ネットワークシステムにおけるデータ管理 ~RDBとNoSQL比較~ (前編)
ネットワークパケットシステムを例にRDBとNoSQLの違いをご紹介します




はじめに
こんにちは!NTTテクノクロスの山口です。
システム開発において「データをどのように管理するのか」という観点は重要なポイントとなりますが、
それはネットワークの世界においても同様です。
例えばセキュリティや分析の観点でパケットの入出力情報を管理する事やSDNコントローラにサービス情報(状態)を
保存されるといったケース、あるいは近年盛んに議論されている「自律型ネットワークの構築」(AI/MLの活用)においても
データをどのように管理するのかは重要な観点となる、など様々な用途でこのポイントは登場します。
とりわけネットワークシステムの分野でも多量のデータを管理する場合はデータベースを活用する事がありますが、
この点でいってもMySQLやPostgreSQLといった従来のリレーショナルデータベース(RDB)だけでなく、
近年はGreenplum DatabaseやVerticaといったデータウェアハウス(DWH)、CassandraやMongoDBといったNoSQL、
TiDBやYugabyteDBといったNewSQLなど、様々な選択肢から選ぶことができます。
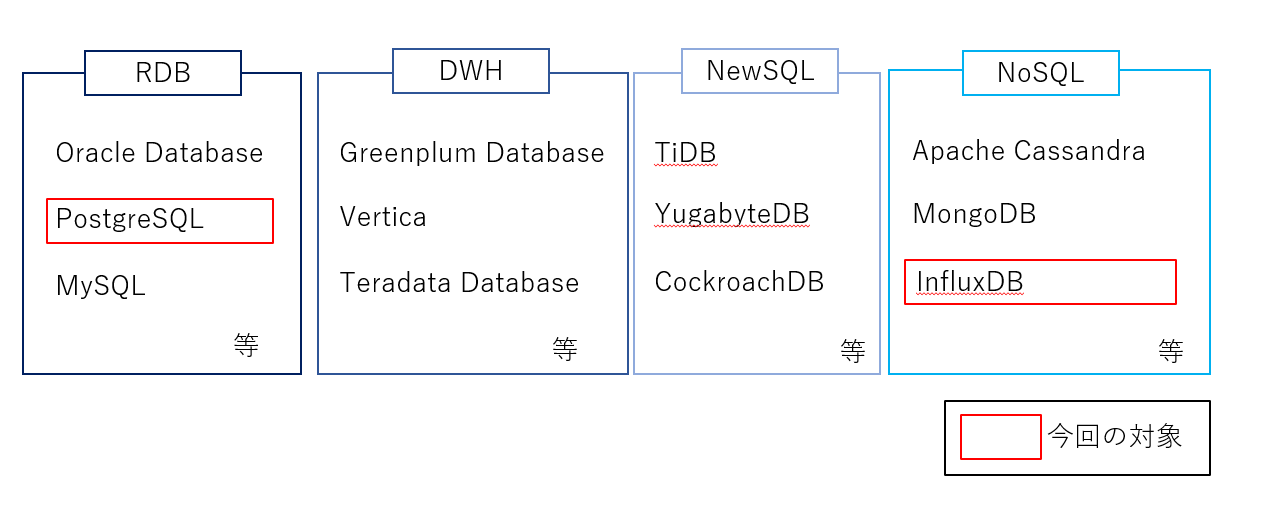
図1: 様々なデータベース
また、AWSに代表される大手パブリッククラウド環境でもRDSやRedShift、DynamoDBやTimestream等の簡単に
使い始められるサービスが用意されている他、OSS製品も多い事からプライベート環境でも試すことができ、
RDB以外の利用敷居も下がってきているように思います。
このように様々な選択肢が取りえる中で、要件に応じてどのように製品(DBエンジン)を選択すれば良いでしょうか。
今回は2回にわけて、一般的に言われている事を観点に本当にそうなのか?という点も踏まえながら、
ネットワークシステムで使う例を想定して、RDB(PostgreSQL)とNoSQL(InfluxDB)の比較を
行いたいと思います。
以降は以下の順で説明していきます。
| 章 | 節 |
| 前編(今回) | ① RDBとNoSQLの一般的な違いについて |
| ② 今回比較するDBと条件について | |
| ③-1 比較の実施 (処理速度) | |
| 後編 | ③-2 比較の実施 (その他) |
| ④ 比較結果からいえる事 | |
| ⑤ RDBとNoSQLを組み合わせた使い方について | |
| ⑥ 終わりに |

RDBとNoSQLの一般的な違いについて
RDBとNoSQLは完全に代替されるものではありませんが、「RDB NoSQL 違い」等のキーワードで検索を行うと
