ローカルモデル利用のRAG実装で学ぶLangChainの基礎 ~LLM活用入門4回~
本記事ではベクトルDBを使ったRAGのサンプルコードから、LangChainの基礎を紹介します。




テクノロジーコラム
- 2025年06月24日公開
はじめに
こんにちは、NTTテクノクロス 山口です。
前回(第3回)・今回(第4回)・次回(第5回)の3回にわたり、RAGをテーマにLLMを活用する為のツールの紹介をしていきます。
今回はRAG実装のサンプルコードから、LangChainの基礎について触れていきます。
「そもそもRAGとは?」という方は前回(第3回)を、「LangChainとは?」という方は前々回(第2回)を参照ください。
● 目次
| 節番号 | 節タイトル |
|---|---|
| 1 | ソースコードの構成と全文について |
| 2 | 細部のポイントについて |
| 3 | 実行例と結果について |
[参考] 本連載の記事
本記事とあわせて、以下も良ければご確認ください。
| 連載番号 | タイトル | 概要 |
| 第1回 | 今だから知っておきたいDify!ノーコード・ローコードでLLM活用基盤を作ろう | Dify自体の説明とChatflow機能を使った例を取り上げています。 |
| 第2回 | 爆速キャッチアップ!LLM活用をリードするプラットフォーム群 | LLMの可能性をより広げるDify/Ollama/LangChain/Hugging Faceの紹介と、 DifyとOllamaでローカルLLMを活用したChatflow機能の利用に関して取り上げます。 |
| 第3回 | RAGとは?Difyから基本を学ぶ | RAGの基礎的な説明とDifyを使った実現方法を取り上げています。 |
| 第4回 | ローカルモデル利用のRAG実装で学ぶLangChainの基礎 | ベクトルDBを用いたRAGのサンプルコードから、LangChainの基礎を解説します。 |
| 第5回 | ローカルモデル利用のRAG実装で学ぶLlamaIndexの基礎 | ベクトルDBを用いたRAGのサンプルコードから、LlamaIndexの基礎を解説します。 |
| 第6回 | Difyで学ぶ、RAGの精度改善手法 | RAGの精度改善手法をDifyのChatflow機能を使いながら紹介します。 |
| 第7回 | ローカル環境で実現する、GraphRAGの基礎 | GraphRAGの基礎から、LangChainとNeo4jを使ったグラフRAGの実装例を紹介します。 |
| 第8回 | ローカル環境で実現する、Text-To-SQLとRDBを用いたRAG | Text-To-SQLと、それを活用したRDBを用いたRAGの実装例を紹介します。 |
| 第9回 | ファインチューニングとは?基礎を理解する | ファインチューニングとそのユースケース、手法を紹介します。 |
| 第10回 | Hugging Faceライブラリで実行する推論と学習の基礎(前編) | Hugging Faceのライブラリを使った、モデルのダウンロードや推論処理について紹介します。 |
