Difyで学ぶ、RAGの精度改善手法 ~LLM活用入門6回~
RAGの精度改善手法であるHyDEとSelf-Routeについて説明します。またDifyを使った実現案も紹介します。




テクノロジーコラム
- 2025年08月07日公開
はじめに
こんにちは、NTTテクノクロスの山口です。
前回(第5回)まではRAGの基本を紹介してきました。
今回はRAGの精度を向上させる為の手法を紹介したいと思います。
RAGの精度改善手法は様々なものがあり、現在でも新たな手法が提案されています。
本記事ではその中から「HyDE(Hypothetical Document Embeddings)」と「Self-Route」と呼ばれる手法を取り上げたいと思います。
後半にはDifyを使い、これらの実現方法も含めて紹介します。
■ 目次
| 節番号 | 節タイトル |
| 1 | HyDEとSelf-Routeとは |
| 2 | ハンズオン: DifyでのHyDE実現について |
| 3 | ハンズオン: DifyでのSelf-Route実現について |
| 4 | 紹介手法の応用について |
[参考] 本連載の記事
本記事とあわせて、以下も良ければご確認ください。
| 連載番号 | タイトル | 概要 |
| 第1回 | 今だから知っておきたいDify!ノーコード・ローコードでLLM活用基盤を作ろう | Dify自体の説明とChatflow機能を使った例を取り上げています。 |
| 第2回 | 爆速キャッチアップ!LLM活用をリードするプラットフォーム群 | LLMの可能性をより広げるDify/Ollama/LangChain/Hugging Faceの紹介と、 DifyとOllamaでローカルLLMを活用したChatflow機能の利用に関して取り上げます。 |
| 第3回 | RAGとは?Difyから基本を学ぶ | RAGの基礎的な説明とDifyを使った実現方法を取り上げています。 |
| 第4回 | ローカルモデル利用のRAG実装で学ぶLangChainの基礎 | ベクトルDBを用いたRAGのサンプルコードから、LangChainの基礎を解説します。 |
| 第5回 | ローカルモデル利用のRAG実装で学ぶLlamaIndexの基礎 | ベクトルDBを用いたRAGのサンプルコードから、LlamaIndexの基礎を解説します。 |
| 第6回 | Difyで学ぶ、RAGの精度改善手法 | RAGの精度改善手法をDifyのChatflow機能を使いながら紹介します。 |
