Hugging Faceライブラリで実行する推論と学習の基礎(後編) ~LLM活用 第11回~
本記事ではHugging Faceのライブラリを使った、ローカルモデルのファインチューニングの実行例を紹介します。




テクノロジーコラム
- 2025年10月09日公開
はじめに
こんにちは、NTTテクノクロスの佐藤・山口です。
前回はHugging Faceのライブラリを使ったコードの全体像の紹介と、モデルのダウンロードや推論の実行に関する紹介を行いました。
今回は、モデルの学習に関するコードの説明やコードを実際に動かした結果について紹介したいと思います。
本記事は前回の続きとなります。
必要に応じて前回も確認ください。
また、Hugging Faceとは?という方は第2回を参照ください。
● 目次
| 記事 | 節番号 | 節タイトル |
|---|---|---|
| 前回 (第10回) |
- | 今回紹介するコードの前提(使用するライブラリのバージョンなど)や、モデルのダウンロード・推論関数について |
| 今回 | 1 | [再掲] ソースコードの全体像について |
| 2 | 細部ポイント(学習関数) | |
| 3 | 実行例 |
[参考] 本連載の記事
本記事とあわせて、以下も良ければご確認ください。
| 連載番号 | タイトル | 概要 |
| 第1回 | 今だから知っておきたいDify!ノーコード・ローコードでLLM活用基盤を作ろう | Dify自体の説明とChatflow機能を使った例を取り上げています。 |
| 第2回 | 爆速キャッチアップ!LLM活用をリードするプラットフォーム群 | LLMの可能性をより広げるDify/Ollama/LangChain/Hugging Faceの紹介と、 DifyとOllamaでローカルLLMを活用したChatflow機能の利用に関して取り上げます。 |
| 第3回 | RAGとは?Difyから基本を学ぶ | RAGの基礎的な説明とDifyを使った実現方法を取り上げています。 |
| 第4回 | ローカルモデル利用のRAG実装で学ぶLangChainの基礎 | ベクトルDBを用いたRAGのサンプルコードから、LangChainの基礎を解説します。 |
| 第5回 | ローカルモデル利用のRAG実装で学ぶLlamaIndexの基礎 | ベクトルDBを用いたRAGのサンプルコードから、LlamaIndexの基礎を解説します。 |
| 第6回 | Difyで学ぶ、RAGの精度改善手法 | RAGの精度改善手法をDifyのChatflow機能を使いながら紹介します。 |
| 第7回 | ローカル環境で実現する、GraphRAGの基礎 | GraphRAGの基礎から、LangChainとNeo4jを使ったグラフRAGの実装例を紹介します。 |
| 第8回 | ローカル環境で実現する、Text-To-SQLとRDBを用いたRAG | Text-To-SQLと、それを活用したRDBを用いたRAGの実装例を紹介します。 |
| 第9回 | ファインチューニングとは?基礎を理解する | ファインチューニングとそのユースケース、手法を紹介します。 |
| 第10回 | Hugging Faceライブラリで実行する推論と学習の基礎(前編) | Hugging Faceのライブラリを使った、モデルのダウンロードや推論処理について紹介します。 |
| 第11回 | Hugging Faceライブラリで実行する推論と学習の基礎(後編) | Hugging Faceのライブラリを使った、ローカルモデルの学習処理と実行例について紹介します。 |
| 第12回 | AIエージェントとは?Difyから考え方を学ぶ | AIエージェントについて、Difyでの動作イメージも含めて紹介します。 |
| 第13回 | MCPとは?AIエージェントの可能性を広げよう | AIエージェントの可能性を広げる技術であるMCPについて紹介します。 |
Hugging Faceのライブラリを使った推論・学習の実行例について
今回は学習関数に関する紹介を行います。
モデルのダウンロード関数や推論関数については前回を確認ください。
[再掲] 実装例のソースコード全文と全体の構成について
前回にもコードの全文や全体構成は載せていますが、改めて記載します。
● コードの全文
# 標準ライブラリ
import argparse
from glob import glob
import os
import torch
from pathlib import Path
# Hugging Face関連ライブラリ
from huggingface_hub import snapshot_download
from transformers import (
AutoTokenizer,
AutoModelForCausalLM,
TrainingArguments,
Trainer,
DataCollatorForLanguageModeling,
EarlyStoppingCallback,
set_seed,
)
from datasets import load_dataset
# 各種オプションの指定
MODEL_NAME = "google/gemma-3-1b-it"
DATASET_NAME = "bbz662bbz/databricks-dolly-15k-ja-gozaru"
LOCAL_DIR = "./models/gemma-3-1b-it"
DATA_DIR="./data/"
OUTPUT_DIR = "./output_gemma"
MAX_LEN = 1024
SEED = 42
# モデル・データセットのローカルダウンロード関数
def run_download():
HF_TOKEN = os.getenv("HUGGING_FACE_HUB_TOKEN")
if not Path(LOCAL_DIR,"config.json").exists():
print("モデルのダウンロードを開始します。")
snapshot_download(repo_id=MODEL_NAME, local_dir=LOCAL_DIR, token=HF_TOKEN,)
print("モデルのダウンロードが完了しました。")
else:
print("既にモデルがダウンロード済の可能性があります。")
if not any(Path(DATA_DIR).rglob("*.json")):
print("データセットのダウンロードを開始します。")
snapshot_download(repo_id=DATASET_NAME, repo_type="dataset", local_dir=DATA_DIR, token=HF_TOKEN,)
print("データセットのダウンロードが完了しました。")
else:
print("既にデータセットがダウンロード済の可能性があります。")
# pad_token_idとeos_token_idの重複回避用関数
def token_valid(tokenizer, model):
print("特殊トークンに関するチェックを開始します。")
# pad_tokenが無い or eos_tokenと同じなら、専用pad_tokenを追加
if (tokenizer.pad_token_id is None) or (tokenizer.pad_token_id == tokenizer.eos_token_id):
print("特殊トークンの追加対応を行います。")
tokenizer.add_special_tokens({"pad_token": "<|pad|>"})
# モデル埋め込みを新語彙サイズに合わせる(新しいPADトークンを追加して語彙が増えた場合は必須)
model.resize_token_embeddings(len(tokenizer))
# トークナイザーとモデルのコンフィグの値整合
model.config.pad_token_id = tokenizer.pad_token_id
if hasattr(model, "generation_config"):
