AlloyDB for PostgreSQL の プレビュー版Query Insights(クエリ分析機能)を使ってみた
AlloyDB for PostgreSQL の Query Insights を色々触ってみたので、使用感等をお伝えします。




ぬこのたのしいぽすぐれ教室
- 2022年09月02日公開
はじめに
こんにちは。NTTテクノクロス株式会社の上原です。 私が所属するデータベースチームでは、現在クラウド環境のDBaaSに力を入れています。特に今年度はAlloyDB for PostgreSQL(以降、AlloyDB)のプレビュー版のリリースや、Azure Database for PostgreSQL - フレキシブル サーバーが GA されたので、今後は積極的にこれらを利用して使用感等を探っていく予定です。
AlloyDBに関する前回の記事では、中村さんによるAlloyDBのサーバパラメータ設定についての調査結果の報告がありました。 まだ詳しい内容のわかっていないパラメータも多数あり、今後勉強していく必要がありそうです。また、現時点ではコンソールからサーバパラメータの設定値を参照できないということだったので、このあたりは運用にも関わる部分なので、GA版でどこまで機能強化されていくのか注目しておく必要がありそうです。
今回の記事では、AlloyDB で使用できる Query Insights というクエリを分析する機能についてご紹介します。
Query Insights はプレビュー版の機能として提供されています。PostgreSQLのフックを利用して、実行計画の自動サンプリング等を行い、時系列で実行計画の変化や性能監視に利用できるもののようです。OSS版のPostgreSQLでは提供されていない機能なので、どういった感じで結果を出力できるのか楽しみです。 なお、同様の機能が Cloud SQLの「Cloud SQL Insights」として提供されていますが、今回調査した限りでは機能として大きな違いはなさそうでした。ただ、取得できる項目に差があったり、オプション設定の有無等、多少の違いはあるようです。
