RAGとは?Difyから基本を学ぶ ~LLM活用入門3回~
本記事ではRAGの基本について紹介します。後半にはDifyとOllamaを使ってローカルモデルを使ったRAG環境を動かす例も紹介します。




はじめに
こんにちは、NTTテクノクロス 山口です。
近年、LLMに関する話題が増えるなかで、LLMモデルが持ち合わせていない知識を補完する手法として、RAG(Retrieval-Augmented Generation)が注目を浴びてきました。
最近ではAIエージェントという言葉もよく耳にしますが、この仕組みの中にもRAGが取り入れられることが多いかと思います。
さらにRAGに関する新しい手法も次々と登場しており、今なお注目度の高い分野です。
またLLMの活用自体も依然として注目を集めていますが、その効果を引き出すためには第2回で紹介したようなツールの理解と活用が重要です。
そこで今回を含むこれから3回は、RAGに着目しながらLLMを活用する為のツールの基本を紹介します。
今回は「そもそもRAGとは?」といった初歩的な部分から入り、ノーコードで利用できるDifyを使ったハンズオンを通じてRAGの基礎を押さえましょう。
次回(第4回)・次々回(第5回)では、プログラムも関連するLangChainやLlamaIndexの基本を紹介します。
これらを通じてRAGの基本だけでなく各ツールの基本・使い方を押さえられれば、と思います。
■ 目次
| 記事 | 節番号 | 節タイトル |
| 今回 (第3回) |
1 | RAGと紹介対象のツール群について |
| 2 | ハンズオンの前の事前準備と前提 | |
| 3 | ハンズオン: DifyでRAGを試す | |
| 次回 (第4回) |
- | ローカルモデル×ベクトルDB構成によるRAG作成で学ぶLangChainの基礎 |
| 次々回 (第5回) |
- | ローカルモデル×ベクトルDB構成によるRAG作成で学ぶLlamaIndexの基礎 |
[参考] 本連載の記事
本記事とあわせて、以下も良ければご確認ください。
| 連載番号 | タイトル | 概要 |
| 第1回 | 今だから知っておきたいDify!ノーコード・ローコードでLLM活用基盤を作ろう | Dify自体の説明とChatflow機能を使った例を取り上げています。 |
| 第2回 | 爆速キャッチアップ!LLM活用をリードするプラットフォーム群 | LLMの可能性をより広げるDify/Ollama/LangChain/Hugging Faceの紹介と、 DifyとOllamaでローカルLLMを活用したChatflow機能の利用に関して取り上げます。 |
