ローカルモデル利用のRAG実装で学ぶLlamaIndexの基礎 ~LLM活用入門5回~
本記事ではベクトルDBを使ったRAGのサンプルコードから、LlamaIndexの基礎を紹介します。




テクノロジーコラム
- 2025年07月14日公開
はじめに
こんにちは、NTTテクノクロス 山口です。
今回も前々回(第3回)・前回(第4回)同様にRAGをテーマに、LLMを活用する為のツールの紹介をしていきます。
今回はRAG実装のサンプルコードから、LlamaIndexの基礎について触れていきます。
「そもそもRAGとは?」という方は前々回(第3回)を参照ください。
また、サンプルコードの構成やできることは前回(第4回)と同様となる為、理解が追いつかなかった場合はこちらも参照ください。
● 目次
| 節番号 | 節タイトル |
|---|---|
| 1 | ソースコード全文と全体の構成について |
| 2 | 細部のポイントについて |
| 3 | 実行例と結果について |
[参考] 本連載の記事
本記事とあわせて、以下も良ければご確認ください。
| 連載番号 | タイトル | 概要 |
| 第1回 | 今だから知っておきたいDify!ノーコード・ローコードでLLM活用基盤を作ろう | Dify自体の説明とChatflow機能を使った例を取り上げています。 |
| 第2回 | 爆速キャッチアップ!LLM活用をリードするプラットフォーム群 | LLMの可能性をより広げるDify/Ollama/LangChain/Hugging Faceの紹介と、 DifyとOllamaでローカルLLMを活用したChatflow機能の利用に関して取り上げます。 |
| 第3回 | RAGとは?Difyから基本を学ぶ | RAGの基礎的な説明とDifyを使った実現方法を取り上げています。 |
| 第4回 | ローカルモデル利用のRAG実装で学ぶLangChainの基礎 | ベクトルDBを用いたRAGのサンプルコードから、LangChainの基礎を解説します。 |
| 第5回 | ローカルモデル利用のRAG実装で学ぶLlamaIndexの基礎 | ベクトルDBを用いたRAGのサンプルコードから、LlamaIndexの基礎を解説します。 |
| 第6回 | Difyで学ぶ、RAGの精度改善手法 | RAGの精度改善手法をDifyのChatflow機能を使いながら紹介します。 |
| 第7回 | ローカル環境で実現する、GraphRAGの基礎 | GraphRAGの基礎から、LangChainとNeo4jを使ったグラフRAGの実装例を紹介します。 |
| 第8回 | ローカル環境で実現する、Text-To-SQLとRDBを用いたRAG | Text-To-SQLと、それを活用したRDBを用いたRAGの実装例を紹介します。 |
| 第9回 | ファインチューニングとは?基礎を理解する | ファインチューニングとそのユースケース、手法を紹介します。 |
| 第10回 | Hugging Faceライブラリで実行する推論と学習の基礎(前編) | Hugging Faceのライブラリを使った、モデルのダウンロードや推論処理について紹介します。 |
| 第11回 | Hugging Faceライブラリで実行する推論と学習の基礎(後編) | Hugging Faceのライブラリを使った、ローカルモデルの学習処理と実行例について紹介します。 |
| 第12回 | AIエージェントとは?Difyから考え方を学ぶ | AIエージェントについて、Difyでの動作イメージも含めて紹介します。 |
| 第13回 | MCPとは?AIエージェントの可能性を広げよう | AIエージェントの可能性を広げる技術であるMCPについて紹介します。 |
ローカルモデル×ベクトルDB構成によるRAG作成で学ぶLangChainの基礎
今回も前回(第4回)同様、最初に「ソースコード」全文を眺めて処理の流れや概要を押さえ、その後に細部のポイントや実行結果について解説します。
また、今回もサンプルコードはPyhonで記載します。
Pythonやライブラリ等のバージョンや前提については、前々回(第3回)を参照ください。
ソースコード全文と全体の構成について
