PostgreSQLでストリーミングレプリケーション(SR)環境はどう構築する?基本的な要点をおさえよう!
PostgreSQLのストリーミングレプリケーション(通称SR)の構築方法を初心者向けにご説明致します。




ぬこのたのしいぽすぐれ教室
- 2025年12月04日公開

目次
1.はじめに
2.SRの仕組み
3.事前準備
4.DBクラスタの作成(プライマリサーバー)
5.パラメータ設定(プライマリサーバー)
6.pg_hba.confの設定(プライマリサーバー)
7.レプリケーションスロットの設定
8.初期データの導入
9.プライマリサーバーからのバックアップ取得
10.パラメータ設定(スタンバイサーバー)
11.pg_hba.confの設定(スタンバイサーバー)
12.レプリケーションの確認
13.よくあるエラー事象
14.まとめ
はじめに
こんにちは!NTTテクノクロスで PostgreSQL の技術支援とデータエンジニアをやっています、外山です。
今回は PostgreSQL の初学者に向け、ストリーミングレプリケーション(SR) の手順を分かりやすく解説していきます。
ストリーミングレプリケーションの仕組み
ストリーミングレプリケーションは、WAL(Write Ahead Logging)と呼ばれる「PostgreSQLへの更新要求があったに書き込まれるログ情報」を元に、リアルタイムで他の PostgreSQLサーバー上に全く同じデータベースを構築できる機能です。
本記事では、ユーザーが更新するデータベースサーバーの「プライマリーサーバー」1台、ログ情報を受け取るデータベースサーバーの「スタンバイサーバー」2台の、合計3台構成でストリーミングレプリケーション環境を作成したいと思います。
(構築イメージ)
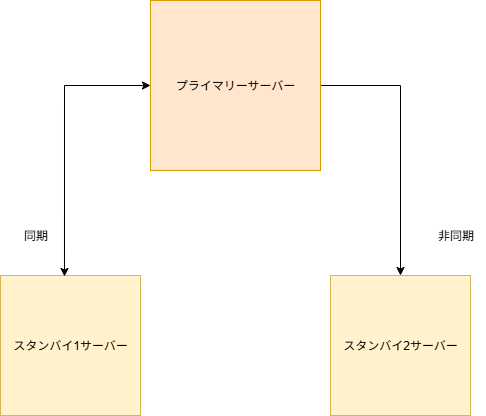
事前準備
環境作成
1. サーバー準備
本記事では仮想マシン(VM)上でレプリケーションを構成します。(Oracle VM VirtualBOXなど)
<VMの環境設定>
・OS:RHEL ver9.0
・プロセッサ数: 2CPU
・メモリサイズ: 4096MB
・ストレージ: 30GB
・PostgreSQL: ver17.5
まず、プライマリーサーバー、スタンバイサーバー2台(合計3台)分の VM を、上記設定で作成します。
2. PostgreSQLのインストール、構築準備
※既にPostgreSQLのインストールができている方は飛ばしてください。
対象:プライマリーサーバー、スタンバイサーバー2台
RPMレポジトリのインストール
$ sudo dnf install -y https://download.postgresql.org/pub/repos/yum/reporpms/EL-10-x86_64/pgdg-redhat-repo-latest.noarch.rpm
postgresql(ver17)のインストール
$ sudo dnf install -y postgresql17-server
PostgreSQL のバイナリコマンド(psql、initdb 等)を使用するために、PostgreSQL のパスを設定します。
※ OS の postgres ユーザで、「.bashrc」ファイルの最下部にパスを追記する。
# su - postgres
$ sudo vi ~/.bashrc
(エディタ内:下記一文を追記します)
PATH=$PATH:/usr/pgsql-17/bin
上記設定を反映させます。
$ source ~/.bashrc
これにてPostgreSQLのバイナリコマンドを実行できるようになりました。 念のため、下記コマンドでバイナリコマンドを実行できるか確認してみてください。
$ psql --version
DBクラスタの作成(プライマリサーバー)
DBクラスタとはデータベースの格納領域です。(標準SQLではカタログクラスタと呼ばれているものです)
対象:プライマリーサーバー
>
何かしら既にDBクラスタを作成している場合はこちらの手順も飛ばしてください。
DBクラスタとするディレクトリの作成
ディレクトリの配置場所は任意です。
今回は /home/postgres/primary 配下にDBクラスタを作成します。
$ mkdir /home/postgres/primary
DBクラスタの作成(初期化)
initdbコマンドで先ほど作成したディレクトリ内にDBクラスタを作成します。
$ initdb --data-checksums --no-locale -D /home/postgres/primary --encoding=UTF8
The files belonging to this database system will be owned by user "postgres".