| 第3回 | RAGとは?Difyから基本を学ぶ | RAGの基礎的な説明とDifyを使った実現方法を取り上げています。 |
| 第4回 | ローカルモデル利用のRAG実装で学ぶLangChainの基礎 | ベクトルDBを用いたRAGのサンプルコードから、LangChainの基礎を解説します。 |
| 第5回 | ローカルモデル利用のRAG実装で学ぶLlamaIndexの基礎 | ベクトルDBを用いたRAGのサンプルコードから、LlamaIndexの基礎を解説します。 |
| 第6回 | Difyで学ぶ、RAGの精度改善手法 | RAGの精度改善手法をDifyのChatflow機能を使いながら紹介します。 |
| 第7回 | ローカル環境で実現する、GraphRAGの基礎 | GraphRAGの基礎から、LangChainとNeo4jを使ったグラフRAGの実装例を紹介します。 |
| 第8回 | ローカル環境で実現する、Text-To-SQLとRDBを用いたRAG | Text-To-SQLと、それを活用したRDBを用いたRAGの実装例を紹介します。 |
| 第9回 | ファインチューニングとは?基礎を理解する | ファインチューニングとそのユースケース、手法を紹介します。 |
| 第10回 | Hugging Faceライブラリで実行する推論と学習の基礎(前編) | Hugging Faceのライブラリを使った、モデルのダウンロードや推論処理について紹介します。 |
| 第11回 | Hugging Faceライブラリで実行する推論と学習の基礎(後編) | Hugging Faceのライブラリを使った、ローカルモデルの学習処理と実行例について紹介します。 |
| 第12回 | AIエージェントとは?Difyから考え方を学ぶ | AIエージェントについて、Difyでの動作イメージも含めて紹介します。 |
| 第13回 | MCPとは?AIエージェントの可能性を広げよう | AIエージェントの可能性を広げる技術であるMCPについて紹介します。 |
あわせて「RAGの導入をどのように進めるか」気になる方は、以下に記載していますので、こちらもよければご参照ください。
うちもRAGをやりたい! どうやって進めればいいか詳しく教えて:生成AIお悩み相談室(1)(1/2 ページ) - @IT
RAGと紹介対象のツール群について
