リソース設定(メモリ) ~DPDK入門 第5回~
DPDKでは高速化を実現するためHugePageというメモリ管理の機能を使っています。今回は現在は主流のアーキテクチャであるNUMA(Non-Uniform Memory Access)での設定方法を解説します。




DPDK入門
- 2019年04月11日公開
はじめに
こんにちは、NTTテクノクロス株式会社の寺尾です。
前回に引き続きDPDKのメモリ設定に関して解説していきます。よろしくお願いします。

NUMA
前回はHugePageの説明を中心に解説させて頂きましたが、今回は現在主流のアーキテクチャであるNUMA(Non-Uniform Memory Access)での設定方法を解説します。以下のコマンドで 複数のnodes(ノード)が表示されるアーキテクチャは、複数のノード毎にメモリが存在するため、より細かく設定を行う必要があります。
以下のコマンドでノード数が確認できます。特に2 nodes以上の出力が得られた場合に関して、解説していきます。
available: 2 nodes (0-1)
・・・・・
NUMAとは
複数のCPUがメインメモリを共有した場合、各CPUが共通経路(バス)を経由してメモリにアクセスする必要があります。従来のアーキテクチャではCPU数が増えると共通経路の利用率も増加するため、そこにボトルネックが起こる可能性があります。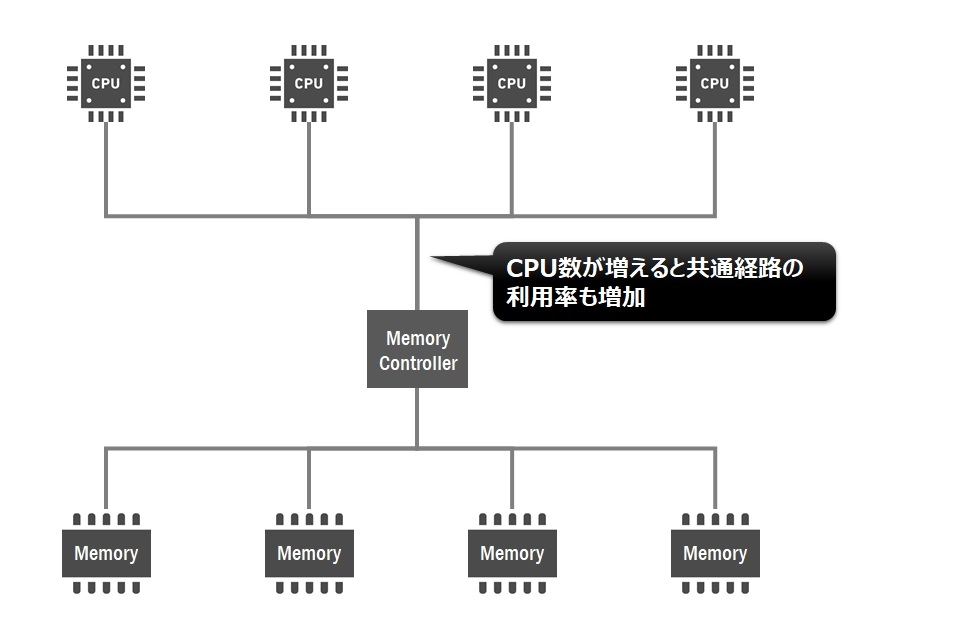
NUMAではその問題を解決するため、各CPUが同時にアクセスできるローカルメモリを搭載し、CPU数が増えても共通経路のボトルネックを解消することで処理性能を高めています。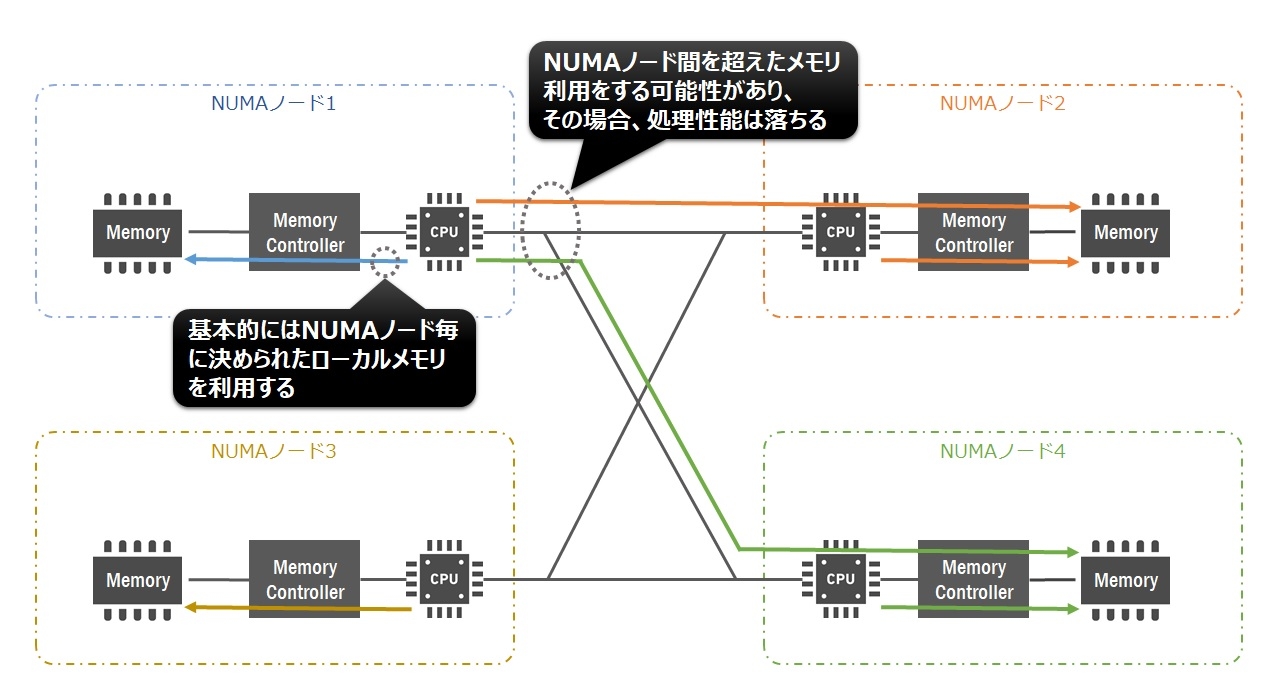
