ネットワークシステムにおけるデータ管理 ~RDBとNoSQL比較~ (後編)
ネットワークパケットシステムを例にRDBとNoSQLの違いをご紹介します




はじめに
こんにちは!NTTテクノクロスの山口です。
前回はネットワークシステムを例にデータ管理をどのように行うべきか、比較対象や条件の説明や
一部比較について説明しました。
今回は残りの比較を行い、結果をまとめつつ、最後には「RDBとNoSQLを組み合わせた例」についても
ご紹介しようと思います。
前回(前編)と今回(後編)の内容は以下のようになります。
比較条件なども前編に記載していますので、まだ御覧になられていない方は合わせてご確認ください。
| 章 | 節 |
| 前編 | ① RDBとNoSQLの一般的な違いについて |
| ② 今回比較するDBと条件について | |
| ③-1 比較の実施 (処理速度) | |
| 後編(今回) | ③-2 比較の実施 (その他) |
| ④ 比較結果からいえる事 | |
| ⑤ RDBとNoSQLを組み合わせた使い方について | |
| ⑥ 終わりに |
比較の実施
「RDBとNoSQLの一般的な違いについて(前回参照)」に記載した観点に沿って比較を行います。
2. 検索性/操作性
① 検索性
検索性の観点では、NoSQLはRDBと比較し、便利な検索機能が少ない事があげられます。
例えば、PostgreSQLでは図1に記載のような結合処理ができますが、InfluxDBでは一部制約が発生します。
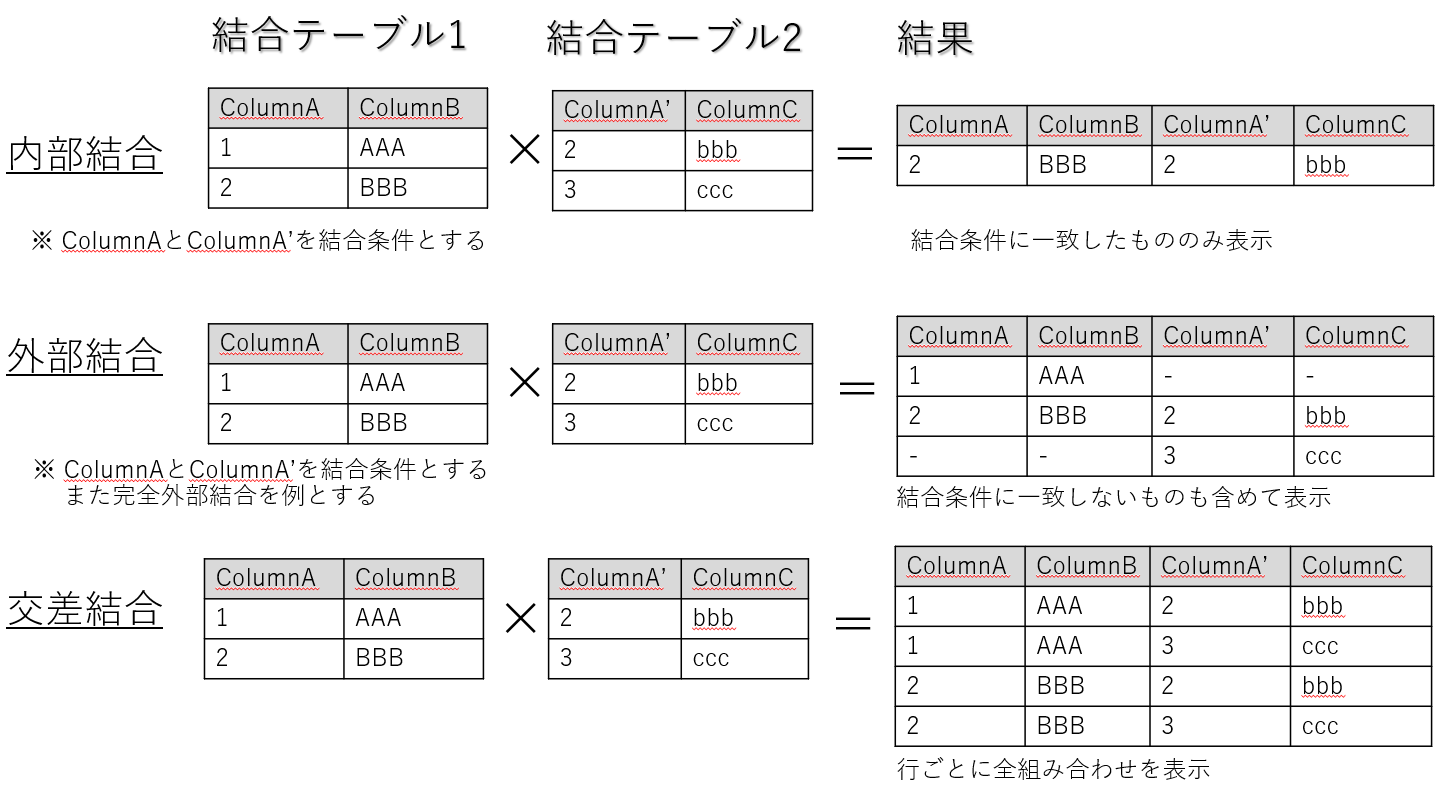
図1 SQLで実行可能な結合の種類
具体的なInfluxDBの結合処理の制約には、以下のようなものがあります。
| 制約 | 具体例 | 備考 |
| ① 活用方法の制限 | Fluxでしか結合検索ができない | 前編の速度比較で使用したInfluxQLでは不可。 またFluxはデフォルトオフの為、有効化が必要。 |
| ② 結合動作の制限 | 結合した際の動作が特殊 | 外部結合は未対応。 |
制約②については少しわかりづらいので、実際にFluxを使った結合をいくつか見ていましょう。