Query Insights とは?
Query Insights は、クエリのパフォーマンス問題を検出するため、監視と診断を行う機能です。ダッシュボードから、SQLの実行時間や、実行回数、実行計画などを確認でき、問題の早期発見、解消に使用することできます。 ダッシュボードから1週間分のデータにアクセスすることができ、多くの業務用クエリが実行される環境であっても、問題となっているクエリの特定や、個々のクエリの性能分析に活用できます。
本来、手間の掛かる監視の準備作業が不要で、AlloyDBを使用するユーザであれば誰でも利用することができます。なお、Query Insights 自体は無償ということなので、これも嬉しいポイントです。
Query Insights は PostgreSQL のフック機能を使用する拡張機能として実装されており、メトリクスや実行計画は共有メモリ内に保存されています。ディスクIOを極力避ける設計となっており、本機能によるオーバーヘッドも小さいということです。ただし、クエリの保存文字列数(google_insights.max_query_length)を変更した場合は共有メモリが増加するため、注意が必要です。
公式ドキュメントはコチラ(About Query Insights)です。
Query Insights の利用手順
Query Insights はデフォルトで有効になっており、パレットから選択して使用することができます。
まず対象のクラスタを選択します。
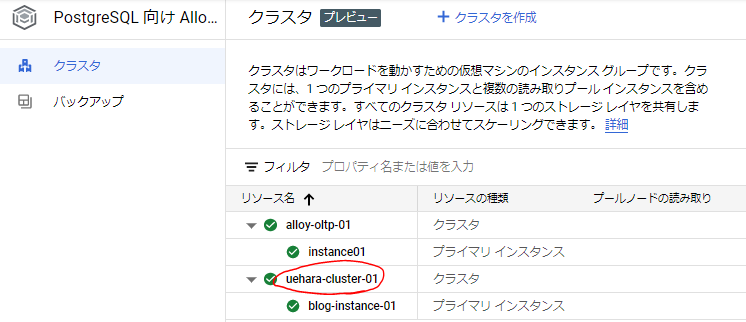
その後、パレット内に「Query Insights」という項目があるので、選択します。
「Query Insights」ではどういった情報が出力されるか