尚、各CPUは必要に応じてローカルメモリに配置されていないデータを利用する可能性があります。その場合でも、CPU間のバスを使いリモートメモリにアクセスすることが可能ですがやや処理が遅くなります。高速にアクセスできるローカルメモリとやや処理が遅いリモートメモリの両方を使うため、「Non-Uniform」と表現しています。
またPCIデバイスに関してもノードとの関係を意識することは重要です。各CPUとメモリ及びPCIデバイスの関係はlstopoコマンドで確認できます。例えば、手元にある2ノード構成のマシンを確認した結果のイメージが以下です。node0(NUMA NODE P#0)はNICのeth1~eth4や論理プロセッサの0,2,4,6が配置されており、node1(NUMA NODE P#1)はNICのeth5~eth6や論理プロセッサの1,3,5,7が配置されていることが確認できます。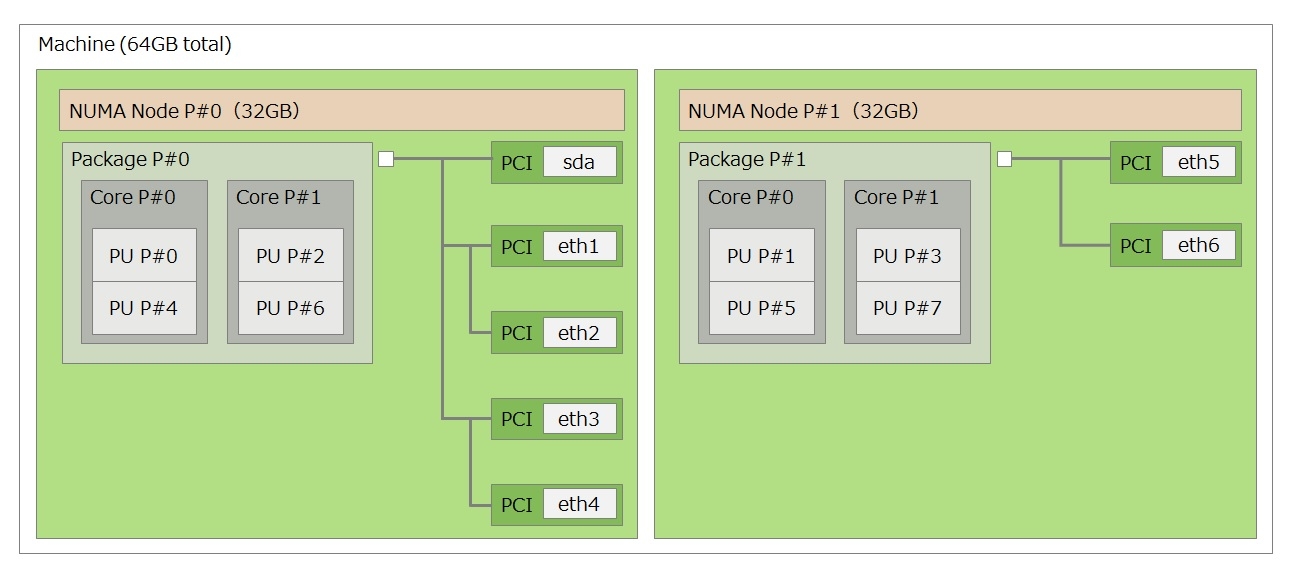
DPDKを利用する際の考慮点
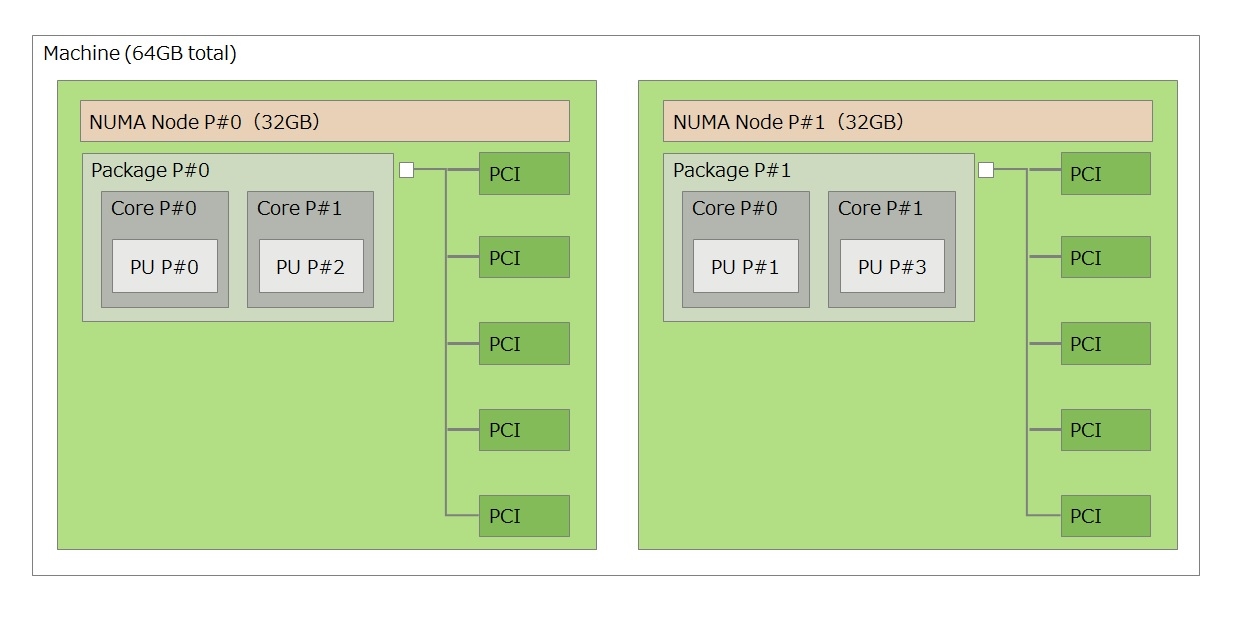
複数のCPUが搭載されたマシンを利用する場合は、利用するNICの位置を把握することが重要になります。普通はNICの位置を用途に応じて変更するケースはすくないと思いますので、lstopoコマンドなどでNICが所属しているノードを調べ、極力自身のノード内のメモリ及びCPUで処理を行うことが理想となります。今回は上記で紹介した2ノード構成のマシンを題材に、eth1及びeth2をDPDKとして利用した例で推奨したい設定例を紹介します。
まずDPDKではメモリはhugepageを利用するため、所属するノード毎にhugepageを設定します。今回は上記で紹介したマシン構成を使って解説します。
以前紹介したhugepageの設定手順では、ノードを意識した設定はしていません。例えば2ノード構成のマシンの場合だと、自動的に各ノードに均等にhugepageが割当たることが確認できます。grubに8Gのhugepageを確保した場合を確認してみます。
・・・・・