| 第7回 | ローカル環境で実現する、GraphRAGの基礎 | GraphRAGの基礎から、LangChainとNeo4jを使ったグラフRAGの実装例を紹介します。 |
| 第8回 | ローカル環境で実現する、Text-To-SQLとRDBを用いたRAG | Text-To-SQLと、それを活用したRDBを用いたRAGの実装例を紹介します。 |
| 第9回 | ファインチューニングとは?基礎を理解する | ファインチューニングとそのユースケース、手法を紹介します。 |
| 第10回 | Hugging Faceライブラリで実行する推論と学習の基礎(前編) | Hugging Faceのライブラリを使った、モデルのダウンロードや推論処理について紹介します。 |
| 第11回 | Hugging Faceライブラリで実行する推論と学習の基礎(後編) | Hugging Faceのライブラリを使った、ローカルモデルの学習処理と実行例について紹介します。 |
| 第12回 | AIエージェントとは?Difyから考え方を学ぶ | AIエージェントについて、Difyでの動作イメージも含めて紹介します。 |
| 第13回 | MCPとは?AIエージェントの可能性を広げよう | AIエージェントの可能性を広げる技術であるMCPについて紹介します。 |
HyDEとSelf-Routeとは
本節では、今回取り上げる手法であるHyDEとSelf-Routeについて紹介します。
まずHyDEですが、これはユーザの質問に対して一度LLMで回答を作ってからRAGの情報を取得する、という手法です。
通常のRAGでは「ユーザの質問文」を使って、RAGから情報を取得していました。
この際にユーザの質問があいまいすぎると、上手くRAGから情報が取得できない場合があります。
よってユーザの質問に対し一度LLMに回答を作らせて、理想となる回答に近い情報を使って必要な情報を取得する、というのがHyDEの考え方です。
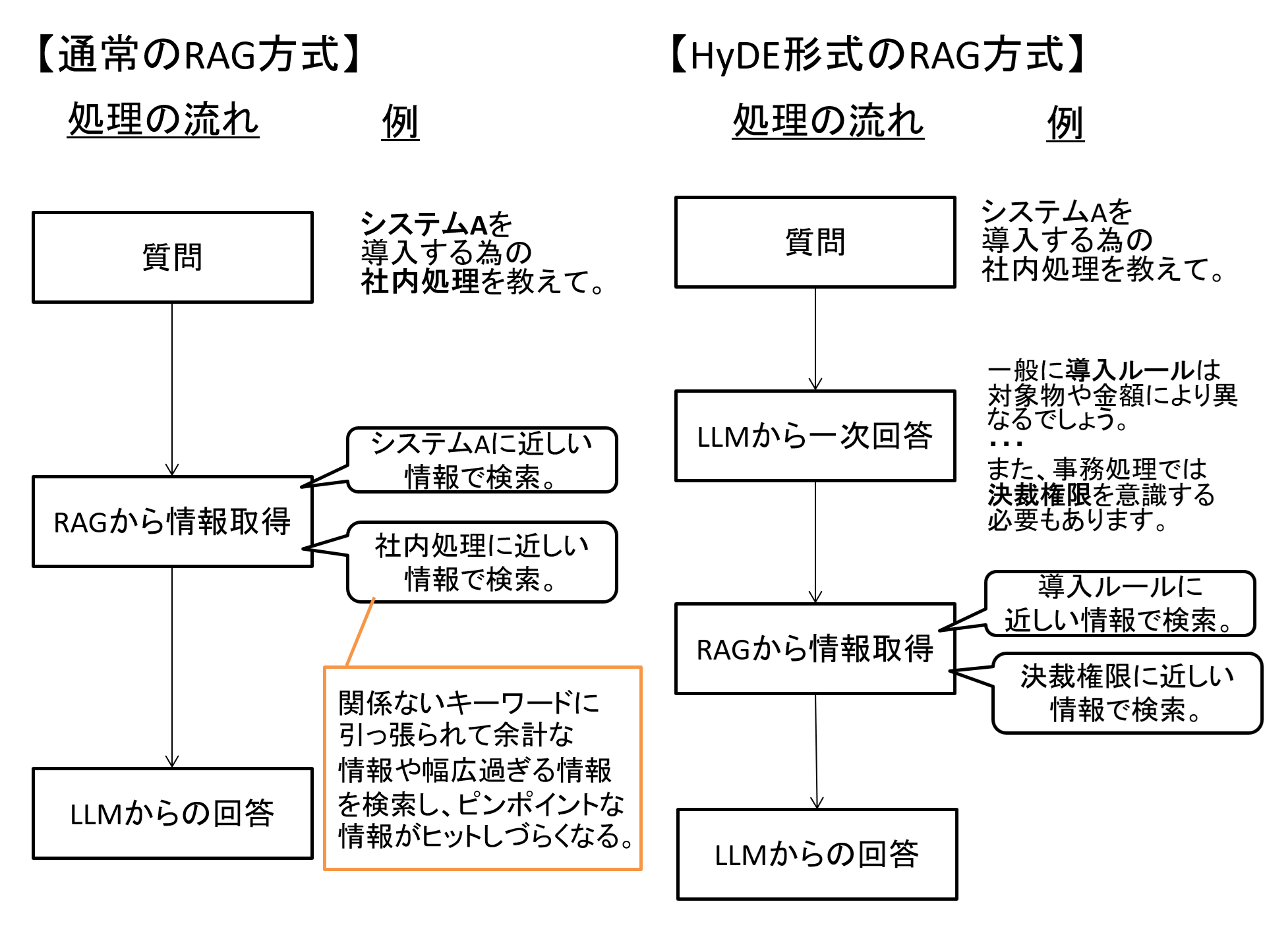
図1 通常のRAGとHyDEの違い
ただしユーザの質問が最初からかなり具体的だったり、LLMの一次回答が盛大にハルシネーションを起こしてしまったりすると効果が出ない場合もあります。
続いてSelf-Routeですが、これはユーザの質問とRAGから取得した情報をみて質問に回答できるかどうかを判定し、それに応じて処理を変える、という考え方です。
