ロジカルレプリケーションで更新用DBと参照用DBを分離してみよう!
今回は、PostgreSQL 10で追加された機能を組み合わせて、ちょっと面白いPostgreSQLの使い方を紹介したいと思います。




ぬこのたのしいぽすぐれ教室 第4回
- 2018年01月25日公開
はじめに
みなさん、こんにちは。ぬこ@横浜です。
2018年も始まってしまいましたね。今更ですが、新年の挨拶です。
postgres=# SELECT tategaki('平成三十年 今年も宜しくお願いします',3,6);
tategaki
----------
お今平 +
願年成 +
いも三 +
し宜十 +
まし年 +
すく +
(1 row)
- tategaki関数についてはgithubを見てください

今年もこのブログで、PostgreSQLの楽しさを伝えていければと思っています。よろしくお願いします。
さて、今回は、PostgreSQL 10で追加された機能を組み合わせて、ちょっと面白いPostgreSQLの使い方を紹介したいと思います。

やってみること
今回の記事では、以下のPostgreSQL 10の機能を組み合わせてみようと思います。
- ロジカルレプリケーション
- 宣言パーティション
- libpqの複数接続先指定
まず、これらの機能の概要を説明します。
ロジカルレプリケーション
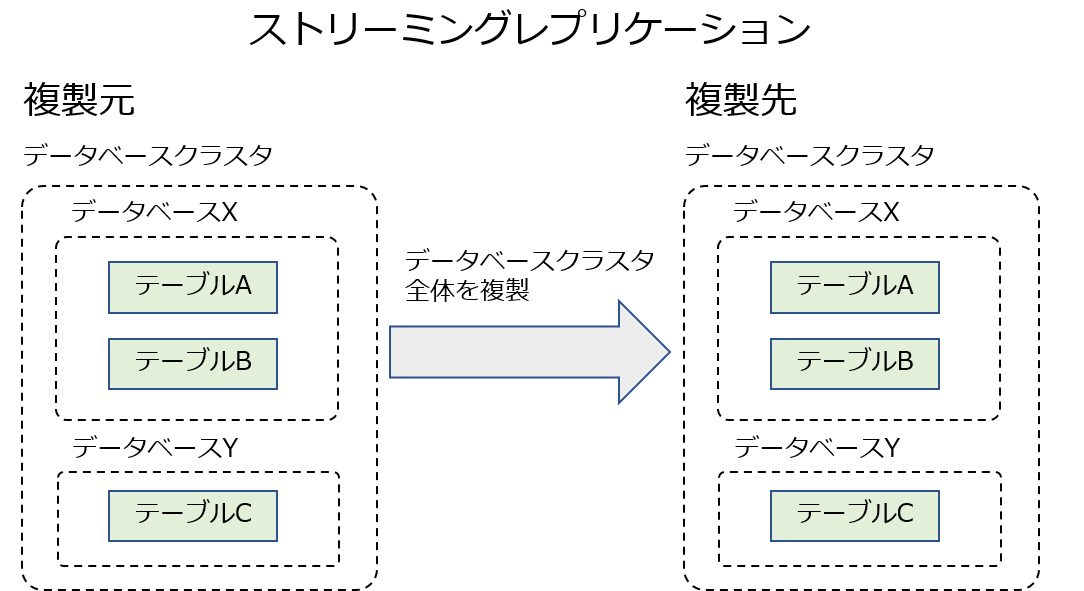
