爆速キャッチアップ!LLM活用をリードするプラットフォーム群 ~LLM活用入門第2回~
本記事ではLLMの可能性をより引き出し、活用をリードするプラットフォーム群(Dify, Ollama, LangChain, Hugging Face, Azure OpenAI Service, Amazon Bedrock)を紹介します。後半にはDifyとOllamaを使ってローカルLLMを用いたフロントアプリケーションを動かす例にも触れます。




はじめに
こんにちは、NTTテクノクロス 山口です。
最近何かと話題の大規模言語モデル(LLM)、自分たちも使ってみたい・試してみたいが専門用語や様々なサービスが多すぎてよくわからない、と言う事はないでしょうか。
今回は特に著名なOSS生成AI活用プラットフォームである「Dify」「Ollma」「Hugging Face」「LangChain」の4つを紹介したいと思います。
あわせて参考として、クラウド環境にあるLLMを使用する際の選択肢となる「Azure OpenAI Service(AOAI)」「Amazon Bedrock」についても簡単に触れたいと思います。
後半には、ハンズオンと題して「Dify」と「Ollma」を実際に連携動作させ、ローカルLLMをノーコードで試す手順も紹介したいと思います。
■ 目次
| 節番号 | 節タイトル |
| 1 | 各種プラットフォームの紹介 |
| 2 | [参考] クラウド上のLLM利用について |
| 3 | ハンズオン: DifyとOllamaの連携について |
[参考] 本記事の連載
本記事とあわせて、以下も良ければご確認ください。
| 連載番号 | タイトル | 概要 |
| 第1回 | 今だから知っておきたいDify!ノーコード・ローコードでLLM活用基盤を作ろう | Dify自体の説明とChatflow機能を使った例を取り上げています。 |
| 第2回 | 爆速キャッチアップ!LLM活用をリードするプラットフォーム群 | LLMの可能性をより広げるDify/Ollama/LangChain/Hugging Faceの紹介と、 DifyとOllamaでローカルLLMを活用したChatflow機能の利用に関して取り上げます。 |
| 第3回 | RAGとは?Difyから基本を学ぶ | RAGの基礎的な説明とDifyを使った実現方法を取り上げています。 |
| 第4回 | ローカルモデル利用のRAG実装で学ぶLangChainの基礎 | ベクトルDBを用いたRAGのサンプルコードから、LangChainの基礎を解説します。 |
| 第5回 | ローカルモデル利用のRAG実装で学ぶLlamaIndexの基礎 | ベクトルDBを用いたRAGのサンプルコードから、LlamaIndexの基礎を解説します。 |
