PostgreSQL 10の宣言的パーティション
PostgreSQL 10には様々な機能が新たに取り込まれる予定です。 このうち自分がとても注目している機能である「宣言的パーティション」について紹介したいと思います。




ぬこのたのしいぽすぐれ教室 第1回
- 2017年10月05日公開
PostgreSQL 10の宣言的パーティション
はじめに
みなさん、こんにちは。NTTテクノクロスの原田と申します。 今回から、弊社のblogにオープンソースデータベースのPostgreSQLに関する記事を書くことになりました。よろしくお願いします。
こんなblogも書いたりしていることから想像できると思いますが、会社ではPostgreSQLに関わる仕事をしています。 また、仕事とは別に「ぬこ@横浜」の名前で変な拡張機能を作っていたり、国内のPostgreSQL関連のイベントで時々話していたりします。もしかすると、今、この記事を読んでいる中には、PostgreSQL関連のイベントで顔を合わせた方もいるかもしれませんね。
PostgreSQL 10がやってくる!
記事作成の依頼を受けて、何を書こうかと少し考えたのですが、今の旬の話題といえば、やっぱり2017/10/5にリリース予定のPostgreSQLの新バージョン、PostgreSQL 10だと思います。なので、今回の記事もPostgreSQL 10をネタに書いてみたいと思います。
PostgreSQL 10は昨年の秋から開発が始まりました。 新機能のソースコードのパッチ、ドキュメントを開発者が提示し、その機能に問題がないのかを開発者用MLリスト内でレビューしながら開発を進め、今年の5月にbeta1、7月にbeta2が公開されました。 この記事を書いている現在ではRC1まで公開されています。そして、いよいよ10/5にPostgreSQL 10.0(正式版)がリリースされる予定です。
PostgreSQL 10には様々な機能が新たに取り込まれる予定です。 主に注目されている機能として
- ロジカルレプリケーション
- 宣言的パーティション
- パラレルクエリの改善
といった機能が挙げられています。 今回は、このうち自分がとても注目している機能である「宣言的パーティション」について紹介したいと思います。
PostgreSQLのパーティション
1つの巨大なテーブルを、複数の小さなテーブル(パーティションテーブル)に分割する技法をパーティショニングといいます。別の言い方ではテーブルの水平分割と呼んだりもしますね。
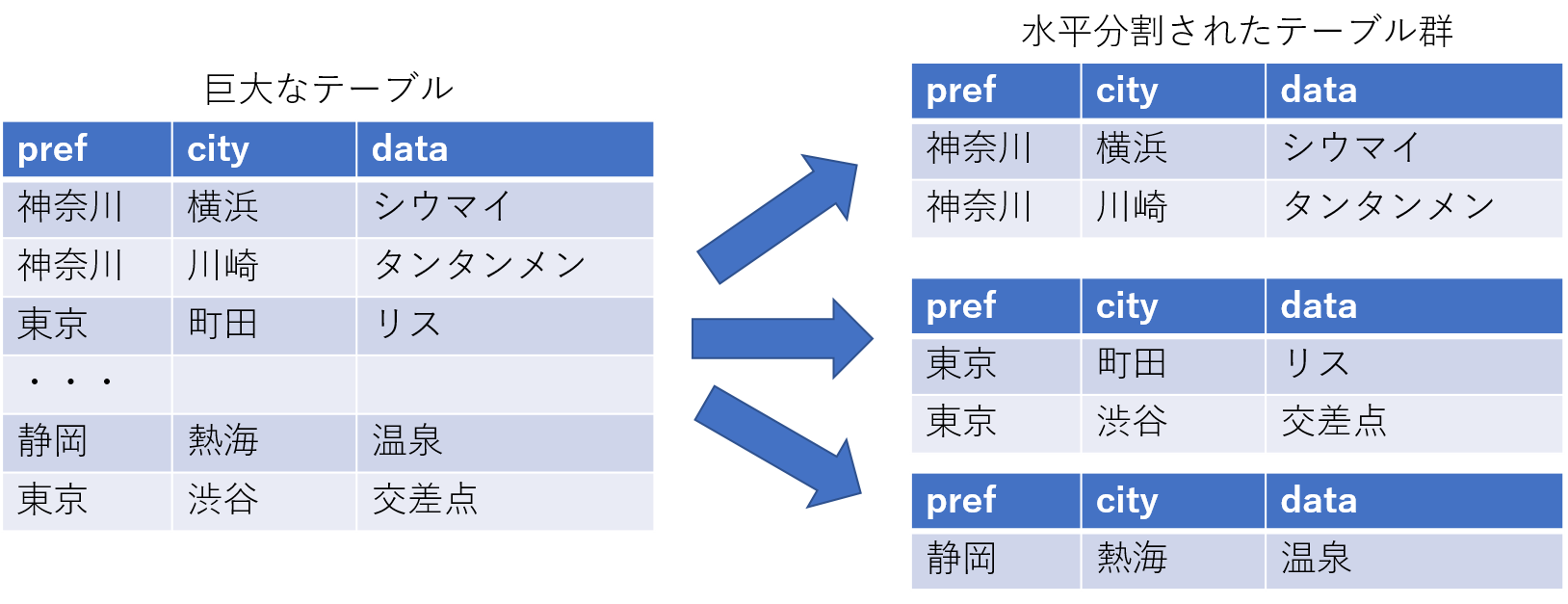
以前から商用のDBMSではパーティショニングの対応はされていました。 「PostgreSQLでもパーティショニングって以前から対応していたのでは?」と思う人も多いかと思いますが、PostgreSQLの場合は、パーティショニング専用の機能があったわけではなく、様々なPostgreSQL機能を組み合わせて、なんとかパーティショニングを実現していました。このため、PostgreSQLのパーティションというのはPostgreSQLにある程度慣れている人であっても面倒くさいという印象がありました。
また、OracleやDB2などの商用DBMSではパーティションの構築はもっとスマートにできるというのもあるので、商用DBMSに慣れている人から見ると、PostgreSQLのパーティションというのは難解なものに思えたのではないでしょうか。
以下、今までのパーティション化の実現手順と、PostgreSQL 10の宣言的パーティション機能を使ったパーティショニングの実現手順を比較してみたいと思います。
これまでのパーティション
PostgreSQL 9.6までは以下の手順でパーティションを構築します。
- 親となるテーブルを作成する。
- 親テーブルを継承した子テーブルをパーティション数分作成する。
- 挿入されたレコードを子テーブルに振り分けるためのトリガ関数を作成する。
- 作成したトリガ関数を利用するトリガ定義を親テーブルに設定する。
以下のようなパーティション(リストパーティション)の例を用いて具体的な手順を示します。
- テーブルとして、都道府県、市群、その他データ(簡易化のためダミーの列を1つ)を持つテーブルを想定します。
- パーティションを分割するキーとして、都道府県を使います。
- また、今回は説明を簡単にするため、都道府県のバリエーションとして、神奈川県、東京都、山梨県、静岡県を対象とします。
図にするとこんな感じですね。

このパーティションを従来の方式で構築しようとすると、こんな感じになります。