以下に全体のソースコード(約100行程度のサンプルプログラム)を示します。
解説用のサンプルコードである為、最小限の実装となっている点はご承知おきください。
またサンプルコードの全体構成や使い方は前回(第4回)と同様です。
# 標準ライブラリ
import argparse
import shutil
# LlamaIndex core
from llama_index.core import (
SimpleDirectoryReader,
VectorStoreIndex,
Settings,
StorageContext,
PromptTemplate
)
from llama_index.core.node_parser import SentenceSplitter
# その他
from llama_index.llms.ollama import Ollama
from llama_index.embeddings.ollama import OllamaEmbedding
from llama_index.vector_stores.chroma import ChromaVectorStore
import chromadb
# モデル指定
Settings.llm = Ollama(model="gemma3", request_timeout= 120, base_url="http://localhost:11434" )
Settings.embed_model = OllamaEmbedding(model_name="nomic-embed-text", base_url="http://localhost:11434")
# Chroma のセットアップ
db = chromadb.PersistentClient(path="./chroma_db")
chroma_collection = db.get_or_create_collection("llamaindex")
vector_store = ChromaVectorStore(chroma_collection=chroma_collection)
# ローカルディレクトリの読み込み対象ファイルを読込み、インデキシング。
def create_index():
print("ドキュメントを読み込んでDBに登録します")
# チャンクサイズ等の指定
Settings.text_splitter = SentenceSplitter( chunk_size=200, chunk_overlap=25, paragraph_separator="。")
# ドキュメント情報取得
reader = SimpleDirectoryReader(input_dir="./local_documents", required_exts=[".pdf"])
raw_docs = reader.load_data()
# ストレージコンテキストを指定
storage_context = StorageContext.from_defaults(vector_store=vector_store)
# DBに登録
VectorStoreIndex.from_documents(raw_docs, storage_context = storage_context )
print("インデキシングが完了しました。")
# DBのクリア
def delete_index():
print("データベースをクリアします。")
# 削除対象のデータ取得
all_items = chroma_collection.get()
ids = all_items["ids"]
# 削除対象のデータがあれば削除、なければ何もしないルートへ。
if ids:
chroma_collection.delete(ids=ids)
shutil.rmtree("./chroma_db")
print("データベースのクリアが完了しました。")
else:
print("削除対象がありませんでした。")
# LLMに関する質問処理
def query_llm( query_str: str):