| 第11回 | Hugging Faceライブラリで実行する推論と学習の基礎(後編) | Hugging Faceのライブラリを使った、ローカルモデルの学習処理と実行例について紹介します。 |
| 第12回 | AIエージェントとは?Difyから考え方を学ぶ | AIエージェントについて、Difyでの動作イメージも含めて紹介します。 |
| 第13回 | MCPとは?AIエージェントの可能性を広げよう | AIエージェントの可能性を広げる技術であるMCPについて紹介します。 |
ローカルモデル×ベクトルDB構成によるRAG作成で学ぶLangChainの基礎
まずは「ソースコード」全文を眺めて処理の流れや概要を押さえ、その後に細部のポイントや実行結果について触れていきます。
なお、今回のサンプルコードはPyhonで記載します。
Pythonやライブラリ等のバージョンや前提については、前回(第3回)を参照ください。
環境の構成は以下の図をご確認ください。
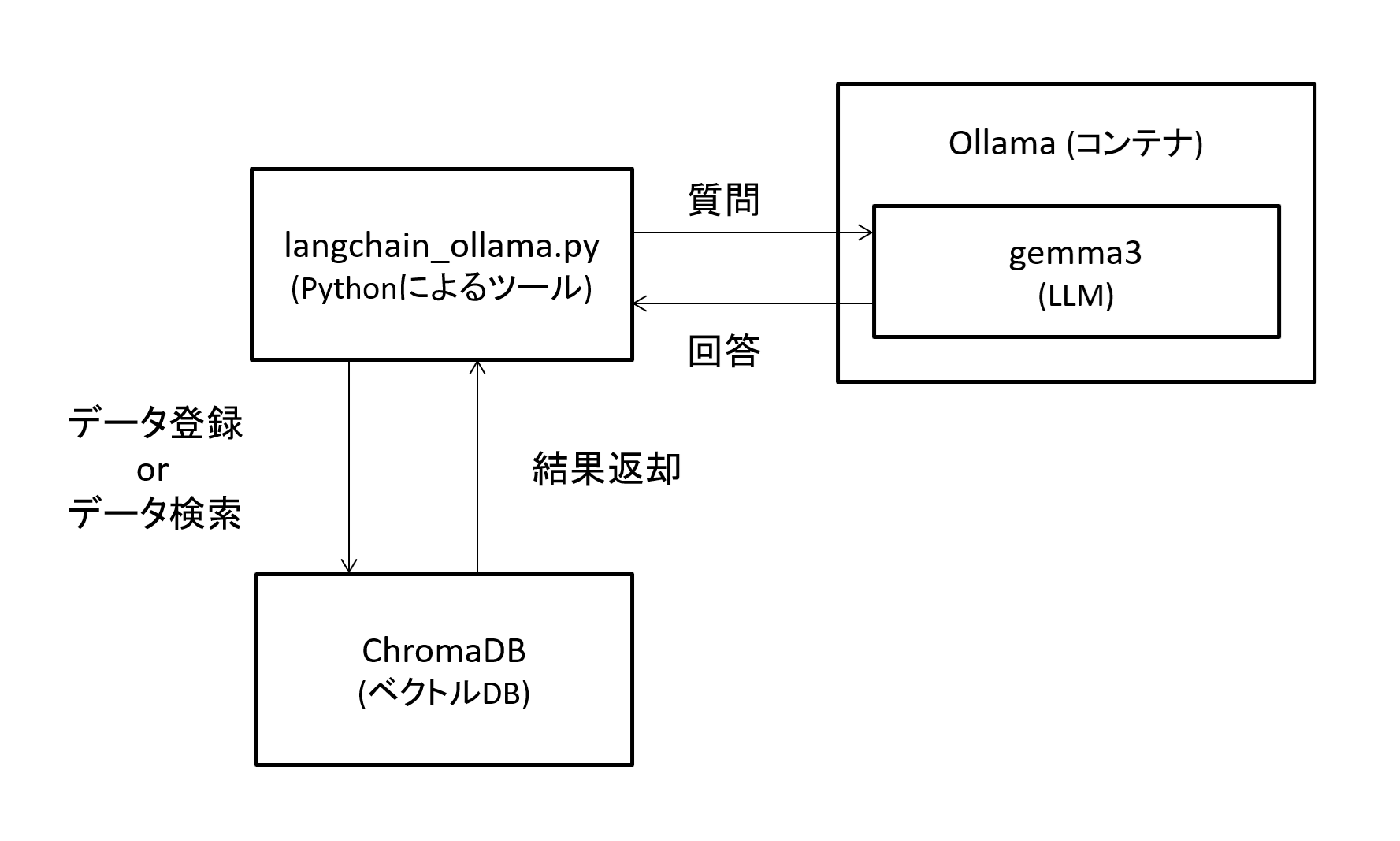
図1 環境の構成
ソースコードの構成と全文について
全体のソースコード(約100行程度のサンプルプログラム)を以下に示します。
サンプルコードの為、最小限の実装となっている点はご承知おきください。
また、この後に細部説明をする為、ここでは細かく理解せずとも大丈夫です。
コメントも多く埋め込んでいる為、どういう処理の流れなのか概要を確認ください。
# 標準ライブラリ
import argparse
import shutil
# LangChain core
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
# LangChain その他モジュール
from langchain_community.document_loaders import DirectoryLoader, PyPDFLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_chroma import Chroma
from langchain_ollama import OllamaLLM, OllamaEmbeddings
# 利用モデルとDB定義
model = OllamaLLM(model="gemma3", base_url="http://localhost:11434" )
emb = OllamaEmbeddings( model="nomic-embed-text", base_url="http://localhost:11434" )
db = Chroma( collection_name = 'langchain', embedding_function=emb, persist_directory="./chroma_db")
# ローカルディレクトリの読み込み対象ファイルを読込み、インデキシング。
def create_index():