model.generation_config.pad_token_id = tokenizer.pad_token_id
print("特殊トークンに関するチェックが完了しました。")
# データセットから空文字などを除去する関数
def data_valid(data):
ins = data.get("instruction", None)
res = data.get("output", None)
return (ins is not None and res is not None and str(ins).strip() and str(res).strip())
# 学習用関数
def run_train(model_path: str):
set_seed(SEED)
# モデル利用の為の準備
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(model_path,attn_implementation='eager',torch_dtype='auto',)
model.config.use_cache = False
token_valid(tokenizer, model)
# データセット読込み
files = sorted(
glob(os.path.join(DATA_DIR, "*.json"))
)
if not files:
raise FileNotFoundError(f"{DATA_DIR}にデータセットがありません。ローカルにダウンロードできていない可能性があります。 ")
dataset = load_dataset("json", data_files=files, split="train")
keep_cols = ["instruction", "output"]
dataset = dataset.select_columns([c for c in keep_cols if c in dataset.column_names])
dataset = dataset.filter(data_valid)
# 学習(train)と検証(test)データを9:1に分割
splits = dataset.train_test_split(test_size=0.1, seed=SEED)
train_ds = splits["train"]
eval_ds = splits["test"]
# トークナイズ及び学習に向けたデータフォーマット
def tokenize_fmt(ex):
messages = [
{"role": "system", "content": [{"type":"text","text":"You are a helpful Japanese assistant."}]},
{"role": "user", "content": [{"type":"text","text": ex["instruction"]}]},
{"role": "assistant","content":[{"type":"text","text": ex["output"]}]},
]
text = tokenizer.apply_chat_template(messages, add_generation_prompt=False, tokenize=False,)
return tokenizer(text, max_length=MAX_LEN, truncation=True, padding=False,)
# トークナイズ
train_tok = train_ds.map(tokenize_fmt, batched=False, remove_columns=train_ds.column_names)
eval_tok = eval_ds.map(tokenize_fmt, batched=False, remove_columns=eval_ds.column_names)
# Collator
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False)
# チューニング用のハイパーパラメータ指定
args = TrainingArguments(
output_dir=OUTPUT_DIR,
learning_rate=8e-6,
per_device_train_batch_size=2,
per_device_eval_batch_size=2,
gradient_accumulation_steps=4,
num_train_epochs=5,
eval_strategy="steps",
eval_steps=1000,
save_strategy="steps",
save_steps=1000,
save_total_limit=5,
load_best_model_at_end=True,
metric_for_best_model="eval_loss",
greater_is_better=False,
fp16=False,
bf16=True,
seed=SEED,
gradient_checkpointing=True,
report_to="none",
)
trainer = Trainer(
model=model,
args=args,
train_dataset=train_tok,
eval_dataset=eval_tok,
data_collator=data_collator,
tokenizer=tokenizer,
callbacks=[EarlyStoppingCallback(early_stopping_patience=3, early_stopping_threshold=0.0)],
)
# 学習実行
trainer.train()
# 学習済モデルの保存
trainer.save_model(OUTPUT_DIR)
tokenizer.save_pretrained(OUTPUT_DIR)
# 推論実行用関数
def run_infer(model_path: str, user_prompt: str):
# モデルを使う為の初期設定
tokenizer = AutoTokenizer.from_pretrained(model_path, local_files_only=True)
model= AutoModelForCausalLM.from_pretrained(
model_path,
local_files_only=True,
attn_implementation="eager",
torch_dtype=torch.float32,
).to("cpu").eval()
# 受け取った質問をセット
messages = [
{"role": "system", "content": [{"type": "text", "text": "You are a helpful Japanese assistant."}]},
{"role": "user", "content": [{"type": "text", "text": user_prompt}]},
]
# 質問文をトークン化
inputs = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
tokenize=True,
return_dict=True,
return_tensors="pt",
)
# 推論実行
with torch.inference_mode():
output = model.generate(**inputs, max_new_tokens=128, temperature=0.1, do_sample=True, )
print(tokenizer.batch_decode(output, skip_special_tokens=True)[0] )
def main():
parser = argparse.ArgumentParser()
sub = parser.add_subparsers(dest="mode", required=True)
