分散処理の概要とDeepSpeedによる単一GPUを使った推論について
「推論」と「分散処理」の概要と、分散処理を行うためのツールである「DeepSpeed」を用いた基礎的な(単一GPUマシンでの)推論についてご紹介します。




はじめに
こんにちは、NTTテクノクロス株式会社の河野と申します。
LLMに関する話題が増えるなか、ローカルモデルを活用している方も多いかと思います。
一方で、より精度が高い・大きなモデルを使おうとしても、動かすためのリソースが足らず苦労している方もいるのではないでしょうか。
そこで今回は「推論」と「分散処理」の概要と、分散処理を行うためのツールである DeepSpeed を用いた基礎的な(単一なGPUマシンでの)推論についてご紹介したいと思います。
目次
- ① 推論と分散処理について
- ② DeepSpeedを使った単体推論の実行について
- ③ おわりに
推論と分散処理について
学習済みのモデル(LLM)に対しては、大きく「推論」と「学習」と呼ばれる処理が可能です。
「学習」とは、ファインチューニングのように、モデルに何かを教え込むことを指します。
「推論」とは、LLMに対して質問を投げかけて回答を生成してもらう処理のことを指します。

(図1: 学習と推論について)
「推論」「学習」どちらも動作させるためのマシンリソースが必要となります。
また、モデルのサイズに応じて必要となるマシンリソースは増加します。
特に重要なリソースがGPUとなりますが、巨大なモデルを扱う場合、1台のGPUやGPUマシンではリソースが足りない場合があります。
この課題の解消手法の1つとして、複数のGPU、あるいはGPUマシンで処理を分割して実行するということが考えられます。
1つの処理を複数の媒体(デバイスやマシン)に分割することで、1媒体にかかる負荷・必要リソースを下げることができます。
このように処理を分割して実現することを「分散処理」と呼びます。
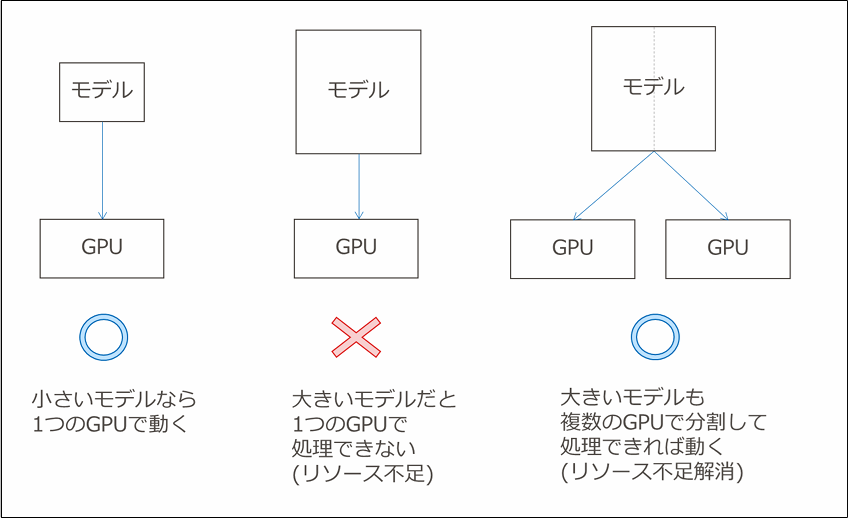
(図2: 分散処理について)
分散処理は「推論」と「学習」のどちらも対応できます。
「学習」のほうがリソースが必要となるため、推論は分散が不要でも学習させる場合には必要になる、といった場合もあります。
分散処理のメリット
分散処理のメリットは、巨大なモデルでの処理実行以外にも以下のようなメリットがあります。
DeepSpeedを使った単体推論の実行について
ここからは、前節で紹介した処理の動作例を紹介します。
動作例では、複数 GPU マシンでの分散処理も実現でき、かつ初⼼者向け寄りな DeepSpeed を取り扱います。
DeepSpeed を活⽤する為の最初の⼀歩として、DeepSpeed を使って単⼀マシン・単⼀ GPU での推論実⾏例について本節で紹介します。
[参考1]DeepSpeedとは?
