Hugging Faceライブラリで実行する推論と学習の基礎(前編) ~LLM活用 第10回~
本記事ではHugging Faceのライブラリを使った、モデルのダウンロードと推論処理について紹介します。




テクノロジーコラム
- 2025年10月09日公開
はじめに
こんにちは、NTTテクノクロスの佐藤・山口です。
前回はファインチューニングの基礎的な紹介しました。
今回からは全2回構成で、Hugging Faceのライブラリを使って、モデルの推論と学習(ファインチューニング)の実行例を紹介したいと思います。
※ 今回は紹介するコードの前提や推論処理に関する紹介がメインです。
Hugging Faceとは?という方は第2回を参照ください。
● 目次
| 記事 | 節番号 | 節タイトル |
|---|---|---|
| 今回 | 1 | 紹介するコードの前提について |
| 2 | ソースコードの全体像について | |
| 3 | 細部ポイント(ダウンロード関数, 推論関数) | |
| 次回 | - | 細部ポイント(学習関数)や実行例 |
[参考] 本連載の記事
本記事とあわせて、以下も良ければご確認ください。
| 連載番号 | タイトル | 概要 |
| 第1回 | 今だから知っておきたいDify!ノーコード・ローコードでLLM活用基盤を作ろう | Dify自体の説明とChatflow機能を使った例を取り上げています。 |
| 第2回 | 爆速キャッチアップ!LLM活用をリードするプラットフォーム群 | LLMの可能性をより広げるDify/Ollama/LangChain/Hugging Faceの紹介と、 DifyとOllamaでローカルLLMを活用したChatflow機能の利用に関して取り上げます。 |
| 第3回 | RAGとは?Difyから基本を学ぶ | RAGの基礎的な説明とDifyを使った実現方法を取り上げています。 |
| 第4回 | ローカルモデル利用のRAG実装で学ぶLangChainの基礎 | ベクトルDBを用いたRAGのサンプルコードから、LangChainの基礎を解説します。 |
| 第5回 | ローカルモデル利用のRAG実装で学ぶLlamaIndexの基礎 | ベクトルDBを用いたRAGのサンプルコードから、LlamaIndexの基礎を解説します。 |
| 第6回 | Difyで学ぶ、RAGの精度改善手法 | RAGの精度改善手法をDifyのChatflow機能を使いながら紹介します。 |
| 第7回 | ローカル環境で実現する、GraphRAGの基礎 | GraphRAGの基礎から、LangChainとNeo4jを使ったグラフRAGの実装例を紹介します。 |
| 第8回 | ローカル環境で実現する、Text-To-SQLとRDBを用いたRAG | Text-To-SQLと、それを活用したRDBを用いたRAGの実装例を紹介します。 |
| 第9回 | ファインチューニングとは?基礎を理解する | ファインチューニングとそのユースケース、手法を紹介します。 |
| 第10回 | Hugging Faceライブラリで実行する推論と学習の基礎(前編) | Hugging Faceのライブラリを使った、モデルのダウンロードや推論処理について紹介します。 |
| 第11回 | Hugging Faceライブラリで実行する推論と学習の基礎(後編) | Hugging Faceのライブラリを使った、ローカルモデルの学習処理と実行例について紹介します。 |
| 第12回 | AIエージェントとは?Difyから考え方を学ぶ | AIエージェントについて、Difyでの動作イメージも含めて紹介します。 |
| 第13回 | MCPとは?AIエージェントの可能性を広げよう | AIエージェントの可能性を広げる技術であるMCPについて紹介します。 |
Hugging Faceのライブラリを使った推論・学習の実行例について
今回と次回で、Hugging Faceのライブラリを用いた推論と学習(ファインチューニング)に関する説明を行いますが、扱う全体のコードは同じものとします。
推論と学習で関数をわけていますので、説明する範囲が分かれるイメージです。
利用するライブラリのバージョン等の前提も同様となります。
学習についてはTrainerクラスを使って、教師あり学習+全パラメータの更新を行うチューニング例を取り扱います。
