ローカル環境で動かす、グラフRAGの基礎 ~LLM活用入門7回~
本記事ではグラフRAG(GraphRAG)とは何かという点からLangChainとNeo4jを使ったシンプルなGraphRAGサンプルコードについて紹介します。




はじめに
こんにちは、NTTテクノクロス 山口です。
本連載の第3回~第6回まではベクトルDBを用いたRAGについて紹介してきました。
今回は上とは少し考え方の異なるRAGである「グラフRAG(GraphRAG)」について触れていきたいと思います。
以下の目次にそって、グラフRAGの基礎をご紹介します。
● 目次
| 節番号 | 節タイトル |
|---|---|
| 1 | グラフRAGとは |
| 2 | シンプルな実装例と実行例 |
| 3 | 実装の改善例 |
[参考] 本連載の記事
本記事とあわせて、以下も良ければご確認ください。
| 連載番号 | タイトル | 概要 |
| 第1回 | 今だから知っておきたいDify!ノーコード・ローコードでLLM活用基盤を作ろう | Dify自体の説明とChatflow機能を使った例を取り上げています。 |
| 第2回 | 爆速キャッチアップ!LLM活用をリードするプラットフォーム群 | LLMの可能性をより広げるDify/Ollama/LangChain/Hugging Faceの紹介と、 DifyとOllamaでローカルLLMを活用したChatflow機能の利用に関して取り上げます。 |
| 第3回 | RAGとは?Difyから基本を学ぶ | RAGの基礎的な説明とDifyを使った実現方法を取り上げています。 |
| 第4回 | ローカルモデル利用のRAG実装で学ぶLangChainの基礎 | ベクトルDBを用いたRAGのサンプルコードから、LangChainの基礎を解説します。 |
| 第5回 | ローカルモデル利用のRAG実装で学ぶLlamaIndexの基礎 | ベクトルDBを用いたRAGのサンプルコードから、LlamaIndexの基礎を解説します。 |
| 第6回 | Difyで学ぶ、RAGの精度改善手法 | RAGの精度改善手法をDifyのChatflow機能を使いながら紹介します。 |
| 第7回 | ローカル環境で実現する、GraphRAGの基礎 | GraphRAGの基礎から、LangChainとNeo4jを使ったグラフRAGの実装例を紹介します。 |
| 第8回 | ローカル環境で実現する、Text-To-SQLとRDBを用いたRAG | Text-To-SQLと、それを活用したRDBを用いたRAGの実装例を紹介します。 |
| 第9回 | ファインチューニングとは?基礎を理解する | ファインチューニングとそのユースケース、手法を紹介します。 |
| 第10回 | Hugging Faceライブラリで実行する推論と学習の基礎(前編) | Hugging Faceのライブラリを使った、モデルのダウンロードや推論処理について紹介します。 |
| 第11回 | Hugging Faceライブラリで実行する推論と学習の基礎(後編) | Hugging Faceのライブラリを使った、ローカルモデルの学習処理と実行例について紹介します。 |
| 第12回 | AIエージェントとは?Difyから考え方を学ぶ | AIエージェントについて、Difyでの動作イメージも含めて紹介します。 |
| 第13回 | MCPとは?AIエージェントの可能性を広げよう | AIエージェントの可能性を広げる技術であるMCPについて紹介します。 |
グラフRAGとは
グラフRAGは、以下のようなデータの持ち方・表現ができるグラフDBを用いたRAGの事を指します。
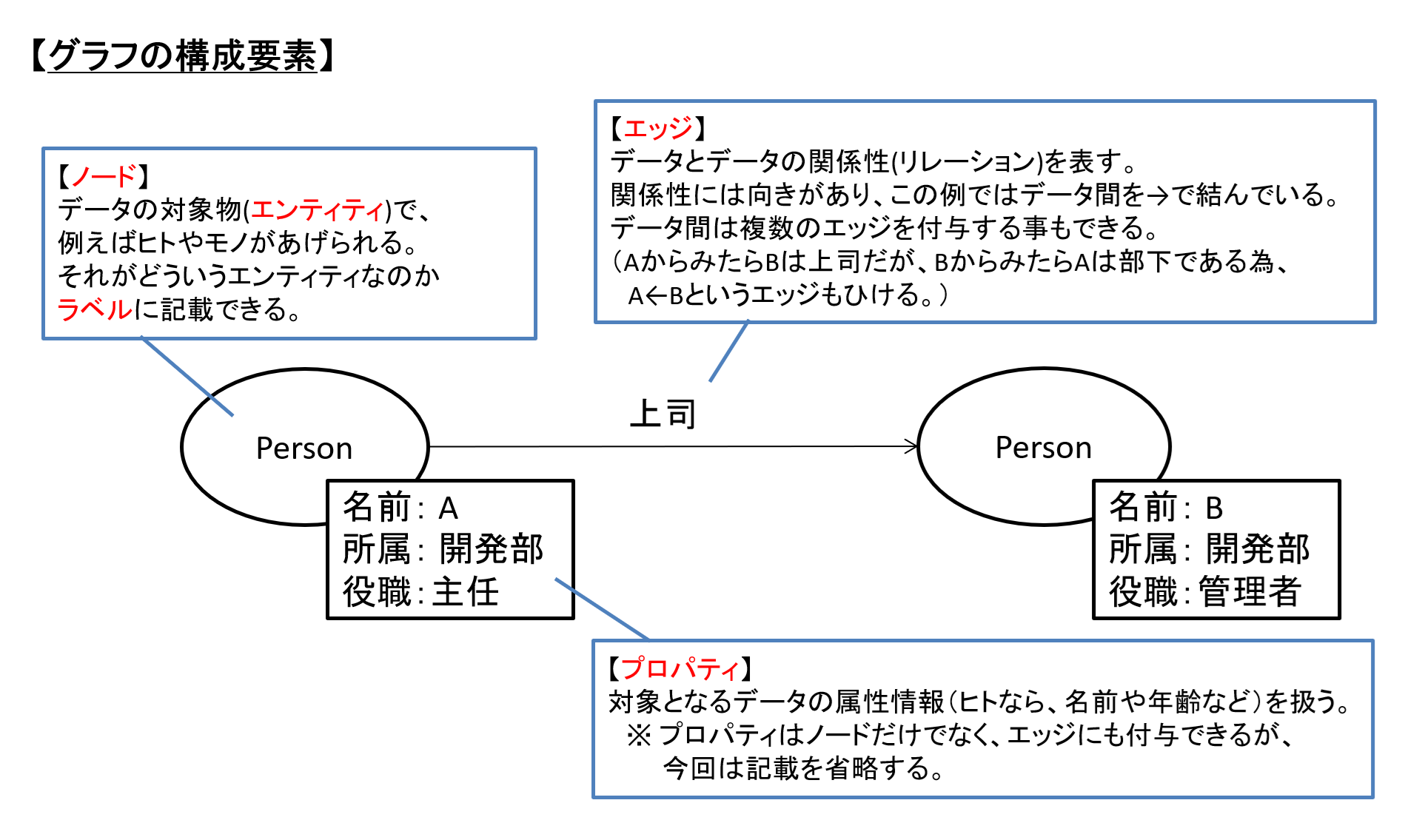
図1 グラフのイメージと構成要素
「グラフDB」のグラフとは「折れ線グラフ」や「棒グラフ」のようなものではなく、ネットワーク上の構成を持った形式とわかるかと思います。