大規模な言語モデルや深層学習モデルの分散学習・高速化・効率化を目的としたMicrosoftが開発したオープンソースソフトウェアのこと。
[参考2] Accelerateを用いた単⼀マシン・複数 GPUでの推論実行例
分散処理については、⼀般的に推論より学習の⽅が敷居が上がります。
また、単⼀マシン・複数 GPU での分散処理より、複数マシン・複数 GPU のほうが敷居が上がります。
したがって、今回取り上げる例は最も初歩的なものとなります。
ちなみに単⼀マシン・複数 GPU での推論実⾏については Hugging Face Accelerate により簡単に実現できます。
具体的には Hugging Face のライブラリ(※)にてモデル指定をする際に device_map オプションにて auto を指定します。
※ Hugging Faceのライブラリに関する基本的な使い方は、LLM活用入門 第10回、第11回参照。
第10回:Hugging Faceライブラリで実行する推論と学習の基礎(前編) ~LLM活用 第10回~ | NTTテクノクロスブログ
第11回:Hugging Faceライブラリで実行する推論と学習の基礎(後編) ~LLM活用 第11回~ | NTTテクノクロスブログ
実⾏する際には、pip install にて Accelerate をインストールしておく必要があります。
### 単一マシン・複数GPUを活用した推論指定例
from transformers import AutoTokenizer, AutoModelForCausalLM, DataCollatorForLanguageModeling, TrainingArguments, Trainer
# トークナイザー、モデルセット
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/DeepSeek-R1-Distill-Llama-70B")
model = AutoModelForCausalLM.from_pretrained("利用するモデル名", device_map="auto", torch_dtype="auto")
# プロンプトセット
messages = [
{"role": "user", "content": [{"type": "text", "text": "ユーザの質問文"}]},
]
# トークナイズ
pr_ids = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt").to(model.device)
# 推論実行
outputs = model.generate(pr_ids, max_new_tokens=4096, temperature=0.7)
result = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(result)Accelerate から DeepSpeed を呼び出すこともできます。
このように分散処理の⽅法は様々ですが、今回はシンプルな例として、DeepSpeed のみで動かす例を以降で示します。
利用したツール、パッケージなどのバージョンについて
使⽤する⾔語は Python になります。
利⽤する各ツール、パッケージ、環境のバージョンや詳細は以下の通りです。
また、今回は GPU を使ってモデルを動かす想定となっております。
したがって GPU が必要、かつ CUDA の設定も必要となります。
◆バージョン一覧
※UbuntuはWindowsマシンの上にWSLで構築します。構築手順について
ここからは構築手順について記載します。
[補足] 事前に行っておいた方が良い設定
・PowerShellの最新化(公式ページからダウンロード可能)
・プロキシ設定(社内環境などの場合)
・エディタの変更(普段からviを使用している場合)
・NVIDIAグラフィックドライバのインストール
以下のサイトから使用しているグラフィックボードにあったバージョンをダウンロードする。
GPU in Windows Subsystem for Linux (WSL) | NVIDIA Developer
・WSL2のインストール
wsl --install・Ubuntuのダウンロード
#以下サイトからローカル環境にダウンロード
https://cloud-images.ubuntu.com/wsl/jammy/current/
#ファイル名
ubuntu-jammy-wsl-amd64-ubuntu22.04lts.rootfs.tar.gz・Ubuntuのインストール
mkdir C:\\WSL\\Ubuntu2204
cd C:\\WSL\\Ubuntu2204\\
cp C:\\Users\\xxx\\Downloads\\ubuntu-jammy-wsl-amd64-ubuntu22.04lts.rootfs.tar.gz .