新たに例としてその時間帯のネットワーク機器のリソース情報(CPU使用率、メモリ使用率、ストレージ使用率)を
管理する「resourcemsr」が追加されたとしましょう。
「特定の時間のパケットの遅延時間が長かった場合にその時間のネットワーク機器のリソース情報を確認する」
といった使い方が想定されます。
このような場合は2つのテーブル(measurement)に必要なデータが跨っているので結合が必要となります。 図2 追加measurementとユースケース例のイメージ
図2 追加measurementとユースケース例のイメージ
まずは簡単な例として「特定の時間を指定し、それぞれ1field情報を得て結合する」ものがどのように結合されるか確認します。
結果は図3の通り、結合条件に一致したものだけが表示されます。
これはSQLで言う「内部結合」の動きとなります。
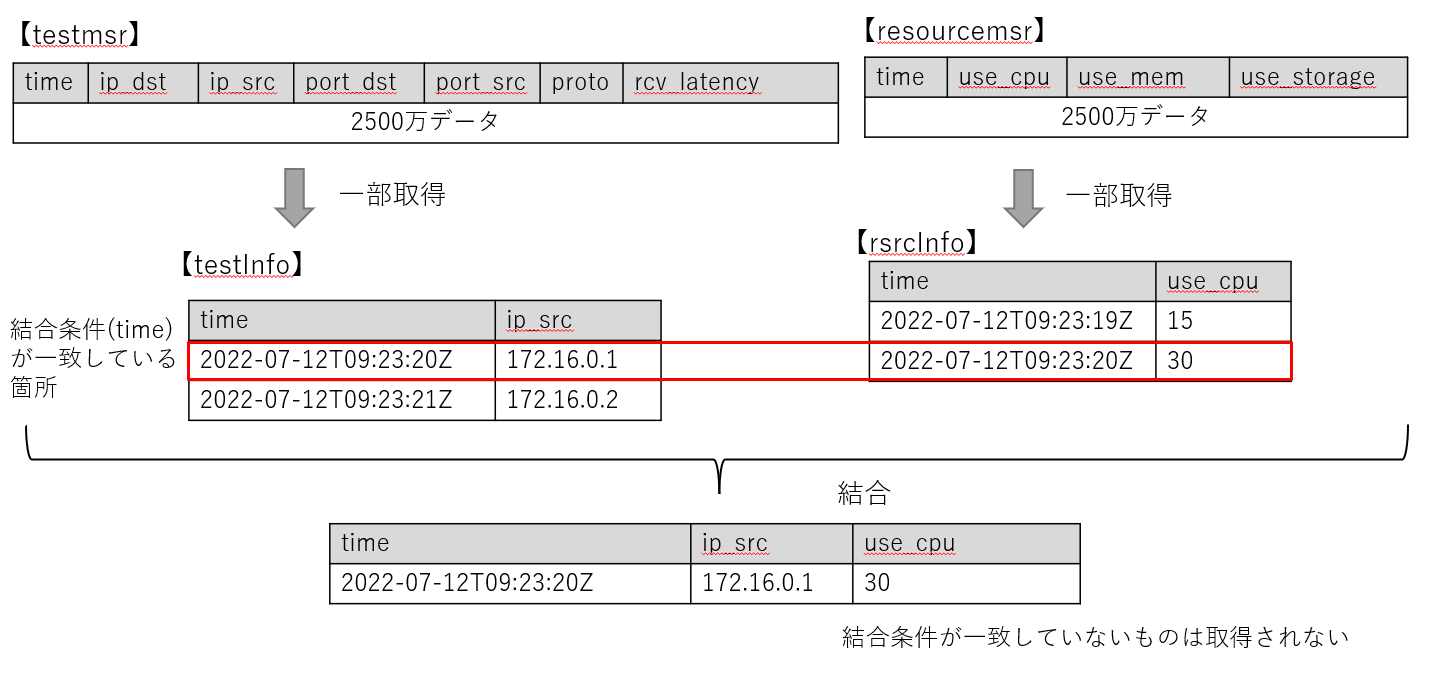
図3 Fluxの実行例1
では結合対象となるレコード(ポイント)とカラムが複数ある場合はどのようになるのでしょうか。
結果は図4のようにデータが取得されます。
時間データごとにカラム(列)の組み合わせを全パターン取得しており、交差結合に近い動きとなります。
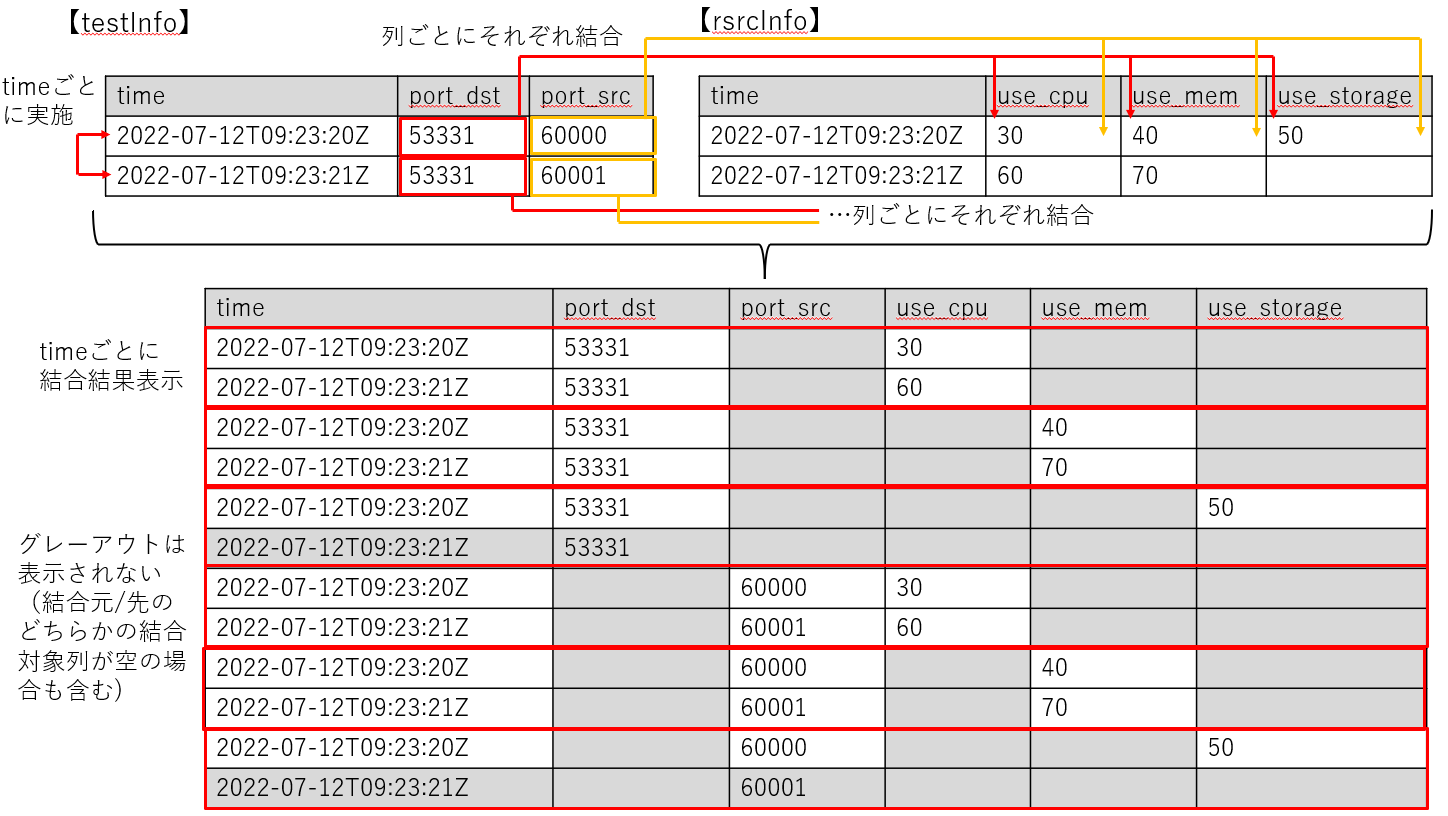
図4 Fluxの実行例2
つまり、結合するレコード自体は条件に一致する内部結合のような動きをしつつ、
列に関しては交差結合のような動きになります。
このように同じ「結合」といってもRDBとは異なった動きをする為、注意が必要です。
なお図3・図4ともに結合条件となる時間と取得するfiledしか記載していない事を注意ください。
(実際の取得結果はそれ以外の情報も含んでいます。)
なお、実行例は長くなる為、記載を省きますが、細部を確認されたい方はこちらから参照ください。
実行例のFluxのコードは単ラインを例に記載しています。
また実行例はあくまで参考ですので、実際に使用する際にはユースケースに沿った確認作業を行う事を推奨します。
② 操作性
PostgreSQLと比較し、InfluxDBに制限が付くのはデータの取得(検索)だけではありません。
以下で何点かご紹介します。
| 制約 | 具体例 | 備考 |
