PostgreSQL 11先行紹介 - パーティション機能のさらなる改善
今回は、現在開発中のPostgreSQL 11に入ると予想される新機能のうち、パーティションに関する機能をいくつか紹介したいと思います。




ぬこのたのしいぽすぐれ教室 第9回
- 2018年07月04日公開
はじめに
みなさん、こんにちは。ぬこ@横浜です。
今回は、現在開発中のPostgreSQL 11に入ると予想される新機能のうち、パーティションに関する機能をいくつか紹介したいと思います。

PostgreSQL 11は2018年10月頃にリリースされる予定ですが、ベータ版(beta1)が2018年5月24日に、beta2も2018年6月28日にリリースされました。現時点で誰でもPostgreSQL 11の機能を先行して使うことができます。もちろんベータ版なので、この機能がPostgreSQL 11に本当に入るかは現時点では確約はできませんが、たぶん大きな問題が起きなければ大丈夫ではないかなと思っています。
さてPostgreSQL 10では革命的とも言えるテーブルパーティションの大幅な強化がなされました。PostgreSQL 10のパーティション機能については、以前の記事(PostgreSQL 10の宣言的パーティション)で紹介しています。とはいえ、まだまだPostgreSQL 10の時点では、いろいろ足りない機能がありました。
PostgreSQL 11では、新たなパーティション種別の追加や、PostgreSQL 10のパーティション機能に関するさまざまな改善が行われています。今日は、そのうち、以下のトピックについて紹介しようと思います。
- ハッシュパーティション
- パーティションテーブルに対するパラレルクエリ
- パーティションテーブルに対するインデックス設定
ハッシュパーティション
PostgreSQL 10で追加されたパーティション機能では、リストパーティションとレンジパーティションの2種類のパーティション方式がサポートされていました。
実はハッシュパーティション機能もPostgreSQL 10リリース前から、開発は進められていましたが、残念ながらPostgreSQL 10リリース時点では組み込まれませんでした。それから1年、さらなる開発&議論が進められPostgreSQL 11に組み込まれるようになりました。
ハッシュパーティションは、パーティションキーのハッシュ値をもとに格納先のパーティションテーブルを決める手法です。リストパーティションやレンジパーティションの場合、パーティションキーの振り分け先は、論理的に意味のある値として扱われます。例えば、リストパーティションであれば、都道府県名(値は「神奈川県」や「東京都」など)で振り分けますし、レンジパーティションであれば、期間(1月1日から3月31日)によって振り分けたりします。
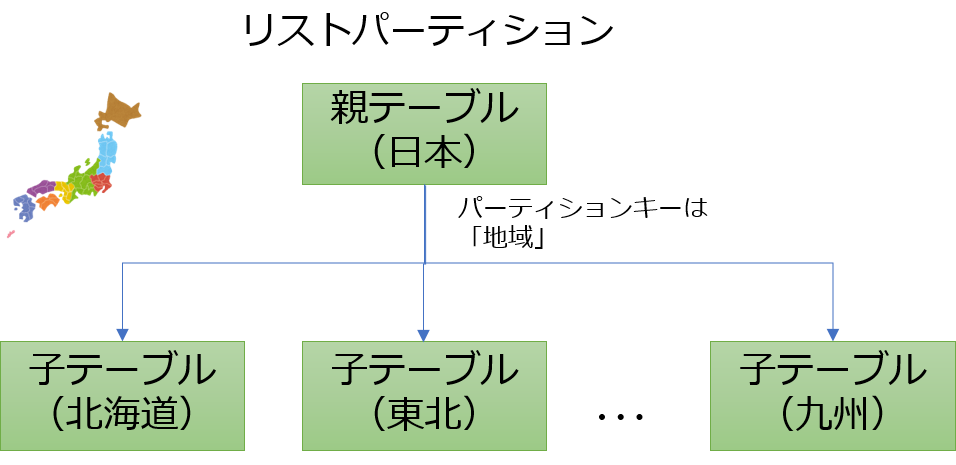
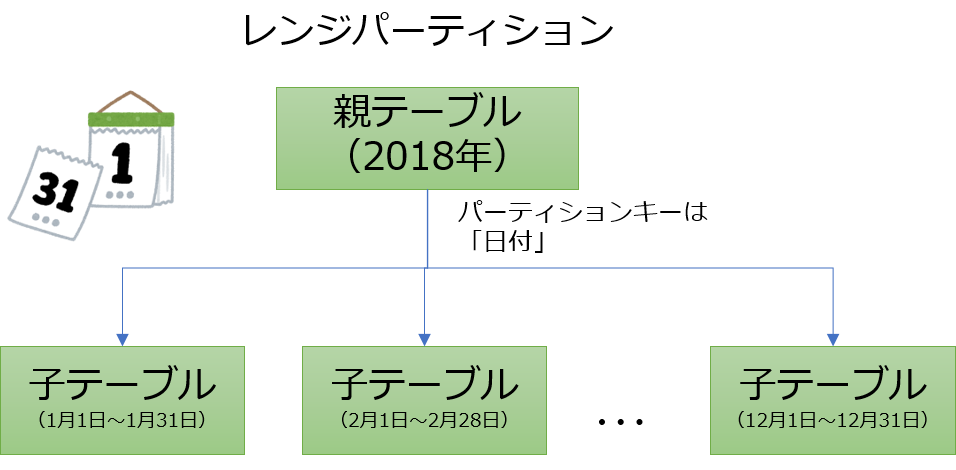
ハッシュパーティションでは、何か意味のある値を用いてパーティションに分割するのではなく、列値をハッシュ関数にかけて得られたハッシュ値に基づいてデータの格納先を振り分けます。このため、リストパーティションやレンジパーティションよりもパーティションテーブル間でのデータ量の偏りを抑制することができます。