さて、グラフの構成要素としては図1の通りですが、グラフを表示する際には一般的にノード上にラベルではなく、プロパティの値を使います。
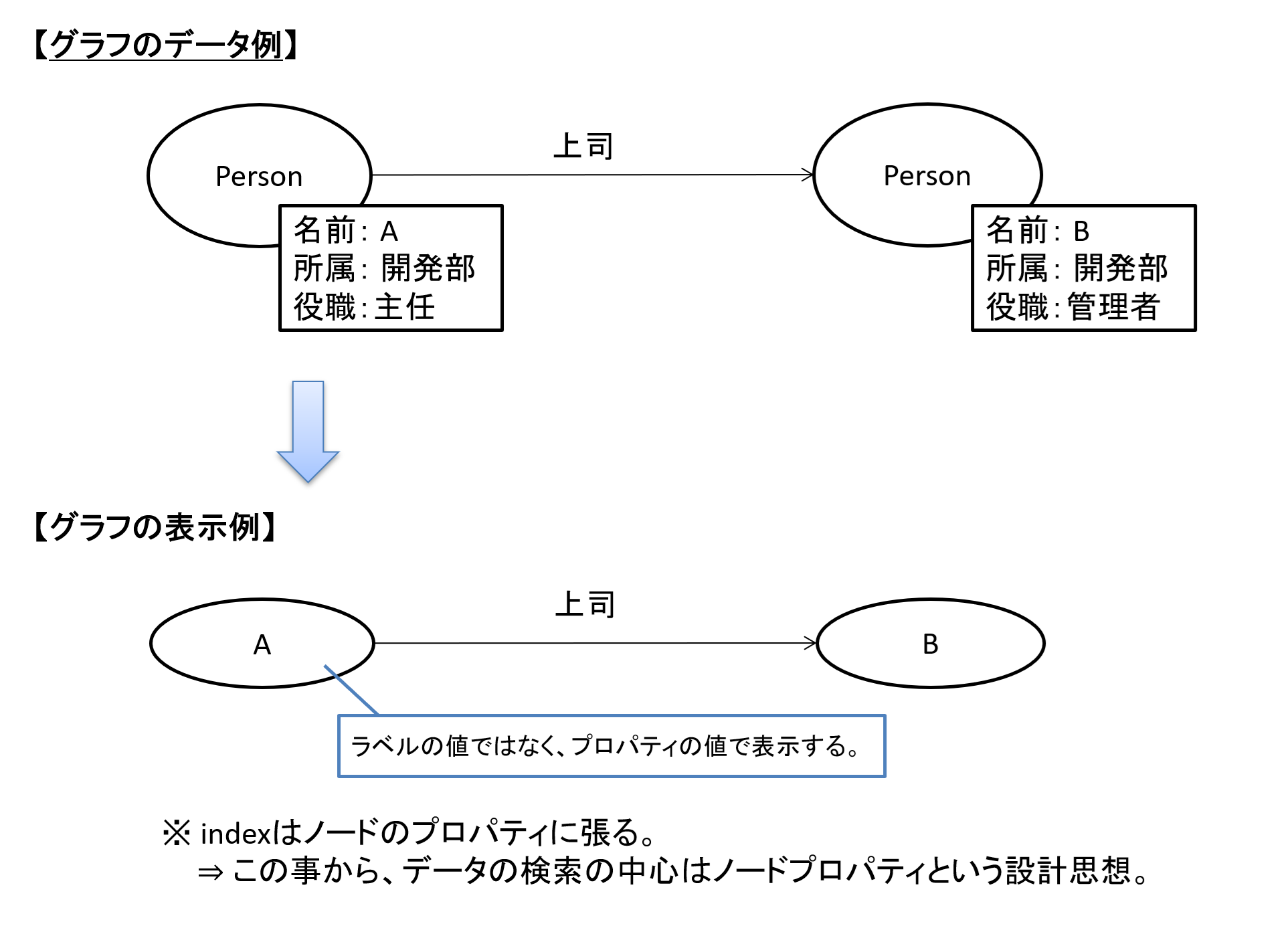
図2 グラフの表示例
本記事でも今後はこのように記載します。
グラフDBは、データ同士の関係を表現したり、関係を取得したりすることが得意です。
この得意分野を活かしてSNSのアカウント同士のつながりや人間関係、路線図などの情報を表すために使われてきました。
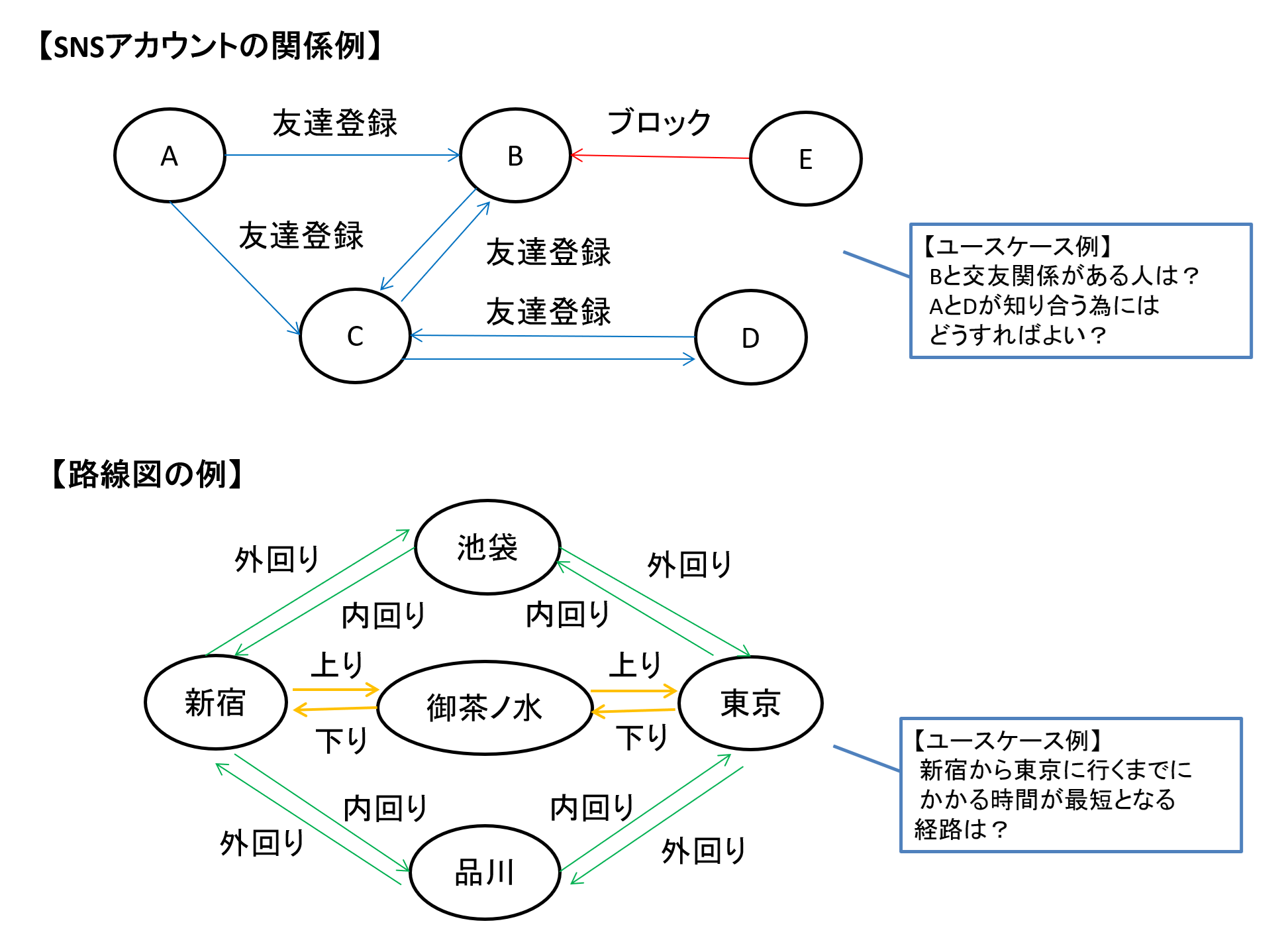
図3 グラフDBの使い方イメージ
近年は上で述べた強みを活かして、対象となる情報をグラフ形式で表現・保有してLLMの知識補完を行う「グラフRAG」という使い方が注目されています。
これまで紹介してきたベクトルDBを用いたRAGは意味的に近しい情報の取得に長けていましたが、グラフRAGは対象となるエンティティ(ヒトやモノ)に関係するエンティティを取得することが得意分野となります。
例えば「ドキュメントAとドキュメントBに共通する事項は?」「XXに関連するルールは?」といった、関係性を意識できていないと回答しづらい質問に対して向いているといえます。
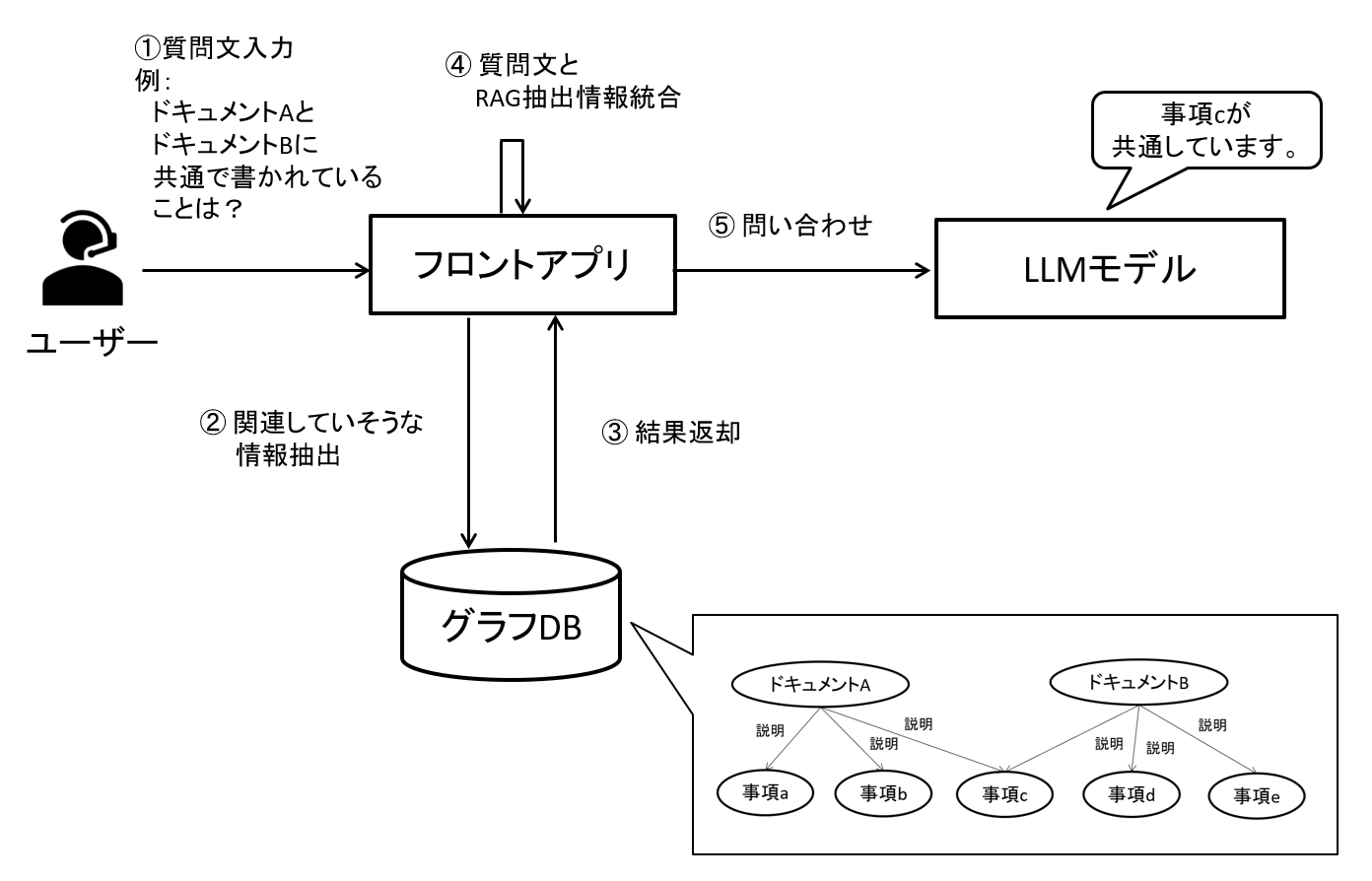
図4 ドキュメントに関する質問回答のイメージ
このように、意味的に近しい情報を取得するベクトルRAGとは、扱いが異なる事がわかるかと思います。
とはいえ、DBでのデータの持ち方が変わるだけで、RAGそのものの考え方・仕組みは変わりません。
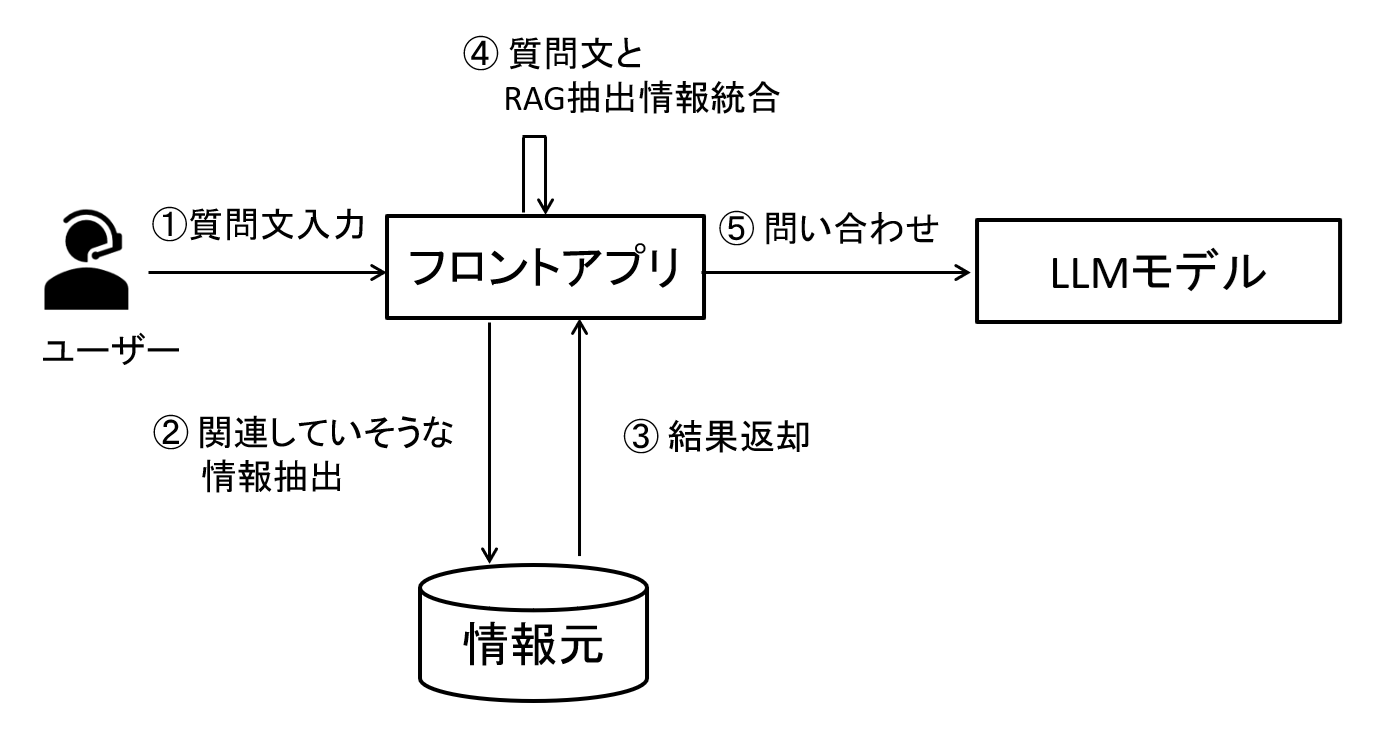
図5 RAGの考え方の本質
グラフRAGによりユーザの質問に適切に回答できるかは、対象とするデータを上手くグラフ形式(※)にできるか、また検索して上手く必要な情報をとれるかにもよります。
この点はベクトルDBを用いたRAGと同様で、グラフDBかベクトルDBかというよりRAG自体の特徴と言えるかと思います。
※ 対象とする情報をグラフ形式で表現したものを「ナレッジグラフ(Knowledge Graph)」と呼びます。
さて、グラフRAGを利用する上で最も手軽な手法はMicrosoft社がOSSで提供しているgraphrag(※)を利用する事でしょう。
※ https://github.com/microsoft/graphrag
上と比較すると敷居は上がりますが、代案としてLangChainやLlamaIndexを使って自前で作る案があります。
今回は小型ローカルLLMモデルで動かすという点とシンプルな構成から説明できると良いかと思いましたので、後者(LangChain)を使った実装で説明をしたいと思います。
シンプルな実装例と実行例
本節では、LangChainを使って実現するシンプルなグラフRAGの実装例とその説明を行います。
構成の全体像は以下となります。
※ 各ツールのセットアップなどはこの後紹介するため、ここでは概要を掴んでいただければ、と思います。
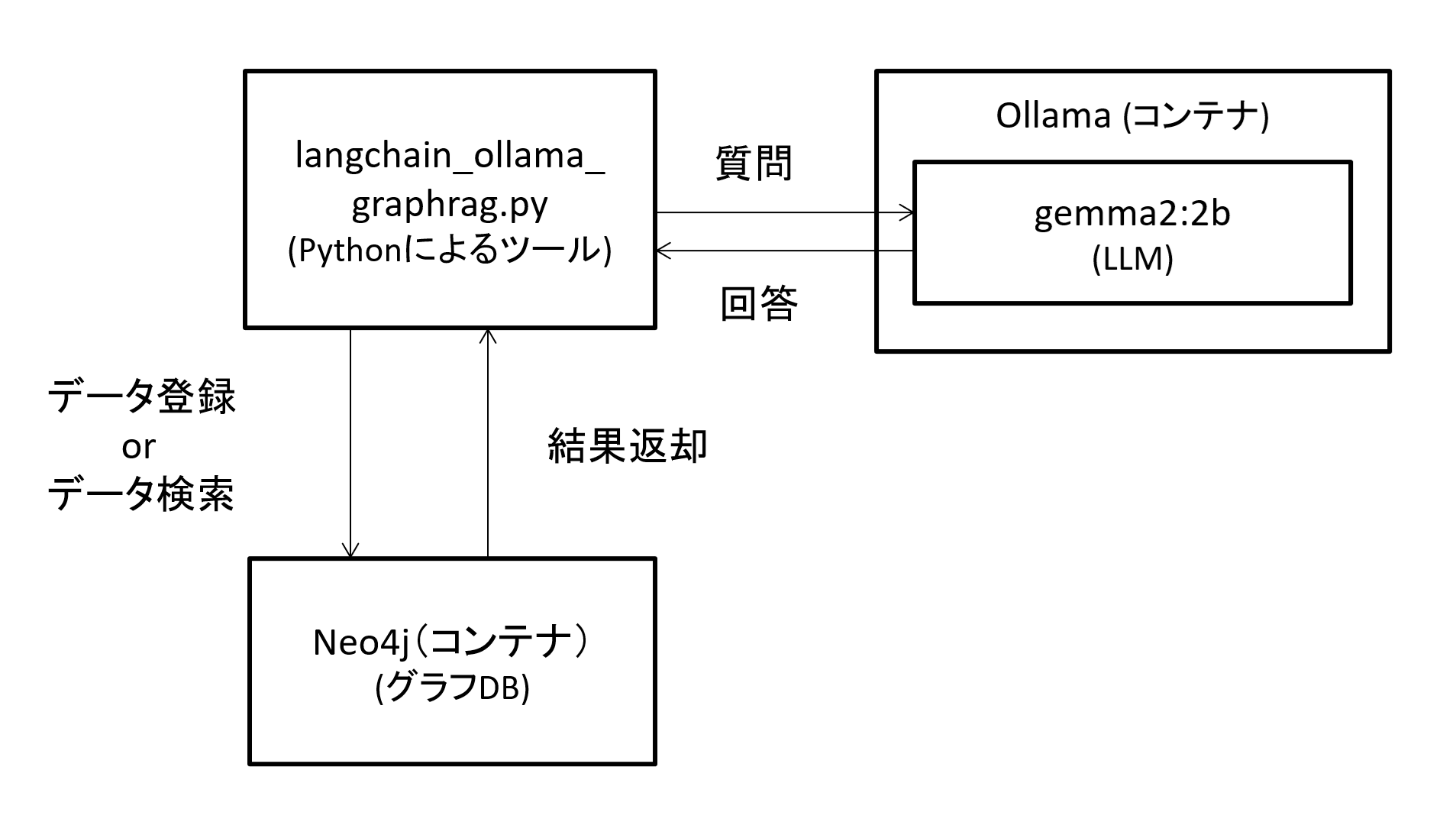
図6 全体の構成概要
前提について
まず、利用するOSSやライブラリのバージョンは以下の通りです。
※ 本記事の内容を用いた開発・運用は、必ずご自身の責任と判断によって行ってください。
開発・運用の結果について、いかなる責任も負いません。
■ ツールバージョン
Python 3.10.13
Ollama 0.6.6
Neo4j 5.26.0
■ ライブラリ
Package Version
---------------------------------------- ---------------
langchain 0.3.26
langchain-community 0.3.26