| ① 更新に関する制限 |
update文が存在しない |
タイムカラムとタグカラムが ※ タグカラムを指定していない |
| ② 削除に関する制限 | delete文による一括削除のみ可 | where句にてfield(indexなし)列を 条件に指定する事は不可。 |
| ③ データ定義に関する制限 |
「inet」型が存在しない ※「float」「integer」「string」 |
IPアドレス(inet型)は |
制約①と③は何が困るのかわかりづらい為、以下で具体的な注意点も何点か挙げます。
| 制約 | 具体例 |
| 制約① 更新に関する制限 |
今回の例のようにタイムカラム+タグカラムが主キーと同義の場合、 RDBと同じ感覚で使うと本来エラーとする箇所を意図せぬ更新がされてしまう。 |
|
都度時間とタグを指定しないといけない為、 |
|
| タイムカラム・タグカラムの更新はできない。 | |
| 制約③ データ定義に関する制限 |
IPアドレス特有の処理がDBMS上でできない。 |
一方でPostgreSQLにはなく、InfluxDB独自の機能も存在します。
例えば今回の例では「7日たったデータは削除する」という要件がありましたが、この点はInfluxDBに最適な機能があります。
それが「リテンションポリシー」と呼ばれる機能で、データ保持期間を設定し、期限が切れたものは定期的に
削除することができます。
ちなみにPostgreSQLでは上記要件をどのように実現するでしょうか。
データの削除手法としてはInfluxDBと同様に1テーブルで集中管理し、日時の範囲指定で定期的に該当レコードを
削除する、という手もあるでしょうし、メンテナンスや検索性の観点からテーブルをレンジパーティションで
日ごとに分けて日ごとテーブルごとにdropするという案もあるでしょう。
ただし、「定期的に削除」という機能はPostgreSQLには存在しない為、スケジューラ(cron等)による定期処理を
別途設定する必要があります。
その為、InfluxDBでは自身のみで完結・対応できていたものが、PostgreSQLの場合はDBMS以外の手段を
組み合わせて対応する必要があります。
3. 一貫性