具体的には下図のように、「RAGから取得した情報を使わずに回答する」「RAG情報を使って回答する」「ドキュメント情報を全て埋め込んで質問する」という3つの処理のどれを実行するか判断します。
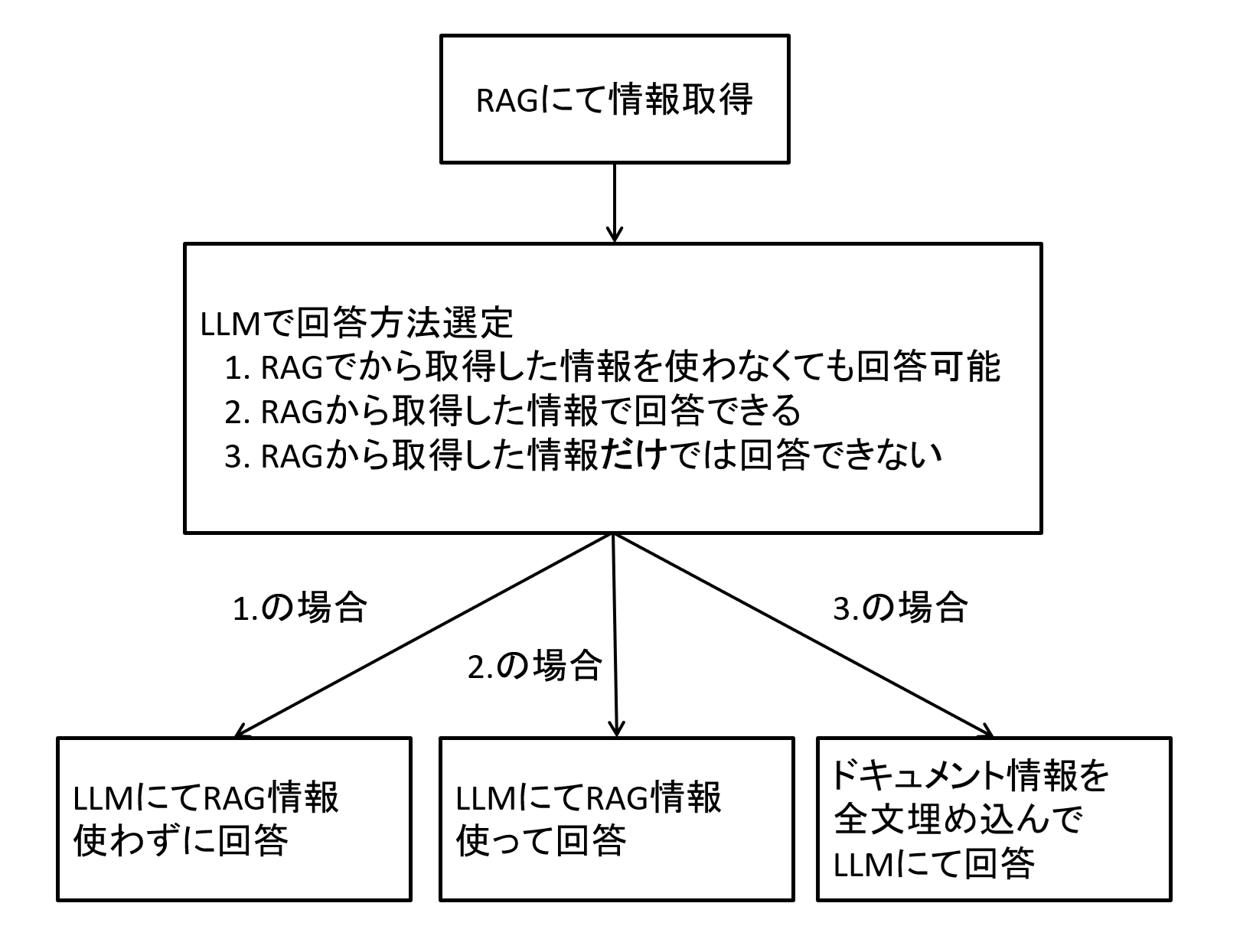
図2 Self-Routeの処理の流れイメージ
RAGは精度向上の為の銀の弾丸ではありません。
例えばRAGに登録しているドキュメントが多いと、中々ピンポイントに必要な情報が取得できない場合がありますし、ユーザの質問が不明瞭であったり、要約のようにそもそもRAGのように「一部情報」を使って回答することが適さないタスクの場合もあります。
このような場合には「ドキュメントの全文をLLMに渡して回答する」と判断する、というのがこの手法です。
また、RAGにより質問と全く関係ない情報が含まれてしまうと精度が悪化する場合もあります。
その為、RAGを使わなくても回答できる質問は、RAG情報の影響を受けないように、RAG情報を使わずに回答させます。
一方でドキュメントを全文入れた場合、消費トークン量が増える為、利用に費用が掛かるLLMモデルだと料金が上がってしまったり、モデルやユースケースによって質問内に入れる情報が多くなるほど精度が落ちる場合もあります。
また、ドキュメントが非常に長い場合、LLMに情報を渡す際に全文入りきらない、ということもあります。
このようにRAG自体も万能ではないですが、精度改善手法も同様に常に万能とはならない点は意識しておけると良いでしょう。
ハンズオン: DifyでのHyDE実現について
ここからはDifyを使って、実際にHyDEを実現してみましょう。
なお、Difyの構築方法は第1回を参照ください。
実現方法
実現方法にはDifyのChatflow機能を利用します。
Difyのトップページから「最初から作成」を選んで、「チャットボット」「Chatflow」を選択ください。
上記を選択すると以下のようなデフォルトの画面が表示されるかと思います。
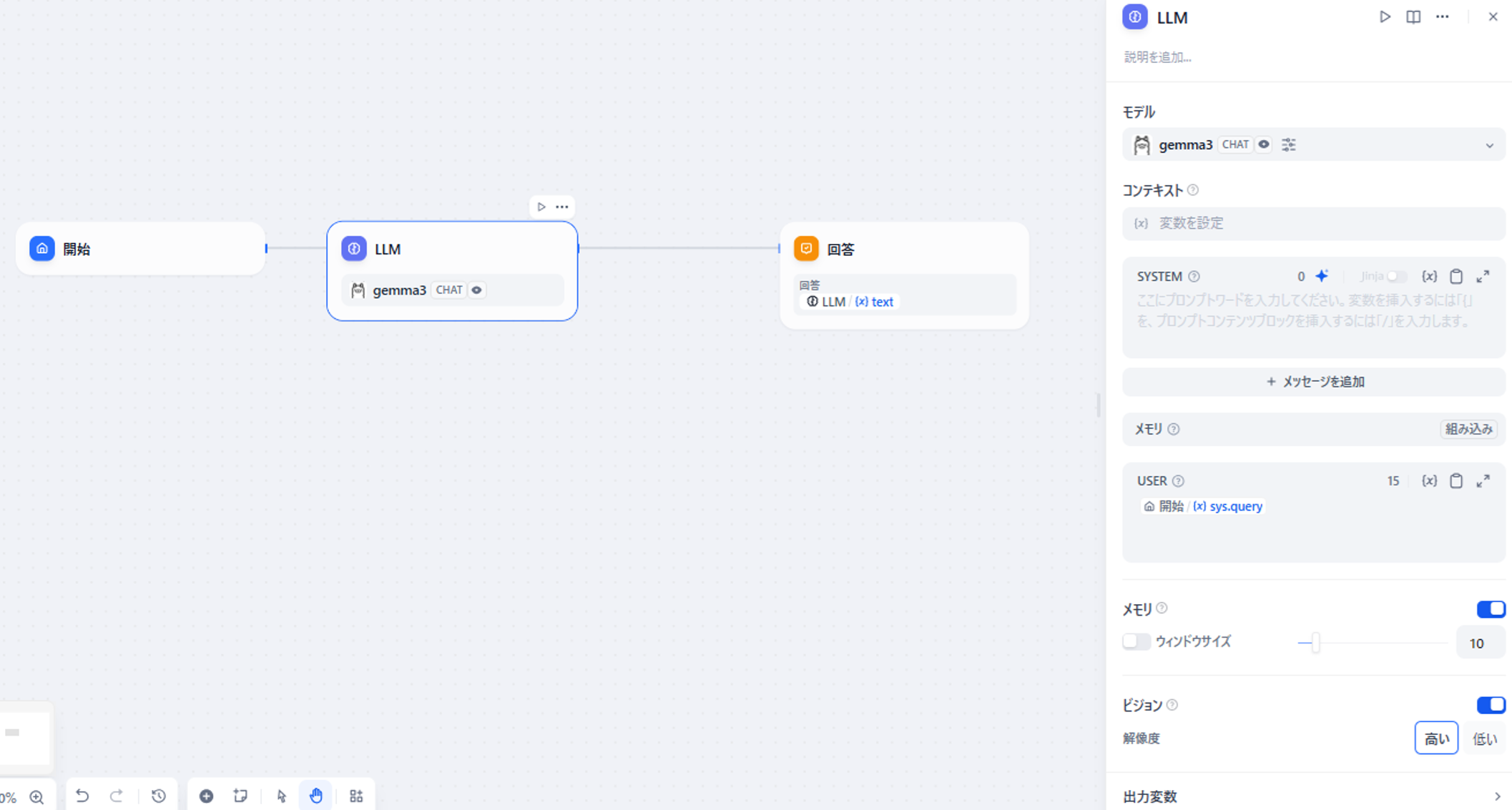
図3 Chatflow画面の初期状態
最終的には以下のような構成となります。
ブロックが2つほど増えていることがわかるかと思います。
なお、今回利用するLLMモデルは、Ollamaに登録したgemma3としたいと思います。
この設定に関しては第2回のハンズオンを確認ください。
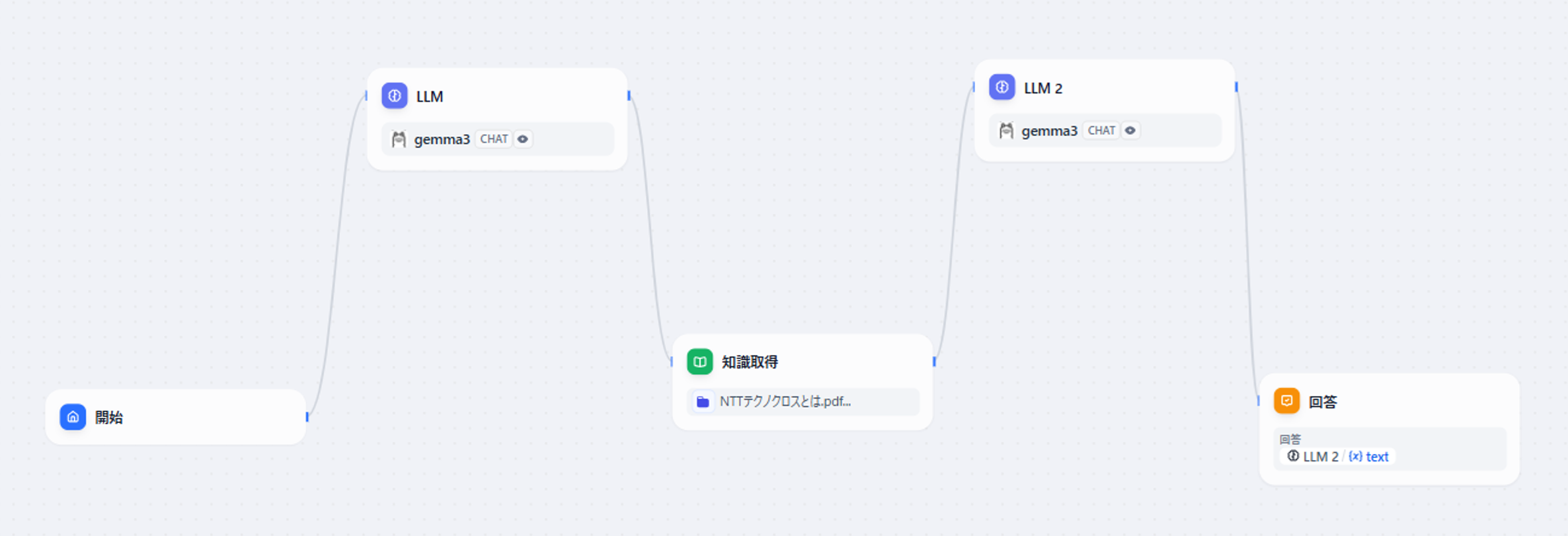
図4 Difyで実現したHyDE処理の全体像
