ヘテロジニアスコンピューティング~DPDK入門 第14回~
前回記事に関連し、ネットワークパケット処理におけるヘテロジニアスコンピューティングについてご紹介します




DPDK入門
- 2022年03月03日公開
はじめに
こんにちは、NTTテクノクロスの山下です。第13回で触れましたが、DPDKにおいてもCPU以外も利用するヘテロジニアスコンピューティングを可能とする技術が登場してきています。今回はヘテロジニアスコンピューティングの概要とDPDKにおけるGPU利用に関する詳細をご紹介します。

ヘテロジニアスコンピューティングとは
ヘテロジニアスコンピューティングとは CPU以外も利用した計算手法のことを意味します。
ヘテロジニアス自体は英語で、異質のものという意味です。対義語はホモジニアス(同質)です。
ヘテロジニアスコンピューティングの必要性については、経済産業省発行の産業技術ビジョン2020に記載があります。これは、産業技術という切り口から日本の課題を見つめ直し、2050年に向けて日本の産業技術の方向性を示したものであり、2025年までに実現すべきことも記しています。
CPU以外を計算に使うアイデア・手法は パソコンでは、昔からあって画像処理にGPU (Graphics Processing Unit)を利用しています。
近年だとPCゲーム利用の際に、高い画像処理能力を持つグラフィックボード を必要とするものもかなり多いです。
GPUはその発祥としては、画像処理を得意としていてそれは 今も変わらないですが、画像処理以外の一般目的にも 利用することも最近よくされています。 このことをGPGPU(General Purpose GPU)と呼んだりします。