RDBはACID特性を満たすため、トランザクション機能がサポートされており、PostgreSQLも例外ではありません。
InfluxDBではこのトランザクションが未サポートとなっています。
その為、例えば一部データを変えた際に別のデータも変えないといけない、という処理があった場合に
片側だけ成功し、片側は失敗となるケース(=データ矛盾が発生する可能性)があります。
一例として複数データ投入で見てみましょう。
csvファイルからデータを投入する方法として、それぞれ以下のような手法があります。
| DBMS | 方法 | 備考 |
| PostgreSQL | copy | 処理は1トランザクションとして行われる。 途中で処理失敗時にはロールバックで 処理開始前に戻して終了。 |
| InfluxDB | ExportCsvToInflux | トランザクションがない為、途中で 処理が失敗しても投入済みデータはそのまま。 |
なお、copyはPostgreSQLに実装された機能であるのに対し、ExportCsvToInfluxはサードパーティツールである点は
注意が必要ですが、InfluxDBはトランザクションがない為、途中で失敗しても巻き戻す方法がない為に
このような動きとなる、といえます。
また、InfluxDBではPostgreSQLと同様にログ先行書き込み(WAL)がある為、ACID特性のD(永続性)は満たされています。
実際にそれぞれの動きを見てみましょう。
[PostgreSQL]
# copy対象(トランザクション確認)用のテーブルtxtblの挿入実行前レコード数確認
testdb=# select count(*) from txtbl ;
count
-------
0
# 現在のトランザクション値を取得(copy実行前)。
# この関数を実行する度に1トランザクションIDを消費する為、何もなければ次は1389となる
testdb=# select txid_current() ;
txid_current
--------------
1388
# copy実行
testdb=# copy txtbl from '/home/ubuntu/tagert.csv' delimiter ',' csv ;