| 第6回 | Difyで学ぶ、RAGの精度改善手法 | RAGの精度改善手法をDifyのChatflow機能を使いながら紹介します。 |
| 第7回 | ローカル環境で実現する、GraphRAGの基礎 | GraphRAGの基礎から、LangChainとNeo4jを使ったグラフRAGの実装例を紹介します。 |
| 第8回 | ローカル環境で実現する、Text-To-SQLとRDBを用いたRAG | Text-To-SQLと、それを活用したRDBを用いたRAGの実装例を紹介します。 |
| 第9回 | ファインチューニングとは?基礎を理解する | ファインチューニングとそのユースケース、手法を紹介します。 |
| 第10回 | Hugging Faceライブラリで実行する推論と学習の基礎(前編) | Hugging Faceのライブラリを使った、モデルのダウンロードや推論処理について紹介します。 |
| 第11回 | Hugging Faceライブラリで実行する推論と学習の基礎(後編) | Hugging Faceのライブラリを使った、ローカルモデルの学習処理と実行例について紹介します。 |
| 第12回 | AIエージェントとは?Difyから考え方を学ぶ | AIエージェントについて、Difyでの動作イメージも含めて紹介します。 |
| 第13回 | MCPとは?AIエージェントの可能性を広げよう | AIエージェントの可能性を広げる技術であるMCPについて紹介します。 |
各種プラットフォームの紹介
まずは本記事で紹介するプラットフォーム群の概要を以下の図に示します。
色々な観点で比較ができるかと思いますが、ここでは横軸を「自身の手元のLLMモデル(ローカルLLM)を実行するのか、クラウド上にあるLLMモデルを実行するのか」、縦軸を「使い方がプログラム寄りか、ノーコード寄りか(使う際の敷居の高さ)」として分類しています。
各プラットフォームが大体どの辺に位置するのかをなんとなく押さえられればと思います。
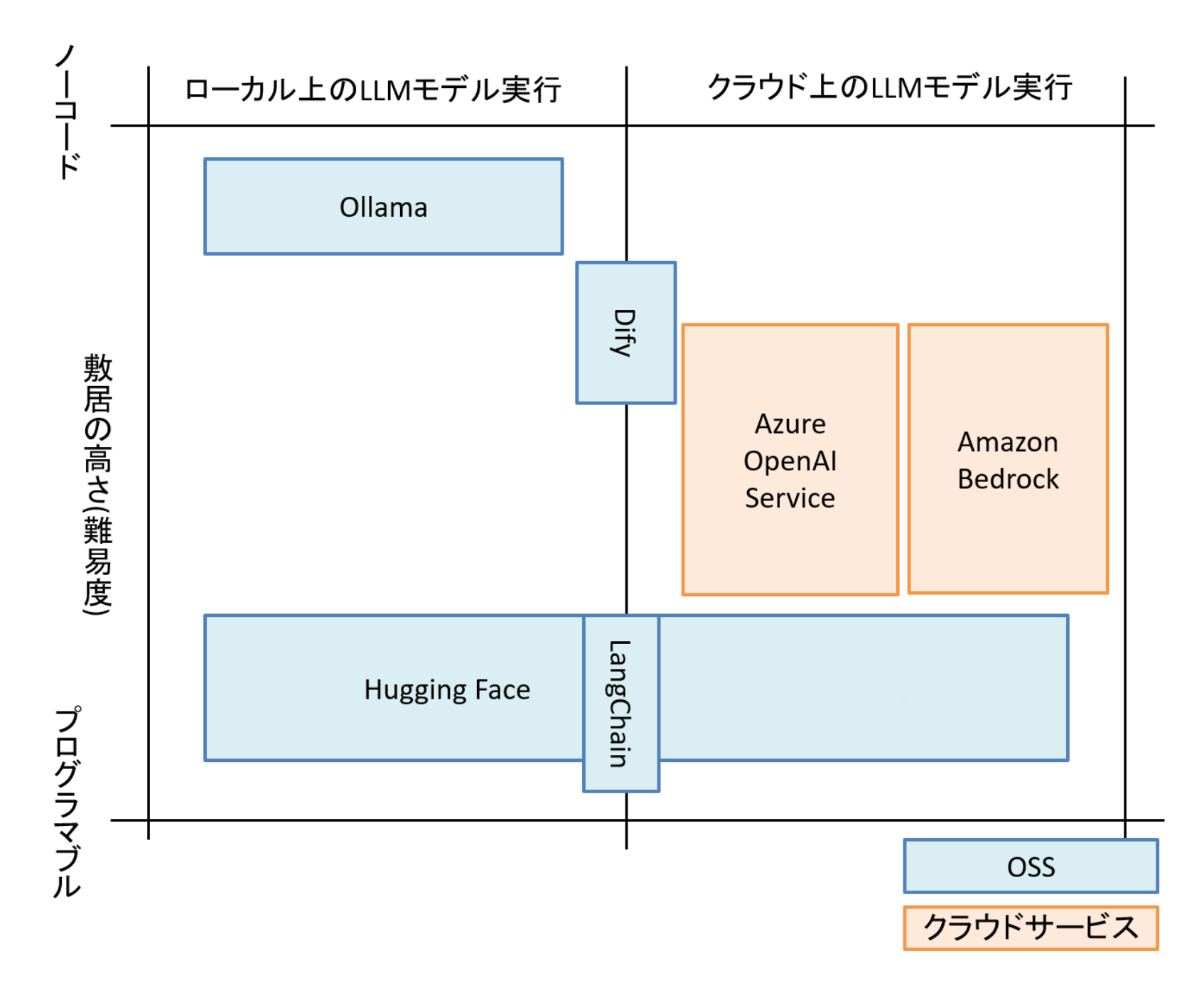
図1 各プラットフォーム・サービスのすみ分けイメージ
ここからは1つ1つのプラットフォームやサービスを簡単に紹介していきます。
それぞれのプラットフォームの位置に加え、上記図では示しきれない使い方の違いにも触れていきます。
Difyについて
Difyは前回も触れましたが、OSSの生成AI活用基盤を作れるプラットフォームです。
その最も大きな特徴は「ノーコード・ローコード」で簡単に生成AIに問い合わせを行うフロントアプリを作れる点にあります。
また、chatflow機能を使う事で、段階的な処理が必要な大きな処理や、複雑な処理を行う仕組みも作ることができます。
前回にchatflowを使った例も記載していますので、よければ前回も参照ください。