ネットワークの世界でもパソコンと同様のことが起きてきており 、CPU以外のプロセッサも用いてパケット処理を行うようなトレンドがあります(図1参照)。
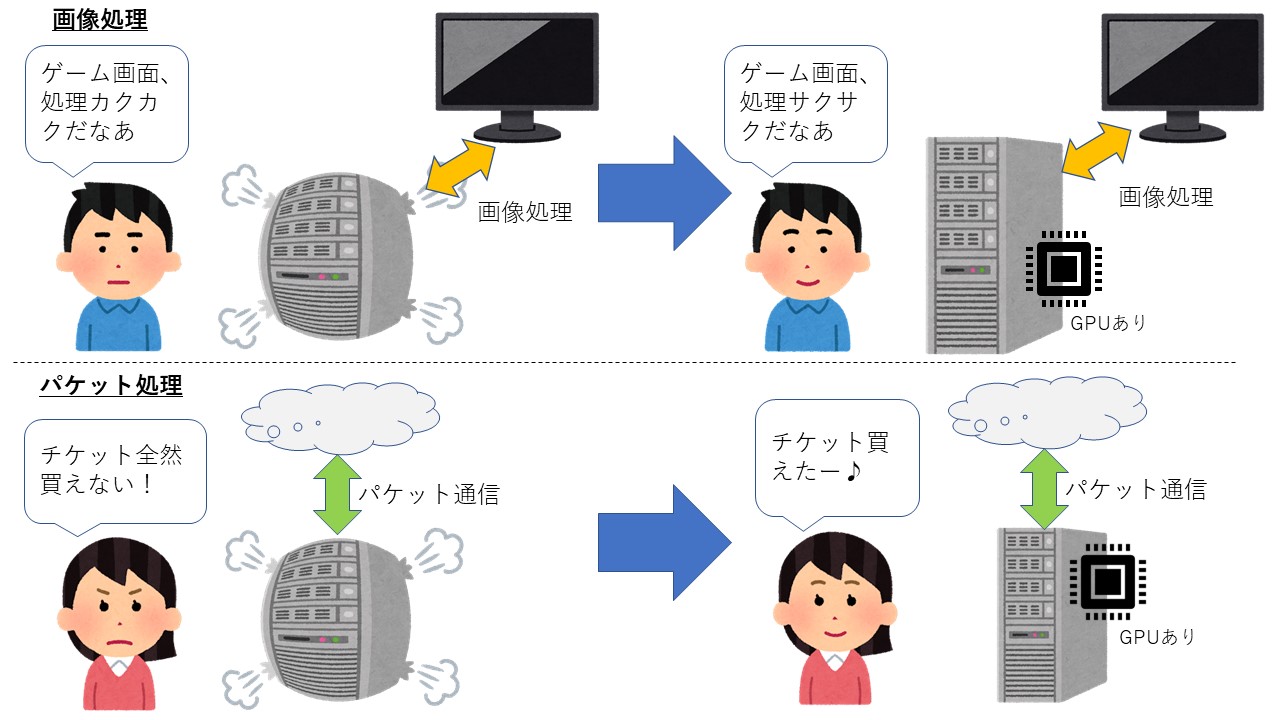
図1.GPU追加による効果
CPU以外とは、具体的にはGPUやFPGAを指しますが 今回は、GPUを利用したヘテロジニアスコンピューティングについて紹介します。
CPU処理のボトルネックとGPUアクセラレーション
DPDKにおいてもヘテロジニアスコンピューティングの手段が用意されています。CPU単独で処理する際に生じるボトルネックを克服するためです。
以下は2019年にDPDK Summit North America(DPDK開発者が集まるイベント)で発表されたプレゼンテーションです。
世界的なGPUベンダであるNvidia社やDPDK対応NICで有名なMellanox社(現在はNvidia社が買収)、国際的な衛星通信システムの会社であるViaSat社が発表しています。
この動画は、GPUを利用したアクセラレーション(以降、本ブログ内ではGPUアクセラレーションと呼びます)について実システムへの適用例も含めて紹介しています。以降で、私なりにGPUアクセラレーションについて紹介します。
具体的にGPUアクセラレーションについてご紹介する前に、CPUのボトルネックについて図2で解説します。昔はCPU自体の処理速度がボトルネックだったのですが、現在はCPUとメモリとの間の転送速度(メモリバス速度)が処理のボトルネックになっています。