YellowfinのETL機能で、データを集約して効率アップ(Yellowfin)
今回はBI活用コラムの第7弾として、BIツールYellowfinのETL機能についてご紹介します。




BI(ビジネスインテリジェンス)活用コラム
- 2019年07月30日公開

こんにちは。Yellowfin担当です。
データ分析をして報告書をまとめるとき、対象となるデータがパソコン上のExcelファイル、ネットワーク上のデータベース、クラウドストレージ等に散らばっているのはよくあることです。それらのデータをすべて集め、分析しやすい形でデータベース上の1カ所にまとめるのは、かなり面倒な作業となります。
このような作業の流れをあらかじめGUIで定義しておくことで、自動的にデータを集約することができます。この機能を「データトランスフォーメーション」または「ETL(Extract/Transform/Load)」といいます。ETLとは、さまざまなデータソースから分析に必要なデータを抽出(Extract)し、分析しやすい形に変換(Transform)し、1カ所のデータベース上に格納する(Load)ということを意味します。
本コラムでは、ビッグデータ分析ツール『Yellowfin』のVersion 7.4より搭載された「トランスフォーメーションフロー」という簡易的なETL機能を例に、データトランスフォーメーションの初歩的な使い方についてご紹介します。すでに『Yellowfin 7.4』を導入済みの方で、初めて簡易ETL機能をお使いになる方はもちろん、『Yellowfin 7.4』は使っていないが、ETLとはどんなものかと関心をお持ちの方にも参考になれば幸いです。
さまざまなデータソースからデータを抽出し集約する、ETL機能とは?
一般的にETL機能は、次の3つのサブ機能群から成ります。『Yellowfin 7.4』で実装されているサブ機能は以下の通りです。
E(Extract)…抽出、Yellowfinでは「インプットステップ」と呼ばれ、次のような抽出手段を選択できます。
・フリーハンドSQL
・シングルテーブル
・CSVファイル
・Yellowfinレポート
・サードパーティコネクタ
T(Transform)…変換、Yellowfinでは「トランスフォーメーションステップ」と呼ばれ、次のような変換手段を選択できます。
・フィルタ
・集計
・計算フィールド
