ローカル環境で実現する、Text-To-SQLとRDBを用いたRAG ~LLM活用第8回~
本記事ではText-To-SQLとRDBを用いたRAGについて、LangChainとPostgreSQLを使ったサンプルコードもあわせて紹介します。




はじめに
こんにちは、NTTテクノクロスの山口です。
これまではベクトルDBを用いたRAGやGraphRAGを用いたRAGについて紹介してきました。
今回は自然言語からSQLに変換するText-To-SQLとRDB(リレーショナルデータベース)を用いたRAGについて紹介していきたいと思います。
● 目次
| 節番号 | 節タイトル |
|---|---|
| 1 | Text-To-SQLとRDBを用いたRAGについて |
| 2 | シンプルな実装例と実行例 |
| 3 | その他 気を付けるべきポイント |
[参考] 本連載の記事
本記事とあわせて、以下も良ければご確認ください。
| 連載番号 | タイトル | 概要 |
| 第1回 | 今だから知っておきたいDify!ノーコード・ローコードでLLM活用基盤を作ろう | Dify自体の説明とChatflow機能を使った例を取り上げています。 |
| 第2回 | 爆速キャッチアップ!LLM活用をリードするプラットフォーム群 | LLMの可能性をより広げるDify/Ollama/LangChain/Hugging Faceの紹介と、 DifyとOllamaでローカルLLMを活用したChatflow機能の利用に関して取り上げます。 |
| 第3回 | RAGとは?Difyから基本を学ぶ | RAGの基礎的な説明とDifyを使った実現方法を取り上げています。 |
| 第4回 | ローカルモデル利用のRAG実装で学ぶLangChainの基礎 | ベクトルDBを用いたRAGのサンプルコードから、LangChainの基礎を解説します。 |
| 第5回 | ローカルモデル利用のRAG実装で学ぶLlamaIndexの基礎 | ベクトルDBを用いたRAGのサンプルコードから、LlamaIndexの基礎を解説します。 |
| 第6回 | Difyで学ぶ、RAGの精度改善手法 | RAGの精度改善手法をDifyのChatflow機能を使いながら紹介します。 |
| 第7回 | ローカル環境で実現する、GraphRAGの基礎 | GraphRAGの基礎から、LangChainとNeo4jを使ったグラフRAGの実装例を紹介します。 |
| 第8回 | ローカル環境で実現する、Text-To-SQLとRDBを用いたRAG | Text-To-SQLと、それを活用したRDBを用いたRAGの実装例を紹介します。 |
| 第9回 | ファインチューニングとは?基礎を理解する | ファインチューニングとそのユースケース、手法を紹介します。 |
| 第10回 | Hugging Faceライブラリで実行する推論と学習の基礎(前編) | Hugging Faceのライブラリを使った、モデルのダウンロードや推論処理について紹介します。 |
| 第11回 | Hugging Faceライブラリで実行する推論と学習の基礎(後編) | Hugging Faceのライブラリを使った、ローカルモデルの学習処理と実行例について紹介します。 |
| 第12回 | AIエージェントとは?Difyから考え方を学ぶ | AIエージェントについて、Difyでの動作イメージも含めて紹介します。 |
| 第13回 | MCPとは?AIエージェントの可能性を広げよう | AIエージェントの可能性を広げる技術であるMCPについて紹介します。 |
Text-To-SQLとRDBを用いたRAGについて
現在、私たちの身の回りでは様々なITシステムが稼働しています。
それらのシステムにおいてデータを管理する為、最も広く利用されているのがRDBといえるでしょう。
また、RDBを操作する為の言語であるSQLも、近年ではDWH(データウェアハウス)でも利用できるなど、RDBにとどまらず広く利用されています。
一方で、SQLは独特の記法から不慣れだと思うように操作しづらいと感じる方も多いと思います。
この課題の解決の糸口になりうるのが、LLMを活用して自然言語(日本語や英語といった、日常的に使う言語)からSQLを生成・変換する「Text-To-SQL」と呼ばれる技術・考え方です。
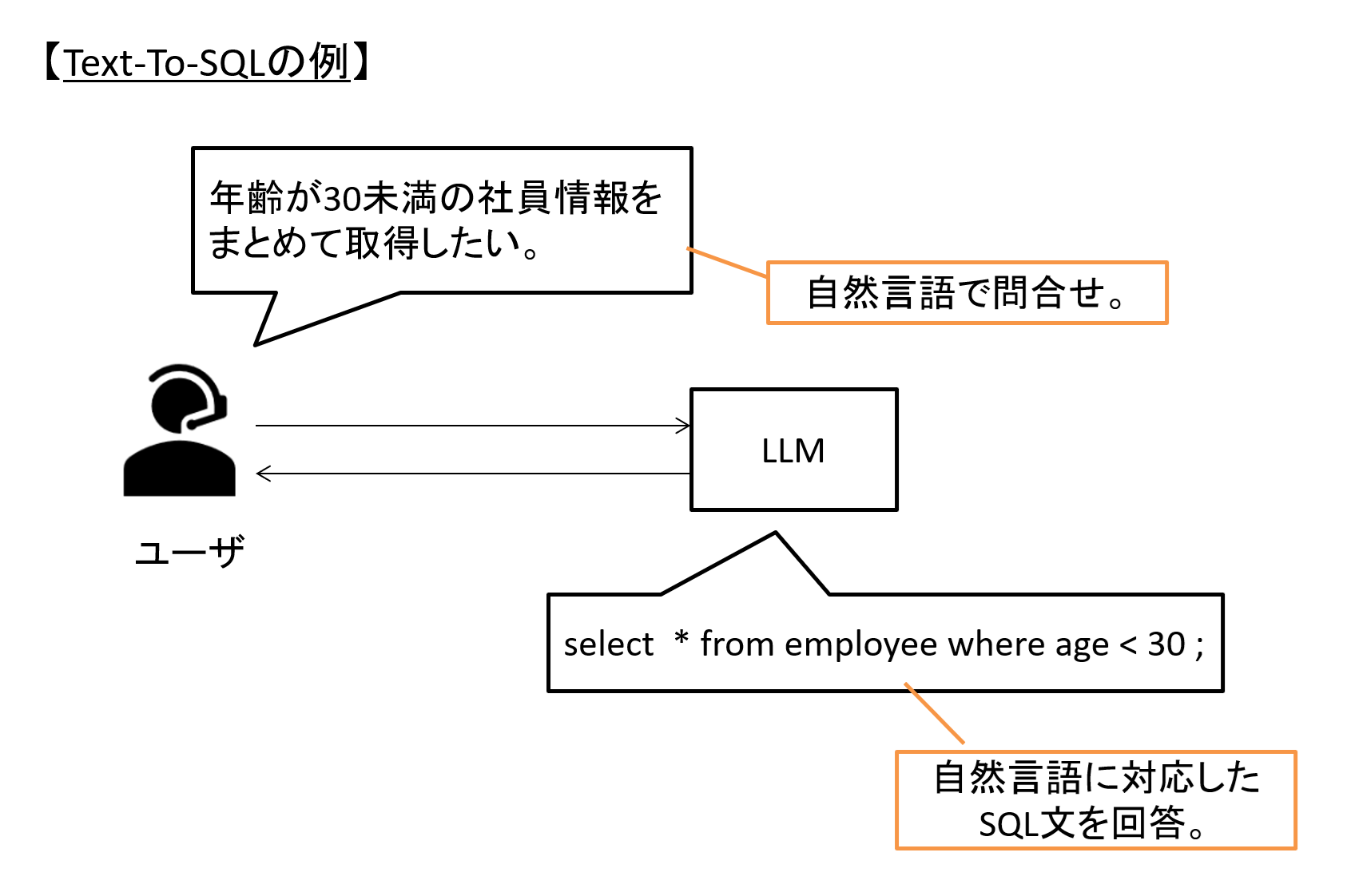
図1 Text-To-SQLのイメージ
最近では、SQLを使わなくてもGUI上で分析処理が可能な製品やシステムが登場しています。