tr = sub.add_parser("train", help="学習の実行")
tr.add_argument("--model", required=True, help="モデルをダウンロードしたローカルパスを指定する")
inf = sub.add_parser("infer", help="推論の実行")
inf.add_argument("--prompt", required=True, help="質問文(プロンプト)")
inf.add_argument("--model", default=OUTPUT_DIR, help=f"推論に使うモデル(省略時は学習したモデル指定: {OUTPUT_DIR})")
sub.add_parser("download", help="モデルをローカルにダウンロードする")
args = parser.parse_args()
if args.mode == "download":
run_download()
elif args.mode == "train":
run_train(args.model)
else:
run_infer(args.model, args.prompt)
if __name__ == "__main__":
main()
● コードの全体構造
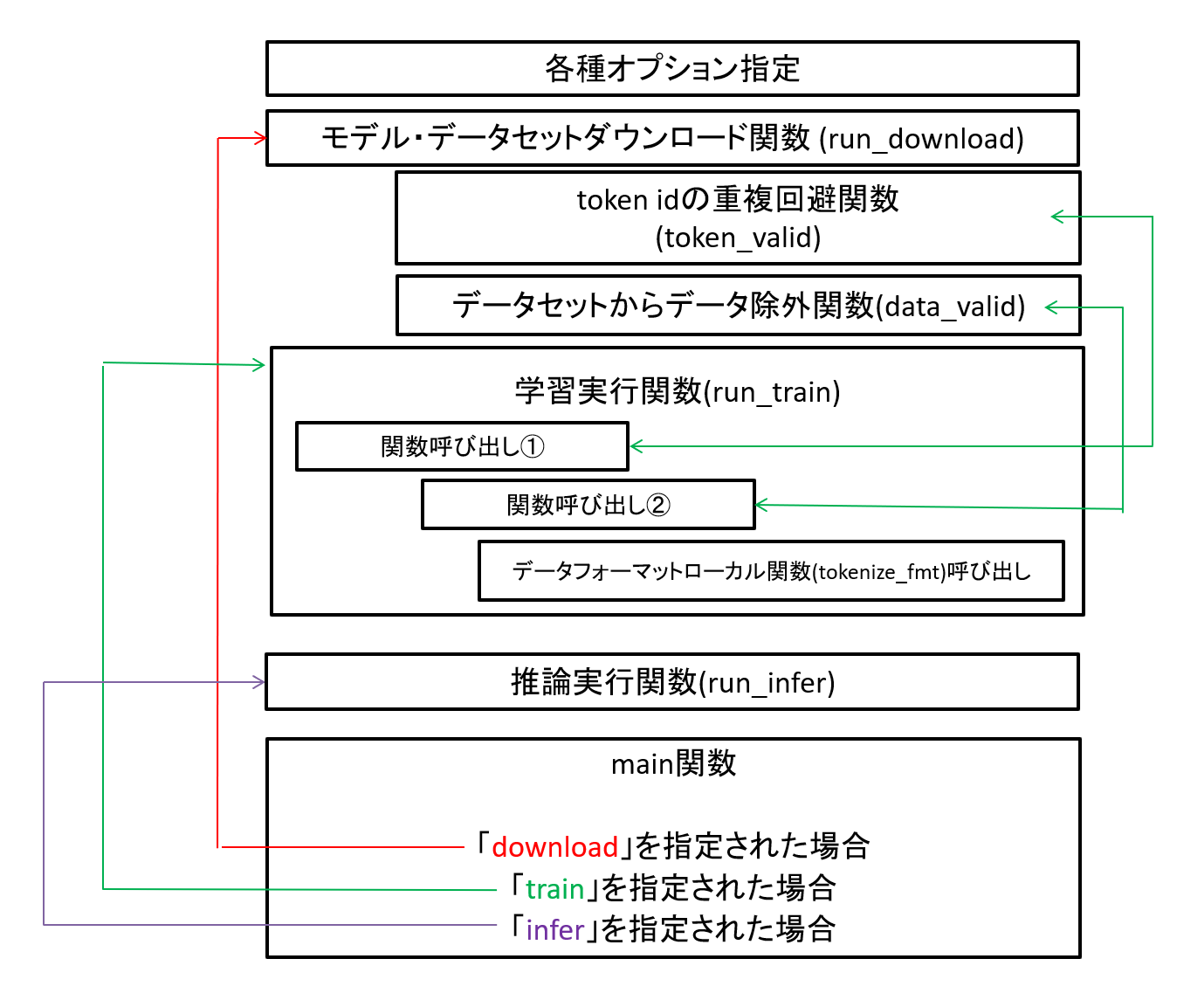
図1 サンプルコードの構成
細部のポイントについて
まずは、学習関数(run_train関数)について紹介します。
学習は大きく以下のような流れで処理を進めています。
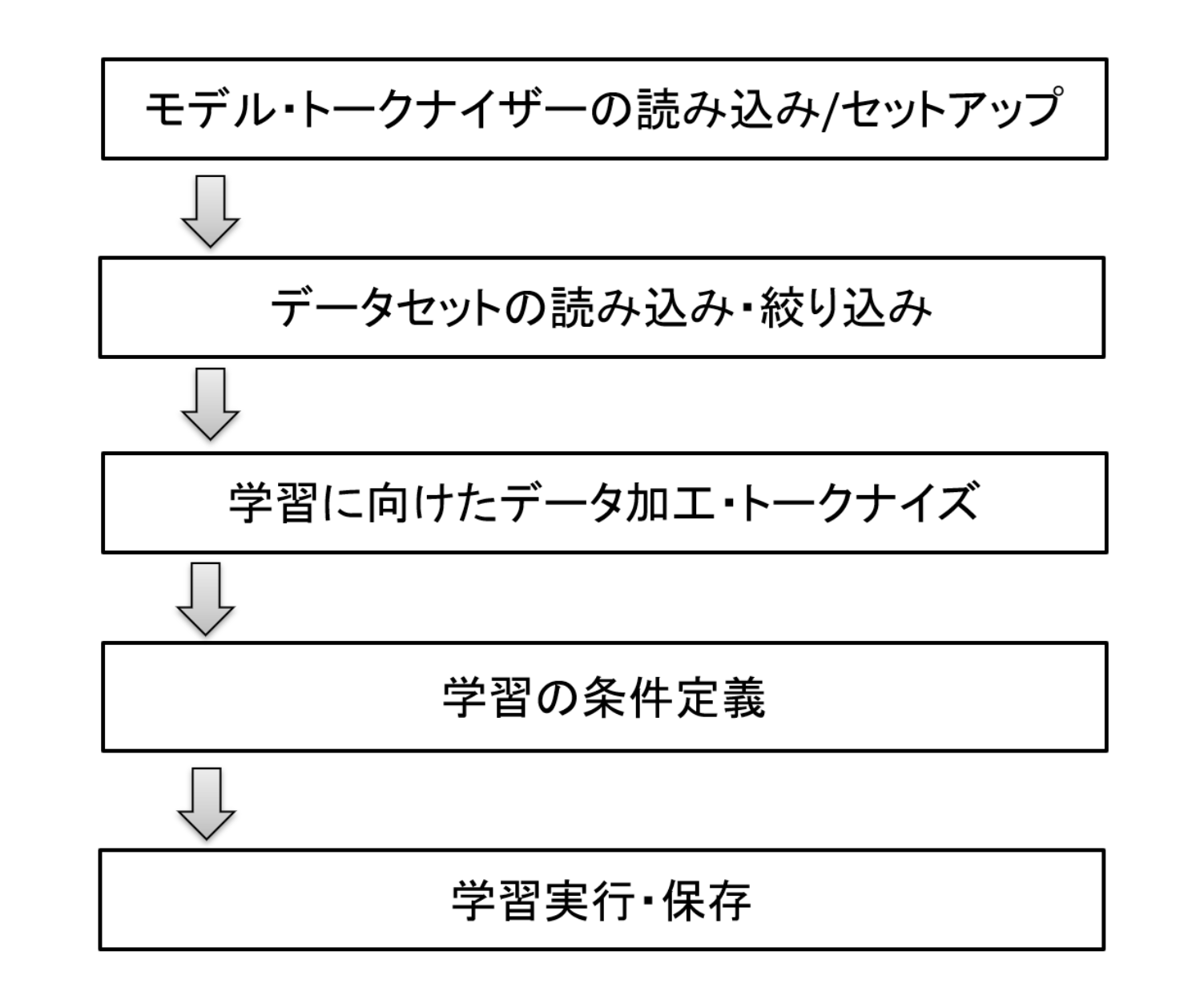
図2 学習関数の処理の流れ
では、1つずつポイントを見ていきましょう。
from transformers import set_seed
def run_train(model_path: str):
set_seed(SEED)
## トークナイザー、モデル読込は推論関数と同様のため、略 ##
model.config.use_cache = False
学習関数もmain関数から呼び出され、その際に対象となるモデルのパスを渡される想定です。
これにより、Hugging Faceからダウンロードしたモデルだけでなく、ファインチューニング済のモデルに追加学習をかける事も可能なつくりとしています。
学習にはランダム要素がある為、同じデータセットで実施しても結果が変わる場合があります。
よってなるべく再現性を上げるべくset_seedでシード値を指定しています。
また、model.config.use_cacheをFalseとしていますが、これは学習時に使用するメモリ量を減らす効果があります。
LLMを扱う上では、GPUメモリ(VRAM)が極めて重要なリソースであり、これが足りないと「OutOfMemory」エラーが発生して学習ができない場合があります。
上のような状態を避ける為、GPUメモリを減らす為の工夫をしているとみて頂ければ、と思います。
def run_train(model_path: str):
token_valid(tokenizer, model)
def token_valid(tokenizer, model):
print("特殊トークンに関するチェックを開始します。")
# pad_tokenが無い or eos_tokenと同じなら、専用pad_tokenを追加
if (tokenizer.pad_token_id is None) or (tokenizer.pad_token_id == tokenizer.eos_token_id):
print("特殊トークンの追加対応を行います。")
tokenizer.add_special_tokens({"pad_token": "<|pad|>"})
# モデル埋め込みを新語彙サイズに合わせる(新しいPADトークンを追加して語彙が増えた場合は必須)
model.resize_token_embeddings(len(tokenizer))
# トークナイザーとモデルのコンフィグの値整合
model.config.pad_token_id = tokenizer.pad_token_id
if hasattr(model, "generation_config"):
model.generation_config.pad_token_id = tokenizer.pad_token_id
print("特殊トークンに関するチェックが完了しました。")
次に、自作関数(token_valid)を呼び出して、特殊トークンに関する処理を行っています。
推論関数の説明(前回)でも少し触れましたが、モデルに渡すデータには以下のような特殊な文字が入ることがあります。
| 特殊文字の代表例 | 説明 |
|---|---|
| <bos> | 生成する文字の開始時点。 |
| <eos> | 生成する文字の終了時点。 |
| <pad> | 学習時にデータの長さを揃える為のパディング文字。 |
上記で触れたのは一部ですが、文章を理解する上で極めて重要な意味合いを持っている事がわかるかと思います。
利用するモデルによっては<pad>文字(pad_token)が未定義であったり、<pad>(pad_token)と<eos>(eos_token)が同じとなっている場合もありえます。
そこで自作関数で上記に該当する場合は、別々の文字列とする処理を入れています。
ちなみに、今回使うトークナイザーは最初から<pad>も<eos>も別文字で設定されています(※)。
その為、今回チューニングをするモデルにおいては不要な処理ですが、特殊文字について理解する上で重要な為、取り入れています。
※ 確認方法は以下の通りです。
print(tokenizer.all_special_tokens)
['<bos>', '<eos>', '<unk>', '<pad>', '<start_of_image>', '<end_of_image>', '<image_soft_token>']
次はデータセットの読み込みに関する処理です。
一般的にデータセットの読み込みや学習用に整える処理は別関数とすることも多いですが、今回は構成をシンプル化する為、学習関数内にまとめています。
from datasets import load_dataset
def run_train(model_path: str):
files = sorted(
glob(os.path.join(DATA_DIR, "*.json"))
)
if not files:
raise FileNotFoundError(f"{DATA_DIR}にデータセットがありません。ローカルにダウンロードできていない可能性があります。 ")
dataset = load_dataset("json", data_files=files, split="train")
keep_cols = ["instruction", "output"]
dataset = dataset.select_columns([c for c in keep_cols if c in dataset.column_names])
dataset = dataset.filter(data_valid)
def data_valid(data):
ins = data.get("instruction", None)
res = data.get("output", None)
return (ins is not None and res is not None and str(ins).strip() and str(res).strip())
データセットはdownload関数にて、ローカル(DATA_DIR)にダウンロードしているはずの為、該当ディレクトリからjsonファイルを読み取っています。
読み取るファイルがなかった場合にはエラーとし、ファイルが存在した場合にはロードした上で必要な列のみに絞り込ます。