# 投入途中で処理停止。925872行目まで処理されていたことがわかる
^CCancel request sent
ERROR: canceling statement due to user request
CONTEXT: COPY txtbl, line 925872
# 再度トランザクションID確認。今回の関数実行分とcopy(1トランザクション)分で前回から+2トランザクションされている事がわかる。
testdb=# select txid_current() ;
txid_current
--------------
1390
# レコード数確認(copy実行後)
testdb=# select count(*) from txtbl ;
上記の実行例のように、PostgreSQLにおいてはトランザクションでcopyによるデータ投入をしており、
失敗した場合は途中まで投入した状態をそのままとせずトランザクション機能を用いて
copy実行前の状態(0レコード)に戻しているとわかります。
[InfluxDB]
# PostgreSQLと同様、投入先measurementの登録数確認。何も表示されない=何も登録されていないという結果。
> select count(*) from txmsr
# OSのターミナルでcsvより挿入コマンド(ExportCsvToInflux)の実行。途中で処理停止とする。
export_csv_to_influx --csv target.csv --dbname testdb --measurement txmsr --tag_columns ip_dst --field_columns ip_src,port_dst,port_src,proto,rcv_latency --time_zone 'Asia/Tokyo' --time_column entry_time --time_format '%Y-%m-%d %H:%M:%S'
(省略)
KeyboardInterrupt
# 再度投入先measurementの登録数確認。中途半端に情報が入っている事がわかる。
> select count(*) from txmsr
name: txmsr
