今だから知っておきたいDify!ノーコード・ローコードでLLM活用基盤を作ろう ~LLM活用入門第1回~
LLMをより効率的に使うための仕組みを簡単に用意できるDifyについて紹介します。




はじめに
こんにちは、NTTテクノクロスの山口です。
近頃はLLM(大規模言語モデル, OpenAI社のGPT-4o等)をはじめとする生成AIが様々な分野で急速に普及しつつあるかと思います。
私の関わる通信分野でもこの流れは同様で、LLM適用に向けて活発に議論されています。
そこで今回は、今話題のLLMをより上手く使う為のDifyについて紹介したいと思います。
■ 目次
| 節番号 | 節タイトル |
| 1 | Difyとその強み・ユースケースについて |
| 2 | Difyの使い方の例について |
[参考] 本連載の記事
本記事とあわせて、以下も良ければご確認ください。
| 連載番号 | タイトル | 概要 |
| 第1回 | 今だから知っておきたいDify!ノーコード・ローコードでLLM活用基盤を作ろう | Dify自体の説明とChatflow機能を使った例を取り上げています。 |
| 第2回 | 爆速キャッチアップ!LLM活用をリードするプラットフォーム群 | LLMの可能性をより広げるDify/Ollama/LangChain/Hugging Faceの紹介と、 DifyとOllamaでローカルLLMを活用したChatflow機能の利用に関して取り上げます。 |
| 第3回 | RAGとは?Difyから基本を学ぶ | RAGの基礎的な説明とDifyを使った実現方法を取り上げています。 |
| 第4回 | ローカルモデル利用のRAG実装で学ぶLangChainの基礎 | ベクトルDBを用いたRAGのサンプルコードから、LangChainの基礎を解説します。 |
| 第5回 | ローカルモデル利用のRAG実装で学ぶLlamaIndexの基礎 | ベクトルDBを用いたRAGのサンプルコードから、LlamaIndexの基礎を解説します。 |
| 第6回 | Difyで学ぶ、RAGの精度改善手法 | RAGの精度改善手法をDifyのChatflow機能を使いながら紹介します。 |
| 第7回 | ローカル環境で実現する、GraphRAGの基礎 | GraphRAGの基礎から、LangChainとNeo4jを使ったグラフRAGの実装例を紹介します。 |