wsl --import Ubuntu-22.04 C:\\WSL\\Ubuntu2204 C:\\WSL\\Ubuntu2204\\ubuntu-jammy-wsl-amd64-ubuntu22.04lts.rootfs.tar.gz・WSL2の確認、起動
#確認
wsl --list --verbose
NAME STATE VERSION
* Ubuntu-22.04 Running 2
#起動
wsl -d Ubuntu-22.042.SSHの設定
・SSHのインストール
sudo apt update
sudo apt install openssh-server
sudo service ssh start
sudo systemctl enable ssh3.必要なライブラリのインストール
・CUDA Toolkitのインストール
sudo apt update
sudo apt install -y wget gnupg
wget <https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/3bf863cc.pub>
sudo mv 3bf863cc.pub /usr/share/keyrings/cuda-archive-keyring.gpg
echo "deb [signed-by=/usr/share/keyrings/cuda-archive-keyring.gpg] <https://developer.download.nvidia.com/compute/cuda/repos/ubuntu$>(lsb_release -rs | sed 's/\\.//')/x86_64/ /" | sudo tee /etc/apt/sources.list.d/cuda.list
#CUDA Toolkitのインストール
sudo apt update
sudo apt install -y cuda-toolkit-12-1
#CUDAのパス設定
echo 'export CUDA_HOME=/usr/local/cuda' >> ~/.bashrc
echo 'export PATH=$CUDA_HOME/bin:$PATH' >> ~/.bashrc
echo 'export LD_LIBRARY_PATH=$CUDA_HOME/lib64:$LD_LIBRARY_PATH' >> ~/.bashrc
source ~/.bashrc
#CUDAの動作確認
nvcc --version・PyTorchのインストール(WSL2のUbuntu上で実施)
#pytorchのインストールコマンド
pip3 install torch torchvision torchaudio --index-url <https://download.pytorch.org/whl/cu121>
#WSLの再起動
wsl --shutdown
#WSLの起動
wsl -d Ubuntu-22.04
#インストール確認
python3 check.py
#出力結果
True
NVIDIA GeForce RTX 2080 SUPER
・check.pyの内容
import torch
print(torch.cuda.is_available())
print(torch.cuda.get_device_name(0))・DeepSpeed、Transformers、Accelerateのインストール
pip install deepspeed transformers accelerate・pdshのインストール
sudo apt update
sudo apt install pdsh・Hugging Faceからモデルのダウンロード
#wslにコピー
cp -r /mnt/c/Users/xxx/.cache/huggingface/hub/models--ABEJA--ABEJA-Qwen2.5-7b-Japanese-v0.1 ~/.cache/huggingface/hub/
Copy-Item -Recurse "C:\\Users\\xxx\\ABEJA-Qwen2.5-7b-Japanese-v0.1" "\\\\wsl$\\Ubuntu-22.04\\home\\xxx"
#コピー確認
ls ~/.cache/huggingface/hub/ABEJA-Qwen2.5-7b-Japanese-v0.1
#オフラインモードの有効化
export TRANSFORMERS_OFFLINE=1
export HF_DATASETS_OFFLINE=1ここまでの手順が今回の環境準備となります。
単体推論のソースコードについて
今回は、以下に示すソースコードを利用して単体推論を行ってみます。
vi ds_test_qwen.py・ds_test_qwen.pyの内容
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
import deepspeed
model_id = "/home/xxx/ABEJA-Qwen2.5-7b-Japanese-v0.1"
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype="auto",
low_cpu_mem_usage=True,
trust_remote_code=True
)
#DeepSpeed Inferenceでラップ
ds_engine = deepspeed.init_inference(
model,
tensor_parallel={'tp_size': 1}, # ここを1に変更
dtype=torch.float16,
replace_with_kernel_inject=True
)
#プロンプトセット
prompt = "こんにちは、自己紹介してください。"
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
#推論実行
with torch.no_grad():
output = ds_engine.generate(**inputs, max_new_tokens=128)
print(tokenizer.decode(output[0], skip_special_tokens=True))今回は、推論時にHugging Face Hubからモデルをダウンロードする形ではなく、モデルやトークナイザーのロード時にローカルパスを指定することで、ネットワークアクセスなしで推論を行っています。
特筆すべきポイントは以下の箇所となります。
#DeepSpeed Inferenceでラップ
ds_engine = deepspeed.init_inference(
model,
tensor_parallel={'tp_size': 1},
dtype=torch.float16,
replace_with_kernel_inject=True
)ここで DeepSpeed を指定しています。
tensor_parallel にて 1 を指定しているのは、単⼀ GPU で実現する為です。
その後、上で指定した ds_engine を使って推論を実⾏します。
#DeepSpeedによる推論実行該当箇所
output = ds_engine.generate(**inputs, max_new_tokens=128)実行手順について
以下が推論の実行コマンドになります。
deepspeed ds_test_qwen.py・推論の実行結果
[2025-09-05 14:40:27,841] [INFO] [real_accelerator.py:254:get_accelerator] Setting ds_accelerator to cuda (auto detect)
[2025-09-05 14:40:29,702] [INFO] [logging.py:107:log_dist] [Rank -1] [TorchCheckpointEngine] Initialized with serialization = False
[2025-09-05 14:40:30,350] [WARNING] [runner.py:220:fetch_hostfile] Unable to find hostfile, will proceed with training with local resources only.