langchain-core 0.3.66
langchain-experimental 0.3.4
langchain-neo4j 0.4.0
langchain-ollama 0.3.3
langchain-openai 0.3.27
langchain-text-splitters 0.3.8
neo4j 5.28.1
pypdf 5.6.1
今回はタイトルの通りローカルモデルを利用するため、OpenAIモデルは利用しませんが、「langchain-openai」はpip installしておく必要があること、ご注意ください。
グラフDBにも様々な種類がありますが、今回はNeo4jを利用したいと思います。
Neo4jにはクラウド型もありますが、今回はdockerコンテナを利用しローカルで動作させます。
ローカルコンテナのNeo4jを利用してRAGを作る場合、拡張ツール(contrib, apoc)が必要となります。
docker runコマンドでコンテナ起動時に「NEO4JLABS_PLUGINS」を指定することで必要なツールが自動で読み込まれます。
拡張ツールについては以下を必要に応じて確認ください。
※ ダウンロードサイト:https://github.com/neo4j-contrib/neo4j-apoc-procedures/releases
以下にNeo4jのコンテナ起動の実行例を記載します。
docker pull neo4j:5.26.0
docker run -d --name neo4j -p 7474:7474 -p 7687:7687 \
-e NEO4JLABS_PLUGINS='["apoc"]' \
neo4j:5.26.0
今回はサンプル用の為、Neo4j(DB)のデータ永続化を行っていません。
よってコンテナを削除するとデータも消える動作となります。
正しく拡張ツールを読み込まれているか確認する為にコンテナ起動後に以下を実行しましょう。
# neo4jコンテナ内にインする
docker exec -it neo4j bash
# neo4jのクエリ実行モードに移行する。
# 初回はID/PWと変更するPWをきかれる。初期ID/PWはどちらもneo4j。変更するPWは任意。
cypher-shell
# クエリ実行モードで以下を実行。オレンジ文字の情報が表示されればOK。
cypher return apoc.version() ;
+----------------+
| apoc.version() |
+----------------+
| "5.26.0" |
+----------------+
# クエリ実行モードから抜ける
:exit
Neo4jコンテナが起動したら、ブラウザからNeo4jにアクセスしてみましょう。
ブラウザのURL欄に「http://[IPアドレス]:7474/browser/」を入れてみましょう。
問題なくアクセスできれば、以下のような画面が表示されるはずです。
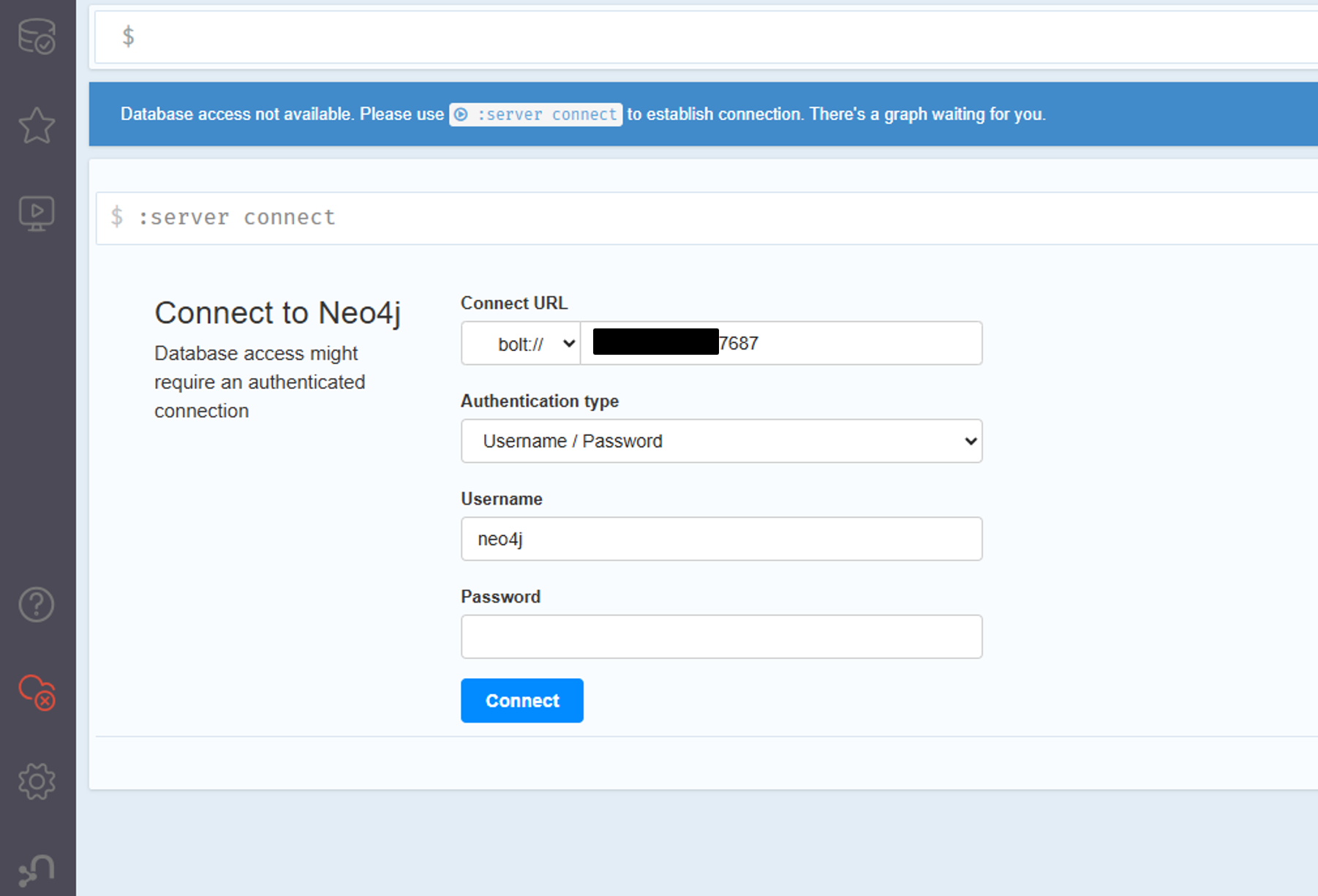
図7 Neo4jにブラウザにて初回アクセスした際の画面
Connect URLなどはそのままとし、Cypher-Shellでログインした際に変更したパスワードを入力してログインしましょう。
ログイン後、「match (n) return n」を実行して、何も表示されない事も確認します。
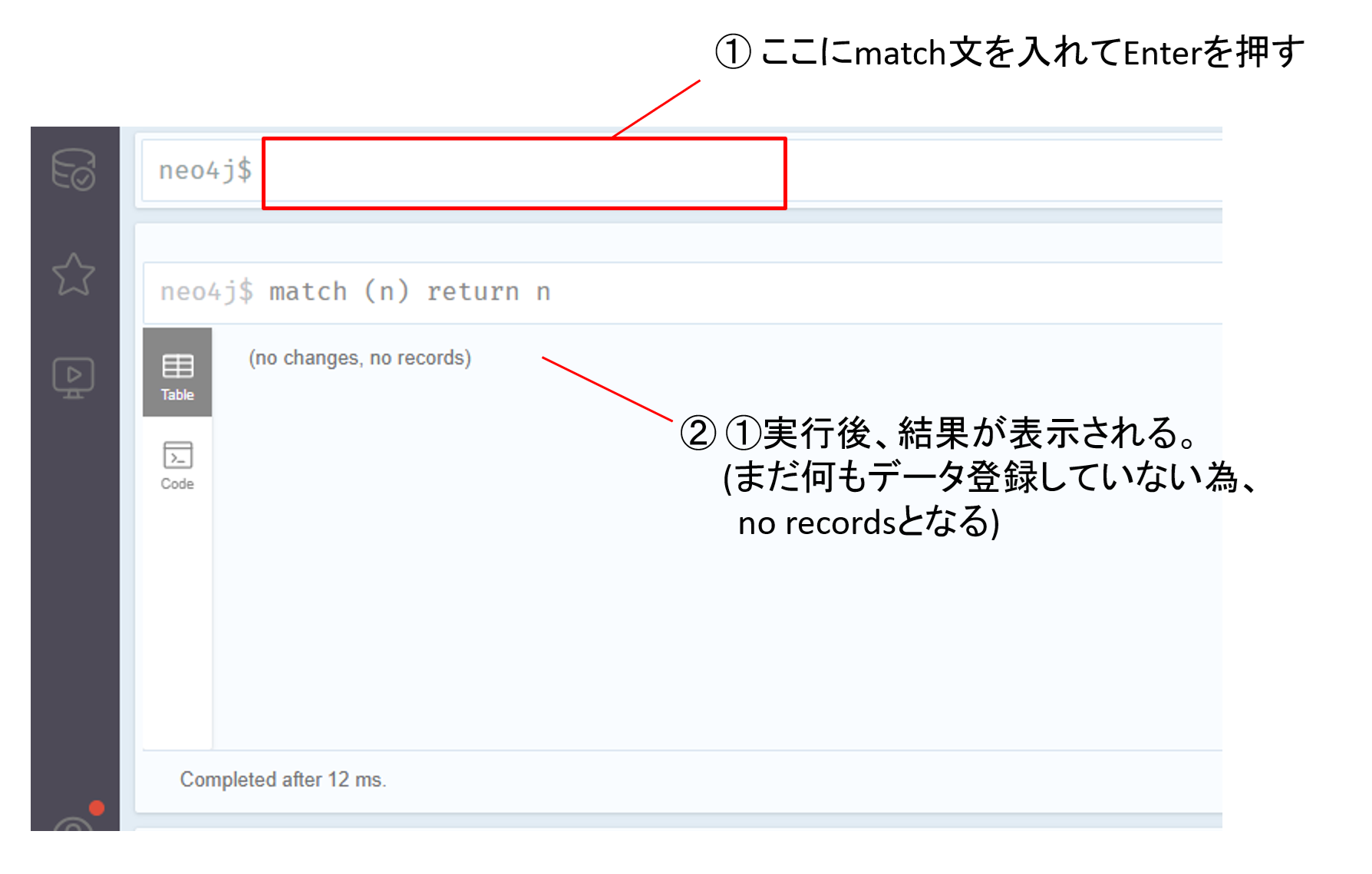
図8 ログイン後に実施する動作確認について
実行したクエリは登録済の全ノードを表示するものです。
match文は指定した条件のデータを取得する為の文法で、イメージ的にはSQLでいうwhere句に近いかと思います。
return句で、matchにて指定した条件のデータを表示する為、こちらはSQL文でいうselect文のような役割です。