| 第8回 | ローカル環境で実現する、Text-To-SQLとRDBを用いたRAG | Text-To-SQLと、それを活用したRDBを用いたRAGの実装例を紹介します。 |
| 第9回 | ファインチューニングとは?基礎を理解する | ファインチューニングとそのユースケース、手法を紹介します。 |
| 第10回 | Hugging Faceライブラリで実行する推論と学習の基礎(前編) | Hugging Faceのライブラリを使った、モデルのダウンロードや推論処理について紹介します。 |
| 第11回 | Hugging Faceライブラリで実行する推論と学習の基礎(後編) | Hugging Faceのライブラリを使った、ローカルモデルの学習処理と実行例について紹介します。 |
| 第12回 | AIエージェントとは?Difyから考え方を学ぶ | AIエージェントについて、Difyでの動作イメージも含めて紹介します。 |
| 第13回 | MCPとは?AIエージェントの可能性を広げよう | AIエージェントの可能性を広げる技術であるMCPについて紹介します。 |
[参考] そもそもLLMとは?という方はこちらも参照ください。
・無料書籍「可能性を広げる!LLM活用入門」
https://techbookfest.org/product/uTB0tniuhtDcb5we11bFXU?productVariantID=8Rh4bcF1WESuChu56dVZeT
・Speaker Deck
https://speakerdeck.com/yamaguchi_tx/llmnoji-chu-tollmhuo-yong-niguan-lian-sitazhu-ming-naturunoshao-jie
Difyとその強み・ユースケースについて
Difyとはオープンソース(OSS)のLLMアプリ開発プラットフォームとなります。
DifyにてAPIキーを指定することで様々なLLMモデルを操作可能となり、それを用いたアプリが簡単に作ることができます。
通常LLMを扱う際にはLLMに問い合わせを行う「フロントアプリ(※)」と、問い合わせを受けて回答する「LLMモデル」が必要となります。
フロントアプリは自前でプログラムをして作るという手もありますが、より簡単に作る手段としてDifyがあげられます。
※ わかりやすい例はチャット画面のようなものですが、API経由でLLMモデルに問い合わせができる為、CUIベースでも可能です(チャット画面は必須ではありません)
