OpenStackSummitAustin報告第二弾運用者必見。運用系セッション
GW直前の4/25(月)-29(金)、アメリカ オースティンにて半年に一度のOpenStack Summitが開催されました。第2回の今回は運用者に見て欲しいセッションをご紹介します。




テクノロジーコラム
- 2016年06月07日公開
OpenStack Summit報告2回目は、運用者がOpenStackを扱う上で是非とも注目していただきたいセッションを2つご紹介します。
まずは運用者に見ていただきたいコンポーネントのご紹介です。
Enforcing Application SLAs with Congress and Monasca
https://www.youtube.com/watch?v=fTileOf4A2Y
CongressとMonascaを連携させることで、アプリケーションのSLAを確保しようというセッション
実際に運用してみると仮想マシンに割り当てられているリソース量と、リソースの実使用量は異なりますよね。
リソースの実使用量にあわせて割当量を変動できたら嬉しいですよね。
そんなときにMonascaの監視とCongressのポリシーを組み合わせると、必要以上に割り当てたリソースを開放することで全体最適化ができるのではないでしょうか。
たとえば、MonascaのCPU監視で2ヶ月間CPU使用率が5%以下なら、CPU数の割り当てを下げても問題ないはずとCongressにポリシーを設定しておくと、CongressからCPUのインスタンスサイズを変える処理を実行すると全体最適化ができますね。
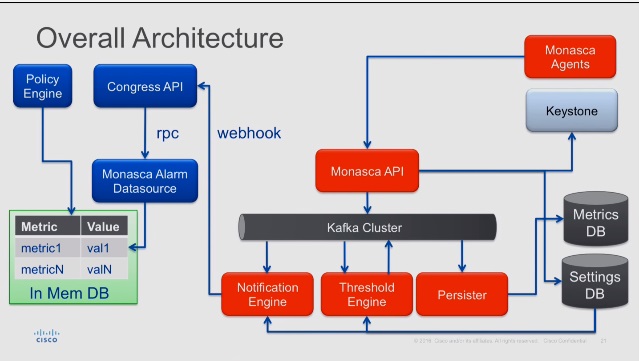
たしかに全体最適化の観点から考えると、過剰に割り当てているリソースは他のリソースにまわすことで無駄を省きたいですが、実運用の観点から見ると、稼働中のVMがいきなり停止->サイズ変更となるので、これを考慮した仮想環境の設計やアプリケーションを作らないといけないです。
実際に使うとなると事前に該当VMはLBにぶら下げておき、VMリサイズ前にLBから一端切り離す等の処理を入れる構成にするのが良さそうです。
Congress+Monascaの連携が実装されたら色々応用が利きそうですね。
たとえばずっと放置されていて使われていない幽霊VMを停止させたり、
パケットが通っていない幽霊仮想ネットワーク、ルータを消したり、
リソースの足りていない仮想資源に割り当てるリソースを増やしたり。
Congress + Monasca以外にも複数コンポーネントを連携させるセッションが多く組まれていましたが、どれも中心となっていたのはCongressかMonascaでした。
Congressはこれから流行りそうなコンポーネントなので、また別の機会に紹介したいと思います。
Monascaは「OpenStack Monascaで本番環境の監視はどこまでできるのか」の連載でご紹介していきます。
実際にトラブルが発生したら、運用者は何をしたらいいの?
Real World Troubleshooting Tips for OpenStack Operations
https://www.youtube.com/watch?v=Vn_CI3i6fTQ
実際にOpenStackを運用するとなると、さまざまなトラブルに見舞われると思います。
そんなときに問題解決のためには現実世界で何をすればよいのかを、How to形式で解説していきます。既に運用している方、これから運用をする人へのチュートリアルとしてオススメします。
普段運用している中で、これだけはぜひ押さえておいて欲しいというものをいくつか紹介します。
OpenStackコマンドが上手く実行できない。なぜかエラーになる。どうしたらいいの?
