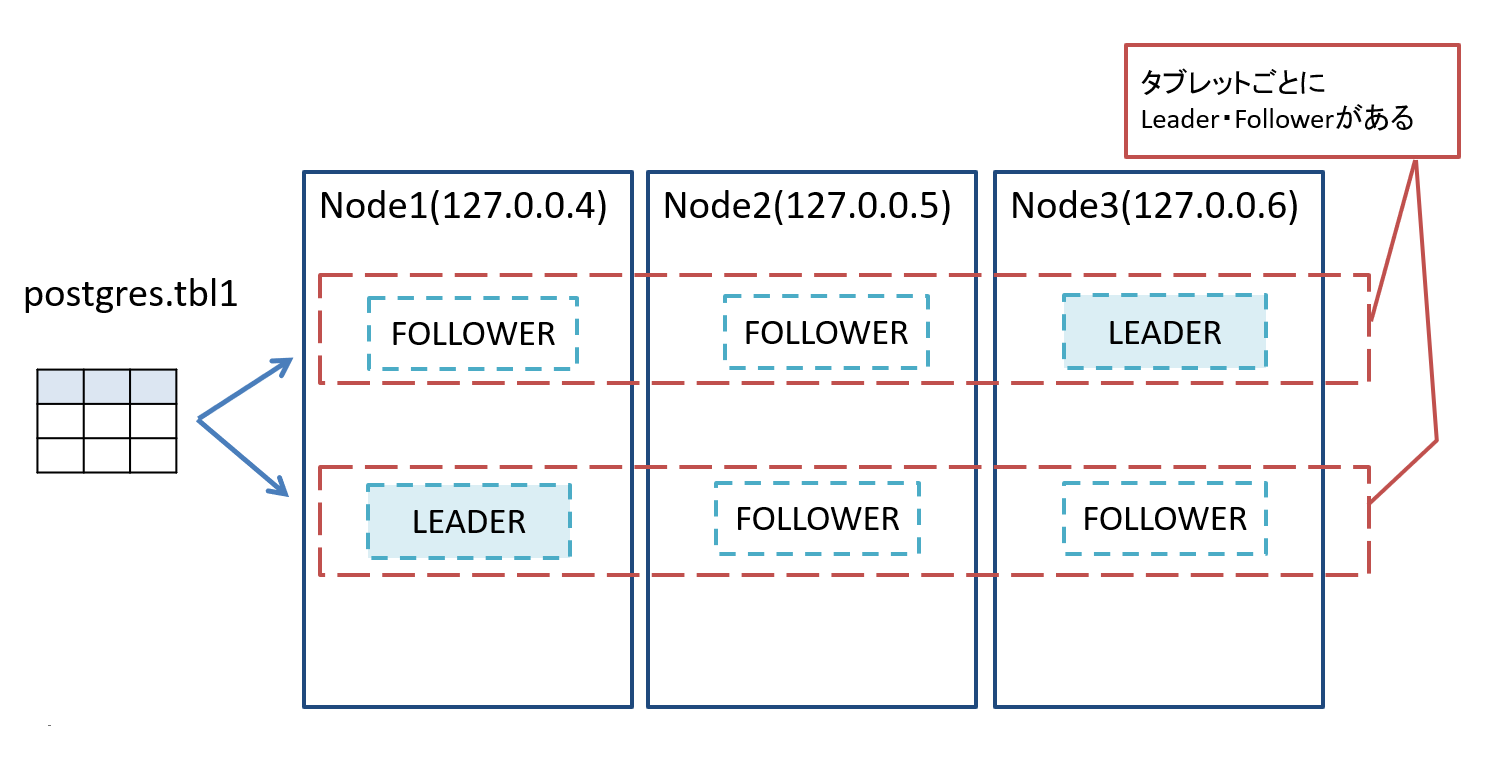
図7 現在までの検証環境の構成
このように既に登録したデータがある状態でも、簡単に1コマンドでノードを追加でき、
それにあわせて構成も自動で変更されます。
最後にレプリケーションファクターが3になった効果を見てみましょう。
具体的には1ノードを落とした上で、3つ目のノードでこれまで使ってきたtbl1とtbl2が見えるかどうか
確認してみます。
$ yugabyted stop --base_dir='/home/yugabytedb01'
Stopped yugabyted using config /home/yugabytedb01/conf/yugabyted.conf.