print(f"質問を受け付けました: {query_str}")
# 情報の読み取り
index = VectorStoreIndex.from_vector_store( vector_store)
if chroma_collection.count() == 0:
print("関連するコレクションが見つかりません。情報未登録の可能性があります。")
return
all_pmt = PromptTemplate( template='''\
以下の文脈だけを踏まえて質問に回答してください。
文脈: """
{context_str}
"""
質問: """
{query_str}
"""
''')
# クエリエンジン初期化
query_engine = index.as_query_engine(similarity_top_k=3, text_qa_template=all_pmt, response_mode="simple_summarize" )
# クエリの実行
ai_msg = query_engine.query(query_str)
print(f"LLMの応答: {ai_msg}")
# コマンドライン引数の解析
def main():
parser = argparse.ArgumentParser(description="llamaindexベースのRAGシステム")
parser.add_argument("-a", "--add", action="store_true", help="ドキュメント登録・インデックス作成")
parser.add_argument("-d", "--delete", action="store_true", help="データベースクリア")
parser.add_argument("-q", "--query", type=str, help="LLMへ質問文を行う")
args = parser.parse_args()
if args.add:
create_index()
elif args.delete:
delete_index()
elif args.query:
query_llm(args.query)
else:
print("いずれかのオプションを指定してください。-h オプションで使用方法を確認できます。")
if __name__ == "__main__":
main()
LangChainでの実装と、構成の概要レベルは変わりませんね。
全体の長さもLangChainでの実装と大きく変わりませんが、記載粒度をそろえる為に任意のコードを明示的に書いている箇所もあります。
この点も踏まえて、以下の細部ポイントに触れていきたいと思います。
細部のポイントについて
以降では特にポイントとなる点について説明します。
from llama_index.core import Settings
from llama_index.llms.ollama import Ollama
from llama_index.embeddings.ollama import OllamaEmbedding
Settings.llm = Ollama(model="gemma3", request_timeout= 120, base_url="http://localhost:11434" )
Settings.embed_model = OllamaEmbedding(model_name="nomic-embed-text", base_url="http://localhost:11434")
LlamaIndexでは、デフォルトでOpenAI社のLLMモデルとEnbeddingモデルを使うように指定されています。
よってOpenAI社のモデルを使う場合は、利用するモデルの定義が不要となります。(かわりにAPI Keyの設定が必要となります)
今回はOllamaで動かしているローカルモデルを利用する為、Settingsにて指定します。
from llama_index.core.node_parser import SentenceSplitter