PostgreSQL 9.0からレプリケーション機能(ストリーミング・レプリケーション)はサポートされていましたが、PostgreSQL 10からはロジカルレプリケーションと呼ばれる、別方式のレプリケーションがサポートされました。
ロジカルレプリケーションとストリーミングレプリケーションは、同じレプリケーションという名前がついてはいますが、方式や用途は大きく異なります。
| 方式 | 対象となるデータ | 対象となる操作 | 主な用途 |
|---|---|---|---|
| ストリーミングレプリケーション | データベースクラスタ全体 | WAL(*)を出力する全ての操作 | 高可用化 |
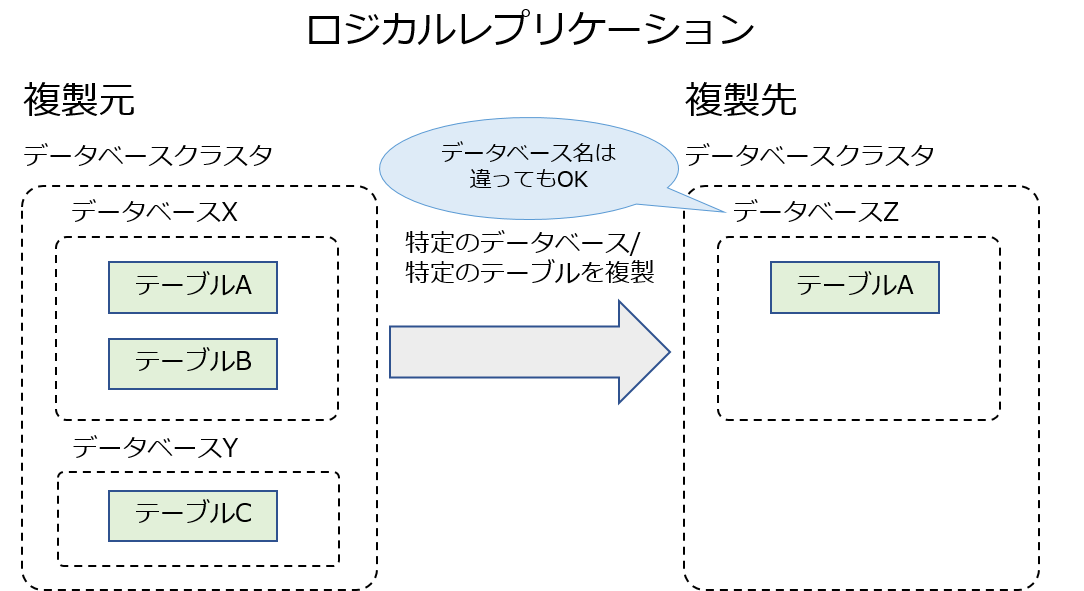
| ロジカルレプリケーション | 特定のテーブル | DML(INSERT/UPDATE/DELETE)のみ | 特定データのコピー |
(*) Write Ahead Log。更新操作を記録するログ。PostgreSQLの場合は、DMLだけでなく、DDL等もWALを出力します。
ロジカルレプリケーションは、特定のテーブルのみレプリケーションできることが一番の特徴になっています。
宣言パーティション
PostgreSQL 10からは非常に簡単にパーティションの指定が書けるようになったのと、INSERT処理が大幅に高速化されています。
詳細はこのブログ記事の第1回目「このパーティションがすごい!」に書いたので、そちらも見てください。
libpqの複数接続先指定
PostgreSQL 10の地味な改善ですが、クライアントライブラリlibpqで複数の接続先が指定できるようになりました。
libpqって何?