本節ではRAGの説明と紹介予定のツール群とそれらの違いについて説明します。
まずRAGとは、LLMモデルに質問する前に外部から必要な情報を取得し、その情報を質問に加えることでLLMの回答精度を上げる仕組み・技術です。
LLMモデルによる回答は、知らない情報をそれらしく回答して間違えたり、知っている情報でも確率的に間違えて出力される(例えば10回やると9回は成功するが1回間違える)事があります。
このような事を抑える為に、回答する為に必要な情報・補足情報を合わせて渡す事で回答精度が向上する、というメリットがあります。
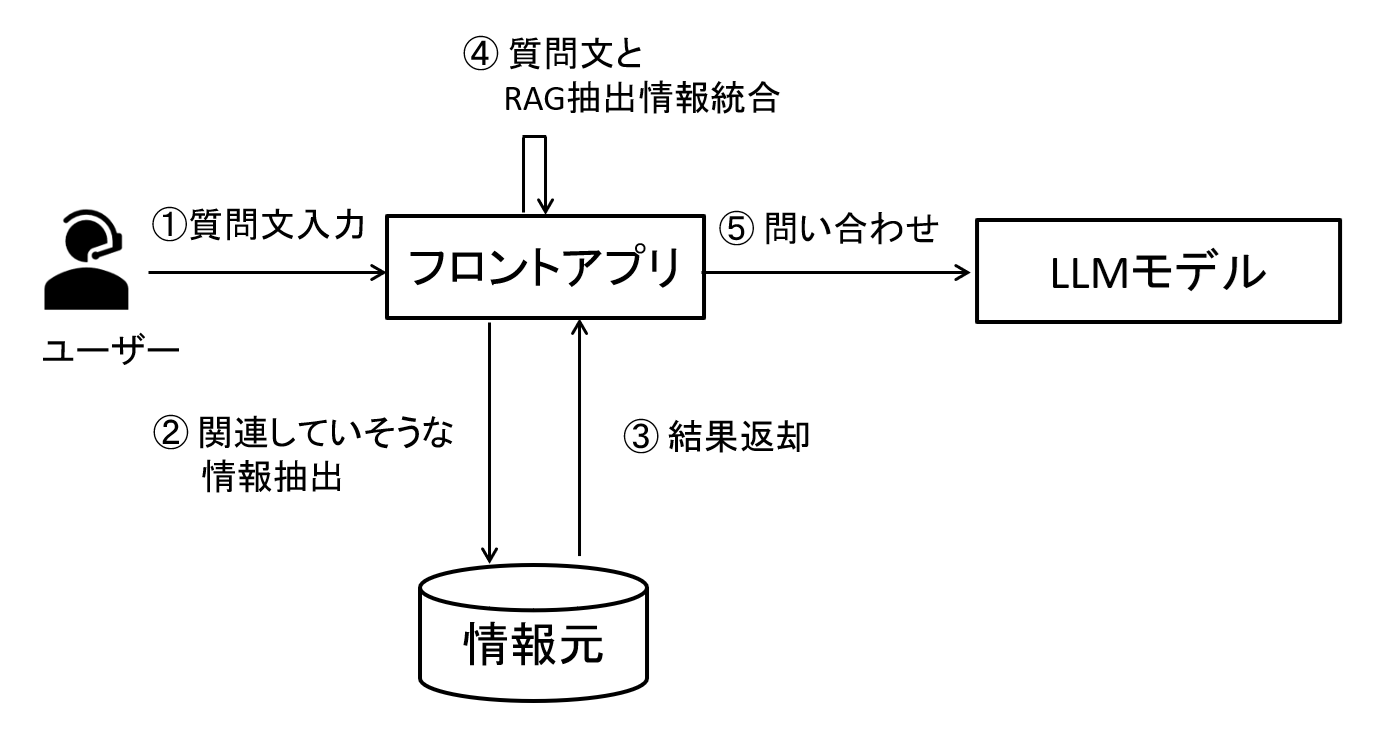
図1 RAGの処理イメージ
情報の取得元は例えば以下のようなものがあります。
|
情報収集元 |
ユースケース例 |
|
① Web検索 |
・最新情報(例えばLLMモデルの学習の後に登場した製品やニュース、更新された法律など)の取得。 ・現在の状態取得(本日の日にちや天気、施設の混雑状態など)。 |
|
② ベクトルDB |
・Webに記載がない情報。 |
|
③ RDB |
・社内で利用しているシステムのDB内情報など。 |
|
④ グラフDBやドキュメントDB |
・利用するNoSQL DBMSによる。 |
この中でもRAGで最も代表的なものが②のベクトルDBを使うタイプです。
これはテキストなどの情報をベクトル化して、データベース(DB)に保存する手法です。
ベクトル化は、簡単にいってしまえば数値化するようなイメージです。
ユーザの質問も同様にベクトル化し、数値情報を比較して意味的に近しい情報を取得します。
ここで、情報をベクトル化する仕組みが必要となります。
これを実現するのが「Embeddingモデル(埋め込みモデル)」です。
Embeddingモデルも、LLMモデルと同様にクラウド型、ローカル型含め様々なモデルが存在します。
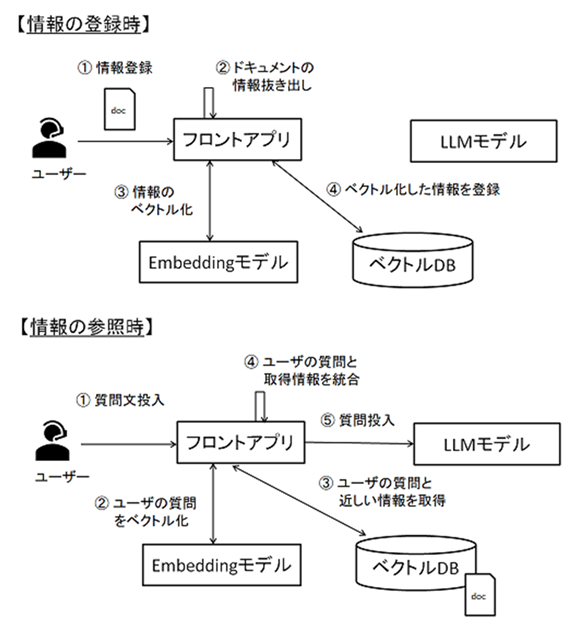
図2 RAG利用の流れ
上記の通り、ベクトルDBを利用する場合は「情報(社内ドキュメントなど)をベクトル化・登録」する段階と「ユーザが質問する」段階の2つがある事がわかるかと思います。
もちろん段階を別々にわけず、常に同時に実施しても良いですが、その場合常に情報のベクトル化と登録処理が発生する為、処理時間が長くなります。
よって、基本的には上記は分けた方が良いと考えます。
なお、DBに情報を登録する事をindexing(インデキシング)と呼びます。
