Parallel Index Scanを実験!その実力は?
PostgreSQL10がリリースされておよそ半年。 ようやく新機能の一つである「Parallel Index Scan」について動作確認したので、ここで共有したいと思います。




ぬこのたのしいぽすぐれ教室 第5回
- 2018年02月22日公開
PostgreSQL10がリリースされておよそ半年。 ようやく新機能の一つである「Parallel Index Scan」について動作確認したので、ここで共有したいと思います。
What's Parallel Index Scan?
その名の通り、パラレル(並列)にインデックスを用いた検索を行うことです。
PostgreSQL 9.6まではテーブル全体を検索するシーケンシャルスキャンなど一部のスキャンでしかパラレル処理できませんでしたが、PostgreSQL 10からインデックスに対するスキャンもパラレルに処理できるようになリました。
オンラインマニュアル(英語): https://www.postgresql.org/docs/10/static/parallel-plans.html#PARALLEL-SCANS
以下、PostgreSQL 10時点で Parallel Index Scan に対応している B-treeインデックスについて書いていきます。
PostgreSQLのIndex Scanおさらい
さて、Parallel Index Scanの動作確認を行う前に、そもそもPostgreSQLがインデックスを用いた検索を行うときの挙動をおさらいします。
PostgreSQLのインデックスファイルはテーブルファイルとは別に作成されます。内部は論理的な木構造となっています。
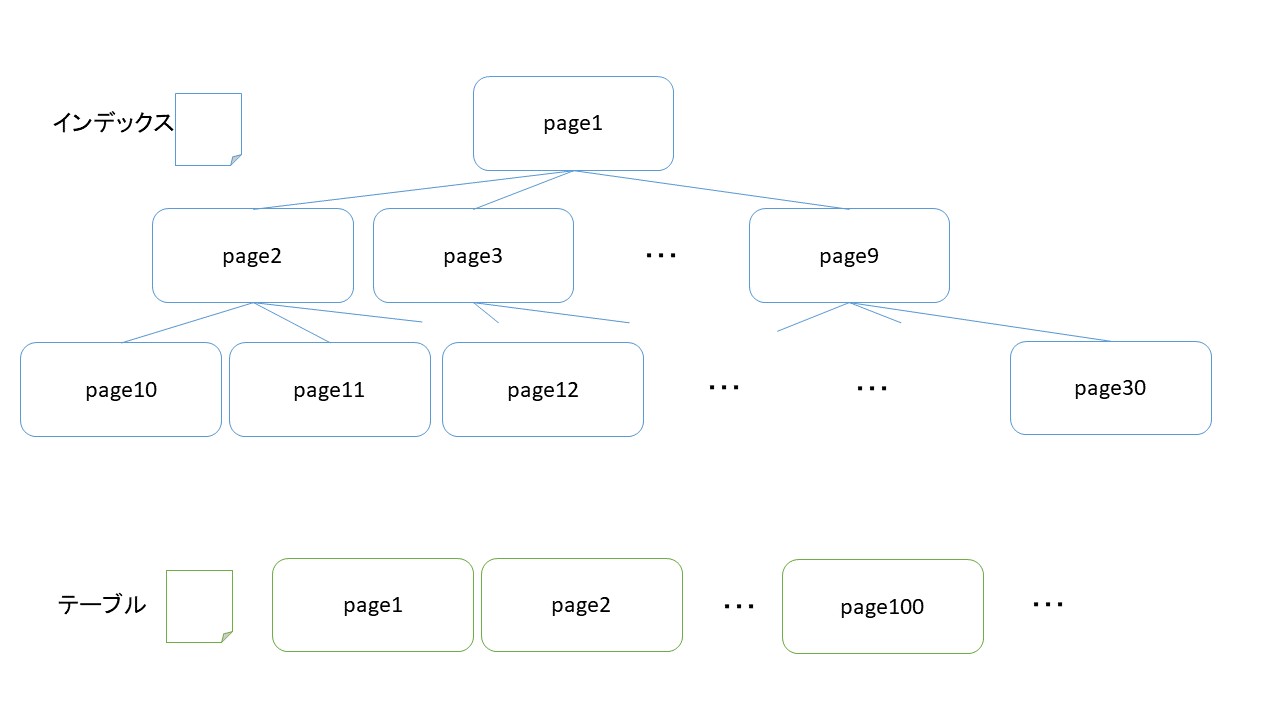
Index Scanが実行されると、下記の通り2種類の走査が発生します。
- インデックスファイルをルートからリーフに向かって辿る(縦方向のスキャン)
- リーフを辿り、テーブルファイルにアクセスしてデータを取得する(横方向のスキャン)
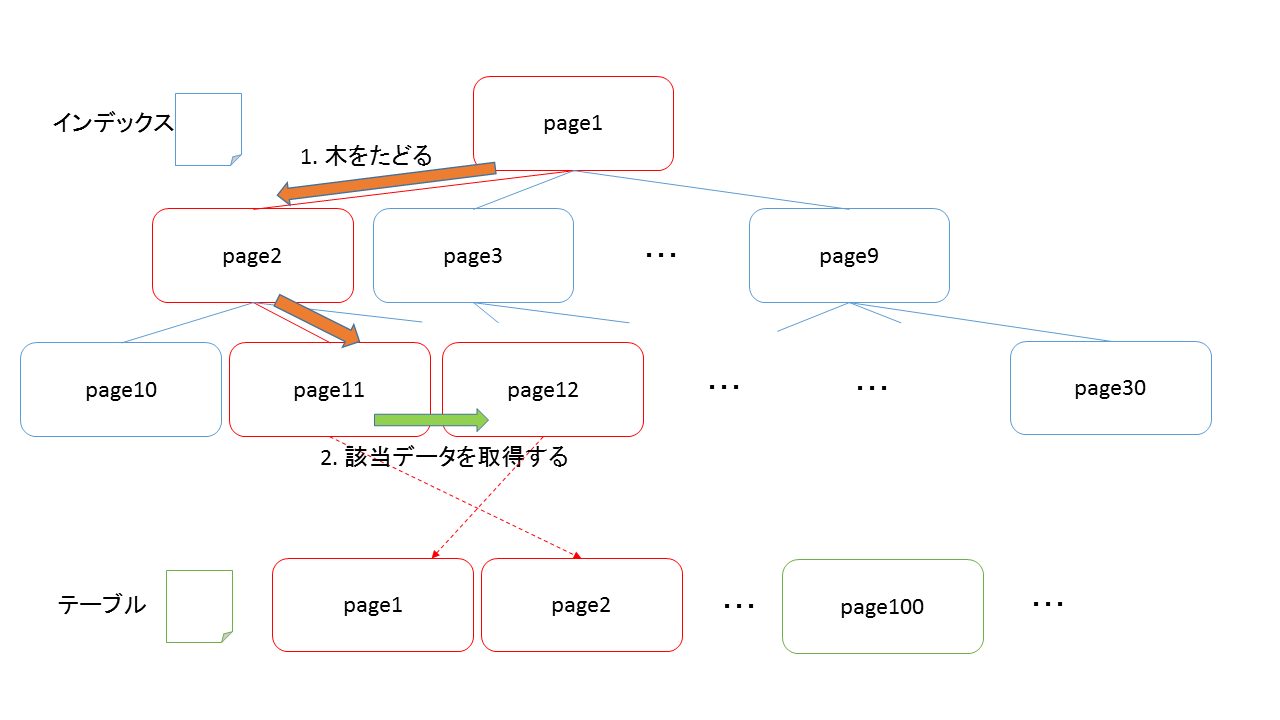
ちなみに、1の処理のみ実行して結果を返すIndex Only ScanもPostgreSQL 10からはパラレルで実行できるようになってます。
疑問
ここでリリースノートのParallel Index Scanに関する記述を見て、ちょっと疑問を抱きました。
--
E.3.3.1. Server
E.3.3.1.1. Parallel Queries
Support parallel B-tree index scans
This change allows B-tree index pages to be searched by separate workers.
https://www.postgresql.org/docs/10/static/release-10.html#id-1.11.6.7.5