前提について
今回はHugging Faceからgemma3 (1bモデル)をダウンロードした上で、チューニングを行います。
gemma3を利用するにはHugging Faceにてアカウントを作成し、利用規約に同意・申請を行うことが必要です。
また、同意したアカウントにてアクセストークン(Readのみで可)をHugging Face上で用意し、手元にメモっておく必要もあります。
※ アクセストークンは他の人に漏らさないように注意しましょう。
今回使用するライブラリとバージョンは以下の通りです。
Package Version
------------------------------------- ------------------
torch 2.6.0+cu124
transformers 4.55.0
datasets 4.0.0
huggingface-hub 0.34.4
tokenizers 0.21.4
safetensors 0.6.2
accelerate 1.10.0
sentencepiece 0.2.0
学習用のデータセットは「bbz662bbz/databricks-dolly-15k-ja-gozaru」(※)を使用します。
※ https://huggingface.co/datasets/bbz662bbz/databricks-dolly-15k-ja-gozaru
これは期待する回答データの語尾が「ござる」となっている独特なデータです。
このデータを活用して学習を行うことで、チューニング後モデルの口調を「ござる」に変えられそうです。
モデルの学習前後の変化や学習の効果がわかりやすいですね。
今回の例では、上のデータで学習を行い、チューニングの効果についても紹介したいと思います。
実装例のソースコード全文と全体の構成について
まずは全体像を以下に示します。
この後にポイントとなる点を説明する為、ここでは細かく理解せずとも大丈夫です。
また、サンプルコードの為、最小限の実装となっている点はご承知おきください。
# 標準ライブラリ
import argparse
from glob import glob
import os
import torch
from pathlib import Path
# Hugging Face関連ライブラリ
from huggingface_hub import snapshot_download
from transformers import (
AutoTokenizer,
AutoModelForCausalLM,
TrainingArguments,
Trainer,
DataCollatorForLanguageModeling,
EarlyStoppingCallback,
set_seed,
)
from datasets import load_dataset
# 各種オプションの指定
MODEL_NAME = "google/gemma-3-1b-it"
DATASET_NAME = "bbz662bbz/databricks-dolly-15k-ja-gozaru"
LOCAL_DIR = "./models/gemma-3-1b-it"
DATA_DIR="./data/"
OUTPUT_DIR = "./output_gemma"
MAX_LEN = 1024
SEED = 42
# モデル・データセットのローカルダウンロード関数
def run_download():
HF_TOKEN = os.getenv("HUGGING_FACE_HUB_TOKEN")
if not Path(LOCAL_DIR,"config.json").exists():
print("モデルのダウンロードを開始します。")
snapshot_download(repo_id=MODEL_NAME, local_dir=LOCAL_DIR, token=HF_TOKEN,)
print("モデルのダウンロードが完了しました。")
else:
print("既にモデルがダウンロード済の可能性があります。")
if not any(Path(DATA_DIR).rglob("*.json")):
print("データセットのダウンロードを開始します。")