time count_ip_src count_port_dst count_port_src count_proto count_rcv_latency
---- ------------ -------------- -------------- ----------- -----------------
0 11500 11500 11500 11500 11500
処理が途中で中断しているにもかかわらず、約1万程度のデータが登録されており、
中途半端な状態になっている事、また処理が失敗しても投入前に戻っていない事がわかります。
「検索性/操作性」の欄でも触れたようにタイムスタンプとタグが同じであればデータが更新されることから
csvインポートは途中で失敗した場合に再度実行する事で漏れなく登録する事はできます。
その為、この例自体はあまり問題にならないかもしれませんが、最初にも触れたような
「特定のデータを更新時に別の箇所も更新する」といった処理を実現しようとするとデータ矛盾に
つながる可能性があります。
4. 分散/拡張性
DBの性能を向上させたい場合、PostgreSQLではどのような手法がとれるでしょうか。
クエリの実行計画を確認し、パラメータチューニングを行う、CPUやメモリ数等を増加させるスケールアップを行う、
テーブル空間(table space)機能で実体ファイルの書き込み先を分ける等、様々な案が考えられます。
また、PostgreSQLの場合はレプリケーション機能で冗長化が可能、かつ
(ストリーミングレプリケーション・ロジカルレプリケーションどちらの方法でも)スタンバイ側で参照が可能な為、
レプリケーション機能を活用する事で書き込み処理と参照処理を負荷分散させるといった運用も可能となります。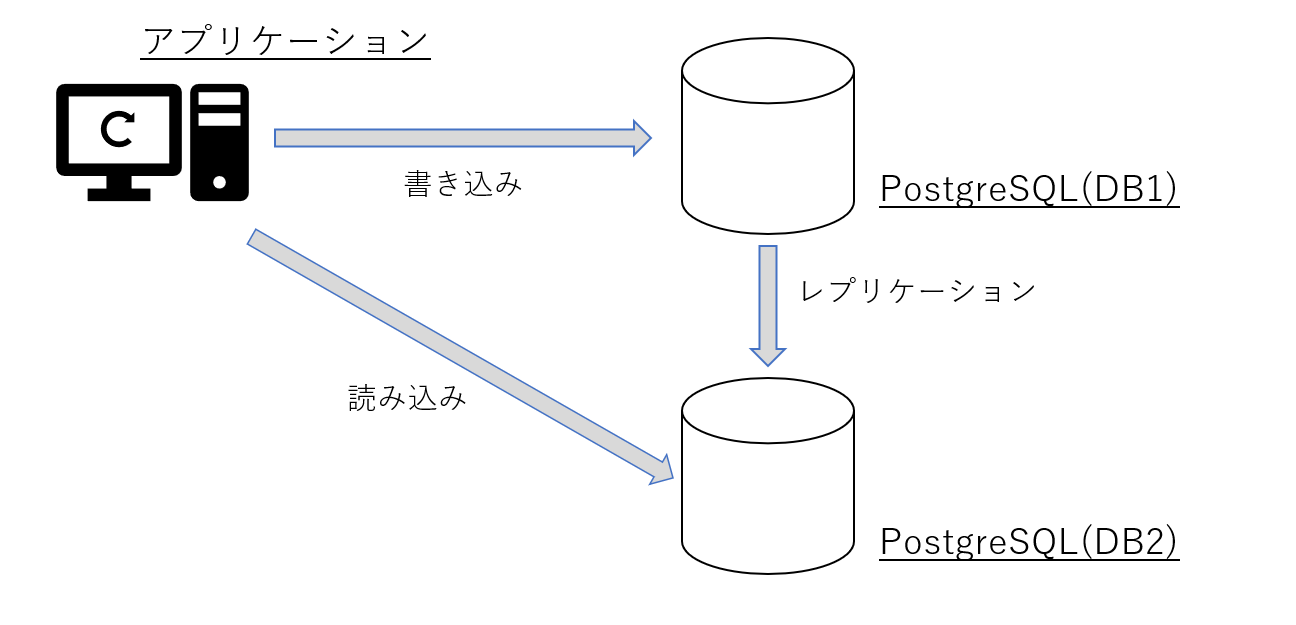 図5 レプリケーションを活用した負荷分散
図5 レプリケーションを活用した負荷分散
一方で、処理マシンの数を増やす事で性能向上を行うスケールアウトはPostgreSQL自体に機能はなく、
追加でシャーディングソフトを入れる等の対応が必要となります。
また、実現方法にもよりますが、例えば一部のクエリが実現できないといった機能的な制限が付く可能性があります。