クエリの分析情報として、以下の内容を確認することができます。
- ・実行状況の概要
- ・データベースの負荷 - すべてのクエリ
- ・上位クエリとタグ
- ・クエリ単位の分析情報
- ・クエリの詳細
- ・クエリプランのサンプル
- ・クエリのレイテンシ
- ・データベースの負荷-特定のクエリ
- ・上位のクライアントアドレス、トップユーザ
- ・実行計画
- ・クエリプラン
- ・エンドツーエンド
- ・トレースログ
- ・ラベル
それぞれ、どういった内容が出力されるのかについては、以下、キャプチャを交えて紹介します。
なお、ここでは以下のベンチマーク実行後の環境でQuery Insights の動作確認を行っています。
$ pgbench postgres -U postgres -h 10.10.10.23 -c 64 -j 8 -T 600 -r
実行状況の概要
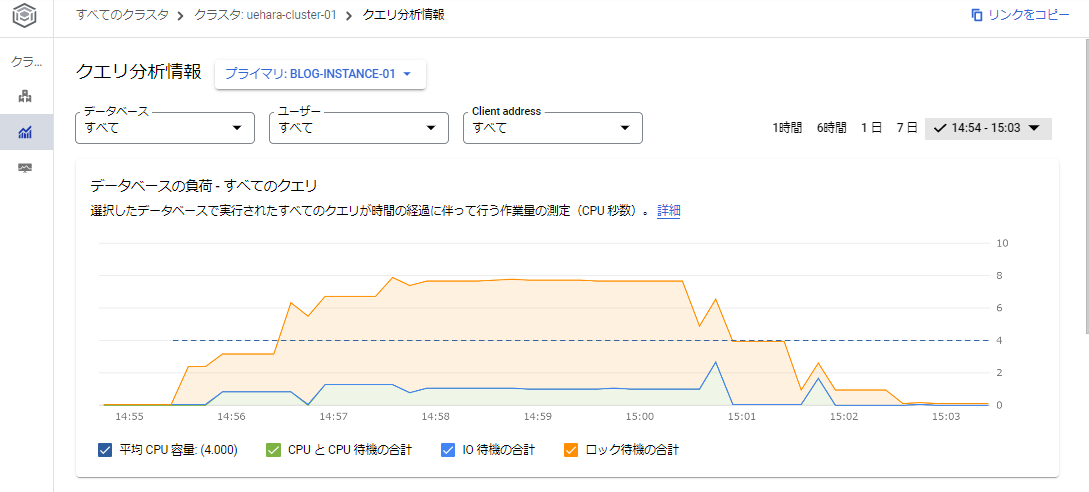
- データベースの負荷 - すべてのクエリ
選択したデータベースで実行されたすべてのクエリのCPUの使用状況の変化を時系列で確認することができます。 サンプルで取得した結果では、CPUの殆どが「ロック待ち」となっていたということが読み取れます。
- 上位のクエリとタグ 現在選択されているデータと期間内で最もデータベースに負荷をかけたクエリとそのタグの概要が出力されます。 Query Insights では、各クエリを関連するビジネスロジックに「タグ付け」することが可能であり、これによりAP観点でクエリの監視が容易になります。
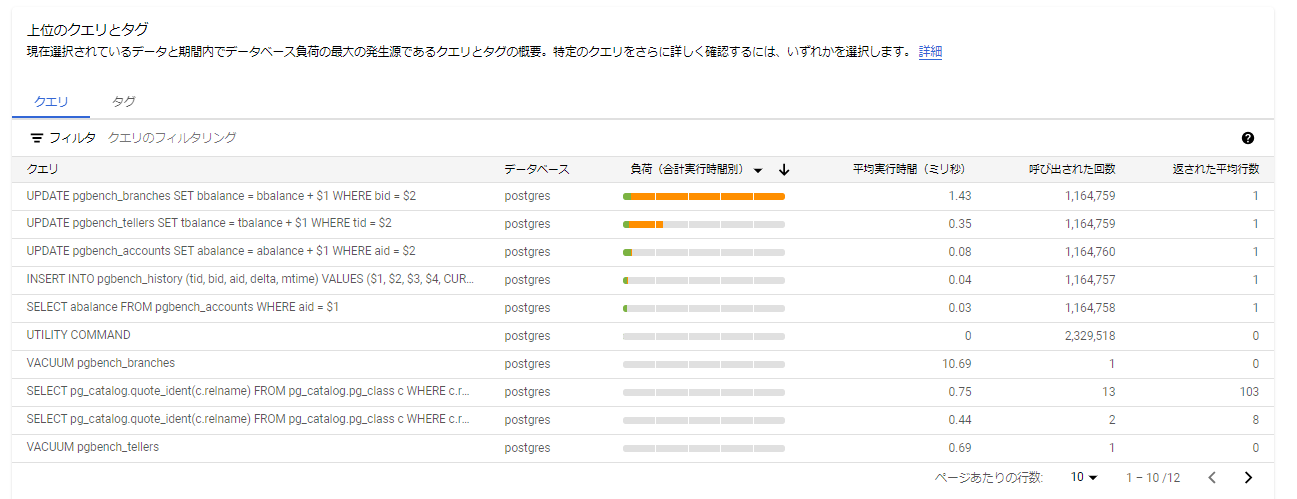
クエリ単位の分析情報
期間中に実行され、画面に出力されているクエリを選択することでより詳細な分析情報を出力することができます。
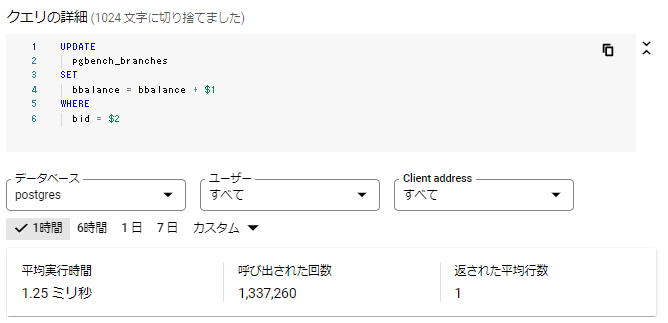
クエリの詳細