snapshot_download(repo_id=DATASET_NAME, repo_type="dataset", local_dir=DATA_DIR, token=HF_TOKEN,)
print("データセットのダウンロードが完了しました。")
else:
print("既にデータセットがダウンロード済の可能性があります。")
# pad_token_idとeos_token_idの重複回避用関数
def token_valid(tokenizer, model):
print("特殊トークンに関するチェックを開始します。")
# pad_tokenが無い or eos_tokenと同じなら、専用pad_tokenを追加
if (tokenizer.pad_token_id is None) or (tokenizer.pad_token_id == tokenizer.eos_token_id):
print("特殊トークンの追加対応を行います。")
tokenizer.add_special_tokens({"pad_token": "<|pad|>"})
# モデル埋め込みを新語彙サイズに合わせる(新しいPADトークンを追加して語彙が増えた場合は必須)
model.resize_token_embeddings(len(tokenizer))
# トークナイザーとモデルのコンフィグの値整合
model.config.pad_token_id = tokenizer.pad_token_id
if hasattr(model, "generation_config"):
model.generation_config.pad_token_id = tokenizer.pad_token_id
print("特殊トークンに関するチェックが完了しました。")
# データセットから空文字などを除去する関数
def data_valid(data):
ins = data.get("instruction", None)
res = data.get("output", None)
return (ins is not None and res is not None and str(ins).strip() and str(res).strip())
# 学習用関数
def run_train(model_path: str):
set_seed(SEED)
# モデル利用の為の準備
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(model_path,attn_implementation='eager',torch_dtype='auto',)
model.config.use_cache = False
token_valid(tokenizer, model)
# データセット読込み
files = sorted(
glob(os.path.join(DATA_DIR, "*.json"))
)
if not files:
raise FileNotFoundError(f"{DATA_DIR}にデータセットがありません。ローカルにダウンロードできていない可能性があります。 ")
dataset = load_dataset("json", data_files=files, split="train")
keep_cols = ["instruction", "output"]
dataset = dataset.select_columns([c for c in keep_cols if c in dataset.column_names])
dataset = dataset.filter(data_valid)
# 学習(train)と検証(test)データを9:1に分割
splits = dataset.train_test_split(test_size=0.1, seed=SEED)
train_ds = splits["train"]
eval_ds = splits["test"]
# トークナイズ及び学習に向けたデータフォーマット
def tokenize_fmt(ex):
messages = [
{"role": "system", "content": [{"type":"text","text":"You are a helpful Japanese assistant."}]},