あわせて登録を行う際のデータ構造をindex(インデックス)と呼びます。
RAG関連ではよく使う言葉なので覚えておくと良いでしょう。
RAGの処理の流れが理解できたところで実現方法に移りますが、これも様々です。
クラウドサービスを利用するほか、OSSを使って自作するという案もあるでしょう。
これから紹介する「Dify」「LangChain」「LlamaIndex」は後者に該当します。
それぞれのツールの違いは以下のようになります。
|
ツール名 |
特徴 |
|
Dify |
ノーコードで(プログラムをせずに)LLMアプリケーションを作ることができる。 |
|
LangChain |
LLMアプリケーションを作る為のフレームワーク。 |
|
LlamaIndex |
LLMに質問する際に使うデータ管理や検索に特化したフレームワーク。 |
このようにそれぞれ特徴は異なる為、実際は組み合わせて利用する事もあるかと思います。
今回はそれぞれのツールの考え方を理解する為、単独での利用を例に紹介します。
ハンズオンの前の事前準備と前提
今回はローカルのLLMモデルとEmbeddingモデルを利用して、ベクトルDBを使ったRAGを実現したいと思います。
LLMモデルは「gemma3(4b)」、Embeddingモデルは「nomic-embed-text」を利用したいと思います。
|
[補足] Ollamaコンテナの構築については、 |
事前にollamaコンテナ内にてgemma3とnomic-embed-textをpullしておきます。
ollama pull gemma3
ollama pull nomic-embed-text
| [補足] もしgemma3が上手くpullできない場合は以下コマンドでdockerコンテナを削除し、再登録してください。 |
ollamaにgemma3をダウンロード出来たら、ollama runコマンドで推論の動作確認をしてみましょう。

上記が動作検証してみた結果ですが、当社の設立は2017年ですので、誤りが発生してしまいました。
これをRAGで改善できると良さそうです。
RAGで利用するDBに登録するドキュメントは以下のような内容とします。
300文字程度で、上記で回答できなかった設立年の他、様々な情報を含めました。
[2025年5月時点の情報]