このことは前述のプレゼンテーションの中でも口頭で触れられていますし、私の経験上でも実感があります。具体的な例としては、ネットワークパケットをCPUで処理させる場合、ネットワークから受信したパケットのサイズが大きかったり、大量のパケットを受信するとメモリとCPUとの間で大量の転送が発生します。これがメモリバスを圧迫し性能のボトルネックとなります。
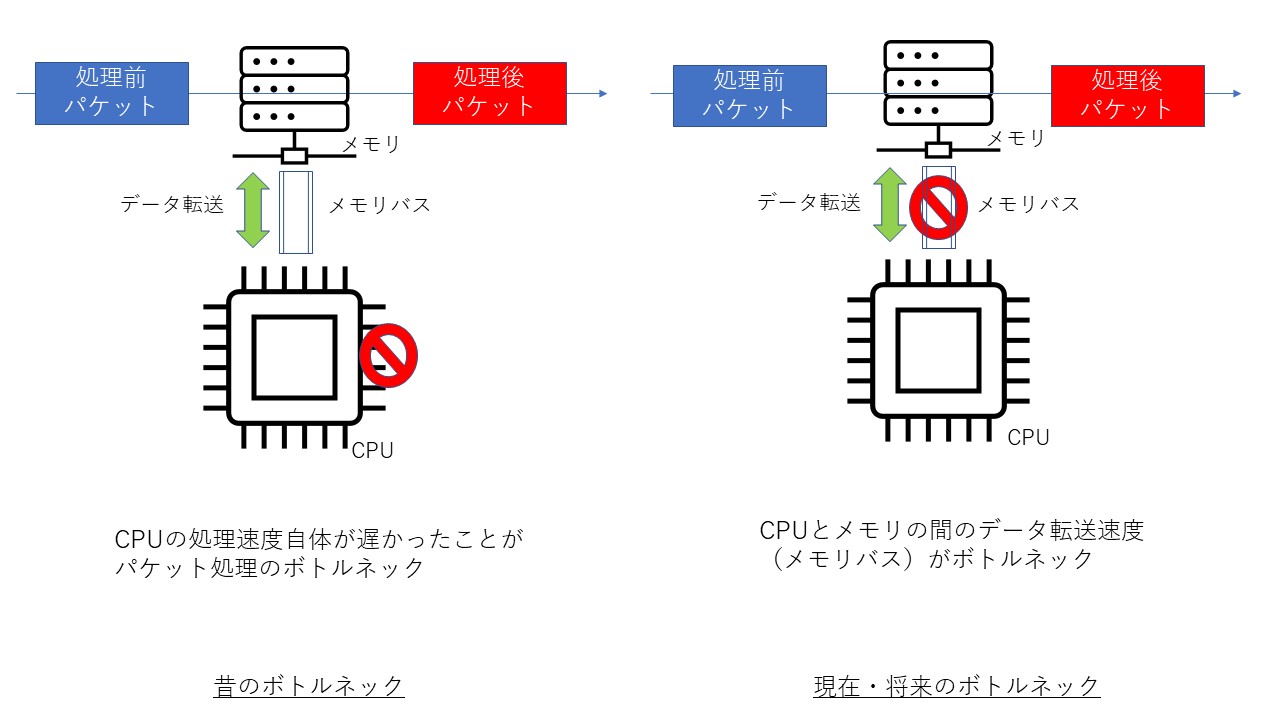
図2.CPU処理のボトルネック
そこで、CPU以外にパケット処理をさせる考えが出てくるのですが、今回はGPUにパケット処理をさせるGPUアクセラレーションについて解説します。
「アクセラレーション」は加速の意味ですが、CPUでの処理負荷を下げるという意味合いで「オフロード(offload)」(自動車やバイクのオフロード(off-road)とは異なります)と呼ばれることも多いかもしれません。
GPUアクセラレーション
GPUアクセラレーションそのものに触れる前に、まずは、ネットワークパケットの構造について簡単に解説します。今回の例ではパケットの構造をまず理解いただくことにより、GPUアクセラレーションの効果が分かりやすくなるためです。
パケットは様々な制御情報(ペイロードの長さや、チェックサムや各種のフラグ)が記述されている「パケットヘッダ」と具体的なデータを格納する「パケットペイロード」に分かれています。一般的にパケットヘッダは、パケットペイロードに比較してデータサイズが小さいという特徴を持っています。
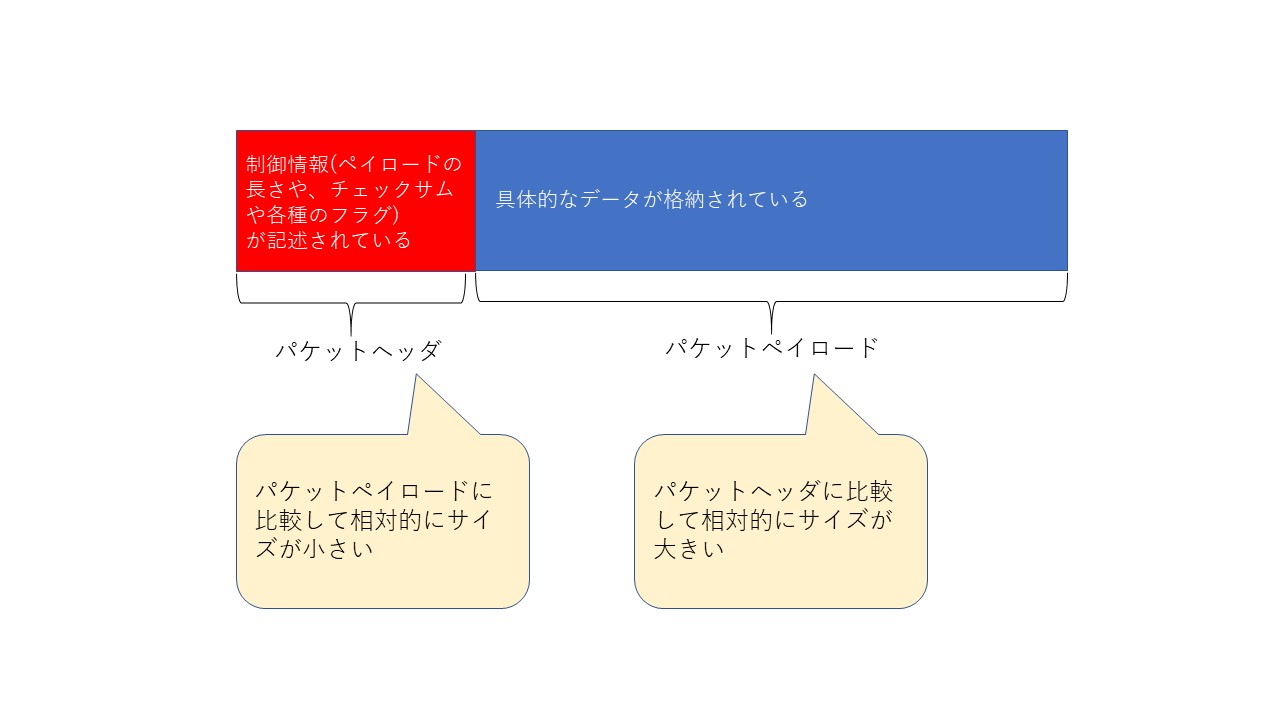