しかし、GUI操作には操作手順の学習コストがかかることや、柔軟な分析を行いづらいといった課題もあります。
こうした中で、自然言語からSQLを生成する仕組みがあれば、SQLをインターフェースに様々なシステムにおいて、非エンジニアも含めて直感的で柔軟なデータ分析を行えるようになると期待できます。
最近では、LLMを用いたコード生成が注目されていますが、SQL生成もまたLLMの有力なユースケースの1つといえるでしょう。
RDBを用いたRAGは、Text-To-SQLを用いた技術で、上に書いたような可能性に踏み込んだ仕組みといえます。
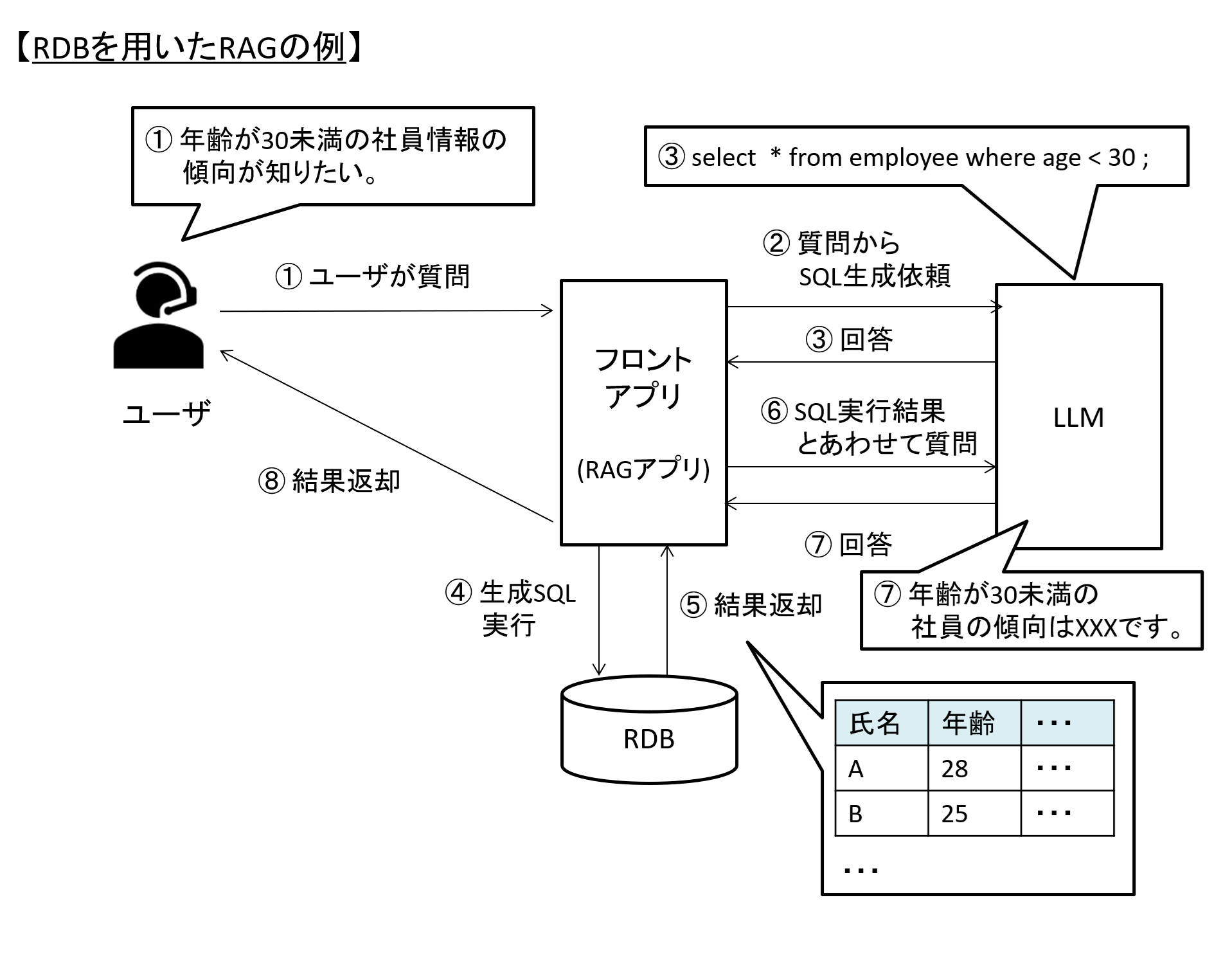
図2 Text-To-SQLを活用した、RDBを用いたRAGのイメージ
RDBを用いたRAGのユースケースについて、ここでは2つ紹介したいと思います。
まず1点目は既存システムに適用することによる、管理者の管理コスト低減や利用者の分析力の向上です。
これまでベクトルDBやGraphDBについても紹介してきましたが、前述の通り、多くのシステムでは依然としてRDB利用が主流かと思います。
このようなシステムが持つ情報も活用した、質問の回答が可能となる点は大きなメリットになり得ます。
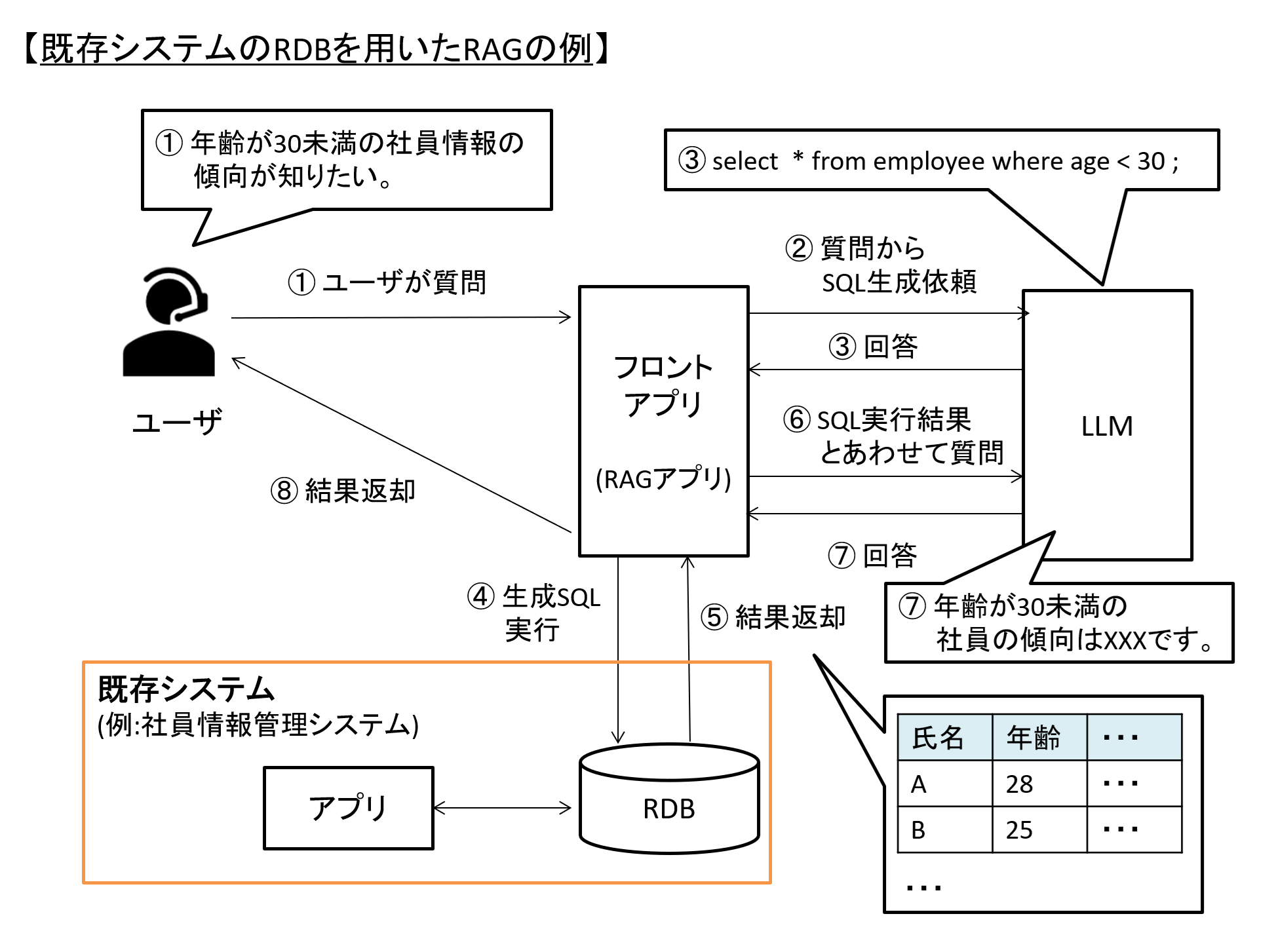
図3 既存システムのRDBに適用したRAGのイメージ例
近年のシステムでは、APIを経由したデータ情報が可能な場合も多くあります。
この場合は、既存のAPIを活用することが適切と考えます。
システムのアプリを経由せずにRDBを直接操作して情報を取得する、という手法はやや特殊なアプローチではあります。
例えばシステム(アプリ+DB)上の作りで、DBの負荷を高めすぎないように適切に優先度付けをした上で処理をさばいている場合、アプリを経由せずにDBを直接操作すると優先制御の対象外の処理がDBで動くこととなります。
こういったシステム設計の意図から外れてしまうことがありえる為、アプリを経由したデータ取得ができる場合はそのほうが望ましいといえます。
一方で既存APIで十分に情報が取得できない場合や古いシステムでそもそも情報取得用のインターフェースが用意されていない場合には、こういった手法が選択肢になりうるかと思います。
とはいえ、システム全体のパフォーマンス管理が十分に設計されている場合や専用のレプリケーションDBを利用できる状態で採用することが推奨されます。
もう1点のユースケースは、ユーザとLLMの対話履歴の「長期保存」です。
LLMは直近の会話内容はある程度参照できるものの、上限があります。
そこでやり取りの内容をDBに保存し、ユーザの質問に応じて関連性する履歴を検索・参照の上でLLMに渡すことで、回答精度を高めるという使い方があげられます。
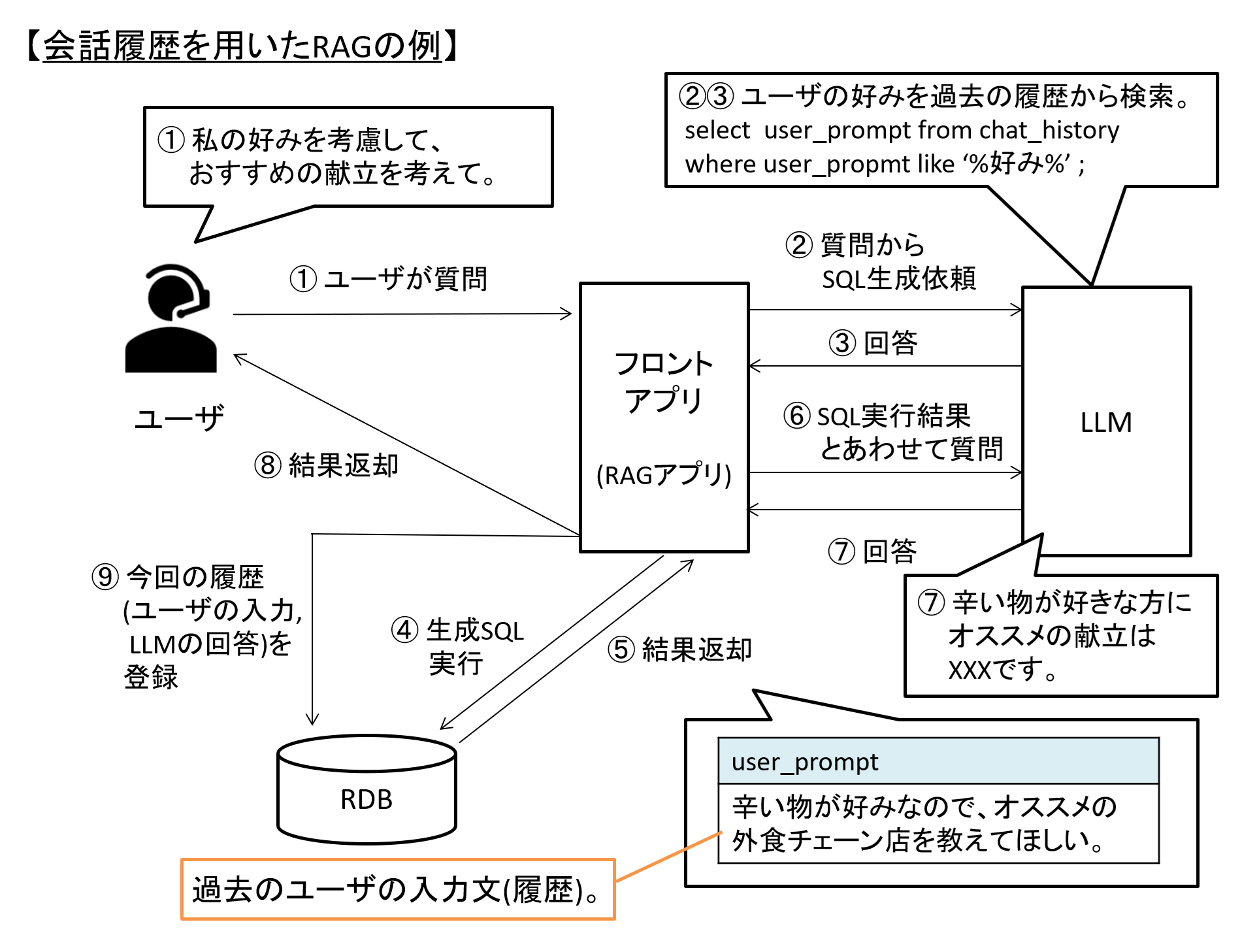
図4 会話履歴の長期保存のイメージ例
対話履歴の参照という使い方はベクトルDBでもあげられるものですが、両者には違いがあります。
ベクトルDBは「意味的に近い情報(抽象的な関連情報)」を取得することに適しているのに対し、RDBは「明示的な条件による検索(直接的な表現による情報)」を取得することに適しています。
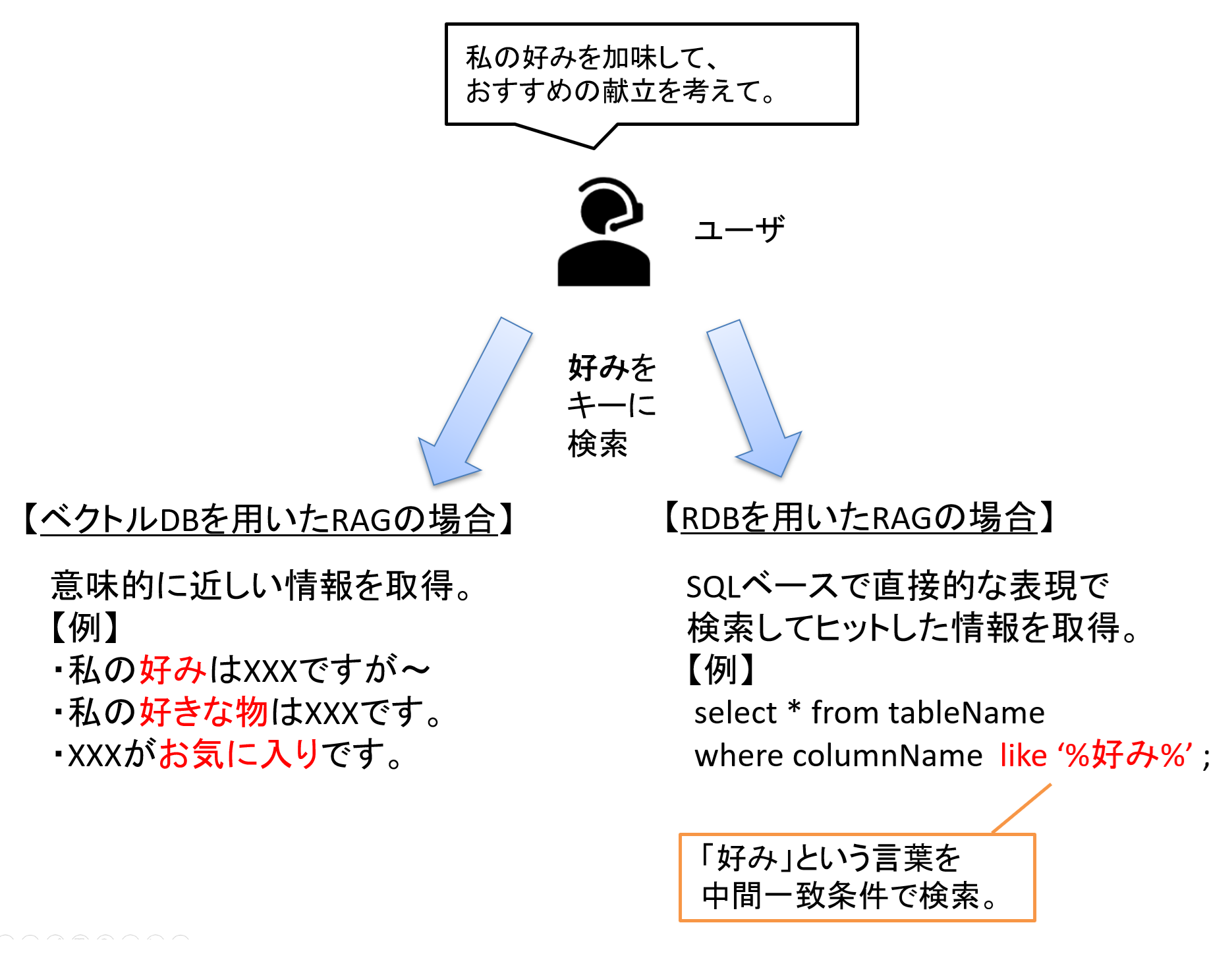
図5 ベクトルDBとRDBを用いたRAGの違い
シンプルな実装例と実行例
RDBを用いたRAGの考え方やユースケースも理解できたところで、ここからはシンプルなコードと実行例を紹介したいと思います。
前提について
今回活用するツールやライブラリのバージョンは以下の通りです。
※ 本記事の内容を用いた開発・運用は、必ずご自身の責任と判断によって行ってください。
開発・運用の結果について、いかなる責任も負いません。
■ ツール
Ollama 0.6.6
PostgreSQL 17.5
■ ライブラリ
Package Version
---------------------------------------- ---------------
langchain 0.3.26
langchain-community 0.3.26
langchain-core 0.3.66
langchain-ollama 0.3.3
psycopg2 2.9.10
SQLAlchemy 2.0.41
今回利用するRDBはPostgreSQL(以降postgresを記載)としたいと思います。
前回のNeo4jと同様にdockerコンテナで動かします。