print("ドキュメントを読み込んでDBに登録します。")
ldr = DirectoryLoader(
"./local_documents", # 登録するドキュメントを配置するローカルディレクトリパス
glob="*.pdf",
loader_cls=PyPDFLoader
)
# ドキュメントの読み込みを実施
raw_docs = ldr.load()
# 読み込んだドキュメントをチャンクに分割。
txt_sp = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=25,separators=["\n\n", "。"])
docs = txt_sp.split_documents(raw_docs)
# ロードしたドキュメントのDB登録(indexing)
db.add_documents(documents=docs )
print("インデキシングが完了しました。")
# DBのクリア
def delete_index():
print("データベースをクリアします。")
db.delete_collection()
shutil.rmtree("./chroma_db")
print("データベースのクリアが完了しました。")
# LLMに関する質問処理
def query_llm( user_pmt: str):
print(f"質問を受け付けました: {user_pmt}")
# DBから質問に関連するドキュメントを得るIF(リトリーバ)を作成
retriever = db.as_retriever(search_kwargs={"k": 1})
context_docs = retriever.invoke(user_pmt)
if len(context_docs) == 0 :
print("関連する情報が見つかりません。情報未登録の可能性があります。")
return
# LangChainのプロンプトテンプレート
pmt_all = ChatPromptTemplate.from_template('''\
以下の文脈だけを踏まえて質問に回答してください。
文脈: """
{context}
"""
質問: """
{user_pmt}
"""
''')
# LangChainのチェイン定義
chain = (
{"context": retriever, "user_pmt": RunnablePassthrough() }
| pmt_all
| model
| StrOutputParser()
)
# ユーザの入力をネタにchainを実行
ai_msg = chain.invoke(user_pmt)
print(f"LLMの応答: {ai_msg}")
# コマンドライン引数の解析
def main():
parser = argparse.ArgumentParser(description="LangChainベースのRAGシステム")
parser.add_argument("-a", "--add", action="store_true", help="ドキュメント登録・インデックス作成")
