OpenStackCeilometer+Heatを使ったオートスケール(第1回)オートスケールって何?
「どうやればOpenStackでオートスケールができるのか」を我々が実際にオートスケールを利用したOpenStackシステムを構築した際の経験を元に解説したいと思います。




テクノロジーコラム
- 2016年02月01日公開
はじめに
OpenStacK®やAWS等でクラウドネイティブなアプリケーションを扱う人にとって、オートスケールは必須な技術になってきました。
オートスケールを活用することで、アクセスが多くなったらサーバーを増やし、アクセスが収まってきたらサーバーを減らすなど、動的にサーバー数を変更できることで、機会損失を抑えるだけでなく、平常時の運用コストも小さく抑えることができるようになります。
OpenStackでオートスケールをいざ始めようと調べてみると、「OpenStackでオートスケールできます」の記事ばかりで、「どうやればできるのか。」「何が必要なのか。」の記載がほとんどありませんでした。
我々が実際にオートスケールを利用したOpenStackシステムを構築してきて得られた知見をもとに、「どうやればOpenStackでオートスケールができるのか」を解説したいと思います。
4部構成となっています。
オートスケールって何?
オートスケールを簡単に説明すると、仮想資源を監視し、負荷が高まったら仮想資源を増やす機能です。
AWSでは" Auto Scaling"に相当する機能です。
OpenStackでオートスケールを実現するためには、「リソース監視」+「オーケストレーション」の2つが必要です。
それぞれ以下のコンポーネントがこれらの役割を担当しています。
リソース監視:Ceilometer、Monasca
オーケストレーション:Heat
まずはそれぞれどのような機能なのかをサラッと解説します。
オーケストレーション
テンプレートにしたがって、クラウド環境上に仮想リソースを作成ならびに設定をする技術です。
図 1のような複雑な仮想システム構成や、ミドルウェア、サービスの配置を自動化することができます。

図 1 複雑な構成を作る前。 インターネットしかない状態。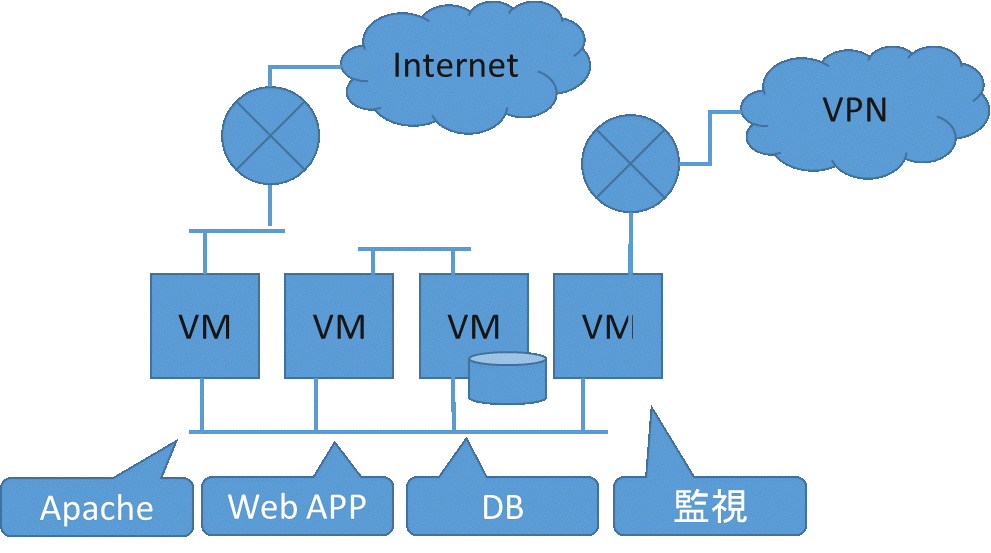 図 2 コマンド1個で環境構築。いろいろ作れた!
図 2 コマンド1個で環境構築。いろいろ作れた!