※ postgresにはpgvectorと呼ばれる、ベクトルデータを扱う為の拡張機能があります。
よってpostgresはベクトルDBとして扱う事もできますが、今回はシンプルなRDBとして扱います。
以下にPostgreSQLコンテナの準備手順を記載します。
docker image pull postgres:17.5
docker run --name rag_postgres -d -e POSTGRES_PASSWORD=postgres -p 15432:5432 postgres
ポートはホスト側のローカルポート15432を、コンテナ内ポート5432と紐づけています。
postgresはポート5432を使うのが一般的ですが、第1回を参考にdifyを立ち上げている場合、difyのコンポーネントと競合してしまう為、15432を使うこととしています。
(第1回を参考にdifyを立ち上げていなければ5432:5432でも問題ありません)
また今回も前回(第7回)同様、サンプルの為、ボリュームを指定しておらず、データの永続化はしていません。
したがって立ち上げたrag_postgresコンテナを削除するとデータは削除されます。
LLMは、今回もOllamaコンテナ上のモデルを利用します。
今回は「gemma3」と「llama3.2:3b」を利用します。
よって事前にOllamaコンテナにてモデルをpullしておく必要があります。
実施方法は第3回を参考に実施ください。
さて、RDBを用いたRAGは「Text-To-SQLとRDBを用いたRAGについて」で触れたように、既存システムでの利用や会話履歴の登録があげられます。
よってサンプルコードもこれらを意識した構成にしたいと思います。
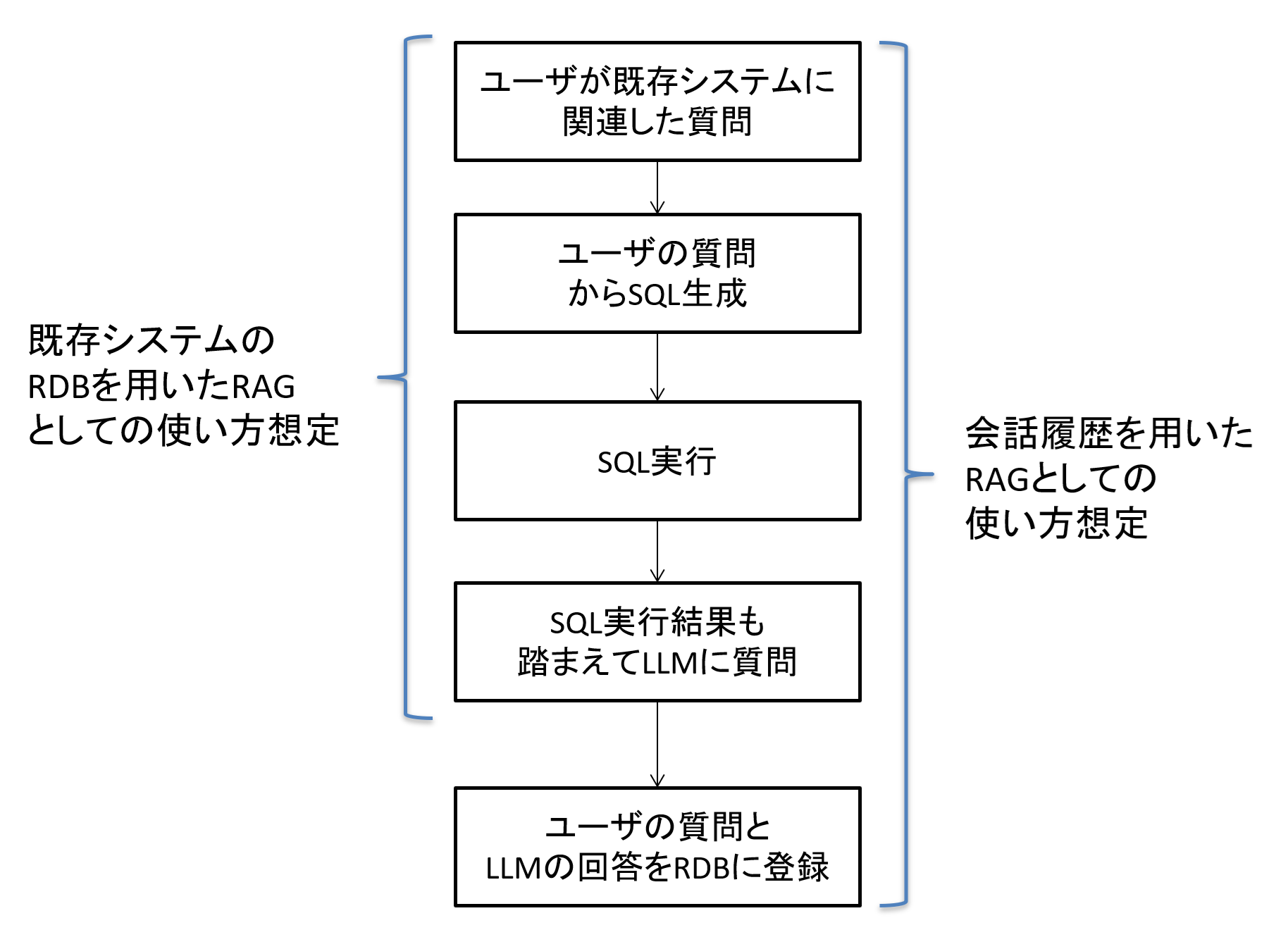
図6 サンプルコードの処理の流れ
今回のサンプルコードは上の図のように大きく機能として、以下の2つがあります。
① ユーザの質問に応じて、RDBから必要な情報を取得の上、質問に回答する。(RAG機能)
② ユーザの質問とLLMの回答をRAG用DBに登録する。
なお、既存システムに向けたRAGであれば既存システム用RDBがデータ取得対象となるでしょうし、会話履歴として使う場合はRAGシステム用DBからデータ取得することが想定されます。
つまり本来であればそれぞれ独立したDBで運用する事が考えられます。
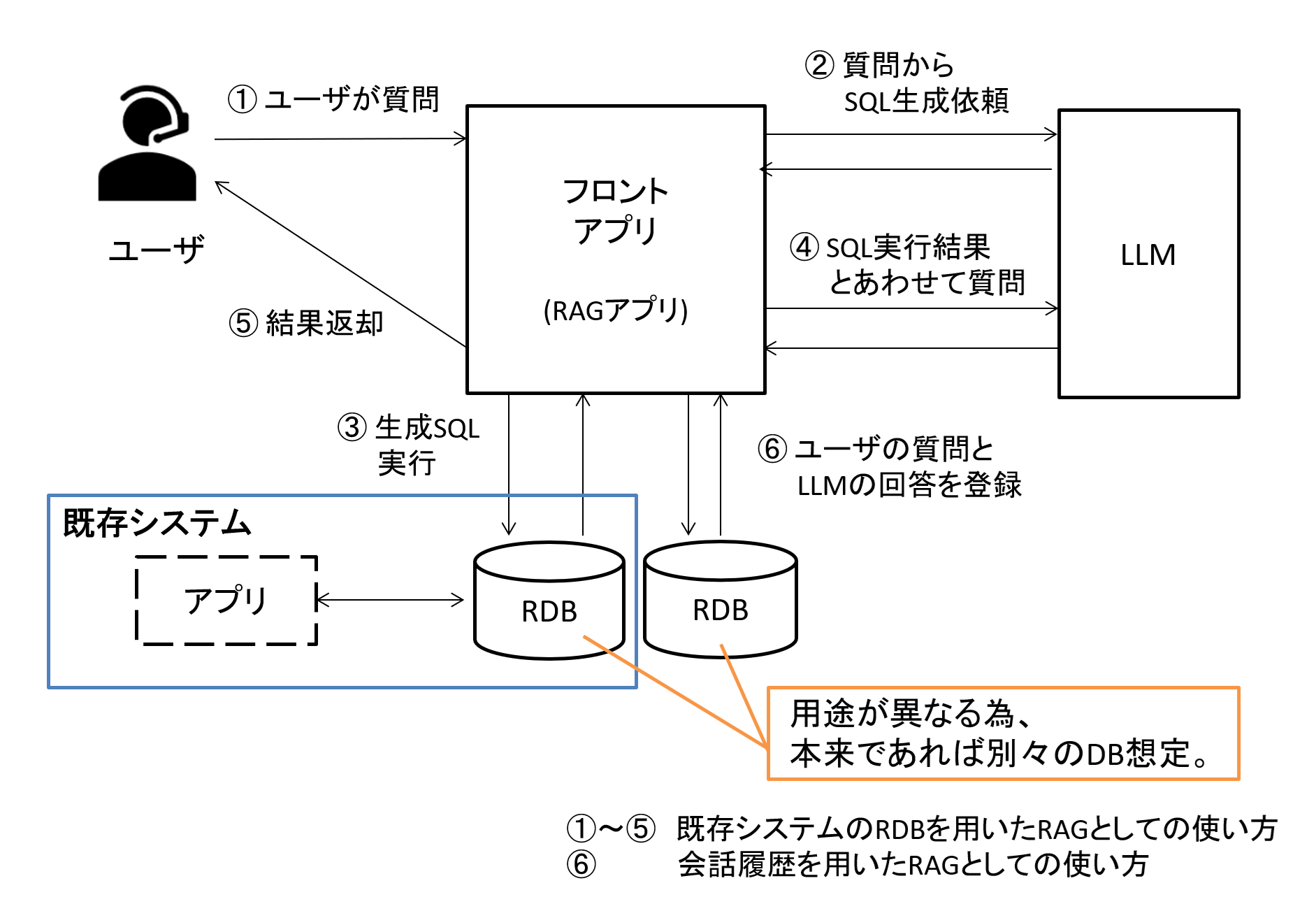
図7 本来の想定される構成
しかし、今回はサンプルの為、簡易的に1つのDBで構成します。
こうすることで、SQL文生成時に複数あるテーブルからLLMが必要なテーブルを選択できるかどうかも確認できます。
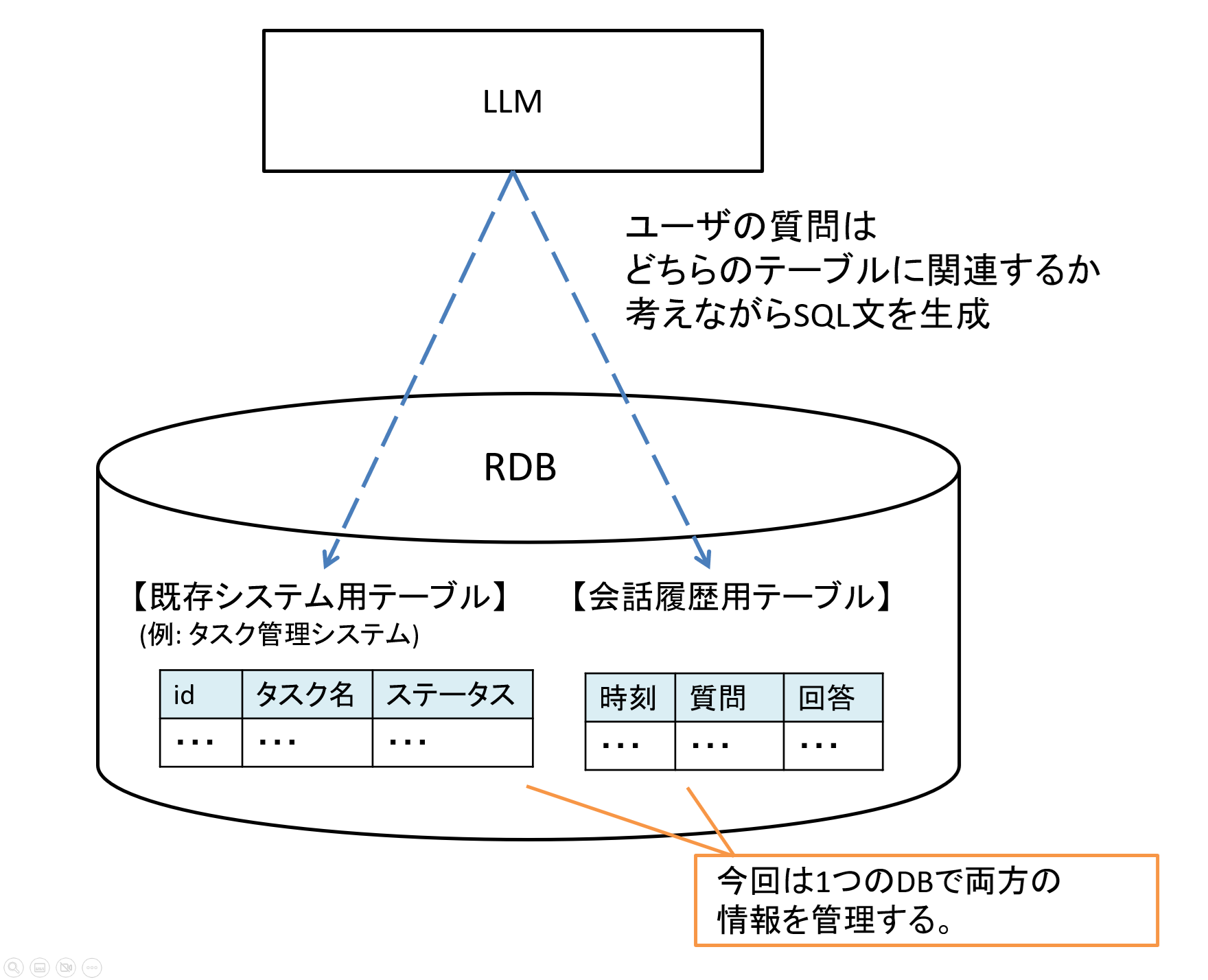
図8 今回のサンプルコードで扱うRDBの構成
また、サンプルコードを実行する為に事前にDBに情報がある事が望ましいです。
よって以下のようなデータがあることを前提とします。
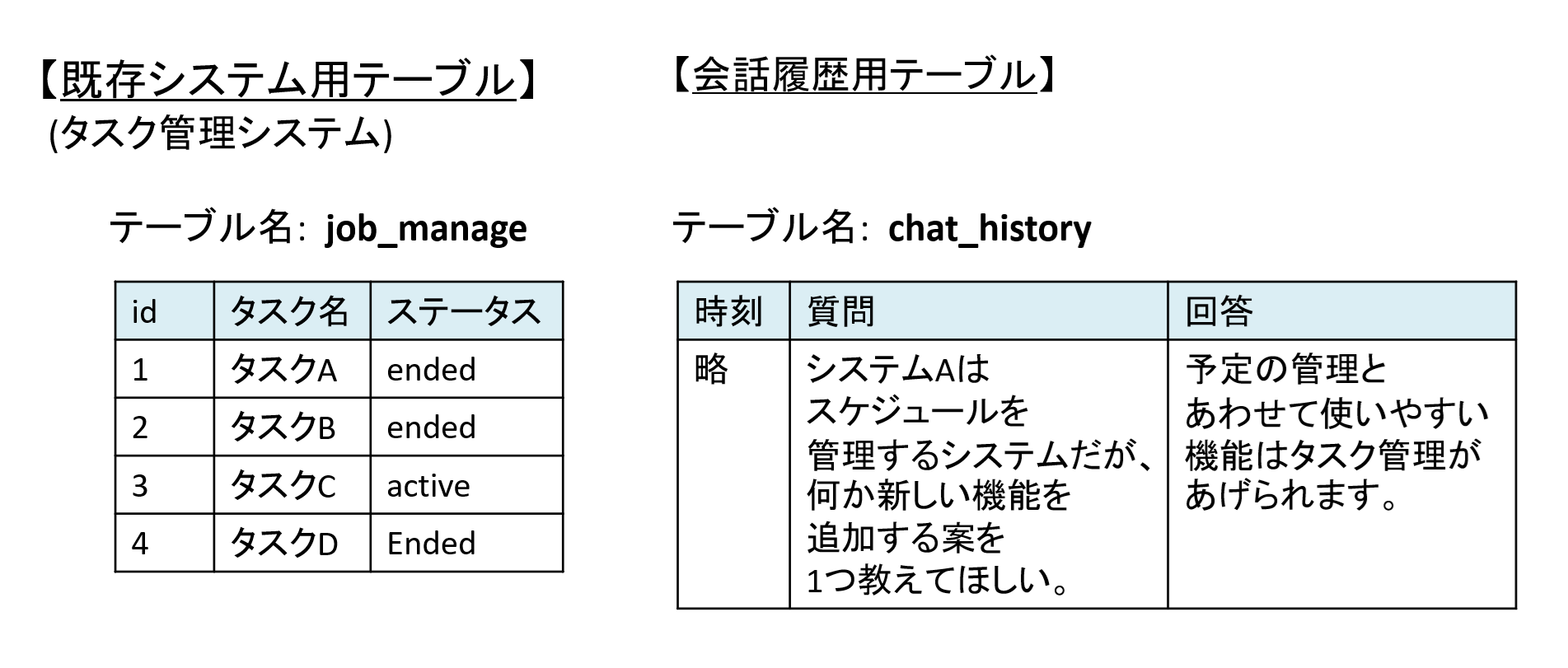
図9 サンプルコードを実行する際のRDB側の登録条件
上の図の状態とする為に以下を実行します。
# postgresコンテナにイン
docker exec -it rag_postgres bash
# postgresのSQL実行対話モードに移行
psql -U postgres -d postgres
# 必要なテーブルと情報登録
create table job_manage ( id int , task_name text, status text ) ;
insert into job_manage values (1, 'タスクA', 'ended'),(2, 'タスクB', 'ended'),(3, 'タスクC', 'active'),(4, 'タスクD', 'ended') ;
create table chat_history ( create_at timestamp primary key default current_timestamp , user_prompt text, llm_response text ) ;
insert into chat_history(user_prompt, llm_response) values ('システムAはスケジュールを管理するシステムだが、何か新しい機能を追加する案を1つ教えてほしい。', '予定の管理とあわせて使いやすい機能はタスク管理があげられます。') ;
これまで説明してきた前提をまとめた、全体の構成は以下の通りです。