HyDEの処理手順は前節で触れたように以下にようになります。
[開始]
① ユーザの質問から、LLMにて一次回答を生成。
② ①の回答を使ってRAGの仕組みを活用して情報取得。
③ ②で取得した情報とユーザの質問を使って再度LLM問い合わせを実施。
[終了]
上記の処理の流れの通りにブロックがあるとわかるかと思います。
ここからはデフォルトの状態から、完成系を作るまでの手順を記載します。
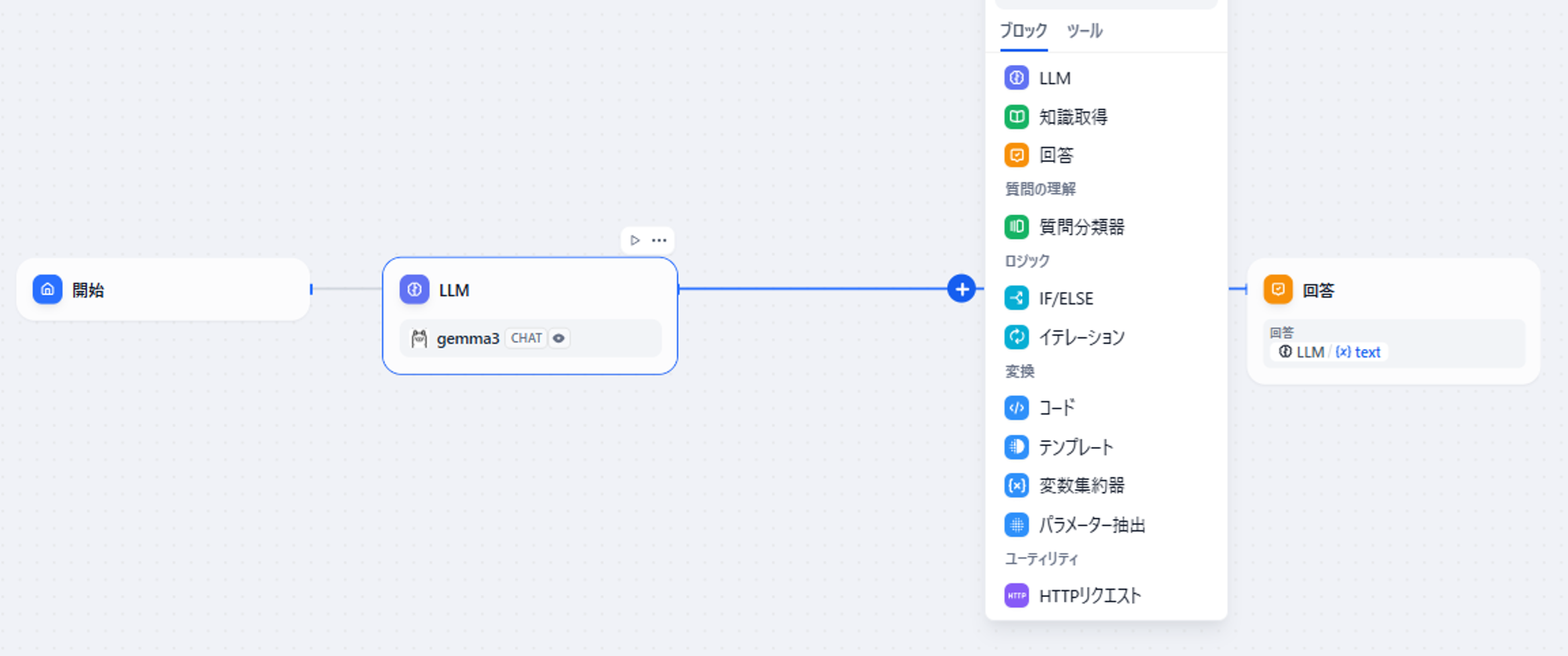
図5 「知識取得」ブロックの追加
まず、初期配置の「LLM」と「回答」の間の線上にある「+」を押して「知識取得」ブロックを配置しましょう。
これがDifyのナレッジ機能(=RAG)を利用するブロックとなります。
なお、ナレッジ機能の利用には事前準備が必要です。
これは第3回のハンズオンを参照ください。
「開始」の横にある「LLM」ブロックは、ユーザの質問を受けてそのまま回答を作る事を期待する為、初期値のままで構いません。
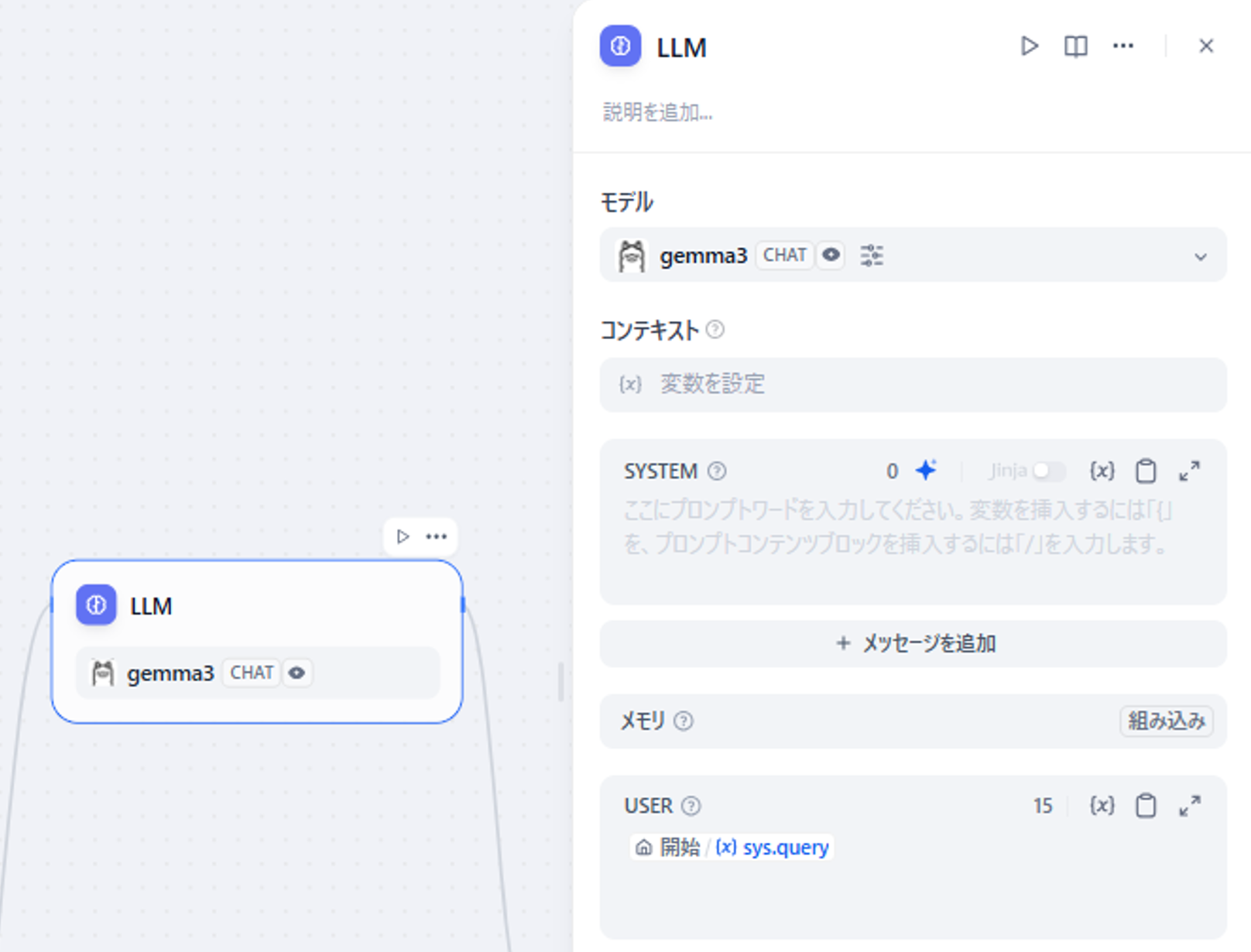
図6 「LLM」ブロックの設定画面
追加した「知識取得」ブロックは以下のように設定します。
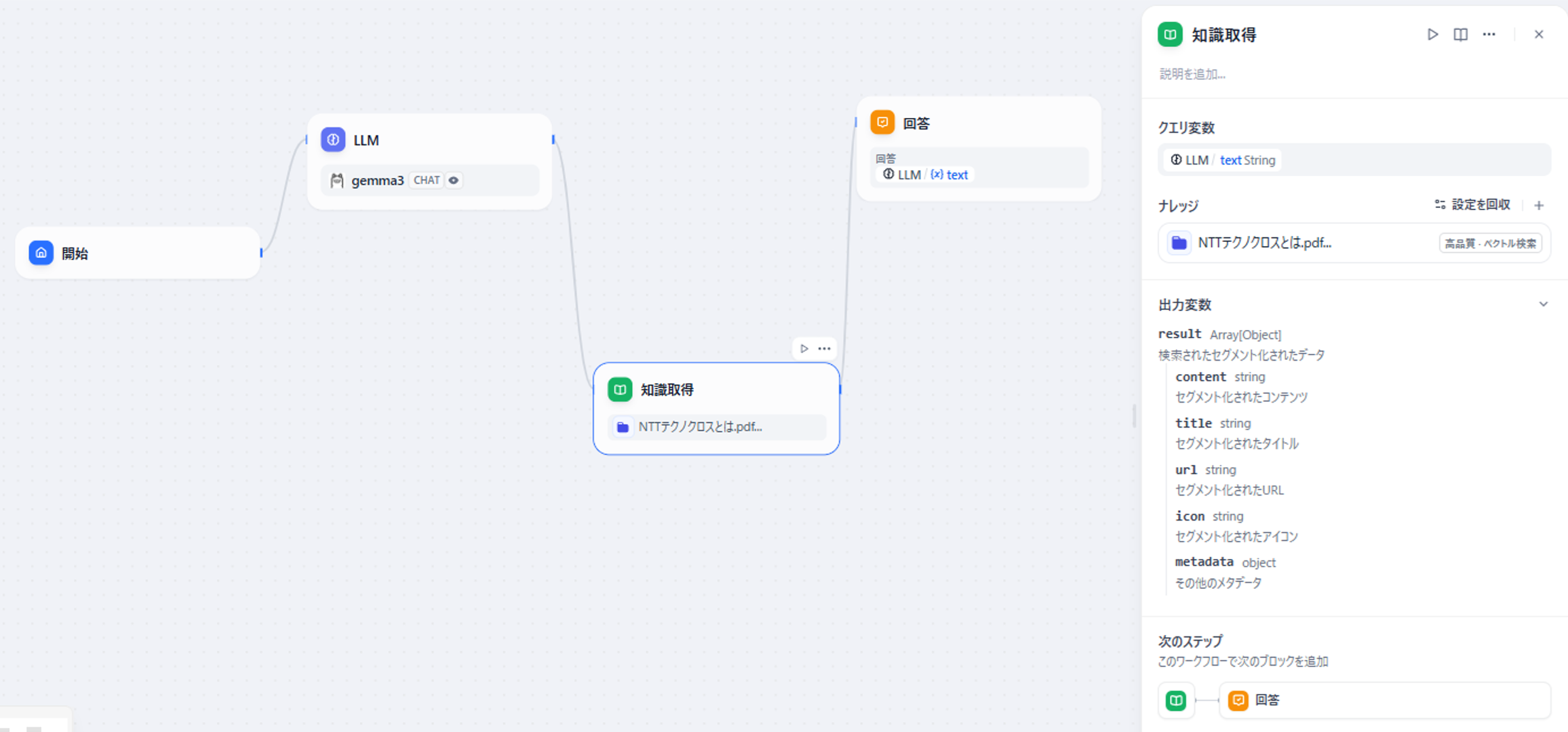
図7 「知識取得」ブロックの設定画面
RAGから情報を取得する為に使う文字列はユーザの質問ではなく、LLMの回答となる為、「クエリ変数」を「LLM」の回答である「LLM: text」とします。
また、ナレッジは事前登録した情報を指定します。
第3回では「チャットボット」の「基本」機能で、Difyのナレッジ機能を利用する例を記載しましたが、このようにChatflow機能に取り入れる事も可能です。
出力変数を確認すると、この処理は「result」変数として出力されることがわかります。
これは次の手順で利用します。
「知識取得」ブロックの設定ができたら、その後に続く処理のLLMブロックを作ります。
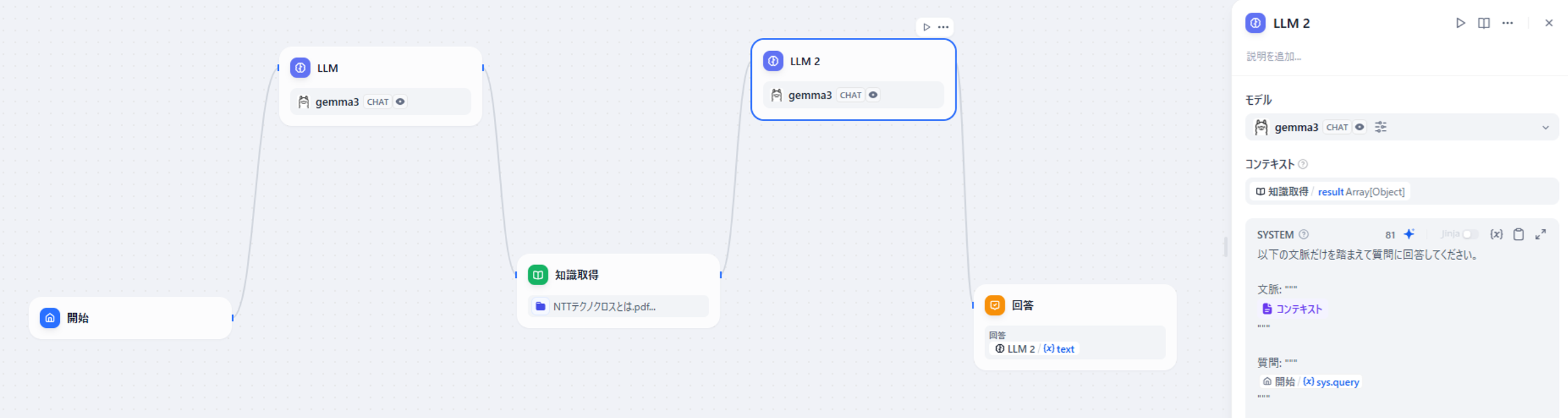
図8 「LLM2」ブロックの設定画面
「LLM2」ブロックの「コンテキスト」欄は、RAGから取得した情報を指定します。
前の手順の「出力変数」で確認した「result」を入れましょう。
「SYSTEM」欄はシステムプロンプトを設定します。
最後に「回答」ブロックの回答を「LLM2」の回答を指定しましょう。