・マージ(結合)
・マージ(ユニオン)
・分割(複製)
・コネクターによるトランスフォーメーション
・内部トランスフォーメーション
L(Load)…格納、Yellowfinでは「アウトプットステップ」と呼ばれ、格納先はデータベースに限定されています。
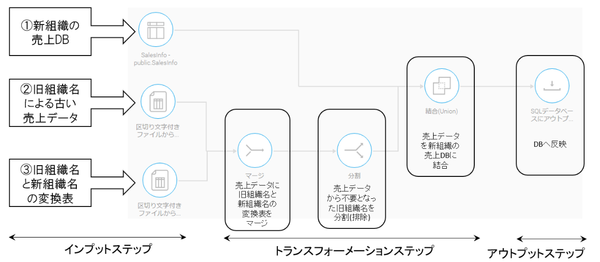
ETL機能で、旧組織の売上データを新組織のデータベースに取り込む方法
簡単な例として、旧組織の売上データを、新しい組織名に置き換えながら、新組織のデータベースに取り込む処理をETLで行う流れをご紹介します。
実際にYellowfin 7.4でETLを使ってみたいという方は、末尾の「Yellowfin 7.4でトランスフォーメーションフローを使うには(注1)」を参考にあらかじめ設定しておいてください。
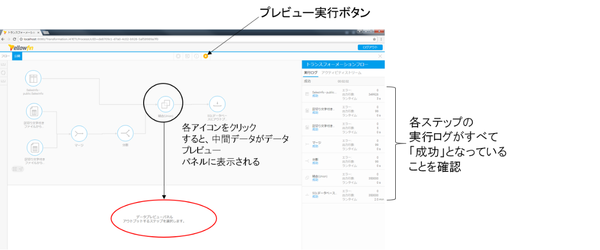
Yellowfin 7.4でのETLは、下図にあるトランスフォーメーションフローの画面から利用します。大まかにみれば、左上のStep1~3のメニューから任意の部品(右端Step1~3参照)を取ってきて、変換ビルダーキャンバス上で組み合わせ、データ処理の流れを定義します。プレビュー実行ボタンを押すと、その流れに沿って処理が進み、変換フローパネルに実行ログが表示され、部品をクリックすると、その時点の処理データを「データプレビューパネル」で参照できます。
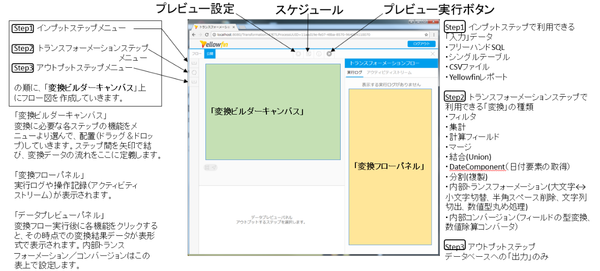
ここでは、新組織で整備されている売上DBに旧組織名の売上データを取り込むケースを想定します。
下記のようなトランスフォーメーションフローで、旧組織名を新組織名に置き換えながら、売上DBに反映させます。
最終的には下図のようなフローとなります。インプットステップから順を追って定義の仕方をご説明していきます。
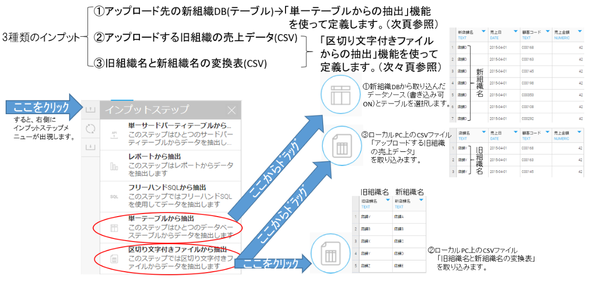
インプットステップの定義を行います
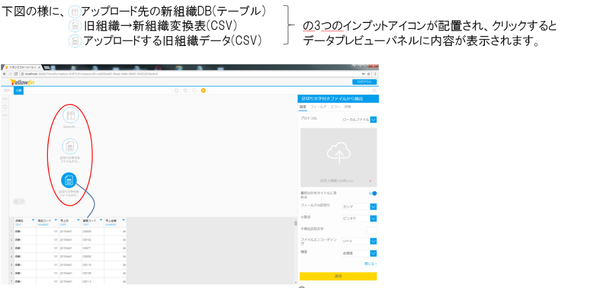
まずインプットステップの定義は、インプットメニューから①~③の部品を変換ビルダーキャンバスまでドラッグ&ドロップして並べ、インプット元を指定します。
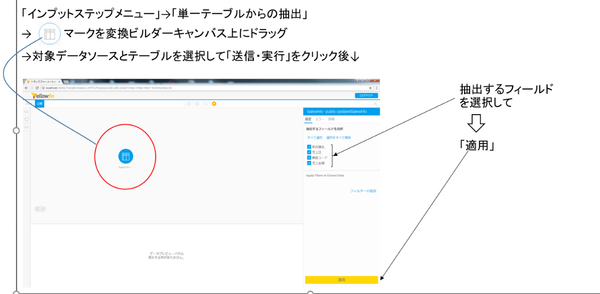