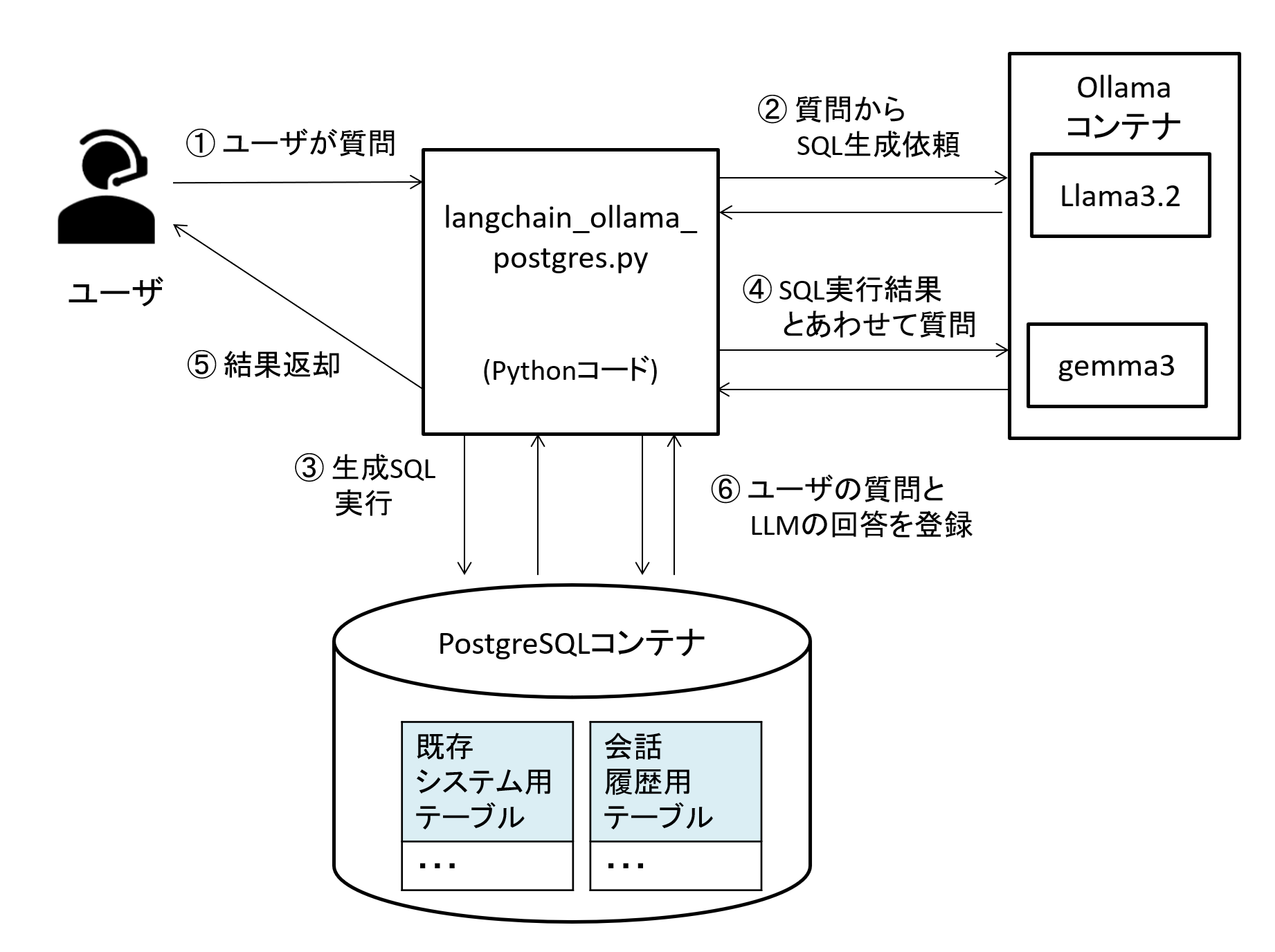
図10 今回のサンプルの構成
これで事前準備はできたので、次はソースコードの確認をしましょう。
実装例のソースコード全文と全体の構成について
まずは全体像を以下に示します。
この後にポイントとなる点を説明する為、ここでは細かく理解せずとも大丈夫です。
また、サンプルコードの為、最小限の実装(例えば例外処理は入れていない)となっている点はご承知おきください。
# 標準ライブラリ
import argparse
# LangChain関連ライブラリ
from langchain_community.utilities import SQLDatabase
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_ollama import OllamaLLM
# SQLAlchemy関連ライブラリ
from sqlalchemy import Column, DateTime, Text
from sqlalchemy.orm import declarative_base, Session, sessionmaker
# モデルやDBの定義
model_sql = OllamaLLM(model="llama3.2:3b", temperature=0.1)
model_answer = OllamaLLM(model="gemma3", temperature=0.1)
db = SQLDatabase.from_uri("postgresql://postgres:postgres@localhost:15432/postgres")
Base = declarative_base()
# ORM用クラス
class ChatHistory(Base):
__tablename__ = "chat_history"
create_at = Column(DateTime, primary_key=True, server_default=text("current_timestamp"))
user_prompt = Column(Text)
llm_response = Column(Text)
# 会話履歴をchat_historyテーブルに登録
def save_chat_history(result: dict):
SessionLocal = sessionmaker(bind=db._engine)
with SessionLocal() as session:
record = ChatHistory(
user_prompt=result["query"],
llm_response=result["result"]
)
session.add(record)
session.commit()
print("履歴登録完了。")
# LLMでの質問処理
def query_llm(user_pmt: str):
print(f"質問を受け付けました: {user_pmt}")
pmt_sql = ChatPromptTemplate.from_template('''\
あなたはSQL生成の専門家です。
以下のテーブル情報を踏まえ、ユーザの質問に回答する為の情報を取得するSQL文を生成する事。
なお、回答は```sql```といったマークダウンブロックは不要な為、SQL文のみ回答してください。
テーブル情報: """
{table_info}
"""
質問: """
{user_pmt}
"""
''')
pmt_answer = ChatPromptTemplate.from_template('''\
質問: """
{user_pmt}
"""
SQL文: """
{sql}
"""
SQL結果: """
{result}
"""
上記を基に自然な日本語で回答してください。
''')
sql_chain = (
{"table_info": lambda _: db.get_table_info(), "user_pmt": RunnablePassthrough()}
| pmt_sql
| model_sql
| StrOutputParser()
)
# RDBに問い合わせるためのSQL生成
gen_sql = sql_chain.invoke(user_pmt)
print("生成したSQL文: ", gen_sql)
# SQL実行
sql_result = db.run(gen_sql)