Ollamaについて
Ollamaはローカル環境でLLM(推論)を実行する為のOSSプラットフォームです。
概要の図でも触れていましたが、LLMの活用方法には「クラウドにあるLLMをWebブラウザ、あるいはAPIで実行する」方法と、「ローカルに置いたLLMモデルを実行する(ローカルLLM)」方法の2つがあります。
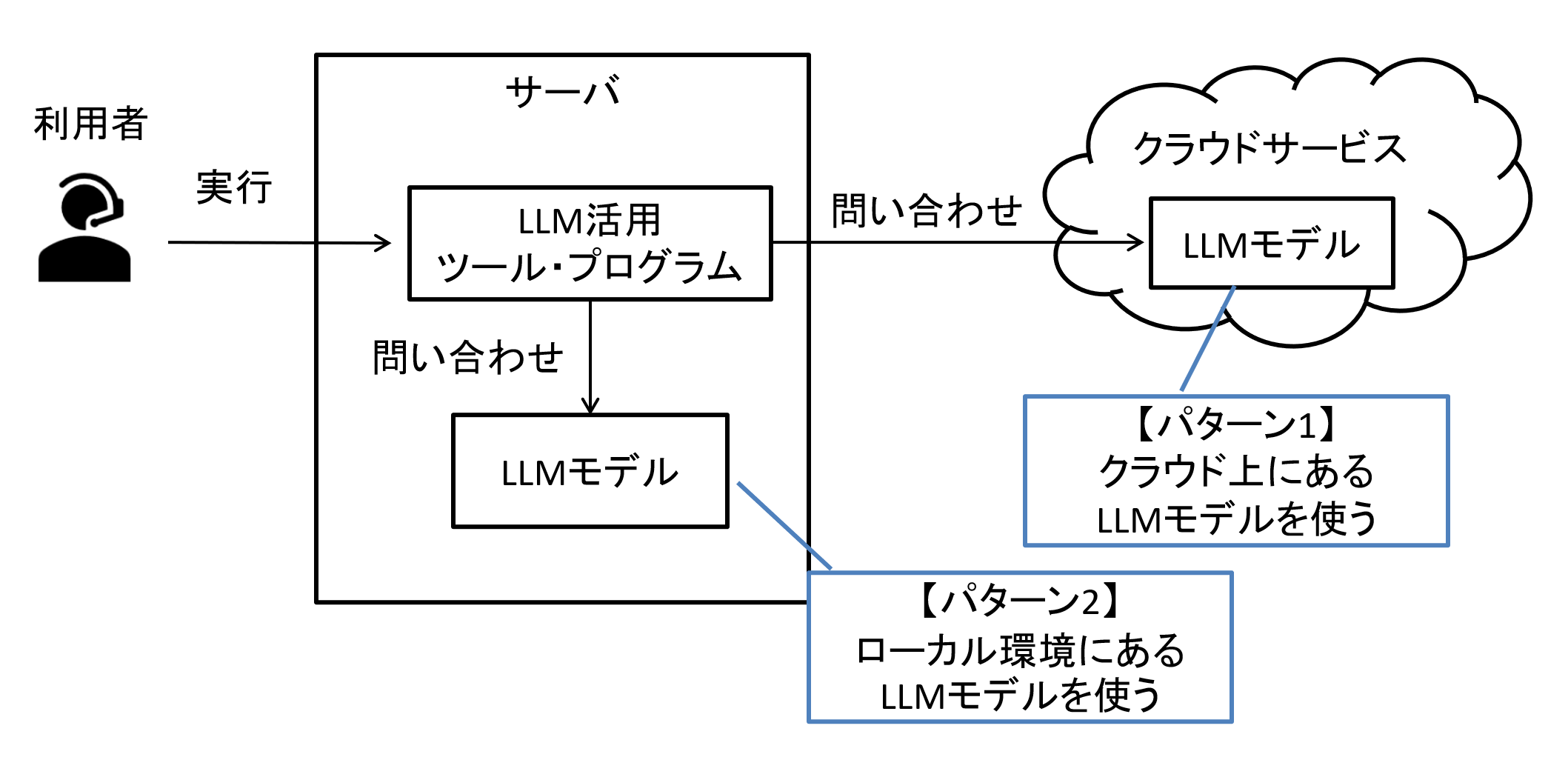
図2 クラウド型LLMとローカルLLM
クラウドにあるLLMを活用する場合はサービスにもよりますが、従量課金制であったり、インターネット接続不可な閉域網では使用できないという注意点があります。
ローカルLLMを活用する場合は自身の環境に置いている為、上記のような点は注意しなくても良くなりますが、一方で大きなモデルを使おうとする場合、スペックの高いマシンを用意する必要があります。
クラウドタイプにも、ローカルタイプにも様々な種類のモデルが存在します。
また、LLMは大きく「推論」と「学習」という2つが実行できます。
推論はLLMモデルに質問を問い合わせる事を指します。
ChatGPTを使って質問をすることは、クラウドタイプのLLMに対して「推論」を実行している、といえます。

図3 学習と推論について
よってOllamaは様々なローカルLLMに対し質問をすることができる(推論)プラットフォームといえます。
また、Ollamaはllama.cppと呼ばれるツールを内部処理で活用していることが知られています。
llama.cppは「量子化」という技術により、モデルを軽量化することができるツールです。
これによりモデルの処理速度の向上や、動作させるために使用するリソース量を減少させることが可能ですが、量子化する前のモデルと比較し、精度は落ちることがあり得ます。
よってOllama経由でモデルを動かす際にも軽量に動作させることができます。
※ ただし軽量化の効果にも限度がある為、どんなモデルでも少ないリソース環境(例えばCPUのみや、下位GPUのみ)で動かせるわけではない点は注意が必要です。
Ollamaで推論を実行するにはコマンドベースで対話的に実行する方法と、APIから実行する2つがあります。
なお、Ollamaにて、どのようなモデルが扱えるかは以下から検索が可能です。
※ なおOllamaは上記の他にも、この後説明するHugging Face上にあるモデル(正確にはGGUFと呼ばれるフォーマットのモデル)も実行可能です。
LangChainについて
LangChainはLLMをより上手く活用する為の、オープンソースのライブラリで、Pythonを始めとするプログラム言語で使用できます。
プロンプトのテンプレート化や複数の(段階的な)処理の実行、RAGを作る為のライブラリなどがあります。