絞り込む前(元々)のデータセット(databricks-dolly-15k-ja-gozaru)は5列ありますが、今回は「ユーザの質問」と「回答」のセットを覚えさせたい為、instructionとoutput列を残すように処理をします。
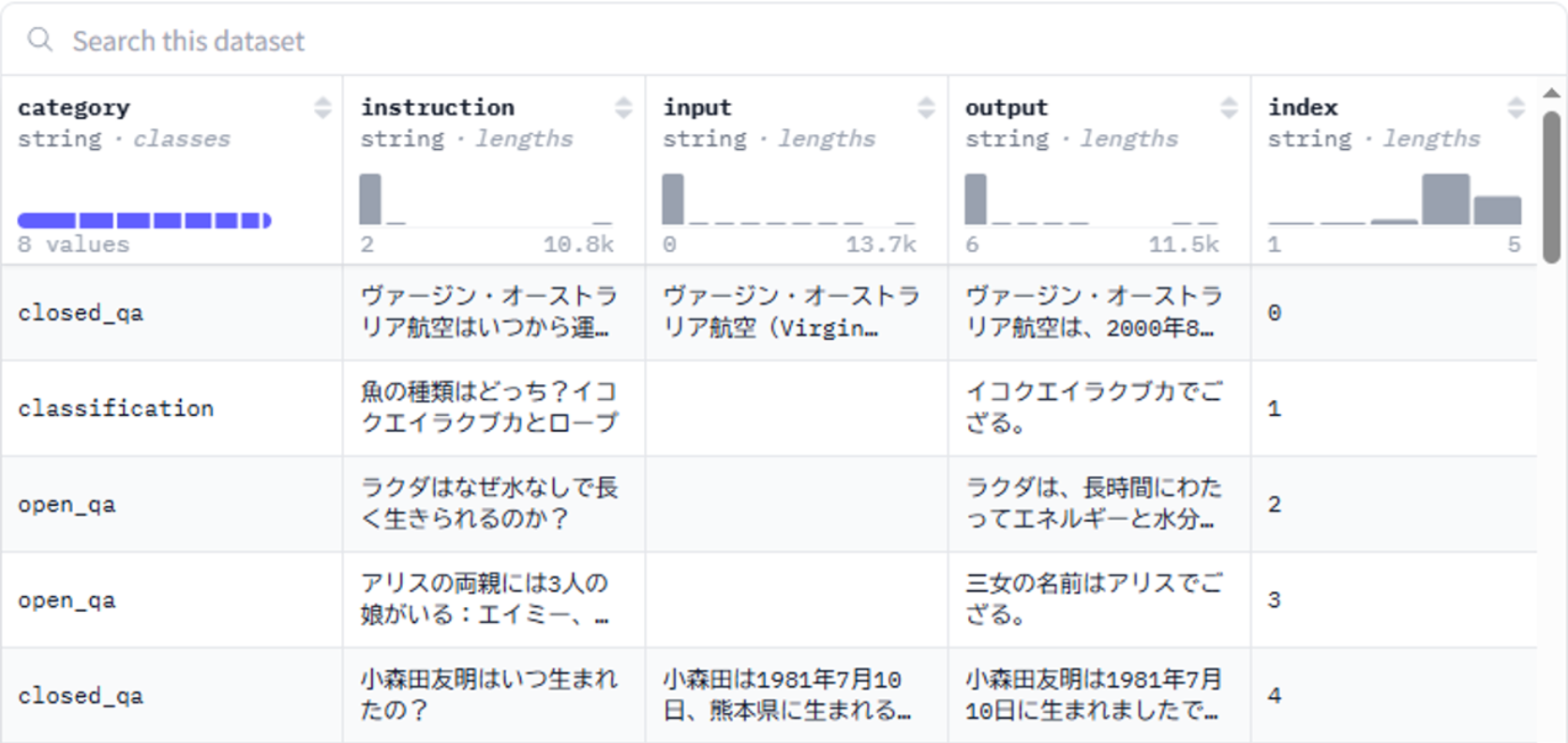
図3 データセットの構成
( 参考: Hugging Face
https://huggingface.co/datasets/bbz662bbz/databricks-dolly-15k-ja-gozaru/viewer/default/train?views[]=train )
その後、「data_valid」自作関数を呼び出し、instructionとoutput列が空だったり半角スペースしかないような、学習させる際に不都合となる行を除外・フィルタリングします。
splits = dataset.train_test_split(test_size=0.1, seed=SEED)
train_ds = splits["train"]
eval_ds = splits["test"]
学習時には、覚えさせる学習データ(train_ds=9割)と、学習の中で適切に学習できているか確認を行う為の検証データ(eval_ds=1割)の2つを用意しておくことが理想です。
よって、上のコードでフィルタリングして残ったデータセットを、9:1に分割して、2つのデータセットを用意しています。
※ 実務では、学習した後に効果・精度を見るために使う評価データもデータセットから抜き出すこともあります。
これらのデータの目的・使い方は後述の「実行例」節にて説明したいと思います。
def run_train(model_path: str):
train_tok = train_ds.map(tokenize_fmt, batched=False, remove_columns=train_ds.column_names)
eval_tok = eval_ds.map(tokenize_fmt, batched=False, remove_columns=eval_ds.column_names)
def tokenize_fmt(ex):
messages = [
{"role": "system", "content": [{"type":"text","text":"You are a helpful Japanese assistant."}]},
{"role": "user", "content": [{"type":"text","text": ex["instruction"]}]},
{"role": "assistant","content":[{"type":"text","text": ex["output"]}]},
]
text = tokenizer.apply_chat_template(messages, add_generation_prompt=False, tokenize=False,)
return tokenizer(text, max_length=MAX_LEN, truncation=True, padding=False,))
上の処理は、まず内部関数(tokenize_fmt)を呼び出して、用意したデータセットを整形しつつトークナイズし、remove_columnsオプション指定により元のinstruction・output列を削除して、tokenize_fmt関数が返したトークナイズ済の列のみ残しています。
推論時には「apply_chat_template」を使う事から、学習時も同じ形式で覚えさせた方が良いでしょう。
したがって、呼び出されたtokenize_fmt関数内では、渡されたデータセットをmessages形式としています。
推論関数と比較し、roleに「assistant」が増えていますが、これはAIの回答を想定した枠となります。
return文のタイミングでトークナイズをかけていますが、この際にtruncationオプション有効化によりMAX_LENで指定した値を超える長い入力を切り詰めています。
| [補足] apply_chat_templateを使わない場合と、今回の学習方法について 「apply_chat_template」を使わない場合(事前学習済モデルをチューニングする場合)のtokenize_fmt関数の例を以下に記載します。 messages形式ではなく、自前で学習データを整形しています。 上の整形からもわかるように、今回は「ユーザの質問(instruction)+回答(output)」をまとめて学習させています。 別のアプローチとしては、「ユーザの質問」を見つつ、「回答」だけ出力が変わるように学習させる方法もあります。 |
|---|
次はDataCollatorを定義します。
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False)
DataCollatorは、学習用のデータをモデルに渡す際の梱包係と言われます。
例えばデータ長がバラバラなデータをパディングすることで同じ長さにしたり、パディングした箇所と元からあった場所の対応表(attention_mask)を用意した上で、パディング箇所を学習対象外とする印を付与します。
こうすることで、GPUで計算をしやすくしつつ、パディングが学習に影響を与えないようにすることができます。
なお、MLMはトランスフォーマーモデルにおけるEncoderに関連した処理となります。
今回使うGemma3はDecoder-Only型のモデルであり、MLMは不要の為、Falseとしています。
ここからはハイパーパラメータ(学習の進め方などを決めるための設定項目、以降ハイパラと記載)指定です。
args = TrainingArguments(
output_dir=OUTPUT_DIR,
learning_rate=8e-6,
per_device_train_batch_size=2,
per_device_eval_batch_size=2,
gradient_accumulation_steps=4,
num_train_epochs=5,
eval_strategy="steps",
eval_steps=1000,
save_strategy="steps",
save_steps=1000,
save_total_limit=3,
load_best_model_at_end=True,
metric_for_best_model="eval_loss",
greater_is_better=False,
fp16=False,
bf16=True,
seed=SEED,
gradient_checkpointing=True,
report_to="none",
)
各ハイパラの意味は以下の通りとなります。
| ハイパラ | 説明 |
|---|---|
| output_dir |
学習後にできたモデルをどこに配置するか。 save_stepsで保存された途中経過モデルも格納される。 |
| learning_rate |
学習率。学習の効きの大きさ。 指数表記法で指定する。 今回指定した「8e-6」は「0.000008」という意味。 |
|
per_device_train_batch_size per_device_eval_batch_size |
学習データ or 検証データを処理する際に、まとめて処理する数。(バッチ数) |
| gradient_accumulation_steps | 学習効果の適用を、指定したステップ分貯めてから実施する。 |
| num_train_epochs | データセットを何周、学習でまわすか。 |
|
eval_strategy save_strategy |
検証・途中経過の保存をどのタイミングで行うかの大方針。 一定step処理が進んだら行うか、一定epoch進んだら行うか。 |
|
eval_steps save_steps |
strategyにstepを指定した場合に規定する。 指定したstep分、処理が進んだら検証 or 途中経過保存を行う。 evalとsaveは同じ値推奨。 |