print("生成SQL文実行結果", sql_result)
# ユーザの質問とSQL実行結果をあわせてLLMに問い合わせ
answer_chain = (
{"user_pmt": RunnablePassthrough(), "sql": lambda _: gen_sql, "result": lambda _: sql_result}
| pmt_answer
| model_answer
| StrOutputParser()
)
answer = answer_chain.invoke(user_pmt)
print("LLMの回答: ", answer)
return {"query": user_pmt, "result": answer}
def main():
parser = argparse.ArgumentParser(description="LangChainベースのRAGシステム")
parser.add_argument("-q", "--query", type=str, help="LLMへ質問文を行う")
args = parser.parse_args()
if not args.query:
print("クエリ文字列が指定されていません。-h でヘルプを表示できます。")
return
result = query_llm(args.query)
save_chat_history(result)
if __name__ == "__main__":
main()
コードの全体構造は以下のようになっています。
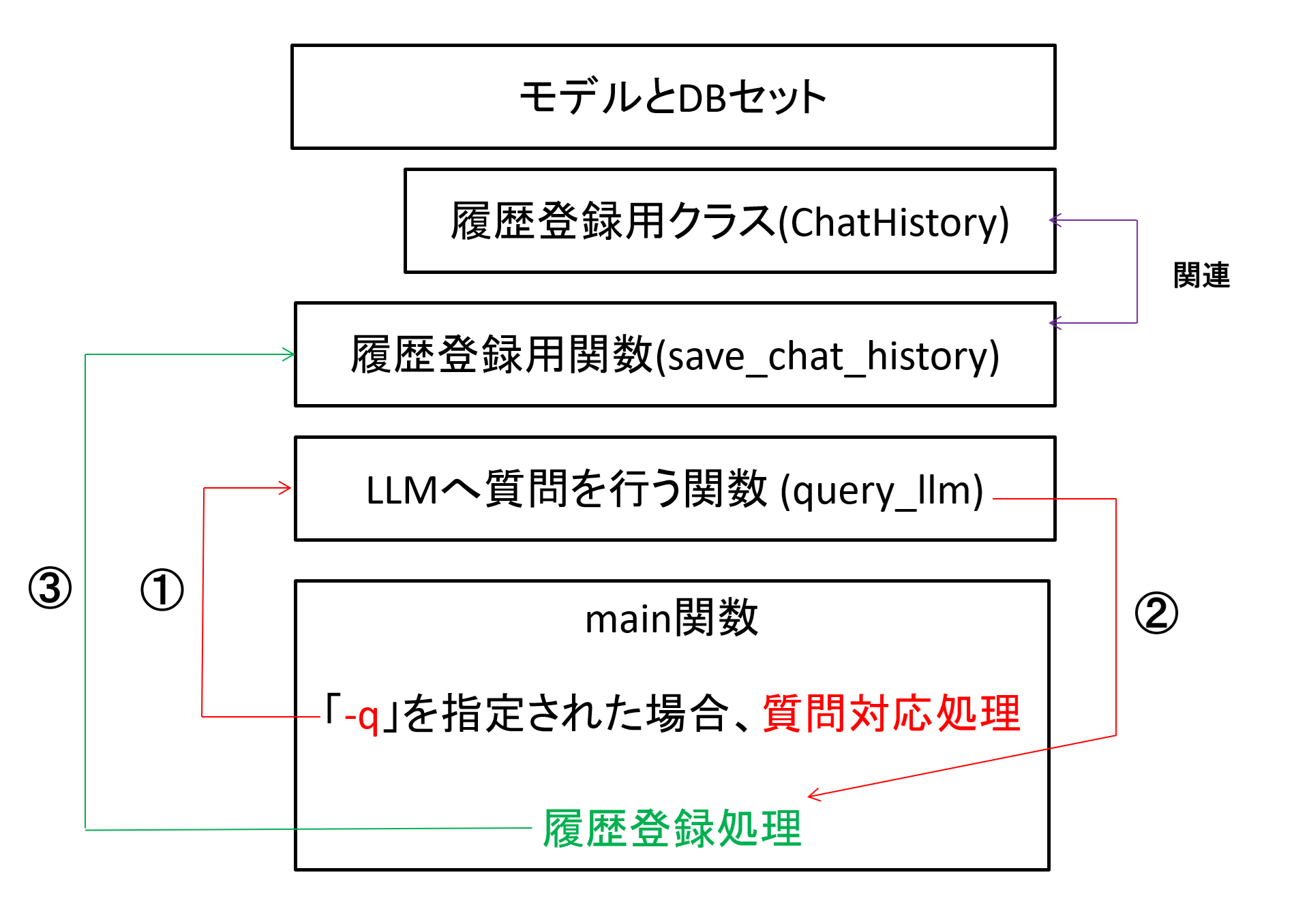
図11 サンプルコードの構成
細部のポイントについて
ここからは、今回のコードの主要なポイントを解説します。
なお、LangChainの使い方は第4回でも触れていますので、重複部分は省略します。
from langchain_ollama import OllamaLLM
model_sql = OllamaLLM(model="llama3.2:3b", temperature=0.1)
model_answer = OllamaLLM(model="gemma3", temperature=0.1)
今回はllama.3.2とgemma3の2つのモデルを使用しています。
例えばOpenAI社のモデルは汎用性が高く、Anthropic社のClaudeはコード生成に強いといった特徴が知られています。
このようにモデルごとの得意分野を意識して使い分ける事も重要な観点です。
今回の例では、gemma3にSQL生成をさせると、以下の図のようなフォーマット(Markdown形式)で回答されました。
Markdown形式で回答することで人の目でみる際にはわかりやすくなる一方、今回のように生成されたSQL文をそのまま実行する上ではエラーの原因となるため、SQL文以外の箇所(Markdown形式での記載)があるのはかえって不都合です。
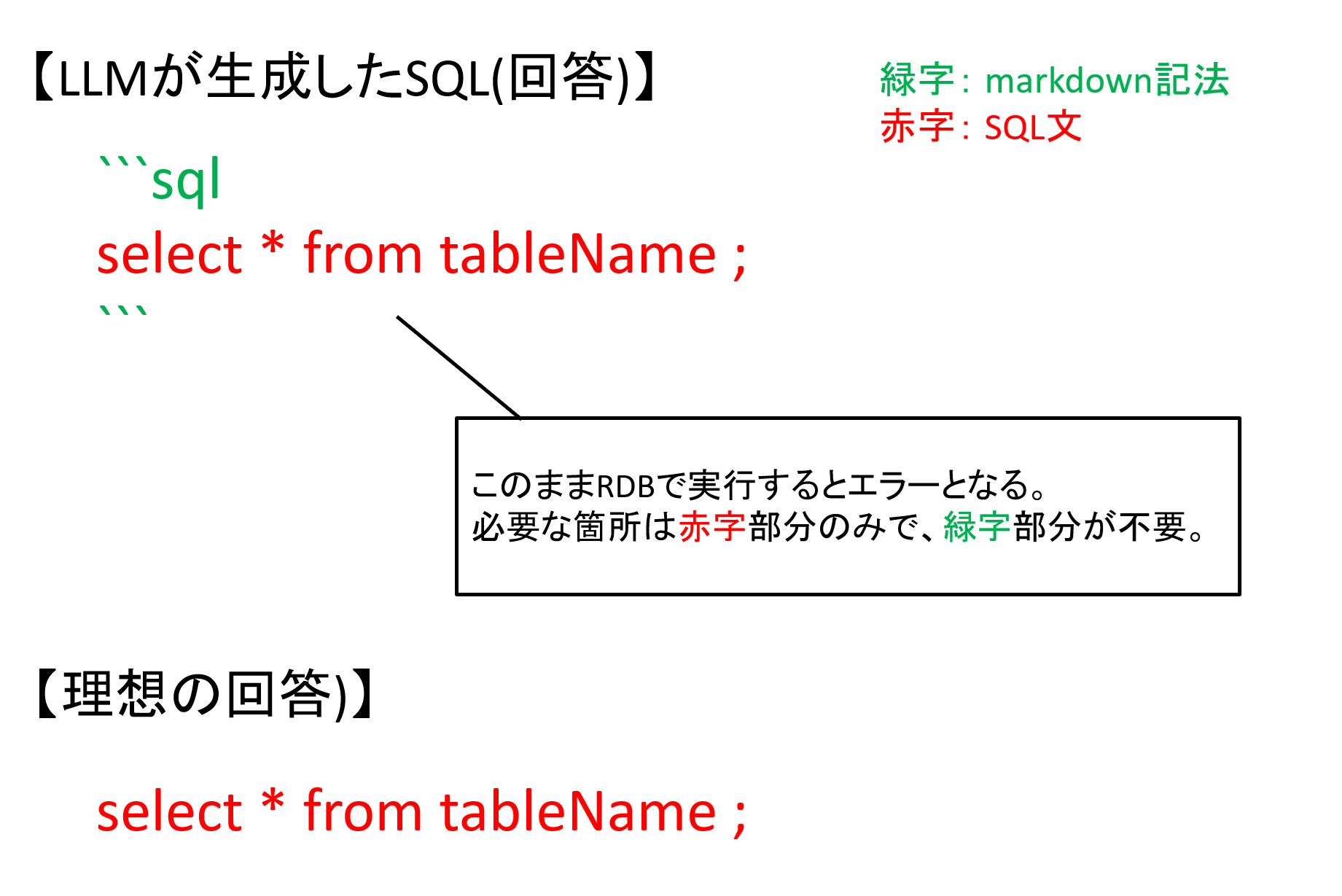
図12 モデルのSQL回答フォーマットと理想の回答フォーマット
この対策として「プロンプトにて出力形式を絞る案」や「生成後の回答から不要箇所をカットする(回答を整形する)案」が考えられます。
しかし前者は軽量モデルでは上手く機能しづらく、後者は実装コード量が増加します。
他方、Llama3.2を使ってSQL生成を行うと、SQL文のみで生成されました。
LLM自体が常に期待通り動くわけでもない為、本来であれば「回答整形案」をとるのが確実かと思いますが、今回はモデルの使い分けの一例としてLlama3.2でのSQL生成、gemma3でのその後回答生成という案をとっています。
from langchain_community.utilities import SQLDatabase
db = SQLDatabase.from_uri("postgresql://postgres:postgres@localhost:15432/postgres")
LangChainにはSQLでDBを扱う為の「SQLDatabase」ユーティリティが用意されています。
これはSQLAlchemyと呼ばれるデータベース操作ツールを利用しています。
SQLAlchemyにて接続DBを定義する際には「DBの種類://ユーザ名:パスワード@IPアドレス:ポート番号/接続DB」という書き方をします。
今回はRDBMSにpostgresを使っている為、postgresを指定していますが、SQLiteやMySQLなどの他のRDBMSでも対応できます。
