ファインチューニングとは?基礎を理解する ~LLM活用入門9回~
ファインチューニングとはどのようなもので、どういった場合に使うのか、またどのように実施するのか、ファインチューニングの基礎をご紹介します。




テクノロジーコラム
- 2025年09月16日公開
はじめに
こんにちは、NTTテクノクロスの佐藤・山口です。
これまではRAGに関して紹介してきましたが、今回はファインチューニング(FT)について紹介したいと思います。
この記事ではファインチューニングは?というところから、チューニングの種類までを紹介できれば、と思います。
■ 目次
| 節番号 | 節タイトル |
| 1 | ファインチューニングとは |
| 2 | ファインチューニングの種類 |
[参考] 本連載の記事
本記事とあわせて、以下も良ければご確認ください。
| 連載番号 | タイトル | 概要 |
| 第1回 | 今だから知っておきたいDify!ノーコード・ローコードでLLM活用基盤を作ろう | Dify自体の説明とChatflow機能を使った例を取り上げています。 |
| 第2回 | 爆速キャッチアップ!LLM活用をリードするプラットフォーム群 | LLMの可能性をより広げるDify/Ollama/LangChain/Hugging Faceの紹介と、 DifyとOllamaでローカルLLMを活用したChatflow機能の利用に関して取り上げます。 |
| 第3回 | RAGとは?Difyから基本を学ぶ | RAGの基礎的な説明とDifyを使った実現方法を取り上げています。 |
| 第4回 | ローカルモデル利用のRAG実装で学ぶLangChainの基礎 | ベクトルDBを用いたRAGのサンプルコードから、LangChainの基礎を解説します。 |
| 第5回 | ローカルモデル利用のRAG実装で学ぶLlamaIndexの基礎 | ベクトルDBを用いたRAGのサンプルコードから、LlamaIndexの基礎を解説します。 |
