LLMは今後どうなる?LLMのイマと次なるコンセプト ~LLM活用入門14回~
今のLLMに関するトレンドと、次のコンセプトとしてLAM, dLLM, ワールドモデルといったキーワードについて紹介します。




テクノロジーコラム
- 2026年06月26日公開
はじめに
こんにちは、NTTテクノクロスの山口です。
ChatGPTが登場した2022年11月からはや3年以上経過した現在、生成AIやLLMが注目を浴び始めた当時と比べ、AIの能力は大きく進化したと言えるでしょう。
2026年現在でもClaude Mythosをはじめ、新たな基盤モデル(大量データで学習を行い、幅広いタスクに適用できる汎用モデル)が続々と登場しており、今後も継続的に進化していくことが予測できます。
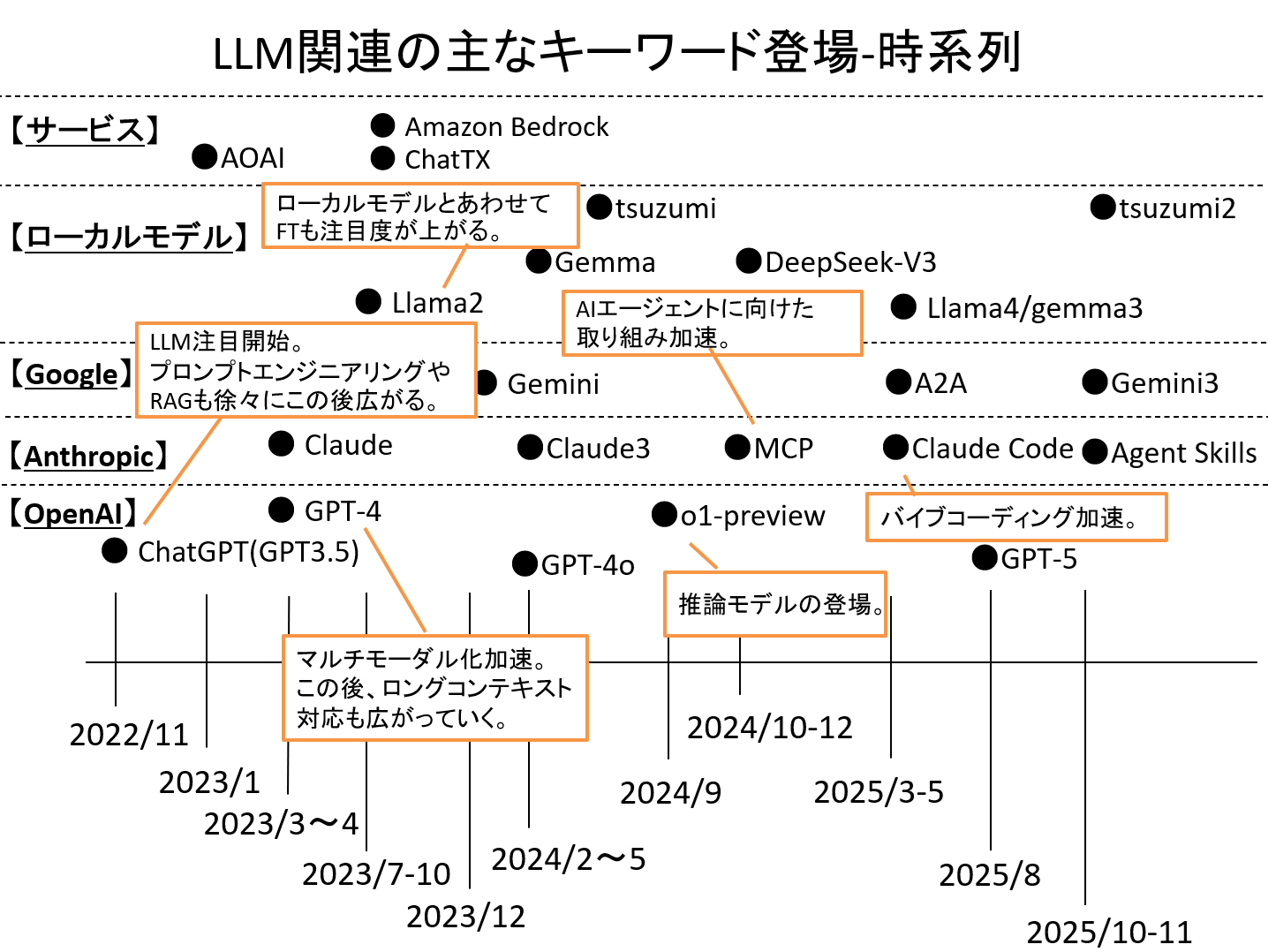
図1 LLMの流行から、トレンドキーワードの変遷
では今後LLMはどのように進化していくのでしょうか。
今回はLLMの進化を考える上での「現在のトレンド」と、進化の方向性を示すキーワードについてご紹介します。
■ 目次
| 節番号 | 大項目 | 小項目 |
| 1-1 | LLMのイマ | モデルの大規模化 |
| 1-2 | マルチモーダル化 | |
| 1-3 | 外部ツール連携も含めたAIエージェントの実現 | |
| 2-1 | LLMの方向性を示すキーワード | より「実行」を意識したモデル: LAM |
| 2-2 | より「推論速度」を意識したモデル: dLLM | |
| 2-3 | より「行動の結果」を意識したモデル:ワールドモデル |
[参考] 本連載の連載の記事
本記事とあわせて、以下も良ければご確認ください。
| 連載番号 | タイトル | 概要 |
| 第1回 | 今だから知っておきたいDify!ノーコード・ローコードでLLM活用基盤を作ろう | Dify自体の説明とChatflow機能を使った例を取り上げています。 |
| 第2回 | 爆速キャッチアップ!LLM活用をリードするプラットフォーム群 | LLMの可能性をより広げるDify/Ollama/LangChain/Hugging Faceの紹介と、 DifyとOllamaでローカルLLMを活用したChatflow機能の利用に関して取り上げます。 |
| 第3回 | RAGとは?Difyから基本を学ぶ | RAGの基礎的な説明とDifyを使った実現方法を取り上げています。 |
| 第4回 | ローカルモデル利用のRAG実装で学ぶLangChainの基礎 | ベクトルDBを用いたRAGのサンプルコードから、LangChainの基礎を解説します。 |
| 第5回 | ローカルモデル利用のRAG実装で学ぶLlamaIndexの基礎 | ベクトルDBを用いたRAGのサンプルコードから、LlamaIndexの基礎を解説します。 |