| save_total_limit |
途中経過として保存するトータルの数を最大いくつとするか。 上限に達すると、古いものから新しいもので上書きされる。 |
| load_best_model_at_end | 学習終了時にmetric_for_best_modelで指定した条件でベストと判定したモデルを最終成果物とする。 |
| metric_for_best_model | 指定した指標で、ベストのモデルと評価する。 |
| greater_is_better |
metric_for_best_modelで指定した値は小さい方が良いか、大きい方が良いのかを指定。 今回指定したeval_lossは小さい方が良い為、False指定とする。 |
|
fp16 bf16 |
利用するGPUにより依存する。 両方をTrueにしないこと。 |
| seed | 乱数固定用。 |
| gradient_checkpointing | メモリを節約する指定。 |
| report_to |
外部ツール(WandBやtensorboard)に学習結果を共有する or しない。 今回はしない指定。 |
使用するハイパラも、今回は代表的な物に絞って指定していますが、それでも初見だと多いと感じるのではないでしょうか。
他にも学習に関するハイパラには様々なものがあり、実際にチューニングを試す際に用途や目的に応じて変えていきます。
したがって精度向上に向けた活動としては、「学習させるデータ」の見直し以外にもハイパラの改善も対象となり得ます。
※ ただし、基本的には「学習させるデータ」の見直しのほうがモデルの精度に与える影響は大きいです。
| [参考] WandBやtensorboardについて ハイパラの1つである「report_to」に関連するWandBやtensorboardについて気になる方は以下をあわせて参照ください。 https://speakerdeck.com/yamaguchi_tx/llmnoji-chu-tollmhuo-yong-niguan-lian-sitazhu-ming-naturunoshao-jie?slide=29 |
|---|
trainer = Trainer(
model=model,
args=args,
train_dataset=train_tok,
eval_dataset=eval_tok,
data_collator=data_collator,
tokenizer=tokenizer,
callbacks=[EarlyStoppingCallback(early_stopping_patience=3, early_stopping_threshold=0.0)],
)
最後にこれまで定義してきた情報を指定して、学習条件を指定します。
具体的には「利用するモデル(model)」「ハイパラ(args)」「学習用のトークナイズしたデータ(train_tok)」「検証用のトークナイズしたデータ(eval_tok)」「使用するDataCollator(data_collator)」「使用するトークナイザー(tokenizer)」を、1つの学習として紐づけています。
最後のcallbacksでは「EarlyStopping」という仕組みを有効化しています。
これはハイパラのmetric_for_best_modelで指定した値で、学習により精度の改善が見られない場合に学習を止める、という仕組みです。
そもそも学習は、実施すれば常によくなるわけではなく、横ばいとなり伸び悩んだり悪化する場合もあります。
EarlyStoppingを入れない場合、学習の良し悪しにかかわらず、ハイパラで指定した分だけ最後まで学習を続けます。
今回はearly_stopping_patienceで3を指定している為、3回悪化したら(eval_lossの値が3回、前のタイミングより悪化したら)学習打ち止めとする指定です。
# 学習実行
trainer.train()
# 学習済モデルの保存
trainer.save_model(OUTPUT_DIR)
tokenizer.save_pretrained(OUTPUT_DIR)
最後に学習を実行し、その後に学習完了時のモデルとトークナイザーを指定ディレクトリ(OUTPUT_DIR)に保存しています。
実行例
ここからは紹介したコードの実行例について触れていきます。
まずはモデルのダウンロードを行います。
### アクセストークン設定
export HUGGING_FACE_HUB_TOKEN="Hugging Faceのアクセストークン指定"
### ダウンロード実行
python train_infer.py download
### 実行結果
モデルのダウンロードを開始します。
Fetching 10 files: 0% 0/10 [00:00<?, ?it/s]
generation_config.json: 100% 215/215 [00:00<00:00, 1.68MB/s]
README.md: 100% 24.3k/24.3k [00:00<00:00, 70.9MB/s]
special_tokens_map.json: 100% 662/662 [00:00<00:00, 6.60MB/s]
added_tokens.json: 100% 35.0/35.0 [00:00<00:00, 408kB/s]
.gitattributes: 100% 1.68k/1.68k [00:00<00:00, 18.6MB/s]
config.json: 100% 899/899 [00:00<00:00, 11.4MB/s]
tokenizer.json: 100% 33.4M/33.4M [00:01<00:00, 26.0MB/s]
tokenizer_config.json: 100% 1.16M/1.16M [00:00<00:00, 1.30MB/s]
tokenizer.model: 100% 4.69M/4.69M [00:01<00:00, 3.67MB/s]
model.safetensors: 100% 2.00G/2.00G [00:15<00:00, 126MB/s]
Fetching 10 files: 100% 10/10 [00:16<00:00, 1.64s/it]
モデルのダウンロードが完了しました。
データセットのダウンロードを開始します。
Fetching 3 files: 0% 0/3 [00:00<?, ?it/s]
.gitattributes: 2.34kB [00:00, 6.42MB/s]
README.md: 100% 290/290 [00:00<00:00, 3.31MB/s]
databricks-dolly-15k-ja-gozaru.json: 100% 17.5M/17.5M [00:01<00:00, 12.5MB/s]
Fetching 3 files: 100% 3/3 [00:02<00:00, 1.48it/s]
データセットのダウンロードが完了しました。
モデルのダウンロードには、Gemma3が利用可能なHugging Faceアカウントのトークンが必要で、かつ環境変数に指定しておく必要がある為、Pythonツール実行前に忘れずにexportしておきましょう。
Pythonツールにてdownloadモードで実行をかけた結果が3行目以降の表示です。
実行結果は大きく10個のファイルを落としてきているまとまりと、3つのファイルを落としているまとまりがありますが、前者がモデルのダウンロード、後者がデータセットのダウンロードのログです。
問題なくダウンロード出来たら、まずはダウンロードしてきたモデル(ファインチューニング前のモデル)に対して、推論を実行してみましょう。
3回トライしてみました。
### 推論実行
python train_infer.py infer --model ./models/gemma-3-1b-it --prompt "日本の首都について教えてください。"
### 結果
user
You are a helpful Japanese assistant.
