PG-Stromでデータ分析が爆速に!?
今回のブログは、今までと趣を変えてPostgreSQLをベースとしたPG-Stromをご紹介いたします。




ぬこのたのしいぽすぐれ教室 第7回
- 2018年05月29日公開
今回のブログは、今までと趣を変えてPostgreSQLをベースとした製品をご紹介いたします。

What's PG-Strom?
PG-Stromは、HeteroDB社が開発した「PostgreSQLから効率よくGPUを利用できるようにしたモジュール」を含むアプライアンス製品です。
オフィシャルサイト:http://heterodb.com/index.html
より正確な説明がPG-Stromのマニュアル( http://heterodb.github.io/pg-strom/ja/ )にあります。
PG-StromはPostgreSQL v9.6および以降のバージョン向けに設計された拡張モジュールで、チップあたり数千個のコアを持つGPU(Graphic Processor Unit)デバイスを利用する事で、大規模なデータセットに対する集計・解析処理やバッチ処理向けのSQLワークロードを高速化するために設計されています。
PG-Stromの中核となる機能は、SQL命令から自動的にGPUプログラムを生成するコードジェネレータと、SQLワークロードをGPU上で非同期かつ並列に実行する実行エンジンです。現バージョンではSCAN(WHERE句の評価)、JOINおよびGROUP BYのワークロードに対応しており、GPU処理にアドバンテージがある場合にはPostgreSQL標準の実装を置き換える事で、ユーザやアプリケーションからは透過的に動作します。