| 第6回 | Difyで学ぶ、RAGの精度改善手法 | RAGの精度改善手法をDifyのChatflow機能を使いながら紹介します。 |
| 第7回 | ローカル環境で実現する、GraphRAGの基礎 | GraphRAGの基礎から、LangChainとNeo4jを使ったグラフRAGの実装例を紹介します。 |
| 第8回 | ローカル環境で実現する、Text-To-SQLとRDBを用いたRAG | Text-To-SQLと、それを活用したRDBを用いたRAGの実装例を紹介します。 |
| 第9回 | ファインチューニングとは?基礎を理解する | ファインチューニングとそのユースケース、手法を紹介します。 |
| 第10回 | Hugging Faceライブラリで実行する推論と学習の基礎(前編) | Hugging Faceのライブラリを使った、モデルのダウンロードや推論処理について紹介します。 |
| 第11回 | Hugging Faceライブラリで実行する推論と学習の基礎(後編) | Hugging Faceのライブラリを使った、ローカルモデルの学習処理と実行例について紹介します。 |
| 第12回 | AIエージェントとは?Difyから考え方を学ぶ | AIエージェントについて、Difyでの動作イメージも含めて紹介します。 |
| 第13回 | MCPとは?AIエージェントの可能性を広げよう | AIエージェントの可能性を広げる技術であるMCPについて紹介します。 |
ファインチューニングとは
ファインチューニングは、モデルの「微調整」を指し、既にできているモデルに対して追加の学習を行う手法です。
これにより元のモデルが持ち合わせていない情報(知識/What)を教え込む事や特定タスクの解き方(どのように回答すればよいか/How)を教え込むことができます。
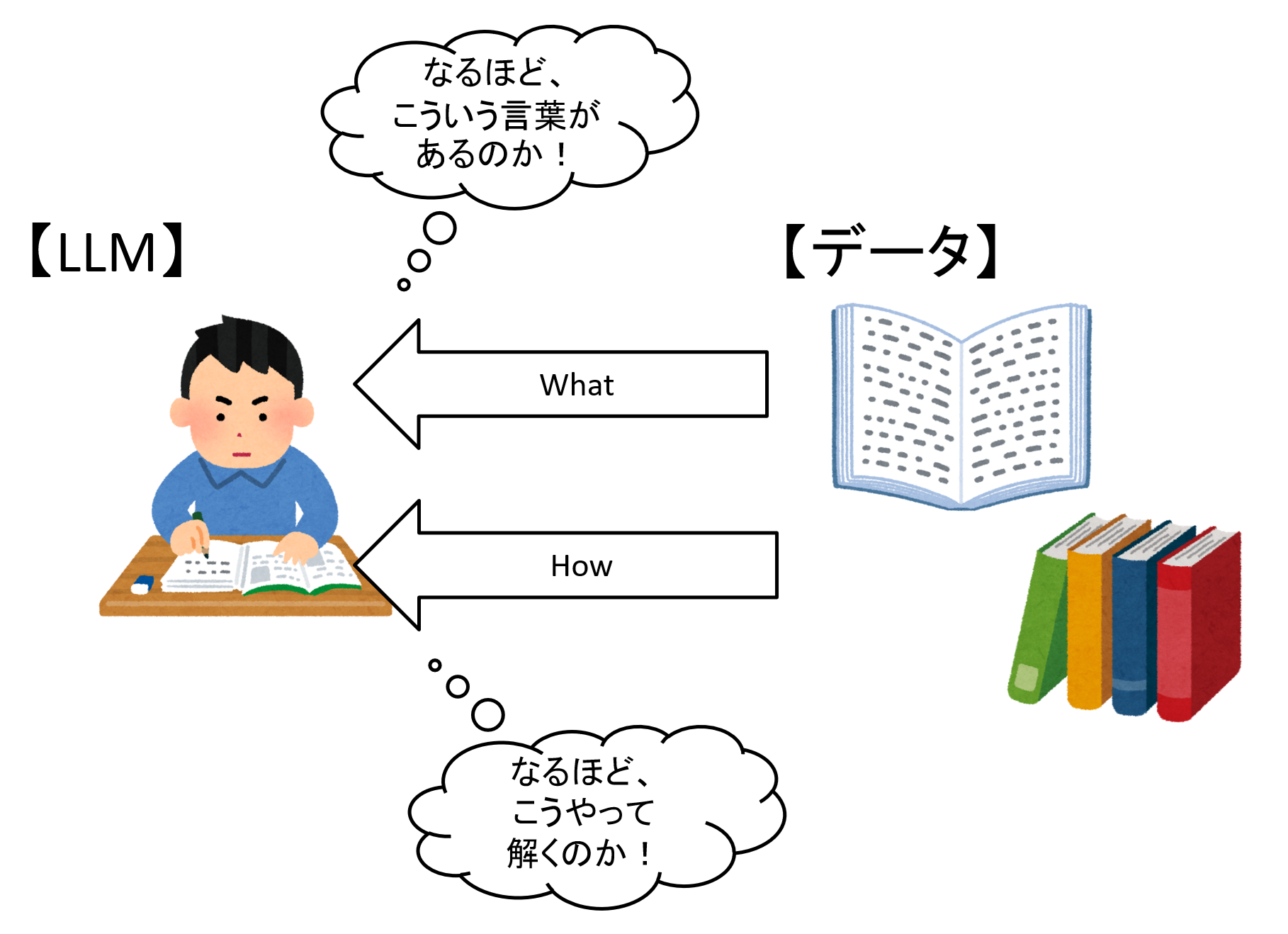
図1 ファインチューニングのイメージ