This user must also own the server process.
The database cluster will be initialized with locale "C".
The default text search configuration will be set to "english".
Data page checksums are enabled.
fixing permissions on existing directory /home/postgres/primary ... ok
creating subdirectories ... ok
selecting dynamic shared memory implementation ... posix
selecting default "max_connections" ... 100
selecting default "shared_buffers" ... 128MB
selecting default time zone ... Asia/Tokyo
creating configuration files ... ok
running bootstrap script ... ok
performing post-bootstrap initialization ... ok
syncing data to disk ... ok
initdb: warning: enabling "trust" authentication for local connections
initdb: hint: You can change this by editing pg_hba.conf or using the option -A, or --auth-local and --auth-host, the next time you run initdb.
Success. You can now start the database server using:
PostgreSQL を起動します。
pg_ctl -D /home/postgres/primary -l logfile start
パラメータ設定(プライマリサーバー)
ここでは、プライマリサーバー側のレプリケーションに関するパラメータについてざっくり説明します。
(スタンバイサーバーに関しては後述)
ファイル /home/postgres/primary/postgresql.conf の最後尾に下記パラメータ設定を付け加えます。
| パラメータ名 | 設定値 | 内容 |
| listen_addresses | '*' | クライアントからの接続を監視するTCP/IPアドレスを指定(注意: '*'でなく、IPアドレスを指定する場合は自身が持つIPアドレスを書くことになる)。 |
| wal_level | replica | WALの情報量を指定。レプリケーション構成にする場合はreplica 以上に設定する。 |
| max_wal_senders | 10 | 同時に稼動するWAL送信プロセスの最大数。 |
| max_replication_slots | 10 | レプリケーションスロット(後述)の最大数。 |
| synchronous_standby_names(※) | 'FIRST 1 (standby1)' | 同期スタンバイサーバのリスト。指定したスタンバイサーバーがデータを受信したことを確認するまでプライマリサーバーはコミットを待機する。左はスタンバイサーバーのうち1台が同期、2台目が非同期の場合。 |
| archive_mode | always | archive_modeが有効(on / always)な場合、完了したWALセグメントはアーカイブ格納領域に送信される。 |
| archive_command | '/bin/cp %p /mnt/archive/pg_archive/%f' | archive_modeが有効な時、左記のコマンドにより /mnt/archive/pg_archive 下にアーカイブファイルを保存させる |
※後述の「初期データの導入」が終了するまでは sychronous_standby_names はコメントアウトしてください。
スタンバイサーバーの準備ができていない状態で本パラメータを設定してしまうと、プライマリサーバーがコミット待機を続けてしまい、上手くテーブルを作成できなくなります。
(記述例)
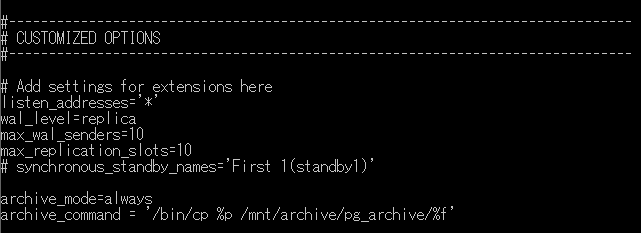
アーカイブWALを格納するディレクトリの作成
対象: プライマリサーバー、スタンバイサーバー2台
サーバーパラメータ archive_command にて mnt/archive/pg_archive 配下にアーカイブが格納されるよう設定しましたが、ディレクトリはご自身で作成しておく必要があります。
今回はスタンバイサーバーも同じディレクトリ構成にするため、3台すべてに mkdir コマンドを実行します。
$ sudo mkdir -p /mnt/archive/pg_archive
# ディレクトリの所有者をPostgreSQLの実行ユーザに変更
$ sudo chown postgres:postgres /mnt/archive/pg_archive
pg_hba.confの設定(プライマリサーバー)
こちらもまずはプライマリサーバーの設定方法だけ記載します。