ChatGPTもフロントアプリであり、LLMモデル(GPT-4oなど)に問い合わせを行っています。
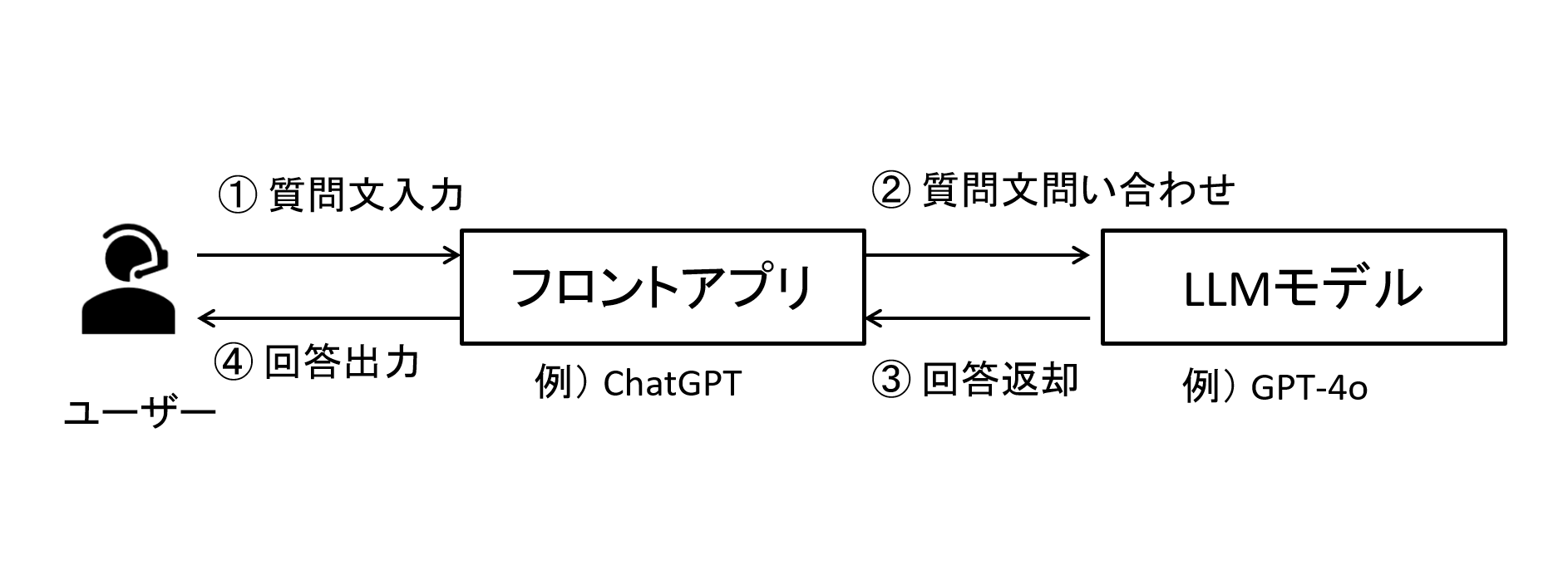
図1 フロントアプリとLLMモデル構成例
ここからはDifyの強みやユースケースについて触れていきます。
1. LLMフロントアプリを簡単に作成できる
最もわかりやすいのはフロントアプリをノーコード(プログラムをせずに)作成可能という点にあります。
(複雑な事をしようとするとプログラムが必要となるケースもあります)
ユーザが質問文を投げてLLMモデルが返答するシンプルなアプリはもちろん、「Chatflow機能」を使う事でやや複雑なフロントアプリも作成可能です。
例えば簡単な質問には軽めのLLMモデルを使用し、難しい質問には重めのLLMモデルを使うといった使い分けがあげられます。
ここでいう軽い/重いという表現は処理の長さや費用の高さと考えて頂ければ、と思います。
具体例でいえば、あくまで一例となりますが用語の質問はGPT-3.5を使用し、故障解析にはGPT-4 Turboを使うといったイメージです。
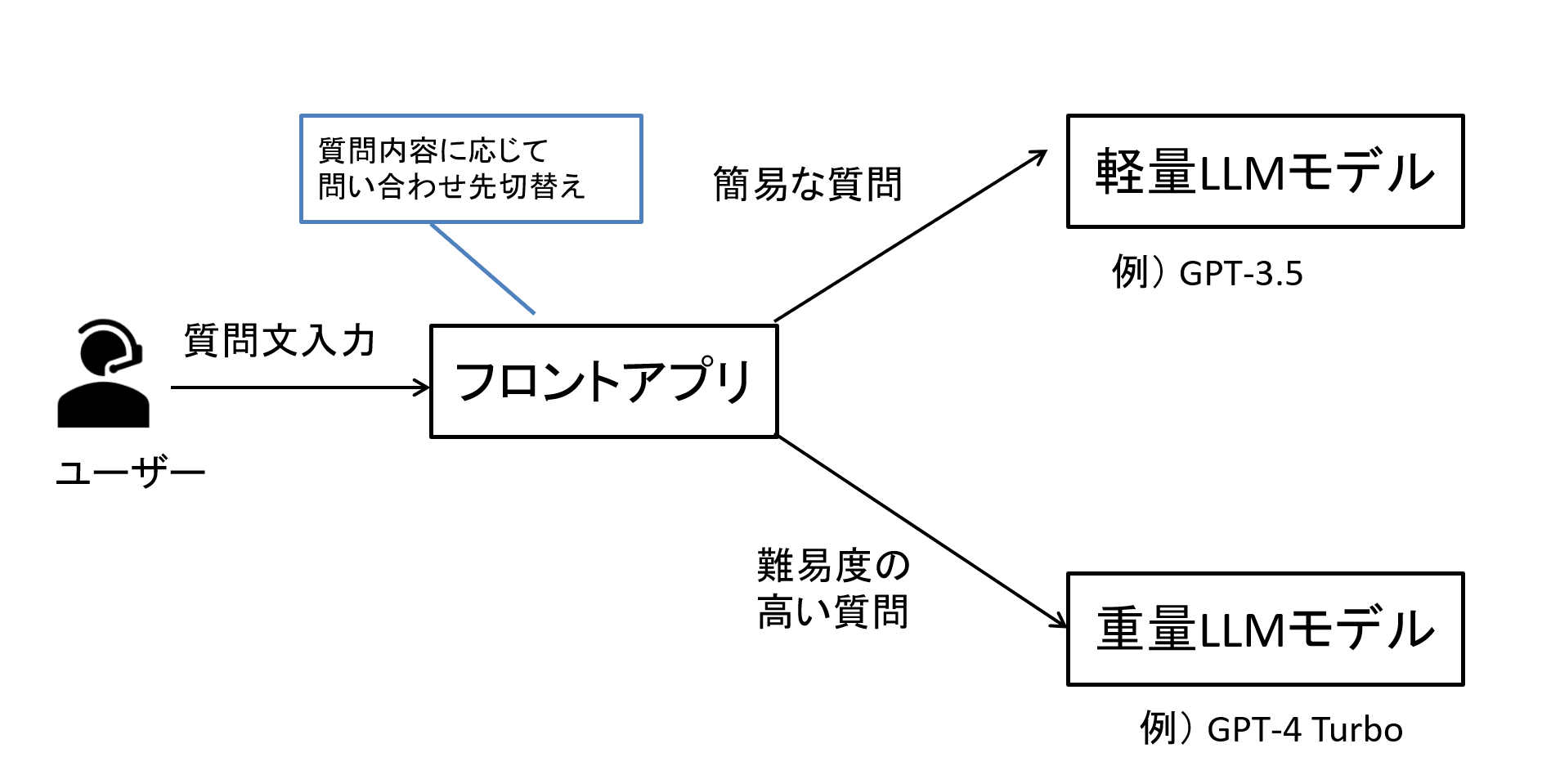
図2 質問内容に応じた問い合わせ先切り替えイメージ例
またユーザの質問文とあわせて何かしらの処理をしてからLLMモデルに問い合わせを行うケースもあげられます。
例えば通信分野ではNW上の機器(ルータやスイッチといったNW機器やVMや物理サーバ等のマシン)の故障解析や状態確認がLLMのユースケースとしてあげられますが、その際にはユーザの質問とあわせて対象のマシンの情報が必要となります。
よってユーザの質問文が発生したら、対象機器の情報を集めた上で、質問文とログ情報を統合してLLMモデルに渡す処理が行えると良いと考えられます。
上記のようなやや複雑な役割を持つフロントアプリもDifyで作成できます。
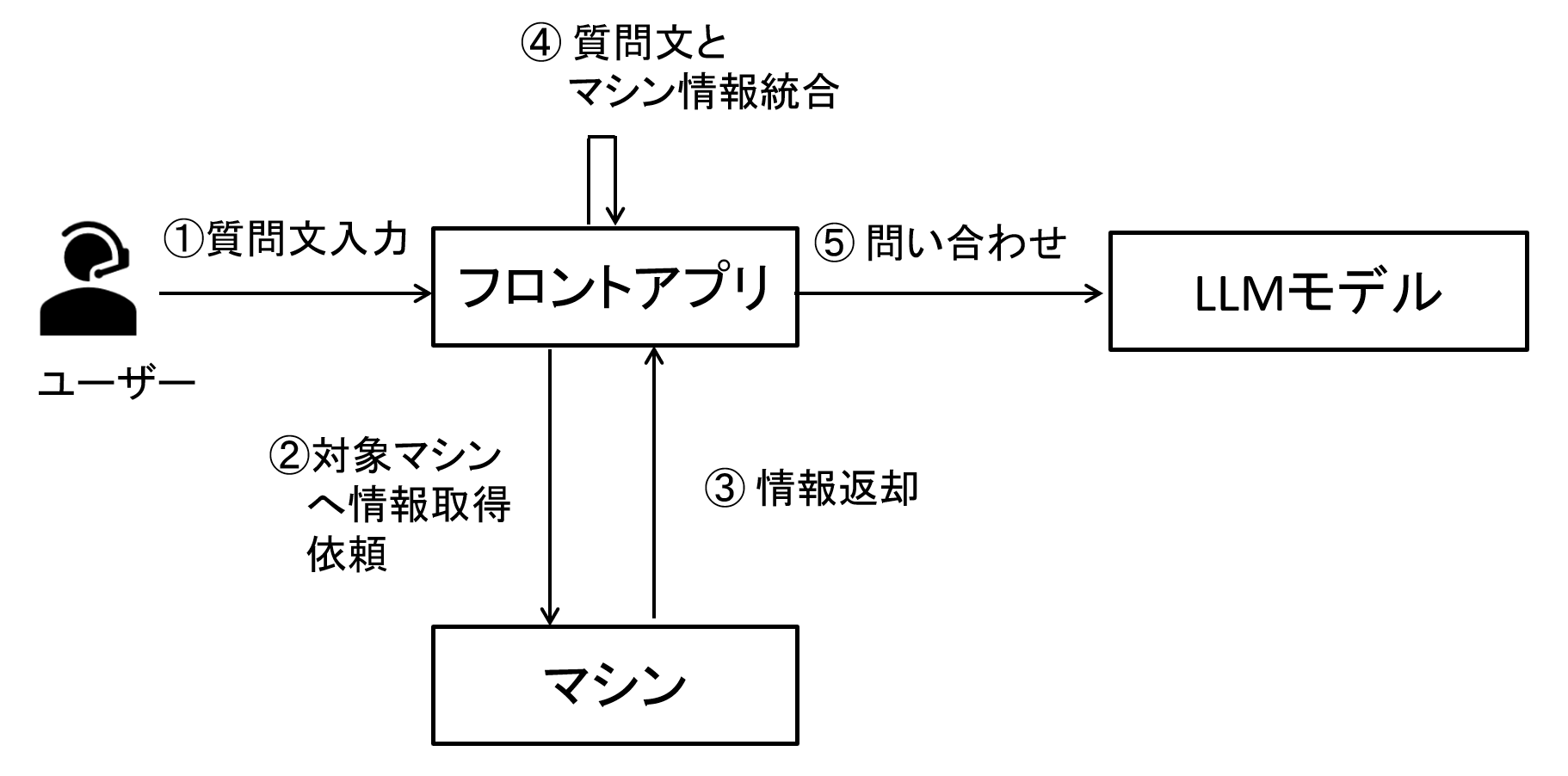
図3 マシン状態不具合や状態確認イメージ例
※ 故障解析に使用する場合、解析時にマシンとの疎通が取れない可能性もある為、マシンに関する情報(リソース使用量やSyslog等)は別場所に定期保存する仕組みを用意し、そこからフロントアプリが情報収集する仕組みとするとより好ましいと考える
またDifyでは作成したフロントアプリを外部からAPIが叩けるようにすることも可能です。
