OpenStack(R)+Cephでストレージ冗長化
OpenStackのシステムを構築して安定して運用するためには、OpenStackのメインコンポーネントへの理解だけでなく、連携ソフトウェアの活用が大きな鍵となっています。特にOpenStackが利用するストレージに関しては、冗長化手法も含めてさまざまな技術が利用されています。




テクノロジーコラム
- 2015年09月29日公開
本記事に関するお問い合わせ先はこちら
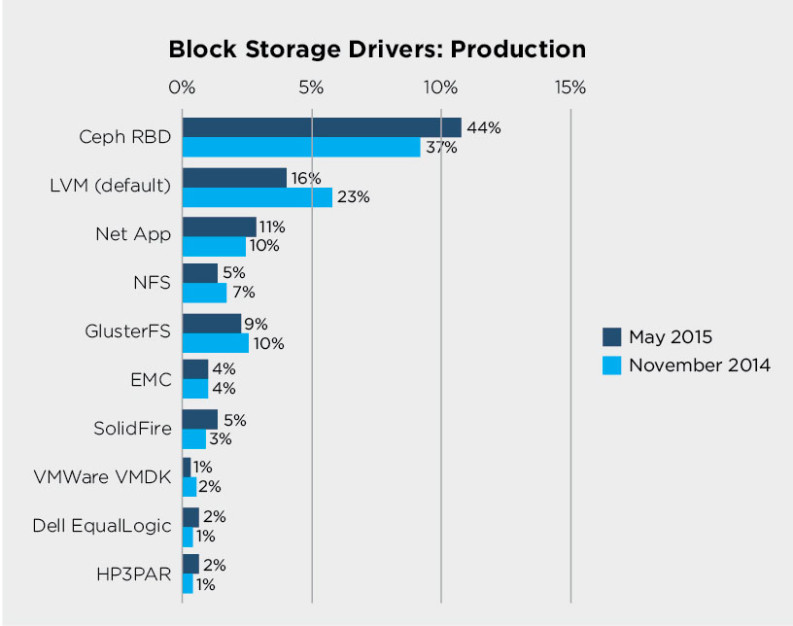
OpenStackのシステムを構築して安定して運用するためには、OpenStackのメインコンポーネントへの理解だけでなく、連携ソフトウェアの活用が大きな鍵となっています。特にOpenStackが利用するストレージに関しては、冗長化手法も含めてさまざまな技術が利用されています。2015年5月にカナダのバンクーバーで開催された「OpenStack Summit May 2015 Vancouver」の参加者アンケートでは、44%のユーザがOpenStackのブロック・ストレージにOSSである分散オブジェクトストア「Ceph」を利用していました。2013年まではLVM(ローカルディスク)が第1位でしたが、Cephの開発が進み品質が向上してきたことや、データの冗長化への要求が増してきたことから、多くのユーザがストレージにCephを選択するようになって来ました。
以下は、OpenStack users share how their deployments stack upのBlock Storage Driversの集計結果です。
Cephは何がいいの
Cephにはどのような特徴があるのでしょうか。Cephは分散オブジェクトストアRADOS (Reliable Autonomic Distributed Object Store)をベースにして、オブジェクトストア、ブロックデバイス、ファイルシステムの機能やインタフェースを提供しているため、1粒で3度おいしく利用することができます。 それだけではなく、Cephの最も大きな特徴は、保存されるデータのレプリカがどのサーバに配置されているかを、どこかのサーバに問い合わせることなく、クライアント側で計算(クラッシュアルゴリズム)により決定できることです。このため、サーバボトルネックにならずに容易に大規模な構成をとることができます。
Cephを構築してみる
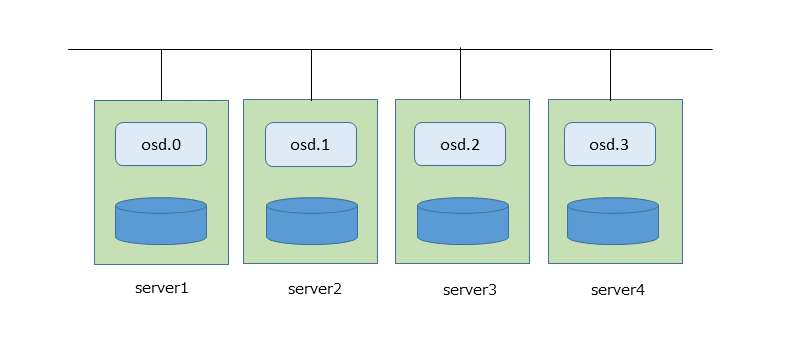
OpenStackでCephを利用するために、Cephのブロックデバイスを構築してみます。ここではOpenStackはKilo stableをCephはHammer (v0.94.3)を利用しています。Cephをデプロイするコマンド、ceph-deployコマンドで、オブジェクトを管理するデーモンosdが4台のサーバ(server1からserver4)に1台ずつ動作する構成を構築してみました。ここではモニターデーモンmonについては省略します。
 % ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 0.12000 root default
-2 0.03000 host server1
0 0.03000 osd.0 up 1.00000 1.00000
-3 0.03000 host server2
1 0.03000 osd.1 up 1.00000 1.00000
-4 0.03000 host server3
2 0.03000 osd.2 up 1.00000 1.00000
-5 0.03000 host server4
3 0.03000 osd.3 up 1.00000 1.00000
% ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 0.12000 root default
-2 0.03000 host server1
0 0.03000 osd.0 up 1.00000 1.00000
-3 0.03000 host server2
1 0.03000 osd.1 up 1.00000 1.00000
-4 0.03000 host server3
2 0.03000 osd.2 up 1.00000 1.00000
-5 0.03000 host server4
3 0.03000 osd.3 up 1.00000 1.00000
CephはOpenStackのどこに使えるの
Cephの用意ができたら、OpenStackのストレージとしてCephを使ってみましょう。OpenStackでは、Cephのブロックデバイス機能Rbd (RADOS Block Device)を利用しています。OpenStackでは、次のデータ保存場所にCephを使うことができます。