-- 親テーブルの定義
CREATE TABLE japan (
pref text,
city text,
data text
);
-- 子テーブル群の定義
CREATE TABLE kanagawa (
CHECK (pref IN ('神奈川'))
) INHERITS (japan);
CREATE TABLE tokyo (
CHECK (pref IN ('東京'))
) INHERITS (japan);
CREATE TABLE yamanashi (
CHECK (pref IN ('山梨'))
) INHERITS (japan);
CREATE TABLE shizuoka (
CHECK (pref IN ('静岡'))
) INHERITS (japan);
-- トリガ関数の定義
CREATE OR REPLACE FUNCTION pref_insert_trigger_func()
RETURNS TRIGGER AS $$
BEGIN
IF ( NEW.pref = '東京') THEN
INSERT INTO tokyo VALUES (NEW.*);
ELSIF ( NEW.pref = '神奈川') THEN
INSERT INTO kanagawa VALUES (NEW.*);
ELSIF ( NEW.pref = '山梨') THEN
INSERT INTO yamanashi VALUES (NEW.*);
ELSIF ( NEW.pref = '静岡') THEN
INSERT INTO shizuoka VALUES (NEW.*);
ELSE
RAISE EXCEPTION 'Data out of range. Fix the pref_insert_trigger()';
END IF;
RETURN NULL;
END;
$$
LANGUAGE plpgsql;
-- 親テーブルに対するトリガ定義
CREATE TRIGGER pref_insert_trigger
BEFORE INSERT ON japan
FOR EACH ROW EXECUTE PROCEDURE pref_insert_trigger_func();
見てもらえばわかると思いますが、子テーブルへの振り分けを行う、トリガ関数の作成が何気に面倒くさいです。また、パーティションが増える(他の都道府県用の子テーブルが増える)ときに、トリガ関数の変更がかかるということも想像できます。

また、トリガ関数内で振り分けの規則をIF文で定義していますが、
IF ( NEW.pref = '神奈川') THEN
INSERT INTO tokyo VALUES (NEW.*);
ELSIF ( NEW.pref = '神奈川') THEN
INSERT INTO kanagawa VALUES (NEW.*);
のような間違った定義(パーティションキーに「神奈川」を設定してもtokyoテーブルに振り分けられてしまう)を記述しても、文法的にエラーになるわけではないので、定義自体は正常となり、実際にデータを挿入すると「あれれ?」ということになってしまうこともあります。
つまり、これまでの方式でもパーティションを構築することはできますが、
- 構築が面倒
- メンテナンスも面倒
- 定義のミスが検出しにくい
という問題があったわけです。
新しい宣言的パーティション
こうしたパーティション構築に関する面倒さを大きく改善するために、PostgreSQL 10から「宣言的パーティション」という方式でパーティションが構築できるようになりました。
ざっくり言ってしまうと、宣言的パーティションでは、CREATE TABLE文のみでパーティションが構築可能になります。面倒なトリガ関数の作成やトリガ定義とはおさらばです!
宣言的パーティションの定義
PostgreSQL 10ではCREATE TABLE文に、PARTITION BY 構文(親テーブル用)とPARTITION OF構文(子テーブル用)が追加されました。以下、同じ構成のパーティションをPostgreSQL 10で構築する例を示します。
-- 親テーブルの定義
CREATE TABLE japan (
pref text,
city text,
data text
)
PARTITION BY LIST (pref);
-- 子テーブル群の定義
CREATE TABLE kanagawa PARTITION OF japan
FOR VALUES IN ('神奈川');
CREATE TABLE tokyo PARTITION OF japan