[2025-09-05 14:40:30,350] [INFO] [runner.py:610:main] cmd = /usr/bin/python3 -u -m deepspeed.launcher.launch --world_info=eyJsb2NhbGhvc3QiOiBbMF19 --master_addr=127.0.0.1 --master_port=29500 --enable_each_rank_log=None ds_test_qwen.py
[2025-09-05 14:40:31,664] [INFO] [real_accelerator.py:254:get_accelerator] Setting ds_accelerator to cuda (auto detect)
[2025-09-05 14:40:33,354] [INFO] [logging.py:107:log_dist] [Rank -1] [TorchCheckpointEngine] Initialized with serialization = False
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████| 4/4 [00:00<00:00, 26.83it/s]
[2025-09-05 14:40:37,731] [INFO] [logging.py:107:log_dist] [Rank -1] DeepSpeed info: version=0.17.4, git-hash=unknown, git-branch=unknown
[2025-09-05 14:40:37,942] [INFO] [logging.py:107:log_dist] [Rank -1] [TorchCheckpointEngine] Initialized with serialization = False
[2025-09-05 14:40:37,942] [INFO] [logging.py:107:log_dist] [Rank -1] quantize_bits = 8 mlp_extra_grouping = False, quantize_groups = 1
こんにちは、自己紹介してください。また、どのような経緯でこのプロジェクトに関わることになったのでしょうか。
私は2016年に株式会社リクルートに入社し、現在はリクルートテクノロジーズのAIプラットフォーム開発部に所属しています。私の主な業務は、新規事業立ち上げや既存プロダクトの改善に向けたPoC(概念実証)やアジャイル開発の推進です。
このプロジェクトに関わるようになったのは、2021年1月頃に「リクルートグループ全体の
[2025-09-05 14:42:14,952] [INFO] [launch.py:351:main] Process 1062 exits successfully.最後から2行目に推論結果が表示されていることから、期待通りに動いたことが確認できます。
おわりに
今回は、分散処理の概要と、単一マシン・単一GPU環境でDeepSpeed(分散処理ツール)を動かすという、最もシンプルな例を紹介しました。
※環境構成はあくまで一例となります。
本格的な分散処理という観点では、tensor_parallelの値を変更(必要に応じて一部コードも修正)することで複数GPUでの実行が可能となります。
さらに、DeepSpeedの設定や実行コマンドを変更し(必要に応じて使用マシンにモデルやトークナイザーを配置することで)、複数マシンでの分散処理へと発展させることもできます。
興味のある方はぜひ調べて頂ければと思います。
最後に、複数マシンで行う分散処理では、実際に処理を行うGPUマシン(=ノード)だけでなく、マシン間をつなぐネットワークも重要となる点を述べておきます。
具体的には、RDMAを用いたロスレスネットワークでマシン間を接続することが望ましいとされています。
RDMAについて気になる方は、ぜひ以下の記事も参考にして頂ければと思います。
RDMAとは ~高速化技術とクラウド 第7回~ | NTTテクノクロスブログ
また、分散処理におけるNW観点は、光を活用して大容量・低遅延NWの実現を目指すIOWNともかかわりが深いといえます。
IOWNのAPN網を活用することで、1データセンサー内だけでなく、地理的に離れた複数のデータセンターを活用した処理も目指すことができます。(=分散DC)
NTTグループでは実際にIOWN APN網を用いた分散学習にも取り組んでいます。
IOWNによる分散学習(NTTドコモビジネス株式会社)
ここまでご覧いただき、ありがとうございました。
本記事、またはそれ以外の記事に関しての問い合わせやご意見がございましたら、以下にご連絡ください。
本件に関するお問い合わせ




[著者プロフィール]
フューチャーネットワーク事業部 第一ビジネスユニット
KONO HIROMASA
![]()