(デフォルトのままでは「LLM」ブロックの回答が入っているはずです。)
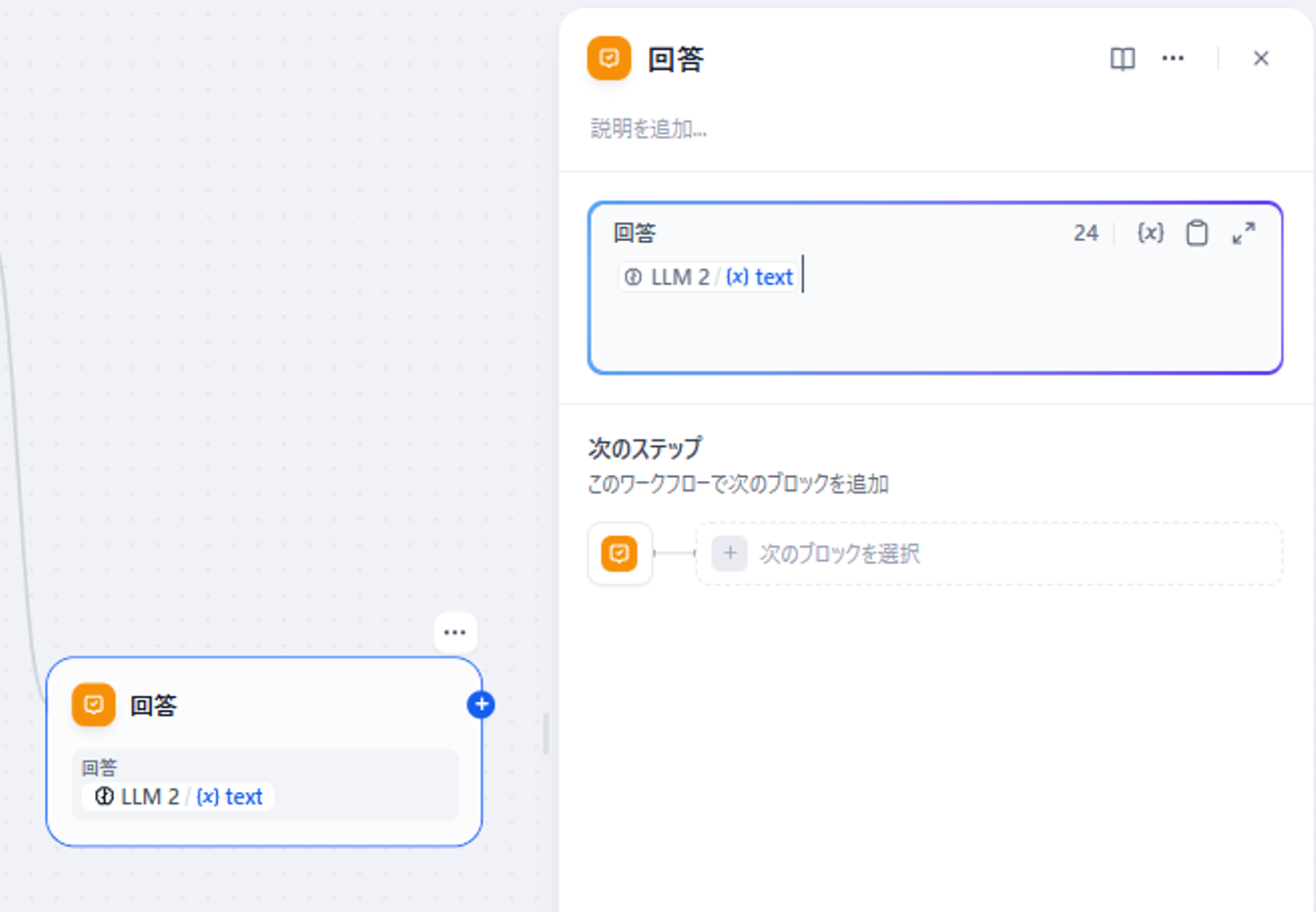
図9 「回答」ブロックの設定画面
これで準備ができました。
この後は実際に試してみましょう。
動作確認
ここからは動作確認をしてみましょう。
第1回の時と同様に「デバッグとプレビュー」で確認してみましょう。
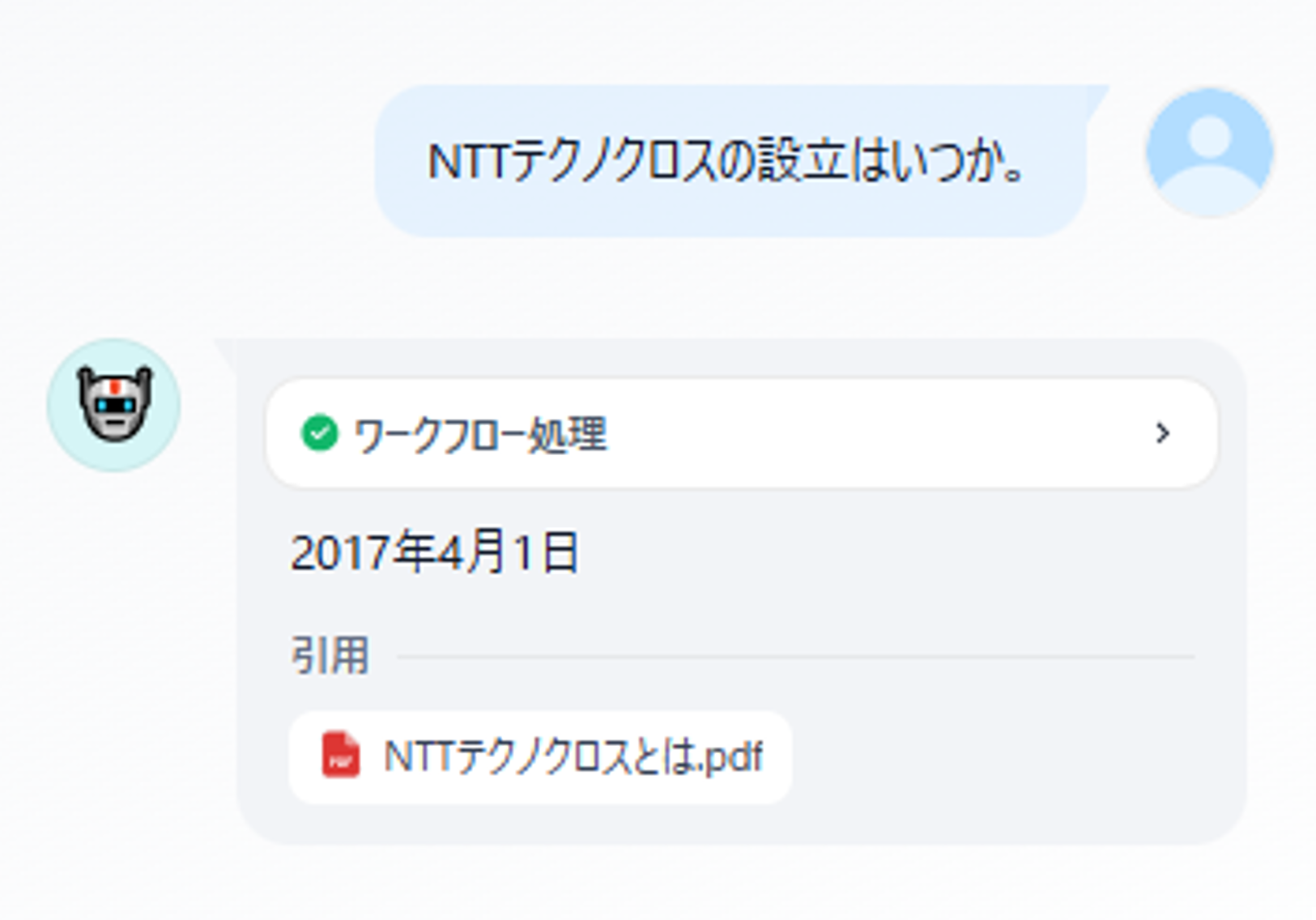
図10 動作確認結果
確認結果が上記となります。
質問自体は第3回と同じですが、問題なく回答できていることがわかります。
中身の処理が想定通りに動いているかも確認してみましょう。
回答欄にマウスカーソルをあわせると「ログの表示」項目が表示されるので、クリックしましょう。
以下は1回目のLLMへの問い合わせ処理のトレース結果です。
RAGの情報を使っていないのでハルシネーションが発生していますが、一方でユーザの質問と比較し「設立」というキーワードが複数回登場するようになり、このキーワードの重要性が上がったような印象が見て取れます。
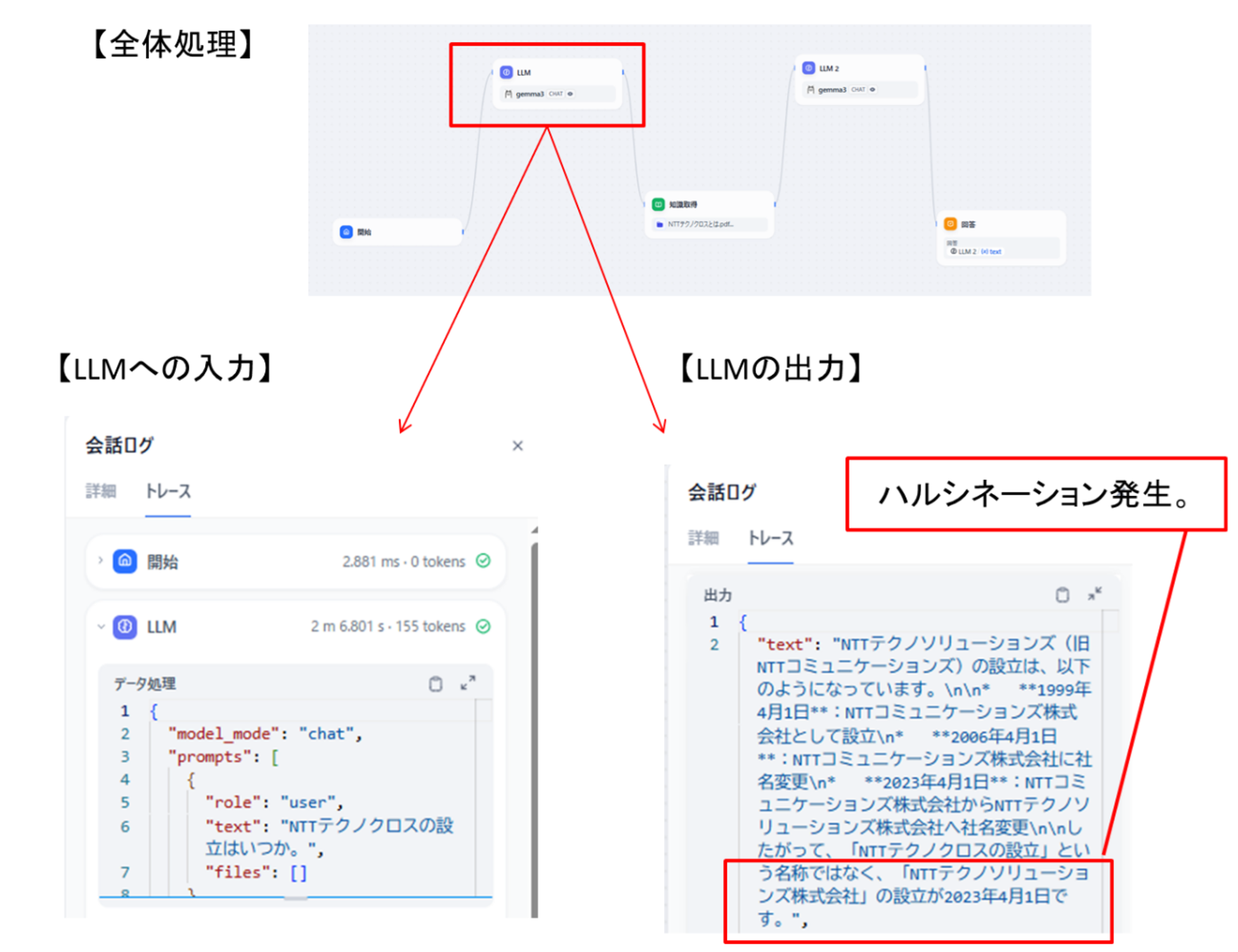
図11 「LLM」ブロックのトレース結果
次の「ナレッジ機能」処理のトレース結果は以下となります。
前のLLMの回答を使って情報を取得できていますね。
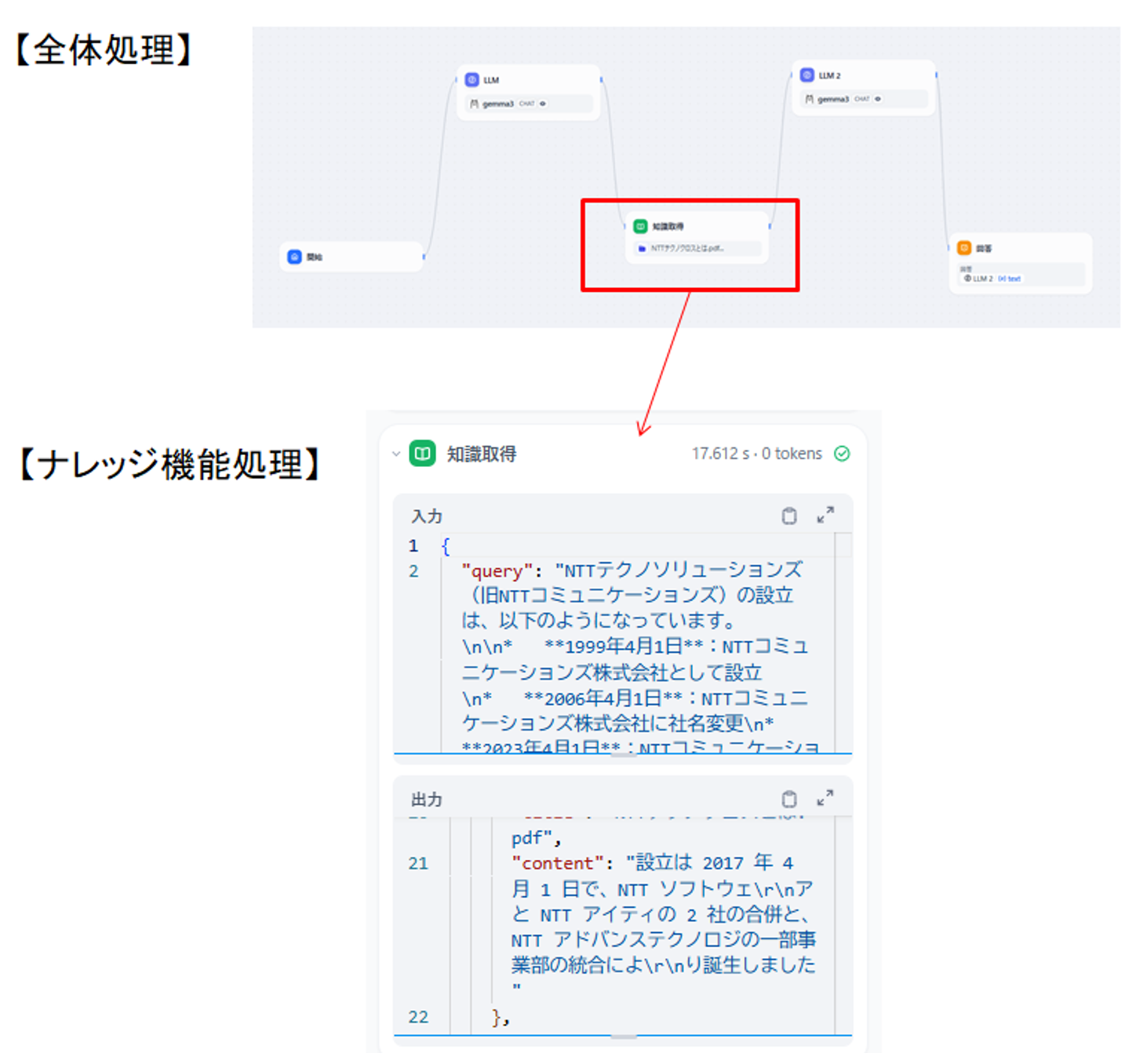
図12 「知識取得」ブロックのトレース結果
最後に2回目LLM問い合わせの処理を見てみましょう。
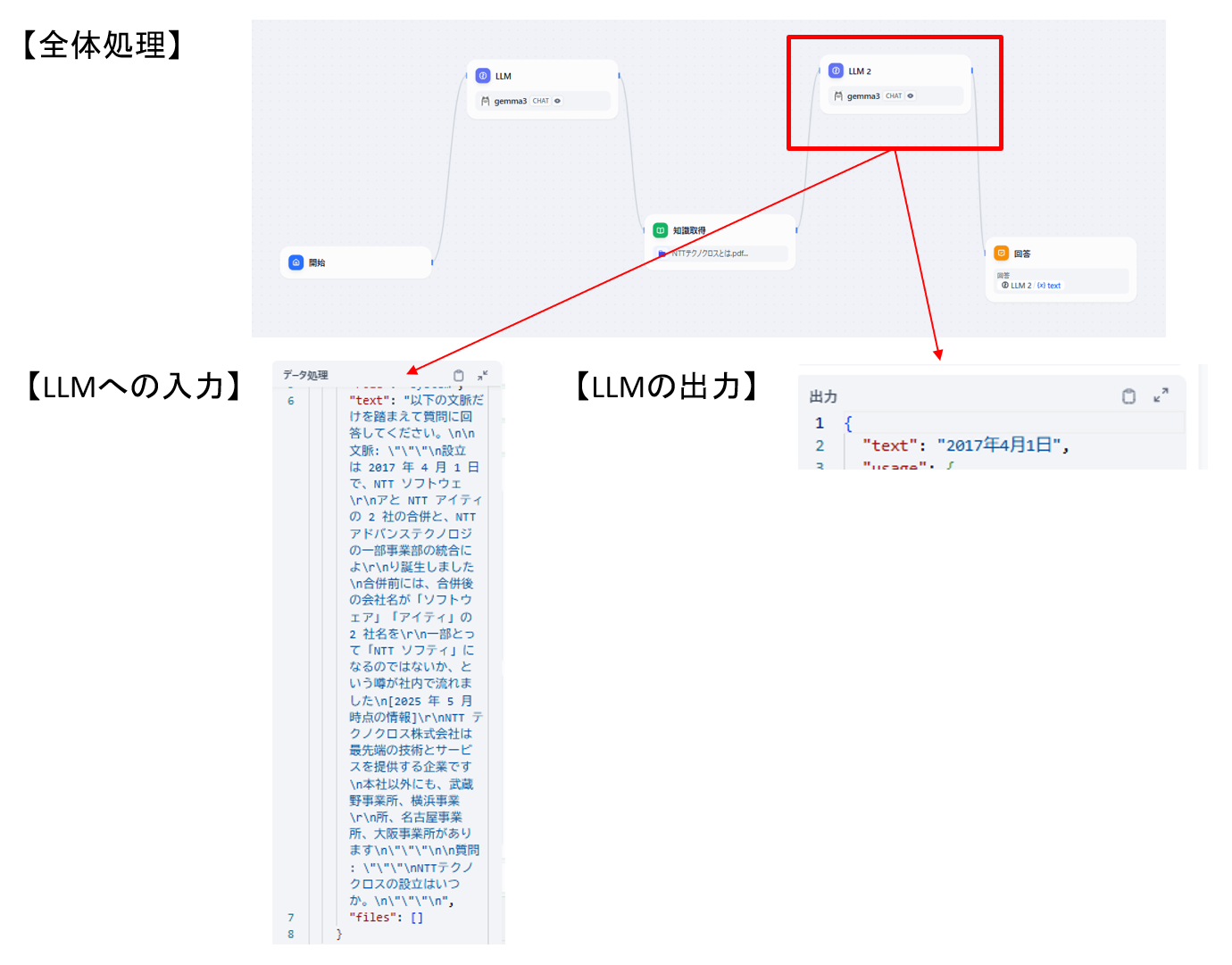
図13 「LLM2」ブロックのトレース結果
システムプロンプトで指定した通りに問い合わせを行い、結果が出力された事がわかるかと思います。
全体的に想定通り動いていることが確認できました。
このように「ログ確認」から処理をトレースすることで、中身の処理を追う事ができます。
今回は上手くいったケースで確認しましたが、想定通りの結果が出ない場合の確認にも有用です。
ハンズオン: DifyでのSelf-Route実現について
続いてSelf-RouteをDifyで実現していきましょう。
なお、Chatflow機能の使い方はHyDEの際に触れているので、Self-Routeは肝となるポイントに絞って説明します。
実現方法
まず、全体像は以下のようになります。
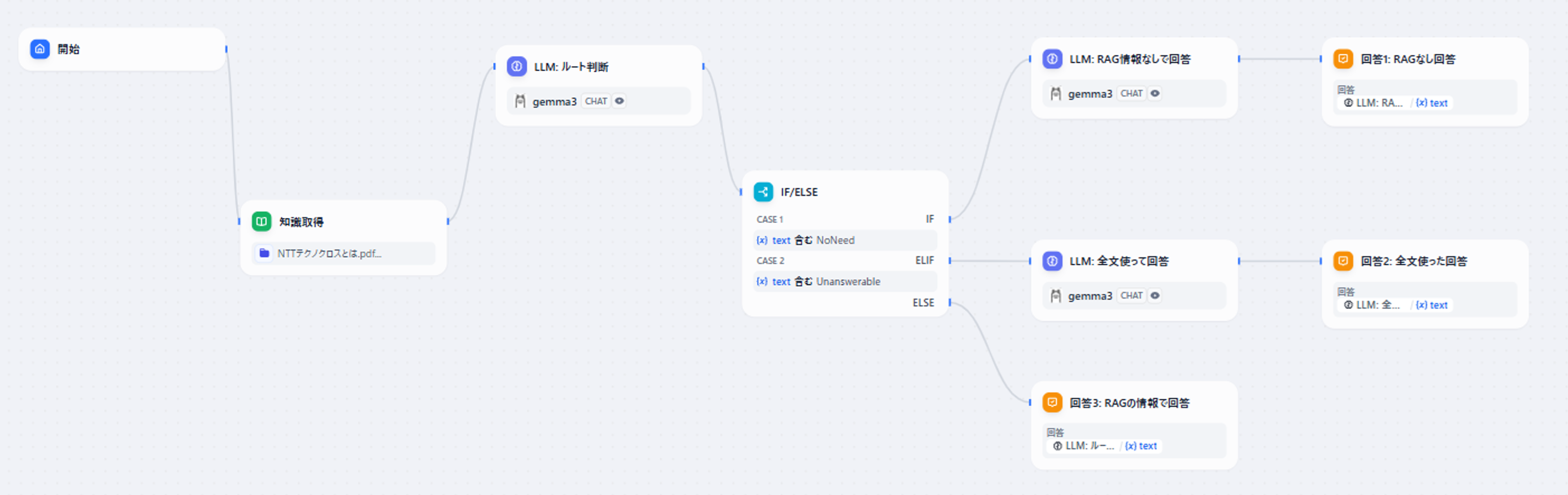
