大規模システム開発における「進捗報告・品質保証・I/F調整」のリアルと教訓
本記事では、大規模システム開発の特徴とマネジメントの難しさに関する、自身の取り組みをお伝えします。




目次
1.はじめに
2.進捗状況の「見える化」
2-1.なぜ進捗状況は「色」で語るべきなのか
2-2.鳥瞰図の目的と構成
2-3.報告タイミングの定期化
3.品質保証体制の強化とトラブル管理
3-1.品質保証体制の強化とトラブル管理
3-2.試験期間中のトラブル管理
3-3.【事例1】官公庁系業務システムピーク時の性能問題(オンライン画面接続不可)
3-4.【事例2】官公庁系業務システムのログイン認証のエラー発生
4.他システムとのI/F調整と再試験
4-1.本番環境との接続調整
4-2.再試験の工数膨張を防ぐ工夫
4-3.多方面とのI/F調整の難しさ
5.おわりに
1.はじめに
大規模システム開発プロジェクトは、単なる「計画通り進める」だけでは上手くいきません。複数ベンダ、複雑な要件など、現場には想定外の課題が次々と発生します。PMとして重要なのは、進捗報告の精度とタイミング、品質保証体制の強化、そして他システムとのI/F調整をいかに乗り越えるかです。第3回では、実際の経験を踏まえ現場で役立つ具体的な工夫と教訓を紹介します。
2.進捗状況の「見える化」とI/F調整の難しさ
2-1.なぜ進捗状況は「色」で語るべきなのか
大規模システム開発において、進捗報告は単なる「順調」「遅延」の二元的な情報では不十分です。幹部層などが求めているのは、プロジェクト全体の健全性とリスクの所在を一目で把握できる情報です。個別タスクの進捗率やWBSの詳細は、現場担当者には有用ですが、意思決定を担う層にとっては「このまま順調にいくのか」「どこに問題があるのか」「どこに追加リソースを投入すべきか」が重要です。
そこで導入したのが、鳥瞰図による色分け表示です。鳥瞰図とは、システム全体を俯瞰できる図で、各機能や性能の出来栄えを色で示すことで、進捗だけでなく品質や性能保証の状態を直感的に把握できる仕組みです。
2-2.鳥瞰図の目的と構成
従来の進捗報告は、WBSやガントチャートを用いて「タスクの完了率」を示すことが中心でしたが、この方法では、システム全体の完成度や性能リスクを直感的に把握することが難しいという課題があります。特に大規模システム開発プロジェクトでは、進捗率が高くても、性能面で重大な問題が潜んでいるケースが少なくありません。こうした状況を幹部層に正しく伝えるために導入したのが、鳥瞰図による見える化です。
鳥瞰図の目的は、「進捗+品質+性能」を一枚の図で俯瞰し、意思決定を加速することです。単なる進捗率ではなく、システム全体の健全性を示すことで、幹部層は「どこにリスクが集中しているか」「どこに追加リソースを投入すべきか」を判断できます。以下は、鳥瞰図の一例です。
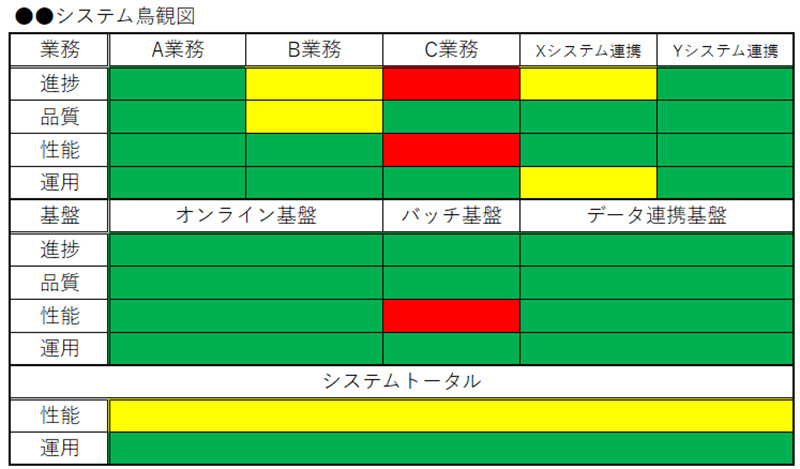
※図の補足(詳細は、下記の構成のポイントにて紹介)
緑=順調(計画通り進行、品質問題なし)
黄=軽微な懸念(性能や品質に注意が必要、監視強化)
赤=重大リスク(即対応が必要、幹部層の意思決定を要する)
■構成のポイント
・対象範囲
システム全体を機能単位等で状態を一目で把握できるように配置
・評価軸
進捗率だけでなく、試験結果や性能検証の状況を加味し、完成度を総合評価
・色分けルール
緑=順調(計画通り進行、品質問題なし)、黄=軽微な懸念(性能や品質に注意が必要、監視強化)、赤=重大リスク(即対応が必要、幹部層の意思決定を要する)
色分けの他、天気や記号で表す場合もあります。
・天気記号(晴、曇、雨)
・記号(〇、△、×)
この鳥瞰図を幹部層に提示することで、会議の議論は「どこに手を打つべきか」に焦点を当てることが可能となるため、決定のスピードが格段に向上すると考えます。さらに、色分けは心理的効果も持ち、緑が多ければ一部課題はあるが大よそ予定通り、赤が目立てば遅延や多くの課題が発生しているという危機感を共有できます。これは、追加リソース投入や優先度変更といった重要な判断を迅速化するうえで非常に有効です。