このように、Neo4jは従来のRDBで使うようなSQL文ではなく、グラフ形式操作用の言語であるCypherクエリ言語を用いて操作します。
参考までに上記で用いたmatch~return文の文法の一例を以下に示します。

図9 match~return文の文法一例
初回アクセスでの動作確認で試したmatch~return文は、関係性の有無に限らず(独立したノードも含め)ノード全てを取得するクエリ文であった、ということがわかるかと思います。
今回利用するLLMのモデルはOllama上で動くgemma2:2bモデルとしたいと思います。
Ollamaコンテナ上でのモデル(gemma2:2b)のダウンロードは以下の通りです。
# Ollamaコンテナにインする。Ollamaコンテナが起動している前提。
docker exec -it ollama bash
# モデルダウンロード
ollama pull gemma2:2b
実装例のソースコード全文と全体の構成について
続いてLangChainを用いた実装例(全体像)を記載します。
コードの全体構成としては、第4回で記載した簡易なRAGツールと同様です。
# 標準ライブラリ
import argparse
# LangChain関連ライブラリ
from langchain_community.document_loaders import DirectoryLoader, PyPDFLoader
from langchain_experimental.graph_transformers import LLMGraphTransformer
from langchain_neo4j import Neo4jGraph, GraphCypherQAChain
from langchain_ollama import OllamaLLM
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 以下処理
graphdb = Neo4jGraph(
url="bolt://IPアドレス:7687",
username="neo4j",
password="password",
)
model = OllamaLLM(model="gemma2:2b", base_url="http://localhost:11434", temperature=0.1 )
def create_index():
print("ドキュメントを読み込んでDBに登録します。")
# ローカルディレクトリに配置したファイルの一覧取得
ldr = DirectoryLoader(
"./local_documents", # 登録するドキュメントを配置するローカルディレクトリパス
glob="*.pdf",
loader_cls=PyPDFLoader
)
#ドキュメントの読み込みを実施
raw_docs = ldr.load()
# 読み込んだドキュメントをチャンクに分割
txt_sp = RecursiveCharacterTextSplitter(chunk_size=250, chunk_overlap=24)
docs = txt_sp.split_documents(raw_docs)
# 文字情報からグラフ情報へのコンバート
llm_graph_transformer = LLMGraphTransformer(llm=model)
graph_docs = llm_graph_transformer.convert_to_graph_documents(docs)
# GraphDBに登録(indexing)
graphdb.add_graph_documents(graph_docs, baseEntityLabel=True ,include_source=True)
print("インデキシングが完了しました。")
def del_index():