疑問は、「1.縦方向のスキャン」も並列実行できるのかしら?ということです。
「2.横方向のスキャン」はなんとなくイメージできるけど、「1.縦方向のスキャン」はどうなんだろう?と。まぁ、普通に考えたらどこの枝を辿るか不明なので、並列実行はできないんだろうけど、マジカルな処理になってたりして。。。と。
実験
PostgreSQL 10からはパラレル処理に関するパラメータがデフォルトで有効になっているので、条件が合えば勝手にパラレル処理が実行されます。 以下、パラレル処理に関する主なパラメータです。
| パラメータ名 | デフォルト値 | 説明 |
|---|---|---|
| max_worker_processes | 8 | システム全体で起動できるバックグラウンドプロセス(パラレル処理を行うプロセス含む)の上限 |
| max_parallel_workers | 8 | システム全体で起動できるパラレル処理を行うプロセスの上限 |
| max_parallel_workers_per_gather | 2 | 1パラレル処理中に起動できるプロセスの上限 |
| parallel_setup_cost | 1000 | パラレル処理を行うプロセスを起動するのに必要なコスト |
| parallel_tuple_cost | 0.1 | パラレル処理でデータを受け渡しするのに必要なコスト |
| min_parallel_table_scan_size | 8MB | テーブルのスキャン対象が指定サイズ以上だとパラレル処理を行うプロセスを追加起動する |
| min_parallel_index_scan_size | 512kB | インデックスのスキャン対象が指定サイズ以上だとパラレル処理を行うプロセスを追加起動する |
実験環境はpgbenchを用いて以下の通り作成しました。
$ pgbench -i -s 2000 bench
対象のテーブルはpgbench_accountsテーブル、インデックスはpgbench_accounts_pkeyです。
bench=# \d pgbench_accounts
Table "public.pgbench_accounts"
Column | Type | Collation | Nullable | Default
----------+---------------+-----------+----------+---------
aid | integer | | not null |
bid | integer | | |
abalance | integer | | |
filler | character(84) | | |
Indexes:
"pgbench_accounts_pkey" PRIMARY KEY, btree (aid)
bench=# select count(*) from pgbench_accounts ;
count
-----------
200000000
(1 row)
Let's parallel!