parser.add_argument("-d", "--delete", action="store_true", help="データベースクリア")
parser.add_argument("-q", "--query", type=str, help="LLMへ質問文を行う")
args = parser.parse_args()
if args.add:
create_index()
elif args.delete:
delete_index()
elif args.query:
query_llm(args.query)
else:
print("いずれかのオプションを指定してください。-h オプションで使用方法を確認できます。")
if __name__ == "__main__":
main()
全体の処理の流れとしては以下のようになっています。
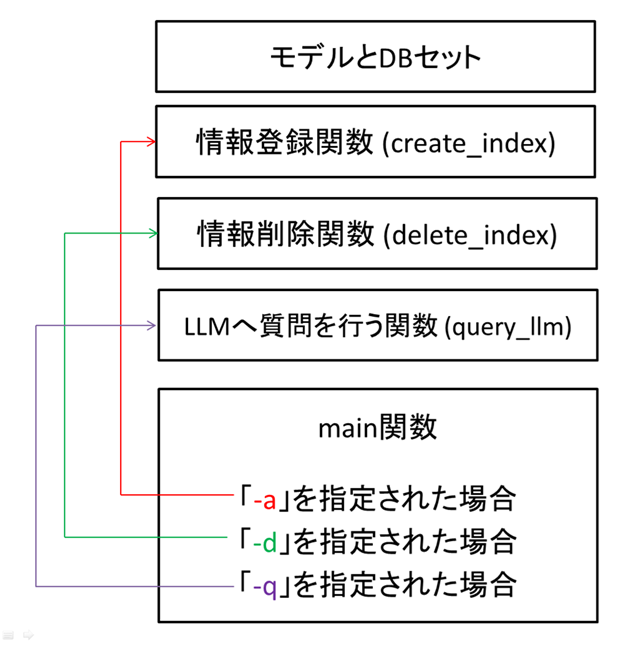
図2 ソースの全体像
上記図の通り、実行時に指定されたオプションにより動作が変わります。
「-a」が指定された場合はcreate_index関数が呼び出され、ベクトルDBへの情報登録を行う、「-d」はベクトルDBの情報削除(一括削除)、「-q "質問文"」で質問をLLMに問い合わせる動きとなります。
使い方は「-a」を実行した後に、「-q」で質問を行う、というイメージですので、2回コードを実行します。
細部のポイントについて
全体のコードをみて処理の流れなど概要を掴めたところで、以降ではポイントとなる点について説明します。
from langchain_ollama import OllamaLLM, OllamaEmbeddings
from langchain_chroma import Chroma
model = OllamaLLM(model="gemma3", base_url="http://localhost:11434" )
emb = OllamaEmbeddings( model="nomic-embed-text", base_url="http://localhost:11434")
db = Chroma( collection_name = 'langchain', embedding_function=emb, persist_directory="./chroma_db")
上記で利用するモデルとベクトルDBの指定をしています。
今回はローカルLLMを動かす為にOllamaを利用するため、「langchain_ollama」からインポートしていますが、Hugging Faceを使う場合は「langchain_huggingface」から必要な物をインポートください。
ベクトルDBにも様々なものがあります(例えばFaiss)が、今回はChromaを利用したいと思います。
登録した情報は「./chroma_db」配下に配置されます。
このディレクトリは事前に作成しておかなくても、後述するデータの登録処理で自動生成されます。