| 第6回 | Difyで学ぶ、RAGの精度改善手法 | RAGの精度改善手法をDifyのChatflow機能を使いながら紹介します。 |
| 第7回 | ローカル環境で実現する、GraphRAGの基礎 | GraphRAGの基礎から、LangChainとNeo4jを使ったグラフRAGの実装例を紹介します。 |
| 第8回 | ローカル環境で実現する、Text-To-SQLとRDBを用いたRAG | Text-To-SQLと、それを活用したRDBを用いたRAGの実装例を紹介します。 |
| 第9回 | ファインチューニングとは?基礎を理解する | ファインチューニングとそのユースケース、手法を紹介します。 |
| 第10回 | Hugging Faceライブラリで実行する推論と学習の基礎(前編) | Hugging Faceのライブラリを使った、モデルのダウンロードや推論処理について紹介します。 |
| 第11回 | Hugging Faceライブラリで実行する推論と学習の基礎(後編) | Hugging Faceのライブラリを使った、ローカルモデルの学習処理と実行例について紹介します。 |
| 第12回 | AIエージェントとは?Difyから考え方を学ぶ | AIエージェントについて、Difyでの動作イメージも含めて紹介します。 |
| 第13回 | MCPとは?AIエージェントの可能性を広げよう | AIエージェントの可能性を広げる技術であるMCPについて紹介します。 |
| 第14回 | LLMは今後どうなる?LLMのイマと次なるコンセプト | LLMに関する現在のトレンドと次なるコンセプトを示すキーワードを紹介します。 |
1, LLMのイマ
LLMの進化における現在のトレンドは大きく以下の3つが挙げられるかと思います。
① モデルの大規模化
② マルチモーダル化
③ 外部ツール連携を活用したAIエージェントの実現
以下でそれぞれをご紹介します。
1. モデルの大規模化
LLMを語る上で最もよく議論されるのは「精度」や「ハルシネーション(誤回答)の発生」です。
精度を高める方法としてよく取り上げられるのがRAGや外部ツールの活用、ファインチューニングなどですが、これらは既に提供されている基盤モデルを補強する手段です。
提供モデルそのものの基礎能力を上げる方法にも「学習データの質の向上」や「モデルアーキテクチャの改良」など、様々なものがありますが、依然として変わらない王道かつシンプルな考え方が「モデルの大規模化」です。
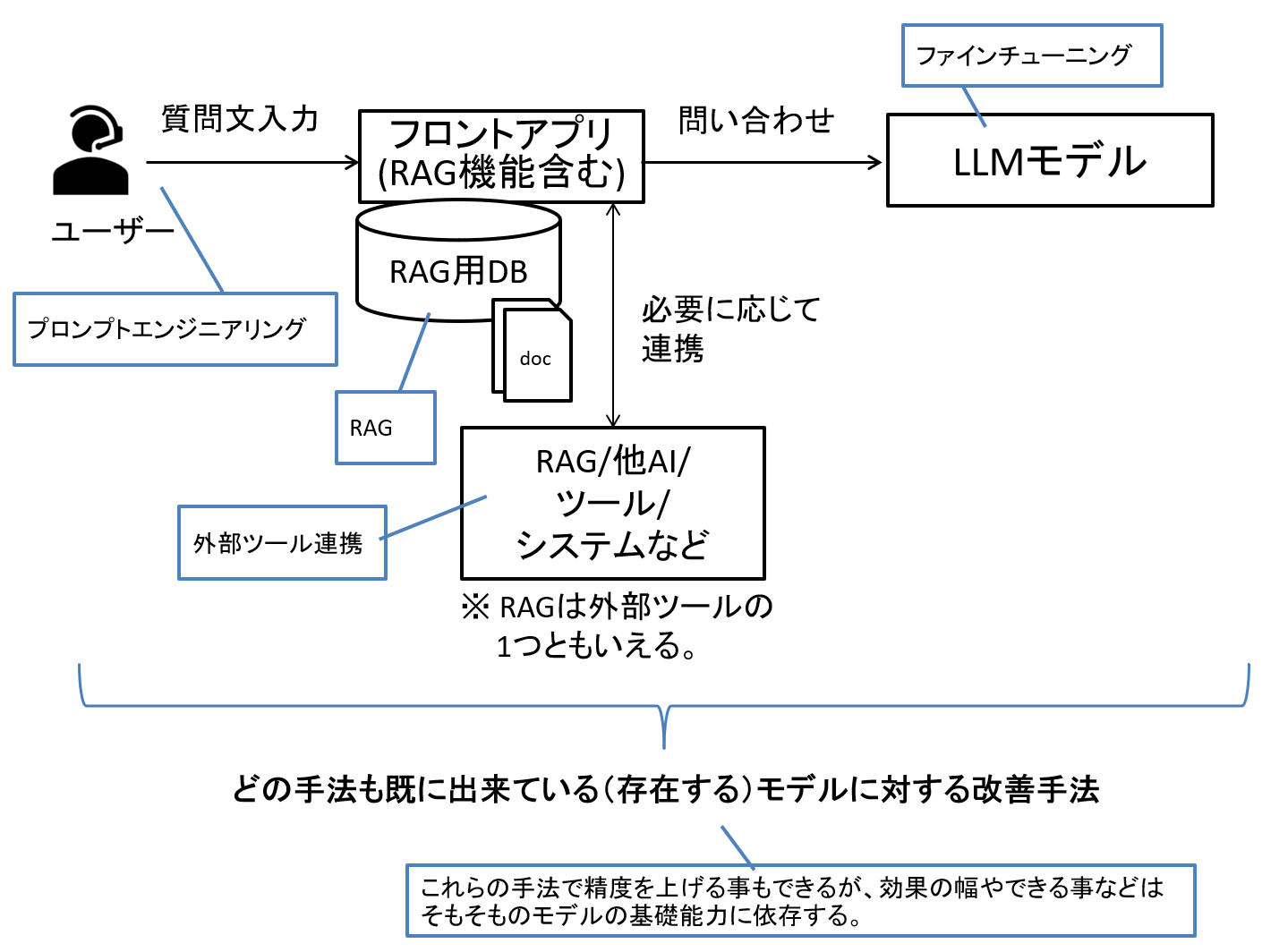
図2 すでにあるモデルを用いた精度向上手法の例
これはモデルのパラメータ数・学習データ量・計算量を増やすほど性能が向上しやすい、というスケーリング則と呼ばれる考え方に基づいています。