巨大なモデルにファインチューニングをかけて、専門知識が必要なタスクに対し高度な処理を行えるようにするほか、軽量モデル(SLM)に特定タスクに特化したファインチューニングを行うことで、そのタスクにおいては巨大なモデル(チューニング前)と同水準、あるいはそれ以上まで引き上げられる可能性もあります。
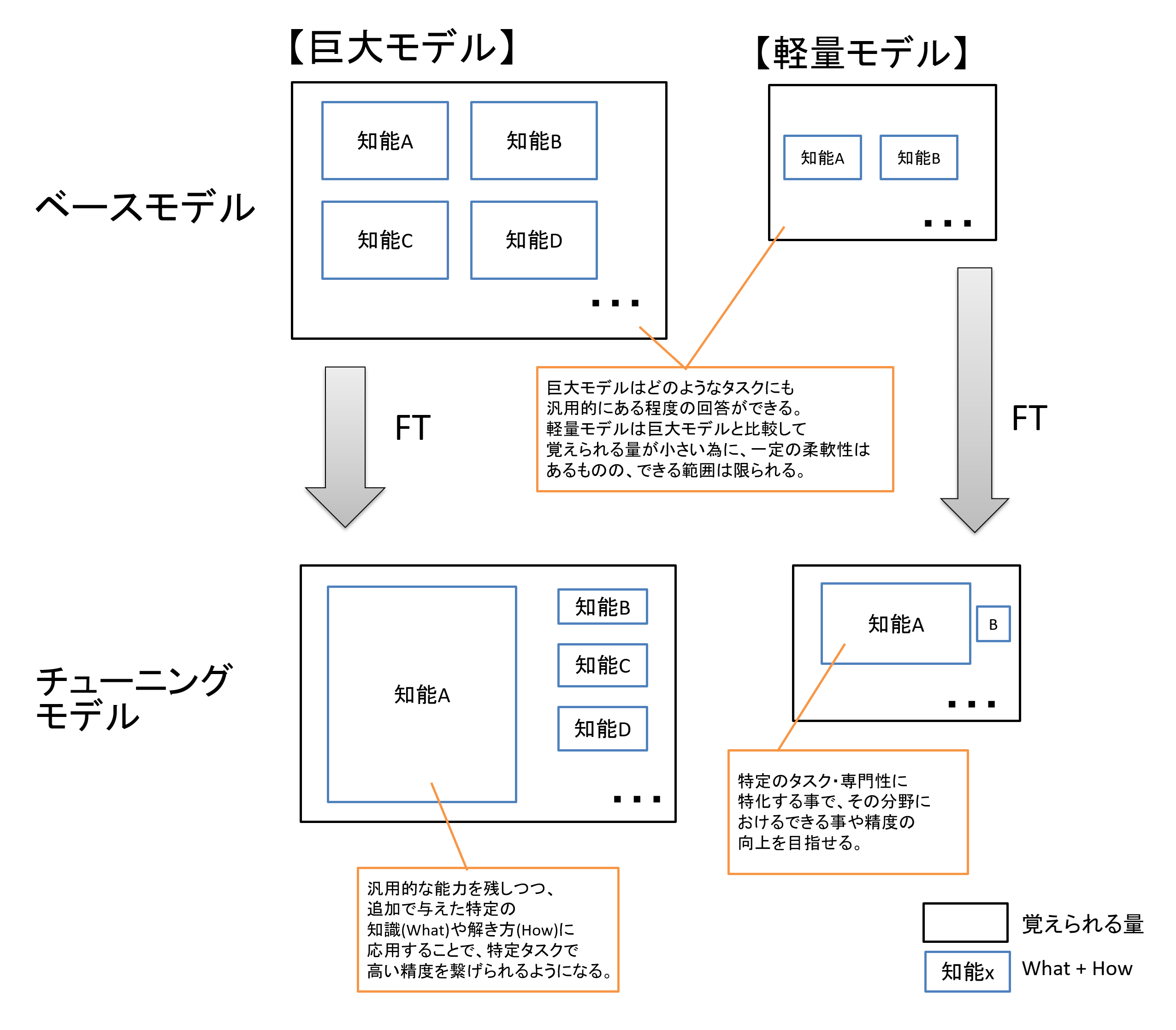
図2 巨大なモデルと軽量モデルの比較
これだけみると巨大なモデルにだけチューニングを行えばよい、と思う方もいるかもしれません。
しかし巨大なモデルに対するファインチューニングはそれだけ計算資源やチューニングにかかる費用も必要となります。
また、LLMに解かせたいタスクによってはオーバースペックとなる場合も多くあります。
よって、例えばシンプルな「要約」や「重要部分の文章抽出」「分類」といった、そこまで高度ではないタスクでは軽量モデルをチューニングして活用するという案もとり得ます。
※ ただし利用するモデルによって、巨大なモデルと比較してモデルに渡せる情報量(コンテキスト長)が短くなる場合もあり、利用をする・あるいは計画する上で考慮・工夫が必要となることもあります。
「元のモデルが持ち合わせていない情報を教え込む」という観点では、RAGでも同じようなことが言われますが、アプローチが異なります。
RAGはモデルに手を加えずに、モデルに渡す情報を工夫する仕組みでしたが、ファインチューニングはモデル自体に手を加えています。
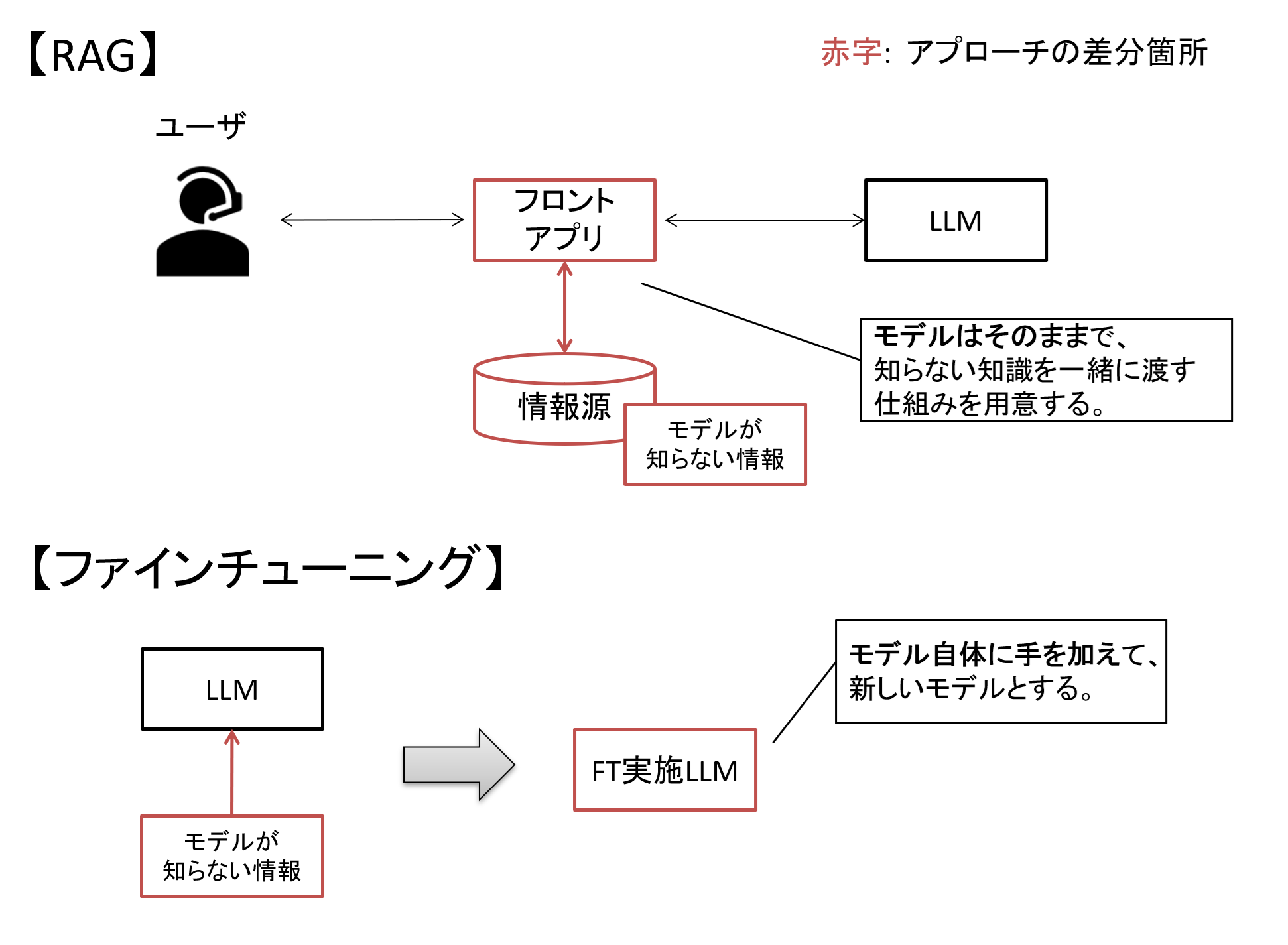
図3 RAGとファインチューニングのアプローチの違い
知識補完が可能な情報の性質もRAGとファインチューニングで少し異なります。
RAGは一般的な用語で書かれた独自ルールの説明などには向いていますが、モデル自体に新しい知識を教え込んだわけではない為、知らない用語(例:専門用語や略語)を前提とした文章や用語が多い文章は上手くモデルが理解できない場合があります。