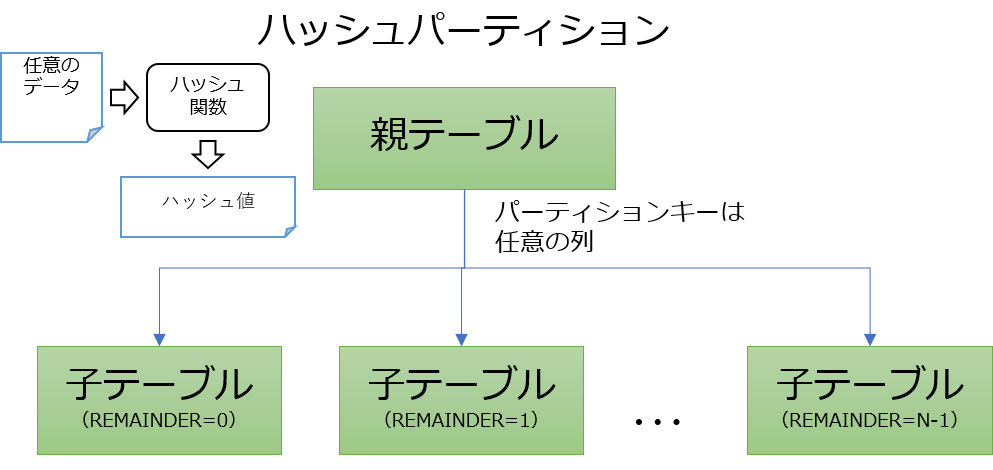
ハッシュパーティションの定義
今回はparentというテーブルをハッシュパーティションを用いて、3つの子テーブルに分割する例を指定します。
まず以下のようにCREATE TABLEコマンドを使って、parentテーブルを定義します。
CREATE TABLE parent (id int, part_key text, dummy text) PARTITION BY HASH (part_key);
後半にあるPARTITION BY HASHという構文がPostgreSQL 11から追加されたものです。ハッシュパーティションのキーとなる列(part_key)を指定します。
次に、ハッシュ値によって振り分けられる子テーブルを定義します。今回は3つの子テーブル(child_0, child_1, child_2)を定義します。まず、child_0 テーブルを定義します。
CREATE TABLE child_0 PARTITION OF parent FOR VALUES WITH (MODULUS 3, REMAINDER 0);
まず、最初にchild_0が、parentのパーティション(子テーブル)である、と書きます。そして、その子テーブルへの振り分け規則をMODULUSとREMAINDERによって指定します。通常、MODULUSには分割したい数を指定します。今回の場合は3つの子テーブルに分割したいのでMODULUSには3を指定します。REMAINDER(余り)にはMODULUSより小さな整数値を指定します。child_0のREMAINDERには0を指定しておきます。
個人的には、ハッシュパーティションの構築時には、REMAINDERに設定する数値を子テーブルの末尾につけると後々、子テーブルの管理をするときにわかりやすくなるんじゃないかと思います。
他の2テーブルについても同様に定義を行います。
CREATE TABLE child_1 PARTITION OF parent FOR VALUES WITH (MODULUS 3, REMAINDER 1);
CREATE TABLE child_2 PARTITION OF parent FOR VALUES WITH (MODULUS 3, REMAINDER 2);
これでハッシュパーティションの定義は終わりです!
psqlを使っているなら、psqlのメタコマンド \d+ を使って、パーティションテーブルの定義内容を確認できます。
hash=# \d+ parent
Table "public.parent"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
----------+---------+-----------+----------+---------+----------+--------------+-------------
id | integer | | | | plain | |
part_key | integer | | | | plain | |
dummy | text | | | | extended | |
Partition key: HASH (part_key)
Partitions: child_0 FOR VALUES WITH (modulus 3, remainder 0),