実行されたSQLと「平均実行時間」、「呼び出された回数」、「返された平均行数」が出力されます。呼び出された回数は出力期間を短くすると減少するので期間内の累計値になっており、他は期間内の平均値が出力されているようです。
クエリプランのサンプル
統計情報としてサンプリングされたのがどのタイミングかを表したものになっているようです。動作確認として、pgbenchを5分しか実行していないので1ポイントしか取れていないようです。

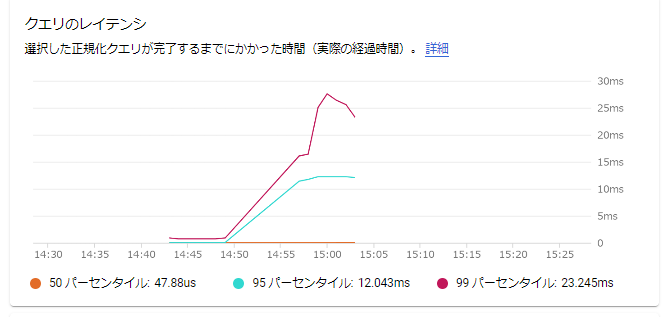
クエリのレイテンシ
選択したクエリのレイテンシが出力されています。
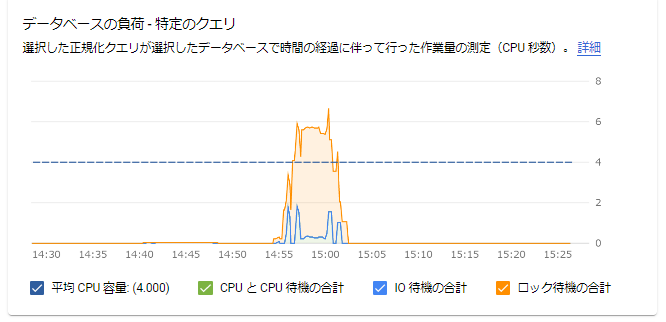
データベースの負荷-特定のクエリ
選択したクエリがどの時間でどういった動きをしていたのかが出力されています。実行状況の概要ではまとまった形で表示されていましたが、選択された特定のクエリに関する情報が出力されるようです。
上位のクライアントアドレス、トップユーザ
AlloyDBに接続しているクライアントやユーザを特定することができます。 AlloyDBのインスタンスに対して多くのクライアントから接続している場合、どのクライアントからの負荷が高いかを分析するのに便利そうです。
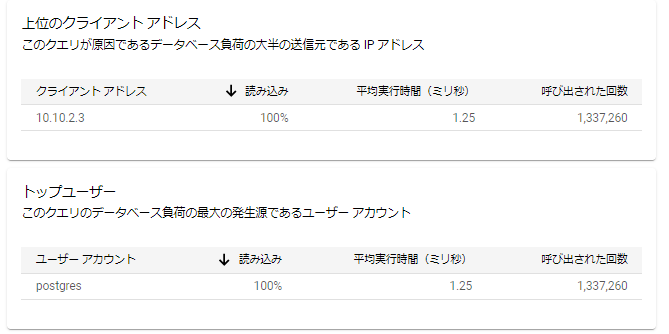
クエリの例
クエリプラン
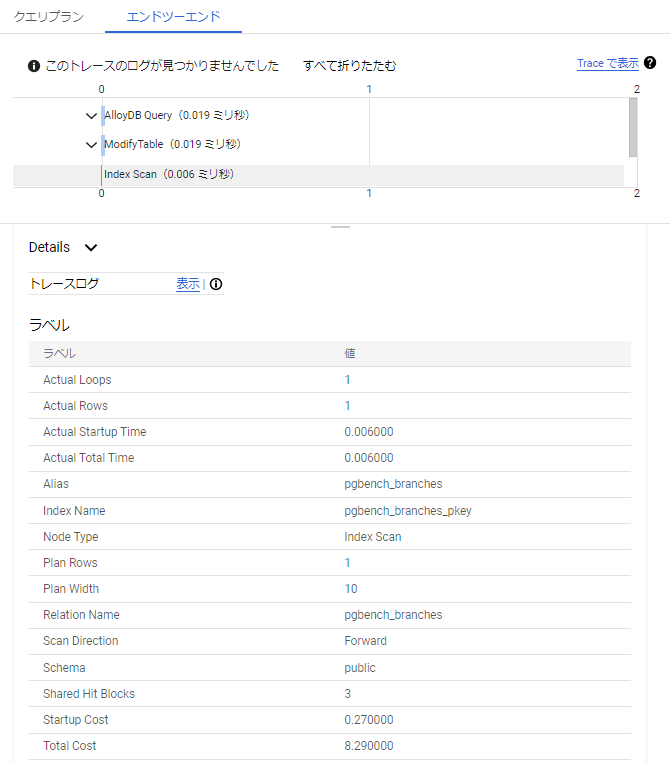
AlloyDB内でサンプリングした該当クエリの実行計画が出力されます。
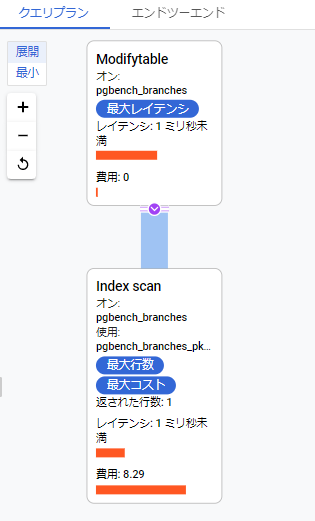
以下、同じ環境で実際にEXPLAINを実行した結果です。 この結果から、「クエリプラン」の費用は、EXPLAINのcostの値が参考にされているということがわかります。
