KFServingで機械学習基盤を作りませんか?
機械学習を用いたシステム開発ではモデルファイルの開発に最大限リソースを注力したいものです。しかし、機械学習プラットフォームを動かすための環境構築はそう簡単ではないですよね。そういった問題に対して本記事では、抽象度の高いyamlファイルを作成するだけで機械学習基盤を迅速に生成できるKFServingについてご紹介します。




テクノロジーコラム
- 2021年01月13日公開
はじめに
KFServingとは
KFServingの概要
- ・TensorFlow
- ・PyTorch
- ・scikit-learn
- ・XGBoost
- ・ONNX
- ・TensorRT
- ・TritonInferenceServer
構成要素
KFServingは以下のようなアーキテクチャで成り立っています。
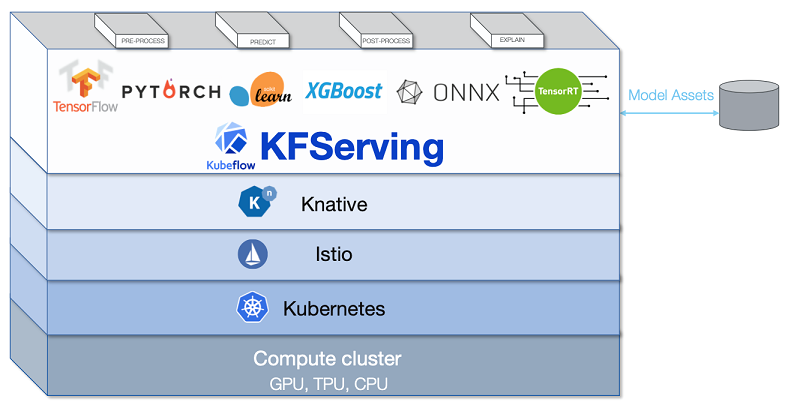
KFServingで出来ること
1. InferenceService
KFSerivngの魅力の一つに、ほんの数行のInferenceServiceのyamlファイルを書くだけで複数のKubernetesリソース、カスタムリソースを作成して、機械学習基盤をすぐに構成できるというものがあります。具体例として、このようなInferenceServiceをデプロイした場合の挙動について説明します。
https://github.com/kubeflow/kfserving/blob/release-0.5/docs/samples/autoscaling/autoscale.yaml
apiVersion:"serving.kubeflow.org/v1alpha2"
kind: "InferenceService"
metadata:
name: "flowers-sample"
spec:
default:
predictor:
tensorflow:
storageUri: "gs://kfserving-samples/models/tensorflow/flowers"デプロイしてから数十秒後には、InferenceServiceはReadyになります。
あとは以下に記載してあるURL http://flowers-sample.kf-sample.example.com 宛に、クライアントからリクエストを送信すると機械学習を行うことができます。
$ kubectl get inferenceservice
NAME URL READY AGE
flowers-sample http://flowers-sample.kf-sample.example.com True 69s
InferenceServiceをデプロイするだけで機械学習を行えたのは、この図のように多くのKubernetesリソース、カスタムリソースが自動で作成されるためです。
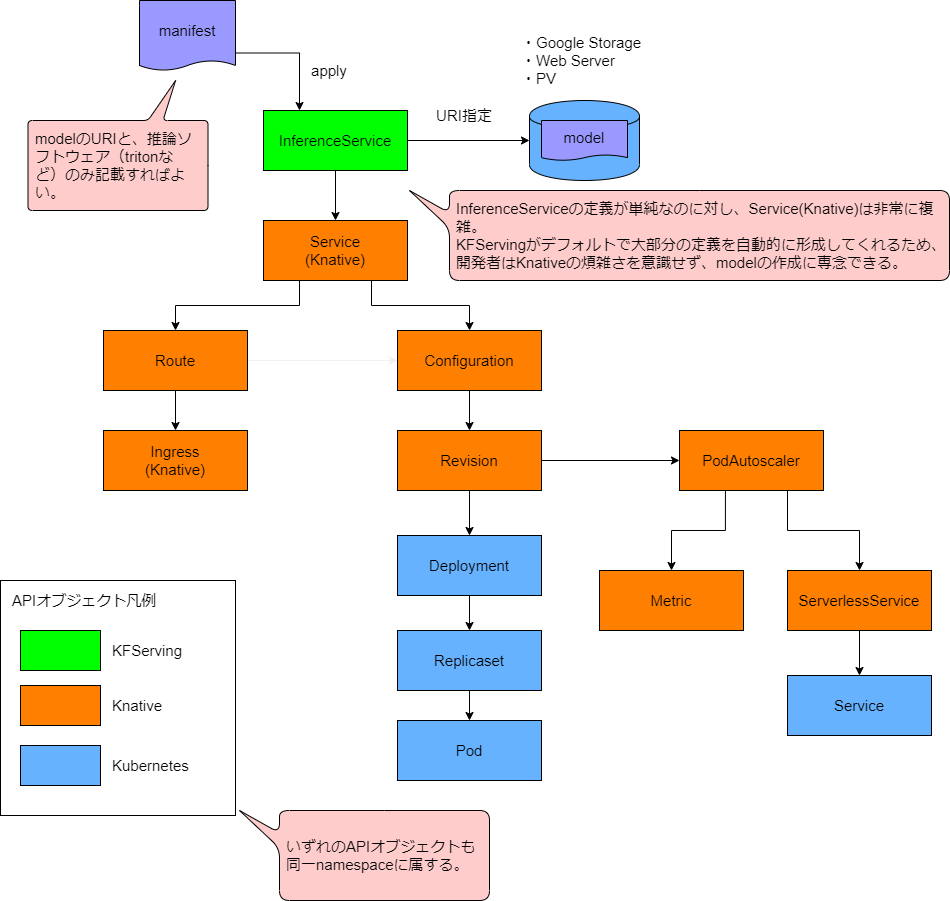
InferenceServiceが作られると、Knativeのカスタムリソースであるserving.knative.devが作られます。
$ kubectl get ksvc
NAME URL LATESTCREATED LATESTREADY READY REASON
flowers-sample-predictor-default http://flowers-sample-predictor-default.kf-sample.example.com flowers-sample-predictor-default-xmgbm flowers-sample-predictor-default-xmgbm True ※serving.knative.devはServiceと表記されることもありますが、KubernetesのServiceとは全く別物です。本ブログでは、以下略称であるksvcと表記します。
$ kubectl api-resources | grep ksvc
services kservice,ksvc serving.knative.dev true Serviceこのksvcからは、以下のものが作られます。