child_1 FOR VALUES WITH (modulus 3, remainder 1),
child_2 FOR VALUES WITH (modulus 3, remainder 2)
このパーティションテーブルに以下のように10万件のデータを投入してみます。
INSERT INTO parent VALUES (generate_series(1, 100000), md5(CLOCK_TIMESTAMP()::text), 'dummy');
- id列には1~100000のユニークな値を設定
- part_keyには32文字のランダムな文字列。これがパーティションキーになる。
- dummyには'dummy'という固定値
ハッシュパーティションへの検索
データ投入が終わったら、検索してみます。まずはparentテーブルの件数から見てみましょう。
hash=# SELECT COUNT(*) FROM parent ;
count
--------
100000
(1 row)
きちんと登録した件数が表示されます。
次に、同様にCOUNT(*)を使ってchild_0~child_2の各子テーブルの件数を見てみると、以下のようになります。多少の誤差はありますが、おおまかに1/3くらいの件数に分割されていることがわかると思います。
| parant | child_0 | child_1 | child_2 |
|---|---|---|---|
| 100000件 | 33292件 | 33435件 | 33273件 |
検索時の実行計画
次に、実行計画を見てみましょう。
検索条件を設定せずに検索した場合は、各子テーブルを検索した結果をマージする、という実行計画になります。
hash=# EXPLAIN SELECT COUNT(*) FROM parent;
QUERY PLAN
-------------------------------------------------------------------------
Aggregate (cost=2819.70..2819.71 rows=1 width=8)
-> Append (cost=0.00..2550.60 rows=107640 width=0)
-> Seq Scan on child_0 (cost=0.00..666.50 rows=35650 width=0)
-> Seq Scan on child_1 (cost=0.00..670.80 rows=35880 width=0)
-> Seq Scan on child_2 (cost=0.00..675.10 rows=36110 width=0)
(5 rows)
次に、パーティションキー(part_key)に条件を指定したときの実行計画を見てみます。
子テーブル(child_1)を直接参照してみます。
hash=# TABLE child_1 LIMIT 3;
id | part_key | dummy
----+----------------------------------+-------
1 | d48feac255c0e89f5b94cb94dac42748 | dummy
2 | cff8506bad80e401bb28b956029c5289 | dummy
4 | cb8f1c84f16446e1597cf4c89bca589e | dummy