libpqというのは、PostgreSQLの基本となるクライアントライブラリで、C言語によって実装されています。「いまどき、C言語なんかでアプリケーションは組まないよ!」という人も多いとは思いますが、さまざまな言語(PHP, Ruby, Python, C++, etc...)のクライアントライブラリは、このlibpqを内部で利用しています(JDBCドライバは例外的にlibpqには依存していませんが)。
つまり、libpqの改善によって追加された機能は、今後、各種言語のクライアントライブラリにも取り込まれる可能性があるので、C言語以外の言語を使って、PostgreSQLへアクセスするアプリケーションを開発している人も、libpqの改善項目についてはWatchしておいて損はないと思います。
PostgreSQL 10での改善点
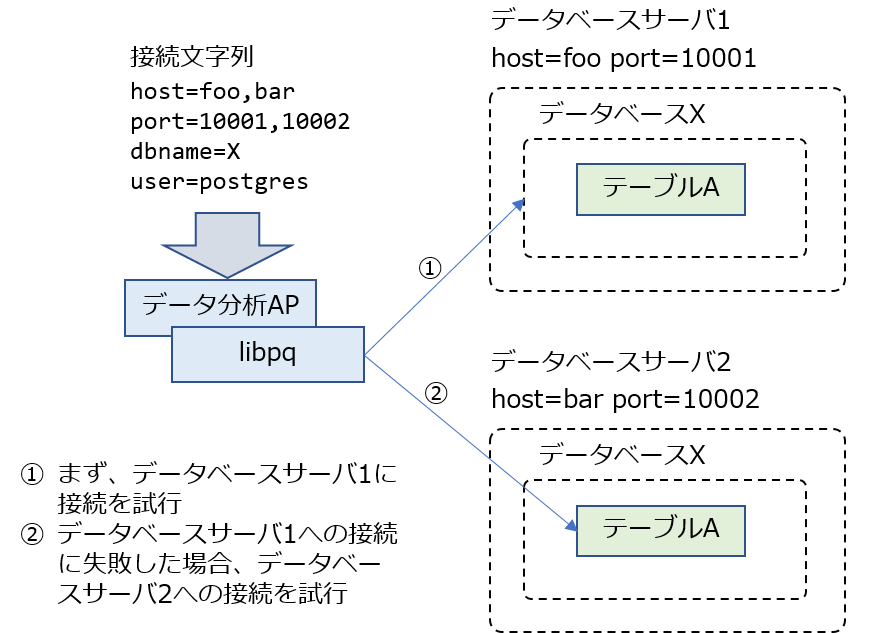
PostgreSQL 10からは、データベース接続時に与える接続文字列として、2つ以上のデータベースサーバの情報を指定できるようになりました。
複数のデータベースサーバの接続情報を記述した場合、libpqは記述順にデータベースサーバへの接続を試行します。接続試行の結果、正常に接続できた場合にはその接続を用いて、クエリを実行することができます。また、データベースサーバがダウンしていた場合には、次の接続情報をすぐに試行します。たとえば以下のような接続情報をlibpqに渡すことができます。
host=foo,bar port=10001,10002 dbname=X user=postgres
この例では、host(データベースサーバの名前)と、port(接続ポート)に対して、カンマ区切りで複数の接続情報を渡しています。
なお、複数の情報を渡せる接続情報は限定されており、PostgreSQL 10では、以下の3種類の情報のみです。
- host
- hostaddr
- port
dbnameやuserといった情報は複数指定することはできません。
この機能を使うことで、複数台のデータベースサーバに対して、アプリケーションから簡単に高可用性のあるアクセスが可能になります。
PostgreSQL 10機能の組み合わせ
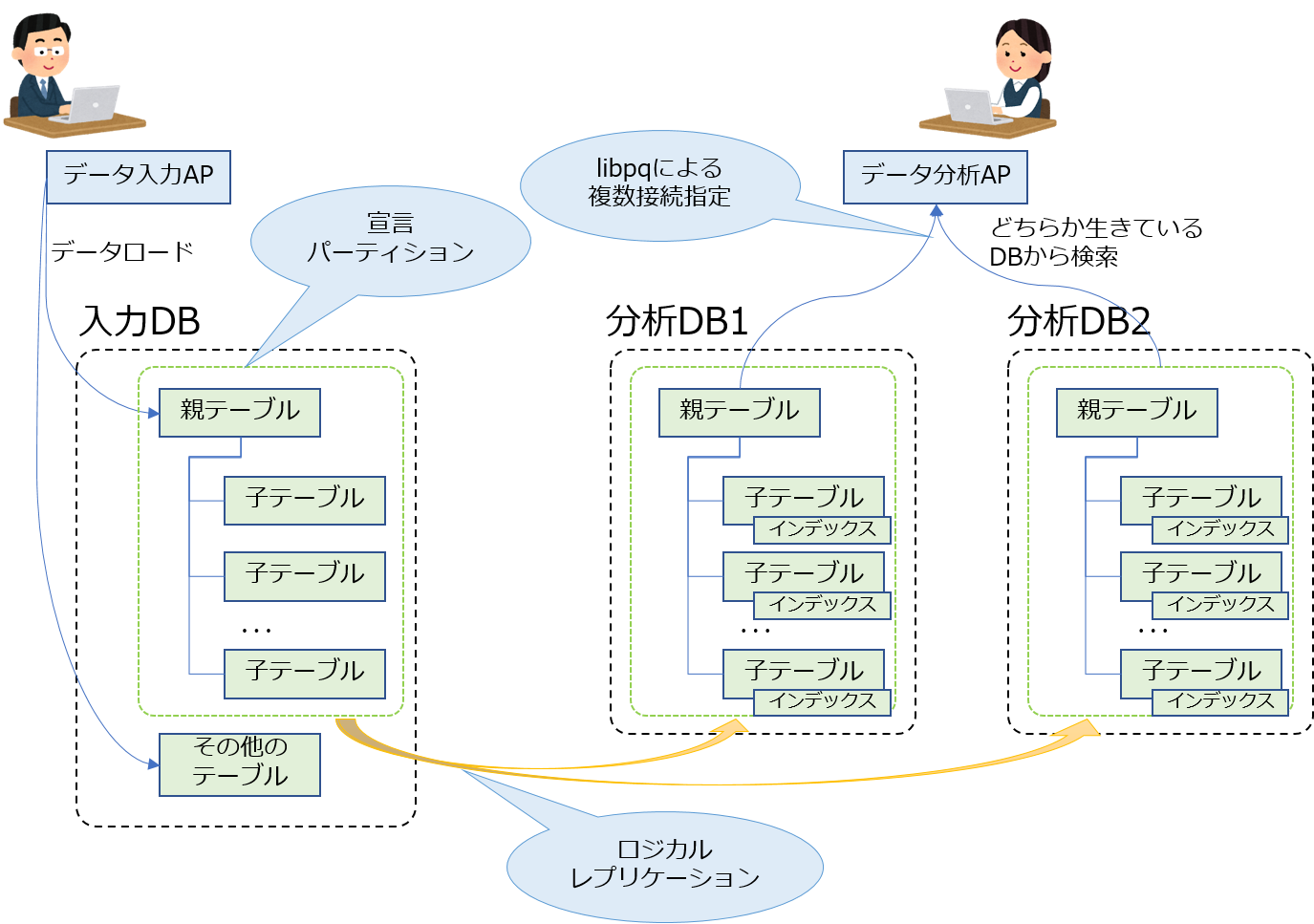
たとえば、データ登録業務と、データ分析業務があるシステムを構築する場合に、データ登録業務用のDBサーバ(入力DB)とデータ分析業務用のDBサーバ(分析DB)に分離するようなケースを想定してみます。このようなケースで、さきほど挙げたPostgreSQL 10新機能を組み合わせて適用してみましょう。
ロジカルレプリケーション
入力DBから分析DBへ「分析対象のテーブルのみ」を、PostgreSQL 10のロジカルレプリケーション機能を用いて複製します。
ロジカルレプリケーションでも、複製元:複製先 = 1:Nという構成を組むことはできます。今回は1つの入力DBに対して、2つの分析DBへ複製してみます。
また、ロジカルレプリケーションは、ストリーミングレプリケーションとは異なり、複製元/複製先の構造が完全で同一でなくてもかまいません。このため、ロジカルレプリケーションを使うと、以下のようなちょっと面白い定義が可能になります。
- (検索を行わない)複製元テーブルにはインデックスを設定しない。
- 複製元と複製先の間は非同期レプリケーションに設定しておく。
- 複製先にはインデックスを設定する。
こうすることで、データ入力時には、インデックス更新を不要にできるため、高速にデータを挿入し、データ分析時には、分析用に設定した任意のインデックスを使用できます(非同期レプリケーションなので、最新データでの分析が必須ではない、ということが前提になります)。
宣言パーティション
分析対象のテーブルが、パーティション化に向いたデータになっている(たとえば分析対象の地域などをパーティションキーに使える)なら、PostgreSQL 10の宣言パーティションを使って、簡単にパーティション構成を組むこともできます。
ただし、宣言パーティションとロジカルレプリケーションと組み合わせる場合には、いくつか注意が必要になります。詳しくは後ほど。
libpqの複数接続先指定
データ分析用APをlibpqを使って作成します。そしてデータ分析用APに与える、データベースへの接続文字列として、分析DB1と分析DB2の情報をまとめて与えてみます。
3機能の組み合わせ
さて、こんな感じで、PostgrerSQL 10新機能を3つ組み合わせてみました。
実際の動作例