また、dockerコンテナを立ち上げたときに指定したように、接続先はローカルホスト:15432としています。
| [補足] コードに直接接続先のDB名やユーザ名・パスワードを書きたくない場合 第7回をご確認ください。 |
|---|
次は関数の中身についてみていきます。
まずはRAG機能そのものであるquery_llm関数を説明します。
大枠としては以下の3段階に分かれています。
①SQL文を生成
②生成したSQL文を実行
③ユーザの質問に、SQL実行結果を付与してLLMに質問
このうちLLMに問い合わせは①と③で行っており、それぞれChainを定義しています。
なお、LangChainが提供する「SQLDatabaseChain」や「SQLDatabaseSequentialChain」を使えば、上の処理を一括で実行できます。
これは第7回で触れた「GraphCypherQAChain」と同様の動作イメージです。
ただし今回は軽量モデルを利用している為、安定性を考慮して、段階的に処理を書いています。
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
sql_chain = (
{"table_info": lambda _: db.get_table_info(), "user_pmt": RunnablePassthrough()}
| pmt_sql
| model_sql
| StrOutputParser()
)
# RDBに問い合わせるためのSQL生成
gen_sql = sql_chain.invoke(user_pmt)
上のコードではユーザの質問とRDBにあるテーブル情報と一部のデータ情報から、必要な情報を取得する為のSQL文を生成する為のChainを定義し、実行(invoke)しています。
このチェインのポイントは、「SQLDatabase」で定義したdbインスタンスの「get_table_info()」によって、RDBにあるテーブル情報とデータ情報を取得し、その結果をChatTemplateにて定義したプロンプトに渡している点です。
なお、get_table_info()の戻り値をそのまま渡すと文字型(str型)で扱われますが、ここで期待するのはRunnable(LangChain独自の概念)、callable(関数のように呼び出せるオブジェクト)、dict(辞書型)のいずれかです。
lambda関数もcallableとして判定される為、lambda _ を使う事でget_table_info() を適切にチェインに組み込めるようにしています。
sql_result = db.run(gen_sql)
answer_chain = (
{"user_pmt": RunnablePassthrough(), "sql": lambda _: gen_sql, "result": lambda _: sql_result}
| pmt_answer
| model_answer
| StrOutputParser()
)
answer = answer_chain.invoke(user_pmt)
return {"query": user_pmt, "result": answer}
生成したSQLを、dbインスタンスのrunにて実行しています。
その結果と生成したSQL文をプロンプトに渡すchain(answer_chain)を定義し、実行することでRAGとしての最終処理を行います。
この後にchat_historyテーブルに会話履歴を登録する為、ユーザの質問とLLMの回答を辞書型で返します。
ここまで見てきて気づいた方もいるかもしれませんが、今回はSQL生成とSQLの実行をそれぞれ1回実施しています。
テーブルは「job_manage」と「chat_history」の2つがありますが、今回SQLを生成するLLMはサイズの小さいモデルの為、高度な処理は難しく、どちらか一方のテーブルの情報のみを取得することが想定されます。
したがって、ユーザの質問によっては会話履歴テーブルとジョブ管理テーブルの両方から情報を取得するべきものもあるかと思いますが、より適切であるとLLMが考えたテーブルからのみ(片方からのみ)データ取得が行われると考えられます。
from sqlalchemy import Column, DateTime, Text
from sqlalchemy.orm import declarative_base, Session, sessionmaker
Base = declarative_base()