日本の首都について教えてください。
model
はい、日本の首都は**東京 (Tokyo)** です。
東京は、日本の中心地であり、経済、文化、ビジネスの中心地です。
以下に、東京に関するいくつかの情報をお伝えしますね。
* **人口:** 約1400万人
* **面積:** 約2,194平方キロメートル
* **気候:** 温暖で、四季がはっきりしています。夏は暑く、冬は比較的温暖です。
* **主要な観光地:**
* **浅草寺 (Senso-ji Temple):** 日本最古の寺
### 推論実行
python train_infer.py infer --model ./models/gemma-3-1b-it --prompt "日本の首都について教えてください。"
### 結果
user
You are a helpful Japanese assistant.
日本の首都について教えてください。
model
はい、日本の首都は**東京 (Tokyo)** です。
東京は、日本の中心地であり、経済、文化、ビジネスの中心地です。
**東京の主な特徴:**
* **人口:** 約1400万人
* **地形:** 港湾都市で、山々に囲まれています。
* **文化:** 伝統的な日本の文化と、現代的な文化が融合しています。
* **観光名所:** 浅草寺、渋谷、新宿、銀座など、世界的に有名な観光スポットがたくさんあります。
* **経済:** 日本最大の経済拠点です。
### 推論実行
python train_infer.py infer --model ./models/gemma-3-1b-it --prompt "日本の首都について教えてください。"
### 結果
user
You are a helpful Japanese assistant.
日本の首都について教えてください。
model
はい、日本の首都は**東京 (Tokyo)** です。
東京は、日本の中心地であり、経済、文化、ビジネスの中心地です。
**東京の主な特徴:**
* **人口:** 約1400万人
* **地理:** 日本の東部に位置し、河川の豊富さや、山々に囲まれています。
* **経済:** 日本最大の経済拠点であり、テクノロジー、金融、製造業などが盛んです。
* **文化:** 伝統的な文化と現代的な文化が融合しており、世界的に有名な美術館や博物館、伝統的な祭りなどがあります
多少回答にブレはありますが、問題なく回答できています。
確認すべきポイントは語尾が「ござる」ではなく、普通の「ですます調」である点です。
| [参考] 推論の結果出力について 上の推論結果表示では、質問文と回答文をあわせて出力しています。 以下のようなコードとすると、回答文のみを出力できます。 |
|---|
ここまで確認できたら、推論時に「ござる」口調になるようにチューニングをかけてみましょう。
### 実行
python train_infer.py train --model ./models/gemma-3-1b-it
### ログ(一部抜粋)
特殊トークンに関するチェックを開始します。
特殊トークンに関するチェックが完了しました。
trainer = Trainer(
{'loss': 2.2501, 'grad_norm': 15.375, 'learning_rate': 7.527573964497041e-06, 'epoch': 0.3}
{'loss': 2.1066, 'grad_norm': 13.0625, 'learning_rate': 7.054201183431952e-06, 'epoch': 0.59}
12% 1000/8450 [17:08<2:07:08, 1.02s/it]
・・・
{'eval_loss': 2.0128183364868164, 'eval_runtime': 50.0456, 'eval_samples_per_second': 30.013, 'eval_steps_per_second': 15.006, 'epoch': 0.59}
12% 1000/8450 [17:58<2:07:08, 1.02s/it]
100% 751/751 [00:49<00:00, 14.69it/s]
{'loss': 2.0631, 'grad_norm': 13.8125, 'learning_rate': 6.580828402366864e-06, 'epoch': 0.89}
{'loss': 1.9899, 'grad_norm': 16.75, 'learning_rate': 6.107455621301775e-06, 'epoch': 1.18}
・・・
{'eval_loss': 1.9597817659378052, 'eval_runtime': 50.1813, 'eval_samples_per_second': 29.931, 'eval_steps_per_second': 14.966, 'epoch': 4.14}
83% 7000/8450 [2:07:57<24:47, 1.03s/it]
100% 751/751 [00:50<00:00, 14.68it/s]
{'loss': 1.8862, 'grad_norm': 9.5, 'learning_rate': 9.003550295857988e-07, 'epoch': 4.44}
{'loss': 1.905, 'grad_norm': 13.8125, 'learning_rate': 4.2698224852071004e-07, 'epoch': 4.73}
・・・
{'eval_loss': 1.9597229957580566, 'eval_runtime': 49.8546, 'eval_samples_per_second': 30.128, 'eval_steps_per_second': 15.064, 'epoch': 4.73}
95% 8000/8450 [2:26:18<07:43, 1.03s/it]
100% 751/751 [00:49<00:00, 14.30it/s]
100% 8450/8450 [2:34:25<00:00, 1.26it/s]There were missing keys in the checkpoint model loaded: ['lm_head.weight'].