{"role": "user", "content": [{"type":"text","text": ex["instruction"]}]},
{"role": "assistant","content":[{"type":"text","text": ex["output"]}]},
]
text = tokenizer.apply_chat_template(messages, add_generation_prompt=False, tokenize=False,)
return tokenizer(text, max_length=MAX_LEN, truncation=True, padding=False,)
# トークナイズ
train_tok = train_ds.map(tokenize_fmt, batched=False, remove_columns=train_ds.column_names)
eval_tok = eval_ds.map(tokenize_fmt, batched=False, remove_columns=eval_ds.column_names)
# Collator
data_collator = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False)
# チューニング用のハイパーパラメータ指定
args = TrainingArguments(
output_dir=OUTPUT_DIR,
learning_rate=8e-6,
per_device_train_batch_size=2,
per_device_eval_batch_size=2,
gradient_accumulation_steps=4,
num_train_epochs=5,
eval_strategy="steps",
eval_steps=1000,
save_strategy="steps",
save_steps=1000,
save_total_limit=5,
load_best_model_at_end=True,
metric_for_best_model="eval_loss",
greater_is_better=False,
fp16=False,
bf16=True,
seed=SEED,
gradient_checkpointing=True,
report_to="none",
)
trainer = Trainer(
model=model,
args=args,
train_dataset=train_tok,
eval_dataset=eval_tok,
data_collator=data_collator,
tokenizer=tokenizer,
callbacks=[EarlyStoppingCallback(early_stopping_patience=3, early_stopping_threshold=0.0)],
)
# 学習実行
trainer.train()
# 学習済モデルの保存
trainer.save_model(OUTPUT_DIR)
tokenizer.save_pretrained(OUTPUT_DIR)
# 推論実行用関数
def run_infer(model_path: str, user_prompt: str):
# モデルを使う為の初期設定
tokenizer = AutoTokenizer.from_pretrained(model_path, local_files_only=True)
model= AutoModelForCausalLM.from_pretrained(
model_path,
local_files_only=True,
attn_implementation="eager",
torch_dtype=torch.float32,
).to("cpu").eval()
# 受け取った質問をセット
messages = [
{"role": "system", "content": [{"type": "text", "text": "You are a helpful Japanese assistant."}]},
{"role": "user", "content": [{"type": "text", "text": user_prompt}]},