※「[専門用語・略語]とは、[一般用語で説明]。」というように、モデルにも理解できるよう情報を与えれば、RAGでも専門用語や略語に関する知識補完ができるケースもあります。
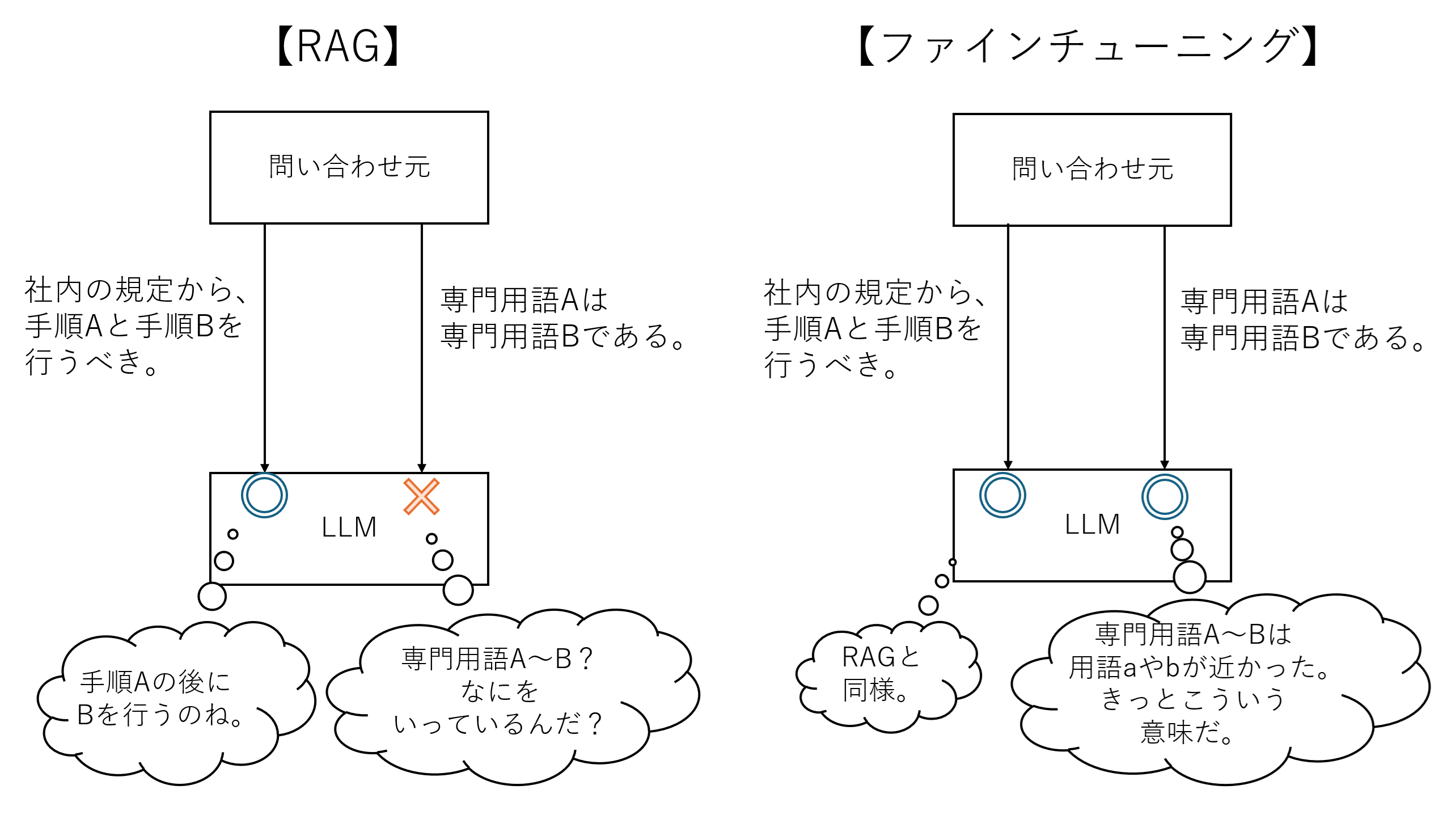
図4 RAGとファインチューニングの「モデルの知らない情報」の対応範囲例
ファインチューニングは、モデルに新たな知識を教え込んでいる為、専門用語にも一定の理解ができる場面が多いです。
一方、RAGのメリットは仕組みを用意する必要はあるものの、計算リソース(GPUなど)はモデルの推論用の分だけで事足りることです。
ファインチューニングはモデル自体に学習を追加で行う為、より多くの計算リソースが必要となります。
計算資源が足りない場合、チューニングに時間がかかるだけでなく、処理自体が成功しない場合もあります。
加えて、ファインチューニングは学習用データも相応の量が必要となります。
少ないデータ量でもチューニング自体はできる場合もありますが、効果が薄かったり、少ないデータにフィッティングしすぎて、LLMの長所である柔軟性がなくなってしまう場合もあります。
よって学習用のデータは、目的に応じたデータかつ可能な限りバリエーションと数を用意する事が理想です。
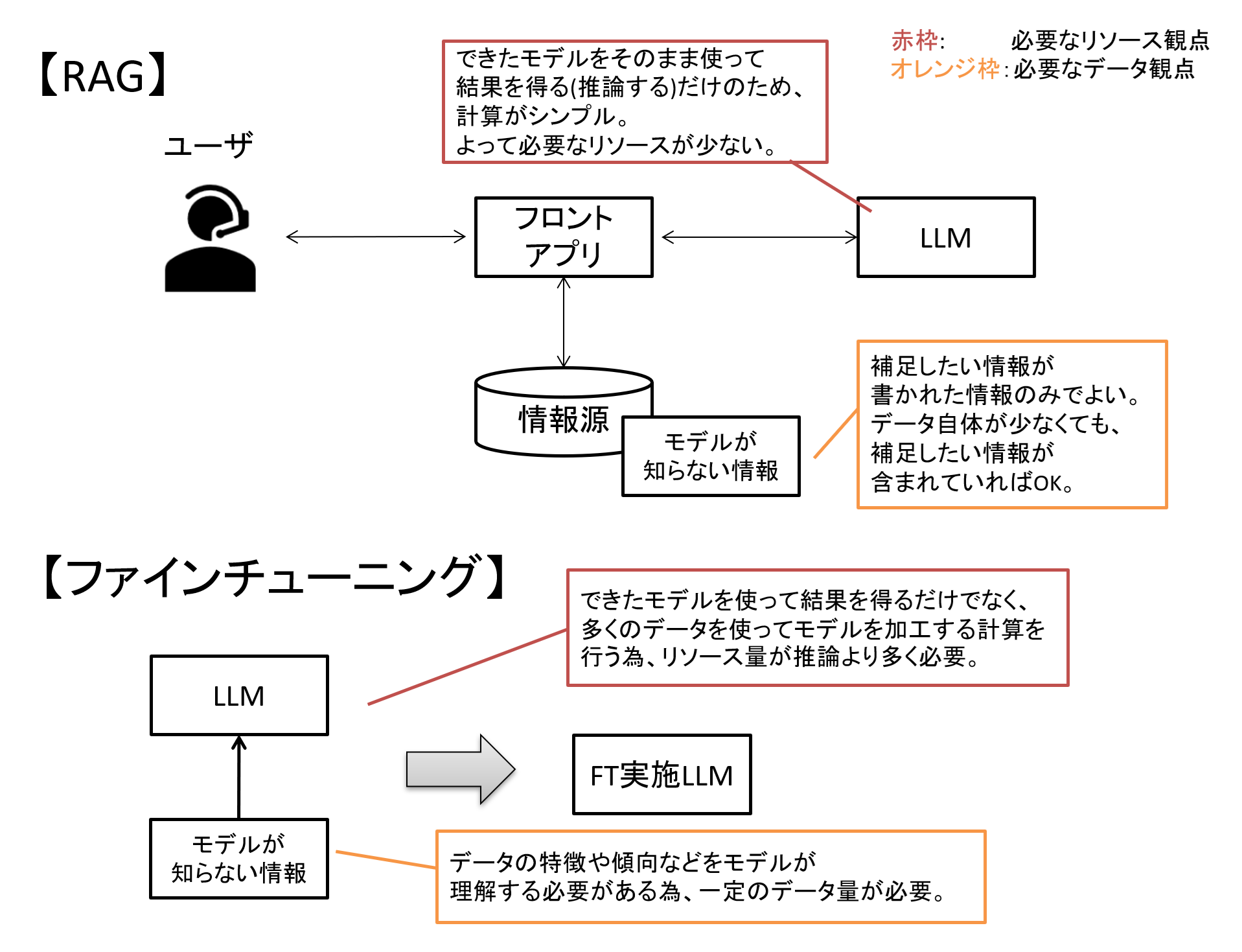
図5 必要な計算リソースやデータ観点でのRAG-FT比較
このように計算リソースやデータ準備の観点から、現状ではファインチューニングよりもRAGの方が敷居は低いと言われています。
ただし、RAGはある程度賢いモデルを使うことが前提となる傾向もある為、どちらの手法を選ぶかは、利用するモデルによっても変わるかと思います。
このように計算リソースやデータ準備、ユースケースなども踏まえて、最適な手法を選ぶことが重要です。