データベースクラスタの作成と設定
今回は、1つのLinuxサーバ上にportを変更した3つのデータベースクラスタを実行させます。それぞれのhostnameとportは以下のように設定します。
| 目的 | hostname | port |
|---|---|---|
| 入力DB | localhost | 10000 |
| 分析DB1 | localhost | 10010 |
| 分析DB2 | localhost | 10020 |
initdbで作成したデータベースクラスタ内のpostgresql.confを修正して、port番号を上記のように変更しておきます。
また、今回はロジカルレプリケーションを使用するため、入力DB(port=10000)のデータベースクラスタの設定として、wal_level=logicalを設定する必要があります。それ以外はデフォルトの設定でOKです。
テーブルの作成
まず、psqlを使って入力DBに、パーティションテーブル(shop, shop_tokyo, shop_kanagawa, shop_chiba, shop_saitama)と、レプリケーション対象ではないダミーのテーブル(user)を作成します。
$ psql -e -p 10000 -U postgres ins_db -c "CREATE TABLE shop (id int, pref text, city text, name text) PARTITION BY LIST (pref)"
$ psql -e -p 10000 -U postgres ins_db -c "CREATE TABLE shop_tokyo PARTITION OF shop FOR VALUES IN ('東京')"
$ psql -e -p 10000 -U postgres ins_db -c "CREATE TABLE shop_kanagawa PARTITION OF shop FOR VALUES IN ('神奈川')"
$ psql -e -p 10000 -U postgres ins_db -c "CREATE TABLE shop_chiba PARTITION OF shop FOR VALUES IN ('千葉')"
$ psql -e -p 10000 -U postgres ins_db -c "CREATE TABLE shop_saitama PARTITION OF shop FOR VALUES IN ('埼玉')"
$ psql -e -p 10000 -U postgres ins_db -c "CREATE TABLE \"user\" (id int primary key, name text, gender text) -- dummy "
同様に、分析DB1と分析DB2に、同じ構成のパーティションテーブルとインデックスを作成します。
$ psql -e -p 10010 -U postgres ana_db -c "CREATE TABLE shop (id int, pref text, city text, name text) PARTITION BY LIST (pref)"
$ psql -e -p 10010 -U postgres ana_db -c "CREATE TABLE shop_tokyo PARTITION OF shop FOR VALUES IN ('東京')"
$ psql -e -p 10010 -U postgres ana_db -c "CREATE TABLE shop_kanagawa PARTITION OF shop FOR VALUES IN ('神奈川')"
$ psql -e -p 10010 -U postgres ana_db -c "CREATE TABLE shop_chiba PARTITION OF shop FOR VALUES IN ('千葉')"
$ psql -e -p 10010 -U postgres ana_db -c "CREATE TABLE shop_saitama PARTITION OF shop FOR VALUES IN ('埼玉')"
$ psql -e -p 10010 -U postgres ana_db -c "CREATE INDEX shop_tokyo_id ON shop_tokyo USING btree (id)"
$ psql -e -p 10010 -U postgres ana_db -c "CREATE INDEX shop_kanagawa_id ON shop_kanagawa USING btree (id)"