Settings.text_splitter = SentenceSplitter( chunk_size=200, chunk_overlap=25, paragraph_separator="。")
同様に、DBに登録する際のドキュメントのチャンクサイズなどもSettingsで設定します。
「paragraph_separator」は段落を見分ける為の指定項目で、今回は文章毎に区切れると良いかと思うため「。」を指定しています。
デフォルトの値はchunk_sizeは1024、 chunk_overlapは200、 paragraph_separatorは「\n\n\n」です。
これもデフォルトのまま利用するのであれば指定不要です。
このようにRAGを使う上で利用する基本的な設定はデフォルトで定義がされています。
細かくこだわりたい場合はコードを書いて指定します。
ちなみにこの情報の加工処理機能をllamaIndexではNode Parser/ Text Splitterと呼んでいます。
過去はServiceContextとして指定していましたが、現在は非推奨となりSettingsが使われるようになりました。
さて、ドキュメント情報をDBに登録するcreate_index関数のなかでも、特に肝となるのが以下です。
from llama_index.core import VectorStoreIndex, StorageContext
storage_context = StorageContext.from_defaults(vector_store=vector_store)
VectorStoreIndex.from_documents(raw_docs, storage_context = storage_context )
上記でストレージコンテキストを定義し、その後、DB(Chroma)に情報を登録しています。
llamaindexではチャンクごとにDBに登録した情報を「ノード」と呼んで管理します。
ストレージコンテキストは、llamaIndexが様々なデータ保存先を扱う為のインターフェースのようなイメージです。
例えば今回はChromaを「VectorStoreIndex」から操作しますが、ベクトルDBは他にも様々なものが存在します。
LlamaIndexがサポートしているベクトルDBは以下の通りです。
[参考] https://docs.llamaindex.ai/en/stable/module_guides/storing/vector_stores/
またllamaIndexはユースケースに応じてベクトルDB以外の保存先を選べます。
わかりやすい例としてグラフDBがあります。
グラフDBもまた、様々な種類があります。
これらを1つのIF(StorageContext)で扱えるようにしたものがストレージコンテキストと言えます。
イメージ例を以下に載せますので、ご確認ください。
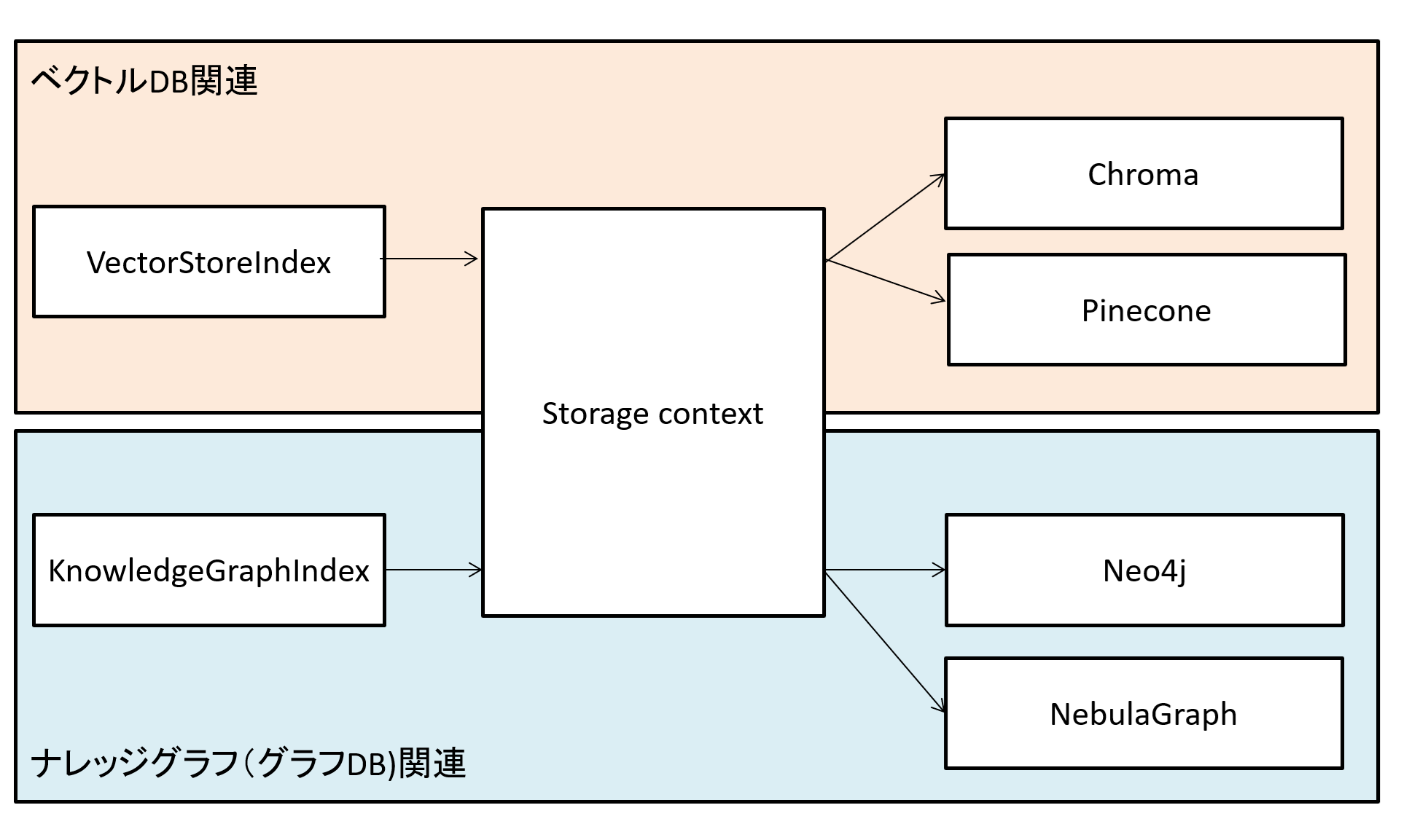
図1 Strage Contextのイメージ
なお、例はベクトルDB(ベクトルストア)とグラフDB(グラフストア)をあげていますが、他にもドキュメントストアや、インデックスストアなどが存在します。
[参考] https://docs.llamaindex.ai/en/stable/api_reference/storage/storage_context/
次はDBの情報を削除するdelete_index関数のポイントについて説明します。
import shutil
if ids:
chroma_collection.delete(ids=ids)
shutil.rmtree("./chroma_db")
print("データベースのクリアが完了しました。")
else:
print("削除対象がありませんでした。")
削除処理はllamaIndex経由ではなく、chromadbから直接操作を行います。
なお、chromadbのdelete処理には、DBに登録したレコードの識別子(ids)を指定する必要があります。
また、レコード識別子が0個だとエラーとなる為、削除対象がない場合のルートも用意しています。
次はLLMへ問い合わせを行うquery_llm関数の中身を見ていきます。
