猫でもできるPostgreSQLのデータ型開発
実はPostgreSQLは最初から、拡張機能を組み込むことを前提とした設計になっています。拡張機能として組み込めるものには、いろいろなタイプのものがあります。以下に、PostgreSQLに組み込める拡張機能の代表的なものを示します




ぬこのたのしいぽすぐれ教室 第6回
- 2018年03月20日公開
はじめに
みなさん、こんにちは。ぬこ@横浜です。
さて、今回は、これまでの記事とちょっと趣を変えて、PostgreSQLの特徴の一つである拡張機能の組み込みについて紹介したいと思います。

PostgreSQLの拡張機能組み込み
PostgreSQLが誕生してからはや20年。何気に長い歴史をもつDBMSなんですが、実はPostgreSQLは最初から、拡張機能を組み込むことを前提とした設計になっています。拡張機能として組み込めるものには、いろいろなタイプのものがあります。以下に、PostgreSQLに組み込める拡張機能の代表的なものを示します。
| 拡張の種類 | こんなことができる | 難易度 |
|---|---|---|
| SQL関数 | SQL内で使える関数を組み込める。 | 低 |
| 集約関数 | SUM()、AVG()のような集約演算用の関数を組み込める | 低 |
| 型 | 型と、その型に対する演算を組み込める。 | 低 |
| 演算子 | +, -, = などの四則演算・比較演算子を組み込める。型と組み合わせて使う。 | 低 |
| 独自インデックス | 画像データ類似検索用のインデックスなどを組み込める。 | 高 |
| 外部データラッパ | PostgreSQL以外のデータをテーブルのように見せるデータラッパを組み込める。 | 中~高 |
| 言語ハンドラ | pl/pgsqlやpl/pythonなどのようにスクリプト内にSQLを書けるようにする。 | 高 |
| バックグラウンドワーカ | PostgreSQLの起動/停止に合わせて裏方として動くプロセスを組み込める。 | 中 |
| HOOK | PostgreSQLの動作に介入して、独自の動作を組み込める。 | 中~高 |
※ 難易度は個人の感想です。
今回は、これらの拡張機能のうち、比較的簡単に実装できる型(ユーザ定義型)を組み込む例を紹介したいと思います。

ユーザ定義型
実はPostgreSQLは他のRDBMSと比べて、組み込みのデータ型が豊富です(PostgreSQL 10文書 データ型 を参照してみてください)。データ型の中には「これ、どんな時に使うんだ?」みたいなデータ型もあるのですが・・・。
それに加えて、PostgreSQLでは自分でデータ型を作成して組み込むこともできます。「そこになければないですね」ではなく、「そこになければつくればいいですね」という事です。
メリットって何だろう?
「わざわざユーザ定義型を作るメリットって何?」という疑問もあると思いますが、自分では以下のようなメリットがあると思っています。
型に固有の操作を、アプリケーション側ではなくデータベース側に任せられる点が大きいです。特に、比較演算をデータベース側で行うことにより、データベースからアプリケーションへのデータ転送量の減少も期待できます。さらに、データベース側で持っているインデックス検索機能を簡単に組み込めるのも重要なポイントだと思っています。
あとは作っていて楽しいというのはありますね。(これは個人の感想です)
気をつけないといけないこともある
とはいえ、データ型をはじめとする拡張機能を開発するときに、いくつか気をつけておくこともあります。
最近、AWS RDS等のデータベースサービスを使うことも多いと思いますが、そうしたデータベースサービスでは、あらかじめ組み込まれている拡張機能しか使えないこともあります。データベースサービスを使うことを前提にしている場合には、今回のブログで紹介するような自分で型を作っても使えないことがあります。
ユーザ定義型には後で書くように、自分で好きな演算子を組み込むことができます。しかし、標準SQLにない演算子を組み込んだ場合、クエリを自動生成する開発フレームワークではそのまま使えないなどの弊害もあるかもしれません。