postgres=> EXPLAIN UPDATE pgbench_branches SET bbalance = bbalance + 10000 WHERE bid = 20000; QUERY PLAN ----------------------------------------------------------------------------------------------------- Update on pgbench_branches (cost=0.27..8.29 rows=0 width=0) -> Index Scan using pgbench_branches_pkey on pgbench_branches (cost=0.27..8.29 rows=1 width=10) Index Cond: (bid = 20000) (3 rows)
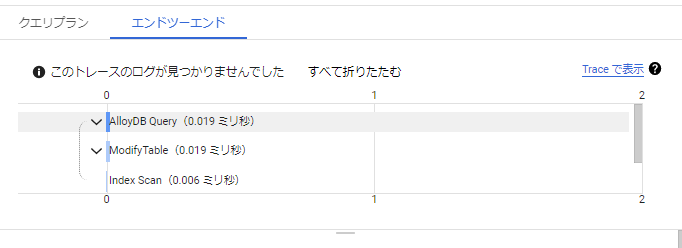
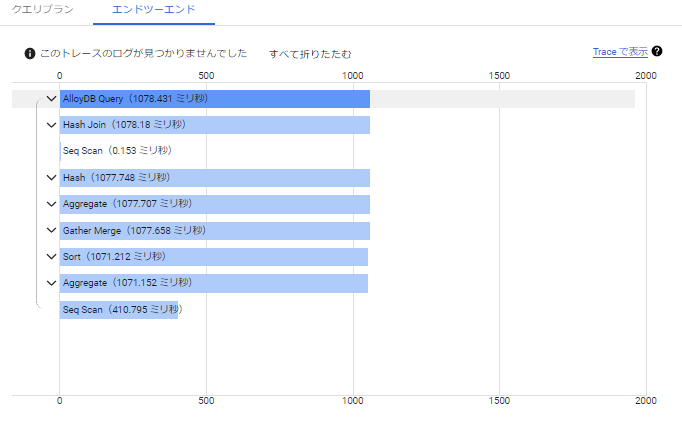
エンドツーエンド
積み上げでクエリの処理時間が算出されるようになっています。
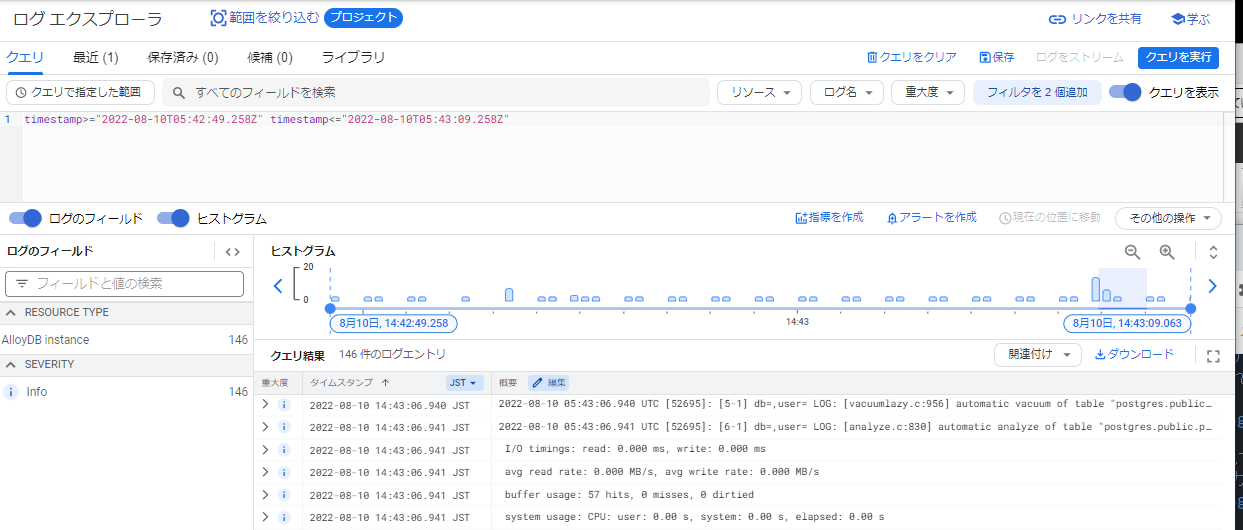
トレースログ
トレースログの「表示」を押下することで、指定したSQLの実行期間中のサーバログを出力することができます。
何件のメッセージが出力されているか、出力されたログレベル(INFO等)のサマリも出力されており、どの時間帯でどれくらいのログが出力されたのかヒストグラムで表示されています。

ラベル
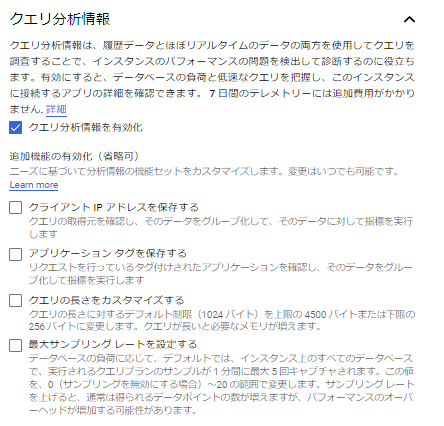
クエリの実行結果の詳細を確認することができます。 また、下図のように任意のノードを指定することで、対象のノードの情報(Actual Total Time:処理に掛かったトータルの時間等)を取得することができます。
分析結果の例