ざっくりとしたイメージとしてはDifyでできる事+α をプログラムで実現する為のライブラリといったところで、LLMを利用する為のアプリケーションを作成する為のもの、というイメージを持っていただくと良いかと思います。
例えば「今の回答は60点の為、100点の回答してほしい」と追加問い合わせするプロンプトテクニックが効果的と良く言われますが、これを毎回ユーザが実行するのは労力がかかります。
よってアプリレベルで、裏で自動的に処理をさせる(ユーザに意識させない)と、便利でしょう。
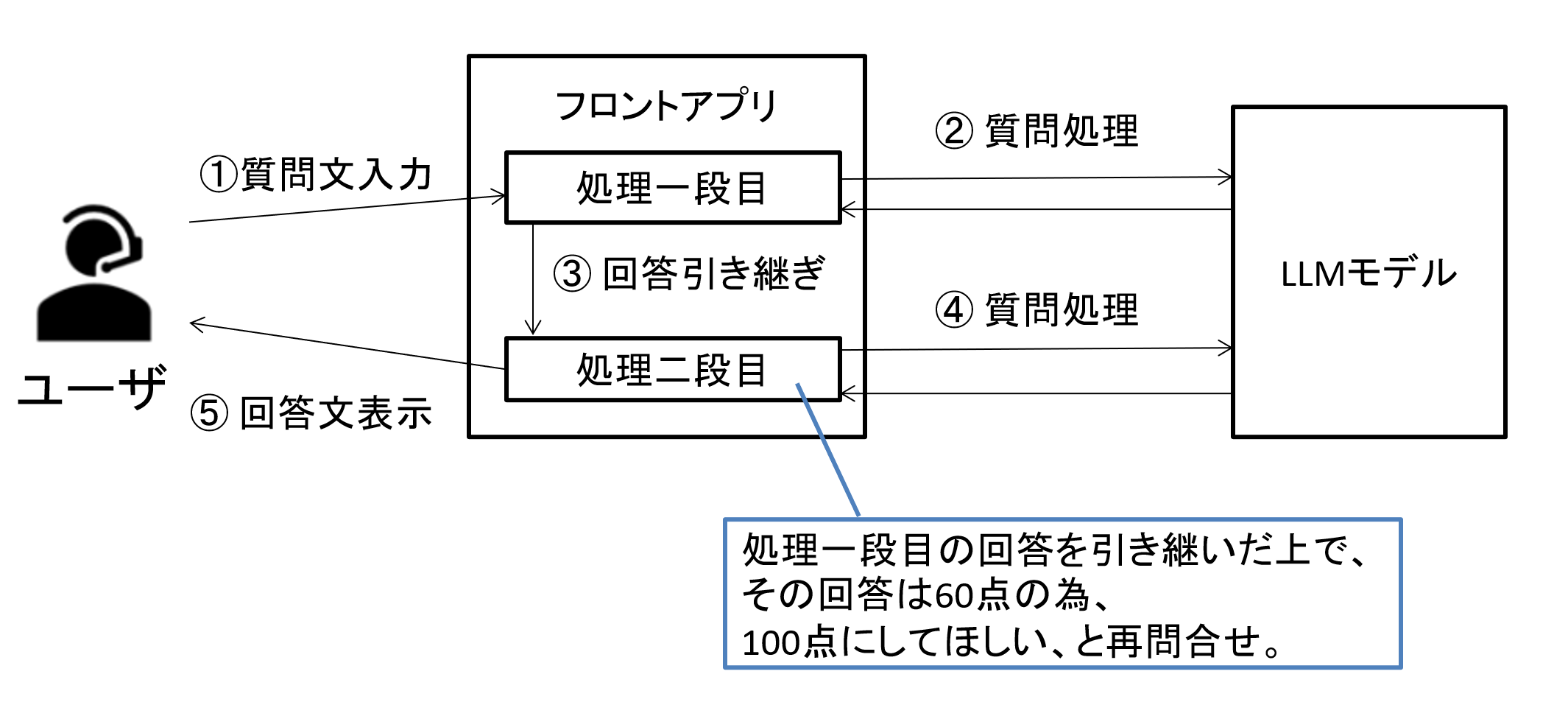
図4 フロントアプリ内で段階的な処理を行う例
他にもRAGを使用する際にドキュメントの前処理が必要な場合等があります。
例えば登録するドキュメントの形式変更(markdown形式への変更など)や画像の抽出などがあげられます。
あるいはどのようなDBにデータを入れるのか整理する事(ベクトルDB or RDB or GraphDB等のNoSQL系)も重要でしょう。
あくまで一例ではありますが、上記のような処理の実現は現状のDifyでは限界があります。
そのような場合にはプログラムを使う分、Difyより敷居は上がりますが、LangChainや他ライブラリを活用して実装するのも手でしょう。
なお、RAGにより特化したライブラリにllamaindexと呼ばれるものがあります。
興味があればこちらも調べてみると良いでしょう。
LangChainは上記の通りプログラムで使用するライブラリの為、他のライブラリと併用して使う事も可能です。
ただし、LangChainはLLMを活用する為のアプリケーションを作る為のライブラリである為、LangChain単体でLLMモデル実行環境までは用意できません。
実際にLLMモデルを利用するにはクラウド型のAPIを叩く他、前述のOllamaとの連携、この後説明するHugging Faceライブラリを使う等があげられます。
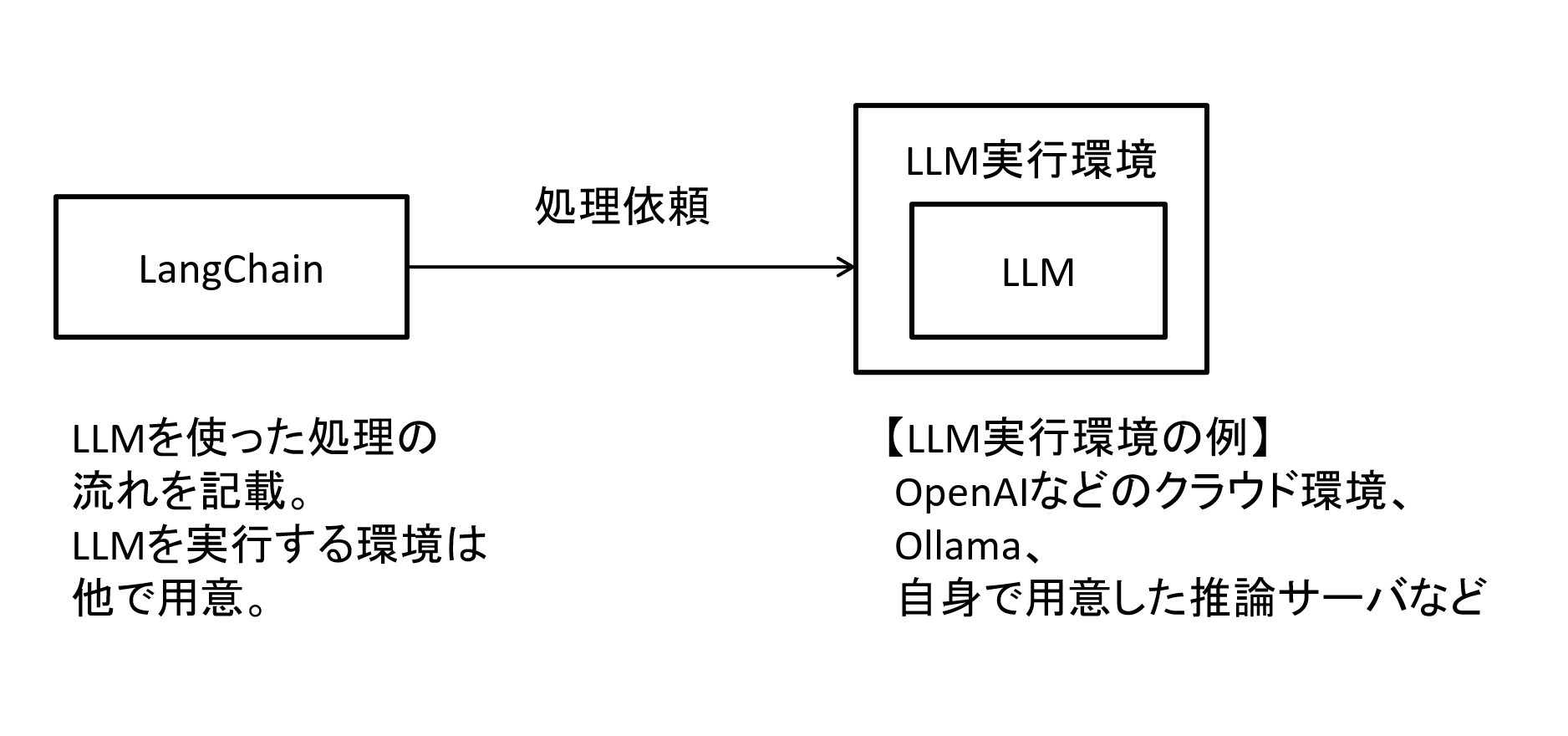
図5 LangChainとLLM実行環境の関係性イメージ
なお、LangChainからLLMモデルの実行環境を用意と処理の実行がしやすいように、例えばOpenAI社のAPIを使うライブラリ(langchain_openai)やOllamaとの連携ライブラリ(langchain_ ollama)、Hugging Faceとの連携ライブラリ(langchain_huggingface)も用意されています。
Hugging Faceについて
Hugging Faceは非常にできる事が多いOSSのAIプラットフォームです。
具体的にはAIモデルをアップロード・ダウンロードしたり、モデルを学習させる為のデータセットをダウンロードしたり、自身が作ったAIサービスをクラウドにホスティングできるサービスもあります。