リソース監視
オートスケールに使える監視機能として、CeilometerとMonascaがあります。
これらが仮想マシンのCPUやメモリの使用率等をチェックし、閾値を超えたらアラートを上げます。このアラートを契機として、先ほどのオーケストレーション機能を呼び出すことで、オートスケールとなります。
コミュニティでは、OpenStackの監視機能としてMonascaの開発が進められていますが、まだ動作が不安定なところがあるので、今回はメータリング機能のCeilometerを使用します。Monascaになってもやることに大差ありません。
※Monasca検証中にバグを見つけたので、コミュニティにバグ報告と修正パッチを即日投稿しました。
(devstackのall-in-one環境を作るときに認証サーバからtokenを取れない問題)
オートスケールのパターン
基本的にはオーケストレーションで出来ることはオートスケール化することができますが、よくある例をピックアップしてみました。
例1)VMが1個だけ増える例。
チュートリアル的なものです。ただ増えるだけですが、基本を押さえているので汎用的に使えます。
たとえば、VMではなく仮想Volumeが増える場合も同じ方法です。
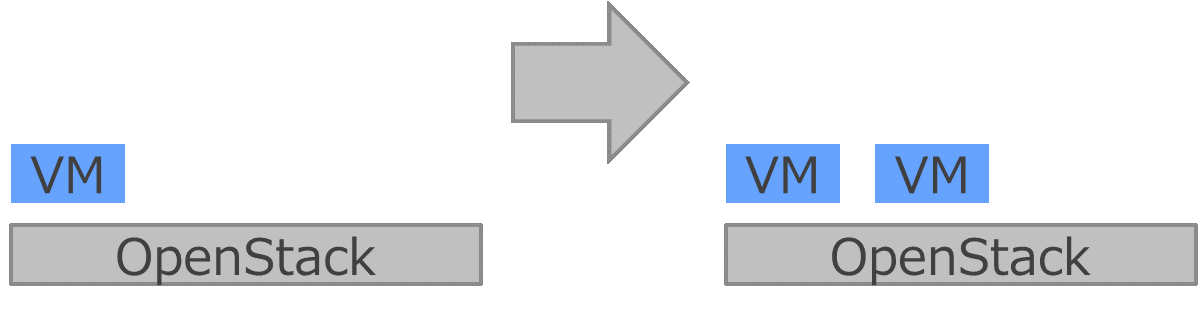
図 3 VMが1個増えるだけ