図3.パケットの構造
GPUアクセラレーションが無い場合と有る場合の違いを図4に示します。
GPUアクセラレーションの肝は、データサイズが相対的に小さいパケットヘッダのみCPUで処理し、パケットペイロードはGPUで処理することです。
このことにより前述のCPU処理のボトルネックを回避して、システム全体としては性能を向上させることができます。
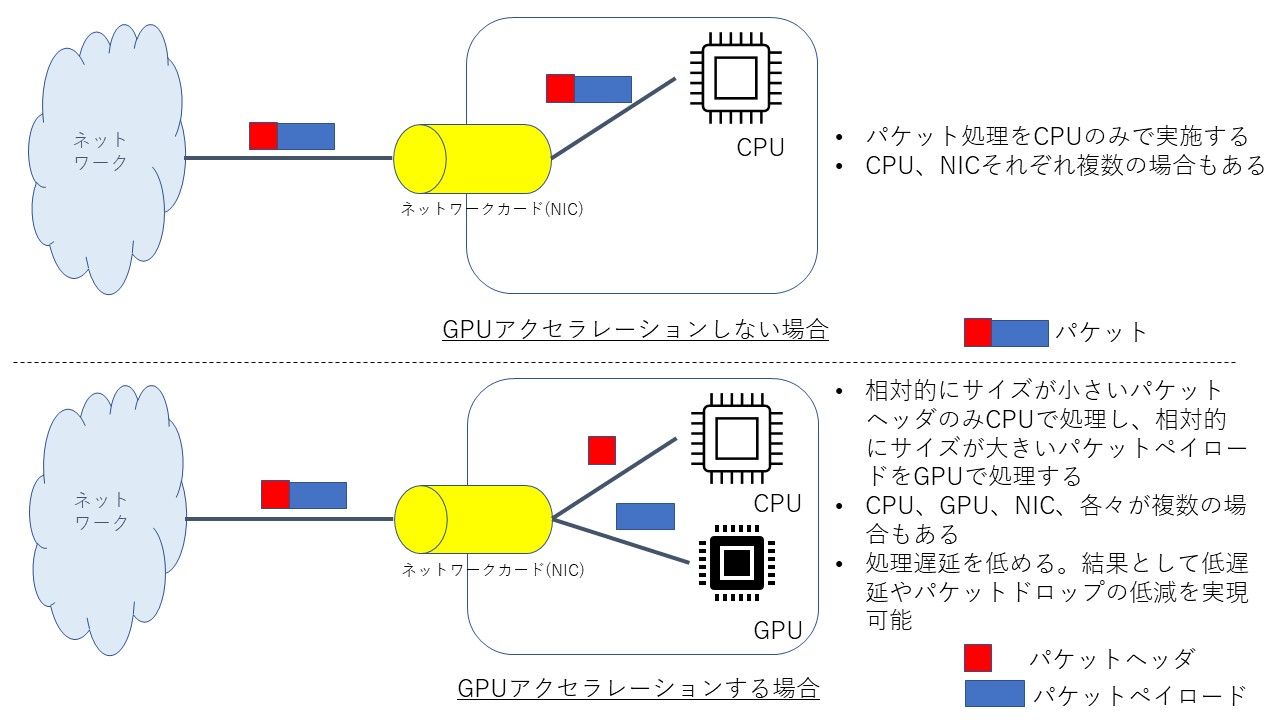
図4.GPUアクセラレーション
DPDKにおいてGPUアクセラレーションを実現させるための主要機能
DPDKにおいて、GPUアクセラレーションを実現させるのための主要な機能である、以下の3つについてご紹介します。
- - GPUサポート
- - External Buffer(外部バッファ)
- - Header Split(ヘッダ分離)
GPUサポートについては第13回でご紹介していますが、DPDKアプリケーションからGPUを制御するための機能です。デバイス情報取得機能、メモリ管理機能、CPUとGPUの間でやりとりをする際に便利なフラグやリスト機能で構成されています。
次に、External Buffer(外部バッファ)について解説します。
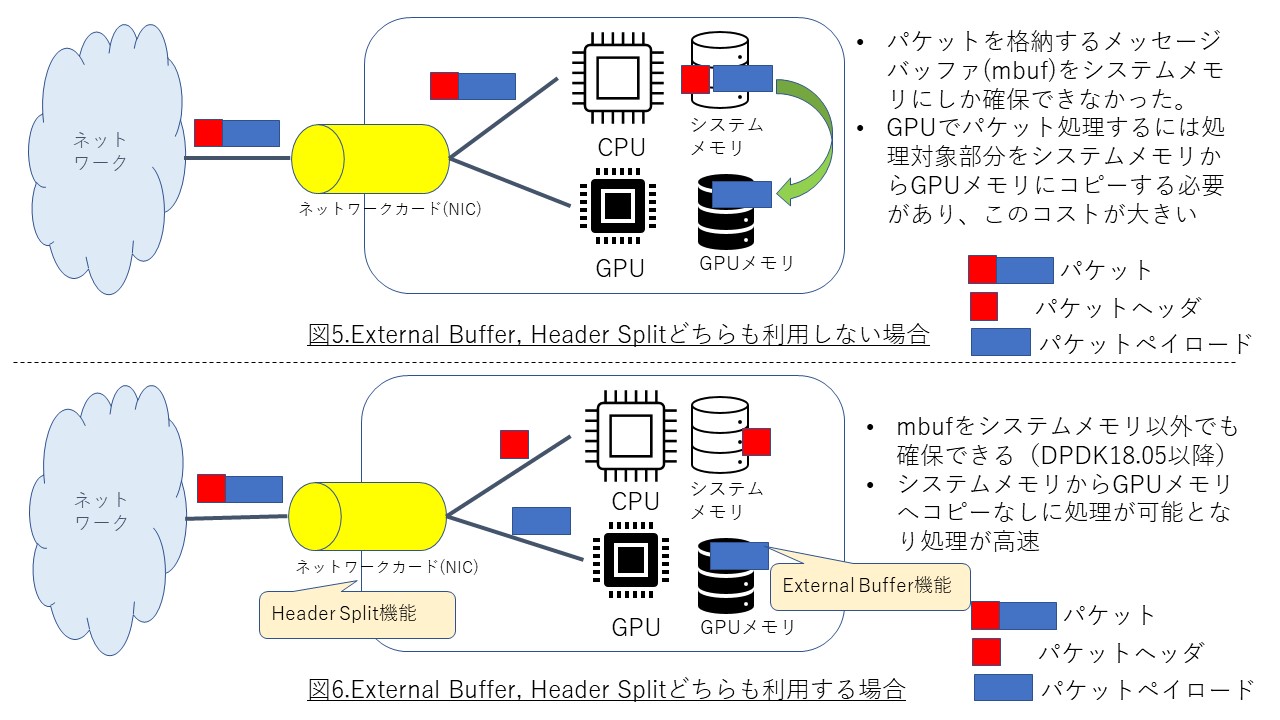
ネットワークからNIC経由で受信したパケットはメモリに蓄積されます。ただし、これはシステムメモリであり、GPUが固有で持つGPUメモリへのパケット蓄積はDPDK18.02以前はできませんでした(図5)。
GPUは基本的にGPUメモリに存在するデータを対象に処理を行うため、これでは都合がよくありません。