なお、近年はローカルLLMに学習用のデータ生成を行わせたり加工させたりすることで、データ量を増やすことも可能になってきました。
これにより、データ準備のハードルは少し下がった為、少しだけファインチューニングの敷居も下がった、ともいえるかもしれません。
ただしクラウド型LLMは学習用データの生成用途では使えない場合が多いことや、モデルの限界からバリエーションをそこまで用意できない場合もあります。
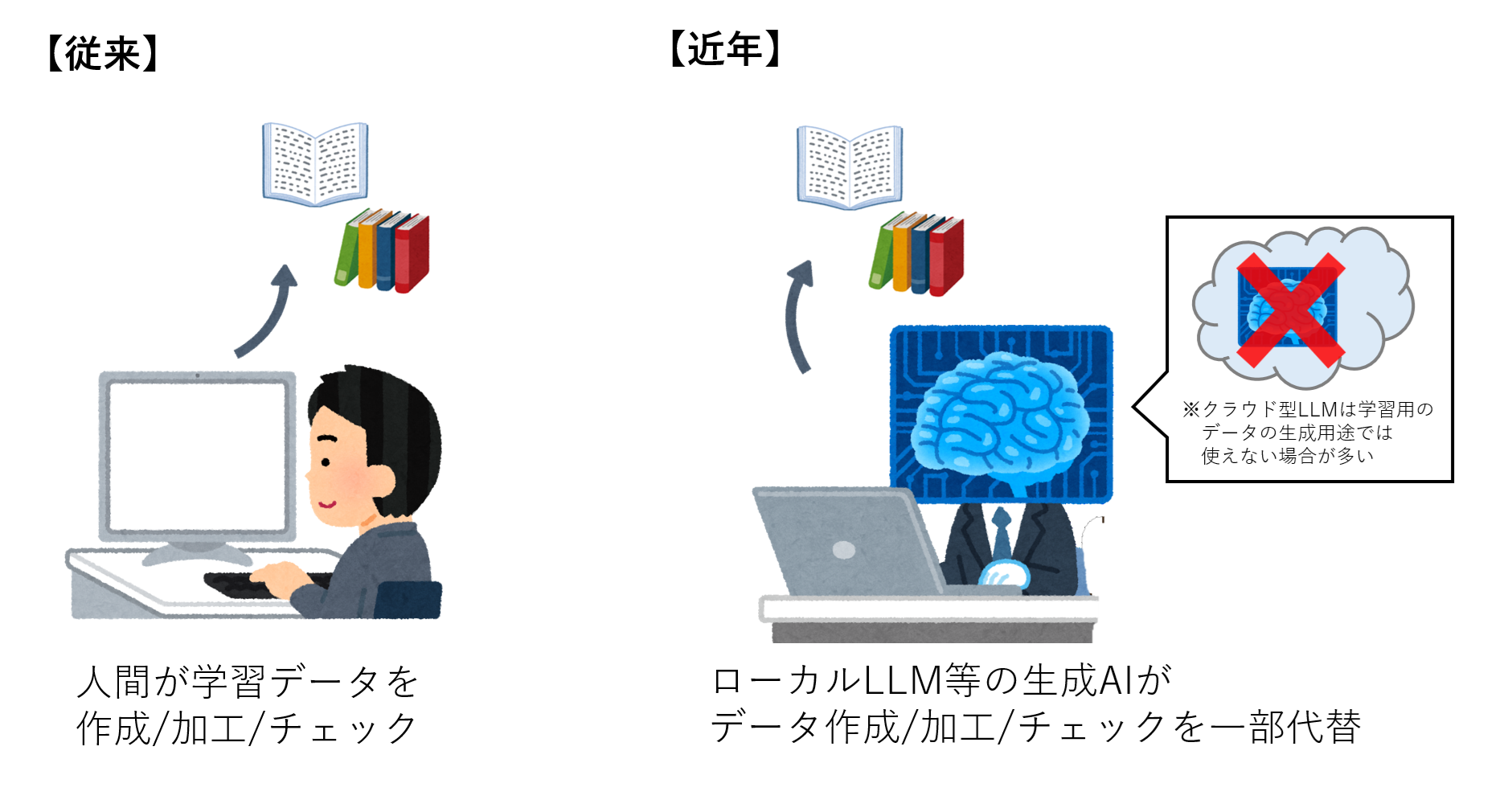
図6 学習データ準備のイメージ
また依然として、学習用の計算リソースは課題になりがちです。
ちなみにファインチューニングは通常のLLMだけでなく、RAGで利用される埋め込みモデルにも行えます。
多くの場合、埋め込みモデルは軽量である為、必要な計算資源もLLMと比較して少なくて済みます。
その為、知識補完を目的とする場合、LLMのチューニングはリソース面に難しくても、RAGを活用しつつ埋め込みモデルをチューニングするアプローチもとり得るかもしれません。
ファインチューニングの種類
ここからはファインチューニングの方法・種類について説明します。
ファインチューニングの種類を考える上では大きく2つの観点があります。
① モデルに何を学習させるのか (= どのように学習させるのか。)
② モデルの影響範囲
以下でそれぞれについて紹介します。
モデルに何を学習させるか
これは前述のWhatを学ばせるのか、Howを学ばせるのかという違いにもなります。
手法としては大きく「教師なし学習」と「教師あり学習」があります。
これらの言葉はLLMに対する学習だけでなく、AI全般における学習方法として広く知られている手法です。
まず教師なし学習ですが、これは正解を与えずに文章だけを与える事で、その文章らの特徴などを学ぶことを目的とした手法です。
文書中の単語と単語の関係や専門用語(業界知識)といったWhatを学ばせることができます。
Web上の文章などをそのまま利用できるため、(教師あり学習と比較して)データの準備労力が低い傾向があります。