$ yugabyted status --base_dir='/home/yugabytedb01'
+----------------------------------------------------------------------------------------------------------+
| yugabyted |
+----------------------------------------------------------------------------------------------------------+
| Status : Stopped |
| Web console : http://127.0.0.4:7000 |
| JDBC : jdbc:postgresql://127.0.0.4:5433/yugabyte?user=yugabyte&password=yugabyte |
| YSQL : bin/ysqlsh -h 127.0.0.4 -U yugabyte -d yugabyte |
| YCQL : bin/ycqlsh 127.0.0.4 9042 -u cassandra |
| Data Dir : /home/yugabytedb01/data |
| Log Dir : /home/yugabytedb01/logs |
| Universe UUID : 3a5be264-c9ca-42a9-b44c-17aa8cc019be |
+----------------------------------------------------------------------------------------------------------+
$ bin/ysqlsh -h 127.0.0.6 -U yugabyte -d postgres
ysqlsh (11.2-YB-2.19.3.0-b0)
Type "help" for help.
postgres=# select * from tbl1 union select * from tbl2 ;
ip | note
--------------+--------
192.168.10.4 | commit
192.168.10.2 | commit
192.168.10.1 | IP1-1
192.168.10.2 | IP1-2
192.168.10.3 | IP2-1
(5 rows)
ノード2を落としても問題なくこれまでのデータがノード3からも見られました。
このことから、スケール性や冗長性が向上しているといえるかと思います。
まとめ
これまで見てきた通り、YugabyteDBは「トランザクション有」「SQL準拠」
「スケール性」という特徴を持ち合わせていそうです。
またinet型がある事からもNW系システムとも相性が良さそうです。
一方でcreate table等はトランザクションが効かない、などの注意点もあります。
このようにスケールアウトに対応したPostgreSQLというイメージで
PostgreSQLと全く同じ挙動を期待すると足をすくわれる可能性はあります。
また、これまで紹介してきた動作は基本操作である為、導入時には詳細な調査が必要となります。
更に目標を達成できるような冗長性を確保するためには機能だけでなく、機能をどう使うか、どういう構成で運用するか
というような設計観点が重要ともなります。
Tsurugiについて
次はTsurugiについてです。
Tsurugiは国産OSS RDBであり、スケールアップのしやすさに重点が置かれています。
実際のコア増加による性能向上の効果については以下に記載がありますのでご確認ください。
[参考]
世界最速レベルの性能を持つリレーショナルデータベース管理システム「劔(Tsurugi)」を開発 - 株式会社ノーチラス・テクノロジーズ
一方で潤沢なコア・メモリを活用するRDBとして想定されている為、
リソースの小さなマシンでは十分に活かしきれない事が注意点となります。
上記サイトのグラフをみると32コアまでは通常のRDBのほうがかえって良いようです。
使い方によっても性能は変わるかと思いますが、まず言えることとして少ないリソースでは
本DBは活かしきれない点がわかるかと思います。
他にもTsurugiならではの特徴はあります。
特に書き込み処理に強みを置いたRDBと言う事ではあるのですが、トランザクション分離レベルは
SERIALIZABLEで動きます。

図8 トランザクション分離レベルと分離性強度の関係性について
一般的に分離レベルが上がると一貫性は上がるものの性能が引きずられる傾向にありますが、
Tsurugiはきわめて強力な分離性と書き込み処理の高速化を両立したDBMSと言う事になります。
この動作により、公式にも「バッチ処理とオンラインの併用が可能」とあるように、
バッチ処理でやらざるを得ないロングトランザクションと、
単発的なショートトランザクションを併用して実施が可能となります。
言い方を変えると、大量データの集計や更新処理中に細かい処理なども可能となります。
また、HTAP構成も簡単に作れる、というメリットもあります。
HTAPとは、以下2つの両方を備えた構成を指します。
| キーワード | 説明 |
| OLTP (オンライントランザクション処理) |
データを確実に保持する為にトランザクション機能を有したもの。 |
| OLAP (オンライン分析処理) |
分析処理を行う為のもの。 |
TsurugiではSpark(デフォルト)等と組み合わせて活用するイメージとなります。
HTAP構成は最近のDBトレンドでもあり、他にもGreenplum DBやAlloyDB、TiDB等が備えています。
AlloyDBは弊社ブログの別記事でも触れていますので、興味があればご参照ください。
[参考]
別記事:AlloyDB for PostgreSQL のサーバパラメータの設定方法を確認してみた!