■PJ内チーム単位での工夫
・凡例の明確化
色の意味を定義し、報告資料に記載。
・更新頻度の設定
小タスクやマイルストーン到達時に定期更新し、情報の鮮度を維持。
・コメント付加
色だけでなく、簡潔な背景説明と次のアクションを添えることで、次のアクションが正しいか判断を仰ぐ。
2-3.報告タイミングの定期化
幹部層へは、工程完了時やマイルストーン到達時に必ず共有します。「報告の遅れ=リスク管理ができていない」と見なされることもありますので、プロジェクトの規模により、4半期単位、毎月等の定期報告を仕組み化することが重要です。
■コメントの付加
2-2では、色分けについて紹介しましたが、色分けだけでは「なぜその状態なのか」が分かりません。例えば、機能Aが性能試験で応答遅延が発生しているとします。その遅延に対する対処方法としてどのような試験を実施しているのか、また複雑かつ説明だけでは分からない場合は、図を作成して具体的にどのような問題が発生しているかを示します。
このようなコメントにより、幹部層は「現状+次のアクション」を理解でき、意思決定に役立つと考えます。
3.品質保証体制の強化とトラブル管理
3-1.品質保証は「工程ごとに仕組み化」
品質保証は試験工程だけでなく、要件定義からの各工程において仕組み化することが重要です。以下に、設計フェーズにおける品質ゲートの例を紹介いたします。
対象 |
基本設計書 + 詳細設計書 ⇒2,500ページ |
関与 |
ベンダ3社 + 社内レビュー担当者10名 |
レビュー期間 |
実施期間2週間 |
指摘件数 |
12件 |
①課題事項
・性能要件が一部設計書に記載されていない。
⇒記載されていないことにより、負荷試験実施時に他試験に影響が出る推測。
②レビュー観点の詳細化(一部紹介)
・業務ロジック、性能要件、セキュリティの観点からチェックリストを作成。
・業務フローで定義された入力項目が設計書に全て反映されているか。
・業務フローに記載は無いが、例外処理として運用で発生するケースが設計に含まれているか。
・応答時間要件(通常:3秒以内、ピーク時:8秒以内)やバッチ処理(60分以内等)、リトライ回数、これらを達成できなかった場合の、他システムへの影響や対応方法の補足資料の追加作成。
③重大指摘の即時対応ルール
・重大指摘は当日中に修正+再レビューを義務化
・修正状況について、どこかどのような状況なのかを分かるように図式化し、修正を実施
3-2.性能保証・品質保証のポイント
■影響度・優先度
試験工程では、トラブル発生は避けられません。重要なのは「管理」する仕組みです。試験工程でトラブルが発生した際、最も重要なのは「どの問題から優先的に手を付けるか」を即座に判断できる仕組みです。単に、重大・軽微といった感覚的な分類ではなく、業務影響・性能影響・法令遵守の3つの観点で評価します。
例えば、業務影響が大きいトラブル(受注処理や出荷処理ができないなど)は最優先で対応します。一方、性能影響はピーク時のレスポンス低下などは、システムを利用できないなどに直結するため、優先度を高く設定します。法令遵守に関わる問題(個人情報の取り扱い、セキュリティ要件の不備)は、影響範囲が広いため、幹部層への報告と並行して対応を進めると良いと考えます。
■解決に向けての役割分担
トラブル発生時によくあることとしては、結局誰が中心となって、進めるかということです。勿論PMが全体を管理することは前提となりますが、トラブル発生直後に、必ず「担当者(担当ベンダ)」「責任者」「対応期限」「各担当の役割明記」を記載し、関係者が把握することです。
担当 |
役割 |
なぜ重要か |
|
試験実施推進 |
|
|
|
トラブル解決推進 |
|
|
|
トラブル管理 |
|
|