また、PG-StromはいくつかのDWH専用システムとは異なり、行形式でデータを保存するPostgreSQLとストレージシステムを共有しています。これは必ずしも集計・解析系ワークロードに最適ではありませんが、一方で、トランザクション系データベースからデータを移動することなく集計処理を実行できるというアドバンテージでもあります。
PG-Strom v2.0ではストレージ読出し能力が強化されました。SSD-to-GPUダイレクトSQL実行や、インメモリ列指向キャッシュはストレージの遅さを補い、クエリを処理するGPUへ高速にデータを供給する事を可能にします。
一方、高度な統計解析や機械学習といった極めて計算集約度の高い問題に対しても、PL/CUDAやgstore_fdwといった機能を使用する事で、データベース管理システム上で計算処理を行い、結果だけをユーザへ返すといった使い方をする事が可能です。
PG-Stromのアーキテクチャ
PG-Stromのアーキテクチャは下図のようになってます。
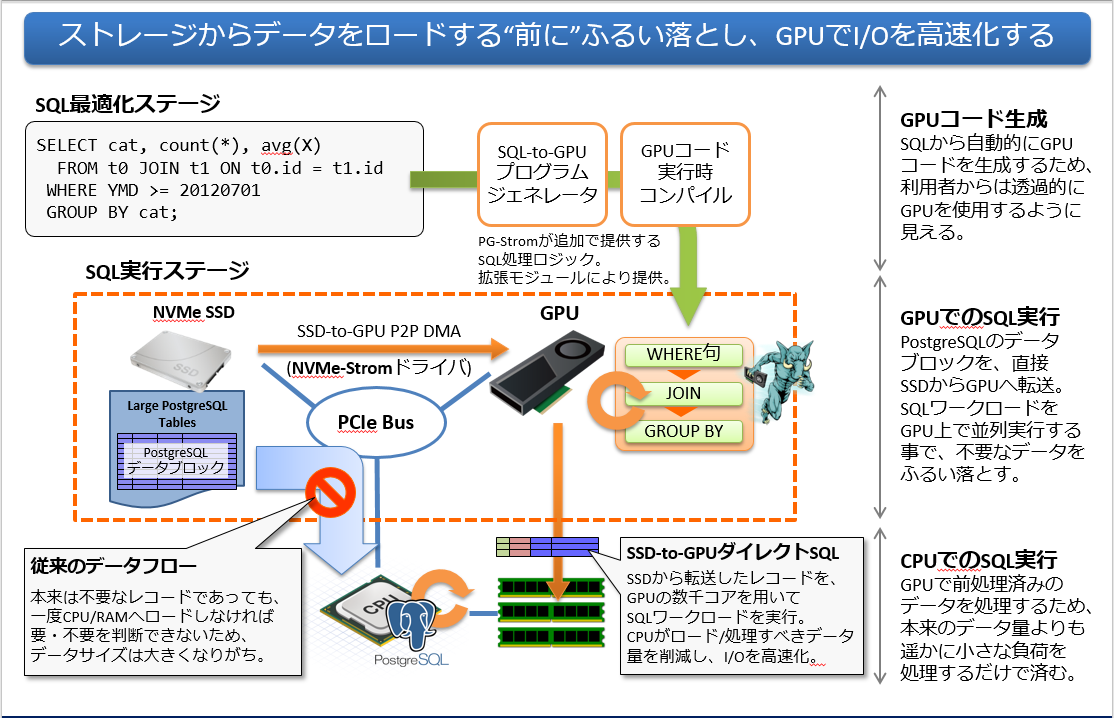
今回は、HeteroDB社にご協力いただき、PG-Stromの実力(上図の「SSD-to-GPUダイレクトSQLによる」の効果)を見てみました。
PostgreSQL vs PG-Strom