例2)neutron LBaaS ( Load Balancer as a Service)の配下にVMを増やしていく。
実用的なよくある例です。VMの負荷やコネクション数を契機にしてスケールアウトします。
LBが持っているIPにアクセスすればVM上のサービスに接続できるので、外からはスケールアウトされていることを意識することなく利用できます。
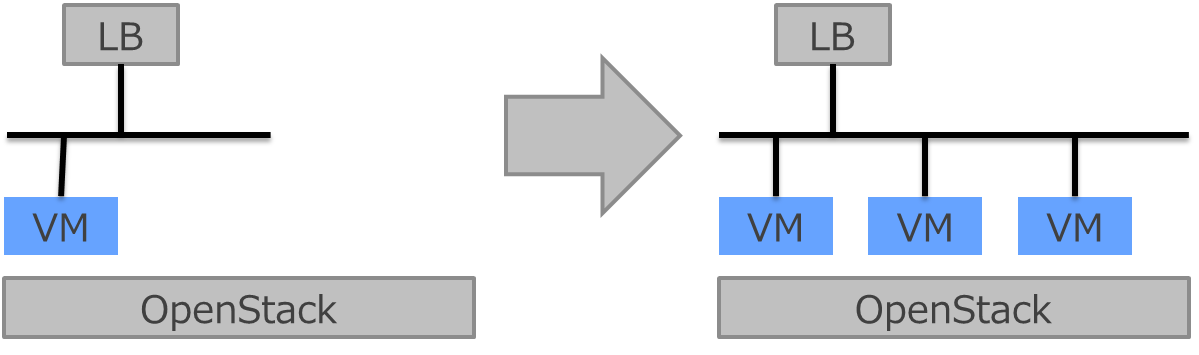
図 4 LB配下でスケールアウト
しかし、1点問題がありまして...。
オートスケール全般に言える話なのですが、スケールアウトするということは、スケールインもします。
スケールインの際に、実は誰かが利用している仮想リソースが消される場合もあります。
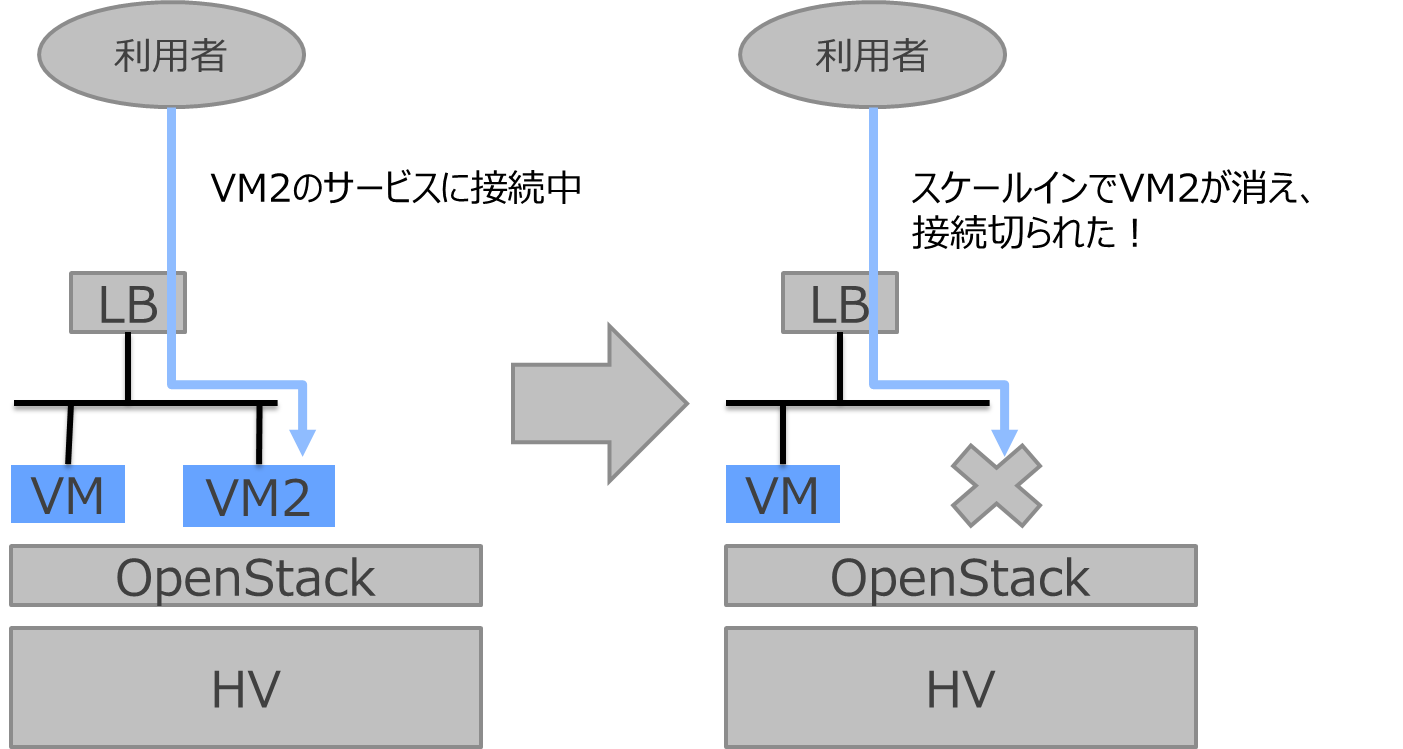
図 5 スケールインでコネクション切断
スケールアウトとスケールインのルールは同じである必要はないので、動かすアプリケーションの用途に合わせてルールを考えなければいけません。ここは扱うシステムに応じて考慮しましょう。
たとえば、
・ LB閉塞後、利用者がいなくなることを見越した一定時間後にスケールインさせる方法。
・ 別の監視システムと組み合わせて、利用者が資源を利用しなくなったら削除する方法。
・ アプリケーション自身がどの仮想資源を利用しているかを把握し、使わなくなったら削除する方法