一方でこの方法は「消費電力の増加」や「推論時間の増加」「学習データの枯渇」などの課題もあります。
その為、軽量モデル化や軽量モデル(SLM)の精度向上も活発に進められています。
それでも大規模なモデルとの精度差はまだあり、より基礎精度の高い(頭の良い)モデルを作るとなると現在でもこの考え方が王道のアプローチとなります。
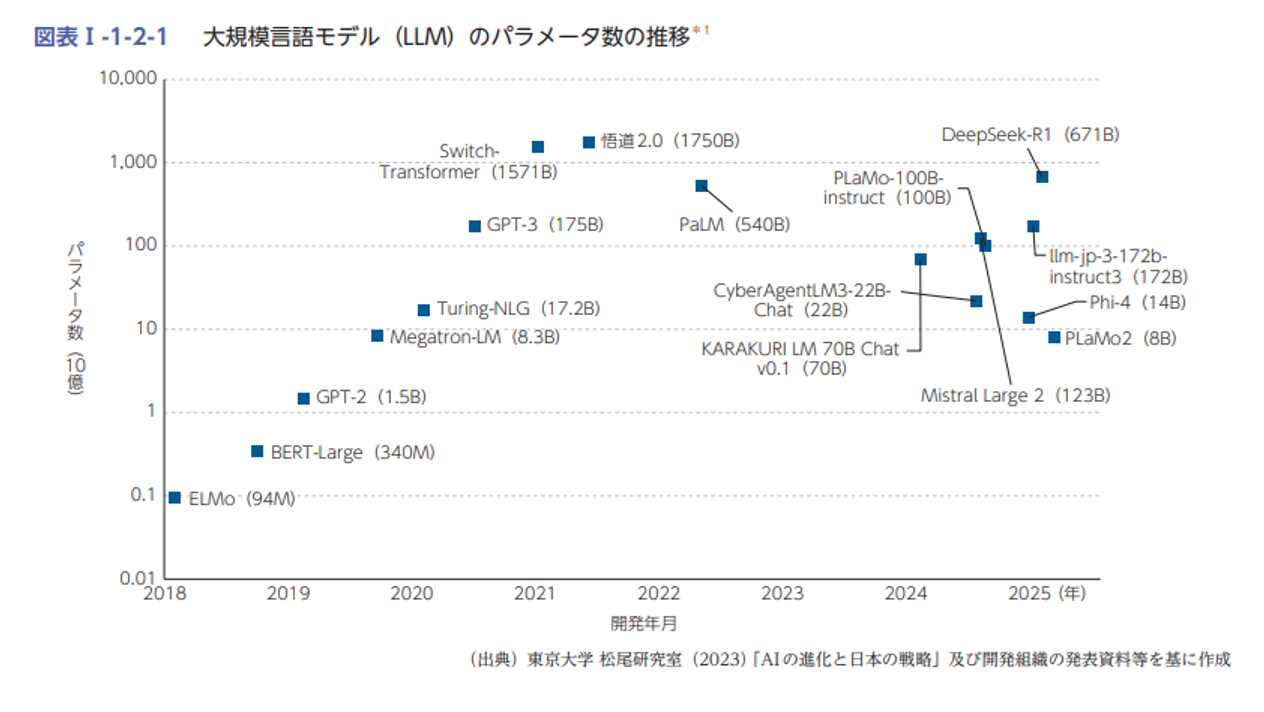
図3 参考: AIの大規模化
[出典] 令和7年度 情報通信白書 AIの爆発的な進展と動向より
(https://www.soumu.go.jp/johotsusintokei/whitepaper/ja/r07/pdf/n1120000.pdf)
|
補足:モデルの対応コンテキスト長の進化とコンテキストエンジニアリング LLMが一度に扱える情報量(コンテキストウィンドウ)には限りがあります。 LLMが注目された当初は、一度にLLMに渡せる情報量が小さかったことから、RAGで情報を渡す際にはチャンクと呼ばれる仕組みで、必要な箇所を区切って渡すなど、いかにLLMに渡す情報量(=コンテキスト長)を抑えるか、という工夫が必要でした。 一方で、今はRAGだけでなくMCPといった外部連携の為の仕組みを使ったり、ユーザとのやり取りの履歴や段階的な処理の為の全体計画などもモデルに渡す場合があります。 また、従来から変わらないことではありますが、クラウド型モデルを利用する場合、扱う情報量が増えるとその分費用も上がります。 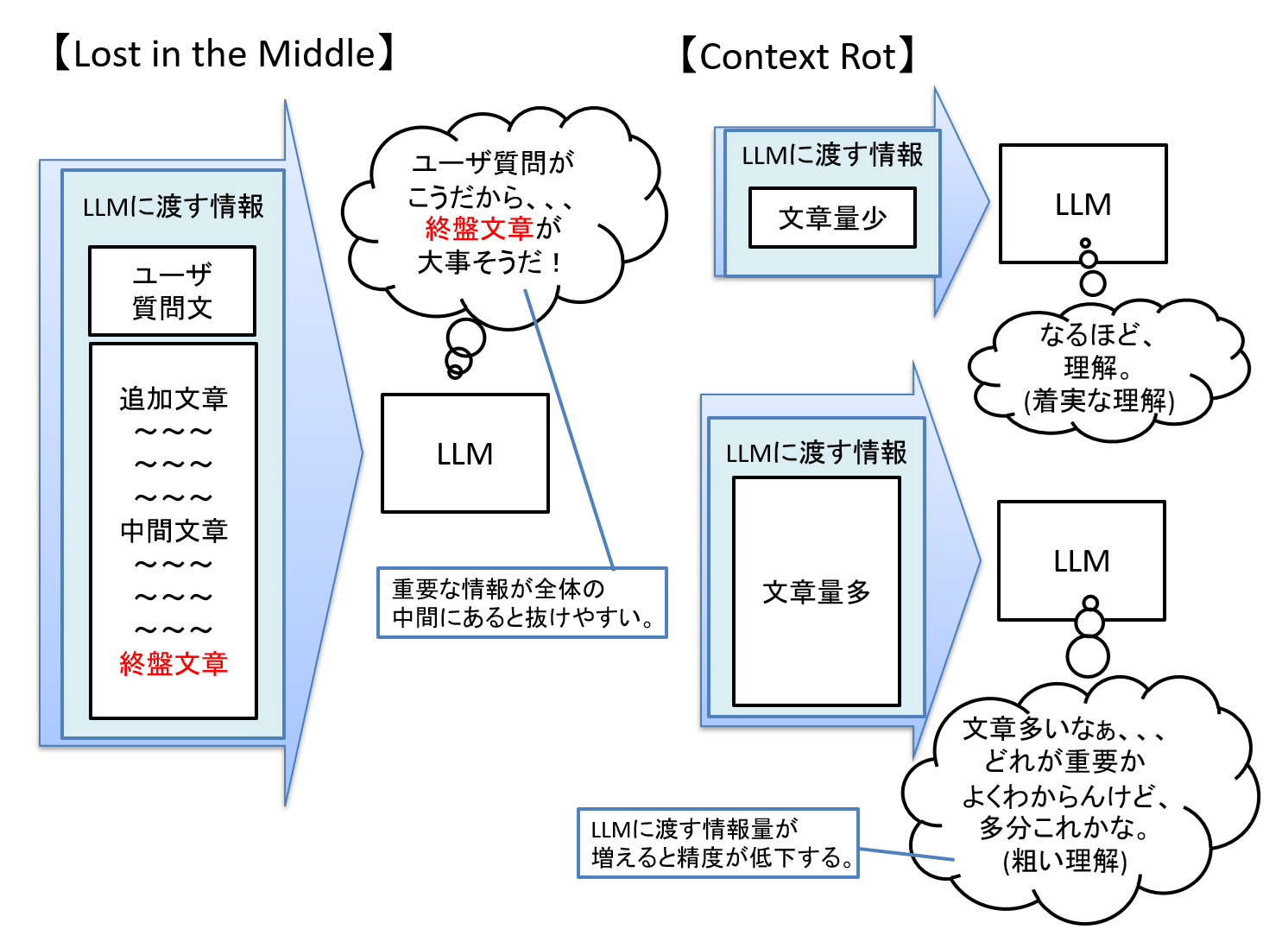
図4 Lost in the MiddleとContext Rotについて その為、「上限を意識して無理に情報量を削る必要はないが、本当に必要な情報だけを渡す」工夫や「情報の並びを意識する」工夫などが必要となってきています。 |
2. マルチモーダル化
ChatGPTが登場した当初は、入力も出力も「テキスト」に限られていました。
つまりは、文章で質問し、文章で回答を受け取る形式だったと言えます。
しかし昨今はテキストに加えて、画像・動画・音声など、様々な形式の情報を扱えるモデルが登場しています。このように多様な形式の情報に対応できる性質を「マルチモーダル」と呼びます。
もともとLLMは「大規模言語モデル(Large Language Model)」の名が指す通り、言語、すなわちテキストを扱うモデルを指す言葉でした。
一方で現在のモデルは前述のようにマルチモーダルな対応ができるようになってきており、もはや言語だけに閉じない能力を持ち始めています。
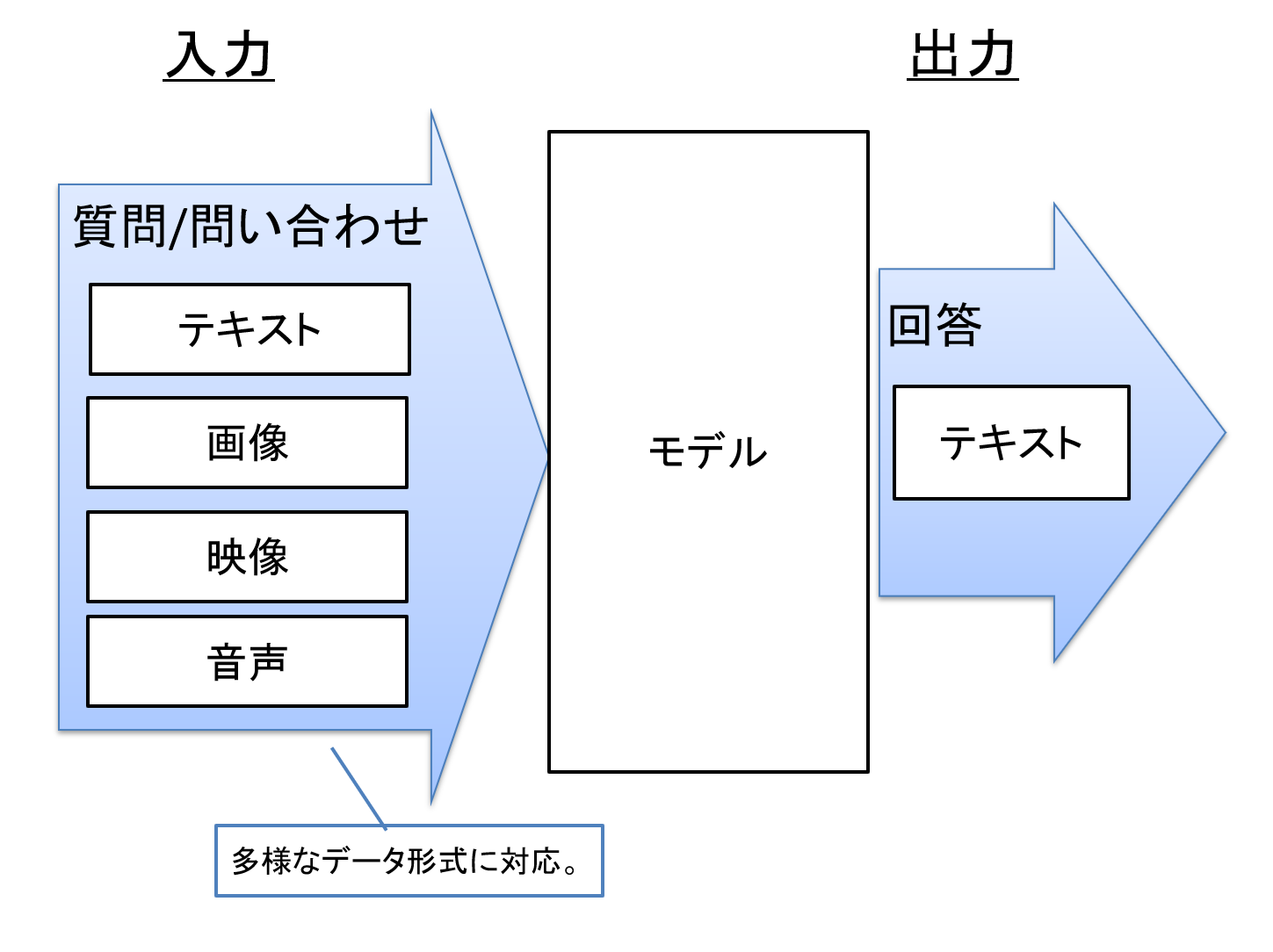
図5 入力がマルチモーダルなモデルの例