図14 Difyで実現したSelf-Route処理の全体像
HyDEの時よりブロック数も増えましたが、大筋はSelf-Routeの説明をした際の処理の流れとなっています。
この処理の中で特に肝となる「LLM: ルート判断」です。
ここで「RAGで取得した情報なしで回答案を作るのか」「RAGで取得した情報を使って回答案を作るのか」「全文を使って回答案を作るのか」が判定されます。
また、その後の「IF/ELSE」ブロックで、判断された結果にあわせてルート分岐を行い、それぞれに応じた処理がされます。
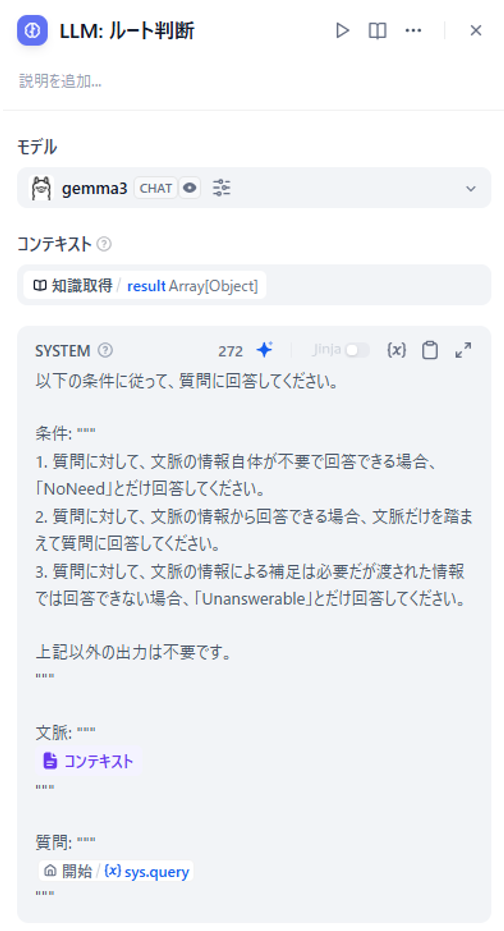
図15 「LLM: ルート判断」ブロックの設定画面
「LLM: ルート判断」のプロンプトは上記のようにセットします。
条件通り動いてくれれば「NoNeed」「Unanswerable」「回答」のどれかが返るはずです。
この値を使ってルート判定を行います。
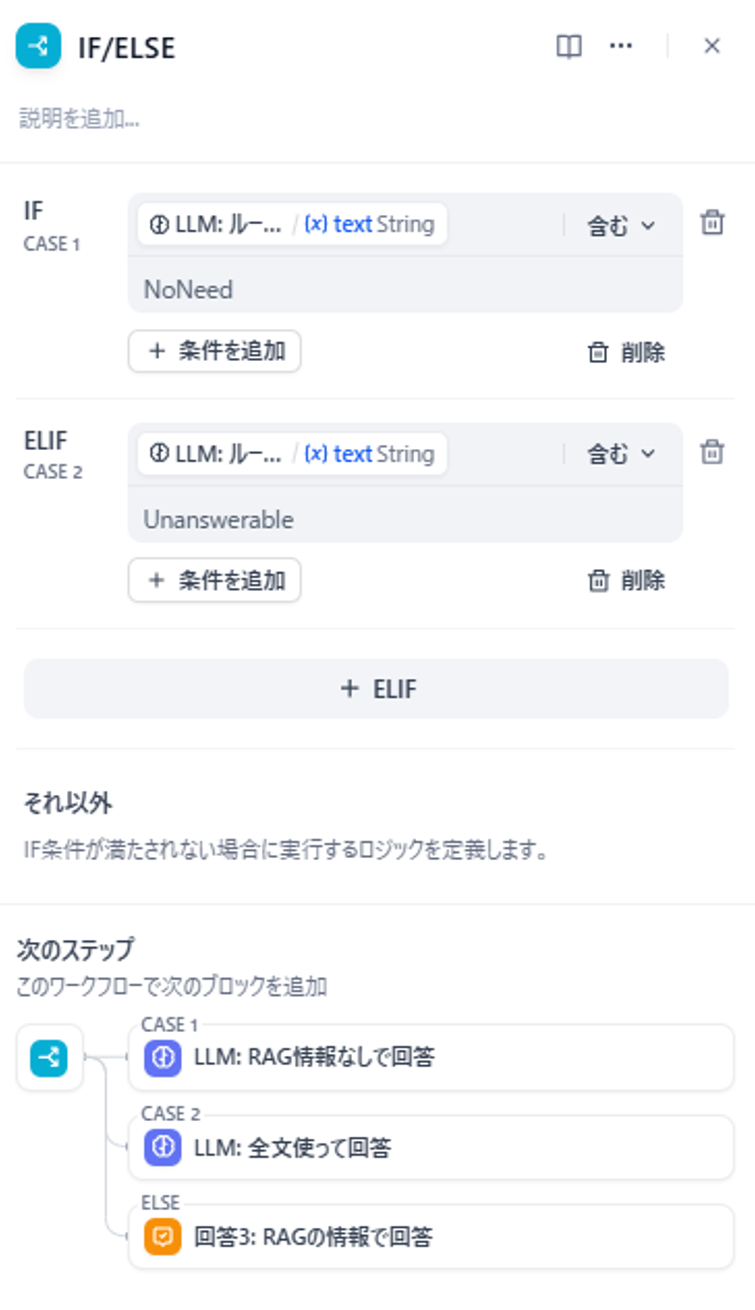
図16 「IF/ELSE」ブロックの設定画面
ルート判定には「IF/ELSE」ブロックを使用します。
前述の通り、「NoNeed」とあればCASE1ルート、「Unanswerable」があればCASE2ルートというようにルート分岐されています。
分岐後のLLM処理の指定は今回は以下のようにしました。
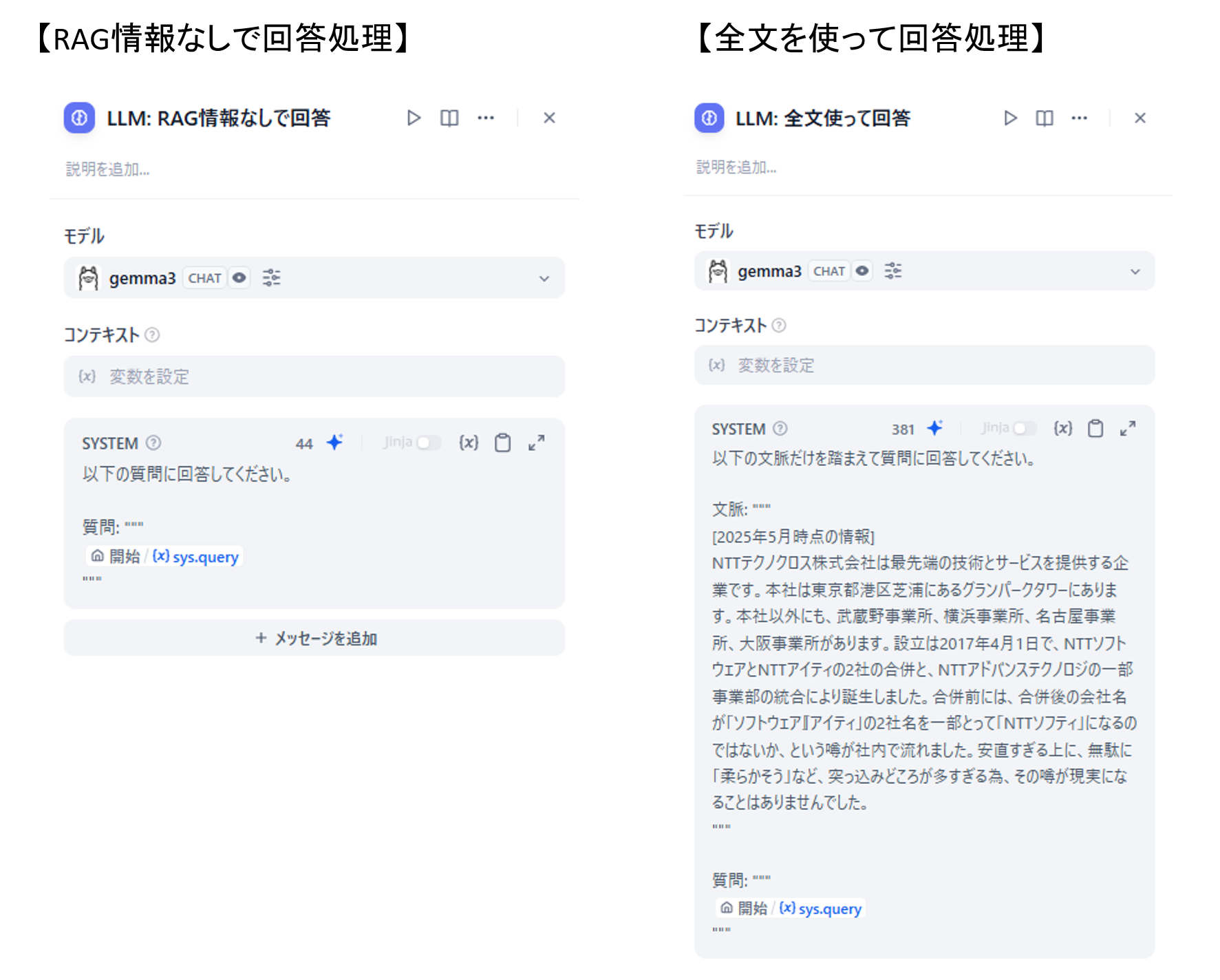
図17 ルート分岐後の各「LLM」ブロックの設定画面
なお、RAGで取得した情報を使って回答する場合は「LLM: ルート判断」時に回答生成されるため、そのまま回答出力とさせます。
これで準備は完了です。
動作確認
準備ができたら早速動作確認をしてみましょう。
まずはRAGの情報を使わずに回答できる質問を試してみます。
RAGには「NTTテクノクロス」の情報を入れていますが、全く関係ない、かつベースのモデルでも知っていそうな「東京」について聞いてみます。
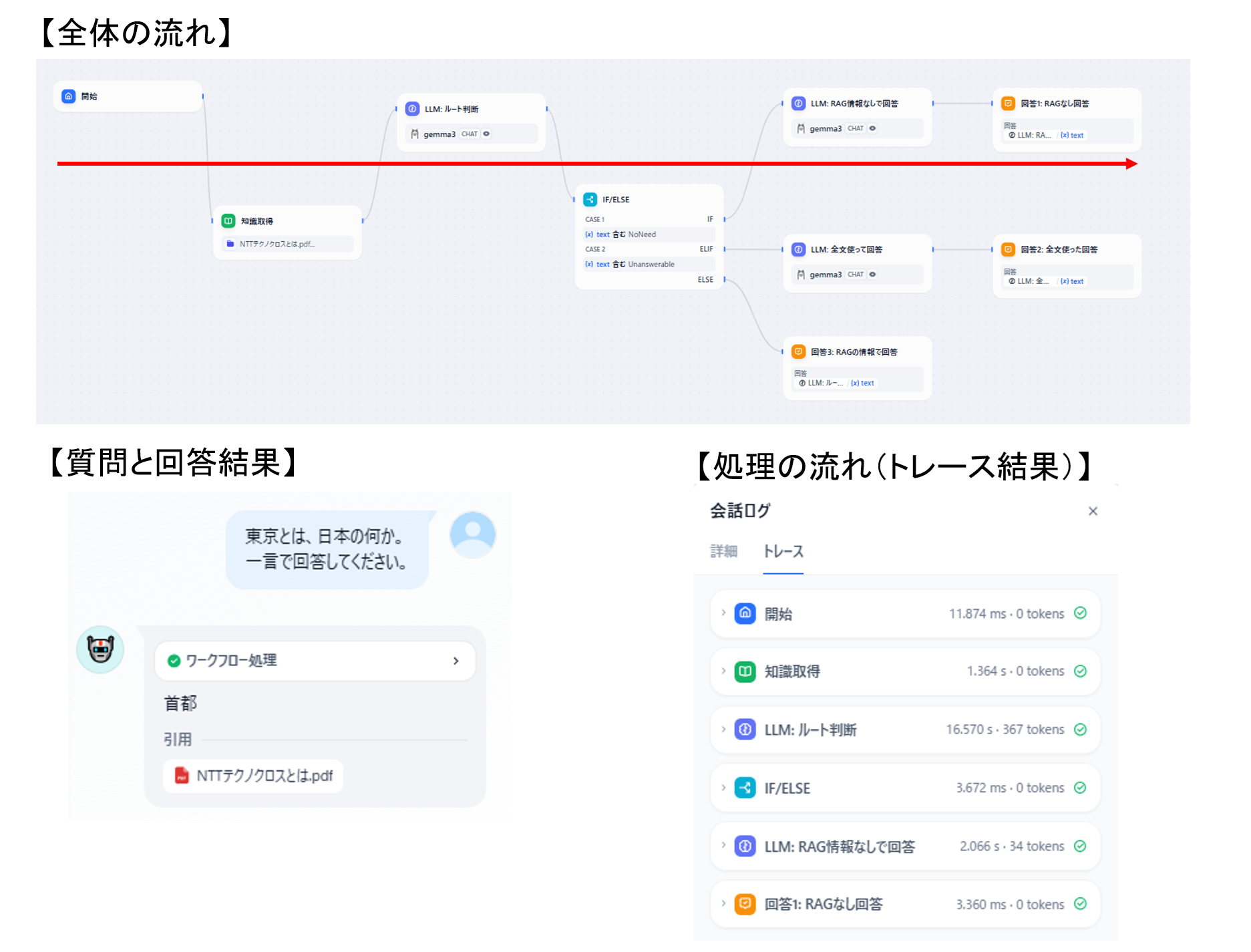
図18 RAG取得データを使わずに回答するルートの動作確認結果
トレースの結果をみると、想定通り「RAGの取得情報を使わない」ルートにいっていることがわかります。
次は「RAGで取得した情報を使って回答する」ルートを試したいと思います。
これはRAGで登録したドキュメントに書かれている情報を聞くと良いでしょう。
今回はいつものごとく「設立」について聞いてみます。