などの仕組みを使って対処させると、利用者への影響を最小に押さえることができます。
オートスケールを考慮したシステム設計のお話
実際に動かし始める前に設計のお話を少しだけします。
オートスケールを考慮したシステム構成
オートスケールやスケールアウトを考慮した設計は、今までのオンプレミスの設計と異なります。
オンプレミスの場合は限られたサーバー台数の中でシステムを動かさないといけないので、1台のサーバー内に複数の機能が作られていたと思いますが、クラウドアプリケーションの場合はサーバー台数を意識する必要がない代わりに、1VM○円のコストが掛かります。
1VMになんでもかんでも突っ込むと、スケールアウトでVMを増やすときもそれ相応の大きさでVMを作らなければならないので、その分余計なコストが掛かってしまいます。
オートスケールを考慮した場合は、1VM1機能の単位に分割することで、負荷が高まっている機能だけピンポイントでスケールアウトさせることができ、無駄に大量の資源を消費することがなくなります。
CPUコア数やメモリ数で料金が変動する場合には、できるだけVM構成単位は小さくし、スケールアウトの際も最小単位で増やすことが出来れば、最適なコストで運用できます。
ただし、ここまで細かくすると今度はNWがボトルネックになってしまうので、実際にはもう少し1VMに複数機能を載せることになるでしょう。