3-3.【事例1】官公庁系業務システムピーク時の性能問題(オンライン画面接続不可)
申請が集中するタイミングで、オンライン画面が全く接続できない状態に陥りました。
■背景と課題
・通常時のTPS :500TPS(Transaction Per Second)
・ピーク時の実態:制度改正などに伴い、申請が集中し600TPS超のアクセスが発生
※本システムでは、リクエスト処理中はセッションおよび通信コネクションを保持する設計となっており、処理時間の長期化やリトライ発生時には、TPSの増加以上に同時接続数(コネクション数)が増加する特性があった。
⇒結果、各種画面がタイムアウトエラーになり、ユーザからの問い合わせが殺到。
■原因分析
当システムでは、処理中にコネクションを保持したままとなる設計や、応答遅延時のリトライにより同時コネクション数が積み上がり、結果としてFWの上限値を超過した。
こうした要因が重なった結果、外部ファイアウォール(以下、FW)およびアプリケーション設計における複数の要因が重なり、同時接続数の増加時にシステム全体の処理能力が著しく低下したことにより発生した。直接的な原因は、外部FWに設定されていたコネクション上限値が10,000であり、業務要件として想定されていたピーク時の同時接続数を下回っていたことである。この設定不備により、同時接続数が増加した際にコネクション不足が発生し、正常な通信が確立できない状態となった。その背景には、複数の原因が存在している。
①HW業者による外部FWのパラメータ設計・設定が、業務要件やシステム全体の接続特性を十分に考慮したものになっておらず、ピーク負荷時の挙動を前提とした設計が行われていなかった点が挙げられる。
②外部FWにおいて、応答遅延が発生した際のリトライ接続パケットを破棄してしまうバグが存在しており、これが通信の再確立を妨げ、接続失敗や遅延を助長する要因となっていた。
③端末からのファイルアップロード処理において、本来の用途とは異なる共通処理を誤って使用していたことにより、セッションタイムアウト値が60分に設定されていた。その結果、リクエスト完了後も不要なセッションが長時間維持され、サーバ側のメモリが過剰に消費された。これにより、Javaヒープ領域の枯渇やGlobal GCの頻発・長期化が発生し、サーバ処理の遅延がさらに拡大する悪循環を招いた。
④ポータル用APサーバから別のAPサーバの機能をリモート起動する必要があり、RMI Proxyを用いた実装が採用されていたが、この方式ではアプリケーション側でのコネクション管理が適切に行われず、使用済みコネクションが解放されない状態となっていた。その結果、不要なコネクションが蓄積され、外部FWおよびサーバリソースの枯渇を加速させる要因となった。
上記の4点の要因が相互に影響し合い、同時接続数の増加を契機として、通信遅延、処理遅延、さらにはシステム全体の性能劣化へと発展した。
■教訓と対応策
教訓としては、以下の4点です。
・インフラ機器(FW等)のパラメータ設計は、単なる製品デフォルトや過去実績に依存せず、業務要件に基づく同時接続数・通信特性を前提に設計すべきである
・製品やバグ・制約事項は、性能・品質リスクとして事前に洗い出し、想定外動作を前提とした検証や設計上の回避策を講じる必要がある
・APの共通処理やリモート呼び出し方式は利便性が高い一方で、セッション管理やコネクション管理の影響範囲を正しく理解する
・個別には軽微に見える設計ミスや設定不備であっても、同時に発生すると、性能劣化を連鎖的に増幅させるリスクがある
対策としては、以下5点です。
・外部FWを含むネットワーク機器について、業務要件に基づいた同時接続数・ピーク時トラフィックを明確に定義し、それを前提としたパラメータ設計・設定を実施。また、設計内容をレビューし、性能観点での妥当性を確認する体制を構築。
