DPDKの設計モデル ~DPDK入門 第11回~
DPDKの設計モデルを紹介




DPDK入門
- 2020年05月26日公開
はじめに
こんにちは、NTTテクノクロス株式会社の寺尾です。今回はDPDKの設計モデルに関して、今まで紹介したサンプルプログラムを使って解説していきます。

2つの設計モデル
DPDKの公式ページでは設計モデル(※1)として「run to completion」モデルと「pipeline」モデルが紹介されています。どちらのモデルも良い点がありますので、アプリケーションの内容に応じて設計モデルを選択する必要があります。
「run to completion」モデルは、一連のパケット処理を1つの論理コア(スレッド)で完結するモデルです。このモデルで実装したサンプルアプリケーションのイメージを以下に記載します。DPDKでは常にポーリングでパケット受信を行いことは以前の記事で紹介しました。今回の例では、パケットを受信したらパケットデータを書き換えてパケットを別のNICに転送します。この一連の処理を一つの論理コアで完結する設計モデルを「run to completion」モデルと呼んでいます。
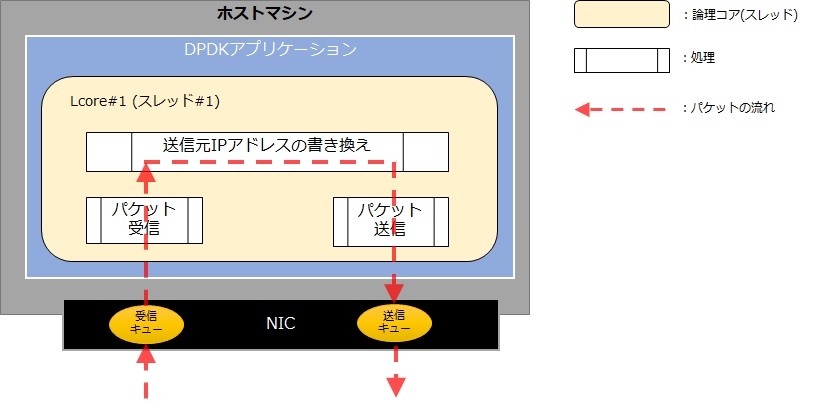
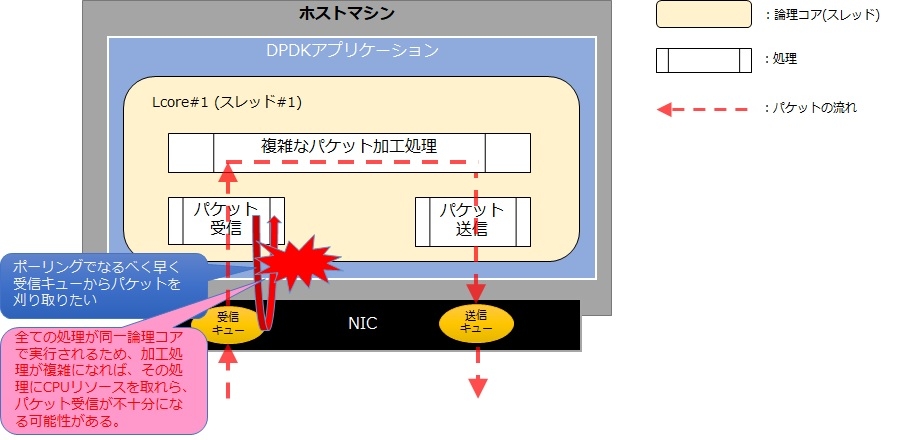
「run to completion」モデルでは、例えばIPアドレスアドレスの書き換えなど簡単な処理を行う場合には有効ですが懸念点もあります。例えばもう少し複雑なパケット加工処理をしようとした場合、CPUリソースがパケット受信に十分に割当たらなくなるかもしれません。NICの受信キューの容量は大きいものではないため、パケット受信処理が十分ではない場合パケットロスの原因になります。
「pipeline」モデルは、パケット受信からの一連の処理を複数の論理コア(スレッド)に分割して実施するモデルです。複雑なパケット加工処理をパケット受信に影響ないように実現したい場合は有効な設計モデルになります。このモデルで実装したサンプルアプリケーションのイメージを以下に記載します。
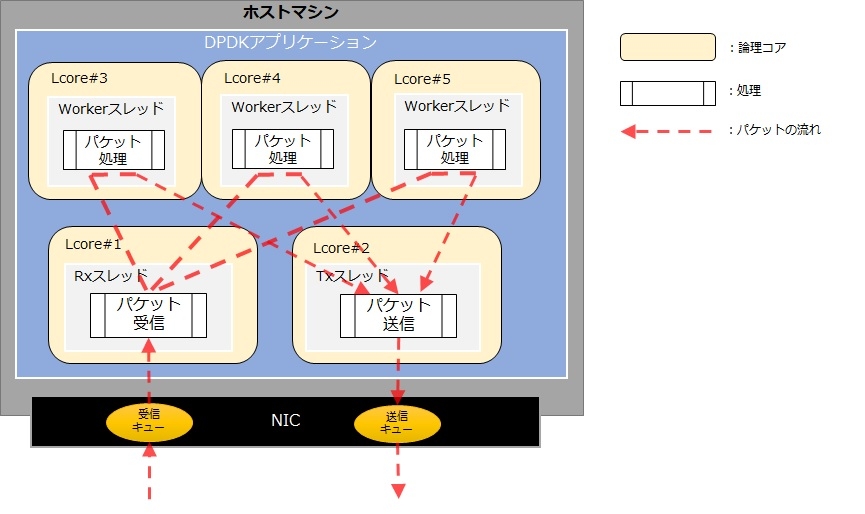
このモデルでは一連の処理を複数の単位に分割し、各々の処理専用のスレッドを割り当てています。ここではパケット受信を行うスレッドを「Rxスレッド」、パケット処理を行うスレッドを「Workerスレッド」、パケット送信を行うスレッドを「Txスレッド」と名付けました。こうすることで「run to completion」モデルでの懸念であったパケット受信処理は他の処理に直接依存することが無くなりました。但し「Workerスレッド」が非常に重い処理になった場合は「Workerスレッド」でボトルネックとなる可能性があります。「pipleline」モデルでは、各スレッドの個数を処理量に応じて柔軟に割り当てることでシステム全体のパフォーマンスを上げていく必要があります。