あわせてトークン使用量の確認等も可能です。
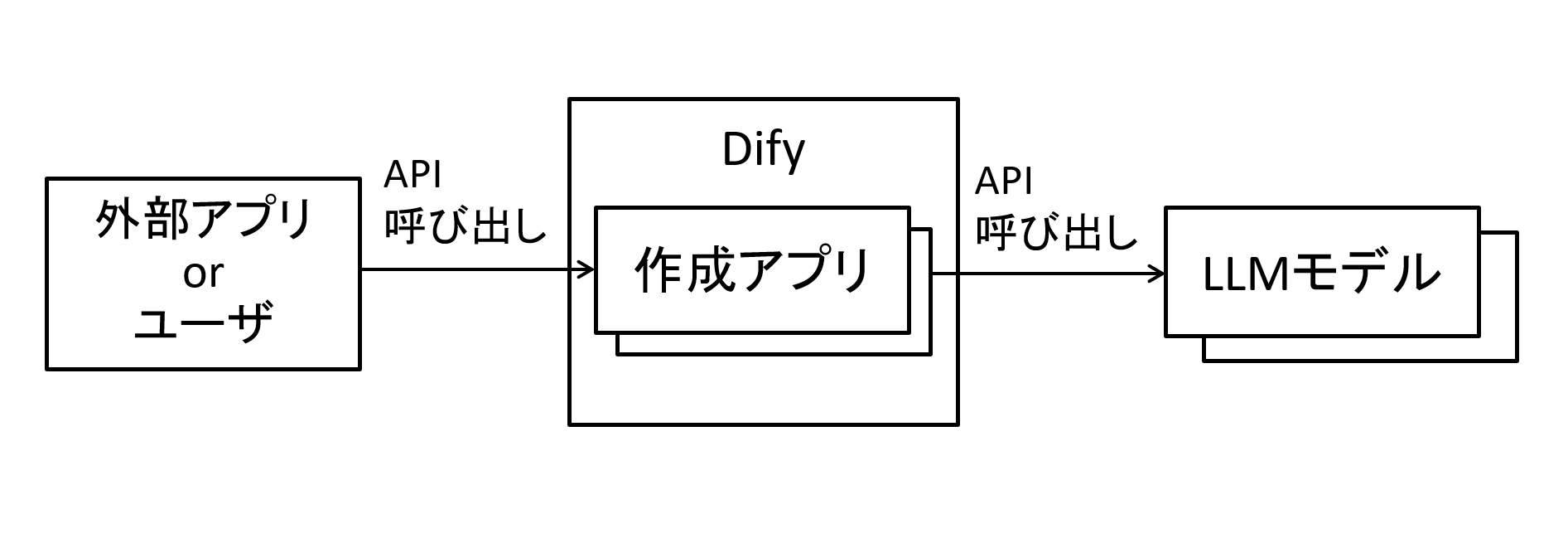
図4 Difyで作成したフロントアプリと外部からのAPI使用例
2. RAG機能も簡単に作れる
Difyの「ナレッジ機能」を使う事で、RAG機能を有したフロントアプリも簡単に作成できます。
RAGとは、LLMモデルに質問する前に外部(データベース等)から必要な情報を取得し、その情報を質問に加えることでLLMの回答精度を上げる仕組み・技術です。
特にLLMモデルが学習していない(=知らない)情報を使ったやり取りをする際に有効です。
LLMモデルが学習していない情報は例えば社内ルール等のインターネット上に公開されていない情報があげられます。
通信分野の例でいえば、各ベンダー・機器が独自に使用しているSNMP 拡張MIBの情報・意味合い等があげられるかと思います。
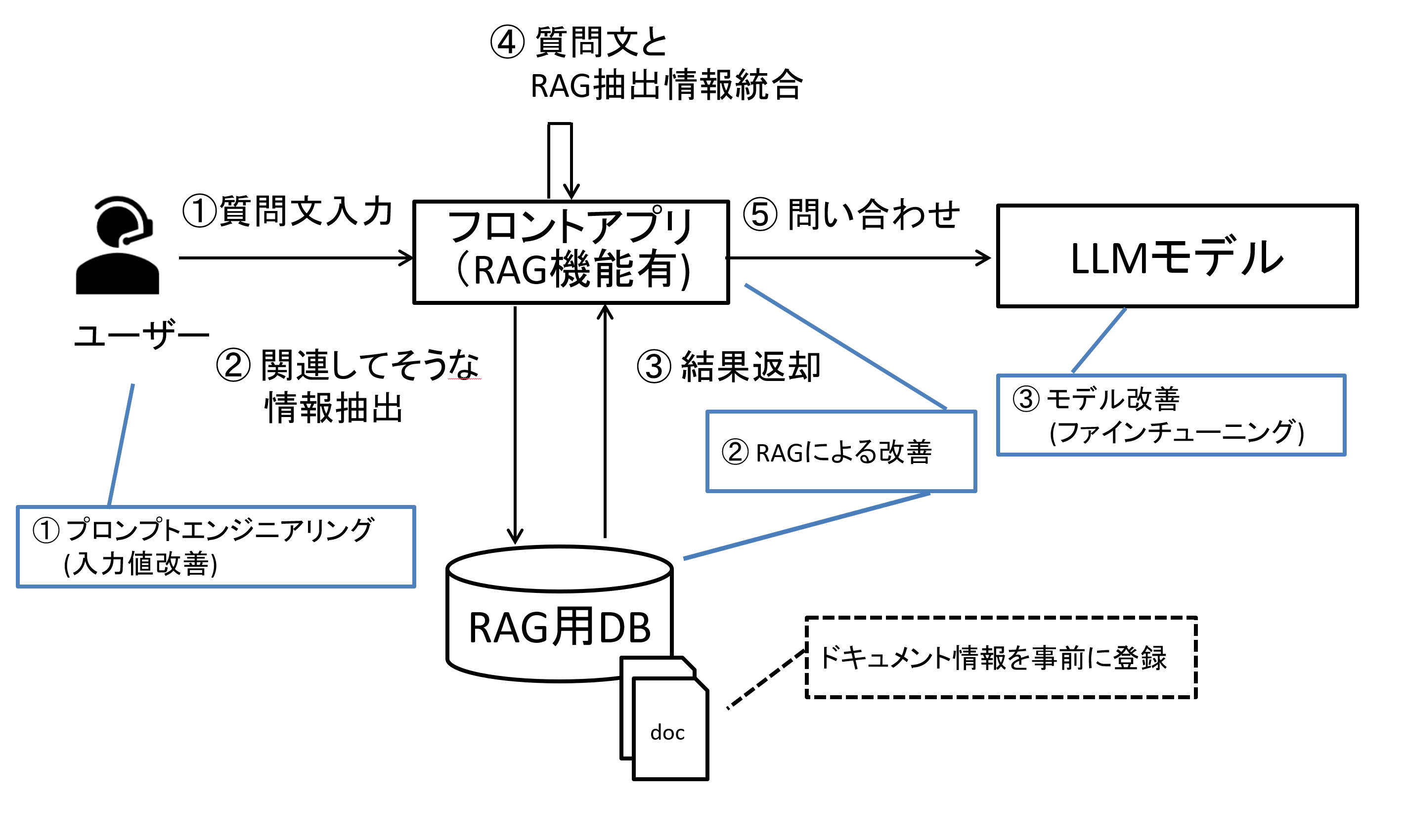
図5 一般的なRAGの処理の流れと精度改善に向けた取り組み
RAGを使う際には、情報を記載したPDF等の資料を登録し、RAGはその情報を独自のDBに格納します。
ユーザからの質問文が来たら関連性の高い情報をDBから引き出し、その情報を質問文をあわせてLLMに渡す、という仕組みとなります。
RAGもLLMを活用する上では重要な技術ですが、自前で作ろうとすると労力がかかる為、Difyを使って簡単に対応できる、という点はDifyの強みと言えるでしょう。
このようにLLMをよりよく使う仕組みを簡単に構築できるのがDifyといえます。
|
[補足] RAGの情報取得方法について RAGを活用して精度向上に取り組む際には大きく2つの観点があります。 ~~~ ②はイメージしやすいかと思います。 ①はRAGの検索手法についてです。 ここではこれ以上RAGの検索の仕組みについては触れませんが、気になった方は調べてみると良いかと思います。 |
Difyの使い方の例について
本節では、前節で触れた「NW上の機器の状態確認」の簡易な検証構成をローカル環境に作ってみたいと思います。
※ 今回操作するDifyのバージョンは0.6.16となります
初期設定
まずはローカル環境にDifyのインストールと初期設定を行います。
はじめにDifyのインストールですがdockerを使える環境なら非常に簡単に対応できます。