HeteroDB社から下記スペックのマシンを用意いただき、PG-Stromなし(素のPostgreSQL)、PG-Stromありでの性能差を比較しました。
| Type | パーツ名 | 個数 | トータル |
|---|---|---|---|
| Barebone | SYS-1019GP-TT | 1 | 1U Rack Server |
| CPU | Intel Xeon Gold 6126T | 1 | 12C, 24HT, 2.6GHz |
| RAM | DDR4-2666 32GB DIMM | 6 | 192GB in total |
| GPU | NVIDIA Tesla P40 | 1 | 3840C, 24GB, Pascal |
| SSD | Intel DC P4600 | 3 | 2.0TB, HHHL |
| HDD | SATA 2.0TB (2.5inch; 7.2krpm) | 6 | |
| Network | Built-in 10Gb ethernet | 2 |
測定シナリオ
以下のように大量の売り上げ情報が集まるテーブルと中規模程度のメニュー項目や店舗情報があるテーブルをスタースキーマで構築し、メニューごとや店舗ごとの情報を一覧取得するようなユースケースを想定し、測定シナリオとしました。
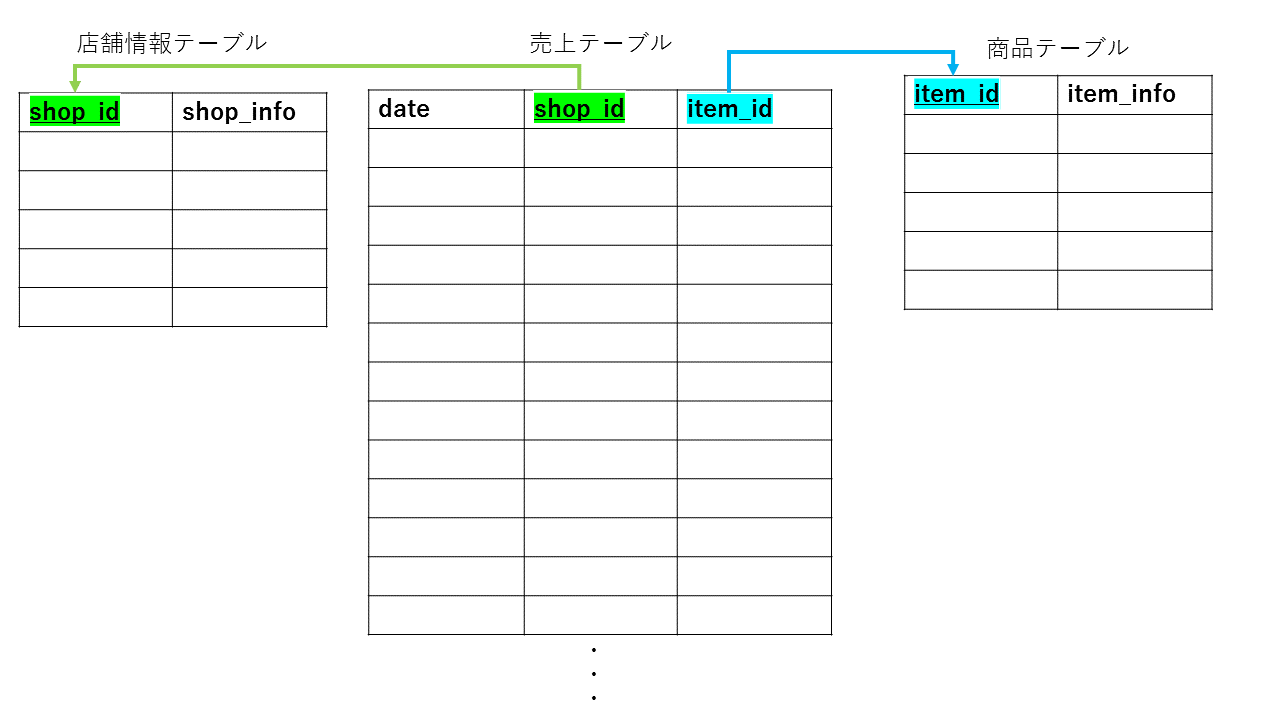
下記2つのテーブルを用いました。
| テーブル名 | 用途 | サイズ |