(3 rows)
id=1のpart_keyの値(d48feac255c0e89f5b94cb94dac42748)を条件値に設定してみます。
hash=# EXPLAIN SELECT COUNT(*) FROM parent WHERE part_key = 'd48feac255c0e89f5b94cb94dac42748';
QUERY PLAN
-----------------------------------------------------------------------------
Aggregate (cost=729.02..729.03 rows=1 width=8)
-> Append (cost=0.00..729.02 rows=1 width=0)
-> Seq Scan on child_1 (cost=0.00..729.01 rows=1 width=0)
Filter: (part_key = 'd48feac255c0e89f5b94cb94dac42748'::text)
(4 rows)
この場合は、part_keyが d48feac255c0e89f5b94cb94dac42748 のときに振り分けられる、子テーブル(child_1)のみを検索するような実行計画になります。child_0やchild_2は実行計画生成時点で検索対象外から外れることになります。これをパーティション・プルーニングと呼びます。これにより、検索実行時にデータが存在しない子テーブルへの無駄な検索をせずに、効率的に検索できます。
ただ、これはあくまでも = 演算子を使ったときのみです。ハッシュパーティションにおいて、パーティション・プルーニングが有効になるのは、 = 比較のときのみということに注意してください。
パーティションテーブルに対するパラレルクエリ
PostgreSQL 11では、複数のパーティションテーブルを検索する場合、かつパラレルクエリが適用可能なケースでは、並列にパーティションテーブルを検索できるようになりました。
さっき使ったパーティションテーブルに登録するデータ数を100万件に増やしてみます。
TRUNCATE parent;
INSERT INTO parent VALUES (generate_series(1, 1000000), (random() * 100)::int, 'dummy');
まず、この状態でパラレルクエリが動作しないようにSETコマンドで設定し、
SET max_parallel_workers_per_gather = 0;
さっき使った件数をカウントするクエリの実行計画を確認してみます。
hash=# EXPLAIN SELECT COUNT(*) FROM parent ;
QUERY PLAN
---------------------------------------------------------------------------
Aggregate (cost=22907.00..22907.01 rows=1 width=8)
-> Append (cost=0.00..20407.00 rows=1000000 width=0)
-> Seq Scan on child_0 (cost=0.00..4621.81 rows=299981 width=0)