NAMESPACE NAME READY STATUS RESTARTS AGE
default pod/flowers-sample-predictor-default-zcc8q-deployment-dd4df876hstvc 2/2 Running 0 37s
NAMESPACE NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S)
knative-serving service/controller ClusterIP 10.233.48.214 9090/TCP,8008/TCP 17d
knative-serving service/istio-webhook ClusterIP 10.233.17.253 9090/TCP,8008/TCP,443/TCP 17d
knative-serving service/knative-local-gateway ClusterIP 10.233.24.46 80/TCP 17d
knative-serving service/webhook ClusterIP 10.233.54.217 9090/TCP,8008/TCP,443/TCP 17d
NAMESPACE NAME READY UP-TO-DATE AVAILABLE AGE
kube-system deployment.apps/dns-autoscaler 1/1 1 1 18d
local-path-storage deployment.apps/local-path-provisioner 1/1 1 1 17d
NAMESPACE NAME URL LATESTCREATED LATESTREADY READY REASON
default service.serving.knative.dev/flowers-sample-predictor-default http://flowers-sample-predictor-default.default.example.com flowers-sample-predictor-default-zcc8q flowers-sample-predictor-default-zcc8q True
NAMESPACE NAME LATESTCREATED LATESTREADY READY REASON
default configuration.serving.knative.dev/flowers-sample-predictor-default flowers-sample-predictor-default-zcc8q flowers-sample-predictor-default-zcc8q True
NAMESPACE NAME CONFIG NAME K8S SERVICE NAME GENERATION READY REASON
default revision.serving.knative.dev/flowers-sample-predictor-default-zcc8q flowers-sample-predictor-default flowers-sample-predictor-default-zcc8q 1 True
NAMESPACE NAME URL READY REASON
default route.serving.knative.dev/flowers-sample-predictor-default http://flowers-sample-predictor-default.default.example.com True この中でも重要な項目は以下の通りです。
- ・Route
- ・http://flowers-sample.kf-sample.example.com を指定してノードに届いた通信を、ksvcから作られるPod宛てにルーティングする役割があります。
・Deployment, ReplicaSet, Pod
- ・これが一番重要です。InferenceServiceで指定したモデルをマウントして機械学習を行うワークロードです。