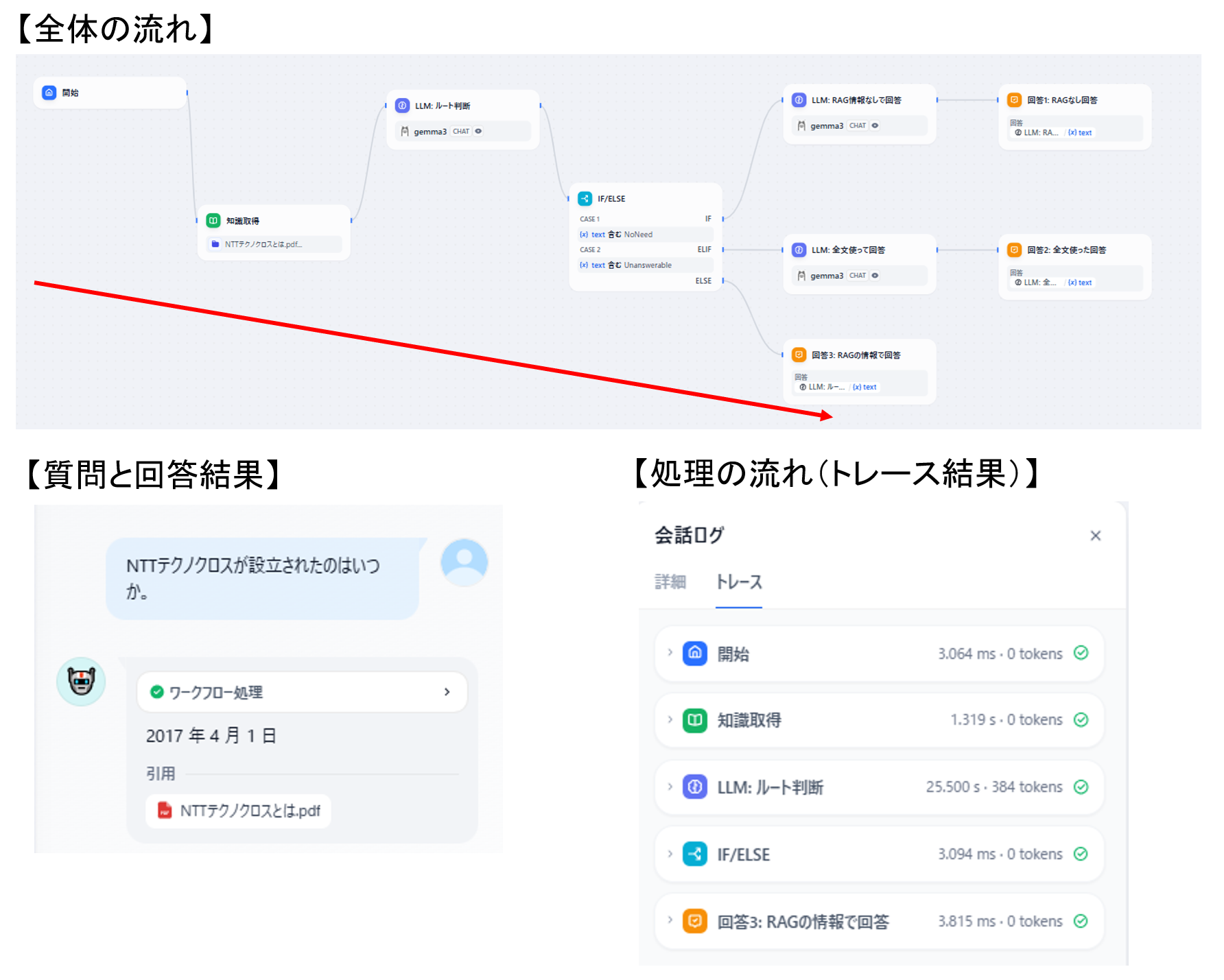
図19 RAG取得データを使うルートの動作確認結果
こちらも問題なく回答もでき、かつ想定通りのルートを通ったことがわかりました。
最後に「全文使うルート」を試してみます。
本来はRAGで取得した情報が正しくない場合で見れると良いのですが、登録したドキュメントの情報も少ない為、登録情報(NTTテクノクロス)と関連しそうだがドキュメントに書かれていない情報を聞く事で、上手く必要な情報が取得できなかった場合を疑似します。
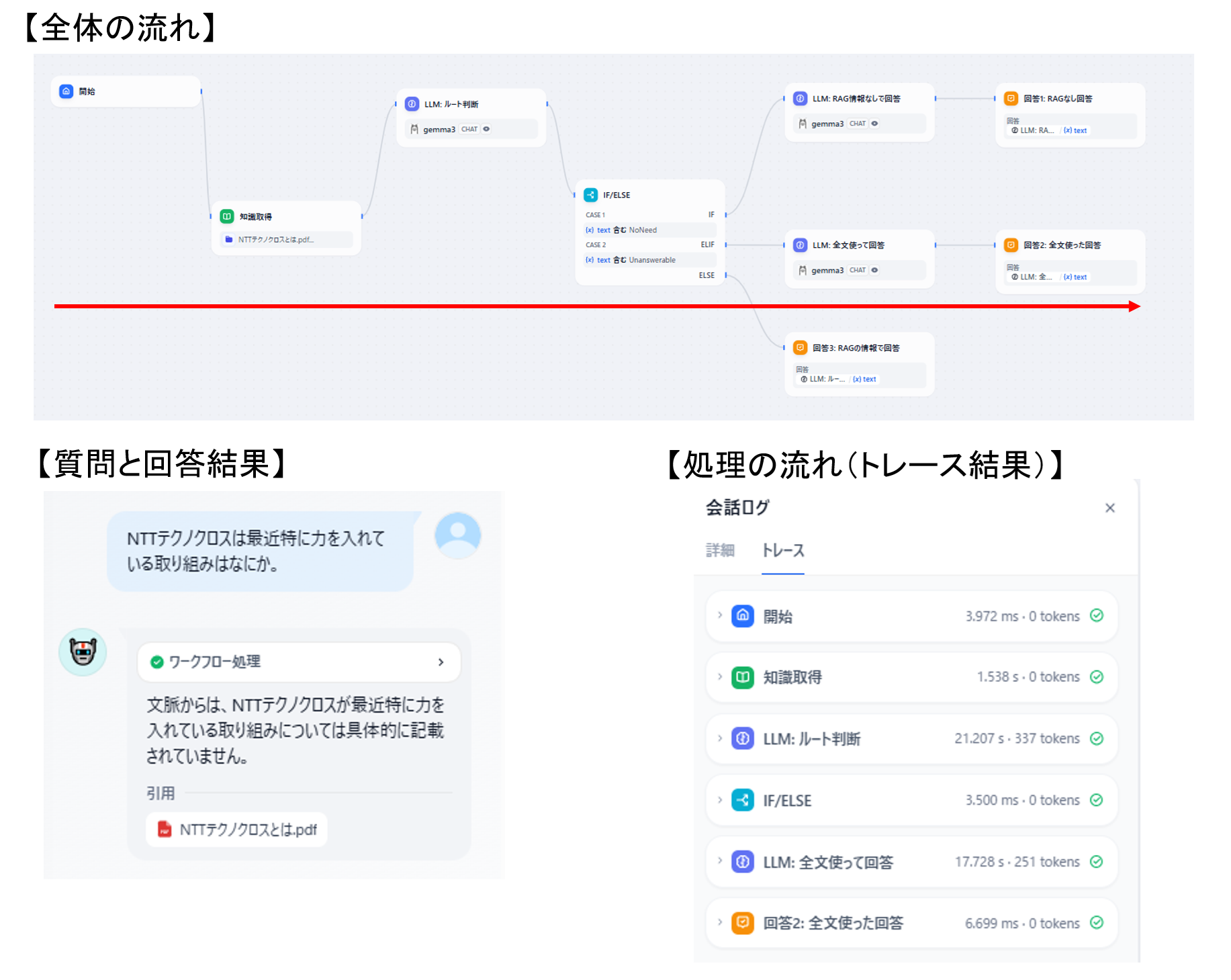
図20 全文を使用した回答ルートの動作確認結果
ドキュメントに書かれていない情報を聞く事で、「RAG登録情報に関連しそうだが、上手くヒットしていないな」とLLMに判断させ、全文ルートに行くことができました。
ただ全文で試しても、そもそもドキュメントに書かれていない事を聞いている為、LLMからは「それらしいことは書いてない」と回答を受けています。
今回は疑似で試していますが、実際にRAGを運用する場合は多くのドキュメントを入れるかと思います。
その場合、必要な情報が上手く取られない事がある為、このようなルートを用意しておく事は有用です。
紹介手法の応用について
ここまで、HyDEとSelf-Routeという2つの手法を紹介しました。
HyDEはLLMの一次回答を使ってRAGから情報取得している一方、Self-Routeは通常のRAGと同様でユーザの質問から情報を取得していました。
よってこれら2つを組み合わせて使う事も可能です。
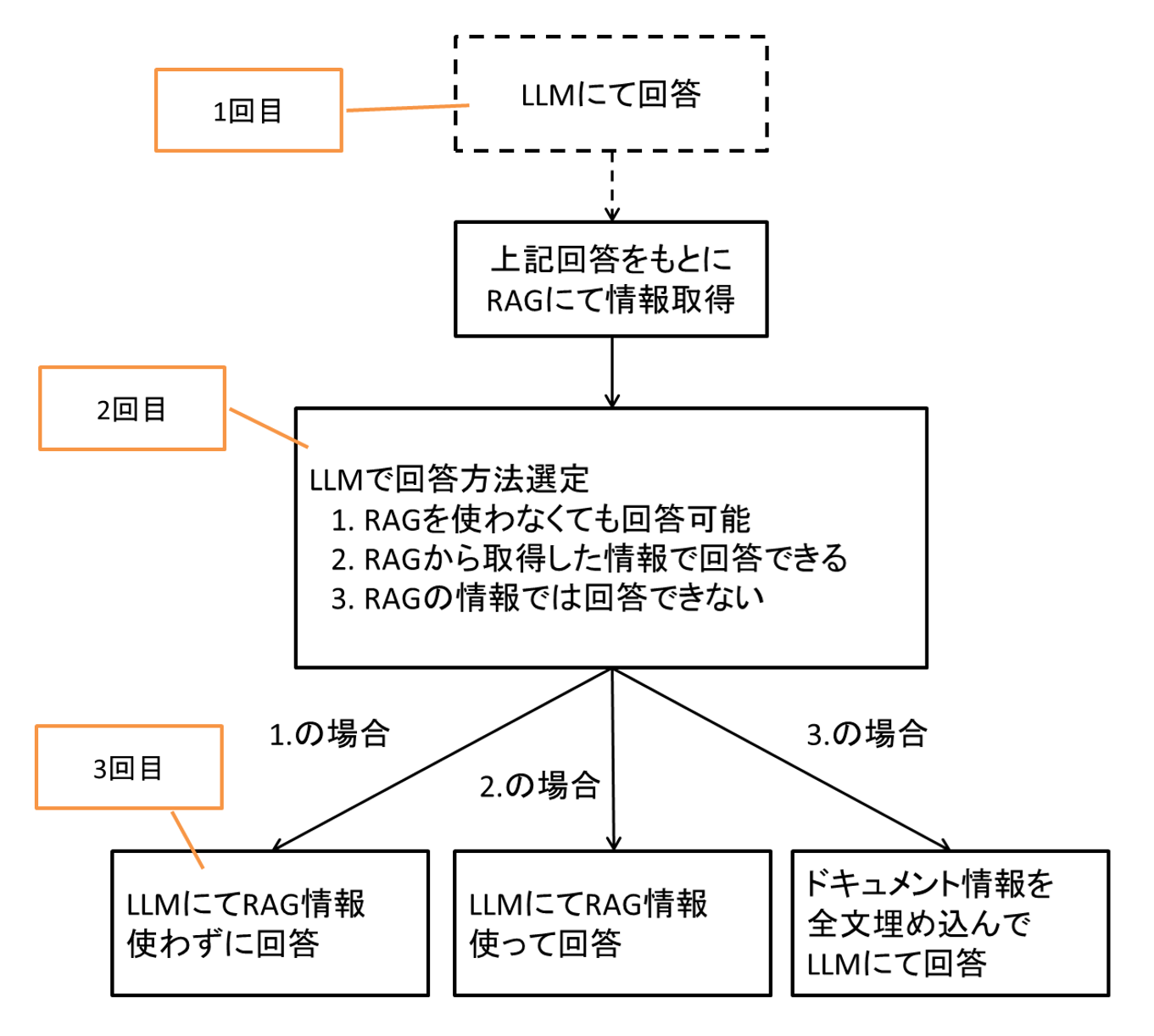
図21 HyDEとSelf-Routeを組み合わせた処理の流れイメージ
ただし上記の通り、その分LLMに問い合わせを行う回数が増えます。
これはユーザから見ると、1回の質問をして回答が出力されるまでの待ち時間がその分長くなることを意味します。
このように様々な手法を組み合わせることでより高度なRAGを実現でき、それにより精度向上も目指せるかと思いますが、その際のデメリットも考慮する事が重要です。
その代表例として、精度と処理時間のトレードオフは意識しておけると良いでしょう。
この考え方は、昨今話題のAIエージェントも同様です。
また、Self-Routeの肝は「LLMがどの処理を行うか判断する」という点でした。
この考え方は他の場面にも適用ができます。