また、ユーザ定義型に限らず、拡張機能をPostgreSQLに組み込んだ場合、拡張機能の中で例外が発生するとPostgreSQLサーバプロセスがクラッシュ→再起動してしまいます。自作の拡張機能を商用システムで使う場合には、十分な試験を行うようにしてください。
ユーザ定義型を作ってみよう!(基本編)
ここからは実際にユーザ定義型の作り方を書いていきます。
私も何種類かユーザ定義型を作ったことがありますが、最初はとっつきにくいですが、慣れてくると割と簡単に作成できるようになってきます。
ユーザ定義型を作成するために必要なスキルは、それほど高いものではありません。
- C言語でコーディング/デバッグができること。特にSQL関数をC言語で実装する場合には、PostgreSQL固有の作法がいろいろあります。PostgreSQL文書のC言語関数が参考になります。また、PostgreSQLのソースコードセットには、こうした拡張機能を作るときに参考になるサンプルも入っています。
- PostgreSQL文書を読めること。特に、SQLの拡張の章はユーザ定義型を作るときには目を通したほうがいいでしょう。
- データベースの一般的な知識。データベースのデータ型では、こんなことが可能であるべき、という勘所があると実装しやすいと思います。
ユーザ定義型のサンプル
今回の記事では、自分がちょっと前に開発してGithubに公開した pg_fraction というユーザ定義型をサンプルにユーザ定義型の作成順序は作成時の注意点について書いていきます。
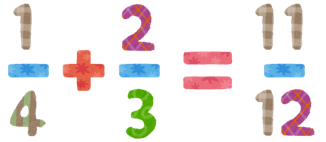
pg_fractionではfraction型というデータ型を提供します。このfraction型は、分子/分母という形式で表現された文字を分数として格納し、分数の四則演算や比較演算を可能にします。例えば、こんな分数の足し算を実行可能にします。
pg_fraction=# SELECT data, data + '1/3'as result FROM test;
data | result
------+--------
1/2 | 5/6
3/17 | 26/51
2/3 | 1/1
(3 rows)
こういう変なデータ型は、MySQLにも商用DBMSにも対応する型はないはずです、たぶん(笑)興味があったら、git cloneでソースを入手して動かしてみてください。
ユーザ定義型を開発する順番
ユーザ定義型を開発するにはいくつかの段階というものがあります。私がユーザ定義型を開発するときには、だいたいこんな順番で段階的に作っていくことが多いです。

型への入出力
一番最初のステップは、自分が作成したいデータ型に、どういう書式(外部表現)で書いたら、どういう形式(内部形式)で格納されるのかを決めることです。同様に、内部形式のデータを検索したときに、クエリの結果として、どういう書式で出力されるのかを決める必要もあります。
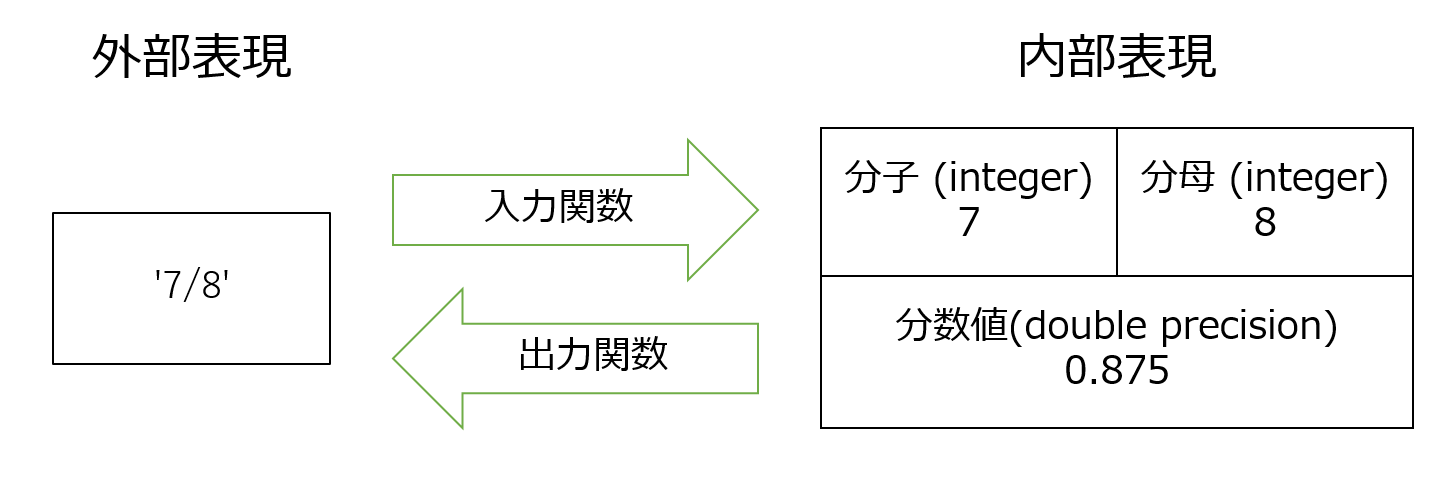
fraction型では、分子/分母という外部表現を入力値として受け付けて、内部的にはinteger型の分子の値、integer型の分母の値、分子の値を分母の値で除算したdouble precision型の分数値を格納します。また、内部表現として格納された分子と分母の数値から、分子/分母という形式の外部表現を生成します。
この入力関数と出力関数をC言語で作成します。サンプルのpg_fractionでは、pg_fraction.c内の、fraction_in(), fraction_out()という関数でこれを実装しています。
さて、C言語の関数を作成しただけでは、この関数をPostgreSQL内で使ってはくれません。作成した関数を、PostgreSQLから使えるようにするために、CREATE TYPEや、CREATE FUNCTIONというPostgreSQLのDDLを発行して、SQL関数として登録する必要があります。