GRUB_CMDLINE_LINUX="default_hugepagesz=1G hugepagesz=1G hugepages=8"
・・・・・
各ノード毎のhugepageを確認する場合は、以下のファイルを参照します。
4
$ cat /sys/devices/system/node/node1/hugepages/hugepages-1048576kB/nr_hugepages
4
それぞれのノード毎に4GBのhugepageが確保されていることが確認できました。ただし今回はeth1及びeth2をDPDKとして割り当てるため、node1側のhugepageは積極的に利用することはないため、node0側のhugepageを大きく割り当ててみます。hugepageをnode毎に設定する場合は、以下のコマンドを用いて設定します。
# echo 2 > /sys/devices/system/node/node1/hugepages/hugepages-1048576kB/nr_hugepages
※ # はroot権限で実行
このコマンド例では、node0に6GB、node1に2GBのメモリを割り当てています。node0の中心にDPDKアプリケーションを動かす場合、node1側のメモリに無駄にhugepageの確保しなくなるため、他のアプリケーションをnode1側のリソースを使い設計することが可能になります。
NIC及びhugepageの設定が終わりましたので、DPDKアプリケーションに対して利用するCPUを指定して起動します。先ほどのマシン構成ではnode0側の論理プロセッサは0,2,4,6なので、このプロセッサを積極的に利用していきます。以前紹介したl2fwdのコマンド例 ( DPDKのパケット処理 ~DPDK入門 第2回~ で紹介)では以下のイメージでした。
EAL: Detected 32 lcore(s)
EAL: Probing VFIO support...