$ psql -e -p 10010 -U postgres ana_db -c "CREATE INDEX shop_chiba_id ON shop_chiba USING btree (id)"
$ psql -e -p 10010 -U postgres ana_db -c "CREATE INDEX shop_saitama_id ON shop_saitama USING btree (id)"
$ psql -e -p 10020 -U postgres ana_db -c "CREATE TABLE shop (id int, pref text, city text, name text) PARTITION BY LIST (pref)"
$ psql -e -p 10020 -U postgres ana_db -c "CREATE TABLE shop_tokyo PARTITION OF shop FOR VALUES IN ('東京')"
$ psql -e -p 10020 -U postgres ana_db -c "CREATE TABLE shop_kanagawa PARTITION OF shop FOR VALUES IN ('神奈川')"
$ psql -e -p 10020 -U postgres ana_db -c "CREATE TABLE shop_chiba PARTITION OF shop FOR VALUES IN ('千葉')"
$ psql -e -p 10020 -U postgres ana_db -c "CREATE TABLE shop_saitama PARTITION OF shop FOR VALUES IN ('埼玉')"
$ psql -e -p 10020 -U postgres ana_db -c "CREATE INDEX shop_tokyo_id ON shop_tokyo USING btree (id)"
$ psql -e -p 10020 -U postgres ana_db -c "CREATE INDEX shop_kanagawa_id ON shop_kanagawa USING btree (id)"
$ psql -e -p 10020 -U postgres ana_db -c "CREATE INDEX shop_chiba_id ON shop_chiba USING btree (id)"
$ psql -e -p 10020 -U postgres ana_db -c "CREATE INDEX shop_saitama_id ON shop_saitama USING btree (id)"
ロジカルレプリケーションの設定
次にロジカルレプリケーションを設定します。複製元になる入力DB側にはCREATE PUBLICATIONコマンドでパブリッシャー(配布者)を、複製先になる分析DB1と分析DB2には、CREATE SUBSCRIPTIONコマンドでサブスクライバ(購読者)を作成します。
パブリッシャーの作成
まず、パブリッシャを作成します。
psql -e -p 10000 -U postgres ins_db -c 'CREATE PUBLICATION ins_db_pub FOR TABLE shop'
CREATE PUBLICATION ins_db_pub FOR TABLE shop
ERROR: "shop" is a partitioned table
DETAIL: Adding partitioned tables to publications is not supported.
HINT: You can add the table partitions individually.
なんと!エラーになってしまうではないですか!

これは現時点での制約なのですが、ロジカルレプリケーションの複製元には、宣言パーティションテーブルの親テーブルは指定できません。
このため、宣言パーティションテーブルをロジカルレプリケーションで複製したい場合には、
FOR ALL TABLES指定で、データベース内のすべてのテーブルを対象とする。psql -e -p 10000 -U postgres ins_db -c "CREATE PUBLICATION ins_db_pub FOR ALL TABLES"- 末端の子テーブルを個々にレプリケーション対象として指定する