以下のような違いがあると出てきます。
|
観点 |
意味 |
|
処理速度 |
検索やデータ投入にかかる時間の違いの事を指しています。 一般的に書き込み処理や読み込み処理がNoSQLの方が早いと言われています。 |
|
検索性/操作性 |
NoSQLだと複雑な検索ができなかったり、RDBではできたことに一部制約が |
|
一貫性 |
データが矛盾なく登録される事を指します。 トランザクションの有無、あるいは制約ともいえます。 |
|
分散/拡張性 |
性能を向上させるためのスケールアウトがしやすい点があげられます。 一般的にはNoSQLの方がスケールアウトしやすいと言われています。 |
上記の4つの観点で、以降で実際に比較を行いたいと思います。
今回比較するDBと条件について
前述で上げた観点をどのように比較していくか、ですが題材とするシステムを以下のように考えたいと思います。
(極力シンプルな例としています)
| 観点 | 条件 | 備考 |
| 題材とするシステム | 「パケット情報」を登録するシステム |
選定理由は、多量のデータを管理する必要があり、 |
| 使用用途(ユースケース) | 何か問題が発生した際の分析 |
ユースケースを満たす具体的な操作としては |
| 管理するパケットデータ (1レコードの情報) |
5tuple情報 + 遅延情報 + 受信時刻(タイムスタンプ) |
5tupleとは「宛先IPアドレス」「送信元IPアドレス」 |
| システムの特徴 |
① 多量のデータを挿入・保存する |
① 管理するデータがパケット情報の為 |
| その他 | データの保持期間は7日間とする | 無限にデータを保存するといつかストレージ容量の 限界を迎える為 |
また、上記の要件を満たす為、データを管理する選択肢として以下の2つまで絞ったと想定します。
| 大項目 | 小項目 | 備考 |
| RDB | PostgreSQL |
PostgreSQL選定理由は以下。 |
| NoSQL | InfluxDB |
InfluxDB選定理由は以下。 |
加えてなるべくPostgreSQLとInfluxDBの比較条件を揃えるべく、テーブル構成は以下とします。
| 観点 | PostgreSQL (RDB) | InfluxDB (NoSQL) | 備考 |
| 主キー | 「受信時刻」「送信元IP」 を複合主キー |
タイムカラム:受信時刻 |
主キーは一意となる情報を指定するものである為、正確には5tuple全て指定した方が確実(システム要件にもよる)だが、今回は例の為、送信元IPのみの指定とする |
| index付与 | 他付与なし | 他付与なし (他は全てフィールドカラム) |