DBの定義で指定しているコレクション名は、RDB(リレーショナルデータベース)でいうところのテーブル名のようなものとなりますので、任意の名前を付けてもらえれば、と思います。
次は情報をDBに登録するcreate_index関数の中身を見てみましょう。
from langchain_community.document_loaders import DirectoryLoader, PyPDFLoader
ldr = DirectoryLoader(
"./local_documents",
glob="*.pdf",
loader_cls=PyPDFLoader
)
raw_docs = ldr.load()
LangChainの「DirectoryLoader」を利用して、ドキュメントを読み込む仕組みを定義しています。
「./local_documents」配下に置いたPDFファイルを全て「PyPDFLoader」で読み込む仕組みを「ldr」として定義しています。
これを実行する(loadする)ことで、PDFから読み取った文字列を「raw_docs」に入れています。
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_chroma import Chroma
txt_sp = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=25,separators=["\n\n", "。"])
docs = txt_sp.split_documents(raw_docs)
db.add_documents(documents=docs)
更にその後、LangChainの「RecursiveCharacterTextSplitter」を利用し、チャンクサイズごとにraw_docsを区切っています。
なお、separatorsで「改行(\n\n)」と「。」があった場合はチャンクを分割するように指定しています。
これでベクトルDBに登録する為の情報(docs)が用意できました。
Chromaのインスタンスであるdbを指定して、add_documentsでdocsを登録しています。
次はDBから情報を削除するdelete_index関数の中身を見てみましょう。
db.delete_collection()
shutil.rmtree("./chroma_db")
上記でコレクションを削除し、その後にchroma_dbフォルダ自体も削除しています。
次はRAGから類似度が高い情報を取得したうえでLLMに問い合わせを行うquery_index関数の中身についてです。
def query_llm( user_pmt: str):
retriever = db.as_retriever(search_kwargs={"k": 1})
context_docs = retriever.invoke(user_pmt)
まず本関数は、呼び出し元(main関数)から「ユーザの質問文(user_pmt)」を受け取ります。
