RDSフェイルオーバーによるダウンタイムの実測(PostgreSQL編)
オンプレミスなシステムをAWSに移行する際など、DBサーバにはRDSを使うかという点がよく議論になります。RDSは非常に便利ですが、導入の検討段階で「定期メンテナンスやフェイルオーバーでダウンタイムが発生するからNGになった」という話をよく聞きます。 ダウンタイムはどの程度か、という話はAWSの公式サイトにも記述があり、「通常」60~120秒とされています。可用性担保を使命とするエンジニアとしては、この「通常」という言葉がとても気になりますよね。 ということで、今回はRDSのフェイルオーバーによるダウンタイムを実測してみました。




ソフト道場の「SIerが目利きする。今日から使えるAWSレシピ」
- 2016年09月14日公開
はじめに
AWSブログではメンバーがAWSのいろいろなテーマでお話していきます。今回は第二弾として、RDSをテーマにお話します。
さて、オンプレミスなシステムをAWSに移行する際など、DBサーバにはRDSを使うかという点がよく議論になります。RDSは非常に便利ですが、導入の検討段階で「定期メンテナンスやフェイルオーバーでダウンタイムが発生するからNGになった」という話をよく聞きます。
ダウンタイムはどの程度か、という話はAWSの公式サイトにも記述があり、「通常」60~120秒とされています。可用性担保を使命とするエンジニアとしては、この「通常」という言葉がとても気になりますよね。 ということで、今回はRDSのフェイルオーバーによるダウンタイムを実測してみました。
検証条件
フェイルオーバーの速度を決める条件が多岐にわたることは想像に難くないので、検証を容易にするためと、ある程度再現性をもたせるために、変化させる検証条件を絞りこみます。 AWSのベストプラクティスによると、
- データベース
- インスタンスクラス
- ストレージタイプ
によってフェイルオーバー時間が変わる、と記載されています。 素直に考えれば上記条件とダウンタイムがどの程度関連を持つかを検証したいところですが、データベースを変更すると検証が大変なため、今回はPostgreSQLに限って検証を行うこととし、インスタンスクラスとストレージタイプについては可変条件としました。
可変条件
RDSのフェイルオーバー時間への影響が大きいであろうパラメータを可変条件としました。
- インスタンスタイプ: t2.micro / r3.8xlarge
- EBSストレージタイプ: Provisioned IOPS(io1) / General Purpose SSD(gp2)
- Provisioned IOPSの場合はEBSボリュームサイズに対し設定可能な最大のIOPSを設定する
- EBSボリュームサイズ: 100GB / 1TB
- 測定開始時のDBデータサイズはpgbenchのScaleFactorでそれぞれディスク使用率が10%程度となる1000,10000とする。
EBSボリュームサイズを可変条件としたのは、Provisioned IOPSに設定可能な最大のIOPSがボリュームサイズによって異なるため、ダウンタイム自体もボリュームサイズに依存するのでは、と考えたためです。
固定条件
上述の通り、その他は基本的に固定条件としています。
- 各測定は5回ずつ行い、結果は5回の測定の平均とする。
- DBエンジンはpostgreSQL 9.4.7とする。
- パラメータセットはデフォルトとする。
- リージョンはTokyoとする。
- バックグラウンド接続として10トランザクションを流し続ける。
実施準備
実施環境構成
今回の実施環境は以下のとおりです。
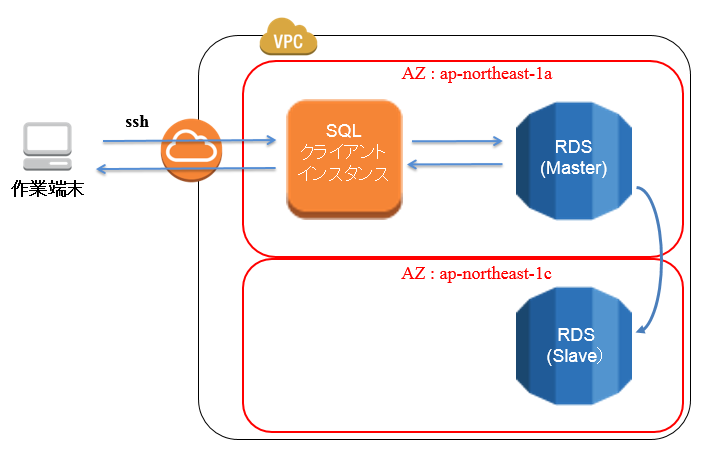
上記の構成で測定を開始し、フェイルオーバーによってSQLクライアントインスタンスからap-northeast-1a側のRDSインスタンスへの接続が途絶えてから、ap-northeast-1c側のインスタンスへ接続が開始されるまでの時間を測定します。
データ投入、クライアント設定
今回はRDSへのデータ投入にpgbenchを利用しました。 pgbenchでデータを作成、RDSに投入していきます。
postgreSQLクライアント、pgbench(contlibに含まれる)をインストール
# yum install postgresql postgresql-devel postgresql-contrib
ベンチマーク用データベースの作成
# pgbench -s 1000 -i 【テスト用DB名】 -U 【PostgreSQLユーザ名】 -h 【RDSエンドポイント】 (EBS:100GBの場合)
# pgbench -s 10000 -i 【テスト用DB名】 -U 【PostgreSQLユーザ名】 -h 【RDSエンドポイント】(EBS:1000GBの場合)
念のため、クライアント側のTCPタイムアウト設定変更