# ORM用クラス
class ChatHistory(Base):
__tablename__ = "chat_history"
create_at = Column(DateTime, primary_key=True, server_default=text("current_timestamp"))
user_prompt = Column(Text)
llm_response = Column(Text)
# 会話履歴をchat_historyテーブルに登録
def save_chat_history(result: dict):
SessionLocal = sessionmaker(bind=db._engine)
with SessionLocal() as session:
record = ChatHistory(
user_prompt=result["query"],
llm_response=result["result"]
)
session.add(record)
session.commit()
print("履歴登録完了。")
続いて会話履歴の登録処理ですが、これはまとめて解説します。
上の処理では、SQLAlchemyを用いてRDBに情報の登録を行っています。
ここでもLLMを使ってSQL文を生成し、データを挿入することも可能ですが、今回はユーザの質問とそれに対するLLMの回答を登録するという、データ構造も処理自体も固定されているケースであり、内容によって処理が変化することはありません。
そのため、LLMを使わず、ルールベースでの処理で十分対応できます。
LLMは出力に揺らぎがある為、処理内容が明確で変動のないケースでは、LLMを使わずに実装する方が良いでしょう。
SQLAlchemyによる登録処理はORMを活用しています。
ORMではプログラムレベルとDBのテーブル構成を紐づけて処理を行います。
この例ではChatHistoryクラスにて、DB側のテーブルにどのようなカラムがあるかを定義しています。
その上で、save_chat_history関数内で、引数として受け取った「ユーザの質問・LLMの回答」をどのカラムに登録するかを紐づけた後、addで登録をしています。
このようにORMを使うとSQLを書かずとも処理が可能です。
なお、SQLAlchemyではSQLを書いてデータ処理を行う事も可能です。
その場合は上の箇所は全部不要で、代わりに以下のように記載すると処理できます。
from sqlalchemy import text
def save_chat_history(result: dict):
with db._engine.connect() as conn:
conn.execute(
text("INSERT INTO chat_history (user_prompt, llm_response) VALUES (:user_prompt, :llm_response)"),
{"user_prompt": result["query"], "llm_response": result["result"]}
)
conn.commit()
print("履歴登録完了。")
実行例と結果について
ここではこのコードの実行例を記載します。
python langchain_ollama_postgres -q "タスクDのステータスはどういう状態か。
質問を受け付けました: タスクDのステータスはどういう状態か。
生成したSQL文: SELECT status FROM job_manage WHERE task_name = 'タスクD';
生成SQL文実行結果 [('ended',)]
LLMの回答: 'タスクDは完了(ended)状態です。
履歴登録完了。
対象のDBには「chat_history」と「job_manage」の2つのテーブルがありますが、ユーザの質問からどちらから情報を取得するべきか含め判定できています。
今回の実行例(ユーザの質問)は「job_manage」テーブルから情報をとって回答すべき質問でしたが、chat_historyから情報をとるべき質問を与えれば、LLMの判断の上、該当テーブルから情報を取ってくれるのではないかと思います。
ただし、今回の例でいえば「タスクDの状態はどうか?」のように、取得すべき列名(status)と異なる言い方をすると精度は不安定化します。
第7回と同様、SQLの生成自体をLLMに任せている為、利用するLLMの精度に、RAG自体の精度も大きく依存します。