NTTテクノクロス株式会社は最先端の技術とサービスを提供する企業です。本社は東京都港区芝浦にあるグランパークタワーにあります。本社以外にも、武蔵野事業所、横浜事業所、名古屋事業所、大阪事業所があります。設立は2017年4月1日で、NTTソフトウェアとNTTアイティの2社の合併と、NTTアドバンステクノロジの一部事業部の統合により誕生しました。合併前には、合併後の会社名が「ソフトウェア」「アイティ」の2社名を一部とって「NTTソフティ」になるのではないか、という噂が社内で流れました。安直すぎる上に、無駄に「柔らかそう」など、突っ込みどころが多すぎる為、その噂が現実になることはありませんでした。
またドキュメントのフォーマットはPDFとしたいと思います。
最後に、今回を含む3回分の各ツールの利用バージョンを示します。
※ pip関連パッケージは次回(第4回)、次々回(第5回)に必要です。今回のハンズオンでは「ツールバージョン」に記載のもののみ必要です。
● ツールバージョン
Dify 0.6.16
Ollama 0.6.6
Python 3.10.13
● pip関連パッケージバージョン
Package Version
---------------------------------------- -----------
chromadb 1.0.4
langchain 0.3.23
langchain-chroma 0.2.2
langchain-community 0.3.21
langchain-core 0.3.51
langchain-ollama 0.3.1
langchain-text-splitters 0.3.8
llama-index 0.12.30
llama-index-core 0.12.30
llama-index-embeddings-ollama 0.6.0
llama-index-llms-ollama 0.5.4
llama-index-vector-stores-chroma 0.4.1
なお、本記事の内容を用いた開発・運用は、必ずご自身の責任と判断によって行ってください。
開発・運用の結果について、いかなる責任も負いません。
ハンズオン: DifyでRAGを試す
本節ではDifyでのRAG実現について紹介します。
Difyの起動とOllama上のモデル登録
Difyのインストールは以下を参照し、ブラウザにてアクセスまで実施ください。
第1回 > Difyの使い方の例について > 初期設定
以降でブラウザの画面からgemma3とnomic-embed-textを登録します。
まずは右上にあるアカウント名をクリックして、「設定」を開きましょう。
その後、「モデルプロバイダー」を押下して、Ollama > モデルの追加 を選択します。