|---|---|---|
| datetime_nums | 店舗ごとに日々の売り上げ情報を格納 | 312GB |
| menu | メニュー情報の管理 | 544kB |
測定したクエリは以下のように、店舗ごとに各メニューの価格を集計して売れ筋を一覧表示します。
SELECT shop_no, cost, count(cost), sum(cost)
FROM datetime_nums dt RIGHT JOIN menu ON dt.menu_code = menu.menu_code
GROUP BY shop_no, cost
ORDER BY shop_no, cost;
PostgreSQLの結果
まずはPG-Stromなし(素のPostgreSQL)の実行計画を見てみましょう。
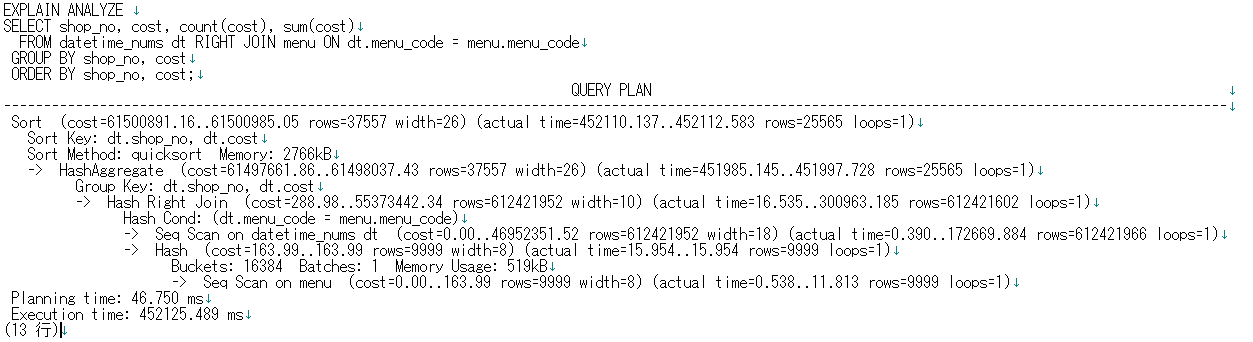
従順に、各テーブルをシーケンシャルスキャンし、Hash結合する実行計画が選ばれてます。 処理にはおよそ7分30秒かかりました。 なお、パラレルスキャンになっていないのは、RIGHT JOIN結合のためです。
PG-Stromの結果
次にPG-Stromありの実行計画を見てみましょう。
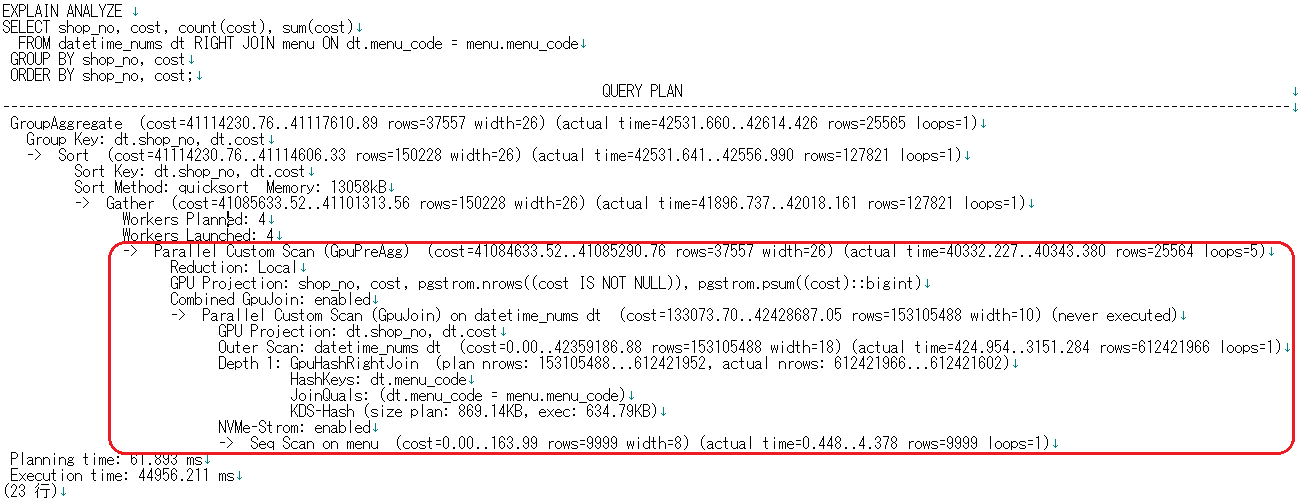