・glanceが管理するイメージの保存場所
・cinderが管理するボリュームの保存場所
・novaが管理する仮想マシンインスタンスの保存場所
glanceのイメージ保存場所がCephブロックデバイス上になるように設定してみます。詳細な設定方法は、Cephのドキュメントを参照してください。
・Ceph側の作業
プレースメントグループ(ハッシュのバケツだと思ってください)が128個あるimagesという名前のプール(論理的な保存領域)を作ります。他の作業もありますが、ここでは省略します。
・OpenStack側の作業
/etc/glance/glance-api.confの[glance_store]セクションに次の行を記載します。
glanceにtrusty-server-cloudimg-amd64-disk1.imgというイメージを登録してみましょう。
イメージidがbb193f00-1c34-4273-812d-d1f7beb18d8eでイメージが登録されました。プールimagesの中を見てみます。
プールimagesにイメージidのブロックデバイスが作成されています。実際のオブジェクトがどうなっているかというと、イメージサイズが258736640バイトなので、radosの中では8MB単位でrbd_data.ac5e5095454b.0000000000000000~rbd_data.ac5e5095454b.000000000000001eまでの31個のオブジェクトに分割されて保存されています。
・glanceが管理するイメージの保存場所
・cinderが管理するボリュームの保存場所
・novaが管理する仮想マシンインスタンスの保存場所
glanceのイメージ保存場所がCephブロックデバイス上になるように設定してみます。詳細な設定方法は、Cephのドキュメントを参照してください。
・Ceph側の作業
プレースメントグループ(ハッシュのバケツだと思ってください)が128個あるimagesという名前のプール(論理的な保存領域)を作ります。他の作業もありますが、ここでは省略します。
% ceph osd pool create images 128
・OpenStack側の作業
/etc/glance/glance-api.confの[glance_store]セクションに次の行を記載します。
[glance_store]
stores = glance.store.rbd.Stores
default_store = rbd
rbd_store_pool = images
rbd_store_user = glance
rbd_store_ceph_conf = /etc/ceph/ceph.conf
rbd_store_chunk_size = 8
glanceにtrusty-server-cloudimg-amd64-disk1.imgというイメージを登録してみましょう。
% glance image-create --name "trusty-server-cloudimg-amd64-disk1" --file ./trusty-server-cloudimg-amd64-disk1.img --disk-format qcow2 --container-format bare --progress
+------------------+--------------------------------------+
| Property | Value |
+------------------+--------------------------------------+
| checksum | 5027d3bb00688c50ee94e67bb1c76867 |
| container_format | bare |
| created_at | 2015-09-08T15:05:04.000000 |
| deleted | False |
| deleted_at | None |
| disk_format | qcow2 |
| id | bb193f00-1c34-4273-812d-d1f7beb18d8e |
| is_public | False |
| min_disk | 0 |
| min_ram | 0 |
| name | trusty-server-cloudimg-amd64-disk1 |
| owner | ae402b133b20446ea12abf06ff04b660 |
| protected | False |
| size | 258736640 |
| status | active |