gemma3の登録は以下のように指定します。
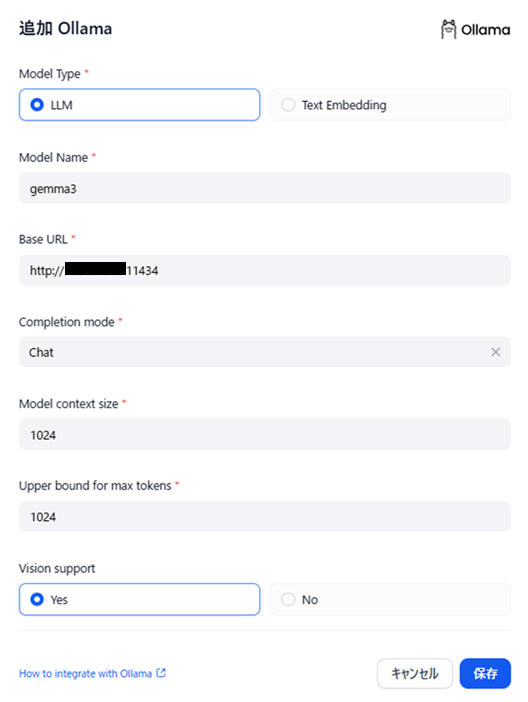
図3 Dify上でのgemma3登録画面
gemma3はLLMモデルとして利用する為、「Model Type」は「LLM」を指定します。
コンテキストサイズや最大トークン数は第2回同様小さめとします。
また、Vision Suportはgemma3がサポートモデルの為、「Yes」を指定します。
(ただし今回この機能は利用しません)
gemma3の登録ができたら、次はEmbeddingモデルを登録しましょう。
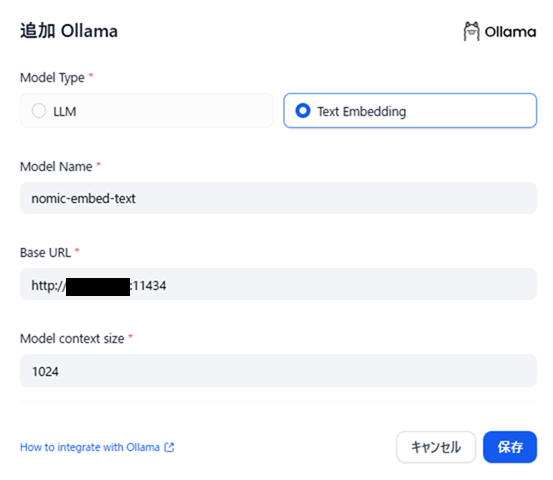
図4 Dify上でのnomic-embed-text登録画面
「Model Type」は「Text Embedding」を指定します。
他はgemma3と同じような設定となります。
両方登録できたら準備完了です。
RAGの仕組みの準備とドキュメントの登録
Difyで「ナレッジ機能」を利用してRAGを実現します。
画面上部にある「ナレッジ」タブを押下し、「ナレッジの作成」を行います。
登録するドキュメントを指定したら、「自動」か「カスタム」か設定を選べます。
どちらを選んでも良いかと思いますが、本記事では「カスタム」を選びたいと思います。
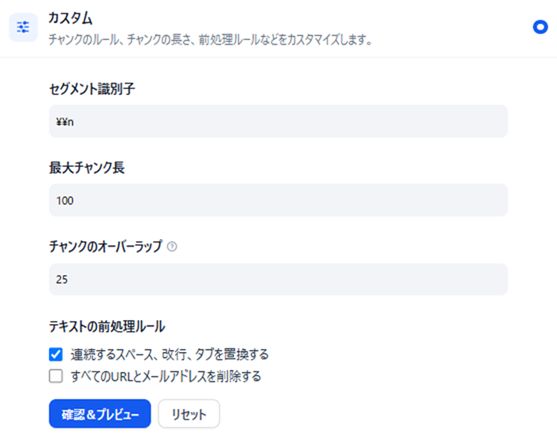
図5 ナレッジ機能の設定画面
今回は上記のように設定しました。
チャンク数とは、1つのデータ(セグメント)として管理する区切り(トークン数)を指します。
DBには、1レコードごとに1チャンクを入れるイメージを持っていただければ、と思います。
よって大きくすれば、1つのデータとして沢山の文字が入る事になりますが、長文が入ることで意味的に情報が多くなりすぎてしまうかもしれません。
一方で少なすぎると文章として成り立たなくなってしまったり、意味的に細かすぎて、利用時にユーザの質問に合わせて付与しても情報が足りなくなってしまう場合もあります。
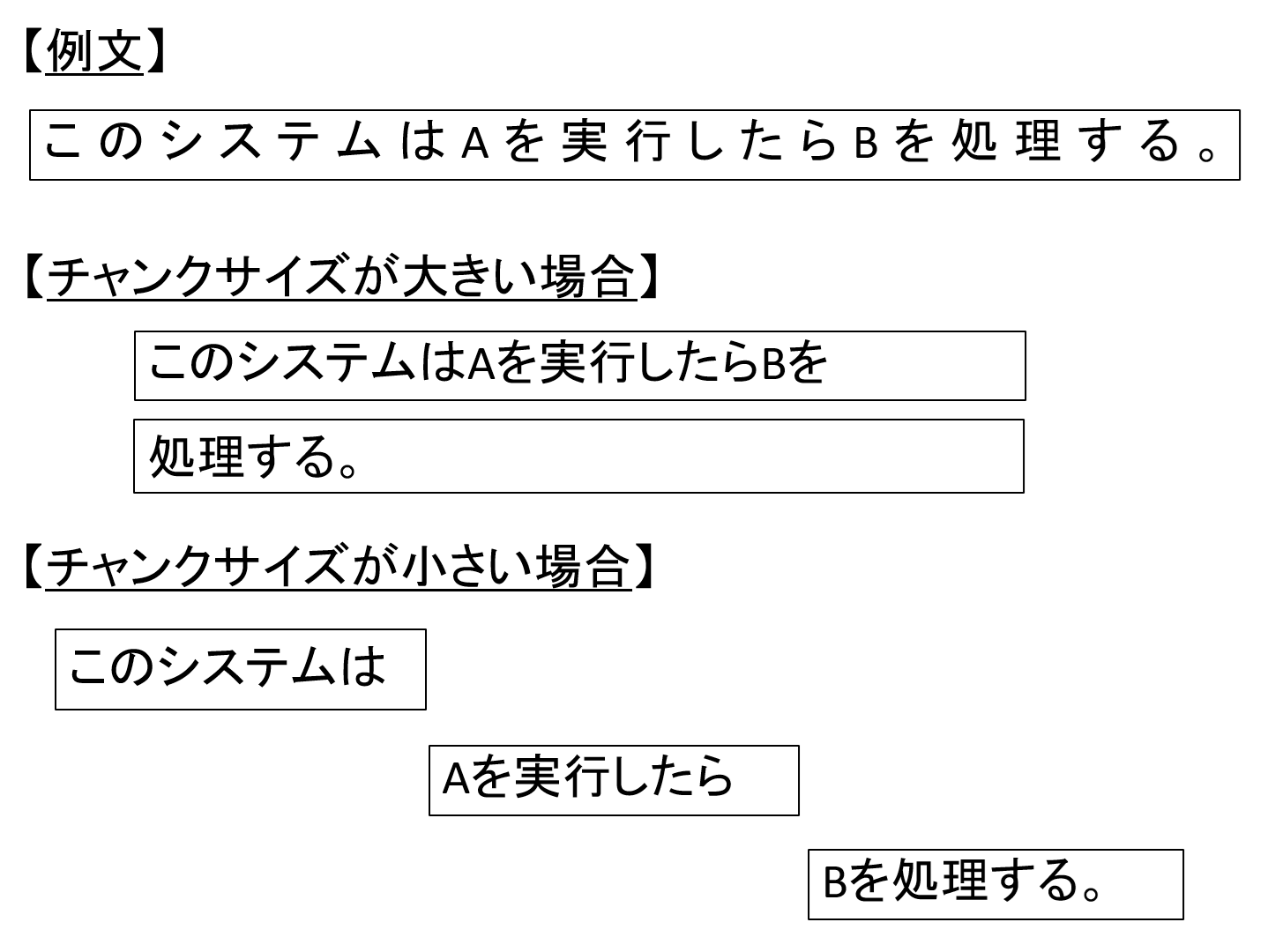
図6 チャンクサイズのイメージ
上記図で短い文で例を記載しています。
黒枠は1データ(セグメント)とみて頂ければ、と思います。
チャンクサイズの区切り方で、1データに入る情報が大きく変わる事がわかるかと思います。
また、チャンクで文章が途中で区切られると、データとして別物扱いとなる為、前の文脈との関係性がわからなくなってしまいます。