pgbenchのデフォルトワークロードではSQLが単純すぎるので、実行例としてJOINを含むクエリ、パーティションテーブルを対象にしたクエリの結果について以下で紹介します。
JOINを含むクエリの場合
JOINを含めたSQLを用いて内容を再度確認します。
動作確認したSQLはこちらです。(内容に意味は無く、適当にJOINさせています。)
SELECT t.bid, t.tid, ab.ca FROM pgbench_tellers t LEFT JOIN ( SELECT COUNT(aid) ca, a.bid FROM pgbench_accounts a LEFT JOIN pgbench_branches b ON a.bid = b.bid AND b.bbalance > $1 GROUP BY a.bid ) ab ON t.bid = ab.bid AND t.tid = $2
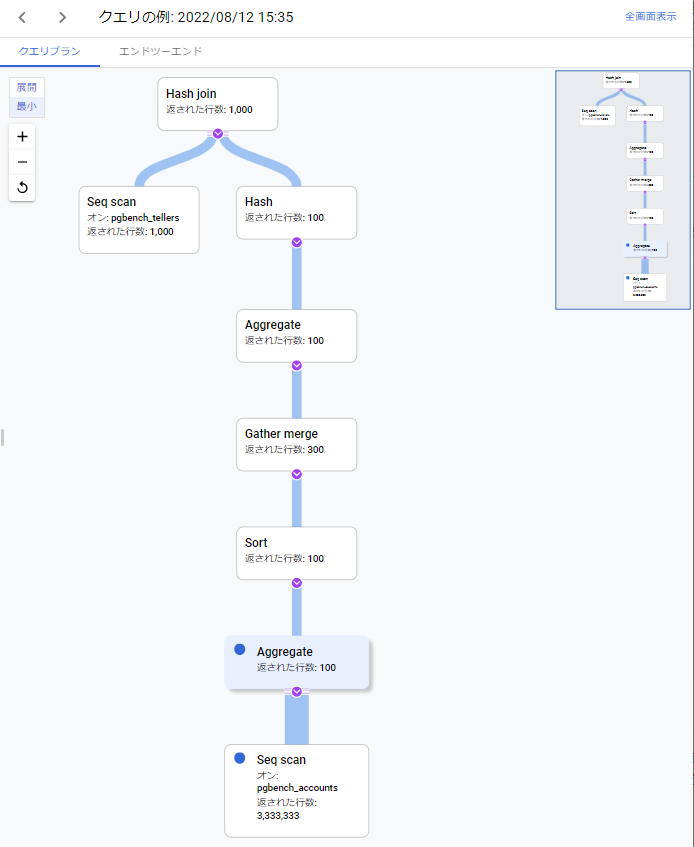
クエリプラン
今回のケースでは、特に絞り込みを行わないまま、pgbench_accountsとpgbench_branchesの結合を行っており、pgbench_accountsに対してパラレルSeqScanが行われています。また、Gather mergeノードからパラレルスキャンが動いたことも確認することができました。
エンドツーエンド
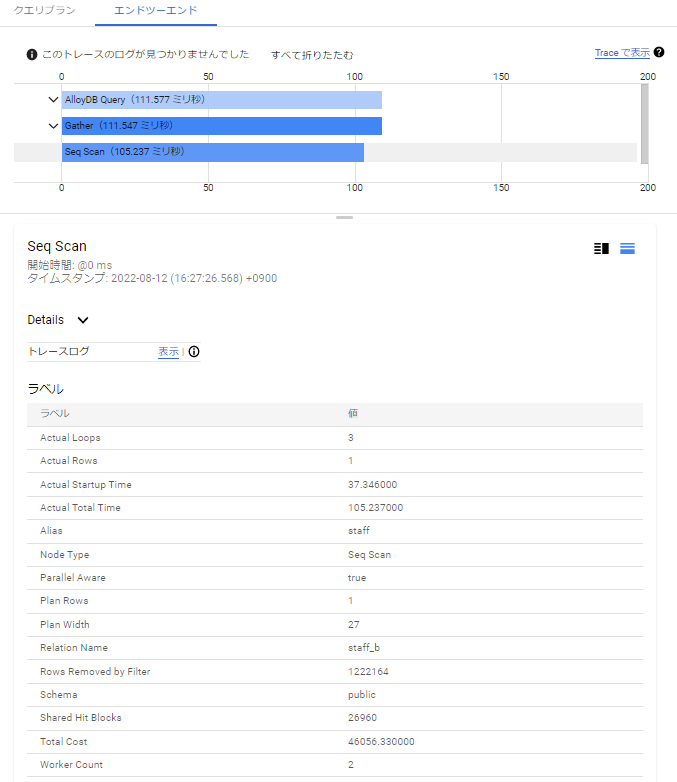
SeqScanノードを選択するとラベル情報で以下のようにワーカー数を確認することができました。
![]()
パーティションテーブルに対するクエリの場合
最後にパーティショニング構成のテーブルに対するクエリでパーティションプルーニングされる場合に分析結果がどのように表示されるのか確認します。
以下のSQLでハッシュパーティションを作成し、staff_idの絞り込みを行うSQLを実行しました。