git clone https://github.com/langgenius/dify.git
cd dify/docker
docker compose up -d
各コンポーネントのコンテナが起動したらブラウザから以下にアクセスします。
| http://[IPアドレス]/install |
初回接続は管理者アカウントの作成が必要となります。
次に使用するLLMモデルのAPIキーを指定します。
Dify自体は無料で使用できますが、その先のLLMのモデルを使用する際には従量課金制でお金がかかる事が多いです。
今回は無料で試せるようにGroqを使ってみましょう。
事前にGroqサイトからAPIキーを作成した後、Dify画面の
右上のアカウント名 > 設定 > モデルプロバイダー
からAPIキーを設定しましょう。
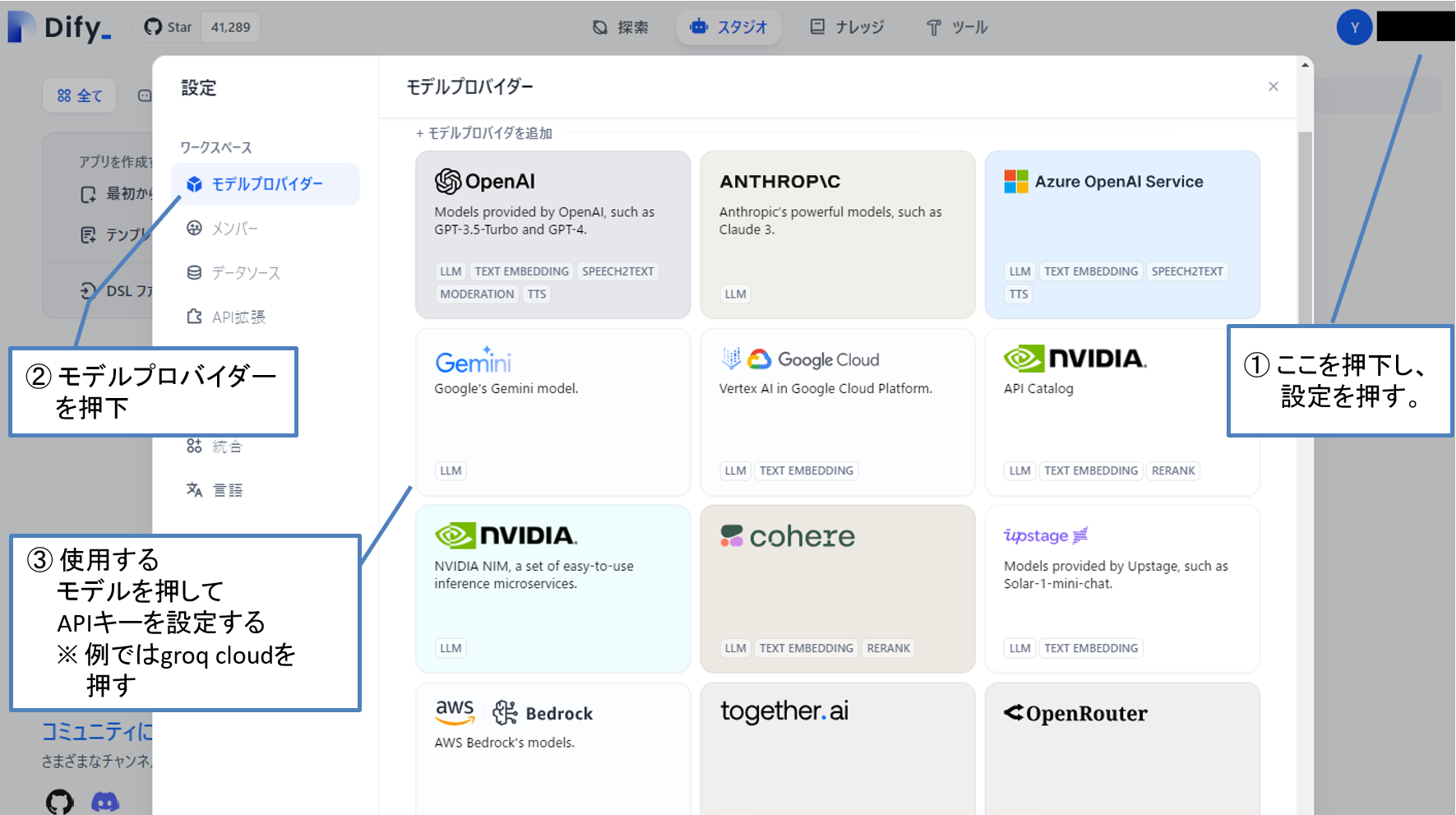
図6 初期設定の流れ
これでDifyを使用する為の最低限の設定は完了です。
ユースケースを持たすための構成作成について
ここからはユースケースに沿った設定をしてみましょう。
「NW上の機器の状態確認」を実現するには「ユーザの質問文とあわせて、対象機器の情報を集めた上で、質問文と機器情報を統合してLLMモデルに渡す」構成が良いだろうと記載しました。
上記を達成するには、以下のような手順が想定されます。
① ユーザに対象機器のIPアドレスと、質問文を入力してもらう
② 該当IPアドレスの機器にAPIでCPU使用率、メモリ使用率をとりに行く
(httpリクエストを実施)
③ ①のユーザの質問文と②の結果を踏まえて、LLMモデルに問い合わせる
④ その結果を出力する
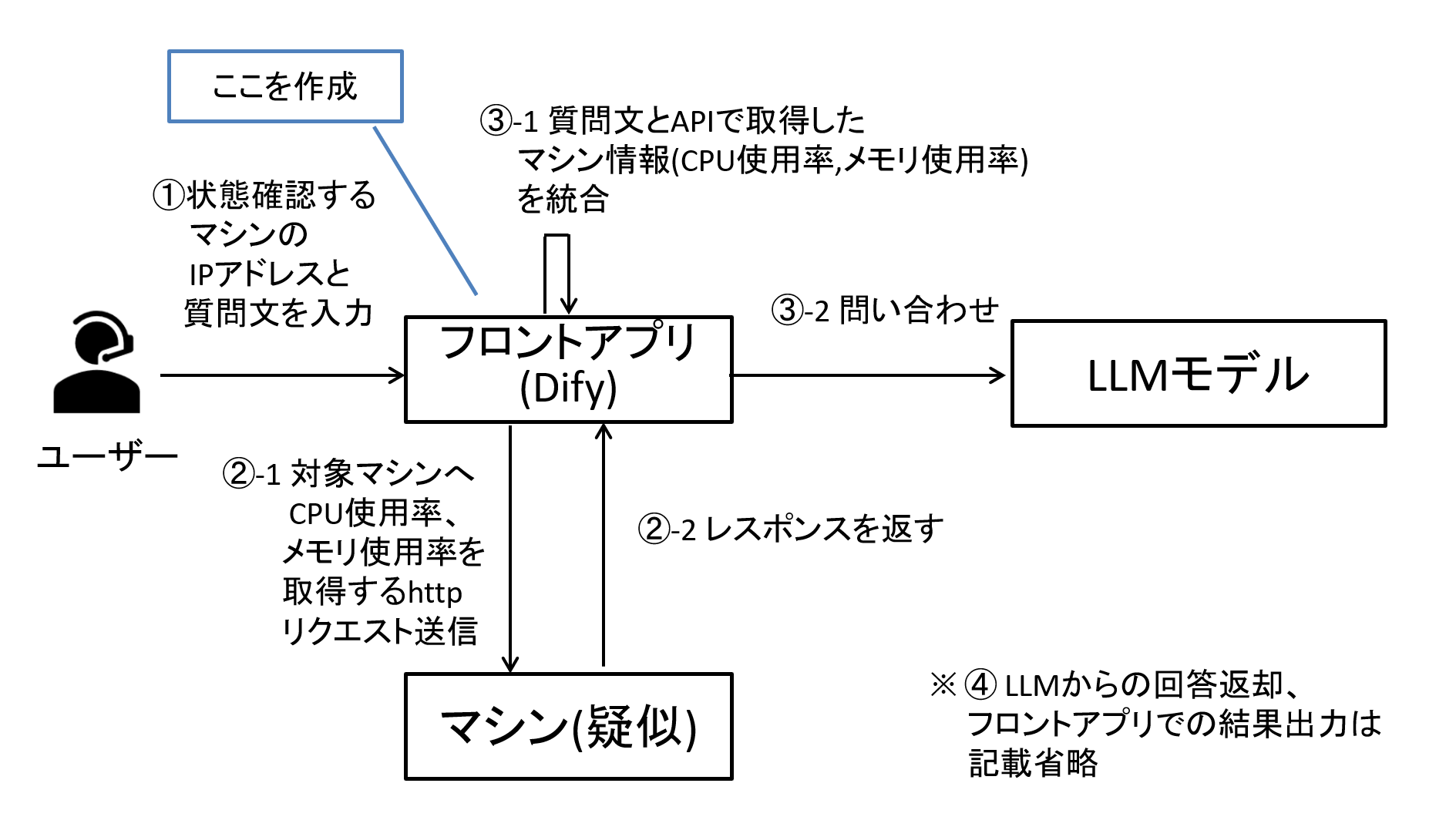
図7 今回Difyで作成するフロントアプリのイメージ
上記から通常のLLMに質問する構成より、やや条件が多いかと思います。
このようなケースでは「Chatflow」機能を使うと良いでしょう。
スタジオタブから、アプリを作成する > 最初から作成 を押して、チャットボット, Chatflowを指定しましょう。
※ 今回は上記のようにフロントアプリで実現する事の条件が多い為、Chatflow機能を使用します。
基本的なものであれば図7のChatflowの横にある「基本」を選ぶ事で、より簡単にフロントアプリが作成できます
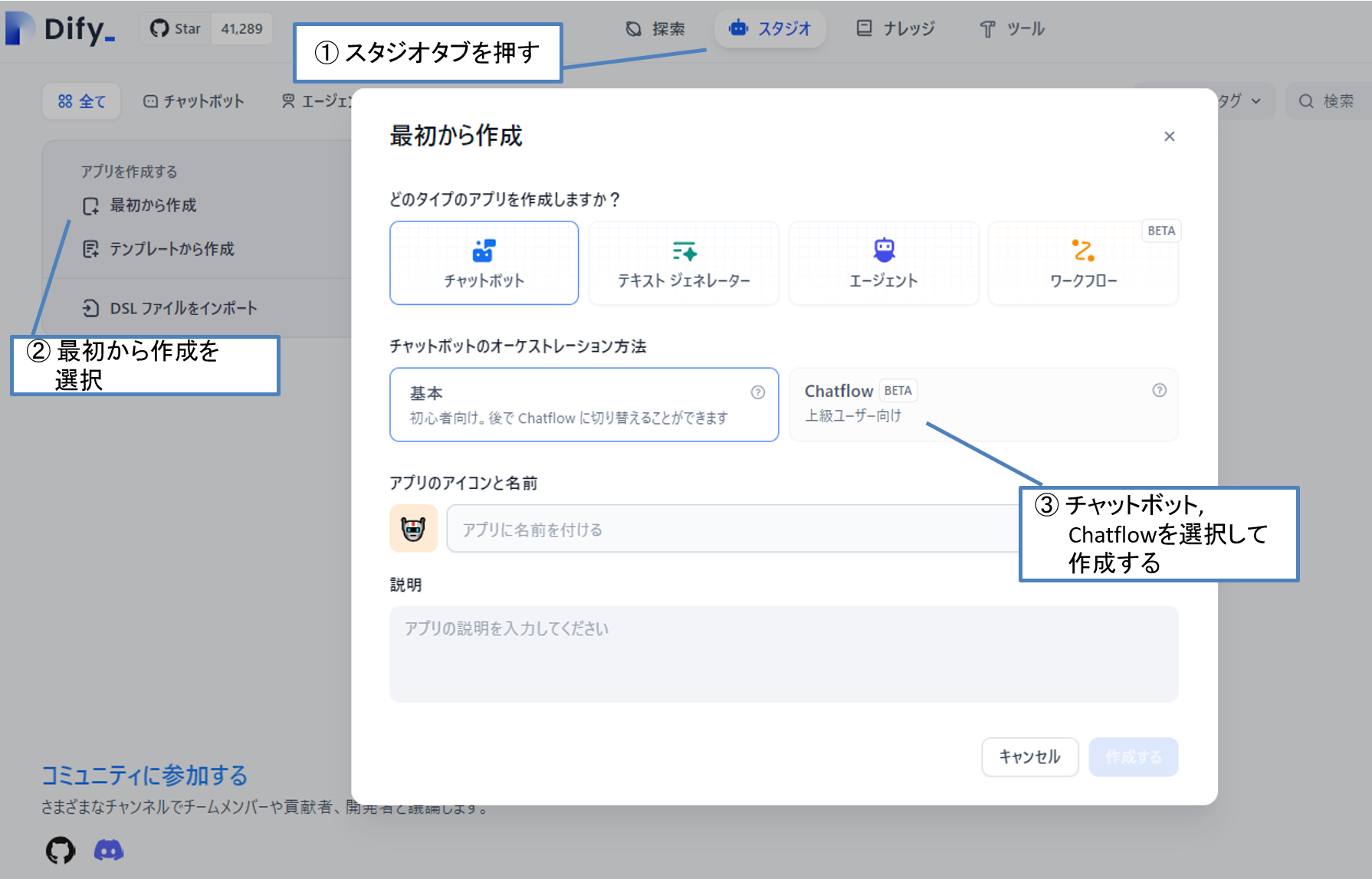