検索を高速化できることから、主キー以外の検索される可能性が高いカラムにも index付与(InfluxDBの場合はタグカラム化)しておくべきだが、今回は例の為、(違和感はあるが)他カラムには付与しない |
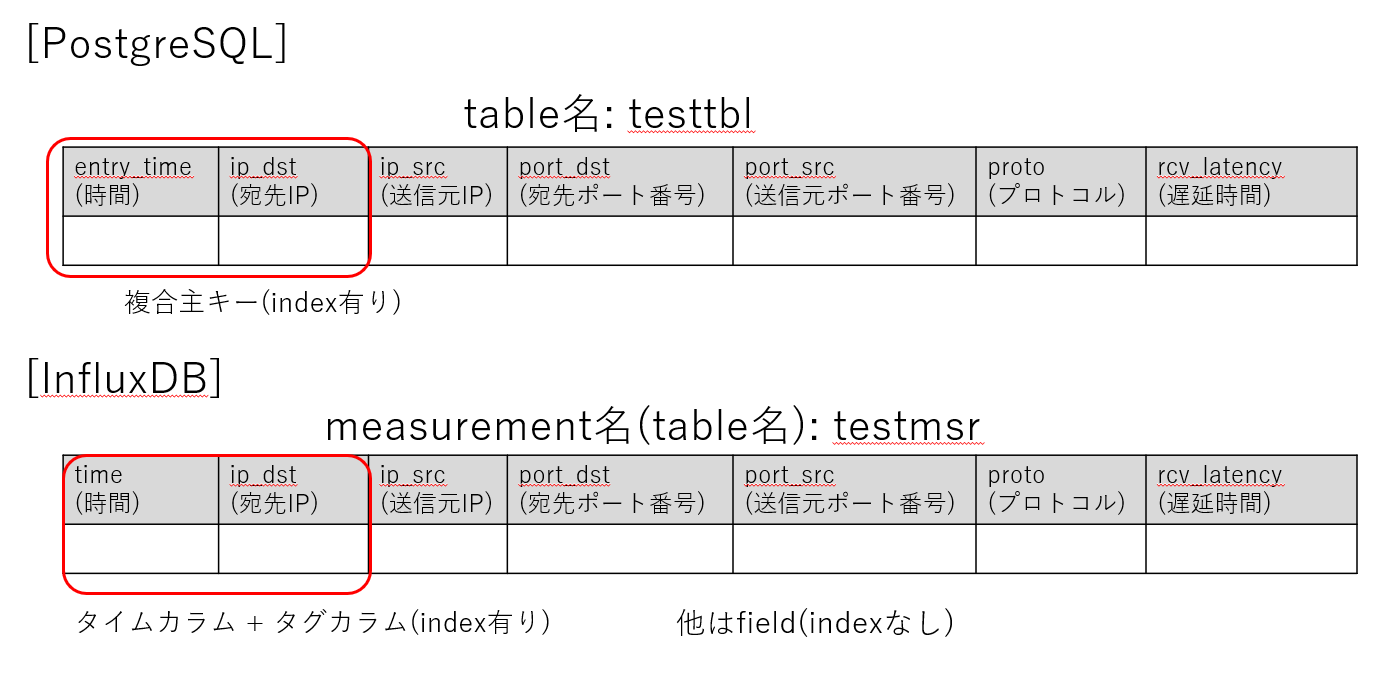
図2: テーブル構成
検討環境はUbuntu20.04 LTS とし、PostgreSQL環境もInfluxDB環境も、vCPU 4コア、 メモリ4GBとします。
また、PostgreSQLは15.1を、InfluxDBは1.8を使用します。
比較の実施
「RDBとNoSQLの一般的な違いについて」に記載した観点に沿って以下で比較を行います。
1. 処理速度
処理速度は「検索(indexあり)」「検索(indexなし)「書き込み」の3観点で実測をしてみました。
① 検索(indexあり)
測定はPostgreSQLはSQL、InfluxDBはInfluxQL(SQLライクに使えるクエリ文)を使用します。
両者ともに「explain analyze」を使用し、検索条件はindexが付与されている
主キー相当(時間と宛先IP)で検索を行います。
測定条件はキャッシュの影響がない状態で1回実施とします。
[PostgreSQL]
クエリ: explain analyze select * from testtbl where entry_time = '2022-05-25 16:13:19' and ip_dst='192.168.9.196' ;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------
Index Scan using testtbl_pkey on testtbl (cost=0.44..8.46 rows=1 width=38) (actual time=462.732..462.738 rows=1 loops=1)
Index Cond: ((entry_time = '2022-05-25 16:13:19'::timestamp without time zone) AND (ip_dst = '192.168.9.196'::inet))
Planning Time: 132.697 ms
Execution Time: 479.034 ms
[InfluxDB]
クエリ: explain analyze select * from testmsr where time = '2022-05-25 16:13:19' and ip_dst='192.168.9.196' tz('Asia/Tokyo')
EXPLAIN ANALYZE
---------------
.