-- パーティションテーブル作成 CREATE TABLE staff( staff_id int not null, name text not null, age int ) PARTITION BY HASH (staff_id); -- 各パーティションを作成 CREATE TABLE staff_a PARTITION OF staff FOR VALUES WITH (MODULUS 3, REMAINDER 0); CREATE TABLE staff_b PARTITION OF staff FOR VALUES WITH (MODULUS 3, REMAINDER 1); CREATE TABLE staff_c PARTITION OF staff FOR VALUES WITH (MODULUS 3, REMAINDER 2);
クエリプラン
プルーニングが効いて、特定のパーティションにのみSeqScanが行われていることを確認できました。
ただ、パーティションキーにはランダムの値を入れて参照を行う用にしていたので、サンプリングの関係で「staff_b」となっているものと考えられます。
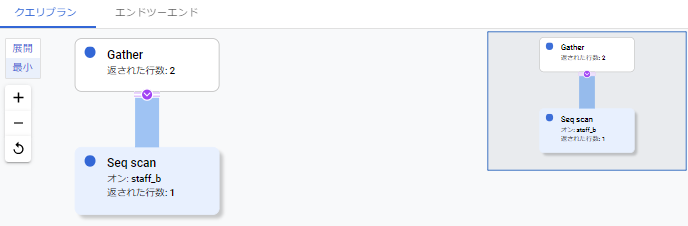
エンドツーエンド
Gatherノードがあることから、パラレルクエリが動作していることパラレルワーカの数が「2」だったことが確認できます。
Cloud SQL Insightsとの違い
クエリの分析機能はCloud SQL Insightsとして同様のものが既にサポートされています。 今回確認した範囲で確認できた違いについて紹介します。
オプションの有無
Cloud SQLでは分析機能を有効化する際にオプションとしていくつかの項目を設定することができます。 AlloyDBでは、現状このようなオプションは用意されていませんが、GA版では用意されるかと思います。
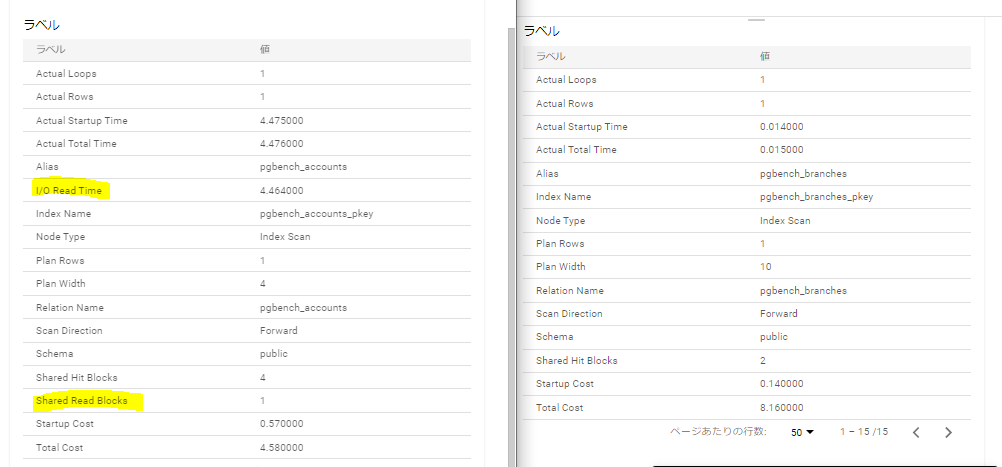
ノード情報の出力項目