処理時間はおよそ45秒で、素のPostgreSQLの約1/10で完了しました! 実行計画で着目すべきところは、「GpuPreAgg」や「GpuJoin」といったカスタムプランが選択されているところです。これらは、PostgreSQL9.5から導入された「カスタムスキャンプロバイダ」で生成されたカスタムプランです。 https://www.postgresql.jp/document/10/html/custom-scan.html
PG-Stromは、可能な限りカスタムプランの恩恵を存分に享受するよう動作します。たとえば上記の例でも、結合処理までをGPU側で処理し、データ転送のオーバヘッドを軽減するなどの工夫がなされています。 また、素のPostgreSQLでは不可能であった、パラレルスキャンもワーカ数4で動作しています。
結果比較と考察
性能差を比較すると以下のようになりました。 素のPostgreSQLでもパラレルクエリが動作するように、Right JoinをLeft Joinにしたときの比較も行っています(今回のデータセットでは、取得件数は同じです)。
| JOIN種別 | PG-Strom | 実行時間(ミリ秒) | スループット MB/s |
|---|---|---|---|
| Right JOIN | なし | 452,125.489 | 690 |
| Right JOIN | あり | 44,956.211 | 6948 |
| Left JOIN | なし | 192,001.529 | 1625 |
| Left JOIN | あり | 45,094.610 | 6857 |
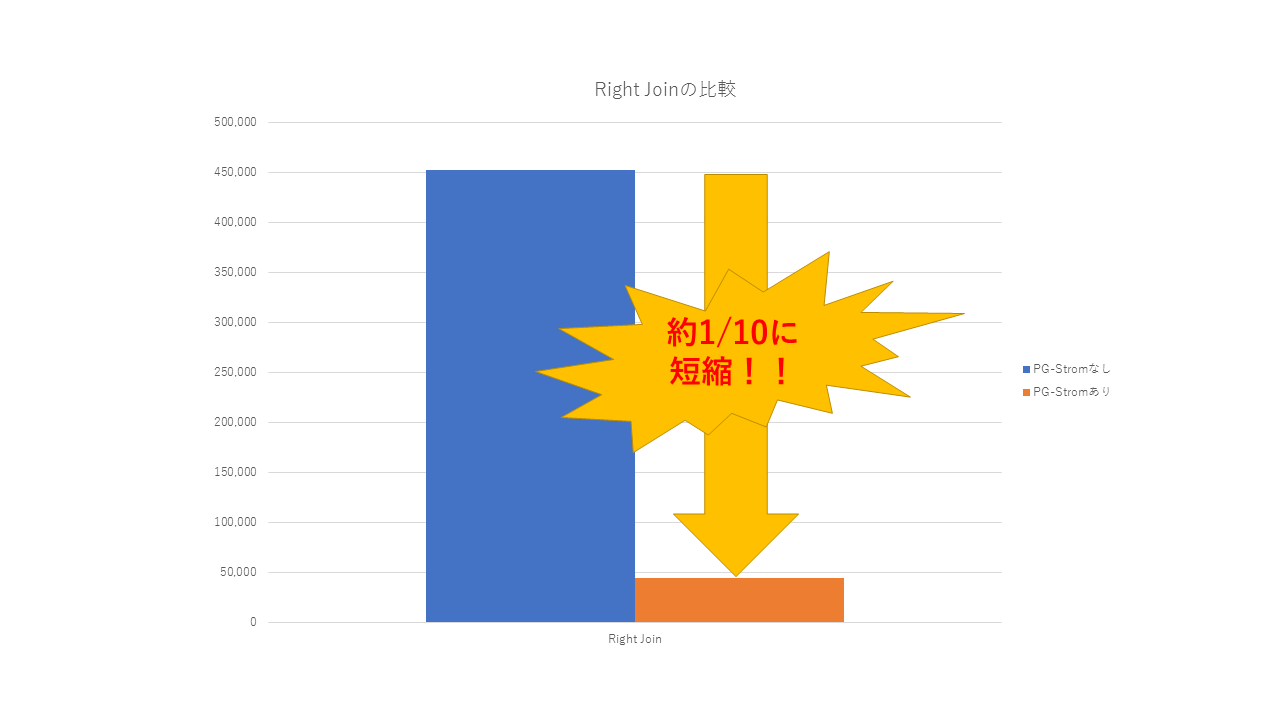