-> Seq Scan on child_1 (cost=0.00..4923.25 rows=319525 width=0)
-> Seq Scan on child_2 (cost=0.00..5861.94 rows=380494 width=0)
(5 rows)
この実行計画では、child_0~child_2までのテーブルをSeq Scanで順次実行し、それが終わったらその結果をマージして集約結果を返却しています。PostgreSQL 10でのパーティションテーブルへの検索はこのような実行計画になっています。
次に、パラレルクエリが動作するようにSETコマンドで設定し、
SET max_parallel_workers_per_gather = 4;
同じクエリの実行計画を確認してみます。
hash=# EXPLAIN SELECT COUNT(*) FROM parent ;
QUERY PLAN
------------------------------------------------------------------------------------------------
Finalize Aggregate (cost=15414.56..15414.57 rows=1 width=8)
-> Gather (cost=15414.35..15414.56 rows=2 width=8)
Workers Planned: 2
-> Partial Aggregate (cost=14414.35..14414.36 rows=1 width=8)
-> Parallel Append (cost=0.00..13372.68 rows=416666 width=0)
-> Parallel Seq Scan on child_2 (cost=0.00..4295.20 rows=223820 width=0)
-> Parallel Seq Scan on child_1 (cost=0.00..3607.56 rows=187956 width=0)
-> Parallel Seq Scan on child_0 (cost=0.00..3386.59 rows=176459 width=0)
(8 rows)
今度は、Parallel Seq ScanとParallel Appendという実行計画が生成されています。これは子テーブルの単位でパラレルに動作することを示します。
利用可能なCPU数が多い環境、かつパーティションテーブルへの検索時には、このパラレルクエリの恩恵が受けられそうです。楽しみですね。
パーティションテーブルに対するインデックス設定
PostgreSQL 10のパーティション機能が入ったときに、パーティションの親テーブルに対するインデックスを設定しようとすると、エラーになってしまいました。このため、子供のパーティションテーブル群に対して、一つ一つ、インデックス作成コマンドを発行する必要があったので、子供のパーティション数が多い場合ちょっと面倒でした。
PostgreSQL 11では、親テーブルに対してインデックスを作成すると、子供のパーティションテーブル群すべてに対して、インデックス作成処理が伝播します。
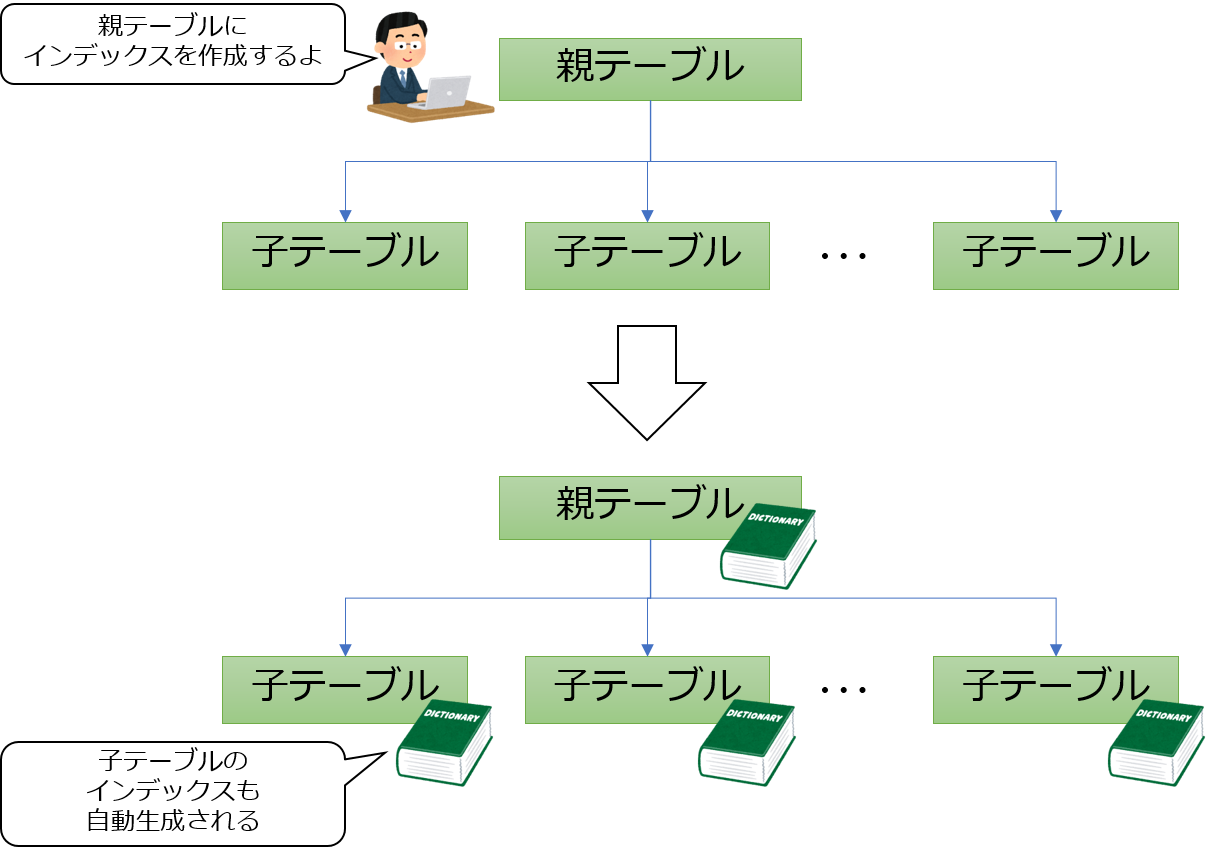
パーティション数が多い環境でインデックスを作成するときにはありがたい機能ですね!