※ 正確には、「正解を与えずに」LLMの学習を行うには自己教師あり学習と呼ばれる手法が用いられます。
これは「次の単語予測を学ぶ為に意図的に文章の一部をマスク(隠蔽)する」というように、与えたデータから自身で正解を作って学習する手法です。
したがって厳密な教師なし学習とは異なるものの、人手で正解を用意しない点は教師なし学習に近く、人や場合によって教師なし学習と表現されるケースもあるため、本記事でも教師なし学習と表記します。
教師あり学習は、想定される入力情報と期待する回答をセットで学習させる手法です。
LLMにおいては、入力情報はユーザの質問、期待する回答はLLMの回答というイメージとなります。
これにより、「どういう質問がきたら、どう答えるのか」というHowを学ばせることができます。
※ 学習データ次第で教師あり学習でもWhatを覚えさせることも可能な場合もあります。
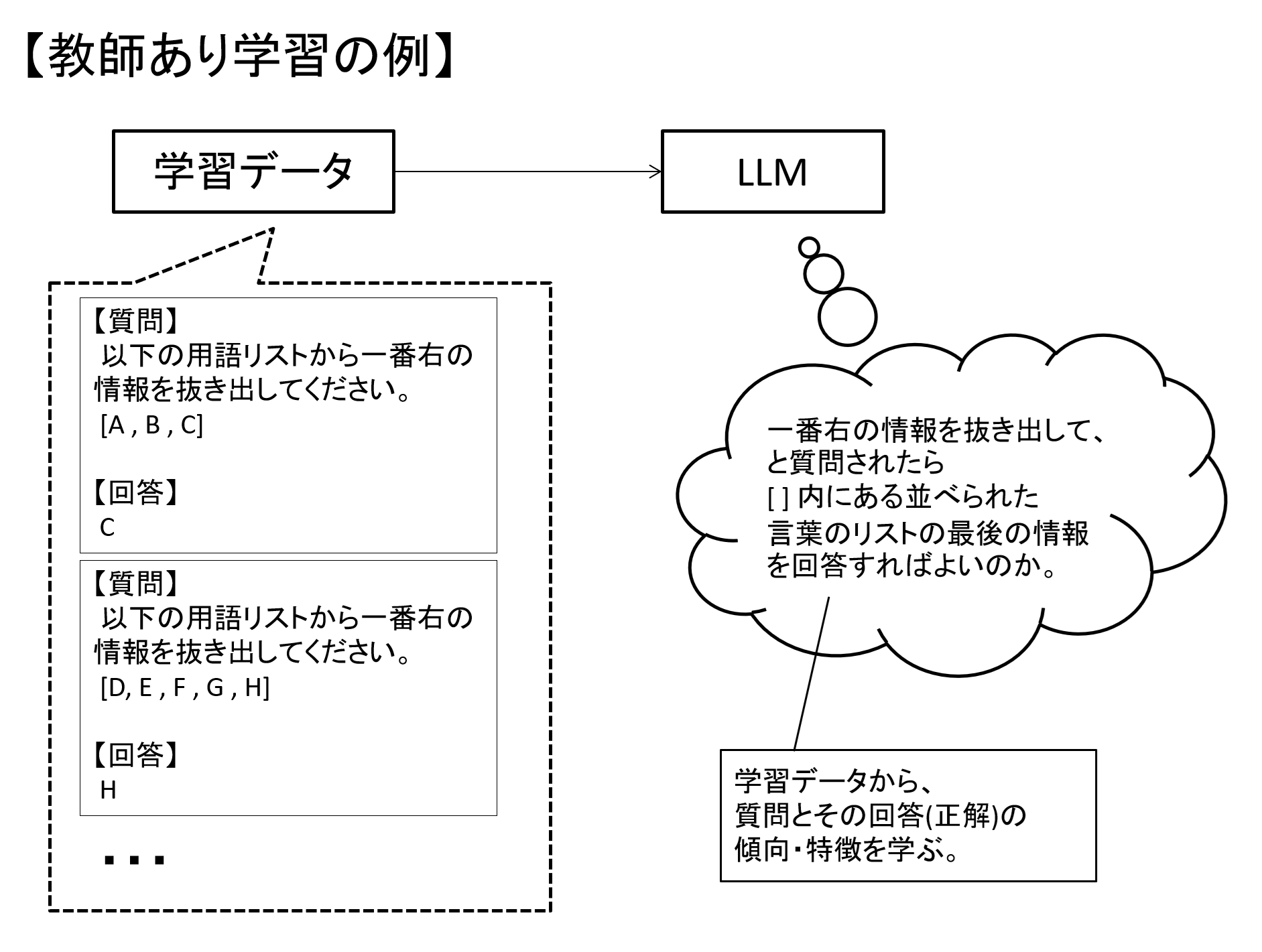
図7 教師あり学習のイメージ
このようにユーザの質問(プロンプト)と対応する回答をLLMに覚えさせる事を「インストラクションチューニング」と呼ぶ場合もあります。
教師あり学習は正解データを整える必要がある為、教師なし学習よりデータ準備に時間・労力がかかります。
一方で、データ量という観点では教師あり学習より、教師なし学習のほうが多く必要となることが一般的です。
また、ファインチューニングでは教師なし学習を選択する場合もありますが、主流は教師あり学習です。
モデルの影響範囲
「モデルのどこまでに影響を与えるのか」という観点で「フルファインチューニング(FFT)」と「PEFT(Parameter-Efficient Fine-Tuning)」と呼ばれる2つがあります。
以下に比較観点を記載します。
|
比較観点 |
フルファインチューニング |
PEFT |
|
影響範囲 |
全パラメータ |