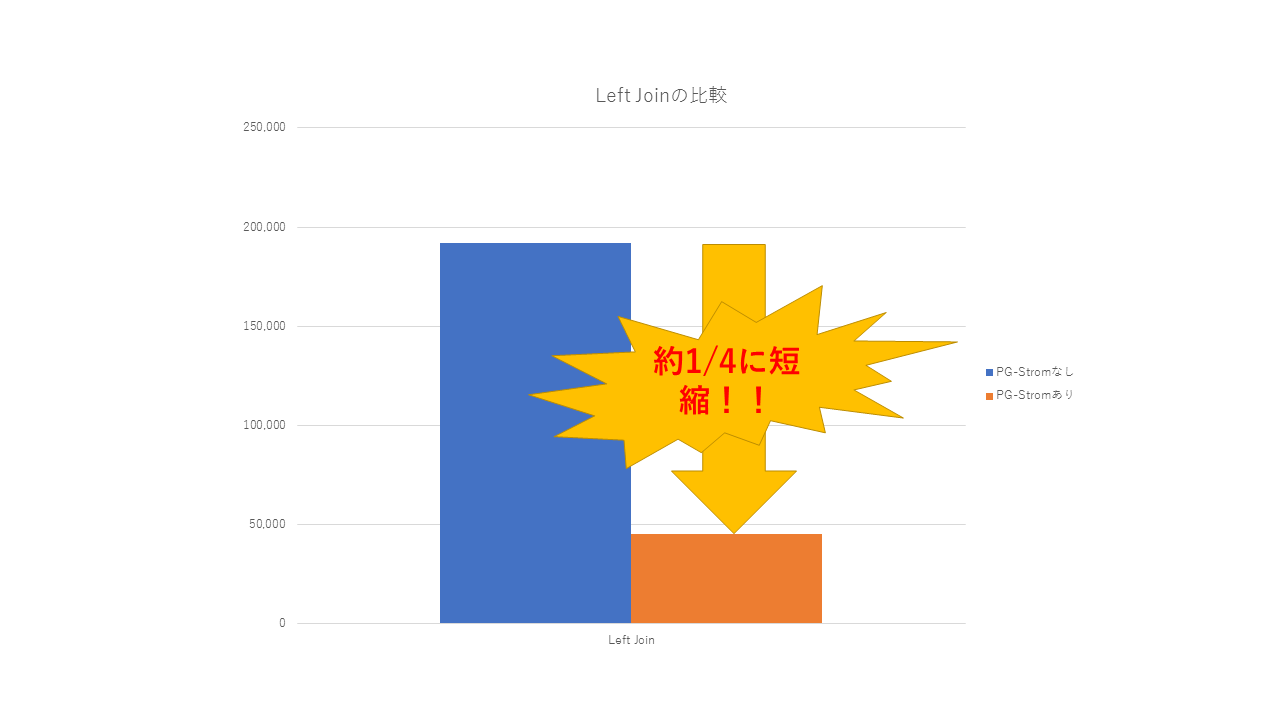
本測定においては、いずれのケースでも素のPostgreSQLよりも高速に処理できることが確認できました。
おまけ
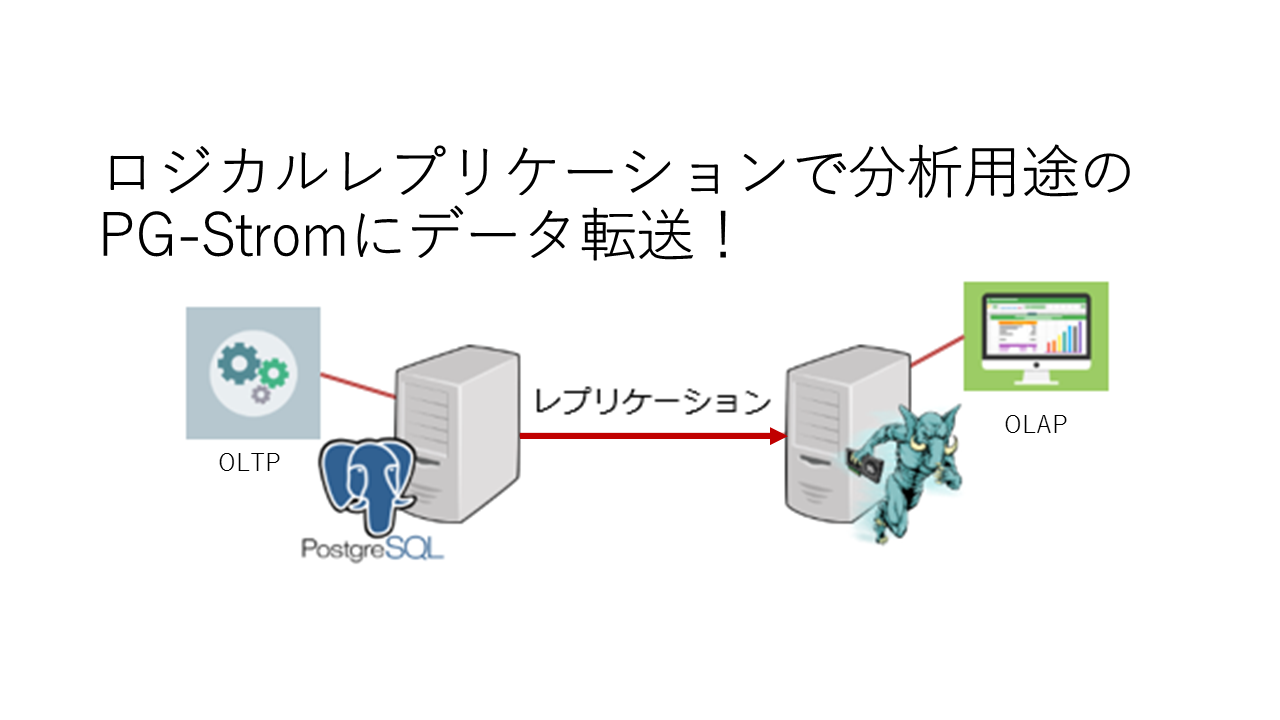
なお、PG-StromはPostgreSQL 10にも対応しています。 つまり、ロジカルレプリケーションにより分析処理をPostgreSQLからPG-Stromにオフロードできる可能性を秘めています!
今回は、シンプルに以下の構成での動作確認も行い、想定どおりにPG-Stromが機能することも確認できました。
おわりに
いかがでしたでしょうか?
GPUを用いたパワフルPostgreSQLの一端を垣間見れたのではないでしょうか?
いきなりPG-Stromを導入するには敷居が高いという場合でも、PostgreSQL 10のロジカルレプリケーションと組み合わせることができる点は大きいと思います。ご興味のあるかたはご相談にのりますので、お気軽にお声掛けください!
PostgreSQLのことならNTTテクノクロスにおまかせください!



10数年に渡り、PostgreSQLの機能拡張や運用サポートを行うとともに、 「PGCon/PGCon.jp」などのコミュニティ活動、セミナー講演、書籍執筆など幅広い普及活動を行っている。 著書に「内部構造から学ぶPostgreSQL 設計・運用計画の鉄則(技術評論社)」がある。 やっぱりネコが好き。
![]()