]
# 質問文をトークン化
inputs = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
tokenize=True,
return_dict=True,
return_tensors="pt",
)
# 推論実行
with torch.inference_mode():
output = model.generate(**inputs, max_new_tokens=128, temperature=0.1, do_sample=True, )
print(tokenizer.batch_decode(output, skip_special_tokens=True)[0] )
def main():
parser = argparse.ArgumentParser()
sub = parser.add_subparsers(dest="mode", required=True)
tr = sub.add_parser("train", help="学習の実行")
tr.add_argument("--model", required=True, help="モデルをダウンロードしたローカルパスを指定する")
inf = sub.add_parser("infer", help="推論の実行")
inf.add_argument("--prompt", required=True, help="質問文(プロンプト)")
inf.add_argument("--model", default=OUTPUT_DIR, help=f"推論に使うモデル(省略時は学習したモデル指定: {OUTPUT_DIR})")
sub.add_parser("download", help="モデルをローカルにダウンロードする")
args = parser.parse_args()
if args.mode == "download":
run_download()
elif args.mode == "train":
run_train(args.model)
else:
run_infer(args.model, args.prompt)
if __name__ == "__main__":
main()
コードの全体構造は以下のようになっています。
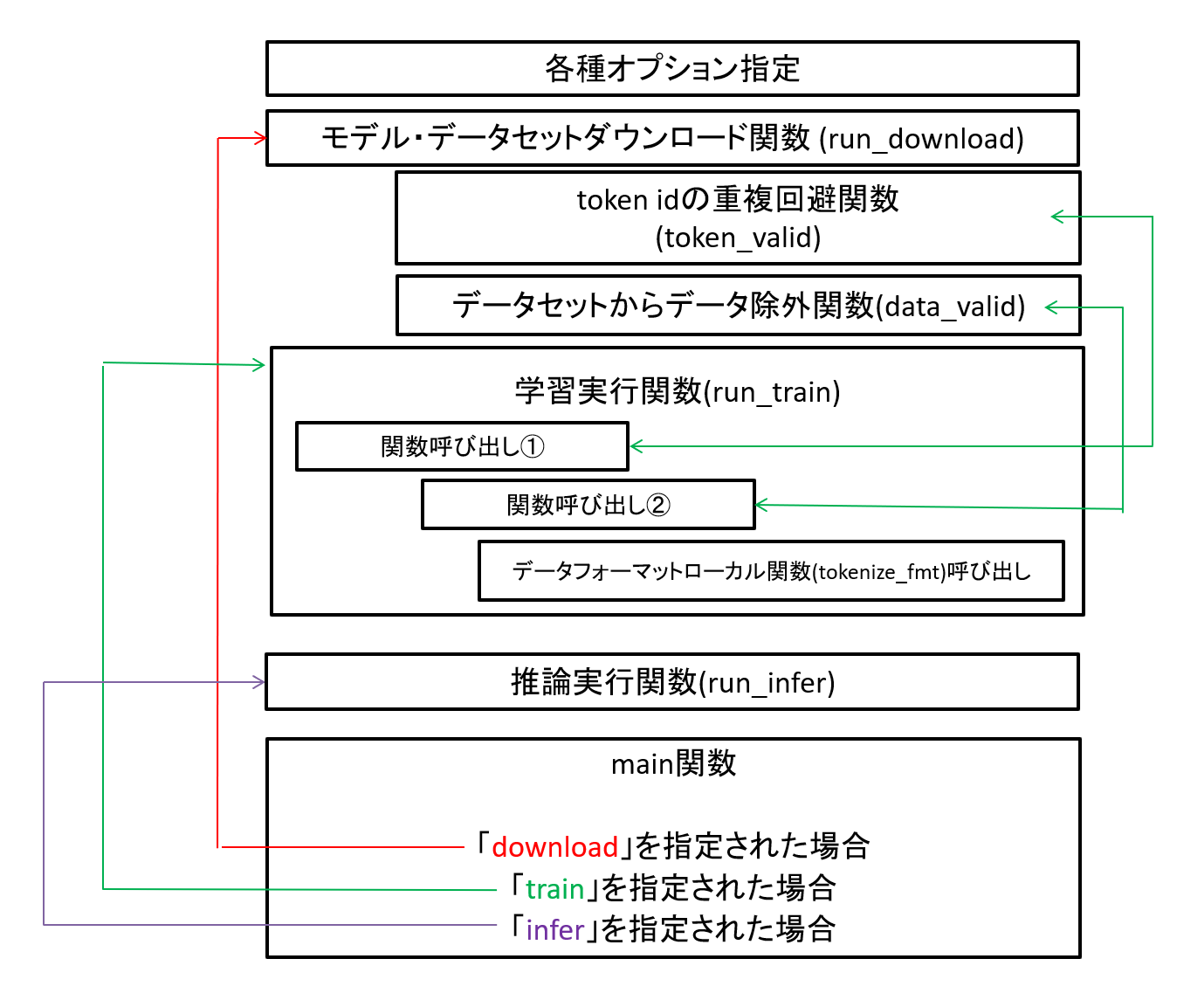
図1 サンプルコードの構成
大きく「①モデル・データセットダウンロード」「②モデルの学習」「③モデルの推論」の3つのモードがあります。
まずは①を実行後に、②や③を使う(ローカルに落としたモデルを使う)ことを前提としています。
細部のポイントについて
ここからは、今回のコードのポイントを解説します。
※ 学習関数に関する解説は次回に掲載します。
まず、各種オプションに使用する為の設定についてです。
MODEL_NAME = "google/gemma-3-1b-it"
DATASET_NAME = "bbz662bbz/databricks-dolly-15k-ja-gozaru"
LOCAL_DIR = "./models/gemma-3-1b-it"
DATA_DIR="./data/"
OUTPUT_DIR = "./output_gemma"
MAX_LEN = 1024
SEED = 42
これらは以下のように使用します。
| 変数名 | 説明 |
|---|---|
| MODEL_NAME | 使用するモデルの指定。 |
| DATASET_NAME | 学習(ファインチューニング)に使用するデータセットの指定。 |
| LOCAL_DIR | Hugging Faceから、使用するモデル(=ファインチューニング前のモデル)をダウンロードして配置するローカルディレクトリ。 |
| DATA_DIR | Hugging Faceから、使用するデータセットをダウンロードして配置するローカルディレクトリ。 |
| OUTPUT_DIR | 学習(ファインチューニング)して、できたモデルを配置するローカルディレクトリ。 |
| MAX_LEN | モデルに学習させる際のデータの最大長(トークン)指定。 |
| SEED | データのランダム取得やモデル学習の結果を固定化する為のシード値指定。 |