CREATE TYPE fraction;
CREATE FUNCTION fraction_in(cstring)
RETURNS fraction
AS 'MODULE_PATHNAME'
LANGUAGE C STRICT IMMUTABLE;
CREATE FUNCTION fraction_out(fraction)
RETURNS cstring
AS 'MODULE_PATHNAME'
LANGUAGE C STRICT IMMUTABLE;
型に対する入出力の関数が使えるようになったので、fraction型を定義するために、再びCREATE FUNCTIONを実行します。INPUTとOUTPUTには、先ほど登録したSQL関数のfraction_inとfraction_outを登録します。
CREATE TYPE fraction (
INTERNALLENGTH = 16,
INPUT = fraction_in,
OUTPUT = fraction_out,
STORAGE = plain
);
これで、やっとfraction型への入出力ができるようになりました。ここまで実装すると、
- CREATE TABLEのときにfraction型の列を定義できる。
- INSERT文でfraction型のデータを格納できる。
- SELECT文でfraction型のデータを参照できる。
といったことができます。実際に、PostgreSQL上で動かしたときの例を以下に示します。
pg_fraction=# CREATE TABLE test (id integer, data fraction);
CREATE TABLE
pg_fraction=# INSERT INTO test VALUES (1, '2/3');
INSERT 0 1
pg_fraction=# TABLE test;
id | data
----+------
1 | 2/3
(1 row)
pg_fraction=#
ここまでで、ユーザ定義型の最低限の実装はできました!
でも、データの格納と取り出しができるだけなので、ちょっと寂しいですよね。これだけなら、TEXT型で格納するほうがマシかもしれません。
算術演算と算術演算子の組み込み
今回、サンプルとして扱っているのは分数です。数を扱っているので、四則演算(足し算、引き算、掛け算、割り算)をしたくなりますよね。そこで、次は四則演算に対応してみます。
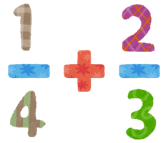
まず、2つの分数値を加算して、加算後の分数値を返却する、C言語関数を作成します。C言語関数で実際に何をやっているのかはpg_fraction.cの、Datum fraction_add(PG_FUNCTION_ARGS)というを見てもらえば分かると思いますが、引数として受け取った2つのfraction型から、分子と分母の値を抜き出して、小学校で習った分数の足し算をやっているだけです。
C言語関数を作成したら、その関数をSQL関数として使えるように登録します。このあたりは、最初に説明した入出力関数の登録と考え方は同じです。加算を行うSQL関数を登録する例はこんな感じになります。
CREATE FUNCTION fraction_add(fraction, fraction)
RETURNS fraction
AS 'MODULE_PATHNAME'
PARALLEL SAFE
LANGUAGE C IMMUTABLE STRICT;
こうすると、SQLとして分数の加算ができるようになります。
pg_fraction=# TABLE test;
id | data
----+------
1 | 2/3
(1 row)
pg_fraction=# SELECT fraction_add(data, '1/4') FROM test;
fraction_add
--------------
11/12
(1 row)
関数を使って加算をしてもいいのですが、せっかくなので加算らしい記号を使ってSQLを書きたいですよね?