その意味では、VLM(Vision Language Model, テキスト+画像)やLMM(Large Multimodal Model, テキスト+様々な形式の情報)、あるいはMLLM(Multimodal Large Language Model, テキスト+様々な形式の情報)と呼ぶほうが正確といえます。
もっとも現在でもこうしたマルチモーダルなモデルも含めて、便宜的に広い意味でLLMと呼ぶことが多いのが現状です。
モデルのマルチモーダル化とその精度の向上により、より使い勝手の向上やユースケースが広がることが見込まれます。
3. 外部ツール連携を含めたAIエージェントの実現
AIエージェントは、LLMを活用して自律的に計画をたて、必要に応じて外部ツールを活用した上で回答を生成する仕組みを指します。
[参考] AIエージェントとは (https://www.ntt-tx.co.jp/column/251028/)
この仕組みの実現には、基盤モデル自体がタスクを分解したり外部ツール利用判断ができるようになった、あるいは実行結果を読み取って次の行動を判断する力が高まったことも大きく関係しています。
AIエージェントにより、従来のLLMが苦手としていた処理の改善に繋がりました。
LLMが苦手と言われていた処理は、例えば以下のようなものがあります。
|
No. |
苦手な処理 |
苦手な理由 |
|
1 |
複雑なタスクの回答や複数の質問が |
与えられた入力に対し一度で回答を生成しようとする為、段階的に考えるべき内容だと回答精度が下がったり、多くの質問がある場合に漏れが発生しやすかった。 |
|
2 |
計算処理 |
LLMは厳密な計算処理を行うわけではなく、文脈から次に出力すべき単語を予測して回答を生成する為、数値計算に弱かった。 |
|
3 |
入力/出力文字数の意識 |
人間は「文字」で情報を扱うが、LLMは「トークン」で情報を扱う為、厳密な文字数の意識などは弱かった。 |
No.1については自律的に計画をたて段階的に処理をしていくことや出力結果の検証処理をAIエージェント内に組み込む事で改善、No.2やNo.3はLLMそのものに解かせるのではなく外部ツールを活用することで改善しました。
また、No.2やNo.3に近いですが、例えばプログラムコードの提案など、回答前に妥当性がチェックできるものに関しては、外部ツールを活用しサンドボックス環境で動作確認をしてから回答する流れとすることで、回答精度の向上に繋がりました。
最近はAIエージェントの理解や活用も広がり、セキュリティの担保や運用の整理といった観点の話題も増えているように思います。
|
補足:適用領域の拡大① ~デジタルから物理世界へ~ AIエージェントは、LLMが苦手としていた処理の補完だけでなくLLMの適用領域を広げる役割も果たしています。 更に近年ではデジタル空間だけでなく、現実世界での物理的なタスク実施にもLLMを活用する検討がされています。 |