今回はサンプルの為、最小限としています。
より汎用的に作る場合は、学習用のハイパーパラメータ(次回に説明予定)なども可変で設定できるようにし、argparseを使ってコード実行の引数として指定できるようにしておくと良いでしょう。
SEEDの値は任意の値で構いませんが、今回はよく使われる42を指定しています。
MODEL_NAMEで指定している「gemma-3-1b-it」のitは「(汎用チャット型とするために)インストラクションチューニングをしたモデル」である事を示しています。
他にも「pt」と書かれたモデルもありますが、これは「事前学習済のモデル」である事を指します。
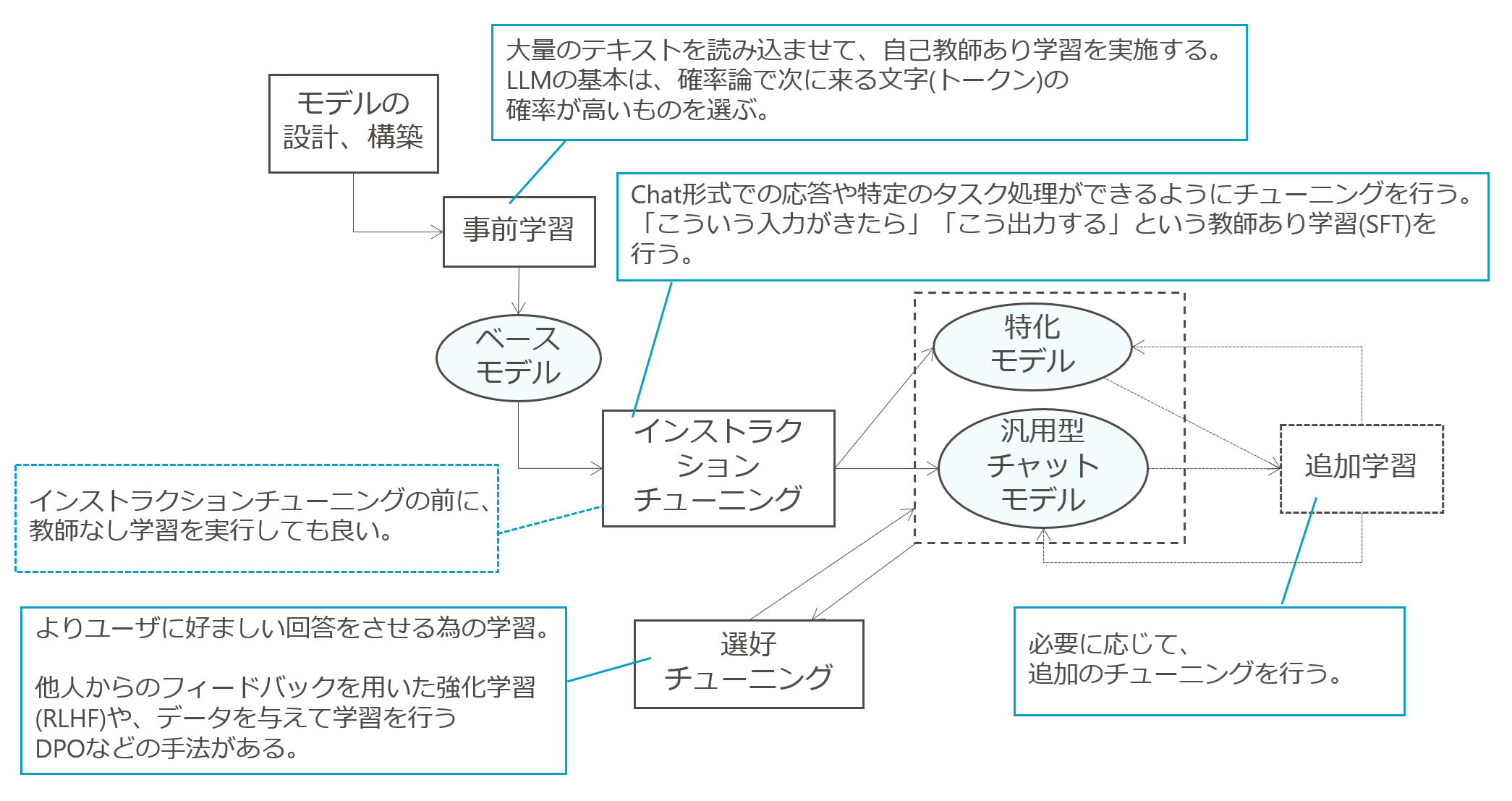
図2 LLMができるまでの流れ
上の図はLLMのモデルができるまでの過程を示した図です。
itモデルは汎用型チャットモデル、ptモデルはベースモデルを指しています。
今回は、ユーザの質問に対して汎用的に答えられる能力は残したまま、口調をござるとしたい為、汎用型チャットモデルであるitモデルを選定しています。
ここからは実際の実行モードにあわせた関数の説明をしていきたいと思います。
まずはモデル・データセットダウンロード関数についてです。
import os
from pathlib import Path
from huggingface_hub import snapshot_download
def run_download():
HF_TOKEN = os.getenv("HUGGING_FACE_HUB_TOKEN")
if not Path(LOCAL_DIR,"config.json").exists():
print("モデルのダウンロードを開始します。")
snapshot_download(repo_id=MODEL_NAME, local_dir=LOCAL_DIR, token=HF_TOKEN,)
print("モデルのダウンロードが完了しました。")
else:
print("既にモデルがダウンロード済の可能性があります。")
まずos.getenvで、OS上の環境変数「HUGGING_FACE_HUB_TOKEN」を取得しています。
よって、本コードを実行する前にOS側で「HUGGING_FACE_HUB_TOKEN」(前提節で紹介したトークン情報)を環境変数に指定しておく必要があります。
トークン設定ができたら、LOCAL_DIRで指定したフォルダと、config.json (モデルを構成するファイルの一部)が存在するか確認し、存在しない場合にはHugging Faceからローカルにダウンロードする「snapshot_download」を実行します。
これによりLOCAL_DIRで指定したフォルダにモデルをローカルにダウンロードし、以降はローカル環境のみで実行ができるようになります。
from glob import glob
if not any(Path(DATA_DIR).rglob("*.json")):
print("データセットのダウンロードを開始します。")
snapshot_download(repo_id=DATASET_NAME, repo_type="dataset", local_dir=DATA_DIR, token=HF_TOKEN,)
print("データセットのダウンロードが完了しました。")
else:
print("既にデータセットがダウンロード済の可能性があります。")
同様にデータセットもローカルにダウンロードします。
なお、データセットによってはjson型以外にjsonl型の場合もあります。
今回使うデータセットはjson型の為、シンプルにjsonファイルがあるかどうかをsnapshot_download実行の判定基準としています。
次は推論関数について紹介します。
def run_infer(model_path: str, user_prompt: str):
本関数はmain関数から呼び出されますが、その際に推論を実行するモデルのパスと、ユーザの質問文(プロンプト)を渡す構成としています。
この構成により、ファインチューニング前モデル(LOCAL_DIRに配置)またはファインチューニング後モデル(OUTPUT_DIRに配置)を選択して利用できるようにしています。