・採用製品の既知バグや制約事項を事前に収集し、性能・可用性への影響を整理したリスク一覧を作成。バグが性能劣化を引き起こす可能性がある場合は、回避策・代替手段・監視項目を事前に定義する。
・共通処理の利用範囲を見直し、処理特性に応じた適切なセッションタイムアウト値を設定。不要なセッション・コネクションが残留しないよう、解放タイミングや上限管理を明確化。
・リモート呼び出し方式を採用する場合は、コネクション管理方式を明確に理解した上で設計。管理が困難な場合は、フレームワークやMW標準のコネクション管理機構を活用する。
・同時接続数の増加時に、本番相当の負荷試験・長時間試験を実施する。単なるレスポンスタイム測定に留まらず、セッション数・コネクション数・メモリ使用量・GC発生状況を監視指標として組み込む。
3-4.【事例2】官公庁系業務システムのログイン認証のエラー発生
■背景と課題
本システムでは、業務開始時間帯に複数の利用者が同時にログインします。平日の始業時間前後は、LDAPサーバへの認証要求が短時間に集中した結果、レスポンス遅延が発生し、利用者側でログインエラーが頻発する事象が発生した。調査の結果、LDAPサーバの設定において同時接続数やスレッド数、タイムアウト値などが実運用のアクセス特性を十分に考慮した設定となっておらず、ピーク時の負荷に耐えられない構成となっていたことが判明。業務中は発生しないものの、業務始業時間帯というアクセスが集中する時間に性能限界を超え、ログイン認証の失敗による業務開始遅延や問い合わせが殺到した。
■原因分析
LDAPサーバの同時接続数、処理スレッド数の設定が、実際の利用者数および業務開始時などに集中するアクセス数を想定した値になっていなかったのが原因です。
認証処理に関する性能試験や負荷試験が、ピーク時(業務始業時間帯)の同時アクセスを前提としたシナリオで実施されていなかった。認証基盤については、共通基盤であるがゆえに安定しているという前提認識があり、アプリケーション側と比べて設定・性能確認が十分に行われていなかった。
■教訓と対応策
教訓としては、主に以下の3点です。
・認証基盤やディレクトリサービスは、業務システム全体の入り口となるため、性能劣化が即座に広範囲へ影響を及ぼす。
・平常時に問題がない設定であってもアクセスが集中するタイミングを想定しなければ、潜在的な性能リスクは顕在化しない。
・MWや基盤系コンポーネントについても、業務特性を踏まえた性能要件定義と検証が不可欠である。
対応策としては、主に以下の4点です。
・業務開始時間帯の同時ログイン数を想定した性能要件を明確化し、LDAPサーバの同時接続数、スレッド数、タイムアウト設定等を見直す。
・認証処理を含めた負荷試験を実施し、ピーク時でも安定したレスポンスが維持できることを事前に確認する。
・認証エラーやレスポンス遅延を早期に検知できるよう、LDAPサーバの監視項目(応答時間、接続数、エラー率等)を強化する。
・共通基盤についてもアプリケーションと同様に「業務影響」という観点でリスク評価を行い、設計・設定レビューの対象に含める。
4.他システムとのI/F調整と再試験
4-1.本番環境との接続調整
全てのシステム開発案件では、他システムとのI/F仕様や試験計画の調整が重要です。特に、I/F先の対外システムとの接続試験は試験環境だけでなく、本番環境を利用して実施するケースも多くあります。さらに、本番環境への移行作業においても、接続確認や最終調整が必要となります。これらの本番環境での作業は、対外システムの運用ルールや業務影響を考慮し、週末や夜間など業務を実施していない時間に限定して実施することが一般的です。メンテナンス中画面の準備や作業開始前2時間前にログインできないようにするなど、事前に詳細に把握し、試験計画や移行計画に反映します。
4-2.再試験の工数膨張を防ぐ工夫