|
補足: 適用領域の拡大② ~汎用から業界特化へ~ 大量の業界データを学習させることで、業界特化モデルを作る、という取り組みも進んでいます。 1つ目は、トヨタ自動車とNTTによるモビリティ領域の取り組みです。 両社は、交通事故ゼロ社会の実現に向けて、通信基盤、AI基盤、計算基盤を組み合わせた「モビリティAI基盤」の構築を進めています。 2つ目に紹介するのはソフトバンクによる通信業界向けの取り組みです。 [参考] ソフトバンクは自社の持つ膨大な運用データやドメインに関連した文書などを学習させ、通信業界に最適化された生成AIモデルである「LTM(Large Telecom Model)」を構築したと発表されています。 このように、LLMの進化はモデル能力そのものの高度化だけでなく、特定業界のデータや業務知識を取り込み、産業ごとに実用化していく方向にも広がっています。 |
2, LLMの方向性を示すキーワード
「LLMのイマ」節で触れた各トレンドは今後も進展していくと考えられる一方で、昨今はLLMの方向性を示す別のキーワードも良く見聞きするようになってきました。
ここからは、LLMの方向性を示す注目キーワードを3つほど紹介していきたいと思います
※ 各技術は新しく注目されているコンセプトや手法ではあるものの、実装段階/習熟度は必ずしも同じ段階ではなく、それぞれやや異なるフェーズにいる点はご留意ください。
1. より「実行」を意識したモデル: LAM
LAM(Large Action Model, 大規模アクションモデル)は、ユーザや呼び出し元の意図を理解し、次にとるべきアクション(行動)を予測・実行に繋げるモデルを指します。
ここでいう「アクション(行動)」は、例えばツールの実行やアプリの操作、施策などがあげられます。
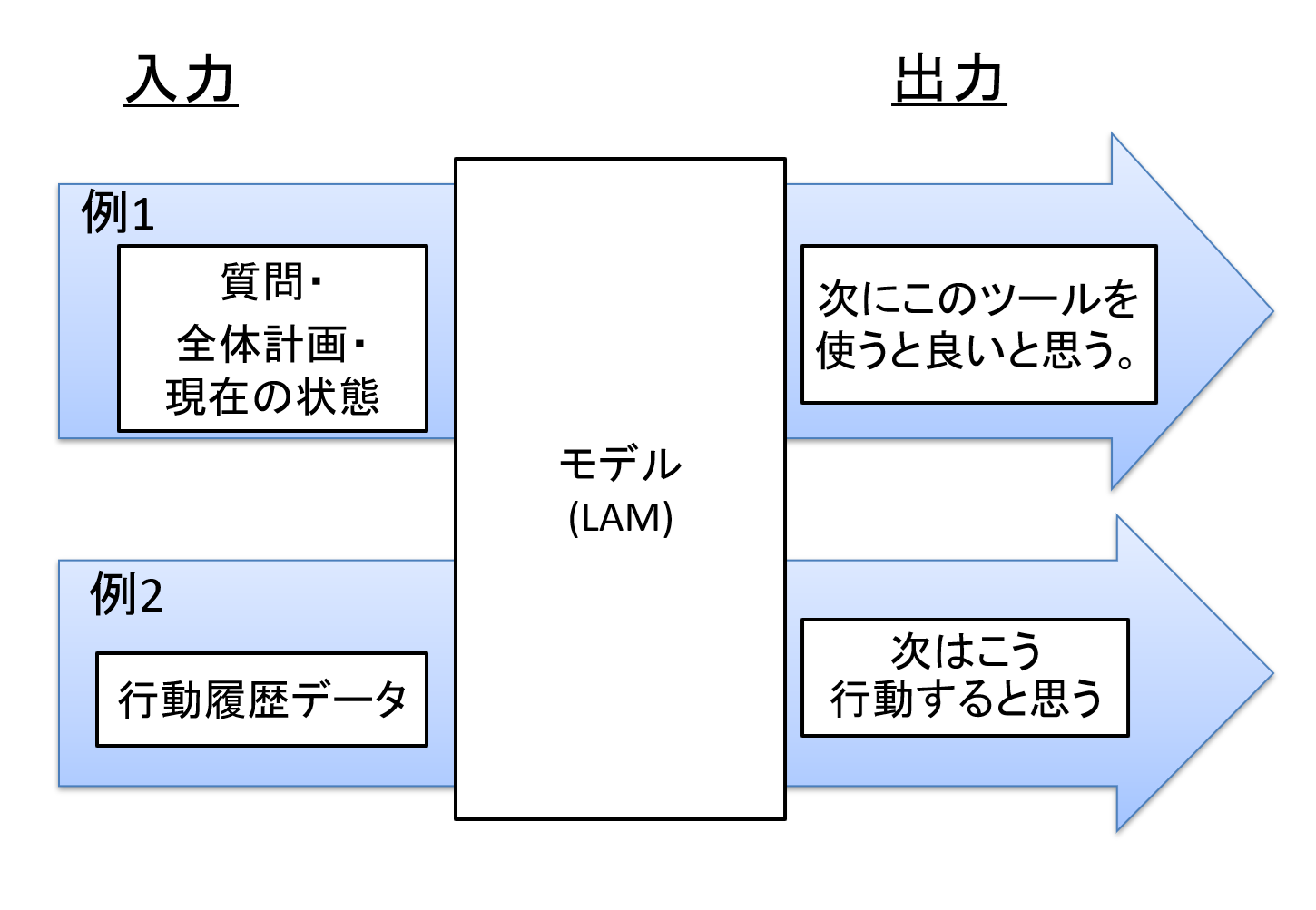
図6 LAMのイメージ例
この説明だけでは、従来のLLMを組み込んだAIエージェントと何が違うのか、と思われる方も多いかと思います。
ポイントは「アクションモデル」という名が示す通り、アクション(行動)に焦点を当てている点です。
つまりは「アクション(行動)を学習対象とする」点がLLMと異なる点と言えるでしょう。
例えば現在のLLMを組み込んだAIエージェントでも、Function CallingやMCPといった仕組みを活用することで、外部ツール実行は可能です。
しかしながら質問に対して思うように意図したツールを実行してくれないことやツールを多く組み込んだ場合に目的と異なるツールを実行してしまう経験をされた方も多いのではないでしょうか。
これは利用しているモデルがどのツールを活用するべきか正しく判断出来ていない事に起因していることが多く、AIエージェントでLLMを活用する場合の課題とも言えます。