一部のパラメータ |
|
学習の影響度 |
大きい |
フルファインチューニングと比較すると小さい |
|
必要な計算リソース |
大きい |
フルファインチューニングと比較すると小さい |
|
必要なデータ |
大きい |
フルファインチューニングと比較すると小さい |
|
懸念点 |
ベースモデルで学習していた事も含めて影響を与える為、用意した学習データが今一つで質的に適切とは言い難いものの場合、精度が大幅に下がってしまう可能性がある。 |
学習の条件によっては効果が出きらない場合がある。 |
フルファインチューニングのほうが影響は大きいものの、計算リソースやデータ準備の観点で敷居が高いことがわかるかと思います。
フルファインチューニングをするほどのマシンスペックを用意できない場合や、チューニング前モデルのベース知識を極力なくさずに(極力ベース知識を活用の上)新しいことを覚えさせた場合にはPEFTを選択すると良いかと思います。
なお、PEFTの手法には「LoRA(Low-Rank Adaptation)」「QLoRA(Quantized Low-Rank Adaptation)」「Prefix Tuning」など様々な種類がありますが、最も有名なのはLoRAとなります。
チューニング手法についてのまとめ
それぞれの観点で、2つずつの手法を紹介してきました。
基本的には何がやりたいかとご自身の環境にあわせて、2×2の4パターンからどれを選ぶと良いか選択できると良いかと思います。
|
- |
教師なし学習 |
教師あり学習 |
|
フルファインチューニング |
Whatの学習 必要リソース・データ大 学習データ準備にかかる労力小 効果大 |
How (+What)の学習 必要リソース・データ大 学習データ準備にかかる労力大 効果大 |
|
PEFT |
Whatの学習 必要リソース・データ小 学習データ準備にかかる労力小 効果(FFTと比較し)少 |