| updated_at | 2015-09-08T15:08:46.000000 |
| virtual_size | None |
+------------------+--------------------------------------+
イメージidがbb193f00-1c34-4273-812d-d1f7beb18d8eでイメージが登録されました。プールimagesの中を見てみます。
% rbd -p images ls
bb193f00-1c34-4273-812d-d1f7beb18d8e
プールimagesにイメージidのブロックデバイスが作成されています。実際のオブジェクトがどうなっているかというと、イメージサイズが258736640バイトなので、radosの中では8MB単位でrbd_data.ac5e5095454b.0000000000000000~rbd_data.ac5e5095454b.000000000000001eまでの31個のオブジェクトに分割されて保存されています。
% rados -p images ls
rbd_data.ac5e5095454b.0000000000000000
rbd_data.ac5e5095454b.0000000000000001
rbd_data.ac5e5095454b.0000000000000002
…
rbd_data.ac5e5095454b.000000000000001c
rbd_data.ac5e5095454b.000000000000001d
rbd_data.ac5e5095454b.000000000000001e
rbd_directory
rbd_header.ac5e5095454b
rbd_id.bb193f00-1c34-4273-812d-d1f7beb18d8e
どうやって冗長化されているの
rados上のオブジェクトはどうやって冗長化されているのでしょうか。各オブジェクトはオブジェクト名のハッシュ値で、対応するプレースメントグループに配置されます。プレースメントグループは、クラッシュアルゴリズムにより配置されるosd群が決められます。複数のosdにプレースメントグループが配置されることで、その中にあるオブジェクトが冗長化されることになります。
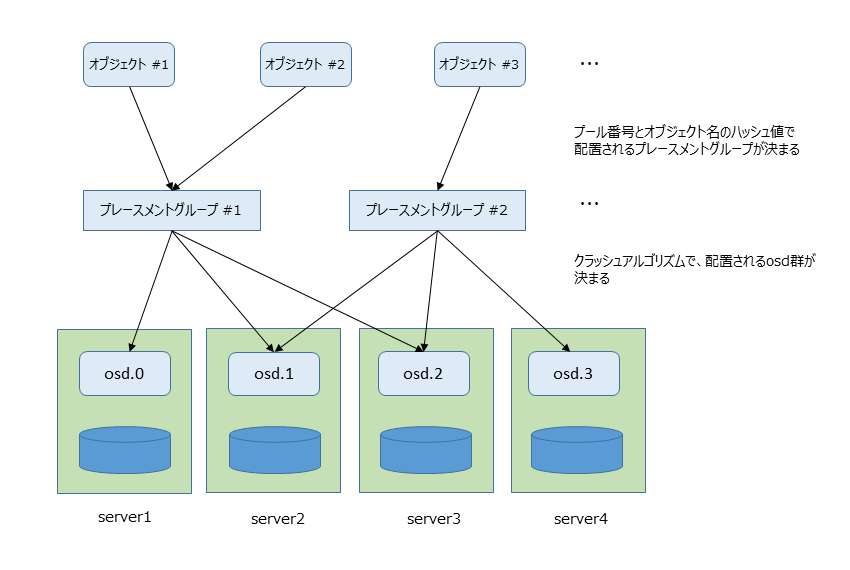
コマンドでプレースメントグループがどのosd群に配置されているかを確認できます。imagesのプール番号は1で、128個のプレースメントグループを設定しているため、1.0~1.7fと名前が付いたプレースメントグループの配置がimagesの配置になります。以下の例では出力の一部を省略しています。
Cephのデフォルトではレプリカ数は3なので、例えば、プレースメントグループ1.0の配置は[3,0,2]でosd3,osd0,osd2の3つのosdに、プレースメントグループ1.1の配置は[3,2,1]で、osd3,osd2,osd1の3つのosdに配置されています。
コマンドでプレースメントグループがどのosd群に配置されているかを確認できます。imagesのプール番号は1で、128個のプレースメントグループを設定しているため、1.0~1.7fと名前が付いたプレースメントグループの配置がimagesの配置になります。以下の例では出力の一部を省略しています。
% ceph osd pool ls detail
pool 0 'rbd' replicated size 3 min_size 1 crush_ruleset 0 object_hash rjenkins pg_num 64 pgp_num 64 last_change 54 flags hashpspool stripe_width 0
pool 1 'images' replicated size 3 min_size 2 crush_ruleset 0 object_hash rjenkins pg_num 128 pgp_num 128 last_change 73 flags hashpspool stripe_width 0
% ceph pg dump | grep ‘^1|^p’ | cut –f 1,14-15
pg_state up up_primary
1.0 [3,0,2] 3
1.1 [3,2,1] 3
…
1.e [0,3,1] 0
1.f [3,2,1] 3
Cephのデフォルトではレプリカ数は3なので、例えば、プレースメントグループ1.0の配置は[3,0,2]でosd3,osd0,osd2の3つのosdに、プレースメントグループ1.1の配置は[3,2,1]で、osd3,osd2,osd1の3つのosdに配置されています。
プレースメントグループの配置を変更してみる