一方LAMはどういう質問が来るとどのツールを使うべきか、といった「アクション(行動)」データも学習させることで、次にどのツールを利用すべきか=アクション(行動)の最適化を目指します。
このモデルをAIエージェントに組み込むことで、より適切なツールを選びながら処理を進めていくことができるようになるでしょう。
このように書くとLLMがLAMに今後代替されていくのか、と思う方もいるかもしれません。
LLMにもアクション(行動)データを学習させることでLAMに寄せていく案もあるとは思いますが、「LLMは回答生成、LAMは次の行動提案」というようにそれぞれ得意分野が異なる事からわけて運用したり目的に応じて使い分けることも考えられます。
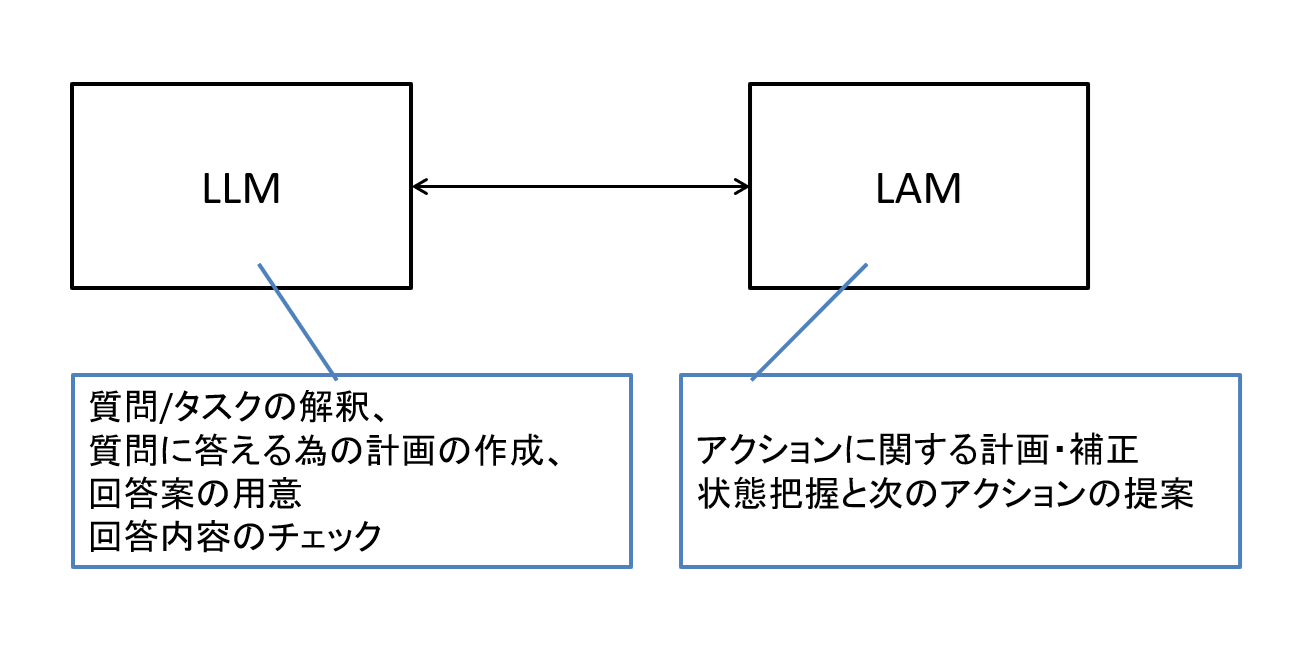
図7 LLMとLAMの作業分担例
事例としては、NTT+NTTドコモ社の以下の取り組みがあります。
[参考]https://group.ntt/jp/newsrelease/2025/11/12/251112a.html
この例では、ツール実行はしていませんが、顧客の行動データ(=アクション)を学習させ、次に取るべきアクションを予測・提案しており、タイトル通りLAMらしい事例といえます。
2. より「推論速度」を意識したモデル: dLLM
dLLM(Diffusion Large Language Model/拡散型大規模言語モデル)とは、主に画像生成の分野で使われていた「拡散モデル」の考え方をテキスト生成に当てはめたモデルです。
画像生成モデルといえばStable Diffusionが有名ですが、このモデルにも読んで字の如く「Diffusion(拡散)」というキーワードが入っています。
dLLMの名前からも、この考え方をLLMに当てはめたものという点はわかりやすいのではないでしょうか。
さて、テキスト生成を「拡散モデル」流にするメリットですが、大きく以下2点が期待できます。
① 出力品質の向上
② 推論速度の向上
①は、より全体を意識して文章を生成する為、「全体的にまとまった文章ができる」というような出力品質の向上が期待できます。
②は、並列的にテキスト生成処理が可能である為、推論速度の向上が期待できます。
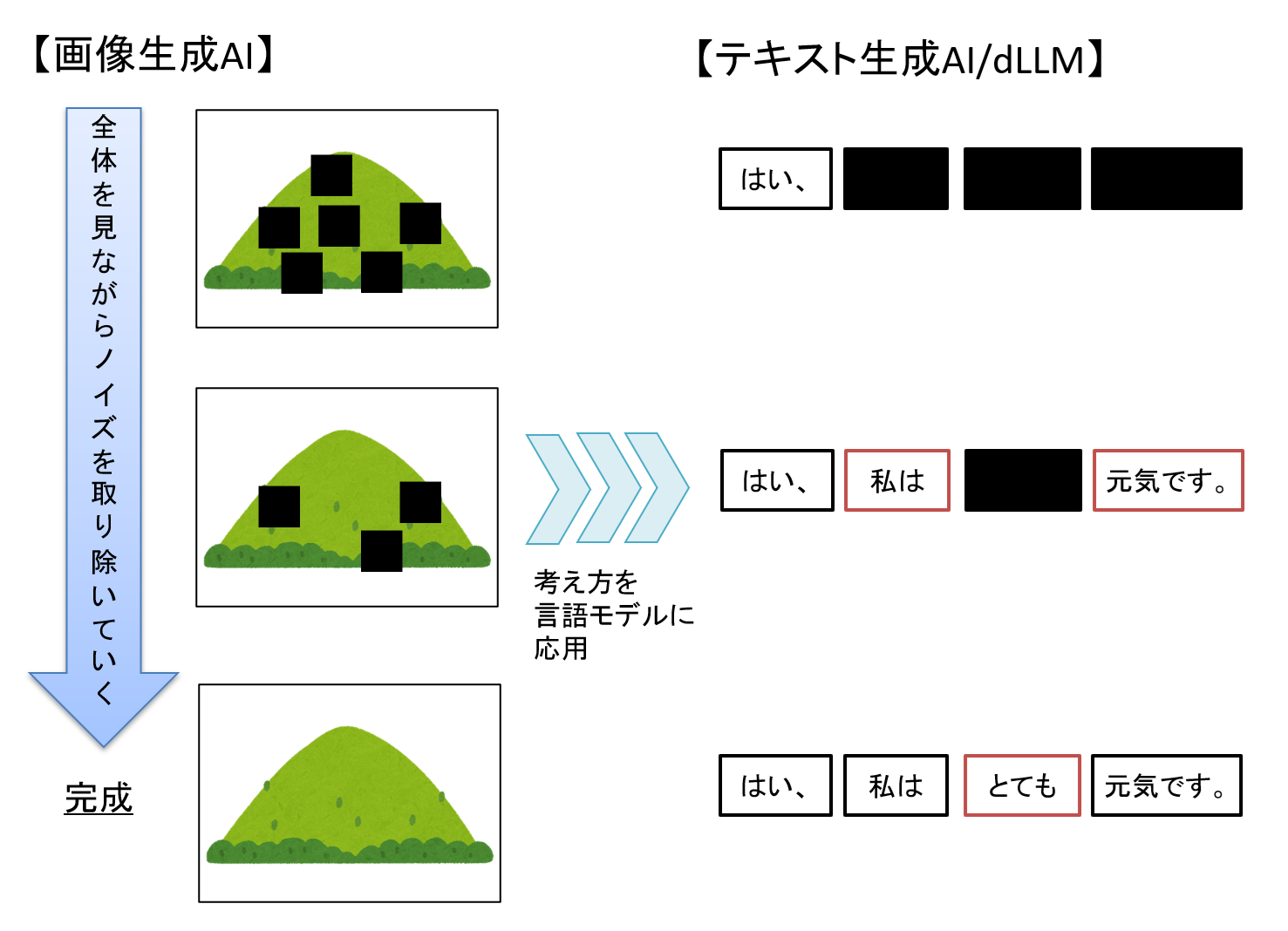
図8 画像生成とテキスト生成の拡散モデル処理イメージ
それぞれのメリットを従来のモデルの動作と比較してイメージしてみましょう。
既存のLLMアーキテクチャでは自己回帰型と呼ばれる、左から右へ1トークンずつ生成する流れとなる為、順次的(シーケンシャル)な処理となっていました。
一方、拡散モデルは少しずつ明らかとなっていない箇所(ノイズ/マスクされた箇所)を生成して、最終的な出力を作ります。