How (+What)の学習 必要リソース・データ小 学習データ準備にかかる労力大 効果(FFTと比較し)少 |
なお、教師なし学習と教師あり学習の両方を混ぜた「半教師あり学習」と呼ばれる手法も存在しますが、2つの学習の対比をわかりやすくするため、ここでは省略しています。
|
[補足] より好ましい回答を出力させるために ファインチューニングを「モデル自体に変更を加える・微調整する」手法と定義すると、ここまで紹介してきた手法以外にも該当するものがあります。 選好チューニングは、よりユーザに好ましい回答を選択する事で、モデルの出力を好ましいものに近づけていく手法です。 ファインチューニングと選好チューニングをわけて考える場合も多い為、今回は補足とします。 |
おわりに
今回はファインチューニングについて、その言葉の意味やユースケース、手法といった基礎的な内容について紹介しました。
近年は巨大なモデルだけでなく、軽量モデル(SLM)に関する期待や注目度も高まってきています。
軽量モデルを活用していく、あるいは軽量モデルの可能性を広げる上でファインチューニングは重要な技術と言えます。
また軽量モデルは「能力密度(Capability Density)」という観点から、同じパラメータサイズであっても徐々に精度が上がってきている傾向も見て取れ、今後にも期待ができます。
より軽量モデルが進化した未来において、軽量モデルと同様にファインチューニングの価値もより大きなものになっているかもしれません。
次回はHugging Faceのライブラリを使って、モデルの推論やファインチューニングを行う例を紹介したいと思います。
本件についてのご意見やご質問などございましたら、以下からお問い合わせください。
最後までご覧いただき、ありがとうございました。
本件に関するお問い合わせ




フューチャーネットワーク事業部
第一ビジネスユニット
佐藤 美公 (SATO MIKU)
(同)
山口 佳輝(YAMAGUCHI YOSHIKI)
![]()