bench=# explain analyze select count(aid) from pgbench_accounts where aid > 1000 and aid < 900000 ;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Finalize Aggregate (cost=18068.91..18068.92 rows=1 width=8) (actual time=106.432..106.432 rows=1 loops=1)
-> Gather (cost=18068.69..18068.90 rows=2 width=8) (actual time=106.414..106.421 rows=3 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Partial Aggregate (cost=17068.69..17068.70 rows=1 width=8) (actual time=100.532..100.532 rows=1 loops=3)
-> Parallel Index Only Scan using pgbench_accounts_pkey on pgbench_accounts (cost=0.57..16209.51 rows=343675 width=4) (actual time=0.066..62.167 rows=299666 loops=3)
Index Cond: ((aid > 1000) AND (aid < 900000))
Heap Fetches: 0
Planning time: 0.174 ms
Execution time: 108.605 ms
(10 rows)
ちょっと見難いですが、「Workers Launched: 2」とあり、「Parallel Index Only Scan」が loops=3 つまり3並列(*)で動いたことがわかります。
(*)上位のノード(Gatherノード)と2つのワーカプロセス
前述のパラメータ max_parallel_workers_per_gather を 0 にして、パラレル処理するプロセスを起動できなくして、性能差を確認できます。
bench=# set max_parallel_workers_per_gather to 0;
SET
bench=# explain analyze select count(aid) from pgbench_accounts where aid > 1000 and aid < 900000 ;
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------------------------------------------------------
Aggregate (cost=23083.00..23083.01 rows=1 width=8) (actual time=196.744..196.744 rows=1 loops=1)
-> Index Only Scan using pgbench_accounts_pkey on pgbench_accounts (cost=0.57..21020.95 rows=824819 width=4) (actual time=0.016..112.755 rows=898999 loops=1)
Index Cond: ((aid > 1000) AND (aid < 900000))
Heap Fetches: 0
Planning time: 0.142 ms
Execution time: 196.777 ms
(6 rows)
90ミリ秒ほどパラレルの方が早いようです。
ちなみに、環境やデータ量によって性能差は変わるので、あくまで参考としてご覧ください。
ある程度制御できることが確認できたので、いよいよ「マジカルな処理」の有無を確認します!
まずは max_parallel_workers_per_gather を元の値(2)に戻して、前述のパラメータを含む "cost" と名のつくパラメータをことごとく 0 に変更してみます。
bench=# set max_parallel_workers_per_gather to 2;
SET
bench=# set min_parallel_index_scan_size to 0;
SET
bench=# set parallel_setup_cost to 0;
SET
bench=# set cpu_index_tuple_cost to 0;
SET
bench=# set cpu_operator_cost to 0;
SET
bench=# set random_page_cost to 0;
SET すると、次のように 1件取得のクエリでも「Workers Launched: 1」とあるようにワーカプロセスが起動されます。
bench=# explain analyze select aid from pgbench_accounts
where aid = 1000 ;
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------------------------------
Gather (cost=0.00..0.01 rows=1 width=4) (actual time=0.328..8.155 rows=1 loops=1)
Workers Planned: 1
Workers Launched: 1
-> Parallel Index Only Scan using pgbench_accounts_pkey on pgbench_accounts (cost=0.00..0.01 rows=1 width=4) (actual time=0.012..0.013 rows=0 loops=2)
Index Cond: (aid = 1000)
Heap Fetches: 0
Planning time: 0.086 ms
Execution time: 9.044 ms
(8 rows)
でも、よく見ると「Prallel Index Only Scan」では「rows=0」となっています。今回のクエリの場合、縦方向のスキャンで結果を返さないことはないので、つまりこのワーカは「2.横方向のスキャン」で起動されたと考えることができます(しかも何もしてない)。
まぁ、当然といえば当然の結果ですが。。。
まとめ
Parallel Index (Only) Scanは、「2. リーフを辿り、テーブルファイルにアクセスしてデータを取得する(横方向のスキャン)」で、複数のプロセスを起動して実現されています。
名前からすると、なんだか凄い性能改善が期待できそうな感じがしますが、今回実際にいろいろ試してみてまだまだ改善の余地がありそうに思いました。
デフォルトでパラレル処理可能になったのはとても便利なのですが、逆にパラレル処理になってしまうことで性能悪化になるケースもありそうです(実際、上記例を別のクエリで実行したら性能が悪くなるケースもありましたorz)。
この記事が、これからPostgreSQL 10を利用・検証しようとしている方に何かのお役に立てれば幸いです!
PostgreSQLのことならNTTテクノクロスにおまかせください!



10数年に渡り、PostgreSQLの機能拡張や運用サポートを行うとともに、 「PGCon/PGCon.jp」などのコミュニティ活動、セミナー講演、書籍執筆など幅広い普及活動を行っている。 著書に「内部構造から学ぶPostgreSQL 設計・運用計画の鉄則(技術評論社)」がある。 やっぱりネコが好き。
![]()