左がAlloyDBの Query Insights の結果で、右がCloud SQL Insightsの結果です。 I/O Read Time, Shared Read Blocksが項目として追加されていることを確認しました。
まとめ
デフォルトの設定でこれだけの情報を取得できるのは、DBの正常性の監視や障害発生時の解析において、非常に有用だと思います。
例えば、OSS版のPostgreSQLであれば、実行計画を取得するには auto_explainを事前に設定する必要があります。また、性能影響を考慮してサンプリングの比率も設計する必要がありました。また、auto_explain の結果はサーバログに出力されるため、性能影響も考慮して設計する必要があり、気軽に利用するのは少し難易度が高いものでした。 しかし、AlloyDBであれば、実行したSQLをサンプリングし、auto_explainの設定なしに実行計画を取得でき、それが集計することなく時系列で確認することもできるので、運用において大きな強みになる考えます。
気になった方はぜひAlloyDBを実際に触って、この機能を試してみてください。
AlloyDB の Query Insights はプレビュー版として提供されているため、GA版ではこの記事のとおりではない可能性がある点についてはご注意ください。
PostgreSQLのことならNTTテクノクロスにおまかせください!
NTTテクノクロス株式会社ではPostgreSQLに関する各種のお問い合わせを受け付けています。 システムの導入、開発、維持管理の際にご活用ください。



PostgreSQLを最初に触ったのは PostgreSQL 9.4 で、それからずっとデータベース関連の業務に携わっています。社内、社外でのセミナー講師等もやらせていただく機会が多く、教材の作成を通じて一緒に勉強させてもらっています。
最近は、AWSだけでなく、Azure、GCPにも手を伸ばして色々勉強中です。
![]()