そして、ベクトルDBから情報を取得する為の設定後、「invoke」でmain関数から受け取ったユーザの質問文を使って、ベクトルDBから関連しそうな情報取得し、結果をcontext_docsに入れています。
「search_kwargs」オプションはベクトルDBから、いくつデータをとってくるかを指定しています。
今回は登録したドキュメントの文字情報も少ない為、あえて値を指定しています。
なお、ベクトルDBから取得した情報が関係性の高い順に並んでいるかというと、そうではありません。
確からしさ順に情報を取得する際にはrerankモデルと呼ばれるモデルを利用します。(今回は利用していません)
if len(context_docs) == 0 :
print("関連する情報が見つかりません。情報未登録の可能性があります。")
return
ヒットがなかった場合にはそれ以降の処理は不要の為、処理を止める上記を入れています。
ちなみに以下をすることで、取得した情報を確認することができます。
print(context_docs)
問題なく情報が取得できていることが確認できたら、いよいよLLMに質問を行います。
pmt_all = ChatPromptTemplate.from_template('''\
以下の文脈だけを踏まえて質問に回答してください。
文脈: """
{context}
"""
質問: """
{user_pmt}
"""
''')
chain = (
{"context": retriever, "user_pmt": RunnablePassthrough() }
| pmt_all
| model
| StrOutputParser()
)
ai_msg = chain.invoke(user_pmt)
上記では、まずLangChainのプロンプトテンプレート機能で、システムプロンプトも含めたLLMに渡す指示文を指定しています。
LLMモデルへ質問を行う際は「context」にRAGで取得した情報、「user_pmt」にユーザの質問文を代入します。
その後の「chain」を定義している箇所がLangChainの最も肝となる点です。
ここではこれまで定義した情報を組み合わせて、chainという実行手順を定義しています。
細かくは以下のようになります。
① contextには定義したベクトルDBからの情報取得(retriever)をした結果、user_pmtには実行時に受け取った値を設定。
(「RunnablePassthrough」は、受け取った値をそのまま代入する、という意味合い)
② ①の値をpmt_allで指定したプロンプトテンプレートに代入。
③ ②のプロンプトを、定義したLLMモデル(model = gemma3)に投入。
④ ③の結果から、LLMの回答箇所のみを抜き出す。(StrOutputParser)
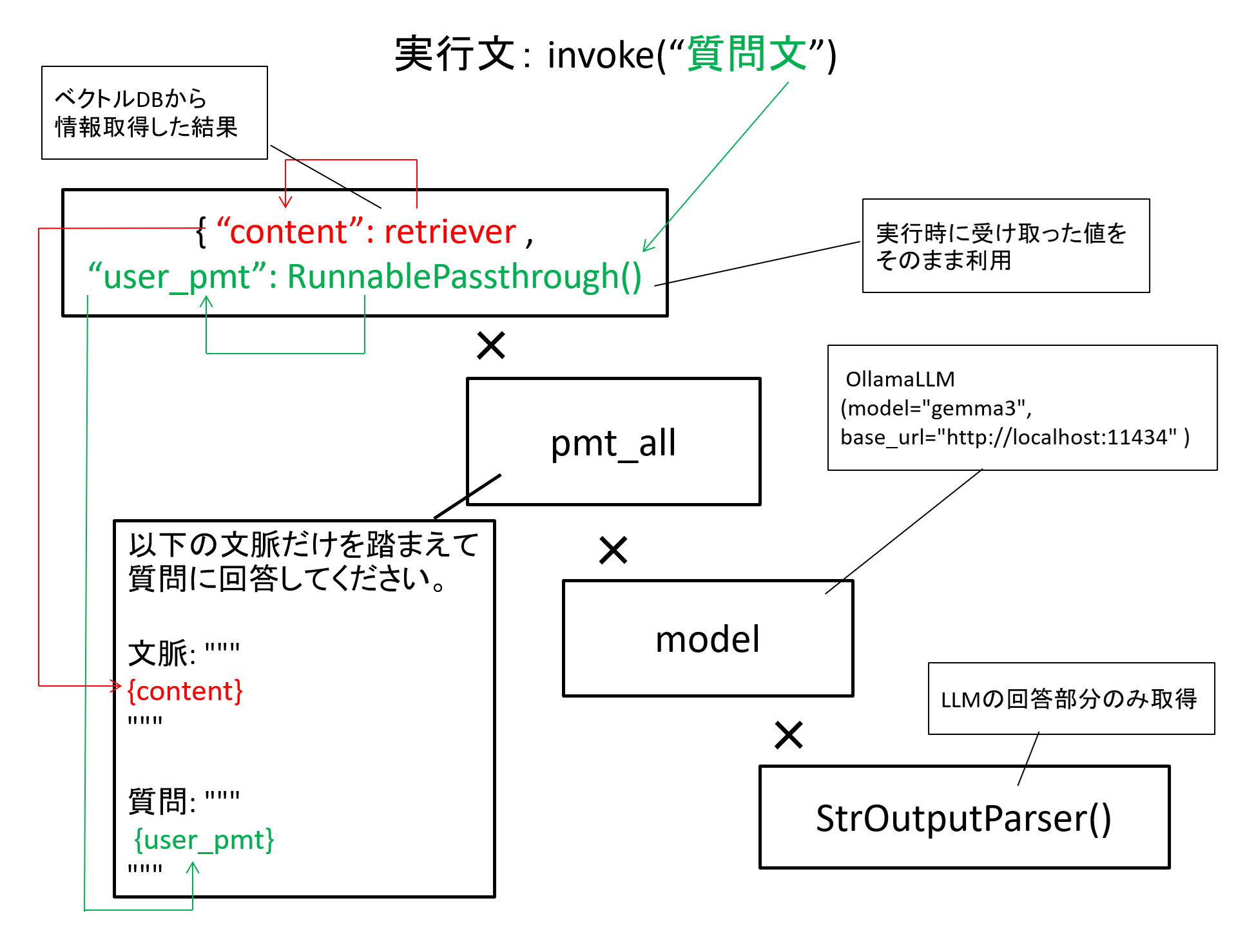
図3 chainの構成イメージ
このように、それぞれ個別に定義した要素(プロンプトテンプレートやモデル)を自由に組み合わせることで、実行手順を定義しています。