{'train_runtime': 9287.1146, 'train_samples_per_second': 7.275, 'train_steps_per_second': 0.91, 'train_loss': 1.9636277491101146, 'epoch': 5.0}
100% 8450/8450 [2:34:47<00:00, 1.10s/it]
結果のログは一部抜粋としていますが、特殊トークンに関するチェック(token_valid関数)で追加処理は行われなかった事がわかります。
また、学習に関しては「学習ステップ数」が8450, 学習が1000Step進むごとに行う検証データでの評価が751ステップあることがわかります。
ログからは進捗の他、最後のログにて8450まで走り切っている為、EarlyStoppingは発生しなかった事も読み取れます。
精度についてはまずはloss値を見るとと良いでしょう。
loss値は簡単にいえば理想とどれだけ近いかを示す値で、0によるほど、理想に近い結果になっていることを示します。
ログをみるとloss値には「loss」と「eval_loss」の2種類がありますが、前者は学習データでみたloss値、eval_lossは検証データで見たloss値となります。
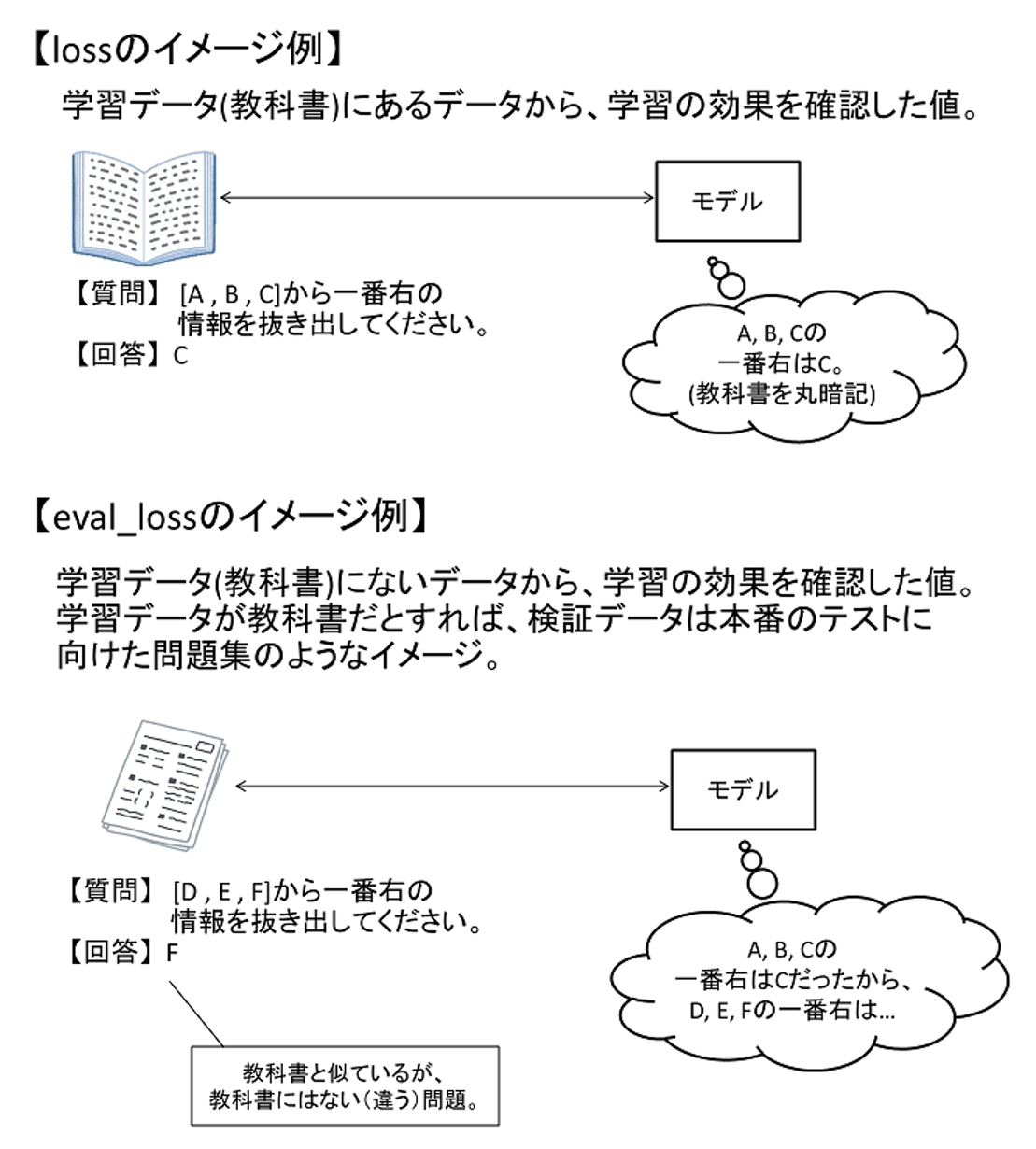
図4 loss値について
シンプルなloss値は、学習で使ったデータをそのまま暗記するだけで理想の状態と判定される為、学習データに過剰にフィッティングしてしまい(=過学習している)、柔軟性を失っている場合に気づく事が難しくなります。
その為、学習データに含めていないデータでloss値をみるeval_lossの値が特に重要な値と考えることができます。
| [参考] 過学習の傾向はどうみる? lossとeval_lossを組み合わせることで過学習に気づきやすくなります。 例えばlossは下がり続けているが、eval_lossは上がり始めている、といった場合には過学習の傾向と見て取れるでしょう。 |
|---|
今回の学習のeval_lossの値は以下となりました。
値が下がっている=学習の効果が出ていることが見て取れるかと思います。
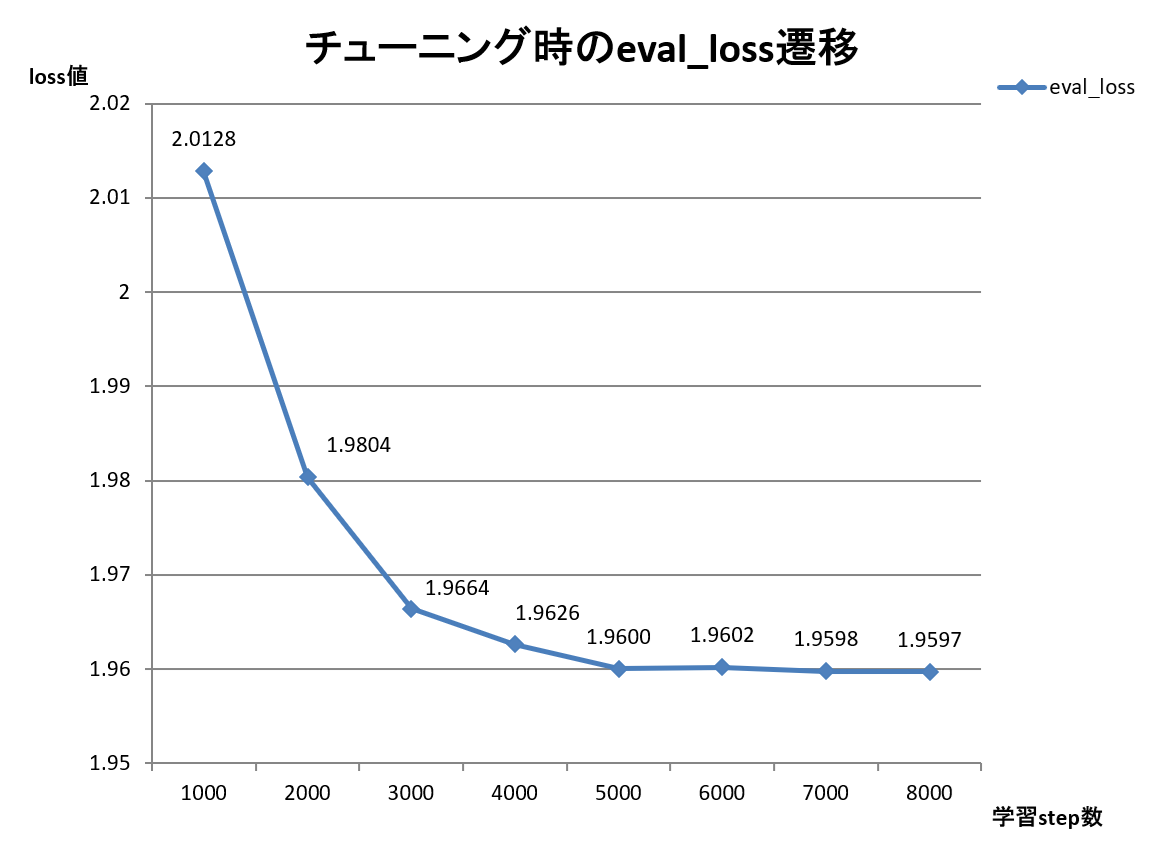
図5 学習効果(eval_loss)の遷移
ちなみにチューニング完了後は以下のようになっており、OUTPUT_DIR配下に「checkpoint_[Step数]」という名前で途中経過が保存されています。
参考までに今回のチューニング完了後のフォルダ構成を以下に記載します。
output_gemma (OUTPUT_DIR)
├─ checkpoint-7000
│ └─ チェックポイント時のモデル関連資材
├─ checkpoint-8000
│ └─ チェックポイント時のモデル関連資材
├─ checkpoint-8450
│ └─ チェックポイント時のモデル関連資材
└─ チューニング完了時の保存モデル関連資材
「save_total_limit」を3に指定したため、チェックポイントは3つのみ保存されています。
また、「save_steps」は1000を指定していたため、学習ステップが1000進むごとに保存されています。
今回の学習では合計で8チェックポイント作らせる想定ですが、「save_total_limit」を3に指定した為、古いものは削除されて、完了時を含む最新の3つ(7000, 8000, 学習完了時のタイミングのチェックポイント)が残っています。
OUTPUT_DIRにチューニング済モデルがある事を確認したら、チューニングの効果を見る為に、チューニング済モデルを指定して推論を実行してみましょう。
### 実行
python train_infer.py infer --model ./models/gemma-3-1b-it --prompt "日本の首都について教えてください。"
### 結果
user
You are a helpful Japanese assistant.