GPUでパケットを処理させるために、システムメモリからGPUメモリにデータのコピーを行う必要があり、このコピー処理のコストが馬鹿にならないためです。
外部バッファ機能により、GPUメモリ上にパケット処理のためのメモリを確保可能となるため、システムメモリからGPUメモリへのコピーをしなくても済むようになります。
最後に、Header Split(ヘッダ分離)について解説します。
Header Splitはネットワークから受信したパケットをパケットヘッダとパケットペイロードに分けて、それぞれを別々のメモリの場所に配置することを可能とする技術です。分ける機能そのものはネットワークインタフェースカード(NIC)が具備していますが、DPDKアプリケーションからは、このNICの機能を利用するかしないか、利用する場合にはヘッダとして分割するサイズをNICに指示することが可能となっています。
上記の主要機能を組み合わせることにより、パケットペイロードをNICからGPUメモリに直接転送することが可能となっています。図6は、上記機能を用いてGPUアクセラレーションした場合の一例を示します。
おわりに
今回はヘテロジニアスコンピューティングの概念とDPDKにおける適用例であるGPUアクセラレーションについてご紹介しました。本記事の連載に関して何か問い合わせがございましたら、以下に連絡下さい。よろしくお願いします。
本件に関するお問い合わせ



[著者プロフィール]
フューチャーネットワーク事業部 第一ビジネスユニット
山下 英之(YAMASHITA HIDEYUKI)
![]()