インデックス設定の実行例
たとえば、親テーブル(parent)/子テーブル(child_0)にもインデックスが存在しない状態があるとします。
hash=# \d+ parent
Table "public.parent"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
----------+---------+-----------+----------+---------+----------+--------------+-------------
id | integer | | | | plain | |
part_key | integer | | | | plain | |
dummy | text | | | | extended | |
Partition key: HASH (part_key)
Partitions: child_0 FOR VALUES WITH (modulus 3, remainder 0),
child_1 FOR VALUES WITH (modulus 3, remainder 1),
child_2 FOR VALUES WITH (modulus 3, remainder 2)
hash=# \d+ child_0
Table "public.child_0"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
----------+---------+-----------+----------+---------+----------+--------------+-------------
id | integer | | | | plain | |
part_key | integer | | | | plain | |
dummy | text | | | | extended | |
Partition of: parent FOR VALUES WITH (modulus 3, remainder 0)
Partition constraint: satisfies_hash_partition('16591'::oid, 3, 0, part_key)
この状態で、親テーブル(parent)のid列に対してインデックスを作成します。
CREATE INDEX parent_id_idx ON parent USING btree (id);
当然、親テーブルにはインデックスが作成されます。
hash=# \d+ parent
Table "public.parent"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
----------+---------+-----------+----------+---------+----------+--------------+-------------
id | integer | | | | plain | |
part_key | integer | | | | plain | |
dummy | text | | | | extended | |
Partition key: HASH (part_key)
Indexes:
"parent_id_idx" btree (id)
Partitions: child_0 FOR VALUES WITH (modulus 3, remainder 0),
child_1 FOR VALUES WITH (modulus 3, remainder 1),
child_2 FOR VALUES WITH (modulus 3, remainder 2)
そして、子テーブル(child_0)にも自動的にインデックスが作成されています!
hash=# \d+ child_0
Table "public.child_0"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
----------+---------+-----------+----------+---------+----------+--------------+-------------
id | integer | | | | plain | |
part_key | integer | | | | plain | |
dummy | text | | | | extended | |
Partition of: parent FOR VALUES WITH (modulus 3, remainder 0)
Partition constraint: satisfies_hash_partition('16591'::oid, 3, 0, part_key)
Indexes:
"child_0_id_idx" btree (id)
子テーブルに自動的に付与されるインデックスの名称は「子テーブル名_インデックス列名_idx」という名前になるようですね。
なお、親テーブル(parent)には、データの実体は格納されないので、インデックスは作成されますが、インデックスサイズが0になります。データの実体が格納される子テーブル側のインデックスのみ実体を持ちます。
hash=# SELECT pg_indexes_size('parent');
pg_indexes_size
-----------------
0
(1 row)
hash=# SELECT pg_indexes_size('child_0');
pg_indexes_size
-----------------
6758400
(1 row)
おわりに
今回は、PostgreSQL 11の目玉機能の一つになりそうな、ハッシュパーティションをはじめとする、パーティション機能の改善について紹介しました。もちろんPostgreSQL 11で追加される機能はこれだけではありません。最初に紹介したように、PostgreSQL 11のベータ版もリリースされているので、自分でダウンロード/インストールして気になる機能を試してみるのも面白いと思います。

PostgreSQLのことならNTTテクノクロスにおまかせください!



PostgreSQLに関わる仕事をしつつ、社内のPostgreSQLの問い合わせにカジュアルに対応。 「ぬこ@横浜」の名前で国内のデータベース関連のイベントでも喋っています。PostgreSQLの変な使い方を考えるのが趣味。 著書に『内部構造から学ぶPostgreSQL 設計・運用計画の鉄則』(技術評論社/共著)。 最近の自己紹介は「『PostgreSQL ラーメン』でググってください」
![]()