のどちらかを行う必要があります。今回はダミーのuserテーブルは複製対象にはしたくないので、2つ目の方式でパブリッシャーを作成します。
psql -e -p 10000 -U postgres ins_db -c "CREATE PUBLICATION ins_db_pub FOR TABLE shop_tokyo, shop_kanagawa, shop_chiba, shop_saitama"
サブスクライバの作成
パブリッシャーを作成したので、次は複製先の分析DB1と分析DB2でCREATE SUNSCRIPTIONコマンドを使って、サブスクライバを作成します。
$ psql -e -p 10010 -U postgres ana_db -c "CREATE SUBSCRIPTION ana01_sub CONNECTION 'dbname=ins_db port=10000 user=postgres' PUBLICATION ins_db_pub"
$ psql -e -p 10020 -U postgres ana_db -c "CREATE SUBSCRIPTION ana02_sub CONNECTION 'dbname=ins_db port=10000 user=postgres' PUBLICATION ins_db_pub"
データの入力
入力DBのshopテーブルに対して、以下のような2つのINSERT文でデータを登録します。2つ目のINSERT文はデータ量をかさ増しするためのダミーデータです。
$ psql -e -p 10000 -U postgres ins_db -c "INSERT INTO shop VALUES \
(1,'東京','品川区','○○家 品川店'), \
(2,'東京','立川市','△△軒'), \
(3,'神奈川','横浜市中区','○○家'), \
(4,'埼玉','さいたま市','麺屋□□□'), \
(5,'千葉','千葉市','ラーメン△□'), \
(6,'神奈川','相模原市中央区','ほげほげめん')"
$ psql -e -p 10000 -U postgres ins_db -c "INSERT INTO shop VALUES (generate_series(7, 100000), '東京', '港区', 'ダミー屋')"
こうして、100万件のデータを登録しておきます。すでにレプリケーション設定を済ましているので、分析DB1, 分析DB2にも入力データがレプリケーションされています。
件数の確認
この状態で、まずshopテーブルの件数を確認します。
$ psql -e -p 10000 -U postgres ins_db -c 'SELECT COUNT(*) FROM shop'
SELECT COUNT(*) FROM shop
count
--------
100000
(1 row)
$ psql -e -p 10010 -U postgres ana_db -c 'SELECT COUNT(*) FROM shop'
SELECT COUNT(*) FROM shop
count
--------
100000
(1 row)
$ psql -e -p 10020 -U postgres ana_db -c 'SELECT COUNT(*) FROM shop'
SELECT COUNT(*) FROM shop
count
--------
100000
(1 row)
無事にロジカルレプリケーションが成功したので、入力DB(port=10000)、分析DB1(port=10010)、分析DB2(port=10020)ともに、100万件のデータが登録されていることが確認できました。
インデックス検索
今回はサブスクライバ側の分析DB1, 分析DB2にのみ、id列に対するインデックスを設定しました。実際にインデックス検索が実行されるのか、実行計画をとって確認します。
$ psql -e -p 10010 -U postgres ana_db -c "EXPLAIN SELECT * FROM shop WHERE pref = '東京' AND id = 1"
QUERY PLAN
-------------------------------------------------------------------------------------
Append (cost=10.03..502.39 rows=1 width=100)
-> Bitmap Heap Scan on shop_tokyo (cost=10.03..502.39 rows=1 width=100)