もっと細かくするとコンテナのお話になってしまうのでそれはまた今度。
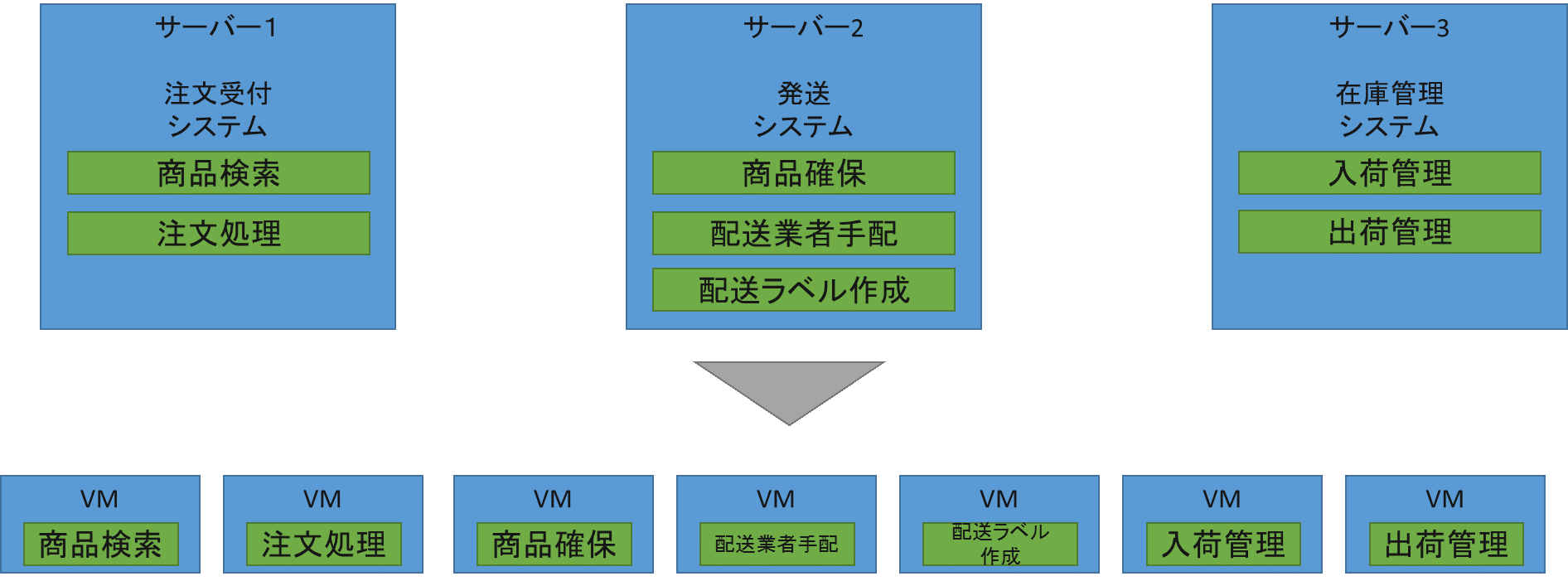
図 6 受注、発送、在庫管理システムの例 (上:オンプレミス 下:クラウド)
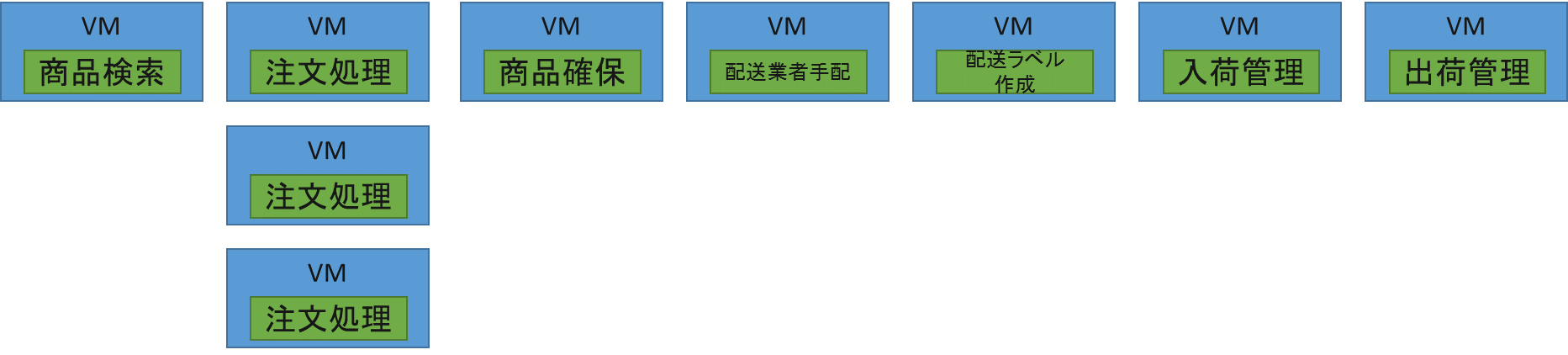
図 7 1機能だけスケールアウト
さいごに
今回は初回でしたので、オートスケールについての概説と設計方法について簡単にご紹介しました。OpenStack使ってみたい!導入したい!と思ってくれる人が増えてくれると嬉しいです。
次回はオーケストレーションをするためのHeat-Templateの書き方について解説します。
OpenStackの構築、運用にお悩みのかた
NTTテクノクロスでは、OpenStackを使ったプライベートクラウドの環境構築支援や、
遠隔保守/監視ソリューションを提供しています。
OpenStackの導入を検討している方、運用にお困りの方は、ぜひこちらからお問い合わせください。
NTTテクノクロスは、OpenStack Foundation や OpenStack コミュニティの関連会社ではなく、公認や出資も受けていません。
その他会社名、製品名などの固有名詞は、一般に該当する会社もしくは組織の商標または登録商標です。
掲載され次第リンクが繋がります



![]()