プレースメントグループの配置がどのように決まるのか、クラッシュアルゴリズムが利用するクラッシュマップを見てみます。クラッシュマップの取り出し方は、cephのドキュメントを参照してください。以下が今回の構成(4台のサーバにosdが1台ずつの構成)のクラッシュマップになります。
Cephではプールを作ると「hostを選んでそのhostの下からosdを1つ選ぶ」というルールセット0がデフォルトで割り当たります。このため各サーバからosdが1つ選ばれます。 例として、プレースメントグループが8個、レプリカが2個のプールtestを作ってみます。
ルールセット0により、各プレースメントグループのレプリカは2つのhostのosdに配置されています。これで、本当に冗長化が確保されているのでしょうか。サーバが2台ずつ、ラックに分かれているような物理配置を考えてみます。
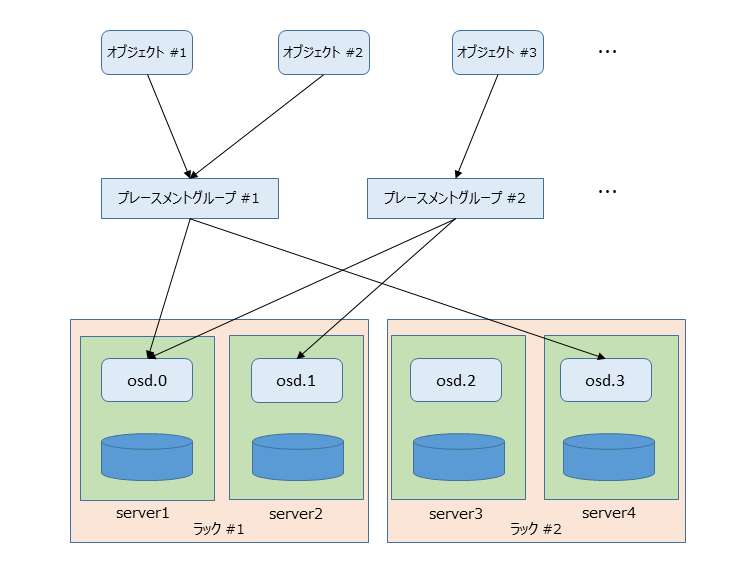 例えば、プレースメントグループ2.1は同じラック#1に搭載されたhostのosd.0,osd.1に配置されているため、ラックのエッジスイッチ故障や電源喪失等、ラック単位での故障が発生して、ラック#1のサーバにアクセスできなくなった場合に、オブジェクトへのアクセスが失われることになります。プレースメントグループ2.3, 2.5も同様です。では、どうすればいいのでしょうか。サーバをラック単位でまとめて、ラックごとにosdを選ぶように新しいルールセット1を追加して見ます。
例えば、プレースメントグループ2.1は同じラック#1に搭載されたhostのosd.0,osd.1に配置されているため、ラックのエッジスイッチ故障や電源喪失等、ラック単位での故障が発生して、ラック#1のサーバにアクセスできなくなった場合に、オブジェクトへのアクセスが失われることになります。プレースメントグループ2.3, 2.5も同様です。では、どうすればいいのでしょうか。サーバをラック単位でまとめて、ラックごとにosdを選ぶように新しいルールセット1を追加して見ます。
この新しいルールセット1をtestに割り当てます。
すべてのプレースメントグループがラック間に分散されたosd群に配置されるようなり、ラック単位の故障が発生しても、冗長性が確保されオブジェクトにアクセスできるようになりました。
host server1 {
id -2 # do not change unnecessarily
# weight 1.000
alg straw
hash 0 # rjenkins1
item osd.0 weight 1.000
}
…
host server4 {
id -5 # do not change unnecessarily
# weight 1.000
alg straw
hash 0 # rjenkins1
item osd.3 weight 1.000
}
root default {
id -1 # do not change unnecessarily
# weight 0.120
alg straw
hash 0 # rjenkins1
item server1 weight 1.000
item server2 weight 1.000
item server3 weight 1.000
item server4 weight 1.000
}
rule replicated_ruleset {
ruleset 0
type replicated
min_size 1
max_size 10
step take default
step chooseleaf firstn 0 type host
step emit
}
Cephではプールを作ると「hostを選んでそのhostの下からosdを1つ選ぶ」というルールセット0がデフォルトで割り当たります。このため各サーバからosdが1つ選ばれます。 例として、プレースメントグループが8個、レプリカが2個のプールtestを作ってみます。
% ceph osd create pool test 8
% ceph set pool test size 2
% ceph pg dump | grep ‘^2|^p’ | cut –f 1,14-15
pg_state up up_primary
2.0 [3,0] 3
2.1 [0,1] 0
2.2 [3,1] 3
2.3 [3,2] 3
2.4 [1,3] 1
2.5 [3,2] 3
2.6 [2,1] 2
2.7 [3,0] 3
ルールセット0により、各プレースメントグループのレプリカは2つのhostのosdに配置されています。これで、本当に冗長化が確保されているのでしょうか。サーバが2台ずつ、ラックに分かれているような物理配置を考えてみます。