「run to completion」モデルのメリットは考え方がシンプルなことにあります。複雑な処理を行わないのであれば、まずこのモデルを検討することをお勧めします。但し要件によっては一種類のスレッドではボトルネックとなってしまう懸念がある場合は、難易度は上がりますが「pipeline」モデルを検討することも必要になります。適用シーンに応じて使い分けることが重要になります。
※1 DPDK Overview
http://doc.dpdk.org/guides-20.02/prog_guide/overview.html
pipelineモデルの実装
これまでの記事で作成したDPDKアプリケーションは1つのスレッドですべての処理が完結している「run to completion」モデルになります。今回は以前作成したパケット転送処理を「pipeline」モデルに変える方法を紹介します。ベースとなるソースコードはDPDKのログ出力 ~DPDK入門第10回~を参照してください。いくつかポイントがありますので、段階を踏んで解説します。
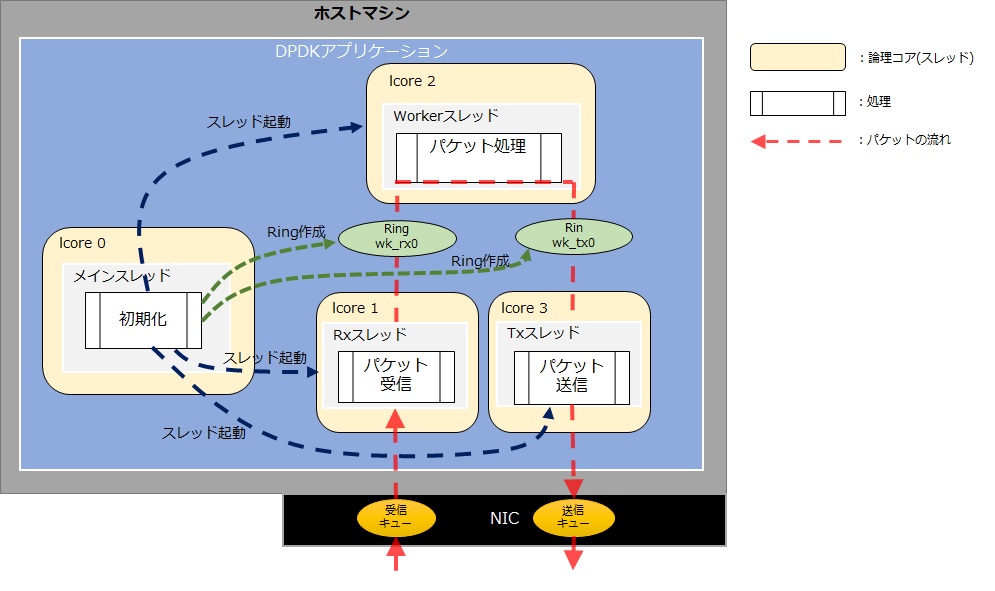
まずは、複数のスレッドを作成します。これまで通りCPU1コアあたり1スレッドとして今回は「メインスレッド」「Rxスレッド」「Workerスレッド」「Txスレッド」の4つに分割します。それぞれのスレッドの分担は以下としました。今まではパケット転送処理をCPU1コアで行っていましたが、CPU3コアで動作可能とすることが目的です。
- メインスレッド:初期化、スレッド起動/停止
- Rxスレッド:パケット受信
- Workerスレッド:パケット転送
- Rxスレッド:パケット送信
今回はメインスレッドからRxスレッド、Workerスレッド、Txスレッドを作成します。今回作成するイメージを以下に示します。スレッド間でパケットを引き渡すためには、アプリケーション内でパケットバッファを共有する仕組みが必要になります。DPDKでは、Ringライブラリ(※2) が用意されていますので、このライブラリを使ってpipelineモデルを実現していきます。
※2 Ring Library
https://doc.dpdk.org/guides/prog_guide/ring_lib.html
pipelineモデルの初期化処理
pipelineモデルでは専用の処理を実施するスレッドを複数作成するとともに、スレッド間でパケットを引き渡すためのRingを作成する必要があります。また、各スレッドを安全に終了させる仕組みに関しても検討する必要があります。今回はアプリケーションの停止はシグナルを使うこととして、終了処理の例として解説します。シグナルはカーネルが提供するソフトウェア割込みの機能になります。ここでは、プログラムの停止時にCtrl-Cキー等の契機でトリガをもらえるようにします。シグナルに関して詳しく知りたい人は http://linuxc.info/signal/signal1.html を参照下さい。以下が初期化処理のシーケンスです。