print("データベースをクリアします。")
graphdb.query("MATCH (n) DETACH DELETE n")
print("データベースのクリアが完了しました。")
def query_llm ( user_pmt: str):
print(f"質問を受け付けました: {user_pmt}")
chain = GraphCypherQAChain.from_llm(graph=graphdb, llm=model, verbose=True,allow_dangerous_requests=True )
ai_msg = chain.invoke(user_pmt)
print(f"LLMの応答: {ai_msg}")
def main():
parser = argparse.ArgumentParser(description="LangChainベースのRAGシステム")
parser.add_argument("-a", "--add", action="store_true", help="ドキュメント登録・インデックス作成")
parser.add_argument("-d", "--delete", action="store_true", help="データベースクリア")
parser.add_argument("-q", "--query", type=str, help="LLMへ質問文を行う")
args = parser.parse_args()
if args.add:
create_index()
elif args.delete:
del_index()
elif args.query:
query_llm(args.query)
else:
print("いずれかのオプションを指定してください。-h オプションで使用方法を確認できます。")
if __name__ == "__main__":
main()
細部のポイントについて
以降でポイントとなる点について紹介していきます。
なお、LangChainの基本的な使い方は第4回で触れていますので、同様の解説となる点は省略します。
まず、LangChainにはneo4jを扱う為のライブラリも用意されており、下記のようにグラフDBを扱う為の情報を定義します。
boltの箇所は、ログイン時の「Connect URL」欄に表示された情報を指定します。
from langchain_neo4j import Neo4jGraph
graphdb = Neo4jGraph(
url="bolt://IPアドレス:7687",
username="neo4j",
password="password",
)
ソースコードにそのまま埋め込むことを避けたい場合は、.envファイルを用意した上で、ソースコードをload_dotenvで読み込む案があります。
あるいは.envファイルの各変数の前に「export」を入れて、ソースファイルを実行する前にsourceコマンドで.envファイルを読み込んで環境変数としておく案もあります。
ここでは一例として、前者を以下に記載します。
● .envファイル
NEO4J_URI=bolt://IPアドレス:7687
NEO4J_USERNAME=neo4j
NEO4J_PASSWORD=password
● ソースコード
from dotenv import load_dotenv
load_dotenv()
graphdb = Neo4jGraph()
以下利用するモデルの指定コードで、第4回と大きく変わりませんが、temperatureオプションを追加しています。
model = OllamaLLM(model="gemma2:2b", base_url="http://localhost:11434", temperature=0.1 )