日本の首都について教えてください。
model
日本の首都は、東京でござる。
モデルの口調が「ござる」となりました。
この結果から、チューニングの効果があったことがわかるかと思います。
最後に、上の実行例では動作を見ることができなかったEarlyStoppingの例について紹介します。
過学習が起こりやすいように、利用するデータを絞った(学習データ(10件)と検証データ(1件) )上で、num_train_epochsを1000・eval_stepsを10に変更してチューニングをしたログを以下に示します。
● データを絞るコード
### 学習(train)と検証(test)データを9:1に分割する処理の後に以下を追加。
# データ量調整
train_ds = train_ds.select(range(min(10, train_ds.num_rows)))
eval_ds = eval_ds.select(range(min(1, eval_ds.num_rows)))
● 実行とその結果
### 実行
python train_infer.py train --model ./models/gemma-3-1b-it
### 結果ログ(一部抜粋)
Generating train split: 15015 examples [00:00, 53665.03 examples/s]
Filter: 100% 15015/15015 [00:00<00:00, 174874.77 examples/s]
Map: 100% 10/10 [00:00<00:00, 405.60 examples/s]
Map: 100% 1/1 [00:00<00:00, 216.67 examples/s]
trainer = Trainer(
0% 10/2000 [00:07<19:43, 1.68it/s]
{'eval_loss': 3.248342990875244, 'eval_runtime': 0.07, 'eval_samples_per_second': 14.296, 'eval_steps_per_second': 14.296, 'epoch': 5.0}
0% 10/2000 [00:07<19:43, 1.68it/s]
100% 1/1 [00:00<00:00, 1989.71it/s]
1% 20/2000 [00:32<26:26, 1.25it/s]
{'eval_loss': 2.9920811653137207, 'eval_runtime': 0.0754, 'eval_samples_per_second': 13.265, 'eval_steps_per_second': 13.265, 'epoch': 10.0}
1% 20/2000 [00:32<26:26, 1.25it/s]
100% 1/1 [00:00<00:00, 1562.12it/s]
2% 30/2000 [00:57<26:53, 1.22it/s]
{'eval_loss': 3.1043128967285156, 'eval_runtime': 0.0694, 'eval_samples_per_second': 14.406, 'eval_steps_per_second': 14.406, 'epoch': 15.0}
2% 30/2000 [00:58<26:53, 1.22it/s]
100% 1/1 [00:00<00:00, 1535.81it/s]
2% 40/2000 [01:23<26:54, 1.21it/s]
{'eval_loss': 3.6295840740203857, 'eval_runtime': 0.0685, 'eval_samples_per_second': 14.606, 'eval_steps_per_second': 14.606, 'epoch': 20.0}
2% 40/2000 [01:23<26:54, 1.21it/s]
100% 1/1 [00:00<00:00, 1522.43it/s]
2% 50/2000 [01:49<26:29, 1.23it/s]
{'eval_loss': 3.966750144958496, 'eval_runtime': 0.0687, 'eval_samples_per_second': 14.557, 'eval_steps_per_second': 14.557, 'epoch': 25.0}
2% 50/2000 [01:49<26:29, 1.23it/s]
100% 1/1 [00:00<00:00, 1612.57it/s]
There were missing keys in the checkpoint model loaded: ['lm_head.weight'].
{'train_runtime': 129.3817, 'train_samples_per_second': 77.291, 'train_steps_per_second': 15.458, 'train_loss': 1.4444430541992188, 'epoch': 25.0}
2% 50/2000 [02:09<1:24:05, 2.59s/it]
eval_loss値は、検証の3回目のタイミングで、前の検証時よりも上がり始めてしまいました。
3回目から、4回目・5回目とeval_lossの値が上がり続けた結果、early_stopping_patienceで指定した上限の3回に達してしまった為、全体の学習ステップは2000であるにもかかわらず、途中で処理が終了しました。
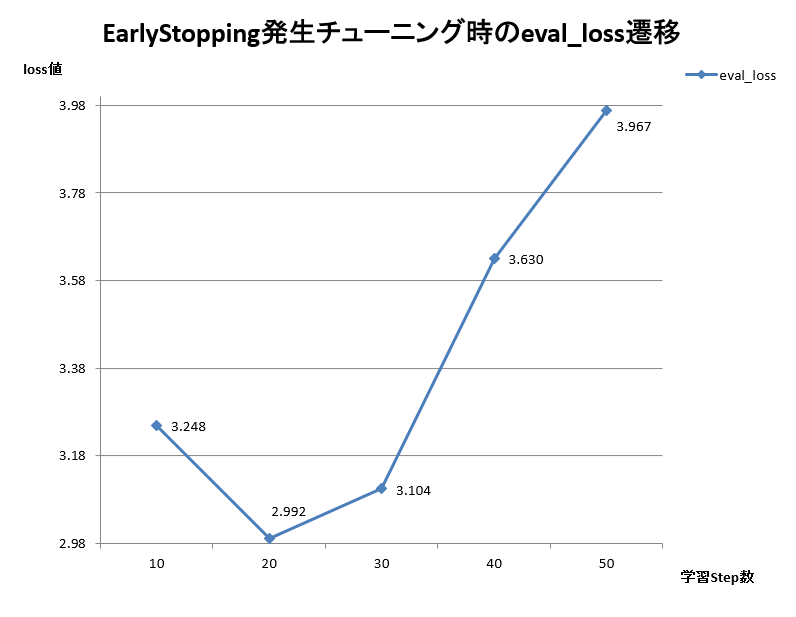
図6 Early Stoppingが発生した学習の効果(eval_loss)遷移
この事から、Early Stoppingが上手く機能していることがわかります。
おわりに
前回と今回の2部構成で、Hugging Faceのライブラリを用いた推論の実行と、フルパラメータチューニング(学習)を行うコードの説明とその実行例を取り上げました。
モデルのチューニングには、モデルのアーキテクチャや仕組みに関する理解も必要となり、これまで連載してきたRAGとはまた違った知識が必要となる事が伝わったのではないでしょうか。
なお第9回に紹介した通り、利用するマシンに応じてHugging Faceのpeftを使って、LoRAなどの一部パラメータへの影響に絞るチューニングを実行することも選択肢となります。
また、今回はHugging Faceに公開されている「用意された」データセットを使いましたが、現場で利用する為のモデルのチューニングには、現場で使われたデータが多く必要となります。
現場で使われたデータは最初からチューニング用に整えられたデータではない事の方が多く、事前のデータの整形や正解データ(LLMの期待回答)の用意なども必要になります。
加えて、チューニング後の結果確認も今回は1質問(1データ)でのみ行いましたが、本来は精度を見る為に、チューニング後の評価用データも一定数用意しておくことが望ましいです。
こういった点からも、チューニングの敷居の高さが伝わるのではないか、と思います。
次回はAIエージェントについてご紹介したいと思います。
ここまでご覧いただき、ありがとうございました。
本記事、またはそれ以外のネットワーク関連に関しての問い合わせやご意見がございましたら、以下にご連絡ください。
本件に関するお問い合わせ





フューチャーネットワーク事業部
第一ビジネスユニット
佐藤 美公 (SATO MIKU)
(同)
山口 佳輝(YAMAGUCHI YOSHIKI)
![]()