図8 Chatflowの新規作成の流れ
Chatflowではノーコード・ローコードツールでよくみるような処理の流れを指定する事ができます。
図8の画面にはChatflowとは別に「ワークフロー」という項目があります。
これもChatflowと同様に、処理の流れを指定することができる機能です。
違いは、ワークフローは人との会話なしに処理を流れを実行する仕組みに対し、Chatflowは人との会話を行うことが前提となっている点です、
例えば人との会話(Chatflow)の場合は、1度質問して回答をもらった後に追加質問をするというように、やり取りが単発では終わらずに何往復もする(過去の会話履歴を参照する)可能性があります。
一方ワークフローは、1回の呼び出しで完結するイメージです。
Chatflow機能とワークフロー機能、処理の流れを作るという点で同じようなものに見えますが、よくよく考えると細かな違いがあります。
※ 機能的な違いは上の通りですが、ワークフローは広義の意味で「処理の流れ」を示す場合もあります。その場合、ワークフローに関する機能というと、どちらも当てはまります。
話を今回の例(Chatflow)に戻します。
前述の①~④の手順を満たすには以下のような設定となります。
左から右へと処理が流れていきます。
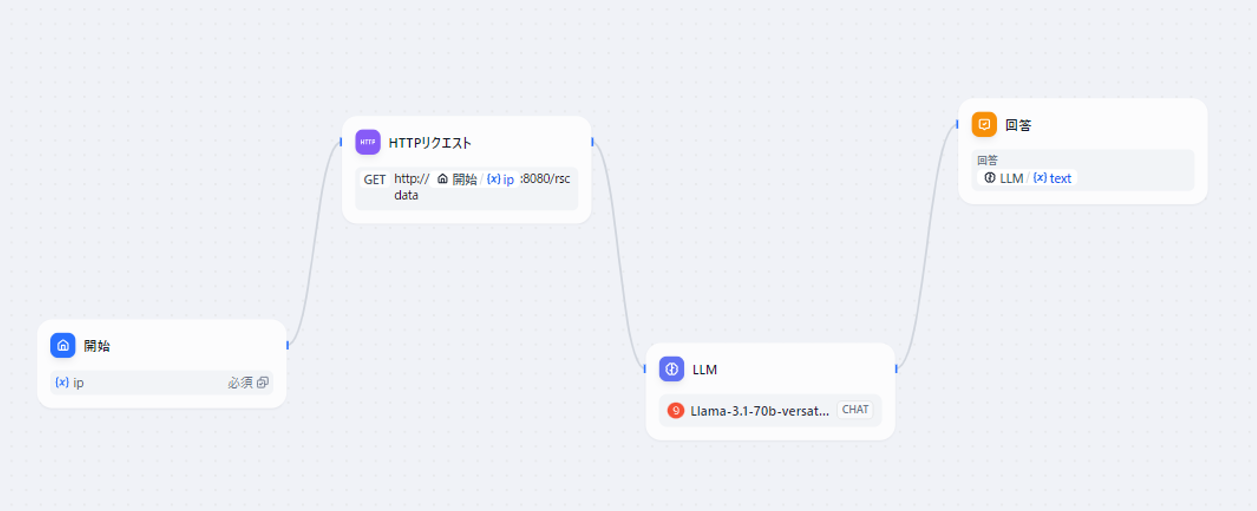
図9 作成するChatflowの全体像について
以下でそれぞれの処理について説明したいと思います。
まず①について設定します。
この処理に紐づくのが「開始」ボックスとなります。
開始ボックスでは「IPの入力受付」と「質問文の受付」を設定します。
が、ユーザからの質問文は「sys.query」として扱われ、本項目は初期から「開始」ボックスに設定されている為、追加設定不要です。
よって「IPの入力」を設定できるように追加設定します。
今回は「10.0.2.15」「10.0.3.15」「10.0.4.15」の3つの機器がいる想定で考えましょう。
存在しないIPを指定されたくない為、存在する機器のIPしか指定できないように選択式で設定する形にしたいと思います。
設定は以下のように行います。
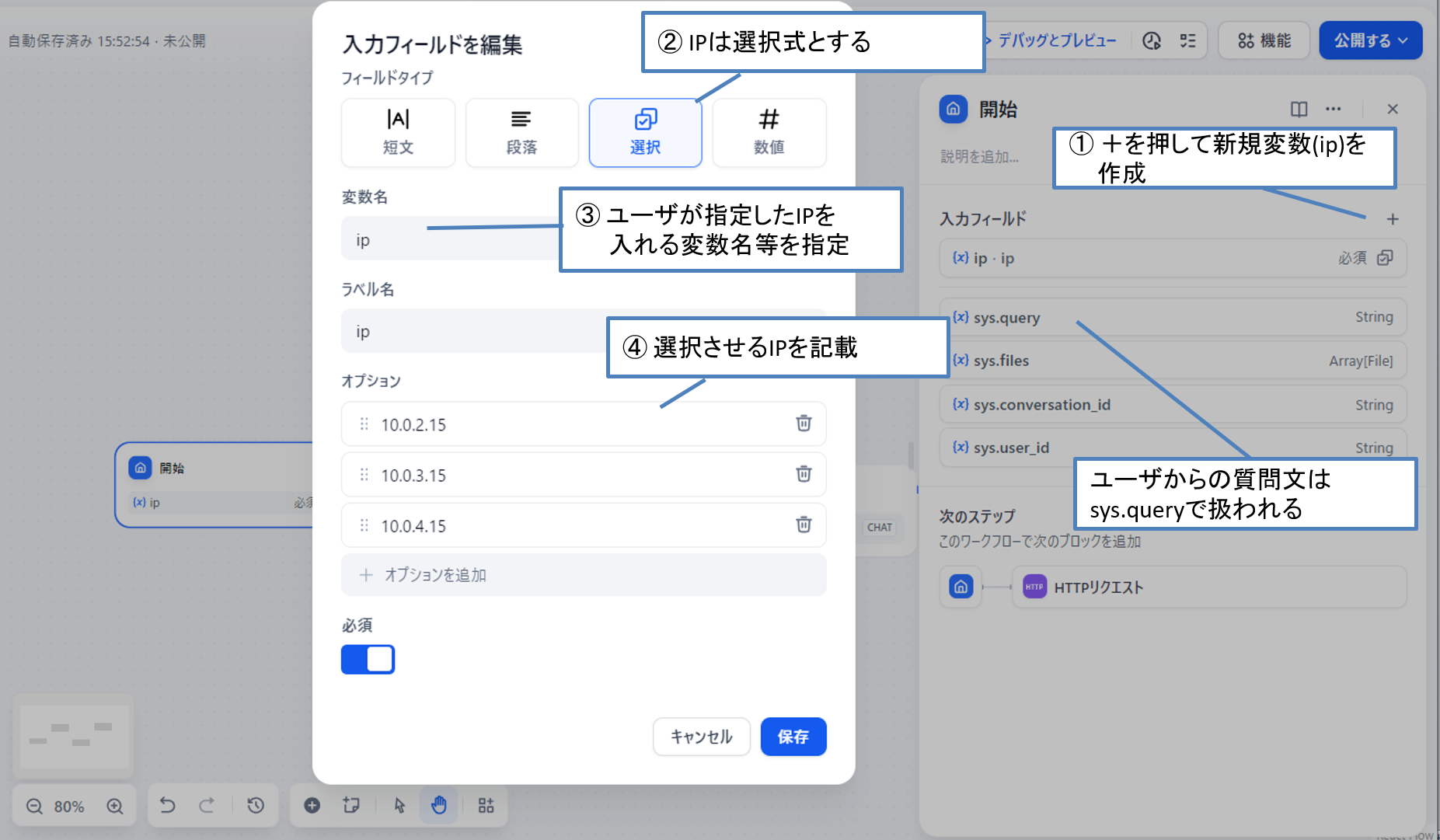
図10 ユーザに入力されるIPアドレス情報の設定について
次に②に紐づく処理を作りましょう。