ファイル /home/postgres/primary/pg_hba.conf の該当箇所を下記に変更します。
# IPv4 local connections:
local all all trust
host all all <プライマリーサーバのIPアドレス> trust # Primary機
# replication privilege
local replication all trust
host replication all 127.0.0.1/32 trust
host replication all <プライマリーサーバ1のIPアドレス> trust # Standby1機
host replication all <プライマリーサーバ2のIPアドレス> trust # Standby2機
(記述例)
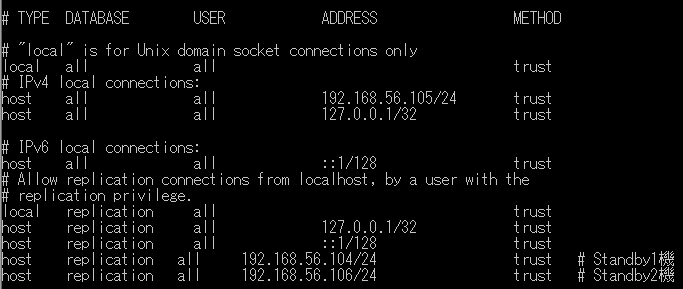
レプリケーションスロットの設定
レプリケーションスロットを使用することで、以下を実現できます。
・全てのスタンバイサーバーが WALセグメントを受け取るまで、プライマリサーバーがWALセグメントを削除しないことを保証する
・スタンバイサーバーが接続していない場合、リカバリの競合が発生する可能性がある行をプライマリサーバーが削除しないことを保証する
psqlに接続し、下記コマンドを実行することでレプリケーションスロットを作成できます。
対象:プライマリーサーバー
・レプリケーションスロットはスタンバイサーバーの数だけ用意する(下記は3台構成でスタンバイが2台の場合)。
※プライマリ側のPostgreSQLの起動
$ pg_ctl start -D /home/postgres/primary
(省略)
$ psql
psql (17.4)
Type "help" for help.
postgres=# SELECT * FROM pg_create_physical_replication_slot('repl_slot1');
slot_name | lsn
------------+-----
repl_slot1 |
postgres=# SELECT * FROM pg_create_physical_replication_slot('repl_slot2');
slot_name | lsn
------------+-----
repl_slot2 |
作成したレプリケーションスロットを確認します。
postgres=# select * from pg_replication_slots;
slot_name | plugin | slot_type | datoid | database | temporary | active | active_pid | xmin | catalog_xmin | restart_lsn | confirmed_flush_lsn | wal_status | safe_wal_size | two_phase | inactive_since | conflicting | invalidation_reason | failover | synced
------------+--------+-----------+--------+----------+-----------+--------+------------+------+--------------+-------------+---------------------+------------+---------------+-----------+-------------------------------+-------------+---------------------+----------+--------
repl_slot_1 | | physical | | | f | f | | | | | | | | f | 2025-04-16 08:19:05.232003+00 | | | f | f
repl_slot_2 | | physical | | | f | f | | | | | | | | f | 2025-04-16 08:19:37.059018+00 | | | f | f
(2 rows)
初期データの導入
プライマリーサーバーにレプリケーションさせるデータを導入します。今回はPostgreSQLのベンチマークに使用されるpgbenchを使用し、疑似的なデータベースを作成していきます。
・pgbenchを使用して、Primary機にデータを投入する。
・-s オプションにはスケールファクタ(データサイズ:スケール1は15MB)を指定する。
・初期データ投入の段階でレプリケーション構成は組まず、単体構成で行う。
$ pgbench -i -s 100
dropping old tables...
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
creating tables...
generating data (client-side)...
vacuuming...
creating primary keys...
done in 79.17 s (drop tables 0.03 s, create tables 0.09 s, client-side generate 65.35 s, vacuum 0.77 s, primary keys 12.94 s).