FOR VALUES IN ('東京');
CREATE TABLE yamanashi PARTITION OF japan
FOR VALUES IN ('山梨');
CREATE TABLE shizuoka PARTITION OF japan
FOR VALUES IN ('静岡');
PostgreSQL 9.6までのパーティション構築と比較すると、ずいぶんシンプルになったことがわかると思います。

パーティションテーブルへの挿入
定義ができたので、パーティションの親テーブル(japan)に以下のようなデータを挿入します。
INSERT INTO japan VALUES ('神奈川', '横浜', 'シウマイ');
INSERT INTO japan VALUES ('神奈川', '川崎', 'タンタンメン');
INSERT INTO japan VALUES ('東京', '町田', 'リス');
INSERT INTO japan VALUES ('千葉', '船橋', 'ソースラーメン'); -- 制約違反になる
最初の3つのINSERTは成功しますが、最後の4つ目のINSERTは、以下のような制約違反のエラーとなり挿入できません。
ERROR: no partition of relation "japan" found for row
DETAIL: Partition key of the failing row contains (pref) = (千葉).
これは子テーブル定義のFOR VALUES IN句に該当する値が存在しないためです。
パーティションテーブルの参照
無事にデータの挿入ができたので、japanテーブルを参照してみましょう。
part=# SELECT * FROM japan;
pref | city | data
--------+------+--------------
神奈川 | 横浜 | シウマイ
神奈川 | 川崎 | タンタンメン
東京 | 町田 | リス
(3 rows)
親テーブルからの参照も問題なくできますね。
このときの実行計画を見ると、
part=# EXPLAIN SELECT * FROM japan;
QUERY PLAN
-------------------------------------------------------------------
Append (cost=0.00..66.00 rows=2600 width=96)
-> Seq Scan on kanagawa (cost=0.00..16.50 rows=650 width=96)
-> Seq Scan on tokyo (cost=0.00..16.50 rows=650 width=96)
-> Seq Scan on yamanashi (cost=0.00..16.50 rows=650 width=96)
-> Seq Scan on shizuoka (cost=0.00..16.50 rows=650 width=96)
(5 rows)
japanテーブルの全ての子テーブル(kanagawa, tokyo, yamanashi, shizuoka)に対して検索をおこない、その結果をマージ(append)していることがわかります。
では、パーティションキーに「神奈川」を指定した条件を追加した場合はどうなるかというと、子テーブルのうちkanagawaテーブルからのみ検索するようになります。
part=# EXPLAIN SELECT * FROM japan WHERE pref = '神奈川';
QUERY PLAN
----------------------------------------------------------------
Append (cost=0.00..18.12 rows=3 width=96)
-> Seq Scan on kanagawa (cost=0.00..18.12 rows=3 width=96)
Filter: (pref = '神奈川'::text)
(3 rows)
この動作を「パーティーション・プルーニング」と呼びます。条件に合致するパーティションのみを検索対象とするので、無駄のない検索が可能になります。
パーティションテーブルの切り離しと組み込み
宣言的パーティションでは、ALTER TABLE文のオプション指定により、パーティションの切り離し(DETACH)や組み込み(ATTACH)が可能になりました。切り離しや組み込みによって、パーティションテーブルの内容を削除することなく、そのパーティションへの挿入を抑止することができます。