例えばユーザの質問を受けたらどのようなタスクに該当するのか分類の上、タスクの種別ごとにLLMのプロンプトや利用するRAGを変える、といった使い方です。
このようにLLMに判断をさせることで、幅広い質問に柔軟に対応でき、かつそれぞれで精度を高めたLLMアプリケーションが作れるようになります。
一方で段階的な処理やLLMによる判断はハルシネーションの影響を受けやすい特性もあります。
問い合わせ内容やプロンプト、利用するモデルや設計にもよりますが、流れに沿ってLLMが処理をする都合上、途中(例えばLLM問い合わせの1回目)でハルシネーションが発生すると後段処理も上手くいかなくなり、結果として単発でユーザがLLMに問い合わせをした場合と比較し、期待値とよりずれた回答が出力されるといった例があげられます。
このような課題を防ぐために処理の中で期待と多く異なっていないかチェックする機構を設けたり、LLMに問い合わせるタスクをなるべく分割してシンプル化することが有効です。
おわりに
今回はDifyを使ってHyDEとSelf-Routeの紹介をしてきました。
Difyを活用することで、簡単に順次処理やルートに応じた処理が作れることが伝わったかと思います。
また前述の通り、処理を複雑化させていくと精度は向上するかもしれませんが、ユーザの使い勝手が悪くなる場合があります。
その為、バランスを考えた上で実装していくことが重要です。
簡単な処理(タスクの分類やルート判断)は回答が早い軽量モデル(SLM)で実現し、最終的な回答は重いモデルで作る、というようにモデルを使い分ける工夫も有効です。
なおRAGの精度改善手法は、今回紹介したようなRAGの処理自体の改善の他に、RAGに登録するドキュメントの改善も案としてあげられます。
特に画像に関しては、昨今マルチモーダルモデルも登場してはいますが、まだまだ課題がある為、Mermaid記法などを使って「文字として読み取れる」形にする事も対策となるかと思います。
次回はグラフRAG(GraphRAG)についてご紹介できれば、と思います。
ここまでご覧いただき、ありがとうございました。
本記事、またはそれ以外のネットワーク関連に関しての問い合わせやご意見がございましたら、以下にご連絡ください。
本件に関するお問い合わせ




<<<<著者プロフィール>>>>
フューチャーネットワーク事業部
第一ビジネスユニット
山口 佳輝(YAMAGUCHI YOSHIKI)
NWに関係したシステム開発を担当しています
>>>>>>>>><<<<<<<<<
![]()