- ・大量に要求が来た場合に、Podの数を増やすなどの設定を行う事ができます。
2. Autoscaling
要求の量に応じてPodの個数を自動で増減することが、KPA(Knative Pod Autoscaler)で設定されています。
参考:https://knative.dev/v0.18-docs/serving/autoscaling/
設定を行うのは基本的に2か所で、グローバル(クラスタ全体)な設定はConfigMapで設定し、InferenceServiceごとの設定はInferenceServiceにannotationを付ける方法で行います。どちらの設定方法も、ほぼ同じ項目から設定します。
デフォルトの設定(グローバル)
apiVersion: v1
kind: ConfigMap
metadata:
name: config-autoscaler
namespace: knative-serving
data:
container-concurrency-target-default: "100"
container-concurrency-target-percentage: "0.7"
enable-scale-to-zero: "true"
max-scale-up-rate: "1000"
max-scale-down-rate: "2"
panic-window-percentage: "10"
panic-threshold-percentage: "200"
scale-to-zero-grace-period: "30s"
scale-to-zero-pod-retention-period: "0s"
stable-window: "60s"
target-burst-capacity: "200"
requests-per-second-target-default: "200"デフォルト設定での挙動説明
以上の設定値でのKFServingのフローをご紹介します。
クライアントからリクエストを送信されていない時はPod数が1で待ち受ける(minreplicasについては設定方法が特殊なため後述)
↓
リクエストの多重度を元にオートスケールする(autoscaling.knative.dev/metricという項目で変更可能)
↓
オートスケールに使用する目標値はcontainer-concurrency-target-defaultで決まる。この場合は100多重を意味する
↓
実際にオートスケールする閾値は、目標値とcontainer-concurrency-target-percentageで決まる。この場合は100 x 0.7で70多重になった時に、Pod数を増やす動作を行う
minreplicasについて
ConfigMapやアノテーションの設定のみだと、Podの最小のレプリカ数は1になっています。リクエストが無い場合のレプリカ数を変更する場合は、predictorの下で設定します。
apiVersion: "serving.kubeflow.org/v1alpha2"
kind: "InferenceService"
metadata:
name: "flowers-sample"
spec:
default:
predictor:
minReplicas: 0
tensorflow:
storageUri: "gs://kfserving-samples/models/tensorflow/flowers"ただし、レプリカ数を0にして待ち受けると通常の処理とはことなる挙動になります。Podが起動するまでに送信されたリクエストは、名前空間knative-servingのActivatorというカスタムリソースにキューイングされます。レプリカ数が1以上だった場合と処理方法が違うので注意が必要です。
KFServing内の通信フローについて
KFServingは送信されたリクエストを以下のようなフローで、モデルファイルを持つ機械学習用のコンテナへ到達させます。
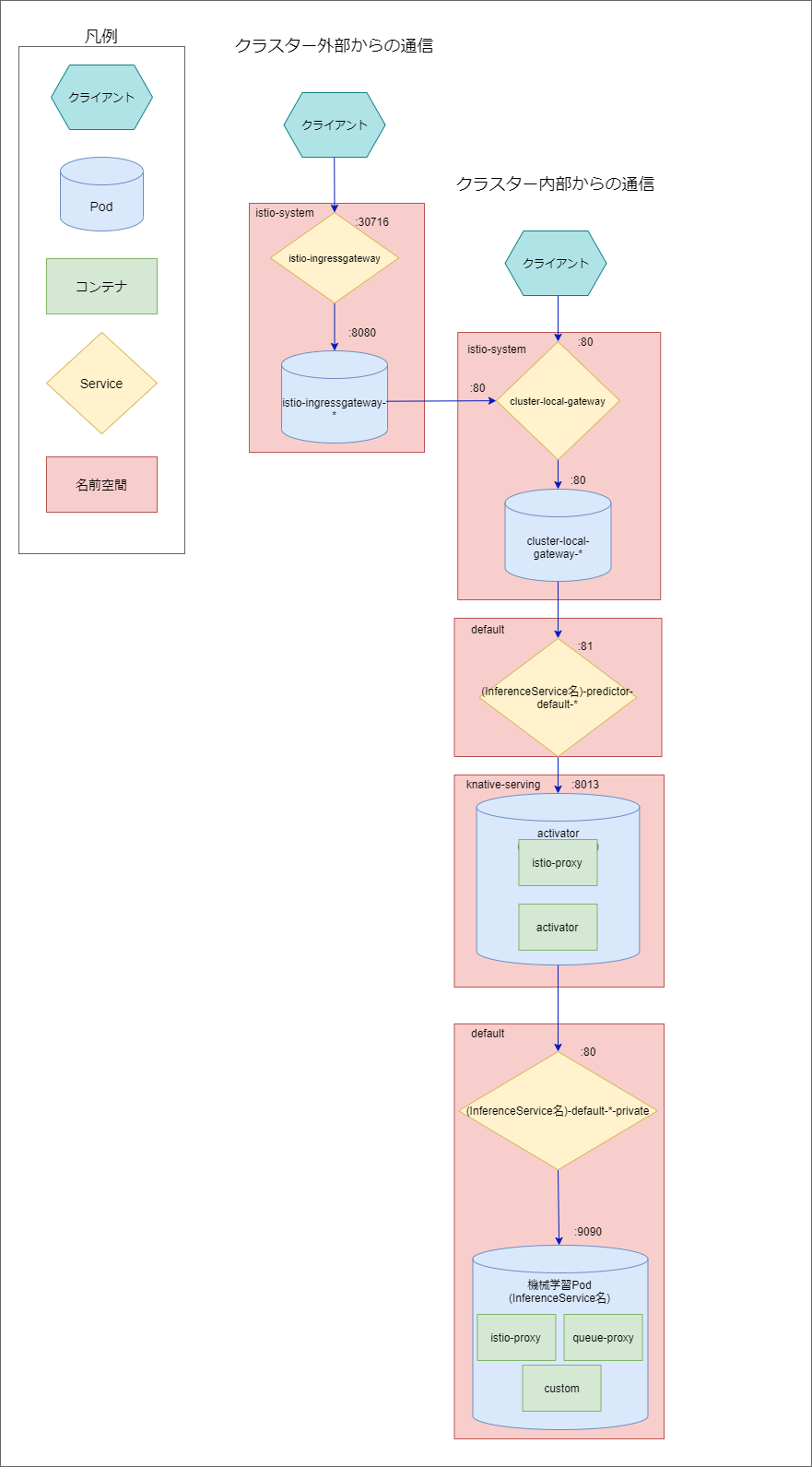