このためには演算子を定義する必要があります。演算子を組み込むためには、CREATE OPERATORというPostgreSQLのDDLを実行します。
CREATE OPERATOR + (
leftarg = fraction,
rightarg = fraction,
procedure = fraction_add,
commutator = +
);
このコマンドでは、左辺にfraction型、右辺にfraction型、加算を実行する関数としてさきほど登録したfraction_addというSQL関数を使う、+という演算子を登録しています。
これで足し算らしく、+演算子を使ってSQLを書くことができました!
pg_fraction=# SELECT data + '1/4' FROM test;
?column?
----------
11/12
(1 row)
引き算、掛け算、割り算も同じように実装していきます。
集約演算の組み込み
PostgreSQLに限らず、データベースであれば数値型に対しては、集約演算(数のカウント、最大値、最小値、平均値等・・・)をサポートしています。ユーザ定義型でも、もちろん集約演算に対応は可能です。
fraction型では以下の2種類の集約演算(最大値、最小値)に対応しています、ここでは、最大値を算出する集約演算maxの定義例を見てみます。 集約演算の場合も、まず集約演算を実装するC言語関数、SQL関数を定義をします。その後で、集約演算を定義する、CREATE AGGREAGTEコマンドで集約演算を定義します。
-- MAX
CREATE FUNCTION fraction_max(fraction, fraction)
RETURNS fraction
AS 'MODULE_PATHNAME'
PARALLEL SAFE
IMMUTABLE
LANGUAGE C STRICT
;
CREATE AGGREGATE max (fraction)
(
sfunc = fraction_max,
combinefunc = fraction_max,
stype = fraction,
initcond = '-99999/1',
parallel = safe
);
上記のCREATE AGGREGATEコマンドのsfuncというパラメータで、集約時に使うSQL関数(この例ではfraction_max)を指定します。 (同じfraction_maxを指定している、combinefuncという指定がありますが、これは後述するパラレル処理対応時に指定するものです)
比較演算と比較演算子の組み込み
ここまでいろいろ実装を進めてきましたが、まだ大事な機能が実装されていません。
そう、今のままだと、fraction型に対する比較が一切できません!今度は、比較演算を組み込んでみます。
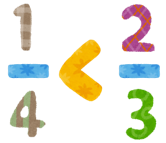
比較演算のときも算術演算と同じように、まずC言語関数を作るところから始めます。
2つの分数型を受け取って、「左辺より右辺が小さいか」を真または偽で返却するC言語関数は、pg_fraction.cの、Datum fraction_lt(PG_FUNCTION_ARGS)という関数で実行しています。ソースを見ると分かるように、入力時に分子/分母で算出して格納した浮動小数点型のデータがここで役に立ってきます。
C言語関数ができたので、それをSQL関数として登録し、そのSQL関数を使って比較演算子<を登録します。
CREATE FUNCTION fraction_lt(fraction, fraction)
RETURNS bool
AS 'MODULE_PATHNAME'
LANGUAGE C IMMUTABLE STRICT;
CREATE OPERATOR < (
leftarg = fraction,
rightarg = fraction,
procedure = fraction_lt,
RESTRICT = scalarltsel
);
これで、比較演算ができるようになりました!
2/3は1/4よりも大きいので、falseになります。
pg_fraction=# TABLE test;
id | data
----+------
1 | 2/3
(1 row)
pg_fraction=# SELECT data < '1/4' FROM test;
?column?