ALTER TABLEコマンドでtokyoテーブルをDETACHすると、japanテーブルを検索したときに、pref列が東京のデータは検索されなくなります。
part=# SELECT * FROM japan;
pref | city | data
--------+------+--------------
神奈川 | 横浜 | シウマイ
神奈川 | 川崎 | タンタンメン
東京 | 町田 | リス
(3 rows)
part=# ALTER TABLE japan DETACH PARTITION tokyo ;
ALTER TABLE
part=# SELECT * FROM japan;
pref | city | data
--------+------+--------------
神奈川 | 横浜 | シウマイ
神奈川 | 川崎 | タンタンメン
(2 rows)
切り離されたテーブルはALTER TABLEで組み込むことができます。組み込む場合には、テーブル名と、そのテーブルに振り分けるための条件を書きます。
part=# ALTER TABLE japan ATTACH PARTITION tokyo FOR VALUES IN ('東京');
ALTER TABLE
part=# SELECT * FROM japan;
pref | city | data
--------+------+--------------
神奈川 | 横浜 | シウマイ
神奈川 | 川崎 | タンタンメン
東京 | 町田 | リス
(3 rows)
組み込みが終わると、japanテーブルを検索したときにtokyoテーブルの内容が検索対象となります。
この機能は、特定パーティションの子テーブルのみTRUNCATEする前にDETACHしておいたり、特定の子テーブルをDETACHしてCLUSTER(表の再編成)を実施して再度組み込み(ATTACH)をかける、子テーブルへの振り分け条件を変更する、などの運用で役に立つのではないかと思います。
宣言的パーティションのここが凄い!
ここまで宣言的パーティションの概要を説明しました。改めて従来のパーティション方式と宣言的パーティションの違いについてまとめます。
パーティションの構築が簡単!
前に説明した実現手順を比べてもわかるとおり、PostgreSQL 10の宣言的パーティションはとても簡単にテーブルのパーティショニングができるようになりました。記述量が少なくなったのも勿論ですが、直感的に構築できるという点も重要です。
そして、個人的にはパーティショニングのためにトリガ関数を作成しなくても済むようになったのが、とても嬉しいですね。 トリガ関数自体は、そこまで作成が難しいものではないですが、関数を作るということは、その関数のデバッグも必要になります。また、パーティションの構成を変更する(パーティションを追加するなど)ときにも、トリガ関数の修正が必要になってきます。
パーティションテーブルへの振り分け規則を定義時にチェックしてくれる!
先ほどのトリガ関数とも関連しますが、従来の方式では子テーブルへの振り分け規則を、トリガ関数内で記述する必要がありました。
しかし、人間は過ちを犯す生き物。トリガ関数を作成するときに、矛盾する条件式を書いてしまうこともあります。文法上は間違ってはいないので、実際に親テーブルにデータを挿入するときに、本来格納されるべき子テーブルにデータが入らないという、面倒なバグの原因にもなります。
宣言的パーティションでは、トリガ関数内に書く振り分け条件相当を、CREATE TABLE文のPARTITION OF構文に書きます。この振り分け条件値が重複したり範囲が重なるような場合には、定義の時点でエラーにしてくれます。地味にこのチェックも嬉しいところです。
たとえば、以下のような振り分け条件が重複した定義(神奈川という値が重複する)をした場合、
CREATE TABLE kanagawa PARTITION OF japan
FOR VALUES IN ('神奈川');
CREATE TABLE tokyo PARTITION OF japan
FOR VALUES IN ('神奈川');
2つ目の子テーブルに対するCREATE TABLE文の実行時にエラーにすることで、定義の誤りを早期に検知することができます。
ERROR: partition "tokyo" would overlap partition "kanagawa"
パーティションテーブルの構成が把握しやすい!