今回はInferenceServiceをdefault名前空間にデプロイした場合を想定します。モデルファイルを持つ機械学習用Podへアクセスするには、リクエストをistio-system名前空間内のServiceへ送信する必要があります。クライアントがクラスター内部にある場合はService/cluster-local-gatewayのIPアドレス宛にリクエストを送信し、Pod/cluster-local-gateway-*に送信されます。また、クライアントがクラスター外部ならばService/istio-ingressgatewayのIPアドレス宛にリクエストを送信し、Pod/istio-ingressgateway-*からService/cluster-local-gatewayへ送信され上記と同じクラスター内の通信に移行します。その後はdefault名前空間のService/(InferenceService名)-predictor-default-*からknative-serving名前空間のPod/activator-serviceへ送信され、default名前空間のService/(InferenceService名)-predictor-default-*-privateから、モデルファイルを持つPod/(InferenceService名)へ送信されます。
KFServingの導入
前提条件
本記事ではKFServing v0.5を一例に導入手順を説明します。KFServing v0.5を導入するには以下の条件が必要になります。
- ・Kubernetes : v1.15以上
- ・Istio : v1.3.1以上
- ・Knative : v0.143以上
- ・CertManager : v0.12.0以上
導入環境
本記事では以下の環境に導入しました。
- ・OS : Ubuntu v18.04
- ・Kubernetes : v1.19.5
導入手順
大まかな手順としてはKubernetes環境にIstio , Knative , CertManagerをインストールした後、KFServingをインストールする流れとなっています。
1. リポジトリをクローンする
KFServingの公式リポジトリをクローンします
root@svmst01:~/root$ git clone https://github.com/kubeflow/kfserving.git2. Kubernetes環境にIstio , Knativeのインストール
Kubernetes環境に必要なアーキテクチャであるIstio , Knativeをインストールします。導入について、クローンしたファイルのkfserving/hack/quick_install.shを使用します。前提条件で示したバージョンをquick_install.shへ入力します。
(注意)KFServing v0.5を導入する際は、KFServingはquick_install.shとは別の方法でインストールします。quick_install.shのKFServingインストールの部分をコメントアウトするようにします。
以下qucik_install.shの内容です。
set -e
export ISTIO_VERSION=1.6.2
export KNATIVE_VERSION=v0.18.0
# export KFSERVING_VERSION=v0.5.0
curl -L https://git.io/getLatestIstio | sh -
cd istio-${ISTIO_VERSION}
(中略)
# Install Cert Manager
kubectl apply --validate=false -f https://github.com/jetstack/cert-manager/releases/download/v0.15.1/cert-manager.yaml
kubectl wait --for=condition=available --timeout=600s deployment/cert-manager-webhook -n cert-manager
cd ..