その為、チャンクで区切る際に、前のチャンクと一定トークン重複する形にすると文脈を維持できる場合があります。
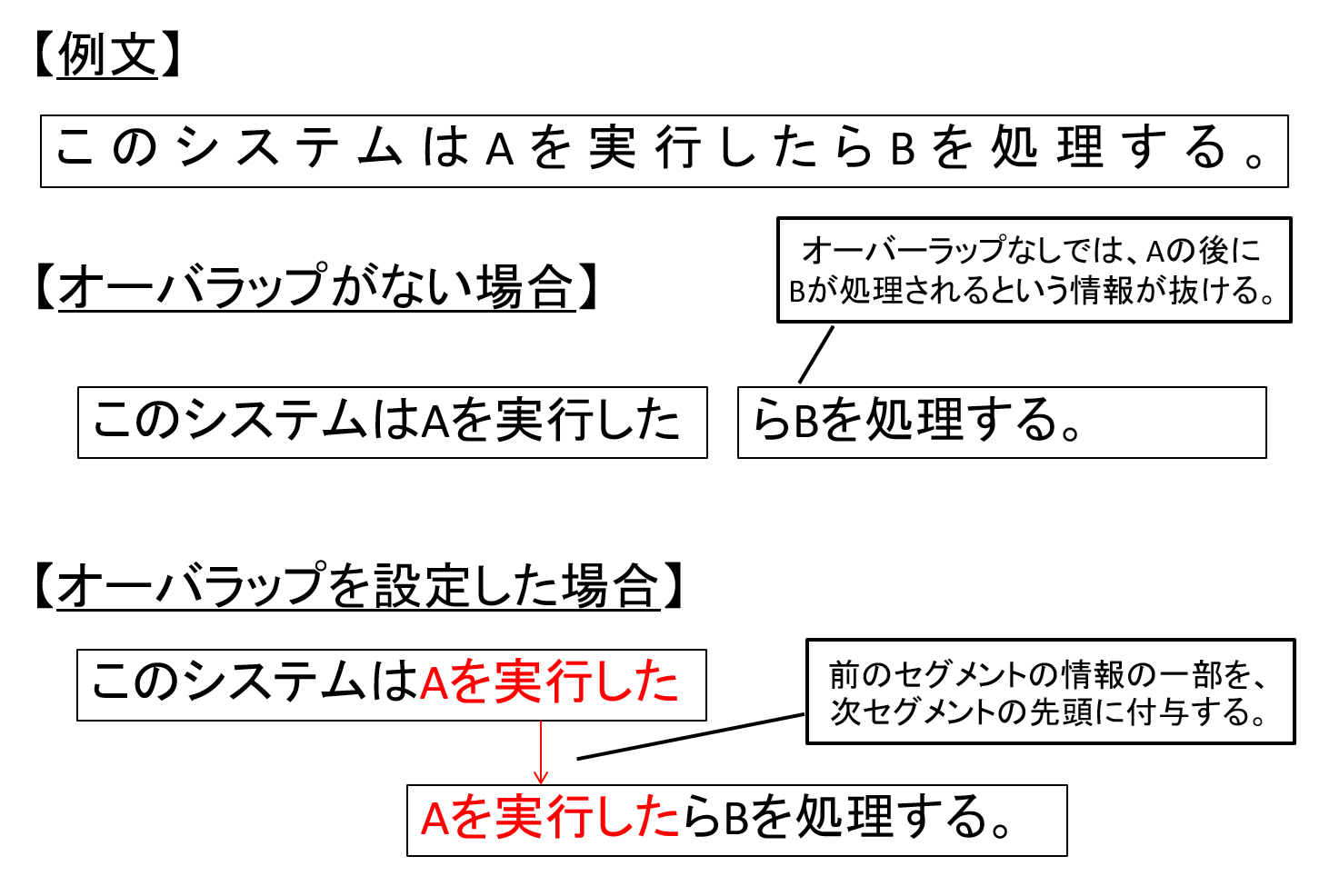
図7 オーバーラップのイメージ
このようにチャンクサイズやオーバーラップは、設定するドキュメントやユースケースに応じて最適な値を調整すると良いかと思います。
なお、「最大チャンク数」はあくまで「最大」の値の為、機械的に100トークンで区切られるわけではありません。
「確認&プレビュー」を押下するとどのように区切られるか確認もできます。
なお、今回の結果はセグメント内で余計な改行が入ってようにみえますが、これはPDF内で行が区切られた為に発生する事象です。
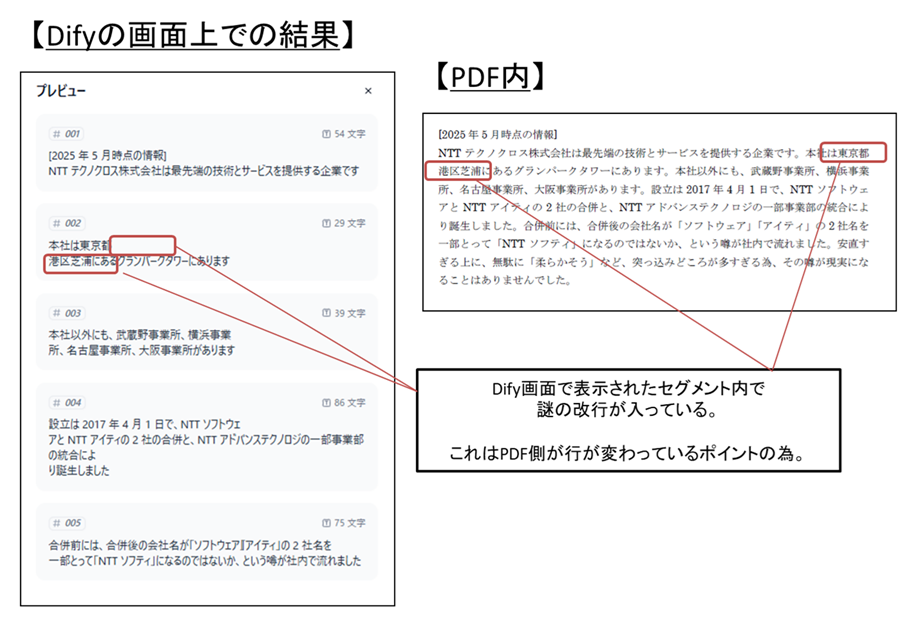
図8 読込対象のPDFとプレビューの結果
参考までに、テキストファイル(txt)で入れると、この事象は発生しません。

図9 PDFファイルとテキストファイルでのチャンクの違い
このように、ファイルのフォーマットによっても動作が変化します。
その為、最初は様々なフォーマットに対応せず、絞って対応・改善していけると良いかと思います。
少し横道に逸れましたが、設定を行った後、「保存して処理」ボタンを押すと、情報が登録されます。
これでRAGの準備とドキュメントの登録は完了です。
ユーザからの質問を受けるチャットボットを作る
続いてユーザの質問を受けて、登録したドキュメントを参照した上で回答するチャットボットを用意しましょう。
Difyトップページから アプリを作成する > 最初から作成 を押下します。
その後のダイアログで 「チャットボット」「基本」を設定の上、チャットボットの名前をいれて「作成する」ボタンを押します。
すると以下の画面が表示されます。
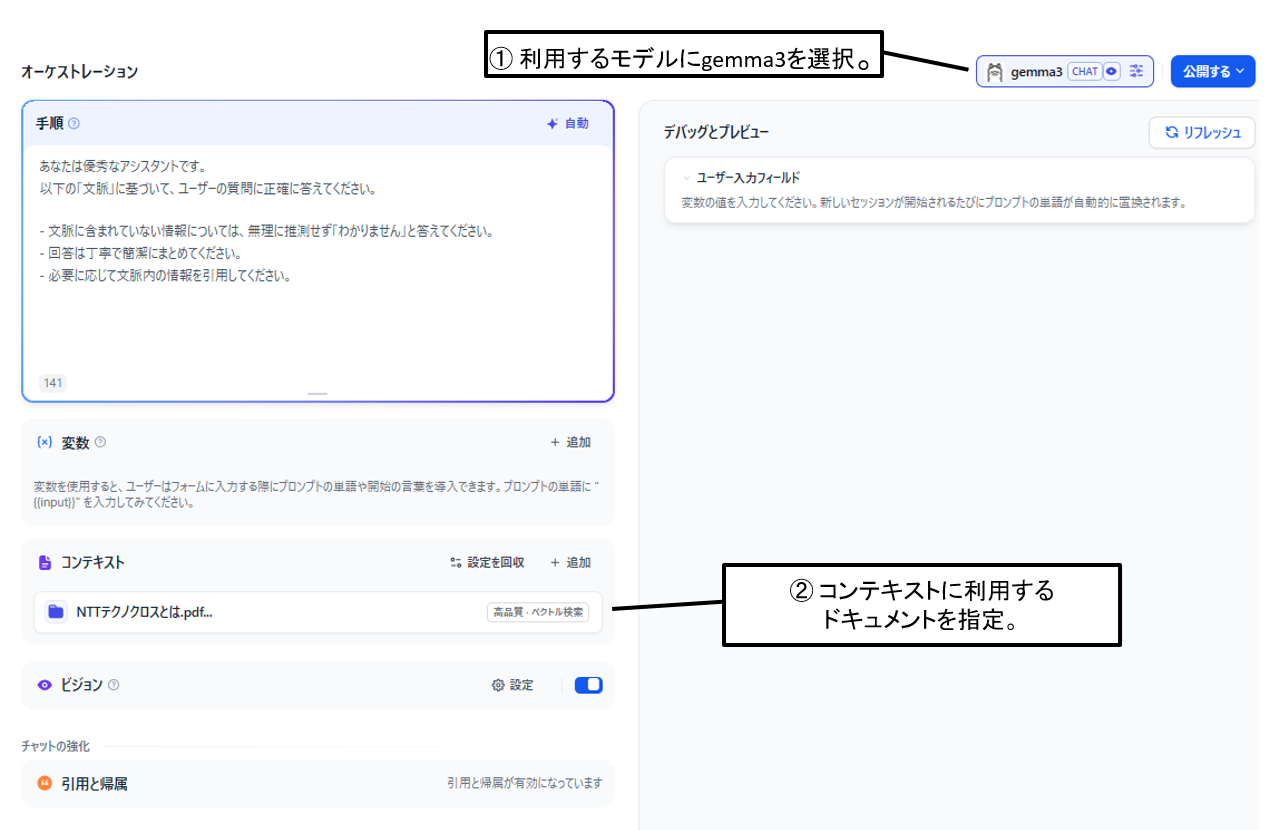
図10 チャットボット作成画面
「手順」欄はシステムプロンプトのようなものと思っていただければ、と思います。
システムプロンプトは、ユーザからは見えないプロンプトで、裏でLLMの役割や期待する処理の内容を記載することができます。
LLMに問い合わせを行う際には、システムプロンプトとユーザプロンプト(ユーザの質問)をあわせて使用します。
今回「手順」欄に記載はしていますが、記載がない場合でもデフォルトの値が入る為、なくても問題ないかと思います。
設定ができたら右側に「デバッグとプレビュー」画面があるので、試してみましょう。