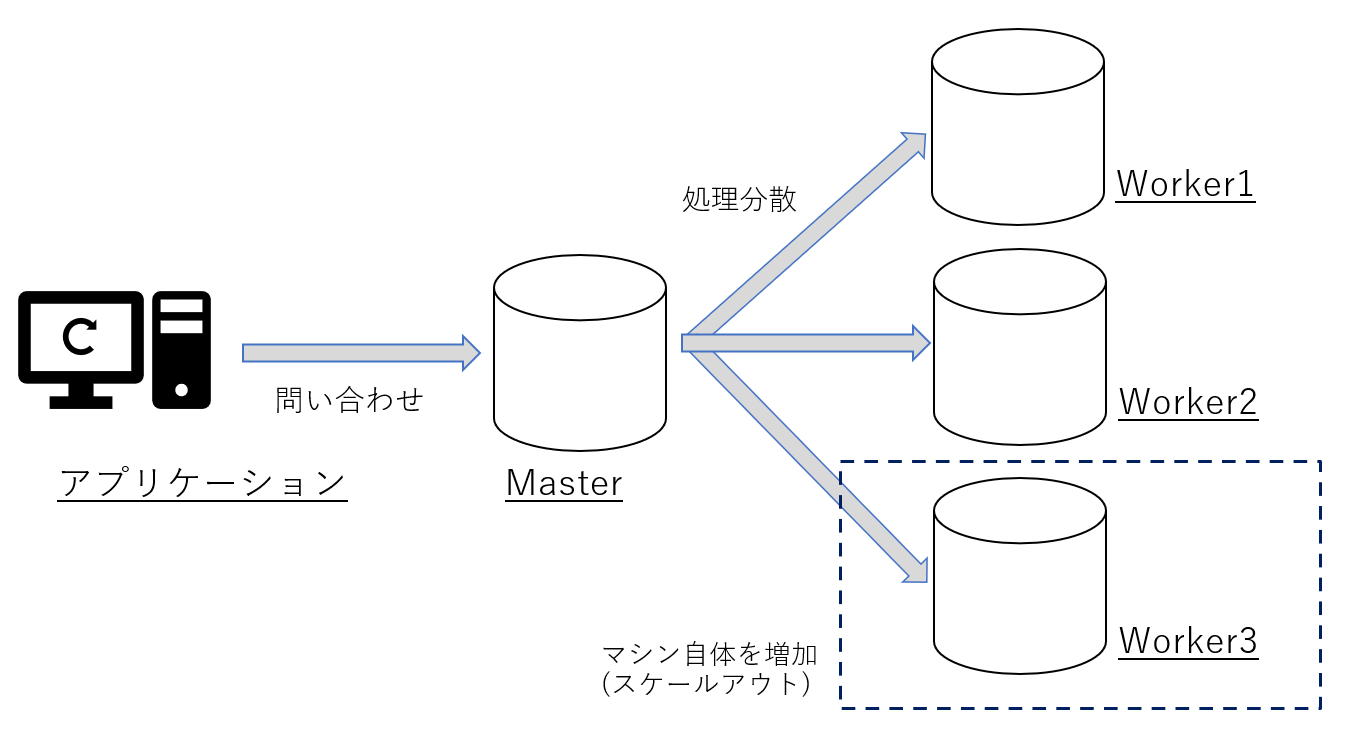
図6 シャーディングとスケールアウトのイメージ例
InfluxDBの場合はスケールアウト(クラスタリング機能)をサポートしており、追加ソフト等が不要で、
基本的にはスケールアウト後の機能的な制限を気にすることなく、スケールアウトを実現する事ができます。
ただし、クラスタリング機能は商用版のみサポートしており、OSS版では使用できません。
同様にレプリケーション機能もクラスタリング機能を使う為、商用版のみとなります。
商用版を使用すれば追加ソフト等不要でスケールアウトが可能になる為、InfluxDBは分散/柔軟性が高いといえます。
比較結果からいえる事
さて、これまで一般的にRDBとNoSQLの違いとして挙げられている事を観点に、PostgreSQLとInfluxDBの比較を行ってきました。
まとめると以下のようになるかと思います。
| 比較観点 | PostgreSQL (RDB) |
InfluxDB (NoSQL) |
| 処理速度 | × InfluxDBと比較し、 読込・書込性能に劣る。 |
〇 PostgreSQLと比較し、 読込・書込性能に優れる。 |
| 検索性/操作性 | △ InfluxDBと比較し、機能が豊富で、 ISOで標準化された方法(SQL)で 操作できる。 ただし、InfluxDBにしかない機能も 一部存在する。 |
△ PostgreSQLでできた操作等で 一部制約が付く事があるが、 InfluxDBにしかない機能もある。 NW観点ではinet型がなく、 DBMSでできる処理にも制限がつく。 |
| 一貫性 | 〇 トランザクションをサポート。 |
× トランザクション非サポート。 |
| 分散/拡張性 | △ レプリケーション機能が存在する。 スケールアウトには制限が付く 可能性あり。 |
× OSS版はレプリケーションも スケールアウトも未対応。 ※ 商用版はサポート |
上記結果はPostgreSQLとInfluxDBの比較結果でした。
次はこの結果をもとにもう一段、視野を上げてRDBとNoSQLの関係で言えそうな事を以下にまとめます。
| ポイント | 理由・具体例・備考 |
|
RDBとNoSQLの基本的な使い分けは、 |