Hugging Face Hubと呼ばれるWebサイトからモデル一覧やデータセット一覧が確認できる他、pythonをはじめとしたプログラミング言語で扱えるライブラリを提供しています。
イメージはdockerに近いのかもしれません。
自身の作ったコンテナをDocker Hubにあげたり、他人が作ったdockerコンテナをダウンロードして使うところはHugging Faceと近しいところがあります。
上記の通り、Hugging Faceは非常にできる事が多いのですが、ここからはHugging Faceが提供するライブラリについて触れていきます。
Hugging Faceのライブラリにも様々なものがありますが、特徴的な点は推論処理だけでなく、学習処理(例えばファインチューニング)を行う事ができる点(transformersライブラリやpeftライブラリを使用)です。
また、複数GPUや複数ノード(GPUマシン)での処理を実行しやすくできるライブラリ(accelerateライブラリ)も存在します。
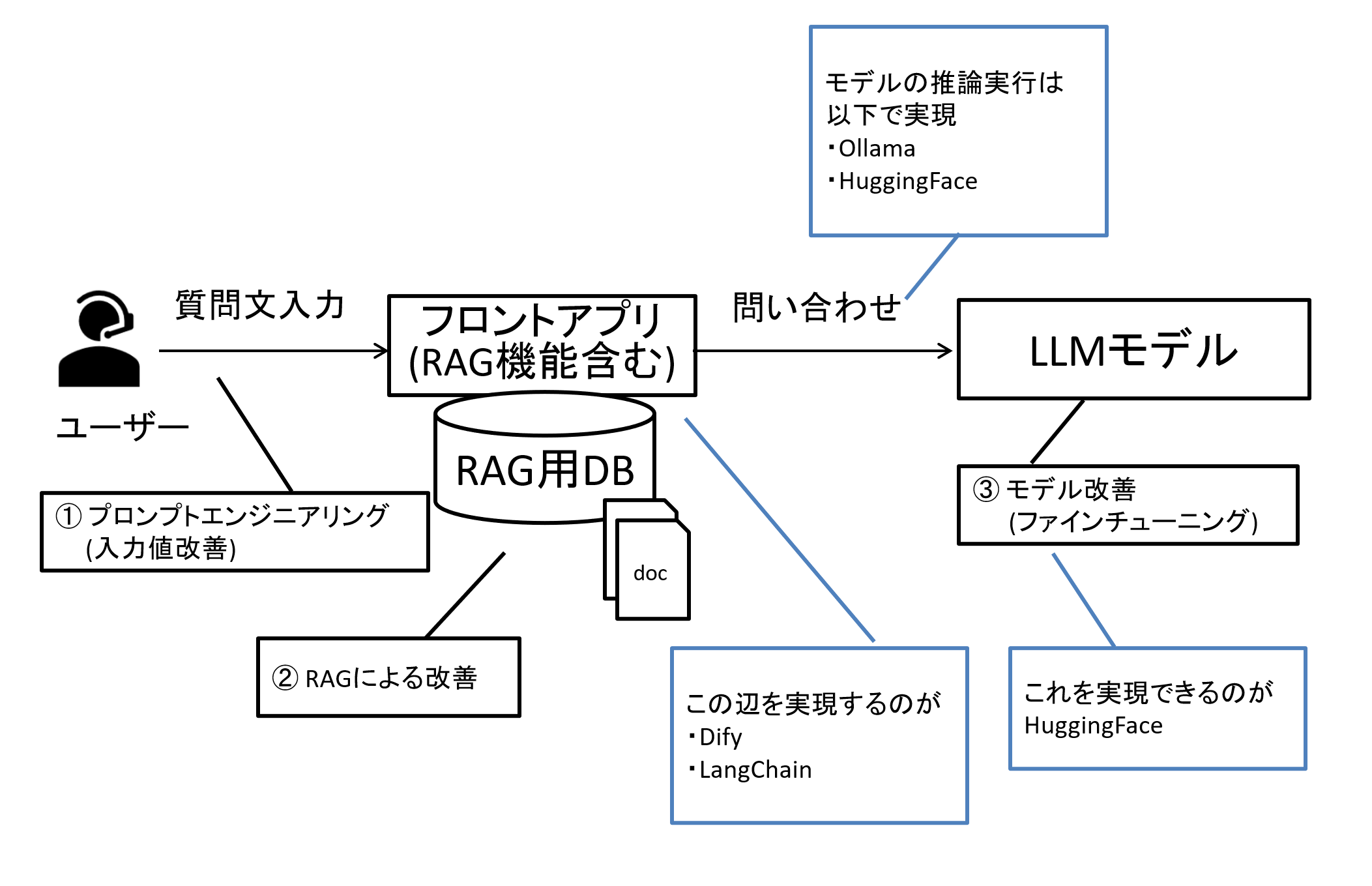
図6 各プラットフォームの適用箇所
Hugging Faceのライブラリを使う事で、Hugging Faceに上がっているモデルをローカル環境にダウンロードし、Hugging Faceにあるデータセットとファインチューニング用のライブラリを使用する事でファインチューニングを実施する、という一通りの処理を完結させることができます。
Hugging Faceに上がっているモデルは、以下から検索が可能です。
https://huggingface.co/models
[参考] クラウド上のLLM利用について
クラウド型のLLMを実行する場合、各LLM提供会社(例:OpenAI社)のサービスを利用する方法もありますが、AzureやAWSといった著名なパブリッククラウドから実行できるサービスも提供されています。
充実したセキュリティ機能や日本法への準拠、その他クラウド上サービスと連携できるメリットなどから、業務上では上記を利用するケースも多くあります。
以下では特に有名な2つのサービスを紹介します。
Azure OpenAI Service(AOAI)について
Miscoroft社のクラウドサービスで、Azure OpenAI Studioと呼ばれるGUIで操作を行って利用する他、API経由でOpenAI社のモデル(GPTやDALL-E等)が使用できます。
処理も推論だけでなく、学習(ファインチューニング)も実行可能です。
従量課金型や事前に使う処理能力を予約する支払方法はありますが、利用には費用が掛かります。