このため、拡散モデルでは全体を見ながら、並列処理ができるようになります。
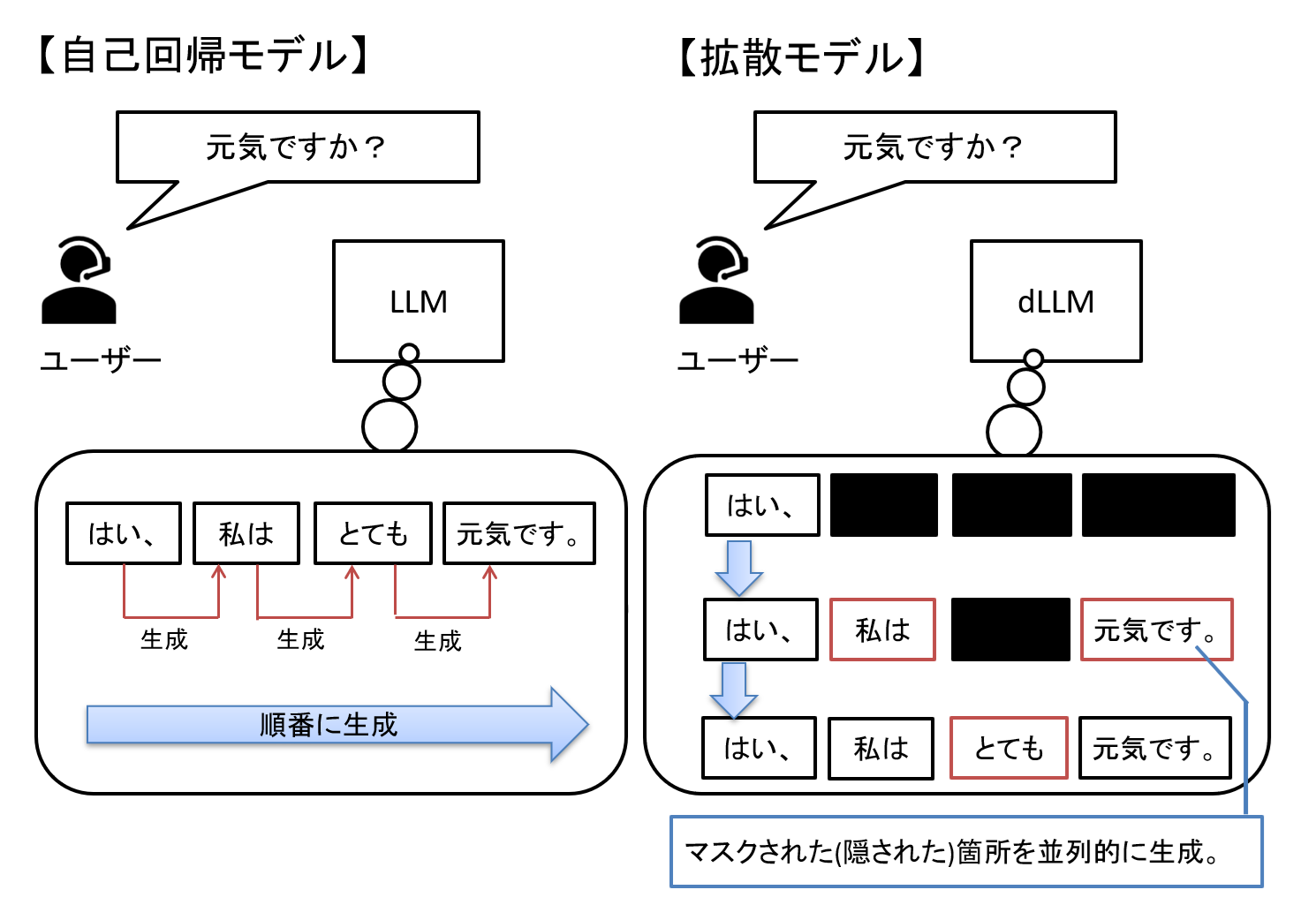
図9 従来型(自己回帰型)と拡散モデルの違いイメージ
一方でdLLMのポイントは「テキスト生成」(=Decode処理)であり、入力文章の意図を理解するといった、いわゆるPrefill側の効果は現時点ではあまり期待できません。
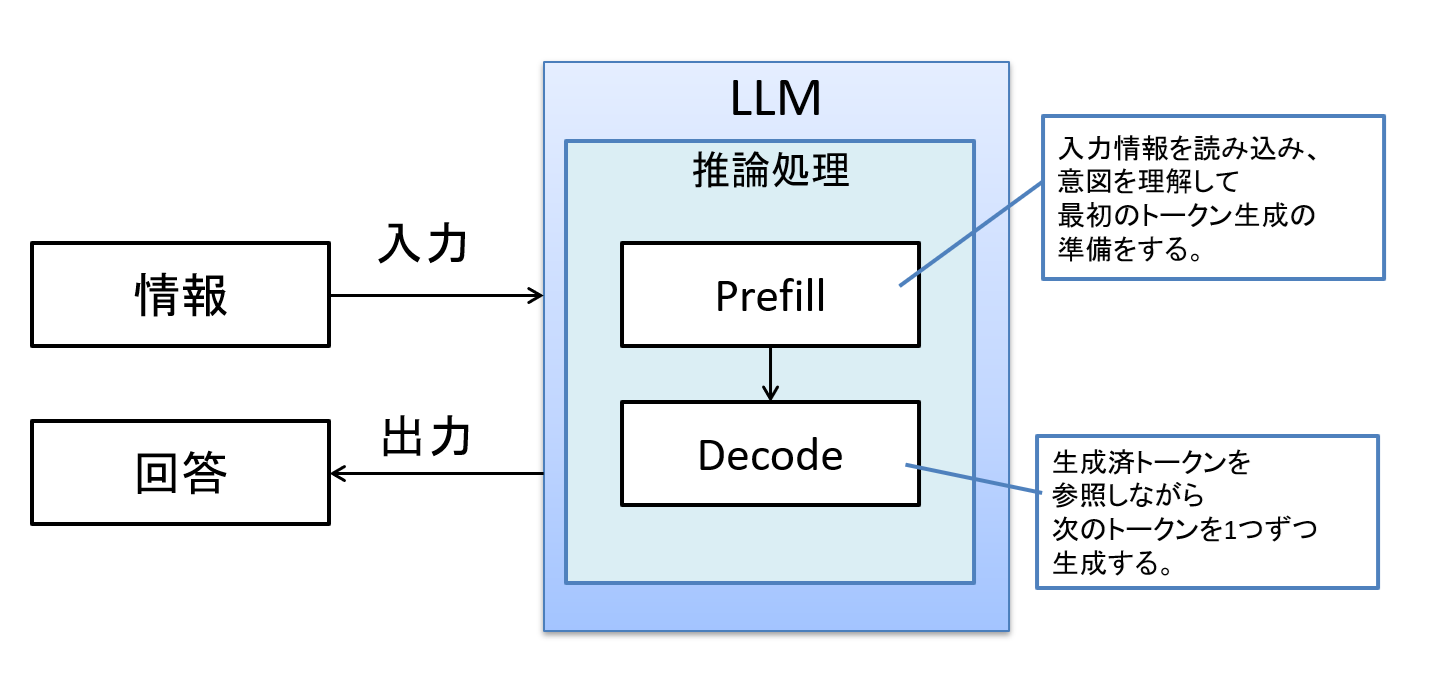
図10 推論処理の全体像
dLLMの活用は、モデルの大規模化やAIエージェントによる内部でのLLM問い合わせ数増加といった、回答待ち時間の増加に対する対策となり得ます。
一方でLost in the MiddleやContext Rotといったロングコンテキスト(長文)インプットによる精度低下課題については、Decode側にも影響はあるもののPrefill側も大きく関係する為、現時点では抜本的な解決案にはならないかと思います。
dLLMはまだ登場して間もないですが、代表的なものとしてMercuryやLLaDAと呼ばれるモデルが存在します。
また、Mercuryでは特定の評価条件において、既存の高速LLMと比較して最大10倍の速度改善をした、と発表されています。
|
補足: 推論の高速化について GPUなどのインフラが重要となるのは学習だけではありません。 |
3. より「行動の結果」を意識したモデル:ワールドモデル
ワールドモデル(World models/世界モデル)とは、AIが現在の状態や候補となる行動をもとに、次に環境にどのような変化が起こるのかを予測することができるモデルを指します。
シンプルに言えばAIに何が起こるのか「想像」する能力/仕組みが付与されたものと考えてもらえれば、と思います。
ここで、「既存のLLMも想像して回答しているのではないか」と思う方もいるかもしれません。
例えば「環境のインストール/セットアップで上手く行かない原因を教えて」と質問すれば、限られた情報から原因となることを想像して回答をくれるのではないか、と思うかもしれません。
しかしLLMは仕組み上、内部的に「次の単語を予測して出力している」為、必ずしも環境の状態変化や行動の副作用を内部で考えて回答しているわけではありません。
上の例でいえば、非常に問い合わせ事象と似たケースの対処方法が「マシン再起動」だったとして、そのデータをモデルが学習していた場合、LLMは「マシン再起動」をそのまま提案してくるかもしれません。
しかし人間がこのような事象に対応する場合には「マシン再起動でいけるかも」とわかったとしても、再起動はある意味リスクのある処理でもある為、他に何か対処方法がないか確認の上、他に対処案がなければ実施する、という流れになるかもしれません。