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained(model_path, local_files_only=True)
model= AutoModelForCausalLM.from_pretrained(
model_path,
local_files_only=True,
attn_implementation="eager",
torch_dtype=torch.float32,
).to("cpu").eval()
Hugging Faceには、モデルに応じたトークナイザーを自動選択して読み込む「AutoTokenizer」と、モデルを読み込む「AutoModelForCausalLM」があります。
これらでモデルを使う最低限の事前設定をしています。
トークナイザーとは何か?というと、人が理解できる自然言語を、モデルが理解できるように数値化する(トークン化する)もので、いわば人とモデルの仲介・翻訳機のような役割を果たします。
モデルは自然言語をそのまま理解しているわけではなく、単語(Gemmaの場合、正確にはサブワード)ごとに数値化した上で、理解をしています。
この単語レベルの分割と数値化処理を、トークナイザーの「エンコード」処理と呼びます。
また、モデルが回答を生成した際にもトークン(数値)で情報が生成される為、そのままでは人が理解できません。
よってトークナイザーがトークンを自然言語化を行います。
この処理を「デコード処理」と呼びます。
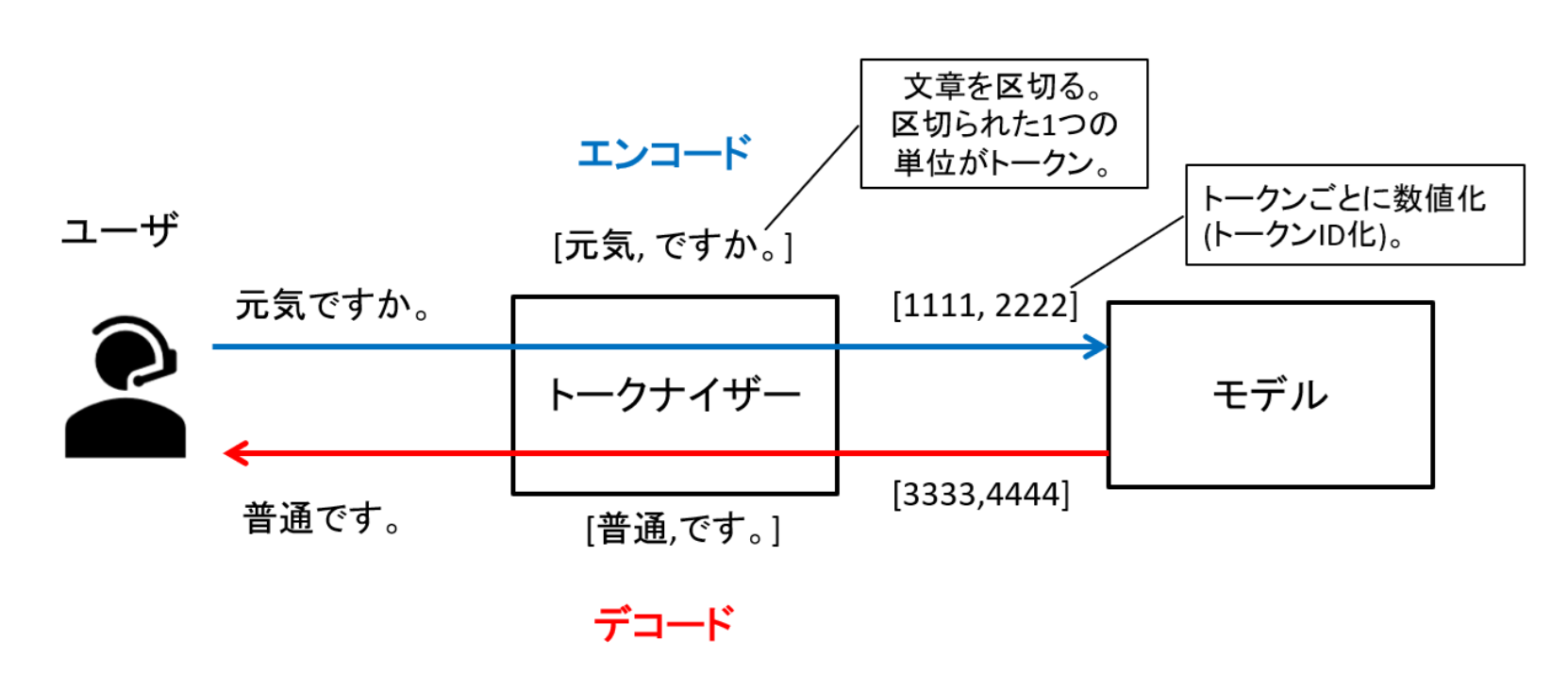
図3 トークナイザーとモデルについて
トークナイザーとモデルは別物ではありますが、密接に連動しており、セットで利用されます。
Gemma3ではSentencePieceと呼ばれるトークナイザーを利用しており、「AutoTokenizer」にて自動で選定しています。
なお、ここでいう数値化(トークンID化)は、第3回で述べたベクトル化とは別の処理である事も注意ください。
次に「AutoModelForCausalLM」についてですが、これはテキスト生成(次に発生する文字を予測して出力する動作)モデルに利用します。
テキスト生成といえばLLMというイメージかと思います。
LLMのアーキテクチャとして最も有名なのは「トランスフォーマー(transformer)」かと思いますが、これには大きくは以下の3種類があります。
| No. | 説明 |
|---|---|
| 1 | Encoder-only型 |
| 2 | Decoder-only型 |
| 3 | Encoder-Decoder型 |
※ ここでいうEncoder, Decoderはトークナイザーの処理(エンコード/デコード)とは別物で、トランスフォーマーの構造の一部を指す言葉です。
今回テーマとして扱うGemma3は、No.2に該当します。
No.2に該当するモデル場合は基本的に「AutoModelForCausalLM」を使います。
※ ちなみに①は「AutoModelForMaskedLM」、③は「AutoModelForSeq2SeqLM」あたりを使うのが一般的です。
| [参考] gemma3のアーキテクチャについて https://storage.googleapis.com/deepmind-media/gemma/Gemma3Report.pdf |
|---|
なお、「AutoTokenizer」でも「AutoModelForCausalLM」でも「local_files_only=True」オプションを付与していますが、これはローカルのみを見に行く指定となります。
また、「AutoModelForCausalLM」にて「attn_implementation」を指定していますが、これはトランスフォーマーの仕組みにあるアテンション(注意機構)の実行選択肢とご理解いただければと思います。
他に選択肢としては「sdpa」などがありますが、今回は最も基本的である「eager」を指定しています。
今回のモデルは1bと小さいモデルの為、「.to("cpu")」とあるように、推論はCPUで実施する想定です。
「.eval()」は推論実行用の指定の為、学習時のモデル設定値には指定しません。
messages = [