一方で上記で使ったデータはモデルの再学習に利用されない、と宣言されており、非常に高い精度のモデルを安全に使用できます。
[参考] https://learn.microsoft.com/ja-jp/azure/ai-services/openai/faq
モデルを使う際に社内情報を含めて質問をしてしまう事で、その情報がモデルの学習に使われて、全く別の人が同じような質問をした際にモデルが学習した内容を回答することで、意図せず情報が漏洩してしまう点を気にする企業や担当の方は多いかと思いますが、学習に使われないと宣言されている点は安心できるポイントかと思います。
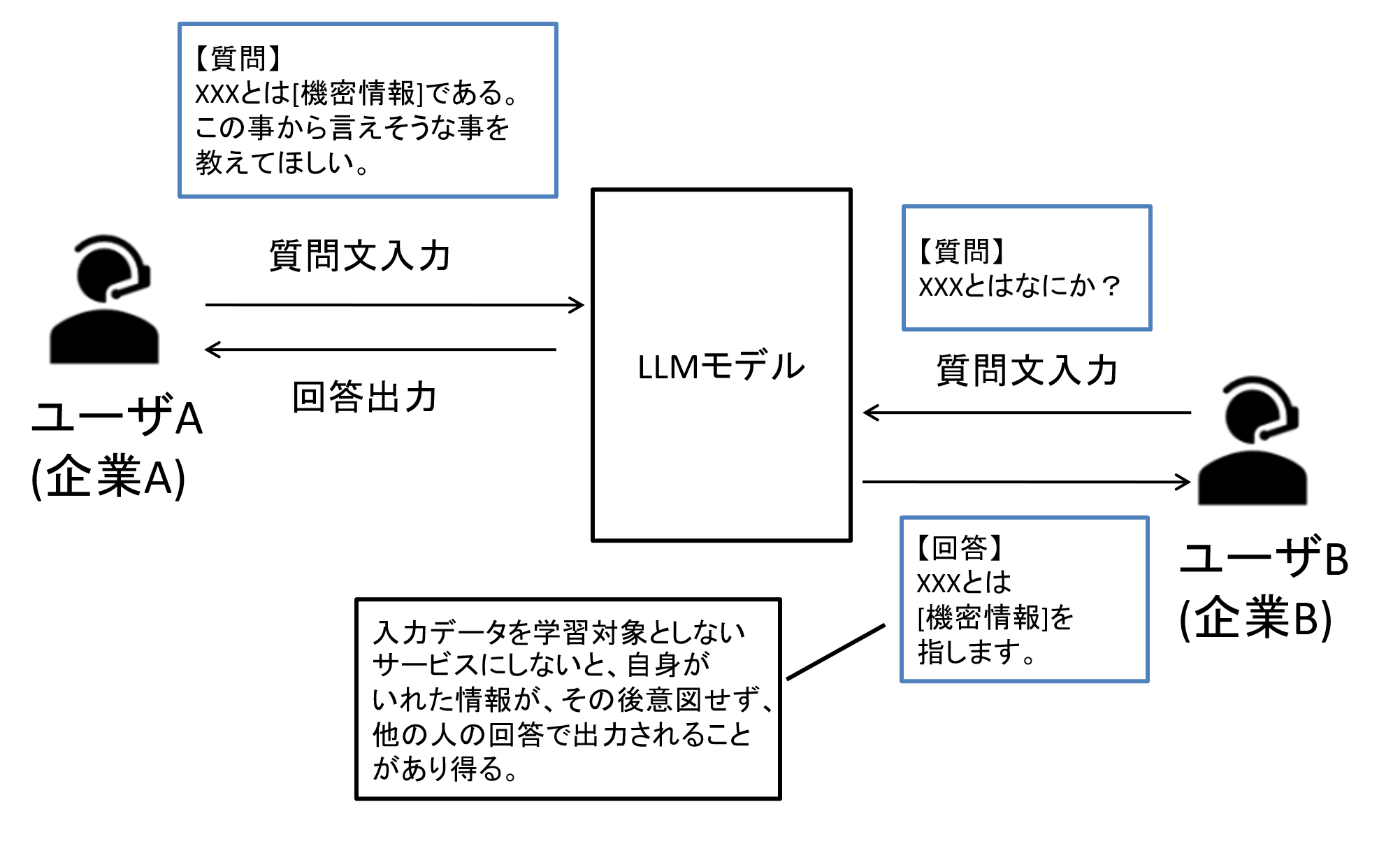
図7 モデルの再学習による懸念点
一方でクラウド上に情報が出ていく事に変わりはない為、使う際にはどこまで情報を入れていいのか等のポリシーは社内で整理しておけると良いと考えます。
Amazon Bedrockについて
AOAIがMicrosoftのクラウドサービスだったのに対し、Bedrockはその名前の通り、AWS(Amazon Web Service)で利用できるAI基盤です。
基本的な利用方法はAOAIと同様に、Playground機能と呼ばれるGUIで操作できるもの(ブラウザで操作するもの)の他、APIを使用し、モデルに対しては推論も学習も実行できます。
提供モデルについてはOpenAI社のモデルこそ使用できないですが、Anthropic社のClaudeやAmazon社が提供するLLMであるAmazon Titanなどが使用できます。
AOAIと比較し様々なモデルを利用できる点がメリットで、複数のモデルに対し同一プロンプトで推論を行い、結果を比較できる機能も有しています。
また、現在OpenAI社が提供していない、RAGの精度向上に使われるRerankモデルもBedrockからは利用できる点も優位点と考えます。
※ なお利用したいモデルにGeminiがある場合はAzureでもAWSでもなくGCPを利用する事となります。
料金に関してはAOAIと似ており、従量課金型や事前に使う処理能力を予約する支払方法があります。
AWSのサービスである為、その他のAWSサービス(Fargate等)と組み合わせた活用ができる点が強みとなると考えています。
また、RAG機能や、不適切な入出力をガードするガードレール機能など、様々な機能が提供されています。
AOAIと同様に、Bedrockも使ったデータはモデルの再学習に利用されないと記載があります。
[参考] https://aws.amazon.com/jp/bedrock/faqs/
AWS上にサービス基盤等を構築している場合は高い親和性があると考えます。
ここまでのまとめ
これまで6つのキーワード(プラットフォームやサービス)について触れてきました。