今回のソースコード内には入っていませんがチェインとチェインを組み合わせて利用する事もできるほか、LLMに複数の問い合わせを並列的に実施し、結果をプロンプトテンプレートに埋め込むなど、非常に柔軟に処理を定義できます。
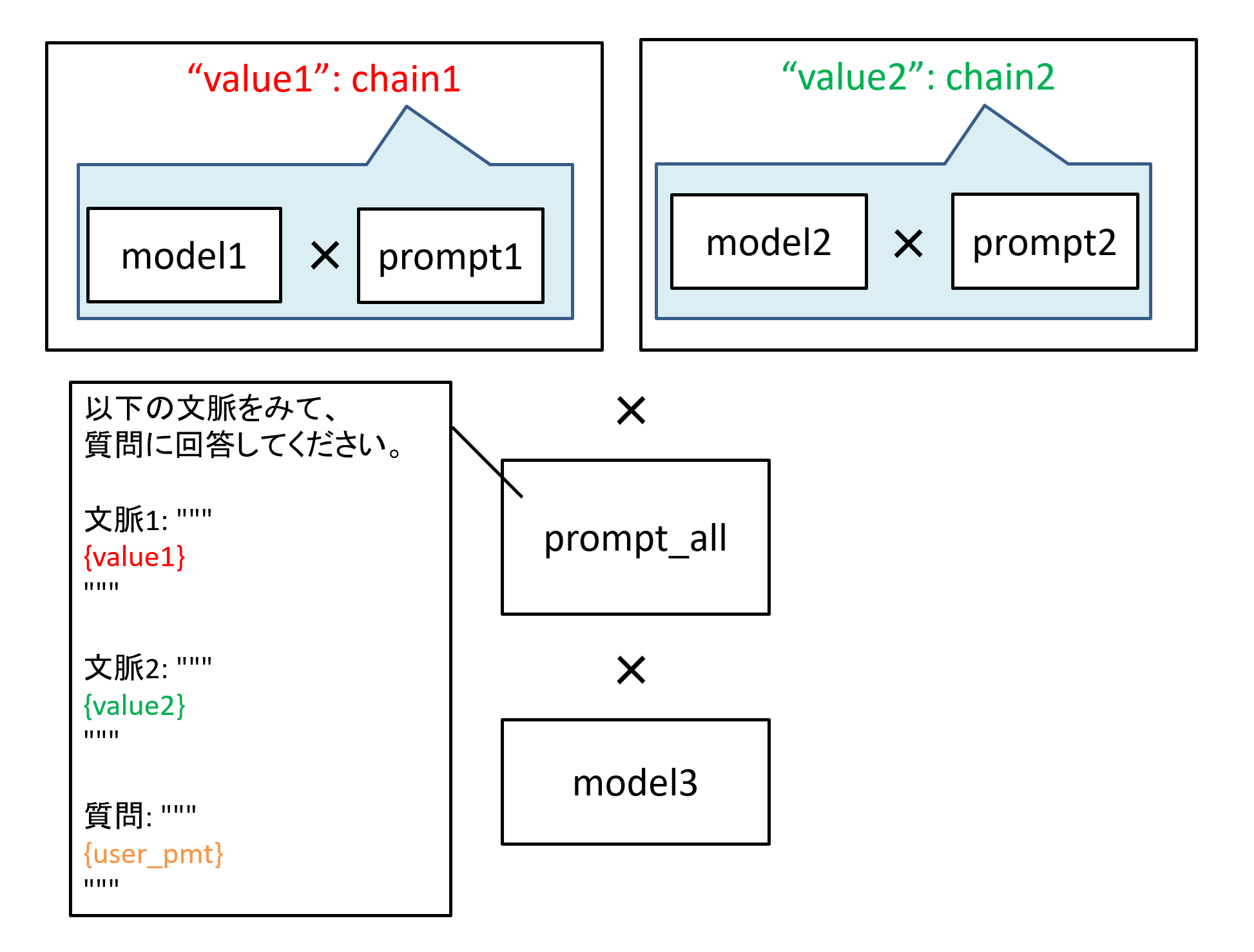
図4 チェインを組み合わせた処理のイメージ例
最後に定義した手順「chain」をinvoke(=実行)して、結果をai_msgに入れています。
その際に「user_pmt」で、ユーザの入力をchainに渡しています。
実行例と結果について
ソースコードも理解できたところで実行した結果を見てみましょう。
まずlocal_documentsフォルダの配下にPDFドキュメントを保存します。
その後は、以下でベクトルDBに情報を登録します。
python langchain_ollama.py -a
ドキュメントを読み込んでDBに登録します。
インデキシングが完了しました。
問題なく登録できたら、「chroma_db」フォルダが生成され、その配下にファイルができているはずです。
その後、以下でLLMに質問をしてみます。
python langchain_ollama.py -q "NTTテクノクロスは、いつ設立されたでしょうか。"
質問を受け付けました: NTTテクノクロスは、いつ設立されたでしょうか。
LLMの応答: 2017年4月1日
無事に回答が出力されました。
おわりに
ここまでローカルモデルで動く簡易なRAGの生成とあわせて、プロンプトテンプレート機能やチェイン機能、Ollamaとの連携とモデルへの問い合わせなどLangChainの基礎的な機能について解説してきました。
今回は触れていませんが、他にもAgent用の機能なども提供しています。
このようにLangChainは様々な機能を持ち合わせており、柔軟にLLMアプリケーションを作成する事ができます。
今回実現したのは基本機能であるため、Difyで実施したこととほぼ変わりません。
簡単な検証やPoCであればDifyを使うのが良いかと思いますが、細かく制御したり作りこみたい場合にはLangChainも利用の選択肢に入るかと思います。
基本的な機能はDifyを使い、Difyで実現できない箇所をLangChainや、次回紹介するLlamaIndexで実装し、組み合わせて利用するというのも良いかと思います。
次回は、RAGまわりの機能が豊富なフレームワークであるLlamaIndexについて、今回同様に基礎的な紹介をしていきたいと思います。
今回の内容についてご意見や質問等ございましたら、以下からお問い合わせください。
今回もご覧いただき、ありがとうございました。
本件に関するお問い合わせ




<<<<著者プロフィール>>>>
フューチャーネットワーク事業部
第一ビジネスユニット
山口 佳輝(YAMAGUCHI YOSHIKI)
NWに関係したシステム開発を担当しています
>>>>>>>>><<<<<<<<<
![]()