例えば、プレースメントグループ2.1は同じラック#1に搭載されたhostのosd.0,osd.1に配置されているため、ラックのエッジスイッチ故障や電源喪失等、ラック単位での故障が発生して、ラック#1のサーバにアクセスできなくなった場合に、オブジェクトへのアクセスが失われることになります。プレースメントグループ2.3, 2.5も同様です。では、どうすればいいのでしょうか。サーバをラック単位でまとめて、ラックごとにosdを選ぶように新しいルールセット1を追加して見ます。
rack rack1 {
id -6
alg straw
hash 0
item server1 weight 1.000
item server2 weight 1.000
}
rack rack2 {
id -7
alg straw
hash 0
item server3 weight 1.000
item server4 weight 1.000
}
root redundant {
id -8
alg straw
hash 0
item rack1 weight 2.000
item rack2 weight 2.000
}
rule redundent_ruleset {
ruleset 1
type replicated
min_size 1
max_size 10
step take redundant
step chooseleaf firstn 0 type rack
step emit
}
この新しいルールセット1をtestに割り当てます。
% ceph osd pool set test crush_ruleset 1 % ceph pg dump | grep ‘^2|^p’ | cut –f 1,14-15 pg_state up up_primary 2.0 [3,0] 3 2.1 [3,1] 3 2.2 [3,1] 3 2.3 [3,0] 3 2.4 [2,1] 2 2.5 [3,1] 3 2.6 [2,0] 2 2.7 [3,0] 3
すべてのプレースメントグループがラック間に分散されたosd群に配置されるようなり、ラック単位の故障が発生しても、冗長性が確保されオブジェクトにアクセスできるようになりました。
おわりに
OpenStackのストレージにCephを利用することで、OpenStackが利用するストレージを冗長化することができます。Cephを利用して冗長化を設定する際には、論理構成だけでなく物理構成も含めて、実際の構成にあったレプリカ配置ルールを設定しておかないと、故障時に期待通りの動作が保障されないことになってしまいますので気をつけましょう。 NTTテクノクロスではOpenStackのメインコンポーネントだけでなく、OpenStackと連携するCephやSwiftといった分散オブジェクトストアに関しても、豊富な経験を有しています。 OpenStackの導入を検討している方は、ぜひこちらからお問い合わせください。

OpenStack のワードマークは、米国とその他の国における OpenStack Foundation の登録商標/サービスマークまたは商標/サービスマークのいずれかであり、 OpenStack Foundation の許諾の下に使用されています。
NTTテクノクロスは、OpenStack Foundation や OpenStack コミュニティの関連会社ではなく、公認や出資も受けていません。
その他会社名、製品名などの固有名詞は、一般に該当する会社もしくは組織の商標または登録商標です。
OpenStack のワードマークは、米国とその他の国における OpenStack Foundation の登録商標/サービスマークまたは商標/サービスマークのいずれかであり、 OpenStack Foundation の許諾の下に使用されています。
NTTテクノクロスは、OpenStack Foundation や OpenStack コミュニティの関連会社ではなく、公認や出資も受けていません。
その他会社名、製品名などの固有名詞は、一般に該当する会社もしくは組織の商標または登録商標です。
参考文献・関連情報
■Cephのドキュメント
http://ceph.com/docs
■Installation (QUICK)
http://ceph.com/docs/master/start/
■Block device and OpenStack
http://ceph.com/docs/master/rbd/rbd-openstack/
■Crash Map
http://ceph.com/docs/master/rados/operations/crush-map/
連載シリーズ
テクノロジーコラム
あわせて読みたい


著者プロフィール

鷲坂 光一
![]()