別記事:AlloyDB for PostgreSQL の プレビュー版Query Insights(クエリ分析機能)を使ってみた
Tsurugiは現在最新のBETAv3版を試す事ができます。
またTsurugiもYugabyteDBと同様にcreate table等のトランザクションが効かないクエリが存在します。
今回はTsurugiの基本的な操作とあわせて上記の確認例を載せたいと思います。
基本的な操作
クエリ実行の為の接続(YugabyteDBでいうysqlsh)には「tgsql」を使用します。
「-c」でipcかtcpかを指定できます。
ipcは高速であるものの、外部からの接続はできません。
上記コマンドで接続後、そのままテーブル作成の確認まで以下で行ってしまいます。
$ tgsql -c ipc:tsurugi
tgsql> select * from tbl1 ;
SYMBOL_ANALYZE_EXCEPTION (SQL-03004: compile failed with error:table_not_found message:"tbl1" location:(unknown))
tgsql> begin ;
tgsql> create table tbl1 ( id int , ip varchar(15) ) ;
execute succeeded
tgsql> insert into tbl1 ( id , ip ) values ( 1 , '192.168.100.100') ;
(1 row inserted)
tgsql> select * from tbl1 ;
[id: INT4, ip: CHARACTER]
[1, 192.168.100.100]
(1 row)
tgsql> rollback ;
transaction rollback finished.
tgsql> select * from tbl1 ;
[id: INT4, ip: CHARACTER]
(0 rows)
明示的トランザクションのなかでテーブル作成とデータ挿入を行いました。
本来であればトランザクション内で上記2手順を行っている為、ロールバックすると
両方ともなかったことになるかと思いますが、実際は(データは挿入される前の状態に戻りましたが)
テーブルは作成済となっています。
このことからもトランザクションが効かないクエリが存在することがわかるかと思います。
なおTsurugiでIPアドレスを管理したい場合、inet型がTsurugiにはない為、
シンプルに文字列型として扱う等の対応が必要となります。
(上記例では文字列型で扱っています)
Tsurugiについてはこれからの技術でもありますが、スケールアップの効果が発揮しやすく、
複数のサーバ管理をせずともよくなる、かつバッチで動かすような複雑な処理にも強いというメリットは
非常に魅力的であり、今後の注目技術と言えるかと思います。
おわりに
今回は「データ管理の最前線」と題して、最新のDBMSについて触れてきました。
YugabyteDBもTsurugiもdockerコンテナも用意されており、非常に簡単に試す事が可能ですので、
ご興味がわいたら触ってみるのも良いかと思います。
また「NWコンピューティングの処理高速化技術 第1回」の記事で触れたように
NW分野でもNW強靭化という観点で「可視化」がトレンドとなっています。
大量データを取りこぼす事なく保存する、という点において
今回紹介したDBMSのユースケースも出てくるかもしれません。
本件に関して、あるいはその他のネットワークに関する点でもご意見・ご質問等ございましたら、
以下にてお問い合わせください。
本件に関するお問い合わせ



<<<<著者プロフィール>>>>
フューチャーネットワーク事業部
第一ビジネスユニット
山口 佳輝(YAMAGUCHI YOSHIKI)
NWに関係したシステム開発を担当しています
>>>>>>>>><<<<<<<<<
![]()