index = VectorStoreIndex.from_vector_store( vector_store)
if chroma_collection.count() == 0:
print("関連するコレクションが見つかりません。情報未登録の可能性があります。")
return
情報の登録は「VectorStoreIndex」の「from_documents」を使いましたが、登録した情報の読み取りは「from_vector_store」を指定します。
なお、ここで取得したデータが0件の場合は、この後の処理は不要の為、ここで終了とする処理を入れています。
all_pmt = PromptTemplate( template='''\
以下の文脈だけを踏まえて質問に回答してください。
文脈: """
{context_str}
"""
質問: """
{query_str}
"""
''')
上記は任意のコードです。
明示的にプロンプトテンプレートを指定しなくても、デフォルトのテンプレートでRAGから取得した情報(context_str)とユーザの質問(query_str)をあわせて、LLMに質問を行ってくれます。
今回はLangChainの時(前回参照)と同様のプロンプトで実施したい為、明示的に指定しています。
なお、「context_str」と「query_str」変数の名前は変更不可です。
query_engine = index.as_query_engine(similarity_top_k=2, text_qa_template=all_pmt , response_mode=" simple_summarize" )
ai_msg = query_engine.query(query_str)
上記で、処理の定義と実行を行っています。
「similarity_top_k」はRAGで何レコード(何ノード)情報をとってくるか、「text_qa_template」は利用するプロンプトテンプレートを指定しています。
「response_mode」は「どうLLMに問い合わせて、どう結果を取りまとめるか」モードの指定をしています。
今回指定している「simple_summarize」は、RAGで取得したレコード(top_k=2としているので、2ノード取得できる)を単純に結合して1プロンプトに載せて問い合わせる(LLMへの問い合わせは1回のみ)、というモードです。
比較としてわかりやすいのは「refine」です。
これは「1レコードごとにLLMに問い合わせを行う」モードです。
デフォルトは「compact」というモードで動作します。
これは「なるべく1プロンプトにレコードを載せる、その際にデータ構造の定義で使っている [ ] 等の不要な情報を削除する。載せきれない場合は複数回、LLMに問い合わせを行う」というモードです。
その他モードに関しては以下参照ください。
[参考] https://docs.llamaindex.ai/en/stable/module_guides/deploying/query_engine/response_modes/
|
[補足] 動作ログとrefineとsimple_summarizeの動作の差分について 処理の流れやLLMに実際に投げたプロンプトを追いたい場合は以下を仕込むと便利です。 上記により、処理の流れを追う事ができます。 例えばresponse_modeのsimple_summarizeとrefineは以下のように表示されます。 RAGから情報を取得(retrieve)した後、プロンプトテンプレートに情報を当てはめ(templating)、LLMに問い合わせている、という流れがわかる他、simple_summarizeはLLMへの問い合わせは1回であるのに対し、refineはRAGで取得したレコード数(2回)問い合わせているのがわかるかと思います。 なお、処理実行コードの後に以下を記載する事で、LLMに渡したプロンプト情報が確認できます。 今回紹介したLlamaDebugHandlerについて気になる方は以下を参照ください。 また、RAGで取得した情報とプロンプト情報は以下でも確認可能です。 |