従来方式でのパーティション方式でも、継承関係による定義をしているため、どのテーブルの子テーブルは何か、という情報をpsqlの \d+ メタコマンドで見ることはできました。
part=# \d+ japan
Table "public.japan"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------+------+-----------+----------+---------+----------+--------------+-------------
pref | text | | | | extended | |
city | text | | | | extended | |
data | text | | | | extended | |
Triggers:
pref_insert_trigger BEFORE INSERT ON japan FOR EACH ROW EXECUTE PROCEDURE pref_insert_trigger_func()
Child tables: kanagawa,
shizuoka,
tokyo,
yamanashi
part=# \d+ kanagawa
Table "public.kanagawa"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------+------+-----------+----------+---------+----------+--------------+-------------
pref | text | | | | extended | |
city | text | | | | extended | |
data | text | | | | extended | |
Check constraints:
"kanagawa_pref_check" CHECK (pref = '神奈川'::text)
Inherits: japan
親テーブルの定義を参照すると、どんな子テーブルをもっているかまでは表示してくれますが、その子テーブルへの振り分け条件まで確認することはできません。また、子テーブルのチェック制約は参照可能ですが、子テーブルへの振り分け条件は、トリガ関数を別途確認する必要があります。
PostgreSQL 10の宣言的パーティションで構築した場合、psqlから \d+ コマンドを実行することで、親テーブルの定義情報に加え、どの子テーブルには、どの値で振り分けられるのかを一目で確認できます。
part=# \d+ japan
Table "public.japan"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------+------+-----------+----------+---------+----------+--------------+-------------
pref | text | | | | extended | |
city | text | | | | extended | |
data | text | | | | extended | |
Partition key: LIST (pref)
Partitions: kanagawa FOR VALUES IN ('神奈川'),
shizuoka FOR VALUES IN ('静岡'),
tokyo FOR VALUES IN ('東京'),
yamanashi FOR VALUES IN ('山梨')
この例では、prefに「神奈川」という値が設定されたら、kanagawa というパーティションテーブルに振り分けられ、「東京」という値が設定されたら、tokyo というパーティションテーブルに振り分けられる、といった情報が表示されています。構築したパーティション定義が正しいのか確認しやすくなりましたね!
挿入が高速!
宣言的パーティションの重要なメリットとして、挿入の速度がトリガ方式と比較すると、抜群に向上していることが挙げられます。
上記のリストパーティションに対して、100万件のデータをロードする時間を、従来のトリガ方式と、宣言的パーティション方式で測定して比較してみました(3回測定した平均値)
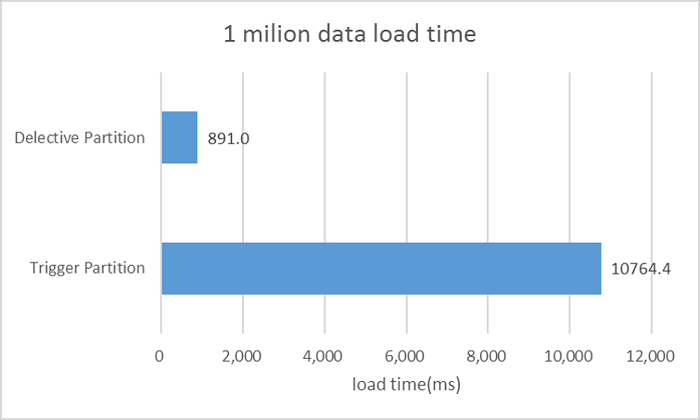
なんと、トリガ方式と比較すると、10倍以上ロード時間が向上しています。

宣言的パーティションのここに注意!