NW機器、あるいはOpSやEMSからHTTPリクエストでCPU使用率とメモリ使用率を受け取ると想定し、HTTPリクエストの設定を行います。
今回のリクエスト先は「http://マシンのIP:8080/rscdata」としましょう。
この場合、以下の図のように設定します。
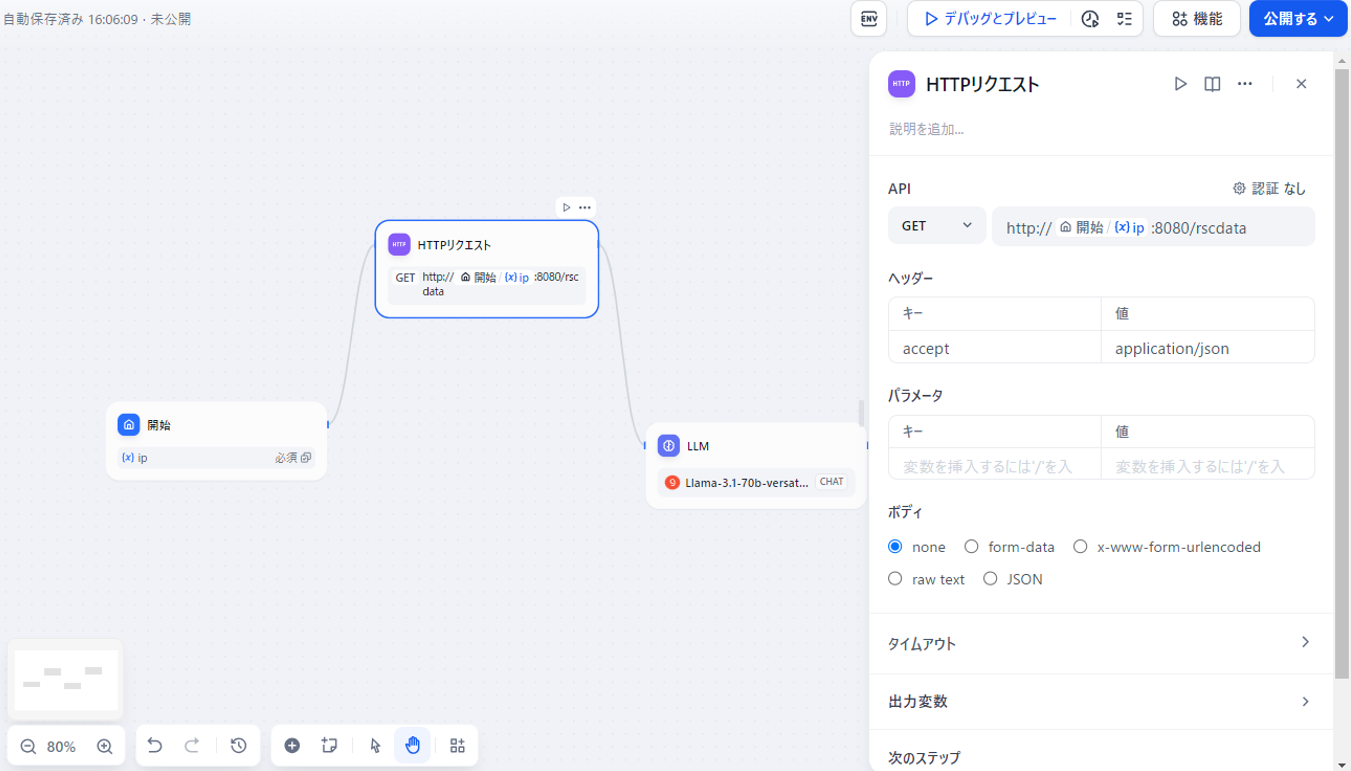
図11 HTTPリクエストの設定について
リクエスト先のURIには青文字で(x)ip とありますが、これは「開始」ボックスでユーザが指定したIPを登録するため、変数を使っている為です。
また、実際にはNW機器か、OpS/EMSによってURIが異なる事が考えられます。
NW機器だけで考えても機種やメーカーによっても異なるでしょう。
この場合、「特定の値の場合はこのリクエストを送る」といった分岐処理を入れることが可能ですので、そのようなボックスを入れると良いでしょう。
今回は簡易な例とする為、URIは共通としています。
なおリクエストの結果(レスポンスのbody部)は「body」変数として自動設定されます。
その為、出力変数の追加設定は不要です。
次に③に紐づく処理の設定となります。
ここでは使用するモデルの設定の他、「システムプロンプト」を指定します。
システムプロンプトとはLLMに渡す質問文と考えて頂いて構いません。
何も考えずユーザの質問文だけ渡す場合は、ユーザの質問文を入れる変数である「sys.query」だけ指定すればよいでしょう。
今回のケースではHTTPリクエストの結果(body)もあわせて与える必要があります。
この事も加味すると、下記のような設定となります。
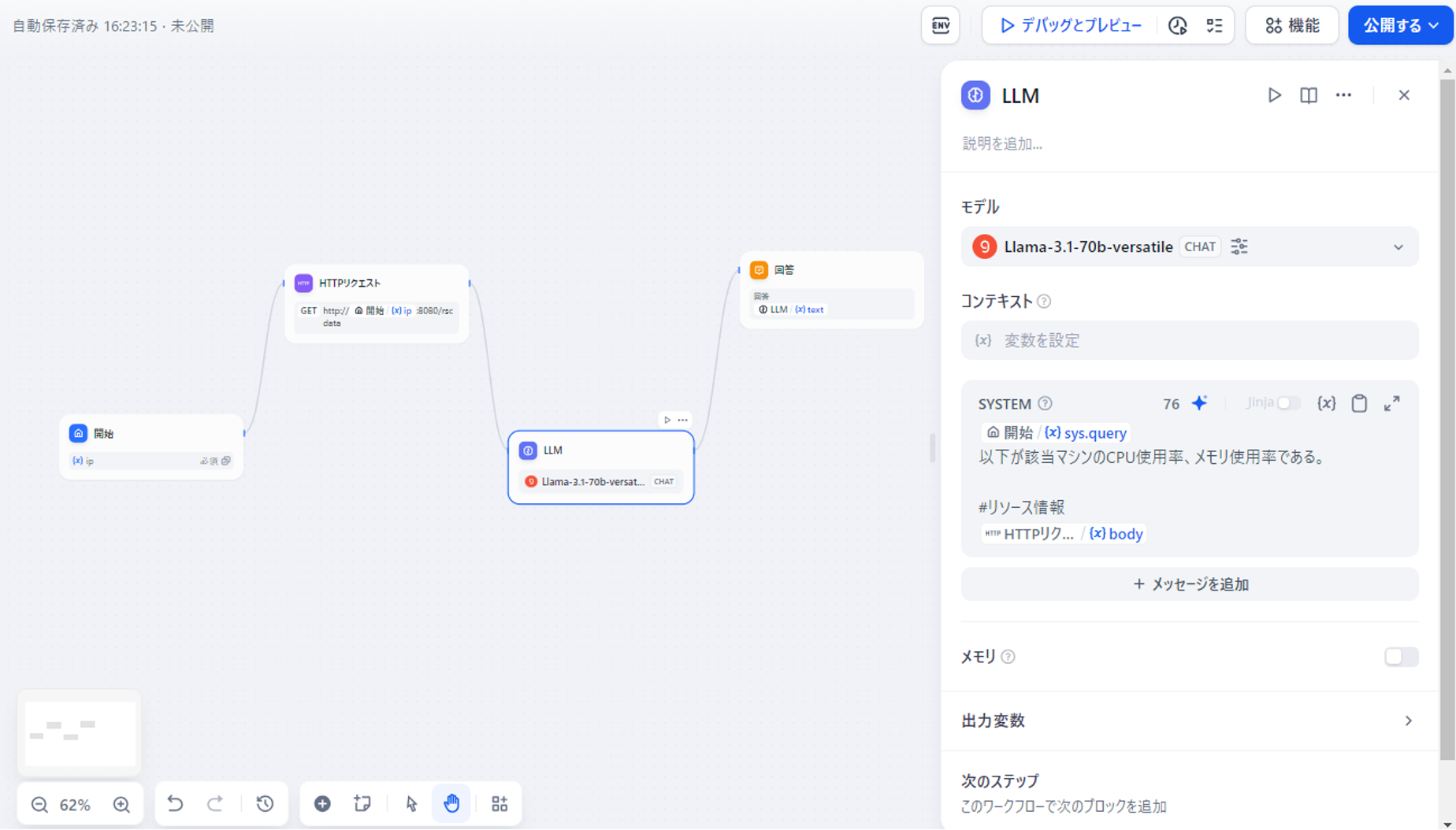
図12 LLMボックスの設定について
「SYSTEM」欄が「システムプロンプト」の欄となります。
ユーザがどういった質問文を投げるかわからない為、念のため、ユーザ質問文の下に「以下が該当マシンのCPU使用率、メモリ使用率である」という文言を、ユーザに見えない形で仕込んでおきます。
ここに記載した形で、LLMモデルに問い合わせを行います。
なお結果はtextと呼ばれる変数に格納されます。
最後は④に紐づく処理で、回答の表示となります。
これは上記に記載したtext変数を表示する形とします。
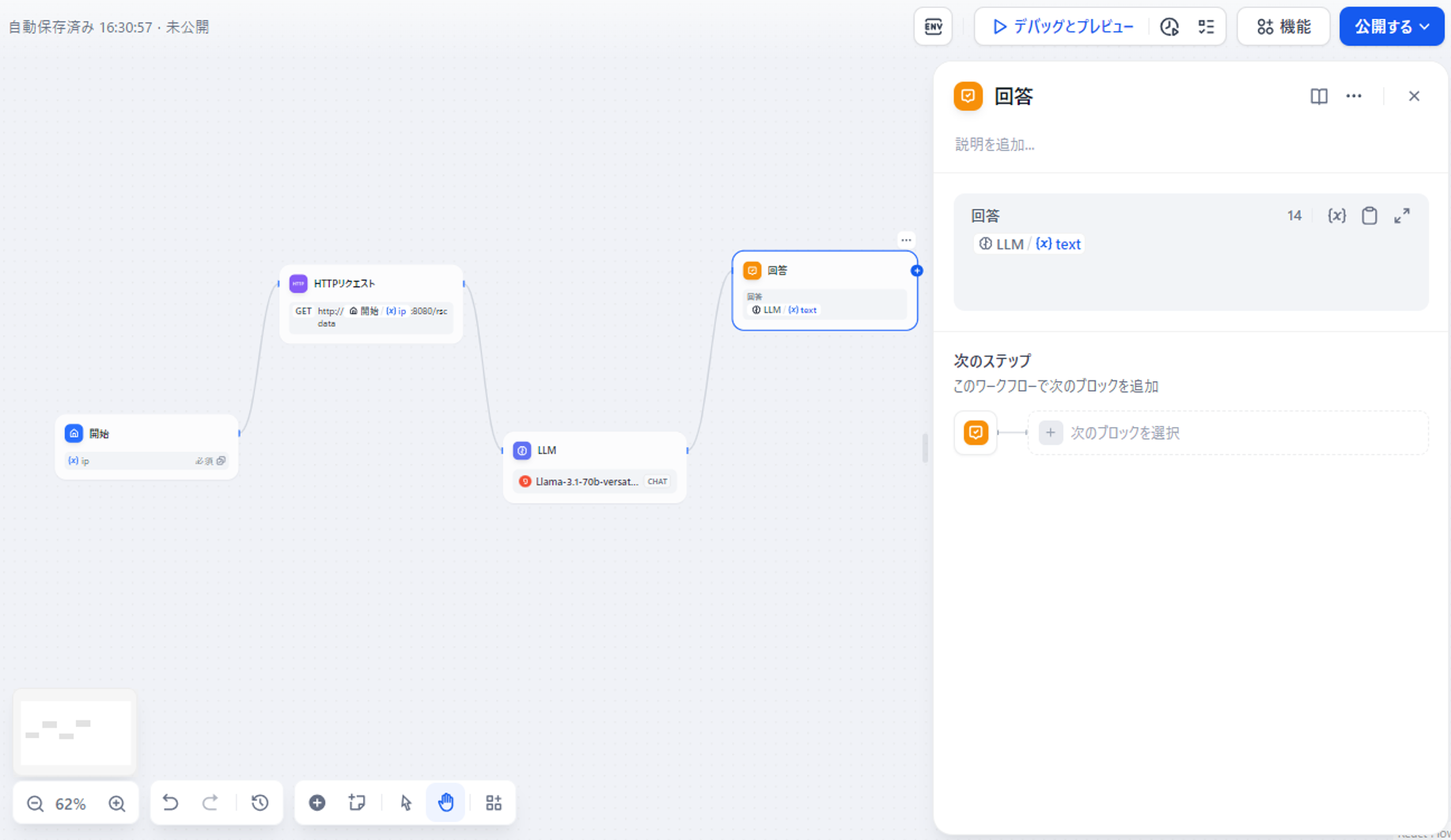
図13 回答ボックスについて