----------
f
(1 row)
WHERE句にも、もちろん使えます。
pg_fraction=# TABLE test;
id | data
----+------
1 | 3/4
2 | 5/8
3 | 4/11
(3 rows)
pg_fraction=# SELECT * FROM test WHERE data < '2/3';
id | data
----+------
2 | 5/8
3 | 4/11
(2 rows)
以下、他の比較演算子(=, <>,<=,>,>=)をちまちまと実装していきます。
そして比較演算子を実装することで、なんと!並べ替え(ORDER BY)ができるようになります!
pg_fraction=# SELECT * FROM test ORDER BY data;
id | data
----+------
3 | 4/11
2 | 5/8
1 | 3/4
(3 rows)
なんか、だいぶ実用的な感じになってきましたね。
ユーザ定義型を作ってみよう!(応用編)
基本編で書いた実装で、ユーザ定義型に対するある程度の操作はできるようになりました。ここからは、ちょっと応用的な機能をユーザ定義型に組み込んでみます。
型変換の組み込み
PostgreSQLでは、型変換(CAST)が可能な場合には、暗黙のうちに型変換を行ってくれます。これらの規則はシステムカタログに事前に登録されてからなのですが、ユーザ定義型の場合にはそうした事前の情報がないので、型変換をユーザ定義型に持たせたい場合には、CREATE CASTを使って、明示的に型変換の規則を登録しておく必要があります。
型変換の機能は必須の機能ではないですが、定義しておくとユーザ定義型を操作するSQLを記述する場合に、記述が楽になるかもしれません。
fraction型では、
- fraction型からdouble precision型
- integer型からfraction型
への型変換の規則を登録しています。
integer型からfraction型への型変換の組み込みのために、以下のようなSQL関数の定義と型変換を定義します。
CREATE FUNCTION int32_to_fraction(integer)
RETURNS fraction
AS 'MODULE_PATHNAME'
LANGUAGE C IMMUTABLE STRICT;
CREATE CAST (integer AS fraction) WITH FUNCTION int32_to_fraction(integer);
型変換を組み込むと、以下のように整数型から、分数型への変換を行います。
pg_fraction=# SELECT 3::fraction;
fraction
----------
3/1
(1 row)
インデックス検索への対応
さて、今のままでも、WHERE句にfraction型に対する比較演算はできるのですが、実運用を考えるとまだ問題があります。そう、今のままではfraction型にインデックスを設定することができません。せっかくなので、fraction型に対しても(B-Tree)インデックスを設定可能にしてみます。
例えば、比較を行ったときにインデックスが使用されるようにするには、以下のような定義を追加します。
CREATE FUNCTION fraction_cmp(fraction, fraction)
RETURNS integer
AS 'MODULE_PATHNAME'
LANGUAGE C IMMUTABLE STRICT;
-- freaction operator class
CREATE OPERATOR CLASS fraction_ops
DEFAULT FOR TYPE fraction USING btree AS
OPERATOR 1 < ,
OPERATOR 2 <= ,
OPERATOR 3 = ,
OPERATOR 4 >= ,
OPERATOR 5 > ,
FUNCTION 1 fraction_cmp(fraction, fraction);
fraction_cmp()は、先に紹介したfraction_eqとちょっと似ていますが、真偽値ではなく、-1(小さい)、0 (等しい)、1(大きい)という整数値を返却する関数を登録しておきます。
正直、CREATE OPERATORの記述は分かりにくいと思いますが、こうすることで、比較演算時にインデックスを利用した高速な検索が可能になると覚えておいてください。個々の比較演算ごとに、CREATE OPERATORの定義をしないといけないのは、なかなかに面倒くさいですが・・・。
実際にインデックス検索への対応ができたのか確認してみます。
pg_fraction=# CREATE INDEX data_idx ON test USING btree (data);
CREATE INDEX
pg_fraction=# EXPLAIN SELECT * FROM test WHERE data = '50/98';
QUERY PLAN
---------------------------------------------------------------------------
Bitmap Heap Scan on test (cost=28.42..707.06 rows=1033 width=20)
Recheck Cond: (data = '25/49'::fraction)
-> Bitmap Index Scan on data_idx (cost=0.00..28.16 rows=1033 width=0)
Index Cond: (data = '25/49'::fraction)
(4 rows)
pg_fraction=#