このオプションは0~1の範囲の値を渡すことで、どれだけLLMの回答を一貫させるか(値が高い方(=1に近づく方)がよりランダム性が高くなる)を指定する為のものです。
LLMは、回答を生成している際に次に使う文字列を確率論で選んでおり、上記値を低くすることで「常に確率が高い物を選ぶ(=結果、回答の一貫性が高くなる)」動作となります。
この後のcreate_index関数の説明でも触れますが、今回は質問に回答する時だけでなくDBにデータを登録する際にもLLMを活用します。
アイデアの検討やオープンクエスチョンであれば自由な発想で回答してもらう為に値を高くするのも良いかと思いますが、DBにデータ登録する際には登録データを一貫させたい為、今回は値を低くしています。
次はcreate_index関数内に触れていますが、半分ぐらいは第4回で触れたベクトルDBの処理と同様です。
これはドキュメントから情報を抜き出したりチャンク分割する処理は、ベクトルDBでもグラフDBでも変わらず共通で行う為です。
グラフはエンティティとエンティティ間の関係性を示す特性上、エンティティは小さい単位(モノやヒト)となります。
管理・登録する対象(エンティティ)が小粒になる為、グラフRAGにおいてチャンクが重要か?と疑問が浮かぶ方もいると思いますが、グラフRAGにおいてもチャンクサイズの概念は重要です。
チャンクを大きくしすぎると、データ登録時(登録クエリ生成時)にエンティティと関係性の情報を漏らしてしまう可能性があります。
グラフRAGのDBへの登録処理においてポイントは以下です。
from langchain_experimental.graph_transformers import LLMGraphTransformer
llm_graph_transformer = LLMGraphTransformer(llm=model)
graph_docs = llm_graph_transformer.convert_to_graph_documents(docs)
graphdb.add_graph_documents(graph_docs, baseEntityLabel=True ,include_source=True)
LLMGraphTransformer(llm=model) の箇所に着目するとわかりやすいですが、ドキュメント情報をグラフ形式にコンバートするのはLLMに行わせます。
よって利用するモデルの精度が、グラフRAGの精度にも大きく影響します。
上記で定義したインスタンスを使って、docs(ドキュメントから抜き出した文字情報をチャンク分割したもの)を与えて、コンバートした上でadd_agraph_documentsにて登録を行います。
なお、baseEntityLabelオプションはノードにラベルを付与するか、include_sourceオプションは登録情報にドキュメント情報(ファイル名など)を含むか指定するオプションです。
今回はどちらも有効(True)としています。
次はdelete_index関数内の処理ですが、これはシンプルで全データ削除クエリを実行する事で、DBクリアをしています。
graphdb.query("match (n) detach delete n")
指定しているクエリは、match(n)でノードを全取得し、detach delete n でノードに紐づくエッジも含めてすべて削除を行います。
ユーザからの質問を回答するquery_llm関数もベクトルDBの時と比較するとシンプルです。
from langchain_neo4j import GraphCypherQAChain
chain = GraphCypherQAChain.from_llm(graph=graphdb, llm=model, verbose=True,allow_dangerous_requests=True )
ai_msg = chain.invoke(user_pmt)