# -----(ここからコメントアウトする)-----
# Install KFServing
# K8S_MINOR=$(kubectl version | perl -ne 'print $1."\n" if /Server Version:.*?Minor:"(\d+)"/')
# if [[ $K8S_MINOR -lt 16 ]]; then
# kubectl apply -f install/${KFSERVING_VERSION}/kfserving.yaml --validate=false
# else
# kubectl apply -f install/${KFSERVING_VERSION}/kfserving.yaml
# fi
# -----(ここまでコメントアウトする)-----
# Clean up
rm -rf istio-${ISTIO_VERSION}3. KFServingのインストール
KFservingをインストールします。クローンしたファイルのkfserving/install/v0.5.0-rc0/kfserving.yamlを以下のコマンドでデプロイします。
root@svmst01:# kubectl apply -f kfserving.yaml
インストール後、バージョンの確認をします。
root@svmst01:# kubectl get po -n kfserving-system -o yaml | grep image.*kfserving-controller
image: gcr.io/kfserving/kfserving-controller:v0.5.0-rc0
image: gcr.io/kfserving/kfserving-controller:v0.5.0-rc0
KFServingの実行例
実行環境
ソフトウェアのバージョンは以下のようになっています。
- ・KFServing : v0.5.0
- ・OS : Ubuntu v18.04
- ・Kubernetes : v1.19.5
- ・Istio : v1.6.2
- ・Knative : v0.18.0
- ・CertManager : v0.15.1
1. InferenceServiceの用意
まずkfserving/docs/samples/autoscalingautoscale.yamlを以下のように変更します。
apiVersion: "serving.kubeflow.org/v1alpha2"
kind: "InferenceService"
metadata:
name: "flowers-sample"
annotations:
autoscaling.knative.dev/metric: "concurrency"
autoscaling.knative.dev/target: "10"
autoscaling.knative.dev/targetUtilizationPercentage: "70"
spec:
default:
predictor:
tensorflow:
storageUri: "gs://kfserving-samples/models/tensorflow/flowers"設定したannotationsの意味としては以下の通りです。
- ・autoscaling.knative.dev/metric: "concurrency"
- ・"concurrency"(リクエスト並列数)を基準にPodの数を増やします。
- ・autoscaling.knative.dev/target: "10"
- ・Podに10並列のリクエストが送信された分だけPodの数を増やします。
- ・autoscaling.knative.dev/targetUtilizationPercentage: "70"
- ・autoscaling.knative.dev/targetの70パーセントのリクエスト並列数でPodの数を増やします。
つまりは「Podに7つの並列数のリクエストが送信されるごとに、新たに1個Podを増やす」というような設定になっています。
2. ファイルのデプロイ
以下のコマンドでデプロイします。
root@svmst01:# kubectl apply -f autoscale.yaml
inferenceservice.serving.kubeflow.org/flowers-sample createdこの段階で「KFServingでできること」の「1. InferenceService」項目で説明した通り、Podだけでなく様々なKubernetesリソース、カスタムリソースがデプロイされます。以下のコマンドで増えたリソース、カスタムリソースを確認しましょう。
root@svmst01:# kubectl get all -A
3. ベンチマークツールの環境変数の設定
ベンチマークツールを使用するため環境変数を設定します。
INGRESS_PORT、INGRESS_HOSTには、リクエスト送信先のistio-ingressgatewayを指定します。以下のコマンドで設定します。
export INGRESS_PORT=$(kubectl -n istio-system get service istio-ingressgateway -o jsonpath='{.spec.ports[?(@.name=="http2")].nodePort}')
export INGRESS_HOST=$(kubectl get po -l istio=ingressgateway -n istio-system -o jsonpath='{.items[0].status.hostIP}')リクエストを送信するホストをHOSTに、送信先のディレクトリにはMODEL_NAMEを設定します。
MODEL_NAME=flowers-sample
HOST=$(kubectl get inferenceservice $MODEL_NAME -o jsonpath='{.status.url}' | cut -d "/" -f 3)ベンチマークで使用するファイルを設定します。