(1)の「単一テーブルからの抽出」定義は、具体的に次のように行います。
(2)と(3)の「区切り文字付きファイルからの抽出」は、具体的に次のように行います。
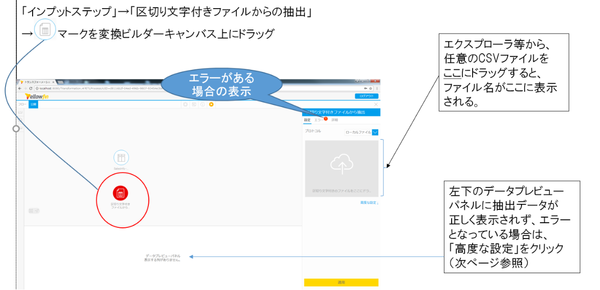
「区切り文字付きファイルからの抽出」の設定として、次の項目をセットしておきます。
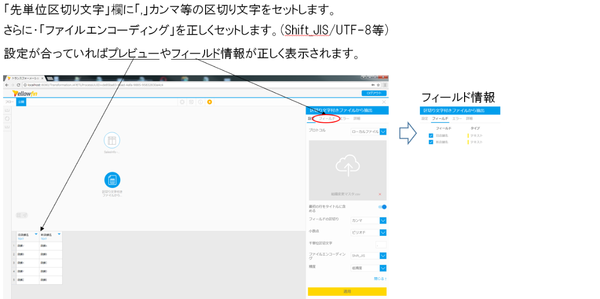
これまでの設定で、インプットステップの定義が完成しました。
トランスフォーメーションステップの「マージ」の定義を行います
次に、トランスフォーメーションステップの「マージ」の定義について見ていきましょう。
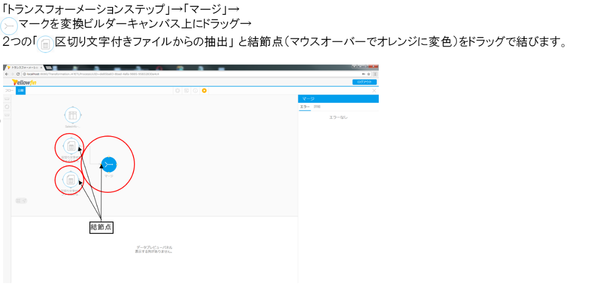
そして、インプットステップからトランスフォーメーションステップへの連結部分のフローを定義します。
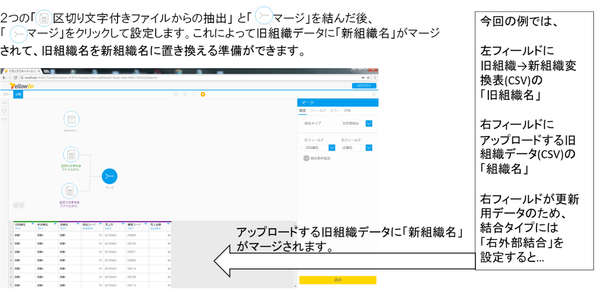
これまでのマージ処理により、旧組織データに新組織名と旧組織名が共存する状態になりましたが、新組織DBにアップロードするにあたっては、旧組織名が必要なくなりますので、分割処理によって切り離します。
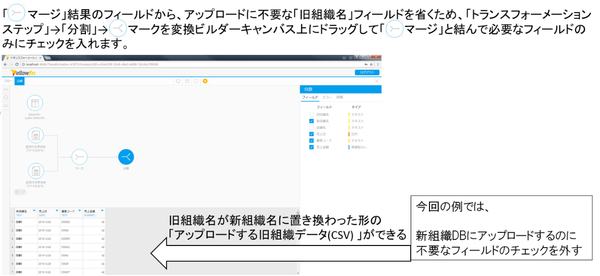
トランスフォーメーションステップの仕上げとして、組織名を旧→新に差し替えた元「旧組織データ」を「新組織DB」に結合します。実際の設定は次のようになります。
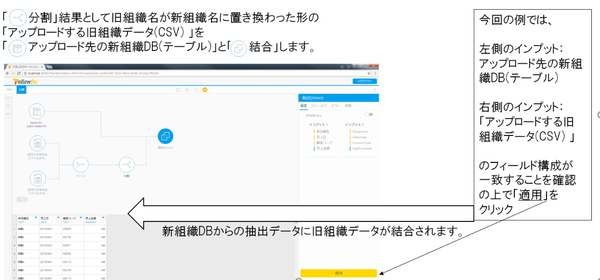 ここまでの、インプットステップ~トランスフォーメーションステップで旧組織データを新組織DBに追加更新する処理がYellowfin内で進みました。
ここまでの、インプットステップ~トランスフォーメーションステップで旧組織データを新組織DBに追加更新する処理がYellowfin内で進みました。
アウトプットステップの定義を行います
最後に、Yellowfin外部のSQLデータベースに処理結果を書き出す「アウトプットステップ」の定義を行います。
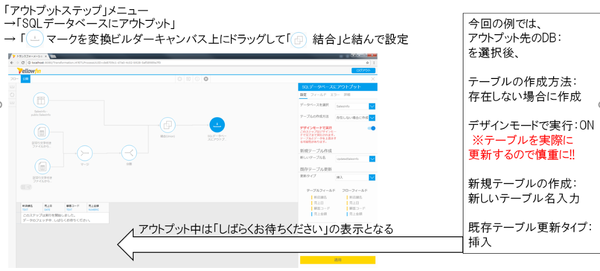
以上で、インプット~トランスフォーメーション~アウトプットの3ステップを結ぶフローができあがりました。