{"role": "system", "content": [{"type": "text", "text": "You are a helpful Japanese assistant."}]},
{"role": "user", "content": [{"type": "text", "text": user_prompt}]},
]
inputs = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
tokenize=True,
return_dict=True,
return_tensors="pt",
)
LLMに質問を渡すには、前述の通りトークン化(トークナイズ)が必要です。
したがって、ユーザから渡された自然言語の質問文(user_prompt)をmessagesにセットの上、トークナイザーを使ってトークン化し、結果をinputs変数に入れています。
※ システムプロンプトは以下の公式情報の規定をみると「You are a helpful assistant.」としていますので、大きくは変えすぎず日本語用途である旨を加えた「You are a helpful Japanese assistant.」としました。
[Hugging Face] https://huggingface.co/google/gemma-3-1b-it
| [補足] apply_chat_templateの利用条件と、事前学習済モデルについて
上の例ではトークナイズ時に「apply_chat_template」を使用していますが、これは常に必要なわけではありません。 「apply_chat_template」を使わない場合のトークナイズの例を以下に示します。 事前学習済モデルは、「どういう情報をもらったら、どう回答するか」というような指示応答型の学習をまだしていない状態のモデルです。 その為、ユーザの質問文も文章の続きを予測したやすい・連続生成を誘導する形で与えるのが適切です。
事前学習済モデルに教師あり学習でのファインチューニング(インストラクションチューニング)した場合には、学習データと同様のフォーマットで質問をすると良いでしょう。 gemma3の事前学習モデルでの推論の仕方について気になる方は以下も参照にしてみてください。 |
|---|
トークン化ができたら、以下のように推論を実施します。
with torch.inference_mode():
output = model.generate(**inputs, max_new_tokens=128, temperature=0.1, do_sample=True, )
print(tokenizer.batch_decode(output, skip_special_tokens=True)[0] )
まず、トークン化した質問文(inputs)をmodel.generateでモデルに渡して、推論を実施(generate)させます。
結果をoutputsに入れていますが、このままでは人が理解できない為、トークナイザーでデコードをさせる必要があります。
その結果をprint文で表示しています。
なお、生成された文章には、文章の終わりなどを示す特殊な文字が入ります。
これはユーザが見る時には不要であるため、デコード時にskip_special_tokens=True とすることで削除しています。
やや中途半端ですが、今回のコードの紹介はここまでとしたいと思います。
残りは学習関数ですが、これは次回に紹介します。
おわりに
今回はHugging Faceのライブラリを使った、モデルのローカルダウンロードや推論の実行方法についてご紹介しました。
推論を実行する、という点においては、これまでの実行例で使ってきたOllamaと同様ではありますが、Hugging Faceを使う場合はモデルに関する理解が一段深く求められる事が伝わったのではないでしょうか。
次回はいよいよ学習関数に関する説明と、実行例について説明したいと思います。
ここまでご覧いただき、ありがとうございました。
本記事、またはそれ以外のネットワーク関連に関しての問い合わせやご意見がございましたら、以下にご連絡ください。
本件に関するお問い合わせ





フューチャーネットワーク事業部
第一ビジネスユニット
佐藤 美公 (SATO MIKU)
(同)
山口 佳輝(YAMAGUCHI YOSHIKI)
![]()