スタンバイデータベースクラスタの作成(プライマリサーバーからのバックアップ取得)
スタンバイデータベースクラスタは、稼動中のデータベースクラスタをコピーすることで作成します。
コピーには pg_basebackup というバックアップ用のコマンドを用います。
pg_basebackup のコマンドは、スタンバイサーバー上から実行します。
-R オプションを指定すると postgresql.auto.conf が作成されます。
このファイルにはプライマリサーバーへの接続情報など、レプリケーションを行うための設定が自動で記載されます。
※ただし、変更する場合は手動で編集できず、ALTER SYSTEM コマンドを使用することに注意
# スタンバイサーバー1から実行
$ cd /home/postgres
$ pg_basebackup -R -h <プライマリサーバーのIPアドレス> -p 5432 -U postgres -D standby1
# スタンバイサーバー2から実行
$ cd /home/postgres
$ pg_basebackup -R -h <プライマリサーバーのIPアドレス> -p 5432 -U postgres -D standby2
取得できない場合はプライマリサーバーのファイアウォール設定などを確認してみてください。
プライマリサーバー側のファイアウォールで、ポート5432(PostgreSQLが使用するポート)を解放する。
# 永続的にポートを開放する
sudo firewall-cmd --zone=public --add-port=5432/tcp --permanent
# 設定を反映させるためにfirewalldをリロードします。
sudo firewall-cmd --reload
パラメータ設定(スタンバイサーバー)
スタンバイサーバーの postgresql.conf ファイルの中身に下記を付け加えます。cluster_name と primary_slot_name は適宜スタンバイサーバーに応じて選択してください。
「スタンバイサーバー1用の設定」(同期レプリケーション)
| パラメータ名 | 設定値 | 内容 |
| listen_addresses | '*' | |
| hot_standby | on | |
| cluster_name | 'standby1' | プライマリサーバーの synchronous_standby_names に対応するクラスター名を記入。 |
| primary_slot_name | 'repl_slot1' | 「レプリケーションスロットの設定」で作成した名前を書く。 |
| archive_mode | always | |
| archive_command | '/bin/cp %p /mnt/archive/pg_archive/%f' |
「スタンバイサーバー2用の設定」(同期レプリケーション)
| パラメータ名 | 設定値 |
| listen_addresses | '*' |
| hot_standby | on |
| cluster_name | 'standby2' |
| primary_slot_name | 'repl_slot2' |
| archive_mode | always |
| archive_command | '/bin/cp %p /mnt/archive/pg_archive/%f' |
※ プライマリサーバーのバックアップで作成したため、postgresql.conf はプライマリサーバー上の設定になっていると思います。
syncronous_standby_names など、不要な項目は適宜削除またはコメントアウトしてください。
(記述例)
■スタンバイサーバー1
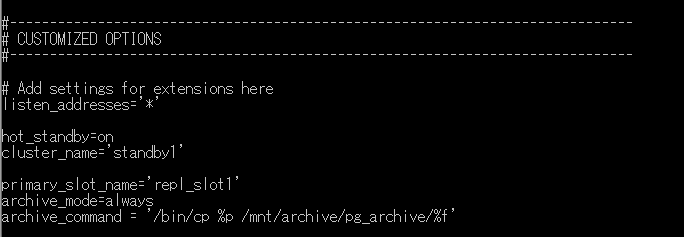
■スタンバイサーバー2

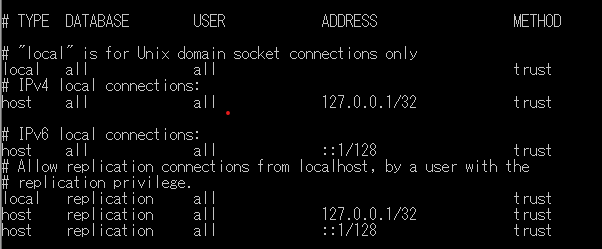
pg_hba.confの設定(スダンバイサーバー)
こちらもスタンバイサーバー2台の設定をしていきます。 プライマリーサーバーの設定が残っていますので、2台とも下記設定に変更してください。
### IPv4 local connections:
local all all trust
host all all 127.0.0.1/32 trust
### replication privilege
local replication all trust
host replication all 127.0.0.1/32 trust
※ プライマリーサーバーで設定していたレプリケーション情報は削除します。
(記述例)
レプリケーションの確認
プライマリーサーバー側の postgresql.conf の synchronous_standby_names のコメントアウトを外し、 プライマリーサーバー側の PostgreSQL を再起動します。
$ pg_ctl restart -D /home/postgres/primary
その後、スタンバイ2台を起動します。
$ pg_ctl start -D /home/postgres/standby1
$ pg_ctl start -D /home/postgres/standby2
下記コマンドで実際にレプリケーション構成が取れているか確認します。
コマンドはプライマリーサーバー上で実行します。
・application_name:設定したアプリケーションネームになっているか
・client_addr:IPアドレスが正しいか
・sync_state:sync(同期)になっているか、又はasync(非同期)になっているか
$psql
postgres=# select * from pg_stat_replication;
pid | usesysid | usename | application_name | client_addr | client_hostname | client_port | backend_sta
rt | backend_xmin | state | sent_lsn | write_lsn | flush_lsn | replay_lsn | write_lag | flush_lag | r
eplay_lag | sync_priority | sync_state | reply_time