Recheck Cond: (id = 1)
Filter: (pref = '東京'::text)
-> Bitmap Index Scan on shop_tokyo_id (cost=0.00..10.03 rows=232 width=0)
Index Cond: (id = 1)
(6 rows)
id列に設定したインデックスを使った実行計画になっていますね。
psql -e -p 10010 -U postgres ana_db -c "SELECT * FROM shop WHERE pref = '東京' AND id = 1"
id | pref | city | name
----+------+--------+-------------
1 | 東京 | 品川区 | ○○家 品川店
(1 row)
実際に検索もできました。
これで入力DB側にはインデックスを設定しないことで更新コストを下げ、分析DB側のみにインデックスを設定することで、分析時には高速な検索が可能になりました!

libpqへの複数接続指定
今回作成した構成では、分析DB1と分析DB2は入力DBから複製されているので、(多少の複製遅延による差異はあるものの)同じ内容のデータが格納されています。この2つのデータベースを使って、シンプルな高可用性をlibpqへの複数接続指定で実現してみます。
このためには、libpqを使ったアプリケーションをサンプルとして作成してみます。ソースコードをここに書くのは長すぎるので、ソースコードについては、昨年、私がPostgreSQL Advent Calenderで書いた記事(libpqで複数の接続先を指定)に書いたものを使います。
このlibpqサンプルアプリケーション(libpq-sample)は、接続文字列と任意のSELECT文を受け取ります。そしてデータベースに接続後、最初に接続したサーバのport番号を出力し、その後にSELECT文を実行してその結果を表示するという簡単なものです。最初のport番号で、どちらのデータベースに接続したのかを判断します。
今の状態では、3つのデータベースサーバ(入力DB、分析DB1、分析DB2)が起動しています。
$ ps -ef | grep "postgres -D"
hara-t 6761 1 0 13:57 pts/0 00:00:00 /home/hara-t/pgsql/pgsql-10/bin/postgres -D /home/hara-t/pgdata/ins
hara-t 6773 1 0 13:57 pts/0 00:00:00 /home/hara-t/pgsql/pgsql-10/bin/postgres -D /home/hara-t/pgdata/ana01
hara-t 6784 1 0 13:57 pts/0 00:00:00 /home/hara-t/pgsql/pgsql-10/bin/postgres -D /home/hara-t/pgdata/ana02
hara-t 9078 29607 0 14:33 pts/0 00:00:00 grep --color=auto postgres -D
この状態で、libpq-sampeを以下のように実行すると、port=10010側のデータベースサーバ(分析DB1)に接続してクエリを実行します。
$ ./libpq-sample "host=localhost,localhost port=10010,10020 dbname=ana_db user=postgres" "SELECT * FROM shop WHERE pref = '東京' AND id = 1"
port=10010
id pref city name
1 東京 品川区 ○○家 品川店
次に、port=10010側のデータベースサーバ(分析DB1)を停止させて、さきほどと同じパラメータでlibpq-sampleを実行します。
$ pg_ctl stop -D ~/pgdata/ana01
waiting for server to shut down.... done
server stopped
$ ./libpq-sample "host=localhost,localhost port=10010,10020 dbname=ana_db user=postgres" "SELECT * FROM shop WHERE pref = '東京' AND id = 1"
port=10020
id pref city name
1 東京 品川区 ○○家 品川店