とっても便利な宣言的パーティションなのですが、PostgreSQL 10ではいくつかの制約事項があります。
親テーブルにはPrimary Keyが設定できない
現状、宣言的パーティション(PARTITION BY構文をもつCREATE TABLE文)をもつテーブルにPrimary Keyを設定することはできません。
たとえば、以下のようなパーティションテーブルを定義しようとすると、
CREATE TABLE japan (
id int primary key,
pref text,
city text,
data text
)
PARTITION BY LIST (pref);
以下のように、パーティションテーブルに対するprimary keyはサポートしていないというエラーになります。
ERROR: primary key constraints are not supported on partitioned tables
新規にパーティションテーブルを作成するときには、あまり気にしなくてもいいと思いますが、既存のテーブルをパーティション化しようとする場合には、そのテーブルにPrimary keyがないか注意する必要があります。
親テーブルにはインデックスが設定できない
また、親テーブルにはインデックスを設定することはできません。
以下のようにパーティションテーブルに対してインデックスを設定しようとすると、
CREATE TABLE japan (
id int,
pref text,
city text,
data text
)
PARTITION BY LIST (pref);
CREATE INDEX japan_id_idx ON japan (id);
パーティションテーブルにはインデックスを作成できないというエラーになります。
ERROR: cannot create index on partitioned table "japan"
なお、子テーブルに対してはとくにその制約はありません。
CREATE TABLE japan (
id int,
pref text,
city text,
data text
)
PARTITION BY LIST (pref);
CREATE TABLE kanagawa PARTITION OF japan
FOR VALUES IN ('神奈川');
CREATE INDEX kanagawa_id_idx ON kanagawa(id);
子テーブルに対してインデックスを設定することは可能です。
なので、個人的には親テーブルに対してCREATE INDEXを設定したら、親テーブルへのインデックスは作成しないけど、子にはインデックス作成の命令を伝播して、子テーブルに自動的にインデックスを作成してくれれば良いのになあ、とは思っています(この機能の主実装者である、Amit Langoteさんと会う機会があったので、この改善要望を伝えておきました)。
パーティションをまたがるUPDATEはできない
パーティションキーを変更するようなUPDATEはエラーになります。
たとえば、以下のようなデータが格納されていると想定します。
part=# SELECT * FROM japan ;
id | pref | city | data
----+--------+------+--------------
1 | 神奈川 | 横浜 | シウマイ
2 | 神奈川 | 川崎 | タンタンメン
3 | 東京 | 町田 | リス
(3 rows)
id = 3 のレコードのprefを神奈川に変更するために以下のようなUPDATE文
UPDATE japan SET pref = '神奈川' WHERE id = 3;
を発行するとエラーになります。
ERROR: new row for relation "tokyo" violates partition constraint
DETAIL: Failing row contains (3, 神奈川, 町田, リス).
これは、町田が神奈川じゃないから・・・ではなく、UPDATE文の背景で、tokyoテーブルに対してprefが神奈川のデータを挿入しようとして制約違反になってしまうためです。
通例、パーティションキーを変更して別のパーティションに移動したいという更新を行うことは少ないとは思いますが、このようにUPDATE文ではうまく更新できません。こうした更新を行うためには、DELETE文とINSERT文を組み合わせる必要があります。
BEGIN;
DELETE FROM japan WHERE id = 3;
INSERT INTO japan VALUES (3, '神奈川', '町田', 'リス');
COMMIT;
シンプルにDELETE文とINSERT文を順次実行してもいいですが、PostgreSQLの場合、DELETE文のRETURNING句とINSERT文を組み合わせて、1つのSQL文で実行することもできます。
WITH tmp AS
(DELETE FROM japan WHERE id = 3
RETURNING id, '神奈川', city, data)
INSERT INTO japan SELECT * FROM tmp;
これを実行すると、id = 3のレコードのprefが神奈川に変わります。町田は神奈川になりました。:-)
part=# SELECT * FROM japan ;
id | pref | city | data
----+--------+------+--------------
1 | 神奈川 | 横浜 | シウマイ
2 | 神奈川 | 川崎 | タンタンメン
3 | 神奈川 | 町田 | リス
(3 rows)
おわりに
さて、PostgreSQL 10の宣言的パーティション、いかがでしょうか。 「PostgreSQLのパーティションって構築が面倒・・・」と思っていた人には、特におすすめしたい機能だと思います。 まだ、いくらか制約事項や、改善すべき事項もあるとは思いますが、きっと今後のバージョンで対応されるのではないかと思います。楽しみですね!
関連サービス



PostgreSQLに関わる仕事をしつつ、社内のPostgreSQLの問い合わせにカジュアルに対応。 「ぬこ@横浜」の名前で国内のデータベース関連のイベントでも喋っています。PostgreSQLの変な使い方を考えるのが趣味。 著書に『内部構造から学ぶPostgreSQL 設計・運用計画の鉄則』(技術評論社/共著)。 最近の自己紹介は「『PostgreSQL ラーメン』でググってください」
![]()