処理の定義と実行の話に戻りますが、実行処理を定義している「as_query_engine」は、多くの処理をラップしています。
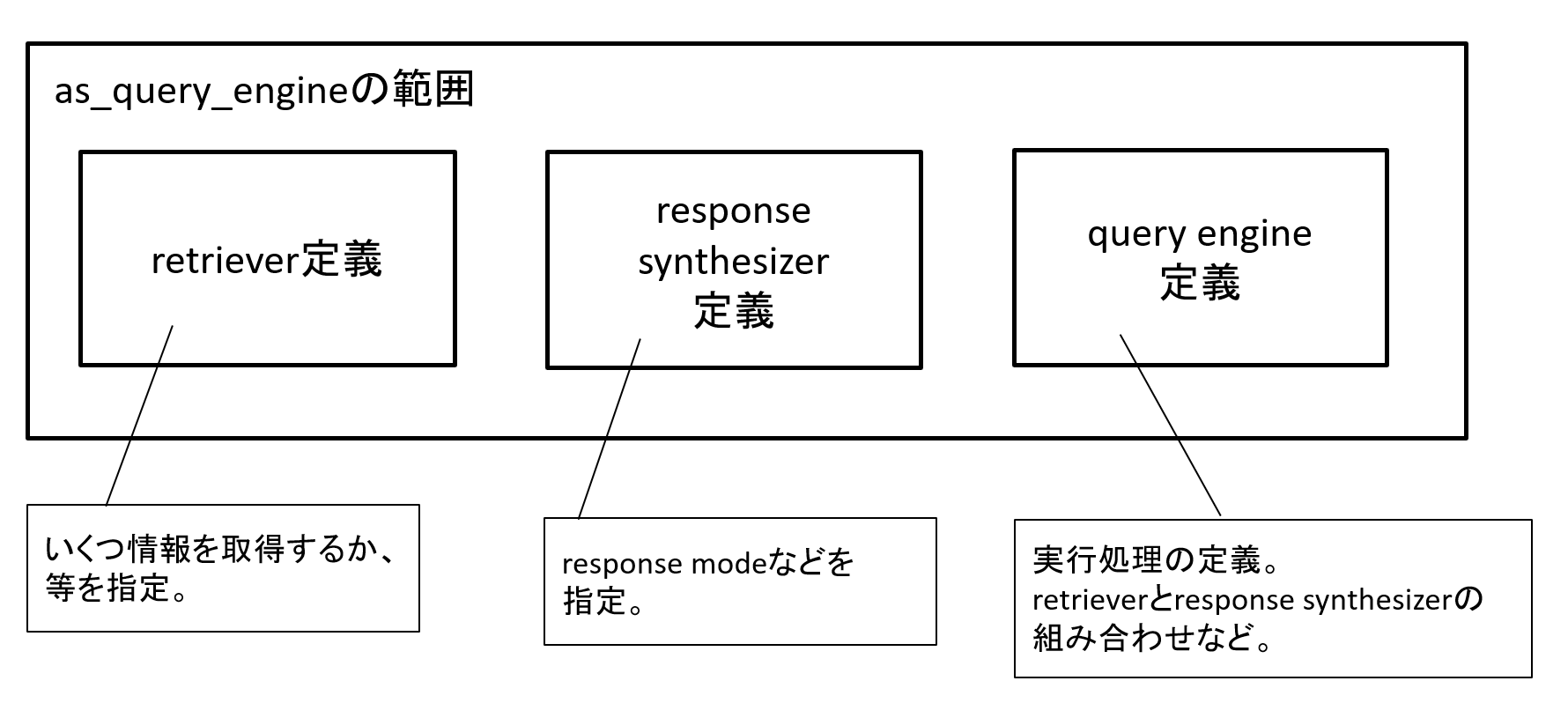
図2 as_query_engineの処理イメージ
より細かい制御や指定を行いたい場合は、以下を参照ください。
[参考]
https://docs.llamaindex.ai/en/stable/module_guides/deploying/query_engine/usage_pattern/
https://docs.llamaindex.ai/en/stable/module_guides/querying/node_postprocessors/
https://docs.llamaindex.ai/en/stable/module_guides/querying/node_postprocessors/node_postprocessors/
ソースコードのポイント紹介は以上となります。
動作させるだけなら極めて簡単に記載ができ、かつ細部をこだわろうとすれば色々できる、というイメージがついたのではないでしょうか。
実行例と結果について
こちらはLangChainと大差ないので簡単に紹介したいと思います。
LangChainの時と同様に、「情報登録(-a)」をしてから「質問をする(-q)」という2段階の処理となります。
python llamaindex_ollama.py -a
ドキュメントを読み込んでDBに登録します。
インデキシングが完了しました。
python llamaindex_ollama.py -q "NTTテクノクロスは、いつ設立されたでしょうか。"
質問を受け付けました: NTTテクノクロスは、いつ設立されたでしょうか。
LLMの応答: 2017年4月1日
無事に回答が出力されました。
今回はLangChainの時と比較し、chunk_sizeを100から200と少し大きめにして、ヒット数も1から2件にしました。
上記にしても問題なく回答できていますね。
おわりに
今回はRAG実装のサンプルコードからLlamaIndexの基礎を説明しました。
今回紹介したのは「ベクトルDB」を使ったRAG(ベクトルストアインデックス)でしたが、LlamaIndexでは他にも「ツリーインデックス」や「ナレッジインデックス」などが可能です。
また、今回は触れていないですが、別インデックスを扱うと、リトリーバのモード(どのように情報を検索・取得するか動作モードを指定する。例えばツリーインデックスならツリーのリーフを検索対象とするのか、ルートのみを検索対象とするのか。)も切り替えられます。
更に高度化を見据えると、これも一例ですが複数のインデックスを使う場合に、ユースケースに応じて利用するインデックスを切り替えられる(ルーティングを行う)Routersという機能もあります。
このようにLlamaIndexはデータ管理や検索に特化したフレームワークという点がわかるかと思います。
これまで3回にわたって、RAGの基礎とあわせてDify・LangChain・Llamaindexの紹介をしてきました。
本連載で各ツールの理解が進めば幸いです。
なお、今回紹介したコードはあくまで最低限のものとなります。
実際に利用をするには、複数人で利用する事や、ユースケースに応じてPDF以外のフォーマットのサポートなども考えないといけないでしょう。
また、RAGは最初から高精度が出る事も稀であり、ユースケースに応じた工夫や継続的な改善も必要となります。
利用を始めた際は古いドキュメントは登録削除する(例えば社内ルールが変わって、今登録しているドキュメントの情報が古くなった場合)など、メンテナンスも重要となります。
本件に関する質問やコメントがございましたら、以下からお問い合わせください。
ここまでご覧いただき、ありがとうございました。
本件に関するお問い合わせ




<<<<著者プロフィール>>>>
フューチャーネットワーク事業部
第一ビジネスユニット
山口 佳輝(YAMAGUCHI YOSHIKI)
NWに関係したシステム開発を担当しています
>>>>>>>>><<<<<<<<<
![]()