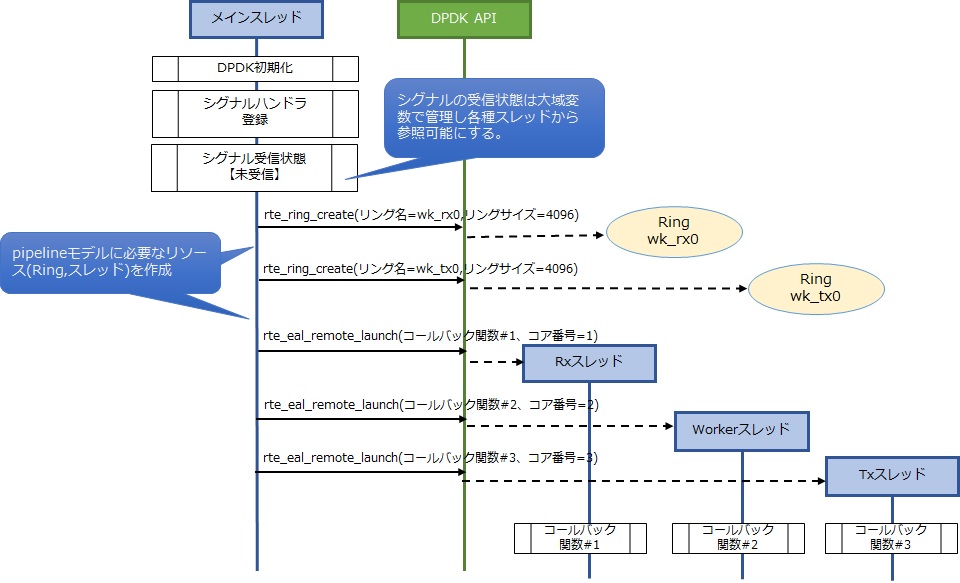
今回はスレッドを4つ使いますので、DPDK初期処理時にCPUを4つ以上使うように設定する必要があります。このあたりは、リソース設定(CPU) ~DPDK入門 第3回~で解説していますので忘れた方は参照下さい。
今回新しく登場するインタフェースは、「Ring作成」「スレッド作成」になります。Ringはスレッド間でパケットを受け渡す際に利用しますが、今回はrxスレッドがNICからのパケットをworkerスレッドに渡すRingとworkerスレッドがNICへ送信するためのパケットをtxスレッドに渡すRingを作成します。
▼ Ring作成
struct rte_ring* rx_ring, tx_ring;
rx_ring = rte_ring_create("wk_rx0", 4096, rte_socket_id(),RING_F_SP_ENQ | RING_F_SC_DEQ); tx_ring = rte_ring_create("wk_tx0", 4096, rte_socket_id(),RING_F_SP_ENQ | RING_F_SC_DEQ); if (rx_ring == NULL || tx_ring == NULL) rte_exit(EXIT_FAILURE, "Cannot create rx/tx ring\n");
スレッドはrte_eal_remote_launch()を使い作成します。ここでスレッド起動後にコールバックする関数を指定します。またコールバック関数のパラメータには、各スレッドが使用するDPDKポート番号を渡すようにしました。
int ret;
ret = rte_eal_remote_launch(launch_one_lcore, (void *)&port_id, slave_lcore); if (ret < 0) rte_exit(EXIT_FAILURE, "Launch slave thread is faild.\n");
詳細はDPDK公式ページのドキュメントを参照下さい。簡単な説明は以下に記載します。
| 概要 | 新しいリングをメモリに作成する | ||
| 引数 | 型 | パラメータ | 補足 |
| const char * | リング名 | 作成するリングの名称 | |
| unsigned | リングサイズ | 作成するリングのサイズ。2の乗数で設定する必要がある。 | |
| int | ソケットID | メモリ確保元のソケットを指定 | |