このように、CREATE INDEXによりインデックスが作成され、また、そのインデックスを使った実行計画が生成されるのを確認しました。
パラレルクエリへの対応
PostgreSQL 9.6から、1つのクエリを複数のプロセスを並列に動かして高速化する、「パラレルクエリ」の機能が入りました。しかし、ユーザが作成するSQL関数はデフォルトではパラレルクエリには対応していません。ユーザデータ型の実装で使ったSQL関数も同様です。
もし、自分で開発したSQL関数がパラレルクエリに対応できる、と判断した場合には、CREATE FUNCTIONや、CREATE AGGREGATEの定義内容を少し修正するだけで、SQL関数がパラレルに動作するようになります。
例えば集約関数maxをパラレルクエリに対応する場合、
CREATE FUNCTION fraction_max(fraction, fraction)
RETURNS fraction
AS 'MODULE_PATHNAME'
PARALLEL SAFE
IMMUTABLE
LANGUAGE C STRICT
;
CREATE AGGREGATE max (fraction)
(
sfunc = fraction_max,
combinefunc = fraction_max,
stype = fraction,
initcond = '-99999/1',
parallel = safe
);
上記の例のように、CREATE FUNCTIONで設定項目PARALLEL SAFEを追加し、CREATE AGGREGATEで、combinefuncとparallel = safeを指定することで、集約関数maxがパラレルクエリに対応できるようになります。
実際にfraction型のmaxがパラレルクエリに対応しているか確認してみます。
pg_fraction=# EXPLAIN ANALYZE VERBOSE SELECT max(data) FROM test;
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------------------------------
Finalize Aggregate (cost=11578.35..11578.36 rows=1 width=16) (actual time=324.607..324.607 rows=1 loops=1)
Output: max(data)
-> Gather (cost=11578.33..11578.34 rows=2 width=16) (actual time=324.594..324.598 rows=3 loops=1)
Output: (PARTIAL max(data))
Workers Planned: 2
Workers Launched: 2
-> Partial Aggregate (cost=11578.33..11578.34 rows=1 width=16) (actual time=300.944..300.944 rows=1 loops=3)
Output: PARTIAL max(data)
Worker 0: actual time=281.487..281.487 rows=1 loops=1
Worker 1: actual time=297.715..297.716 rows=1 loops=1
-> Parallel Seq Scan on public.test (cost=0.00..10536.67 rows=416667 width=16) (actual time=0.042..179.000 rows=333333 loops=3)
Output: data
Worker 0: actual time=0.040..172.332 rows=350177 loops=1
Worker 1: actual time=0.047..174.830 rows=366909 loops=1
Planning time: 0.169 ms
Execution time: 324.958 ms
(16 rows)
この実行計画では、2つのパラレルワーカプロセスを起動して、3つのプロセスで並列にmax関数の処理を実施しています。
SQL関数のパラレル化については、PostgreSQL文書の関数と集約のためのパラレルラベル付けのページも参考になると思います。
おわりに
今回は、pg_fractionという分数を管理するデータ型を題材に、ユーザ定義型を作成してみる一連の流れを説明してみました。自分でデータベースのデータ型を比較的簡単に作ることができる、というのはPostgreSQLの魅力の一つです。その魅力が少しでも伝われば幸いです。
参考情報
データ型以外にもPostgreSQLでは色々な拡張機能を組み込むことができます。拡張機能の組み込みについては、少し古い記事ですが、過去にいろいろな方が勉強会等で説明しているので、そちらも参考になるかと思います。
- PostgreSQLを拡張せよ! dbtech showcase 2014で発表された、SRA OSS. 高塚さん作成のスライド
- PostgreSQL開発ことはじめ ハッカーズチャンプルー2014で発表された花田さんのスライド。前半で拡張機能について説明。
PostgreSQLのことならNTTテクノクロスにおまかせください!



PostgreSQLに関わる仕事をしつつ、社内のPostgreSQLの問い合わせにカジュアルに対応。 「ぬこ@横浜」の名前で国内のデータベース関連のイベントでも喋っています。PostgreSQLの変な使い方を考えるのが趣味。 著書に『内部構造から学ぶPostgreSQL 設計・運用計画の鉄則』(技術評論社/共著)。 最近の自己紹介は「『PostgreSQL ラーメン』でググってください」
![]()