INPUT_PATH=../v1alpha2/tensorflow/input.json4. リクエストの送信、オートスケールの確認
環境変数の設定が完了したら以下のコマンドを実行します。
root@svmst01:# hey -z 30s -c 25 -m POST -host ${HOST} -D $INPUT_PATH http://${INGRESS_HOST}:${INGRESS_PORT}/v1/models/$MODEL_NAME:predictコマンドの説明としては30秒間、並列数25でINPUT_PATHのファイルをリクエストとして送信し続けるというものです。 項目1ではInferenceServiceのオートスケールの条件について「Podに7並列のリクエストが送信されるごとに1つPodを増やす」と設定しました。 したがって 25 / 7 = 3...4 から4個のPod立ち上がることとなります。
コマンドを実行します。
root@svmst01:# hey -z 30s -c 25 -m POST -host ${HOST} -D $INPUT_PATH http://${INGRESS_HOST}:${INGRESS_PORT}/v1/models/$MODEL_NAME:predict
Summary:
Total: 32.8718 secs
Slowest: 17.3003 secs
Fastest: 0.9521 secs
Average: 6.5550 secs
Requests/sec: 3.6810
Total data: 26620 bytes
Size/request: 220 bytes
Response time histogram:
0.952 [1] |■
2.587 [16] |■■■■■■■■■■■■■■■■■■■
4.222 [12] |■■■■■■■■■■■■■■
5.857 [34] |■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■■
7.491 [14] |■■■■■■■■■■■■■■■■
9.126 [14] |■■■■■■■■■■■■■■■■
10.761 [19] |■■■■■■■■■■■■■■■■■■■■■■
12.396 [1] |■
14.031 [5] |■■■■■■
15.665 [3] |■■■■
17.300 [2] |■■
Latency distribution:
10% in 2.4688 secs
25% in 4.6974 secs
50% in 5.4991 secs
75% in 9.3946 secs
90% in 10.4025 secs
95% in 12.8048 secs
99% in 17.3003 secs
Details (average, fastest, slowest):
DNS+dialup: 0.0003 secs, 0.9521 secs, 17.3003 secs
DNS-lookup: 0.0000 secs, 0.0000 secs, 0.0000 secs
req write: 0.0002 secs, 0.0001 secs, 0.0012 secs
resp wait: 6.5541 secs, 0.9518 secs, 17.3000 secs
resp read: 0.0001 secs, 0.0000 secs, 0.0004 secs
Status code distribution:
[200] 121 responses
コマンド停止後、すぐにPod数を確認します。Podが4つ立ち上がっていることが確認できます。
root@svmst01:# kubectl get po
NAME READY STATUS RESTARTS AGE
flowers-sample-predictor-default-bl5s5-deployment-69cd67967kn7q 2/2 Running 0 41s
flowers-sample-predictor-default-bl5s5-deployment-69cd6796hzwss 2/2 Running 0 39s
flowers-sample-predictor-default-bl5s5-deployment-69cd6796npjch 2/2 Running 0 166m
flowers-sample-predictor-default-bl5s5-deployment-69cd6796pdnqj 2/2 Running 0 43s
5. ベンチマーク後のPod数の減少
リクエストの処理が完了すると元のPod数である1つに戻るために、増えた3つのPodステータスが"Terminating"になります。
root@svmst01:# kubectl get po
NAME READY STATUS RESTARTS AGE
flowers-sample-predictor-default-bl5s5-deployment-69cd67967kn7q 1/2 Terminating 0 2m43s
flowers-sample-predictor-default-bl5s5-deployment-69cd6796hzwss 1/2 Terminating 0 2m41s
flowers-sample-predictor-default-bl5s5-deployment-69cd6796npjch 1/2 Terminating 0 168m
flowers-sample-predictor-default-bl5s5-deployment-69cd6796pdnqj 2/2 Running 0 2m45sおわりに



IoTイノベーション事業部 第2ビジネスユニット所属
基盤構築業務に携わっています。
特にDocker , Kubernetesを使用しています。
![]()