さて、これでChatflowができましたが、想定通りに動くかチェックをしましょう。
「デバッグとプレビュー」を押すと動作確認が行えます。
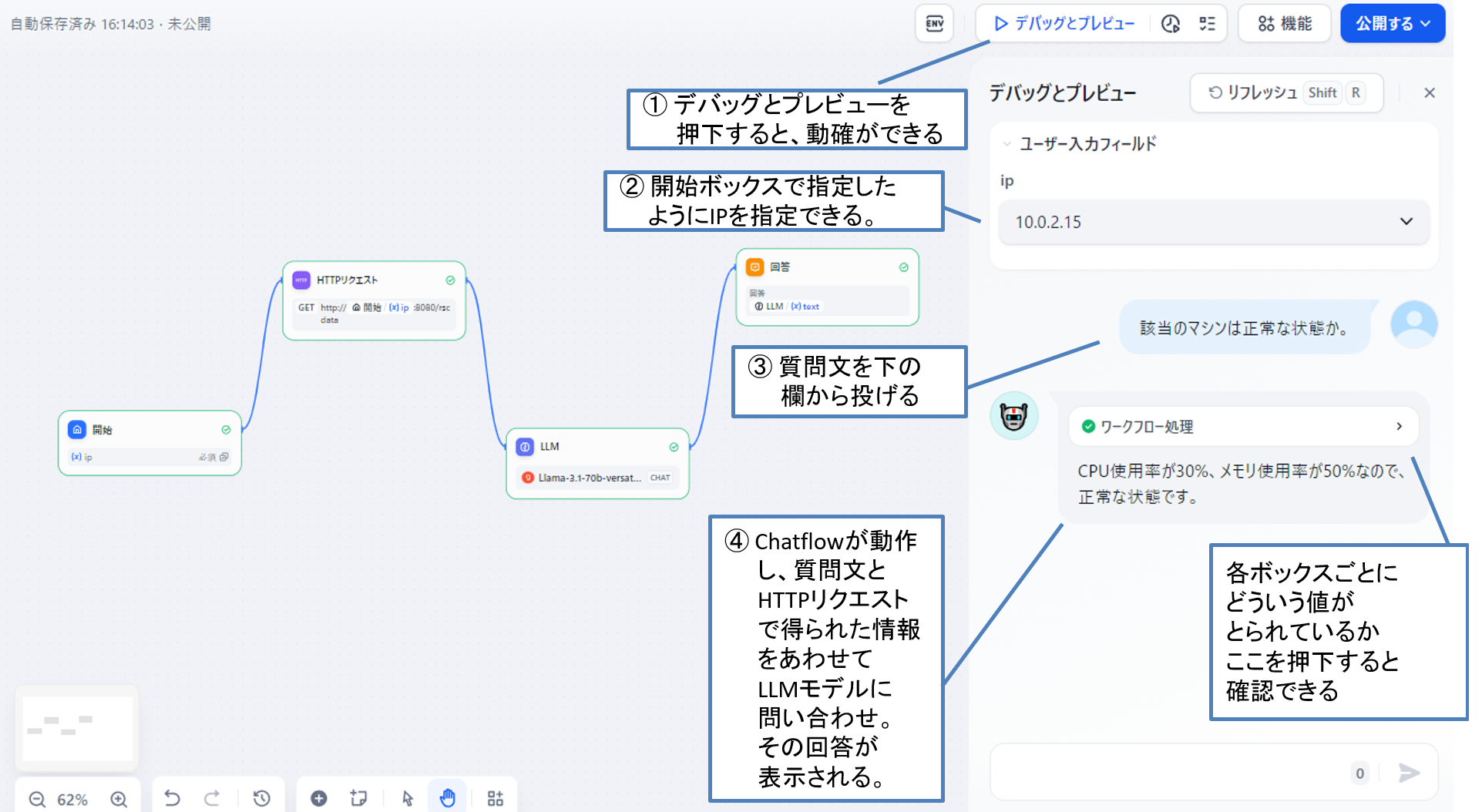
図14 動作確認の例
上の例ではユーザはマシンのIPをプルダウンから指定し、質問文で「該当のマシンは正常な状態か」と確認しています。
回答は図の通りとなります。(HTTPリクエストの結果、該当マシンのCPU使用率は30%、メモリ使用率は50%程度だったようです)
例はここまでとしますが、この後にAPIとして外部から処理を呼び起こす事も可能です。
なお今回、HTTPリクエスト先はDify外でFlaskを使って簡易につくっていますが、リクエスト先から返す値をより実戦的にすることで、より複雑なケースも試すことが可能になります。
上記例のように「特別なつくりが必要」と思える構成でも簡易に作ることができました。
このように様々なケースに向けて簡易に作ることができる為、LLM構成を作成する上での検証や調査に非常に向いていると考えられます。
おわりに
今回はDifyについてその説明、ユースケースと、Chatflow機能を使ったフロントアプリ作成例を紹介しました。
LLMは近年急速に進歩していますが、一方で「周りが使っているから自社にも適用しよう」という考え方は推奨されません。
例えば自社の業務のどこに何を狙って適用するのかユースケースを整理すると、その適用範囲によりユーザが入力した情報を学習データとさせたくない場合が出てくるかもしれません。
その場合には、使用するモデルやサービスに制約が出ると考えます。
上記は一例ですが、他にもコスト的な観点や「そもそもユースケースを達成できるのか?」といった調査を行う事も推奨されます。
これらの結果から最適な構成で適用するのが理想といえます。
上記ユースケース検討や調査、様々なLLMモデルの比較などにDifyは向いていると考えます。
本記事、またはそれ以外のネットワーク関連に関しての問い合わせやご意見がございましたら、以下にご連絡ください。
ここまでご覧いただき、ありがとうございました。
本件に関するお問い合わせ



<<<<著者プロフィール>>>>
フューチャーネットワーク事業部
第一ビジネスユニット
山口 佳輝(YAMAGUCHI YOSHIKI)
NWに関係したシステム開発を担当しています
>>>>>>>>><<<<<<<<<
![]()