実行してみた結果は以下となりました。
「設立」に関する質問も正しく回答できるようになったほか、「裏話」といった直接的な表現でなくてもうまく回答ができています。
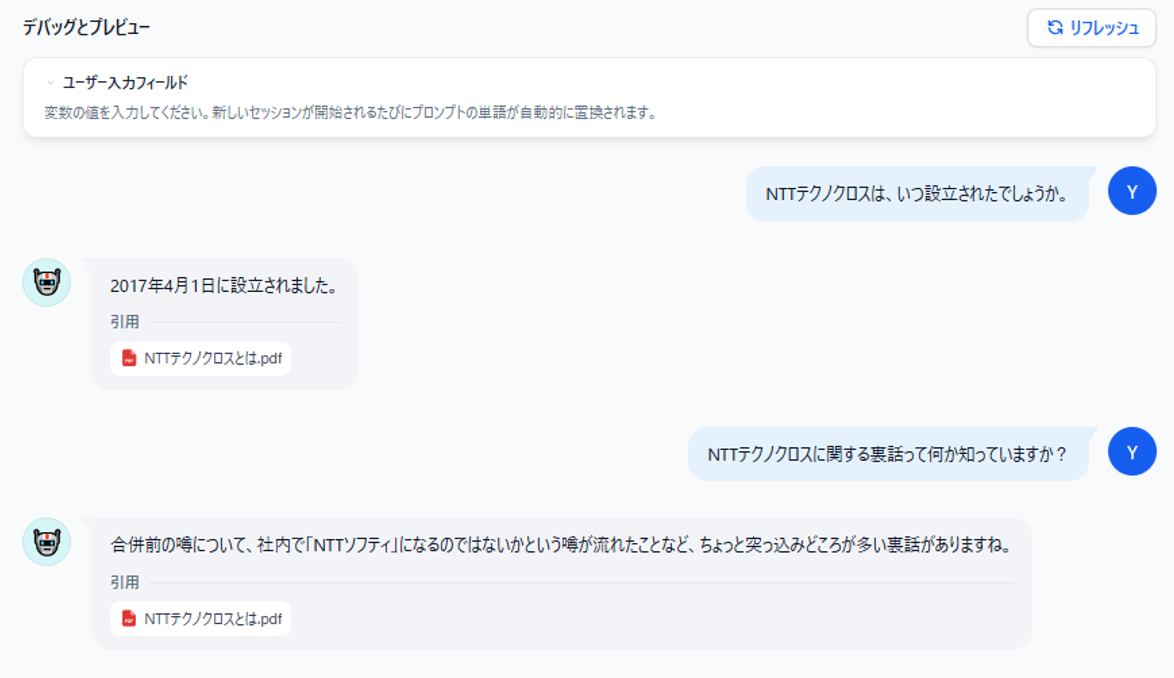
図11 実行結果
「引用」欄にあるファイル名をクリックすると、どのセグメントを取得したのかトレースも可能です。
RAGを使う場合、時に全く想定していない回答が返ってくる場合があります。
そのような場合には、まずは上記のトレースをみて、想定通りの情報を抜き出せているのか確認すると良いでしょう。
また上手く質問に関連した情報がヒットしていない場合は、チャンクサイズやオーバーラップの見直しやプロンプトの変更、利用するEmbeddingモデルの変更などをまず考えてみると良いかと思います。
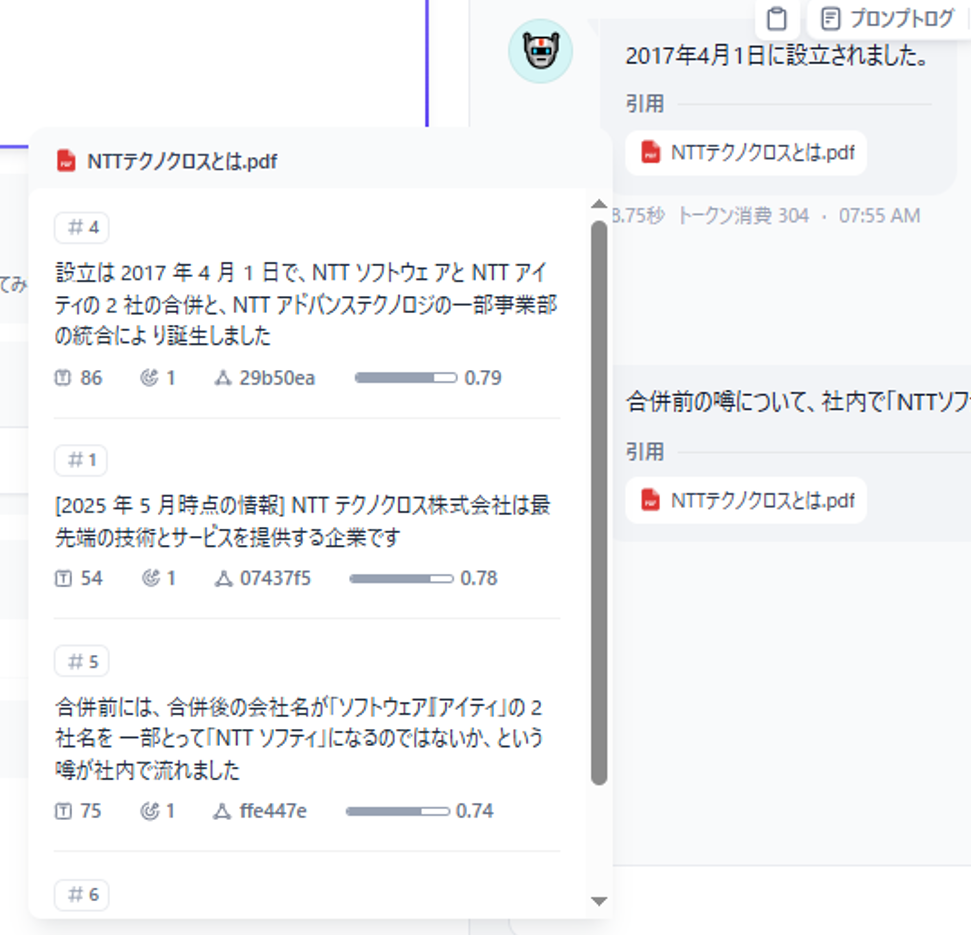
図12 RAGにてヒットした情報のトレース
今回はDifyの「チャットボット」機能の「基本」という極めてシンプルな例で試しましたが、第1回で触れたChatflow機能でナレッジ機能(RAG機能)を組み込む事も可能です。
Chatflow機能を使えば、処理方法自体も工夫したRAGの実現も可能となります。
このようにDifyを使えば簡単にRAGの効果を試すことができます。
おわりに
今回はDifyを題材にし、プログラムを挟まずにRAGの概念や仕組みといったRAGの基本を紹介しました。
Difyを使えば、簡単にRAGを用意し、効果を試すことができることが伝わったのではないでしょうか。
一方でRAG含めたLLMの活用に関しては、精度を上げる為、継続的な改善や工夫が必要です。
今回紹介したものはあくまで最低限のものであるとご理解ください。
今回、RAGの基本を押さえられたかと思うので、次回(第4回)は少し難易度をあげてプログラムレベルでの紹介をしたいと思います。
具体的にはRAG実装のサンプルコードからLangChainの特徴や使い方を紹介できれば、と思います。
本件についてのご意見やご質問などございましたら、以下からお問い合わせください。
最後までご覧いただき、ありがとうございました。
本件に関するお問い合わせ




<<<<著者プロフィール>>>>
フューチャーネットワーク事業部
第一ビジネスユニット
山口 佳輝(YAMAGUCHI YOSHIKI)
NWに関係したシステム開発を担当しています
>>>>>>>>><<<<<<<<<
![]()