# /sbin/sysctl -w net.ipv4.tcp_keepalive_time=3 net.ipv4.tcp_keepalive_intvl=3 net.ipv4.tcp_keepalive_probes=2
続いて、実行トランザクションを定義します。フェイルオーバーの実行時間はAWSのマネジメントコンソールから確認できますが、インスタンスの再起動等を含めた時間になっています。実際にDBへの接続が不可能である時間を「ダウンタイム」とすべきですので、RDSに対してSQLを発行し続けるためにテスト用のSQLを用意します。 今回はストアドプロシージャを用意し、psqlコマンドから呼び出すようにしてみました。 以下、定義したストアドプロシージャです。
# testTransaction.sql
CREATE OR REPLACE FUNCTION myfunc(t_id int, b_id int, a_id int, delta_ int) RETURNS timestamp
AS $$
BEGIN
PERFORM abalance FROM pgbench_accounts WHERE aid = a_id;
UPDATE pgbench_tellers SET tbalance = tbalance + delta_ WHERE tid = t_id;
INSERT INTO pgbench_history (tid, bid, aid, delta, mtime) VALUES (t_id, b_id, a_id, delta_, CURRENT_TIMESTAMP);
RETURN CURRENT_TIMESTAMP;
END;
$$ LANGUAGE plpgsql;
このストアドプロシージャは、pg_benchで作成したテーブルに対して、取得、更新、登録を行うトランザクションを実行します。 ストアドプロシージャの戻り値として現在時刻を指定しておくことで、各接続の終了時刻を出力しています。 マネジメントコンソール上のログ出力ではなく、このストアドプロシージャの戻り値の時刻差を用いることで、実際のダウンタイムを測定していきます。
これで準備は完了です。
発行トランザクション
定義したストアドプロシージャに対して、同時接続数10でSQLを発行し続けます。
同時実行コマンド(並列数:10)
# seq 1000 | xargs -t -P10 -n1 ./script.sh
# script.sh
for x in {1..10}
do
timeout 2 psql -t test -U postgres -h 【RDSエンドポイント】 -c "select testTransaction($x,$x,$x,$x)"
done
ポイントとしては、timeout 2 を用いてpsqlコマンドのタイムアウトを行っている点です。これで、RDS側から2秒反応がなかった場合にすぐに次の実行に移るようにし、接続の回復を2秒程度の誤差で検知しています。 ストアドプロシージャに変数をもたせたのは、発行されるSQLにある程度バリエーションを作るためです。
フェイルオーバーの実施はRDSのマネジメントコンソールから手動で実施しました。
測定結果
以下の結果になりました。
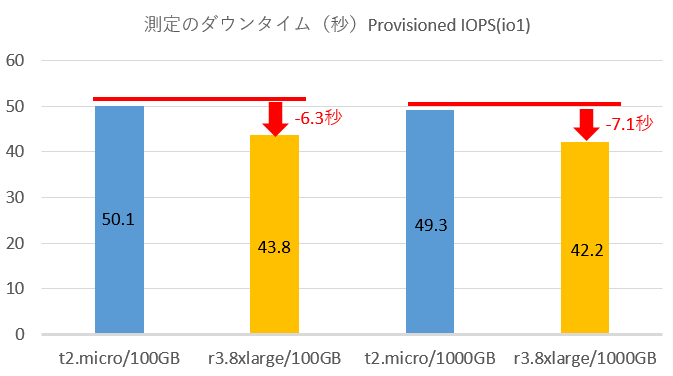
Provisioned IOPS利用時の結果
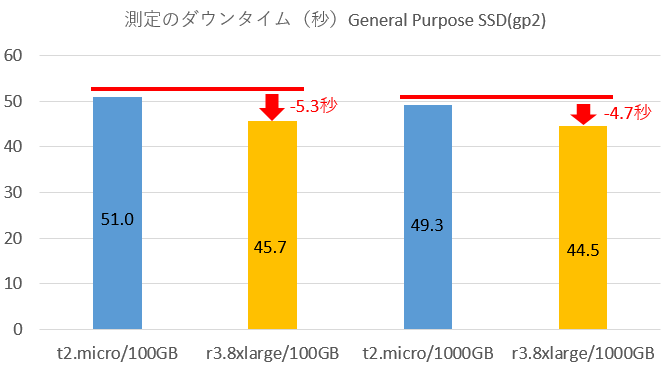
General Purpose SSD利用時の結果
考察
RDSのダウンタイムは公式にある値よりも少し小さめの、40秒~60秒という結果になりました。 これは、月に1回60秒のフェイルオーバーが発生しても、99.9998%の可用性を担保できる、という計算になります。
インスタンスタイプの変更によって、5~7秒程度の差が出ていますが、スペック最低と最大を比べてこの程度なので、インスタンスタイプによる影響は無視して良いレベルかと思います。
また、ボリュームタイプ、ボリュームサイズによる影響については有意といえるほどの差は出ませんでした。 ボリュームタイプ(General Purpose SSDとProvisioned IOPS)で差が出なかったのは意外ですが、今回の検証ではIOボトルネックになるほどの負荷をかけていなかったことが原因かもしれません。今回は送信SQLのTPSを一定にしたため、単位時間あたりのWALの転送量等の影響を受けていませんが、大きなボリュームが必要とされるほど、大抵の場合はWALの転送量も増加するでしょうから、転送量に紐付いてダウンタイムが増加する可能性はあります。このあたりも今後、測定してみたいですね。
おわりに
今回検証した内容では、インスタンスタイプやProvisioned IOPS等でかなり高価なものもありました。r3.8xlarge+1000GBのProvisioned IOPSボリュームでは、1時間あたり約1500円かかります。個人で気楽に検証するには二の足を踏んでしまいますが、会社の予算でできるというのは嬉しいものです!
最後に、「もっとダウンタイム短くできるよ」「他のDBエンジンも試してよ」と言ったご意見ご要望、お待ちしています!



AWSチーム
![]()