すなわち人間は「再起動するとマシンが起動しなくなるかも」「一部の永続化していない設定が飛んで他に影響があるかも」といった行動した結果を想像の上、対処方法を選んでいると言えます。
これと同様にAIにも回答や行動の結果を想像の上で対応する力を付与する、という考え方がワールドモデルです。
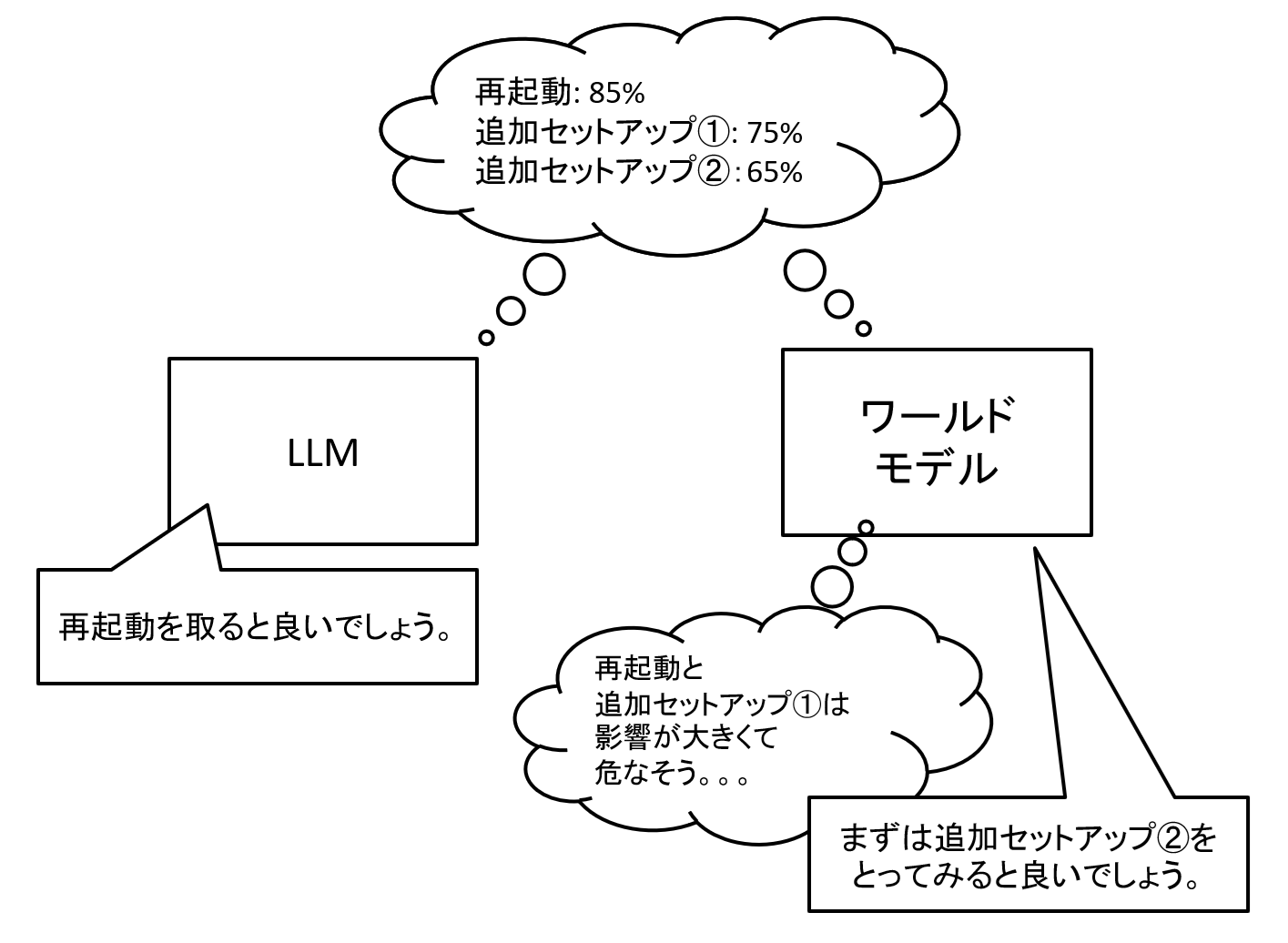
図11 従来LLMとワールドモデルの考え方の違いイメージ
これまでの例は「セットアップ」でしたが、「自動運転」や「ロボットを動かすようなフィジカルAI」の分野で想像すると、より必要性が見えて来るかと思います。
例えば自動運転の観点では、現在一定のスピードで走っているが、次はどうするのか=「物陰から人が飛び出してくるかも」「隣を走っている自転車が倒れてくるかも」「前の車が急にブレーキを踏むかも」など、安全運転に向けて周囲の状況に合わせた想像とその対処が極めて重要になります。
では、このようなモデルを組み込んだ「AIエージェント」はどのように変化するのでしょうか。
現在のAIエージェントはその都度の状況から試行錯誤を繰り返していく形になりがちです。
それが「想像する」ことができるモデルを組み込んだ場合は、失敗や副作用が大きそうな行動は避けながら、より効率的に対応を進めていけるようになるでしょう。
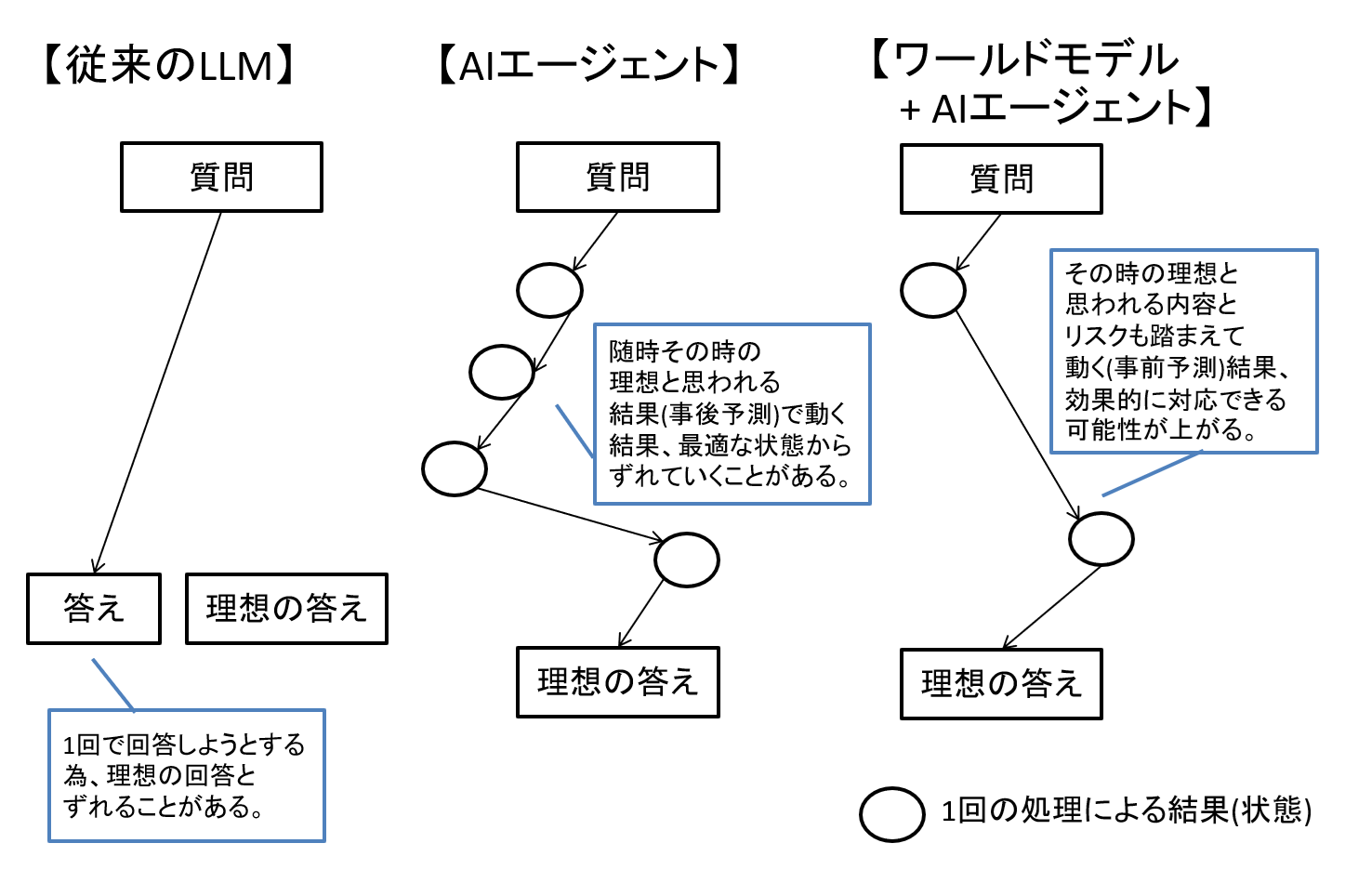
図12 従来のLLM/従来のLLMを使ったAIエージェント/ワールドモデルとAIエージェントの動きの違いイメージ例
このようにワールドモデルは、デジタル領域でも現実世界においても、AIが安全かつ適切に行動する為に重要な要素となりうると考えます。
おわりに
今回はLLMに関する今のトレンドと次を見据える上で重要なキーワードについて紹介しました。
最近はバイブコーディングという言葉も注目を浴び、プログラミング領域への適用がトレンドになっているかと思います。
一方でLLMやAIエージェントの進化はそれだけに限らず、様々な方向に広がっていることが改めて見えたのではないでしょうか。
LLMの活用を検討する上でも、現在のLLMの状態や課題とそれに対する対抗策、将来を見据えたトレンドなども把握しておけると良いでしょう。
なお、AIが外部ツール活用をしたり現実世界への適用、行動の予測に進むほど、安全性や評価の重要性も高まります。
今後はモデル能力の向上や仕組みの改善だけでなく、安全に利用するための設計(例えばガード機能など)もより重要になっていくでしょう。
今回もご覧いただきありがとうございました。
もし何かご意見・コメント・ご質問などがあれば、以下からお問い合わせください。
本件に関するお問い合わせ





フューチャーネットワーク事業部
第一ビジネスユニット
山口 佳輝(YAMAGUCHI YOSHIKI)
![]()