具体的な使い分け例は以下。 |
|
一般的に言われている事(※)が使用予定の製品に |
「NoSQLは分散/拡張性が高い」と一般的に言われていたものの、 |
|
管理する情報やその情報の使い方に合う |
今回の例では、NWシステム特有の事例として、inet型の有無が該当。 |
参考までに弊社で例に近しいシステムを開発した際には検討の結果、RDBを使用しました。
理由は様々ですが、主な理由として高度な検索が必要であった事があげられます。
また、NoSQLの活用事例でいえば応答速度の求められる加入者DBの構築に用いた例等があります。
満たしたい要件や重視するポイントによって使用する製品を選択する事が重要です。
RDBとNoSQLを組み合わせた使い方について
「RDBとNoSQLの一般的な違いについて」の欄(前編参照)にて「RDBとNoSQLは完全に代替されるものではない」と記載しました。
最後に組み合わせて使うケースの例をご紹介します。
「比較結果からいえる事」で、NoSQLは書き込み速度がRDBより早いという点を上げました。
例えば「高度な検索を行いたいが、書き込みが多く、処理が追いつかない」という場合には
以下のような構成が取りうると考えます。
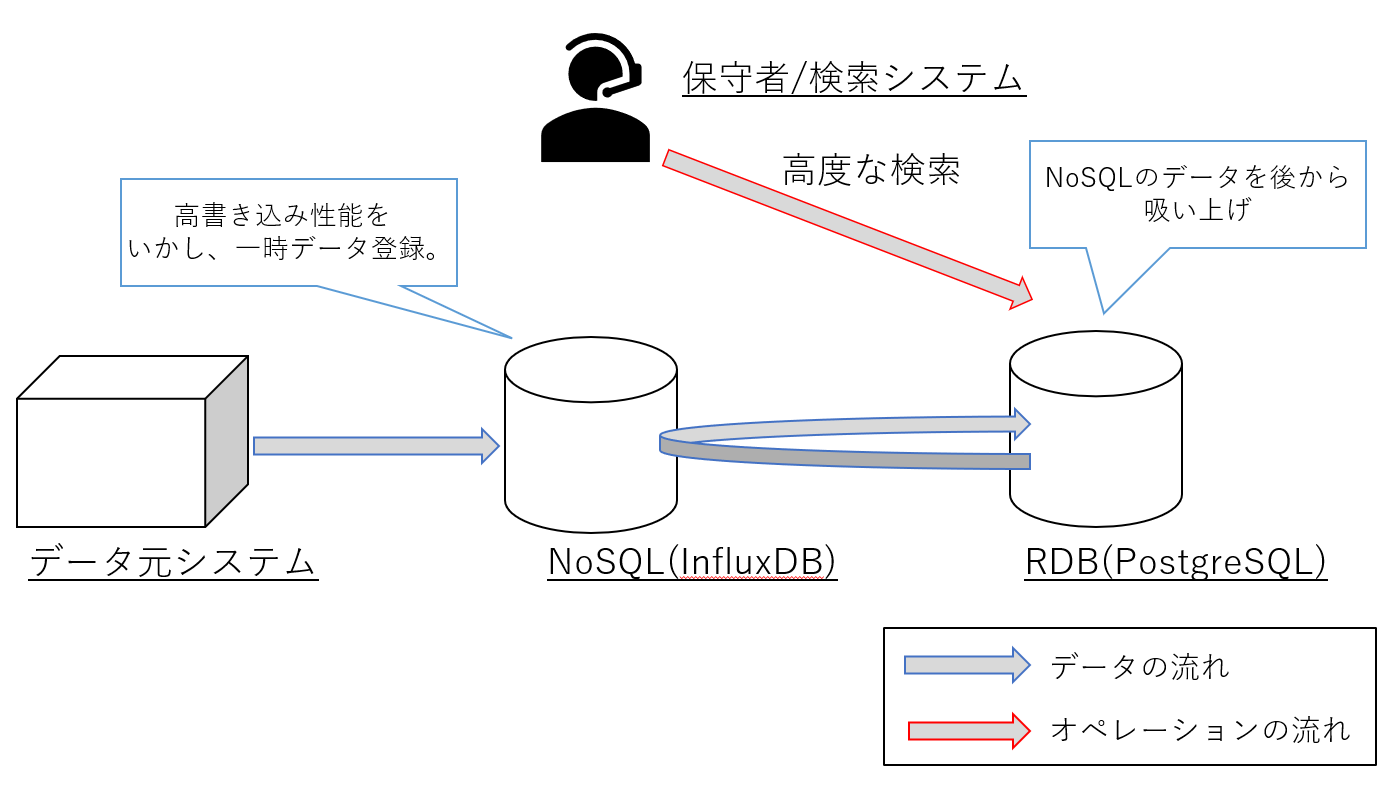
図7 NoSQLとRDBの組み合わせ構成例
このようにお互いの長所を組み合わせて、短所を補う形で構成する、という視点も重要です。
おわりに
今回はネットワークシステムを例にRDBとNoSQL(時系列)の比較を行いました。
NWエンジニアはNWの事だけ理解していれば良いというわけではなく、要件に応じてDBやフロントエンドの
理解も必要となります。
今回はその一例として、DB観点の比較を取り上げました。
弊社ではネットワークシステムの開発だけではなく、クラウドのノウハウも有しています。
クラウドに関して、パブリック・プライベート問わず、コンサルから設計、構築、保守・運用までご相談可能です。
よろしくお願いいたします。
本件に関するお問い合わせ



[著者プロフィール]
フューチャーネットワーク事業部 第一ビジネスユニット
山口 佳輝(YAMAGUCHI YOSHIKI)
![]()