LLM自体の精度に頼らずに仕組みの工夫により精度を上げる方法としては、Agentを作る時の考え方に近いですが、「生成したSQL文をLLMに添削させる(見直しさせる)」方法や「Sandbox環境で動くか確認する」などが一例としてあげられます。
今回は軽量モデルを使っていることもあり、全体的な精度には課題があるものの、近年の小型モデルの進歩を考えると今後より実用性が高まっていくかもしれません。
その他 気を付けるべきポイント
まず、LLMにSQLを生成させる場合、ユーザの質問によってはdelete文やtruncate文といったデータ削除や、全件データ取得などの管理者の意図せぬ操作がされてしまう場合があります。
この点は第7回と同様で、実運用では注意が必要です。
1つの対策として、DB側で参照可能なテーブルや実施可能な操作(selectのみに限定するなど)を権限管理により絞り込むと良いでしょう。
具体的にはロールやビューを使うと良いかと思います。
| [補足] ロールやビューについて 少し宣伝とはなってしまいますが、これらについて気になる方は「SQL100本ノック+α 第3章」をご確認ください。 |
|---|
また今回ユースケースの1つとしてあげた「既存システムへの適用」についてですが、導入によるDBのコネクションの枯渇や既存処理の性能影響に注意が必要です。
これも対策の一例となりますが、ストリーミングレプリケーション(SR)により冗長化をしている場合はMaster側ではなく、Slave側に対して問い合わせを行いましょう。
RAGでの用途は参照に限られるため、書き込み・更新操作がブロックされているSlave側を利用することは性能面でも安全面でも都合が良いかと思います。
ただし、既存システムでもSlave側DBに対して参照処理を実行している場合、性能影響に関する懸念は残ります。
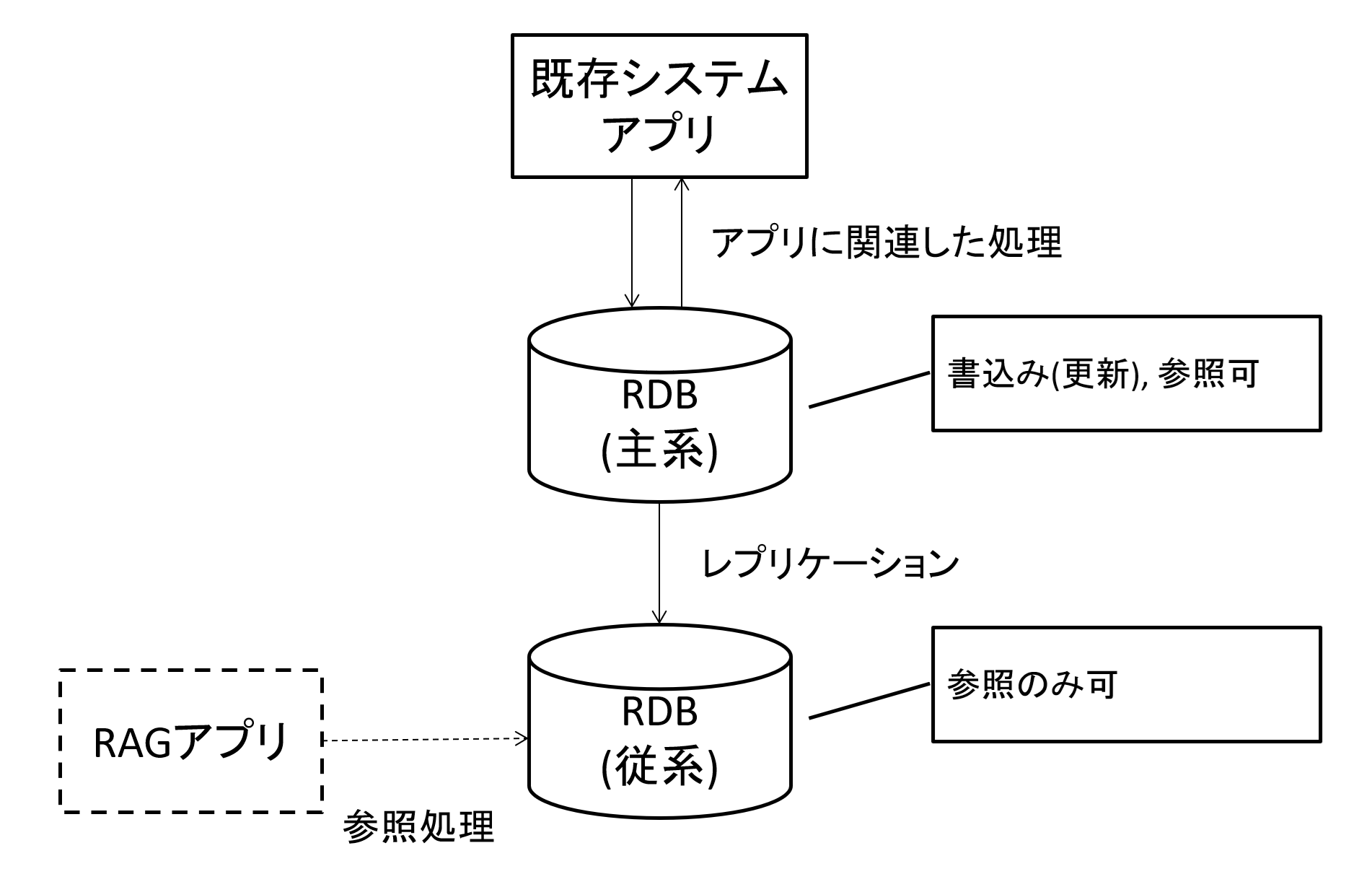
図13 SRを活用したRAG構成の例
新たにレプリケーション用のサーバ(RAG専用DB)を用意し、RAGとして使う場合はそのDBで処理を行う、という案もありかと思います。
会話履歴として使う場合は、ユーザが使えば使うほどデータは蓄積されていきます。
無制限に保存データが増える状態は好ましくない為、適切なデータ削除ルールを整理しておく必要があります。
例えばユーザがLLMとの対話ルーム(スレッド)を削除したタイミングでDBからも削除する方法や一定時間経過による削除などの対策があげられます。
用途やシステム要件にあわせて検討しておきましょう。
なお、お気づきの方もいるかもしれませんが、今回はサンプルとして単一ユーザの利用を想定していた為、chat_historyテーブルではcreated_at列(時刻情報)に主キーを設定していました。
主キーには一意性制約(重複禁止)があるため、複数ユーザが同時に利用するような環境では登録時刻が重なる可能性があります。
よって、上のような運用を想定する場合にはこのような設計は避けた方が良いでしょう。
また今回はテーブル数が2つしかなく、それぞれが独立している(joinのような結合処理が不要なテーブル構成)、シンプルなテーブル構成でした。
より実践的な構成で精度を上げていく為には、使用するLLMの変更も含めた、様々な改善が重要になると考えます。
おわりに
これまでベクトルDB・グラフDB・RDBといった様々なDBMSを活用したRAGについて紹介してきました。
それぞれが異なる特徴や強みがあり、ユースケースも異なります。
また、情報取得の手段はDBに限らず、インターネット検索や各種サービスのAPIを活用する方法もあります。
※ 第1回の例はAPIを使った他システム連携を題材としていましたが、これもRAGの一種といえます。
このようにモデルの知識を補完する為の情報取得方法には様々な選択肢があります。
そこでユーザの質問に応じて、どこから情報を取得するか判断して処理する統合型RAGを構築するのも有効です。
このように自律的に判断を行い、動的に処理を変えるRAG構成をAgentic RAGと表現する場合もあります。
次回は少し内容を変えて、モデル自体に変更を加えるファインチューニングについて紹介したいと思います。
本件に関する質問やコメントなどがございましたら、以下からお問い合わせください。
今回もご覧いただきありがとうございます。
本件に関するお問い合わせ




<<<<著者プロフィール>>>>
フューチャーネットワーク事業部
第一ビジネスユニット
山口 佳輝(YAMAGUCHI YOSHIKI)
NWに関係したシステム開発を担当しています
>>>>>>>>><<<<<<<<<
![]()