└ select
├ execution_time: 13.993811ms
├ planning_time: 20.728276ms
├ total_time: 34.722087ms
以下略
[総評]
PostgreSQLよりInfluxDBの方が読み取りが早い、という結果となりました。
| 測定対象 | 結果 |
| PostgreSQL | 611.73ms |
| InfluxDB | 34.72ms |
② 検索(indexなし)
今度はindexの付与されていないカラム(フィールド)に対して検索を行ってみます。
[PostgreSQL]
クエリ文:explain analyze select * from testtbl where ip_src='172.16.19.136' and port_dst = 52499 and port_src = 52499 ;
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------
省略
Planning Time: 0.141 ms
省略
Execution Time: 59665.057 ms
[Influxdb]
クエリ文:explain analyze select * from testmsr where ip_src='172.16.19.136' and port_dst = 52499 and port_src = 52499
EXPLAIN ANALYZE
---------------
.
└ select
├ execution_time: 32.675338211s
├ planning_time: 1.691275217s
├ total_time: 34.366613428s
以下省略
[総評]
Indexが付与されていない場合もInfluxDBの方が圧倒的に早い結果となりました。
| 測定対象 | 結果 |
| PostgreSQL | 59665.2ms |
| InfluxDB | 34.36ms |
RDB全般に言える事ですが、やたらにindexを付与すると容量肥大化やinsert処理に時間がかかるようになるなどの
副作用が発生する為、全てのカラムにindexを付与する事は現実的ではなく、その点においてもInfluxDBが優位に見えます。
③ 書き込み
書き込み処理(insert)ではInfluxDBがexplain analyzeを使用できない(※)為、DBMSの処理時間のみを抽出する事は
できない方法ですが、dateコマンドで開始と終了時刻を表示させ、間でフロントエンドツール(psql(PostgreSQL)、influx(InfluxDB))
で挿入処理を行うシェルスクリプトを使用して測定を行います。
※ postgeSQLはexplain analyzeが可能です
[PostgreSQL・InfluxDB]
それぞれ3回ずつ測定した結果が以下となります。
|
|
1回目 |
2回目 |
3回目 |
|
PostgreSQL |
0:00:00.626 |
0:00:00.743 |
0:00:00.489 |
|
InfluxDB |
0:00:00.004 |
0:00:00.009 |
0:00:00.004 |
[総評]
若干ブレはあるものの、書き込みにおいてもInfluxDBの方が圧倒的に早い事がわかります。
一般的に言われている通り、NoSQL(InfluxDB)の方が、RDB(PostgreSQL)と比較して、
読込・書込ともに処理速度が優れている点がわかりました。
前半における比較は一旦ここまでとしたいと思います。
おわりに
今回は比較観点や題材とするネットワークシステムに関する説明、処理速度に関する比較を行いました。
次回(後編)では検索性/操作性や、一貫性、分散/拡張性などの比較を行った上で、最後にRDBとNoSQLと
組み合わせて使う例もご紹介します。
一般的に言われている事とのズレや、検索性/操作性の観点ではネットワークシステムならではのポイントにも
触れたいと思います。
本記事の連載に関して何か問い合わせがございましたら、以下に連絡下さい。
よろしくお願いいたします。
本件に関するお問い合わせ


{kind=link}

[著者プロフィール]
フューチャーネットワーク事業部 第一ビジネスユニット
山口 佳輝(YAMAGUCHI YOSHIKI)
![]()