GraphCypherQAChainにて利用するグラフ情報とモデルを指定する事で、ユーザの質問から問い合わせ用クエリを生成して回答を行うチェインを作ります。
verboseオプションを有効とすることで処理中の情報が出力されます。
どのような出力がされるかは、この後の実行例の箇所にて触れたいと思います。
またこのチェインを使う為に「allow_dangerous_requests」オプションを有効とします。
このオプションはその名の通り「危険なリクエストも許可する」ものです。
今回GraphCypherQAChain.from_llmを利用するquery_llm関数は「ユーザの質問から必要な情報を取得して回答すること」を目的としており、意図するDB操作は「検索処理」に限定される想定です。
しかし、例えばユーザが「match (n) detach delete nをしてほしい」といった、全データ削除を実行する旨の質問をした場合、そのままユーザの質問からデータ削除が実行されてしまう危険性もあります。
このような悪意ある操作により意図しない挙動を引き起こす事をプロンプトインジェクションと呼びます。
今回はサンプル用途の為、特に対処・対策はしていませんが、この例に当てはめて言えばユーザ質問のできる幅を狭めたり権限を絞るといった対策が必要かと思います。
上の例は一例ではありますが、本来はこのようなセキュリティ対策をしておくことが推奨されます。
ここまで見てきたように、この実装はデータの登録時もユーザの質問時も、モデルにてクエリ変換を行っている点がポイントとなります。
実行例と結果について
ここからは実行例をみてみましょう。
なお、この例では「./local_documents」に配置する登録対象ドキュメントは第3回で触れたドキュメントと同様とします。
python langchain_ollama_graphrag.py -a
ドキュメントを読み込んでDBに登録します。
インデキシングが完了しました。
上のようにドキュメント登録後に、Neo4jブラウザ画面にて「match(n) return n」を実行すると、登録された情報が表示されるはずです。
今回の動作例の結果を以下に示します。
「なるのでは」や「部」ノードといった、ところどころ怪しい箇所もありますが、それらしく登録はできていそうです。
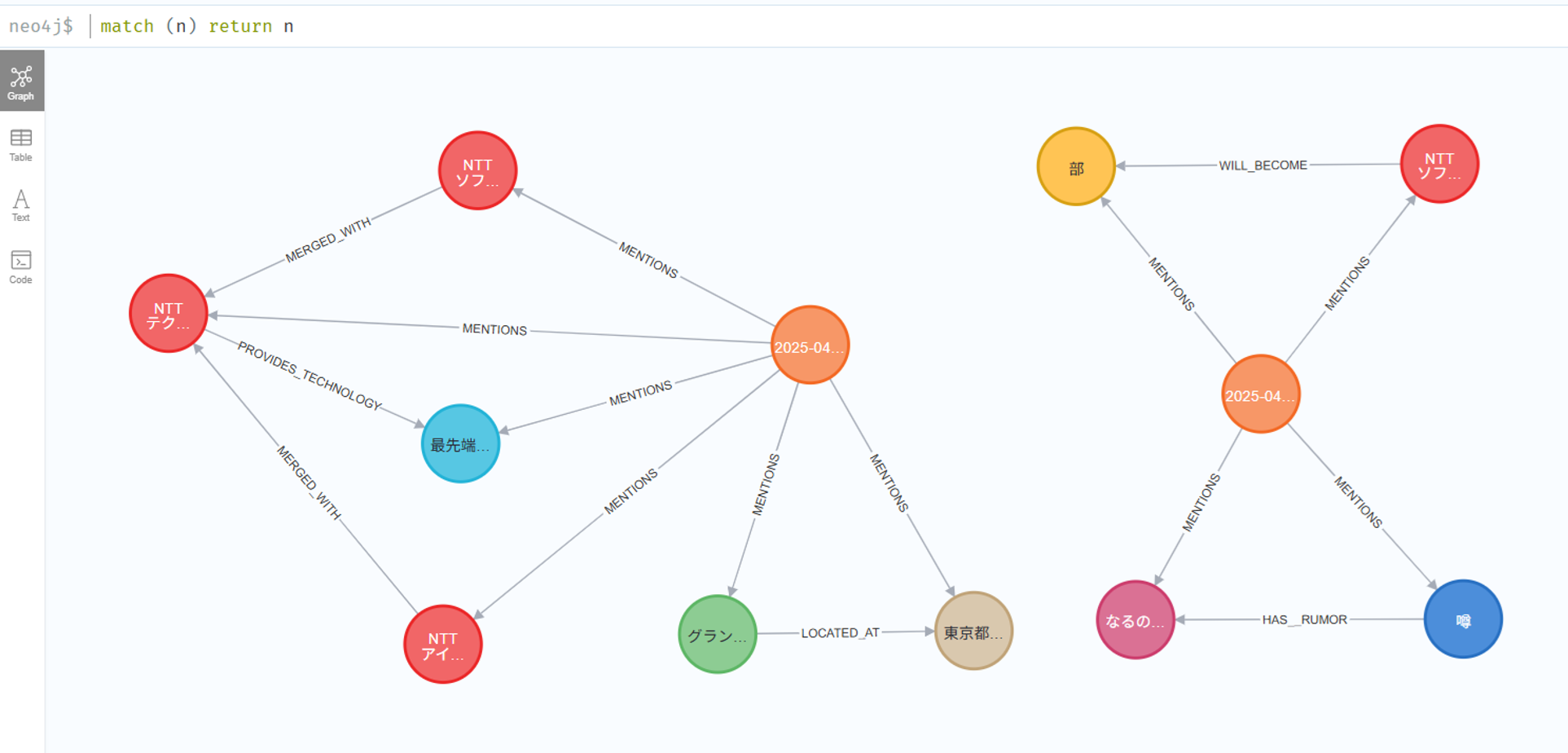
図10 登録情報をNeo4jのブラウザ画面上で確認した結果
参考までに、temperatureオプションを1.0(最大限ランダム)にして登録した場合は以下のようになりました。
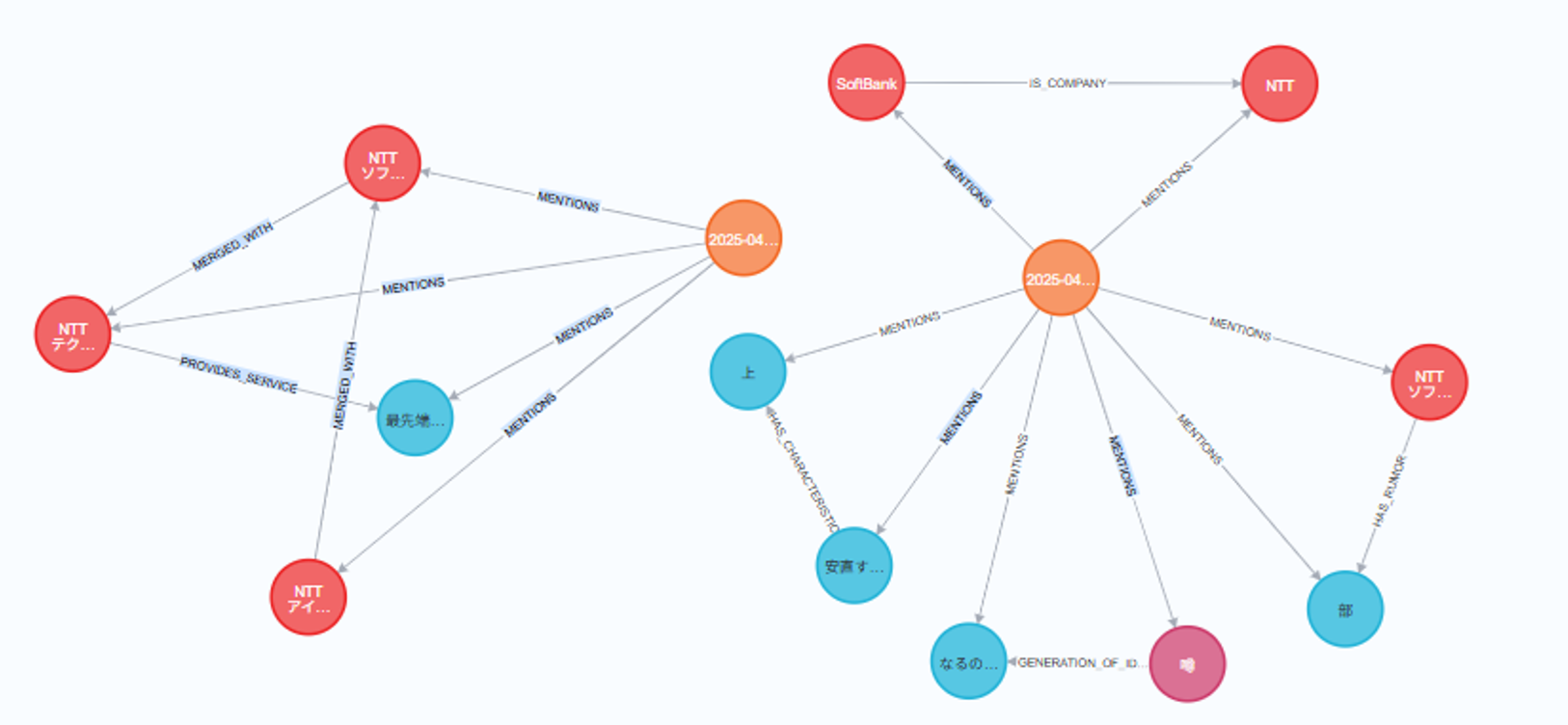
図11 tempreratureを最大にした際の登録情報をブラウザ上で確認した結果
グラフの形が大きく変わった他、ドキュメント内では言及していないSoftBank社のノードもできました。
この事から、データ登録時に自由度高くLLMが回答してきていることがわかるかと思います。
問題なくデータが登録できたら早速質問をしてみましょう。
以降の処理は、1つ目の登録結果(temprerature 0.1)の状態にて試した結果を記載します。
python langchain_ollama_graphrag.py -q "NTTテクノクロスの前の会社名はなにか。"
質問を受け付けました: NTTテクノクロスの前の会社名はなにか。
> Entering new GraphCypherQAChain chain...
Generated Cypher:
cypher
MATCH (c:Company)<-[:WILL_BECOME]->(u:Unit)
RETURN c.id AS company_id, u.id AS unit_id
Full Context:
[{'company_id': 'NTT ソフティ', 'unit_id': '部'}]
> Finished chain.