改めて各プラットフォーム・サービスのすみ分けイメージ図を確認してみましょう。
最初のころよりも、イメージが掴みやすくなったのではないでしょうか。
なぜその位置にプロットしたか追加説明が必要なものについては、図9の下部に記載していますので、併せてご確認ください。
図8 [再掲] 各プラットフォーム・サービスのすみ分けイメージ
※ Hugging Faceについては前述の通りライブラリでローカルにLLMモデルをダウンロードしてファインチューニングなどを行う一方で、AIサービスをホスティングするサービスがある事等からも、ローカルとクラウド両方で利用できる為、まだいた記載とした。
※ Dify、LangChainはあわせて連携するサービス(LLM実行環境)や利用するライブラリ等によりローカルモデルもクラウドモデルも活用できる為、真ん中に配置とした。
ハンズオン: DifyとOllamaの連携について
ここからはDifyとOllamaを連携させて、DifyからローカルLLMを実行する手順を紹介します。
Difyは前回実行した初期セットアップとワークフローを使う形としたいと思います。
適宜前回をご参照ください。
今回実施するのは以下の2つとなります。
(1)DifyとOllamaの連携設定
(2)前回作成したワークフローをOllamaに設定したローカルLLM実行で回答させる
(1). DifyとOllamaの連携設定
まず、Ollamaのセットアップを行いましょう。
docker pull ollama/ollama
docker run --name ollama -v ollama:/root/.ollama -p 11434:11434 --network docker_default -d ollama/ollama
ollamaコンテナが起動したら、以下を実行しましょう。
docker exec -it ollama bash
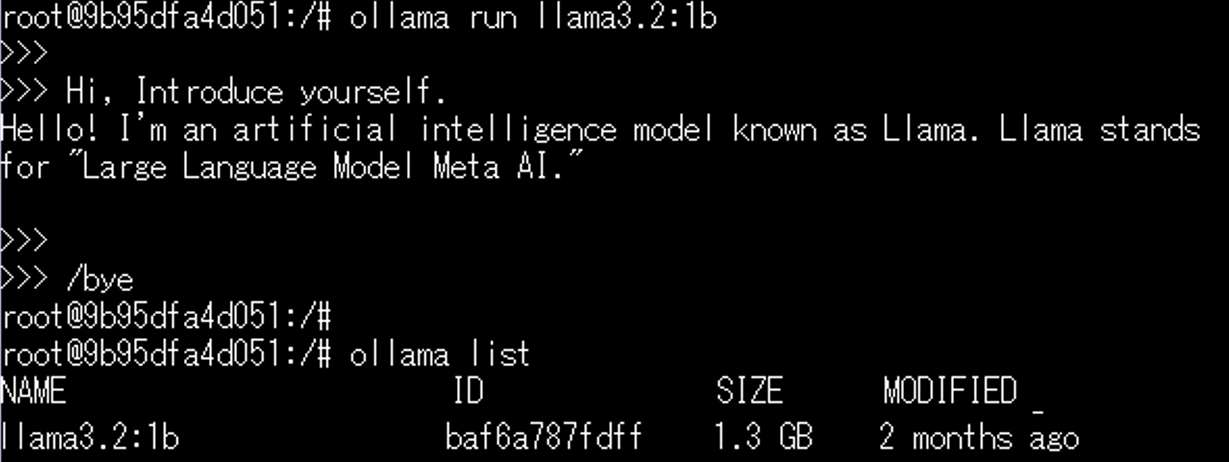
ollama run llama3.2:1b
/bye
ollama list
1つ目のコマンドで立ち上げたコンテナ内に入り、2つ目のコマンドで約1GBのサイズの小さいLLMモデル(SLM)であるllama3.2モデルをダウンロードし動かす指定をしています。
llama3.2:1bを別のモデルとすることで、他モデルを動かす事が可能です。
最後のコマンドではローカルにダウンロードしたモデル一覧を取得しています。
以下に、動作させた場合の例を記載します。
例ではモデルダウンロード後、「自己紹介」を求めており、その回答として「Llamaと呼ばれるAIモデルである」旨が返ってきています。
このようにOllamaでモデルを動かすだけであれば極めて簡単に扱う事ができます。