OpenStackコマンドのオプションにある「--debug」を付けると、実際に実行しているCURL文や、使用しているEndpoint、レスポンスのJSONが返ってきます。
debugオプションを使用すると、リターン文の中にリクエストID「req-*」が返ってきます。
コンポーネント内の処理は同一のリクエストIDでログファイルに記録されるので、何が起こったのかを追跡しやすくなります。
余談ですが、コンポーネントを跨いだ処理でも同一のリクエストIDで処理のログを追跡できるようにする機能の実装に弊社エンジニアも参加しており、Mitaka版ではいくつかのコンポーネントで実装されています。
ログ監視ってどうすればいいの?
障害をいち早く検知、解析を容易にするためにはどのような仕組みを用意するとよいでしょうか。
GraphiteやELK stackを活用すると、ダッシュボードへアクセスするだけでOpenStack環境の状態やログを確認することができます。
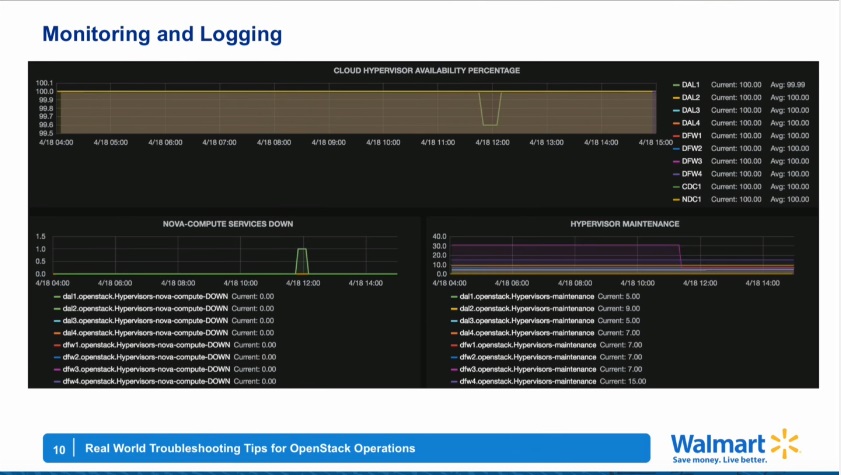
上記の図ですと、Nova-Computeが1台Downしている様子がグラフで可視化されて分かりやすくなっていますね。
OpenStackはコンポーネント毎にログ出力がわかれているので、一連の流れをログファイルから追跡するのは大変です。OpenStackを導入している方々に話を聞くと、ELK stack等のログ解析用サーバを用意するのがスタンダードになりつつあります。
OpenStackコミュニティでもOpenStackログ解析は課題になっており、監視用コンポーネントのMonascaにELK stackが搭載されました。詳細はMonascaの連載記事でご報告します。
他にもこのセッションでは、
・「VMにネットワーク疎通が取れない場合はどうすればいいのか」
・「Cinder Volumeが作れなかったらどうすればいいのか」
などが紹介されていました。
よく運用者が陥るトラブルなのでぜひ見ていただきたいと思います。
さいごに
今回のOpenStack Summitのテーマのひとつとして、「連携」というものがありました。
OpenStackはコンポーネント単体では機能が成熟してきており、今後は他のコンポーネントとの機能連携が課題となっています。Congress+Monascaも機能連携することで、OpenStackができる事を増やそうという試みです。
Austin Summitではクロスプロジェクトと呼ばれるコンポーネント間を連携させることを主題に置いたテーマが多数用意され、それぞれのコンポーネント開発者によって様々な意見交換がされました。
次回は一緒にAustin Summitに参加した本上から、技術系のセッションより最新技術の動向や、クロスプロジェクトで話し合われた内容についてご紹介します。



NTTソフトウェア株式会社
クラウドセキュリティ事業部
第一事業ユニット
![]()