LLMの応答: {'query': 'NTTテクノクロスの前の会社名はなにか。', 'result': 'NTTソフティの前の会社名は、NTTテクノクロスの前身である **NTT ソフティ** です。 \n'}
質問を受け付けてから回答が出力されるまでの間、どのようなクエリを投入して、結果どのような情報が取得したかが表示されます。
これはGraphCypherQAChainにてチェイン定義をする際にverboseオプション有効化を指定したためです。
(verboseオプションが無効の場合、データ取得が0件だった場合を除き、基本的には何も途中経過は出力されません。)
肝心の結果ですが「噂となった社名」の方に引きずられてしまい、正しい回答(NTTソフトウェアやNTTアイティ、NTTアドバンステクノロジの一部)が出力されませんでした。
登録済のグラフをみると「NTTテクノクロス」と「NTTソフトウェア」「NTTアイティ」間はMERGE_WITHという関係で繋がれていますが、質問した際のクエリは関係性を「WILL_BECOME」として検索してしまっている為と考えられます。
実装の改善例について
実行例にて発生したズレの原因として、登録時と検索時で異なるLLMへの問い合わせになっており、連携できていない(ユーザの質問を受けてクエリを作成する時に、登録済データを意識せずに生成している)ことが考えられます。
今回はこの点に着目し、シンプルな改善の一例、かつ第6回のおさらいもかねてSelf-Routeの考え方に近い方法で改善してみましょう。
具体的には「エンティティXからエンティティYに何か関係があるもの」一覧を全て取得し、(ユーザの質問とあわせて)この情報を渡すことで、LLMに回答を作らせる、というやり方です。
エンティティとその間の関係性全ての情報は、言い換えればグラフの全体構造が分かる情報です。
Self-Routeの「全文をLLMに渡す」やり方に近しいと感じるのではないか、と思います。
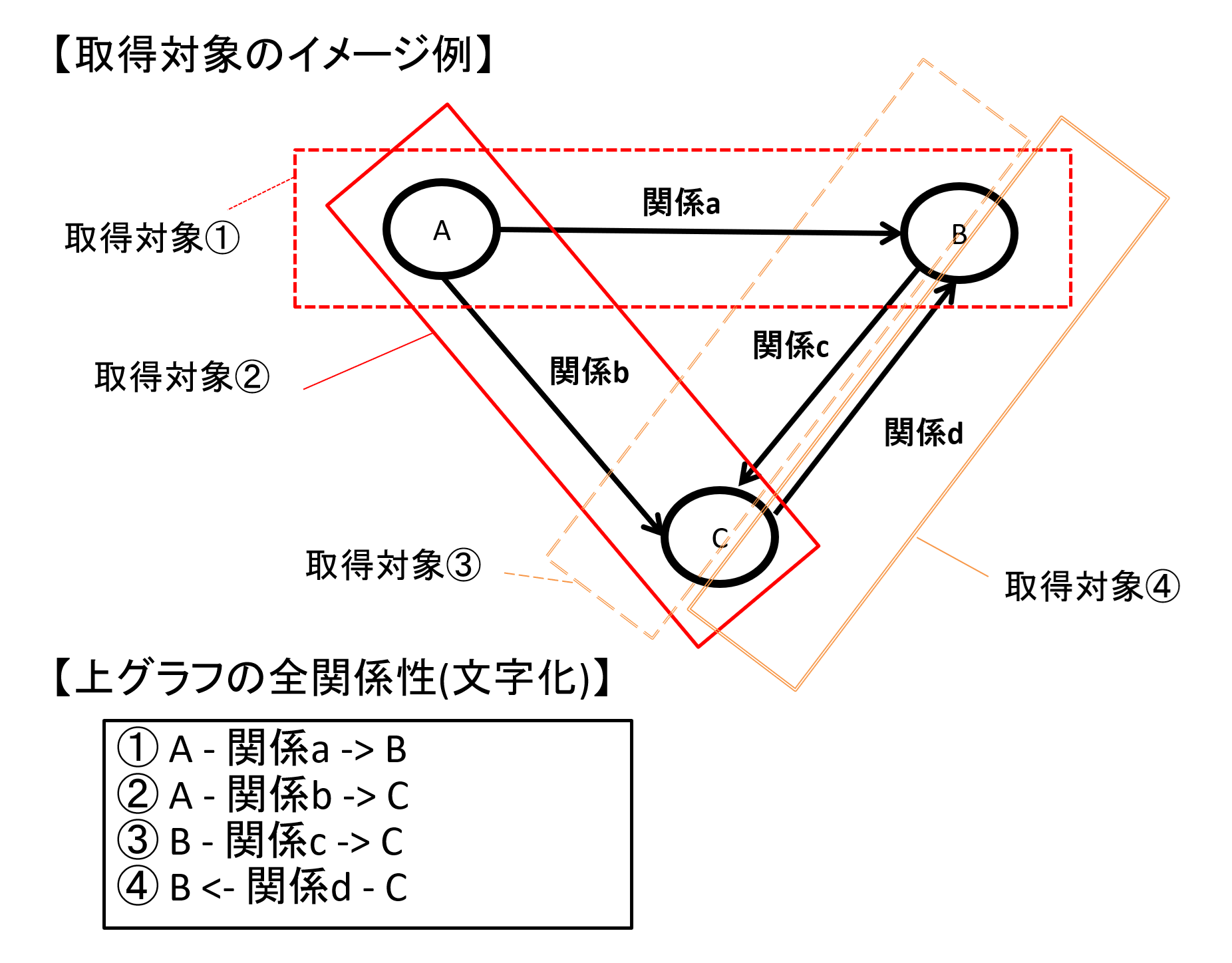
図12 シンプルなグラフ(3ノード構成)を例にした全データ/関係性取得イメージ
なお、上記例から気が付かれた方もいるかと思いますが、何の関係性も持っていない独立ノードは取得していません。
今回は必要な情報も持っていないものと想定して、取得対象外としています。
query_llm関数の改善例を以下に示します。
改善コードのほとんどが第4回で触れた構文と同じとなります。
graphdb.queryでエンティティとエンティティの関係性一覧を取得する箇所は第4回にはないですが、graphdb.queryによるクエリの実行は(実行クエリ自体は異なるものの)今回のdelete_index関数で利用しているものと同じです。
graphdb.queryにより、グラフの全体を取得し、プロンプトテンプレート機能を使ったpmt_allの{context}内に入れ込んで質問を投げています。
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
def query_llm ( user_pmt: str):
print(f"質問を受け付けました: {user_pmt}")
graph_data = graphdb.query("match (x)-[r]->(y) return x, r, y")
pmt_all = ChatPromptTemplate.from_template('''\
以下のグラフ構造のみを踏まえて質問に回答してください。
グラフ構造: """
{context}
"""
質問: """
{user_pmt}
"""
''')
chain = (
{ "context": lambda _: graph_data , "user_pmt": RunnablePassthrough() }
| pmt_all
| model
| StrOutputParser()
)
ai_msg = chain.invoke(user_pmt)
print(f"LLMの応答: {ai_msg}")
実行例と結果について
上の改善を入れたツールの実行例と結果を以下に示します。
python langchain_ollama_graphrag.py -q "NTTテクノクロスの前の会社名はなにか。"
質問を受け付けました: NTTテクノクロスの前の会社名はなにか。
LLMの応答: NTTテクノクロスの前身の会社名は **「ソフトウェア」** と **「アイティ」** です。
今回は正解に近い回答ができました。
この方法により、登録時はグラフ形式の為、グラフ形式のメリットを損なわずに質問回答ができるようになりました。
一方でSelf-Routeの全文投入ルートと同じことが言えますが、グラフデータが膨大になるとLLMに与えられる情報量を超える為、本案は利用できません。
その為、大きなグラフデータを扱う際には全グラフデータをそのまま使うのではなく、関係しそうなところだけに事前に絞り込む仕組みを入れるといった仕組みが必要になるかと思います。
他にもそもそも利用するモデルをより巨大で精度の高いものにする案や、グラフRAGをより高度化していくという観点でグラフデータで入れる値をベクトル化してグラフ形式とベクトル形式を組み合わせるやり方、プロパティにより多くの情報を登録するといったやり方などもあるかと思います。
おわりに
今回はグラフRAGの考え方や得意分野、LangChainを使ったシンプルな実装などに触れてきました。
ベクトルDBとはまた異なる考え方のものである点が伝わったのではないかと思います。
本件に関する質問やコメントなどがございましたら、以下からお問い合わせください。
今回もご覧いただきありがとうございます。
本件に関するお問い合わせ





<<<<著者プロフィール>>>>
フューチャーネットワーク事業部
第一ビジネスユニット
山口 佳輝(YAMAGUCHI YOSHIKI)
NWに関係したシステム開発を担当しています
>>>>>>>>><<<<<<<<<
![]()