なお、対象のllama3.2モデルは英語等の8か国の言語をサポートしていると記載がありますが、日本語サポートの記載はありません。
そのようなモデルでも日本語で推論して動くのか、という観点でも見て頂けると良いかと考えます。
[参考] https://ollama.com/library/llama3.2
これでOllama側の設定は完了です。
次にDify側の設定をしましょう。
Difyの設定 > モデルプロバイダー からOllamaを指定し、以下の設定を行いましょう。
モデル名は正しいモデル名(ollama runコマンドで指定したモデル名)を記載しましょう。
URLはOllamaを立ち上げたマシンのIPを指定し、Ollamaコンテナを起動した際に指定したポート番号11434を指定します。
コンテキストサイズや最大トークン数は通常もっと大きい値(8194)を入れますが、今回は試験用でもある為、小さい値を設定しておきます。
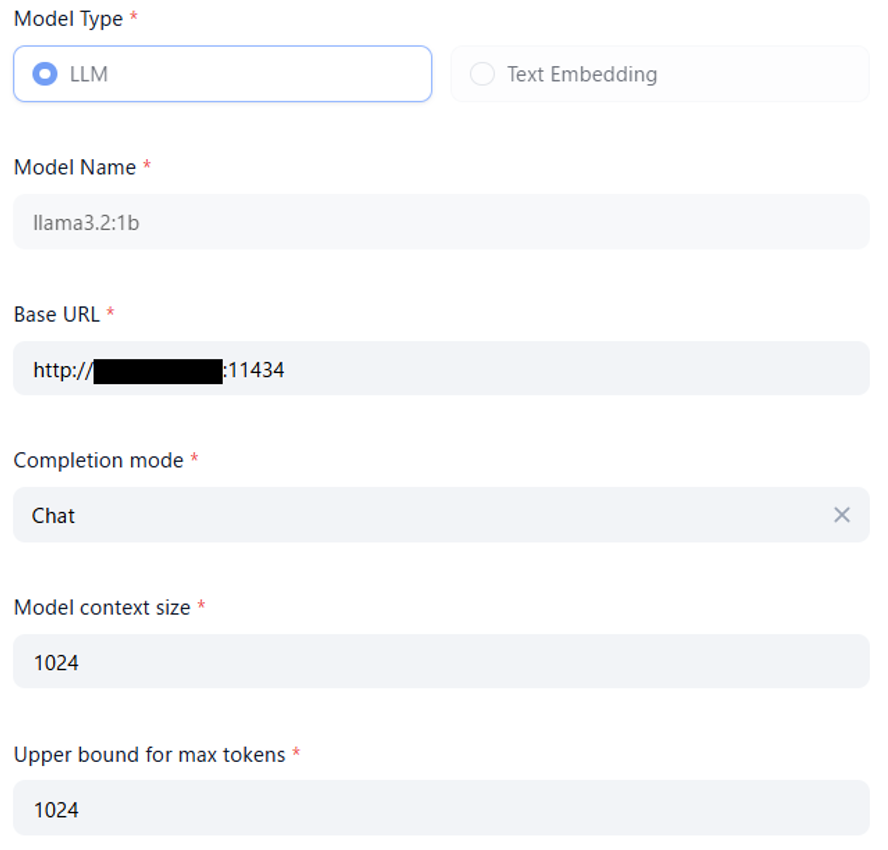
図9 Dify上の設定画面
上手く設定ができていれば、上記の設定ダイアログが自動で閉じられるかと思います。
これで連携設定は完了です。
(2). 前回作成したワークフローをOllamaに設定したローカルLLM実行で回答させる
では指定したモデルを使って動くか早速試してみましょう。
前回に作ったワークフローから、LLMの箇所を指定し、使用するモデルを変更します。
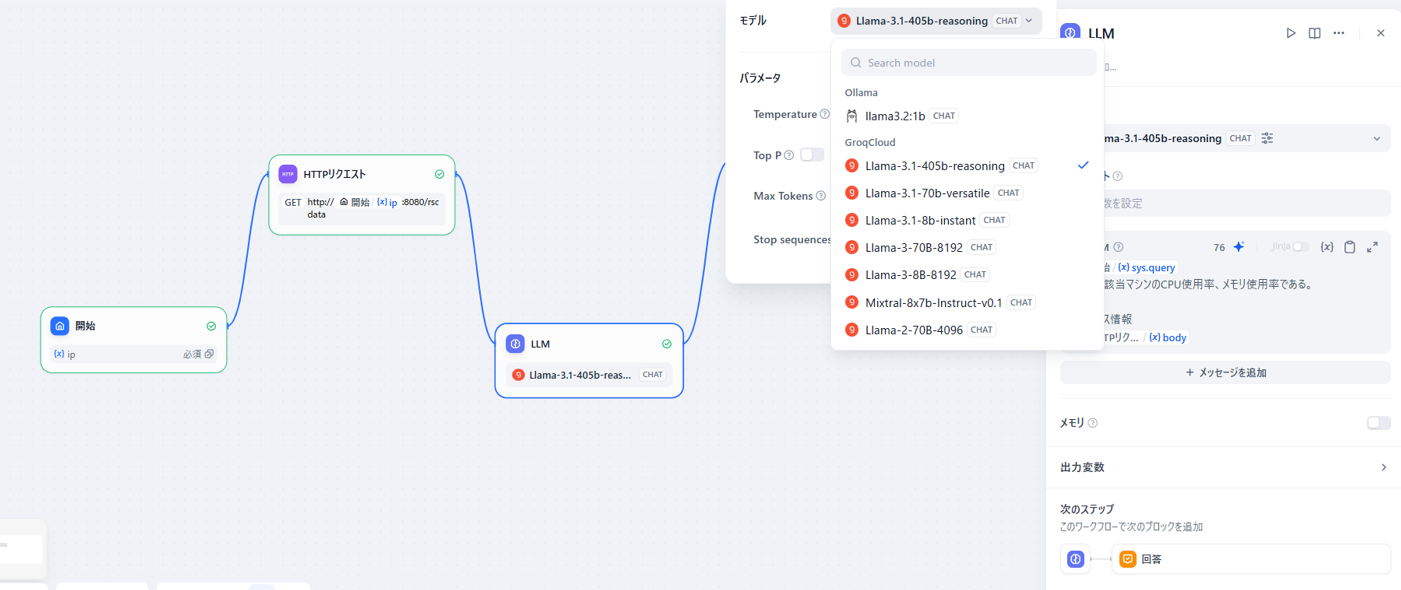
図10 Difyでのモデル変更イメージ
使うモデルの変更はこれだけで終了です。
では前回同様「デバッグとプレビュー」モードで動きをみてみましょう。
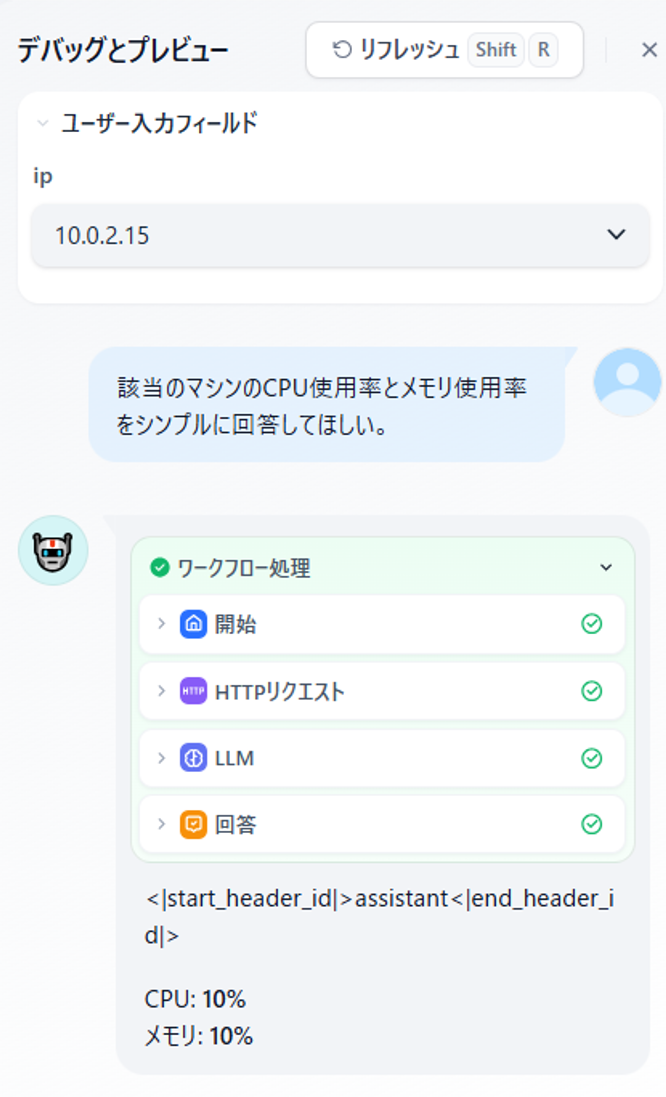
図11 DifyからOllamaのモデルを呼び出した際の実行結果
問題なく回答が返ってきました。
今回使用したモデルはサイズが小さい事もあり、複雑な処理・推論には向きません。
今回もかなりシンプルな例で実行しています。
またサポート言語に日本語は記載がなかったものの、一応日本語で推論をかけても動く事はわかりました。
ただし「動きはする」だけで推奨できるものではない事は予めてご了承ください。
おわりに
今回は各種プラットフォームやサービスの説明と、DifyとOllamaの連携について触れてきました。
本件について何かコメント等ございましたら、以下にご連絡ください。
最後までご覧いただき、ありがとうございました。
本件に関するお問い合わせ




<<<<著者プロフィール>>>>
フューチャーネットワーク事業部
第一ビジネスユニット
山口 佳輝(YAMAGUCHI YOSHIKI)
NWに関係したシステム開発を担当しています
>>>>>>>>><<<<<<<<<
![]()