------+----------+----------+------------------+----------------+-----------------+-------------+--------------------
-----------+--------------+-----------+------------+------------+------------+------------+-----------+-----------+--
----------+---------------+------------+-------------------------------
1439 | 10 | postgres | standby1 | 192.168.56.104 | | 34754 | 2025-10-28 10:13:04
.606637+09 | | streaming | 0/550000D8 | 0/550000D8 | 0/550000D8 | 0/550000D8 | | |
| 1 | sync | 2025-10-28 10:16:26.204806+09
1447 | 10 | postgres | standby2 | 192.168.56.106 | | 38160 | 2025-10-28 10:15:35
.503777+09 | | streaming | 0/550000D8 | 0/550000D8 | 0/550000D8 | 0/550000D8 | | |
| 0 | async | 2025-10-28 10:16:28.285475+09
(2 rows)
また、プライマリ、スタンバイ両方のログを確認して、無事レプリケーションができているか確認してください。
・ログの所在:/home/postgres/primary/log/
<プライマリー側>
LOG: standby "standby1" is now a synchronous standby with priority 1
<スタンバイ側>
LOG: started streaming WAL from primary at 0/53000000 on timeline 1
データ挿入による確認
プライマリーサーバー上の現在のテーブルを確認、新規テーブルを挿入します。
$ psql
psql (17.6)
Type "help" for help.
postgres=# \d
List of relations
Schema | Name | Type | Owner
--------+------------------+-------+----------
public | pgbench_accounts | table | postgres
public | pgbench_branches | table | postgres
public | pgbench_history | table | postgres
public | pgbench_tellers | table | postgres
(4 rows)
続いて、新規にテーブルを作成します。
postgres=# CREATE TABLE my_table (
id SERIAL PRIMARY KEY,
name VARCHAR(50) NOT NULL,
age INTEGER,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
CREATE TABLE
postgres=# \d
List of relations
Schema | Name | Type | Owner
--------+------------------+----------+----------
public | my_table | table | postgres
public | my_table_id_seq | sequence | postgres
public | pgbench_accounts | table | postgres
public | pgbench_branches | table | postgres
public | pgbench_history | table | postgres
public | pgbench_tellers | table | postgres
(6 rows)
スタンバイサーバー側からも、新規作成したテーブルが表示されていればレプリケーションは成功していることが確認できます。
よくあるエラー事象
■ WALアーカイブが格納されるディレクトリへのアクセス権限がない
postgresql.conf の archive_command で、アーカイブWALを保有するディレクトリの所有者が rootユーザなどになっており、アーカイブWALが保存できず上手くレプリケーションができないケースがありえます。
⇒chownコマンドで postgresユーザに所有者を変更しましょう。
■ レプリケーションに必要なWALファイルがなくなっている
pg_basebackup の実行から時間が経ってしまうと、レプリケーションに必要な WALがプライマリーサーバー上から削除されてしまい上手くレプリケーションできないことが考えられます。
⇒その場合は、再度 pg_basebackup を使用してバックアップを取りなおす必要があります。
■ プライマリーサーバー側のFW設定でスタンバイサーバーからの接続がはじかれている
postgresql.conf に記載した primary_conninfo の設定に従ってスタンバイサーバーからプライマリーサーバーに接続しようとしたところ、ファイアウォールの設定やSELINUXの設定で接続ができないケースが考えられます。
⇒ファイアウォールの設定を弱める場合はセキュリティに問題が無いことを確認して設定してください。
まとめ
無事にストリーミングレプリケーション環境を構築できましたでしょうか? 本記事が PostgreSQL を初めて扱う方の参考になれば幸いです。
PostgreSQLのことならNTTテクノクロスにおまかせください!
NTTテクノクロス株式会社ではPostgreSQLに関する各種のお問い合わせや、移行に関する対応を受け付けています。
オンプレだけではなく、Azure、AWSなどのクラウド上でのシステムの導入、開発、維持管理のご相談もお待ちしております。




NTTテクノクロス株式会社
IOWNデジタルツインプラットフォーム事業部
第三ビジネスユニット
![]()