試験期間中は、特に対外接続試験において再試験が発生しやすく、工数の膨張が大きな課題となります。再試験が発生しやすくなる理由としては、環境差異や設計書には記載が抜けており明示されていなかった設定など外部要因の影響を受けやすいことに起因します。実行したところ、いきなりエラーとなるなども珍しくありません。再試験は単なる「やり直し」ではなく、発生した問題の原因分析と再発防止策の実装を伴うため、無計画に増えるとプロジェクト全体の進行に深刻な影響を及ぼします。例えば、事前疎通における対策としては、本番環境での接続試験前に、試験環境で実運用データに近いデータを用いた疎通確認を必須化。APの試験工程では相手システムで作成したバリエーションデータでの機能保証の実施。本番環境での接続トラブルやデータ不整合の発生を未然に防ぎ、再試験の発生頻度を大幅に抑制。ただし、設計書や仕様書に環境設定の詳細が十分に記載されていない場合など、誤った設定をしてしまうリスクがあるため、リスク軽減を図るため、環境設定情報の管理・誤った接続をし、本番環境に影響を与えてしまった場合にすぐに対応できるよう、体制の強化や接続環境の事前確認プロセスの徹底も併せて実施しました。
4-3.多方面とのI/F調整の難しさ
公共系案件では、各省庁・自治体との横断的な調整が不可欠です。政府指針は存在するものの、要件理解が統一されていないため、I/Fに関する試験で不整合が頻発しました。
【実際に経験したトラブル】個人識別情報連携システム
■概要
・各省庁で仕様解釈が異なり、試験段階で連携不具合が続出
・サービス開始日が公表済みで、スケジュール遵守が必須
この状況では、「誰がどの判断をするか」が曖昧になりがちです。結果として、試験工程で想定外の不具合が発生し、調整に膨大な時間を要しました。
■対応策
・優先度付けと期限設定
全トラブルをリスト化し、影響度に応じて解決順序を明確化。重大リスクは即対応、軽微な懸念は後回し。
・合意形成の場を設定
ベンダ・省庁間で一件ずつ議論し、責任範囲を明確化。
・スケジュール再調整の判断
必要に応じてサービス開始延伸も検討。これは政治的な判断を伴うため、幹部層への迅速な報告が不可欠。
この経験から学んだことは、「I/F調整は技術課題ではなく、合意形成の課題」ということです。PMは、技術的な解決策だけでなく、関係者間の信頼構築を同時に進める必要があります。
■複数ベンダ開発での注意点
複数ベンダが関与する場合、意識のズレが致命的な影響を及ぼすことがあります。
ソースコードをビルドする際に共通部品や他ベンダ作成部品を参照している等の場合は順序やIFやバージョン面の整合が取れていないとエラーが頻発します。
また、環境開放時の疎通確認が不十分だと、本格的な試験実施時にトラブルが頻発することとなり、トラブル改修待ちによる中断が発生し、試験工程が大幅に遅延します。実際、試験実施後に「試験中断」が発生し、試験工程が数週間遅延したことに加えて、小さな仕様差異により、再試験工数が膨張することもあります。
■教訓
・疎通確認の徹底
環境開放時に必ず接続確認を実施。形式的なチェックではなく、実データを用いた検証が必要。
・ビルド期間の確保
複数ベンダの成果物を統合する際、ビルド期間を十分に確保し、トラブル対応の余地を残す。
・認識共有の仕組み化
簡易なミスでも影響が大きいという認識を全ベンダに共有。定例会議でトラブル事例を共有し、横並び調査の実施、再発防止策を徹底。
PMとして重要なのは、「技術的な統合」だけでなく「文化的な統合」です。異なる企業文化や開発プロセスを持つベンダ間で、共通の品質基準と進捗管理ルールを確立することが、プロジェクト成功の鍵となります。
5.おわりに
大規模システム開発においては、進捗状況の「見える化」や品質保証体制の強化、そして多方面とのI/F調整がプロジェクト成功の鍵となります。特に、色分けによる鳥瞰図の活用や工程ごとの品質ゲート設置、トラブル発生時の明確な役割分担は、現場の混乱を防ぎ迅速な意思決定を促します。また、技術的な課題だけでなく、関係者間の合意形成や文化的な統合にも注力することが重要です。



{kind=link}
![]()