すると、port=10020側のデータベースサーバ(分析DB2)に接続し、クエリを実行します。
なお、port=10020側のデータベースサーバ(分析DB2)も停止させると、全ての接続先への接続に失敗するため接続エラーになります。
$ pg_ctl stop -D ~/pgdata/ana02
waiting for server to shut down.... done
server stopped
$ ./libpq-sample "host=localhost,localhost port=10010,10020 dbname=ana_db user=postgres" "SELECT * FROM shop WHERE pref = '東京' AND id = 1"
Connection to database failed: conninfo=host=localhost,localhost port=10010,10020 dbname=ana_db user=postgres, message=could not connect to server: Connection refused
Is the server running on host "localhost" (::1) and accepting
TCP/IP connections on port 10010?
could not connect to server: Connection refused
Is the server running on host "localhost" (127.0.0.1) and accepting
TCP/IP connections on port 10010?
could not connect to server: Connection refused
Is the server running on host "localhost" (::1) and accepting
TCP/IP connections on port 10020?
could not connect to server: Connection refused
Is the server running on host "localhost" (127.0.0.1) and accepting
TCP/IP connections on port 10020?
この機能を使うことで、どちらかの分析DBサーバが生きていれば、検索自体は可能になるという構成が実現できます。
停止した分析DBサーバについては、再起動後にレプリケーションを再開して入力DB側と同期を開始します。レプリケーションが追いついた時点で、論理的にはもう片方の分析DBサーバと同一の内容となります。
おわりに
今回はPostgreSQL 10の新機能を組み合わせて、今までのPostgreSQLではできなかった構成で動かしてみました。
PostgreSQL 10の新機能は、もちろんこれだけではないので、興味がある方は以下に挙げている参考情報を読んだり、実際に動かしたりして楽しんでください!
参考情報
- PostgreSQL 10リリースノート
- 公式文書です。日本語版ももう少しで出てくると思います。
- 「篠田の虎の巻」 第7弾 『PostgreSQL10 beta1 検証結果』
- 日本ヒューレットパッカード篠田様による技術文書。beta1のころの調査結果です。
- PostgreSQL10徹底解説(スライド資料)
- NTT OSSセンタ澤田様によるOSC北海道での発表資料です。
- 次期バージョン PostgreSQL 10 の 新機能とその後の方向性
- SRA OSS, Inc. 長田様のJPUG勉強会での発表資料です。
- PostgreSQL 10全部ぬこ Advent Calendar 2017
- 昨年12月に私が書いたAdvent Calenderです。
- PostgreSQL 10のマイナーな機能や改善項目について書いています。
NTTテクノクロスでは、OracleからPostgreSQLへの移行や、運用支援のサービスを提供しています。



PostgreSQLに関わる仕事をしつつ、社内のPostgreSQLの問い合わせにカジュアルに対応。 「ぬこ@横浜」の名前で国内のデータベース関連のイベントでも喋っています。PostgreSQLの変な使い方を考えるのが趣味。 著書に『内部構造から学ぶPostgreSQL 設計・運用計画の鉄則』(技術評論社/共著)。 最近の自己紹介は「『PostgreSQL ラーメン』でググってください」
![]()