| unsigned | フラグ | 作成するリング属性を指定する。 ・「RING_F_SP_ENQ」 enqueue処理で「single-producer」 ・「RING_F_SC_DEQ」 dequeue処理で「sigle-consumer」 指定しない場合は、「multi-producer」「multi-consumer」となる。 |
|
| 返り値 | 型 | 補足 | |
| struct rte_ring* | 成功した場合、新たに生成したリングのポインタを返却する。 失敗した場合はNULLを返却する。 |
||
| 概要 | 新しいlcoreで動作するスレッドを生成する。Masterコアで実行する必要がある。 rte_eal_wait_lcore()のために「終了状態」をローカル変数に設定する。 |
||
| 引数 | 型 | パラメータ | 補足 |
| lcore_function_t * | 関数ポインタ | - | |
| void * | 関数パラメータ | - | |
| unsigned | Slave論理コアID | 関数を実行する論理コアIDを指定する | |
| 返り値 | 型 | 補足 | |
| int | 成功した場合、0を返却 | ||
pipelineモデルの終了処理
pipelineモデルで各スレッドを安全に終了させる仕組みとして、シグナルハンドラを使った例を紹介します。
初期化処理ですでにシグナルハンドラの登録を行っており、アプリケーションはシグナルを受けれる状態になっています。それまでは各スレッドは周期処理を行っていますが、周期処理中では常にシグナルの受信状態を監視するようにしておきます。この状態監視の処理は定期処理中常に実行するので、なるべく軽量にしておきます。状態監視のやり方はいろいろありますが、今回は大域変数を使ったシンプルな方法を紹介します。方法としては、メインスレッドではシグナルを受けたら大域変数にシグナルを受信した状態値を書き込み、各スレッドは大域変数の値をチェックしてその状態値が確認できたら定期処理を抜けるようにします。以下が終了処理のシーケンスです。
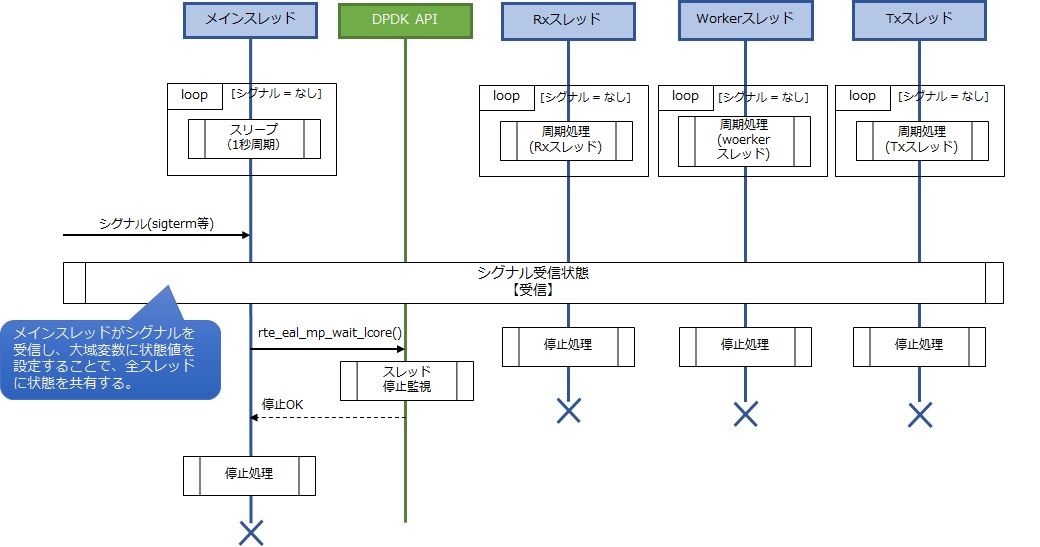
ここで利用したインタフェースは、「スレッド停止監視」になります。rte_eal_remote_launch()で生成したスレッドの停止状態を待合せることができます。実装方法はDPDKを使えば以下の一行のみです。
▼ スレッド停止監視
rte_eal_mp_wait_lcore();
| 概要 | スレッドのジョブを終了するまで待ち合わせる。Masterコアで実行する必要がある。 | ||
| 引数 | 型 | パラメータ | 補足 |
| なし | |||
| 返り値 | 型 | 補足 | |
| なし | |||
おわりに
今回はDPDKでよく採用される設計モデルの紹介とpipelineモデルの初期化処理、終了処理の考え方を紹介しました。次回は各スレッドの周期処理を解説していきます。よろしくお願いします。


![]()