プレビュー実行ボタンを押すと、フローに従って処理が流れ、右側の「変換フローパネル」に実行ログがリアルタイムで表示されます。各アイコンをクリックすると、中間データが下側のデータプレビューパネルに表示されますので、思った通りに処理が進んだか、実行ログと合わせて確認しましょう。
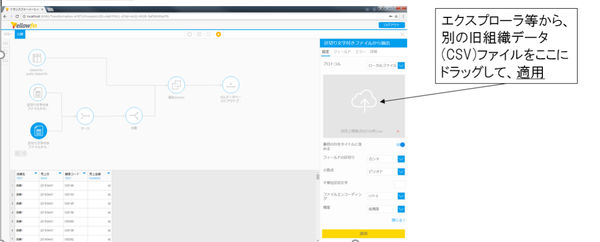
インプットステップの「区切り文字付きファイルからの抽出」では、アップロードしたい旧組織データとして、手元のPC上にある特定のCSVファイルを指定しました。
他にも、同様にアップロードしたい旧組織データファイルがある場合は、「アップロードする旧組織データ(CSV)」のアイコンをクリックし、下記の要領で差し替えて処理することができます。
このように、トランスフォーメーションフローを使うと、DB上の単一テーブルやSQL実行結果、ローカルCSVファイルなど、他のレポートからデータを取り込み、様々な加工を施してDBへ反映する処理のフローを描くことで、視覚的にわかりやすくルーティン化できるのです。
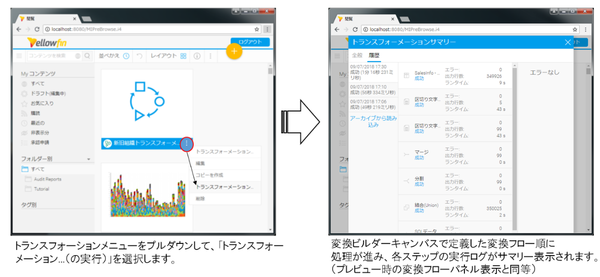
なお、次のような操作で閲覧メニューから、公開済みのトランスフォーションを実行することもできます。
※注1 Yellowfin 7.4でトランスフォーメーションフローを使うには…
Yellowfinというツールは、従来、データ分析のためにデータベースを参照しますが、参照先データベースの改変は行えませんでした。ところが、トランスフォーメーションフローという新機能では参照先データベースの改変も行うことができるようになりました。そのため、使用にあたっては注意を要します。
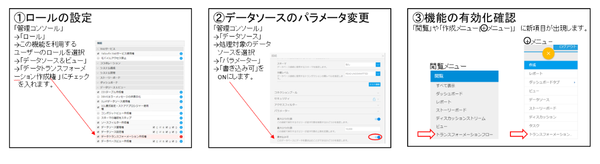
安全上の理由から、Yellowfin 7.4ではインストール直後の状態ではトランスフォーメーション機能を使えない様にしてあり、次の3つの手順で、機能を有効化する必要があります。なお、Yellowfin 7.4の仕様により、クライアント組織(マルチテナント)を利用している場合には、Default組織のみしかトランスフォーメーションフロー機能を利用できません。
▼YellowfinのETL機能についてお問い合わせはこちら
▼BIツールYellowfinのセミナーについてはこちら



NTTテクノクロス株式会社
ビジネスソリューション事業部
![]()