EAL: PCI device 0000:04:00.0 on NUMA socket 0
EAL: probe driver: 8086:1521 net_e1000_igb
EAL: PCI device 0000:04:00.1 on NUMA socket 0
EAL: probe driver: 8086:1521 net_e1000_igb
・・・・
MAC updating enabled
Lcore 0: RX port 0
Lcore 1: RX port 1
Initializing port 0... done:
Port 0, MAC address: xx:xx:xx:xx:xx:xx
Initializing port 1... done:
Port 1, MAC address: xx:xx:xx:xx:xx:xx
Checking link status...............................................done
Port0 Link Up. Speed 1000 Mbps - full-duplex
Port1 Link Up. Speed 1000 Mbps - full-duplex
L2FWD: entering main loop on lcore 0
L2FWD: -- lcoreid=0 portid=0
L2FWD: entering main loop on lcore 1
L2FWD: -- lcoreid=1 portid=1
Port statistics ====================================
Statistics for port 0 ------------------------------
Packets sent: 0
Packets received: 0
Packets dropped: 0
Statistics for port 1 ------------------------------
Packets sent: 0
Packets received: 0
Packets dropped: 0
Aggregate statistics ===============================
Total packets sent: 0
Total packets received: 0
Total packets dropped: 0
====================================================
-c オプションで与えるパラメータが論理プロセッサ番号になりますが、この例では0と1を指定しています。これでは論理プロセッサ1番はCPUはメモリが遠い位置にあるため、最適な設定ではありません。論理プロセッサを0と2に指定し直します。
EAL: Detected 32 lcore(s)
EAL: Probing VFIO support...
EAL: PCI device 0000:04:00.0 on NUMA socket 0
EAL: probe driver: 8086:1521 net_e1000_igb
EAL: PCI device 0000:04:00.1 on NUMA socket 0
EAL: probe driver: 8086:1521 net_e1000_igb
・・・・
MAC updating enabled
Lcore 0: RX port 0
Lcore 1: RX port 1
Initializing port 0... done:
Port 0, MAC address: xx:xx:xx:xx:xx:xx
Initializing port 1... done:
Port 1, MAC address: xx:xx:xx:xx:xx:xx
Checking link status...............................................done
Port0 Link Up. Speed 1000 Mbps - full-duplex
Port1 Link Up. Speed 1000 Mbps - full-duplex
L2FWD: entering main loop on lcore 0
L2FWD: -- lcoreid=0 portid=0
L2FWD: entering main loop on lcore 2
L2FWD: -- lcoreid=2 portid=1
Port statistics ====================================
Statistics for port 0 ------------------------------
Packets sent: 0
Packets received: 0
Packets dropped: 0
Statistics for port 1 ------------------------------
Packets sent: 0
Packets received: 0
Packets dropped: 0
Aggregate statistics ===============================
Total packets sent: 0
Total packets received: 0
Total packets dropped: 0
====================================================
lcoreidの出力結果より論理プロセッサ番号が0,1の割り当てから、0,2に変化したことが分かります。このように起動することで、CPU、メモリ、NICが全て自ノード内にあるため、より良いパフォーマンスが期待できます。
おわりに
前回に引き続きメモリ管理の機能を説明させて頂きました。NUMAを意識してチューニングをすることでより効率の良い運用ができるようになりますので参考にして頂ければと思います。次回ですが、NICの設定に関して解説をしていきたいと考えています。よろしくお願いします。


{kind=link}

長年NTTの通信基盤となるネットワーク関連の仕事に従事。 最近では仮想化技術が主流化しており、最新動向を追従する日々。 DPDKに関してはニッチな領域のためか仲間が増えないと感じており、ブログを通した仲間づくりを開始。 横浜生まれだが、巨人ファン。たまに東京ドームに観戦に行くことが楽しみ。
![]()