Amazon S3 利用状況を分析してストレージのコストを削減する
今回はAWSが提供するオンラインストレージであるAmazon Simple Storage Service (Amazon S3) を対象に、S3バケットの利用傾向を把握することで、データ管理運用の見直しによりストレージ利用コストを最適化するアプローチについて紹介します。




APIを活用したクラウドの「コストの見える化」改革
- 2019年10月01日公開
APIを活用したクラウドの「コスト見える化」改革
第4回 Amazon S3 利用状況を分析してストレージのコストを削減する
- AWS管理者アカウント 1個
- Linuxマシン(VM) 1台
- :60分
- 効果:
今回はAWSが提供するオンラインストレージであるAmazon Simple Storage Service (Amazon S3) を対象に、S3バケットの利用傾向を把握することで、データ管理運用の見直しによりストレージ利用コストを最適化するアプローチについて紹介します。
どうぞよろしくお願いいたします。
必要な知識を得る
S3の料金体系
S3は大きく分けてデータストレージの利用料金と、データの取得、保存などのリクエストデータ転送料金で構成されています。
今回はデータストレージの利用料金について、分析した上で状況を把握、利用料金の削減を検討します。
S3のストレージ種別
S3は標準ストレージ以外に、Glacierと言われるよりデータ保存料金が安価なストレージ種別があります。
安価な代わりにデータを参照する前にデータの復元する必要があること、データの復元に数時間かかること、および復元にかかる時間を短くすればするほど高額な請求になることには注意が必要です。
参考URL:Amazon Web Service社様HP作業に必要な準備をする
過去回で利用したものを流用します
手順を実施していない方は下記リンクから参照の上実施してください。
第1回 Amazon EC2 利用コストを可視化してリザーブドインスタンス(RI)を使い倒す
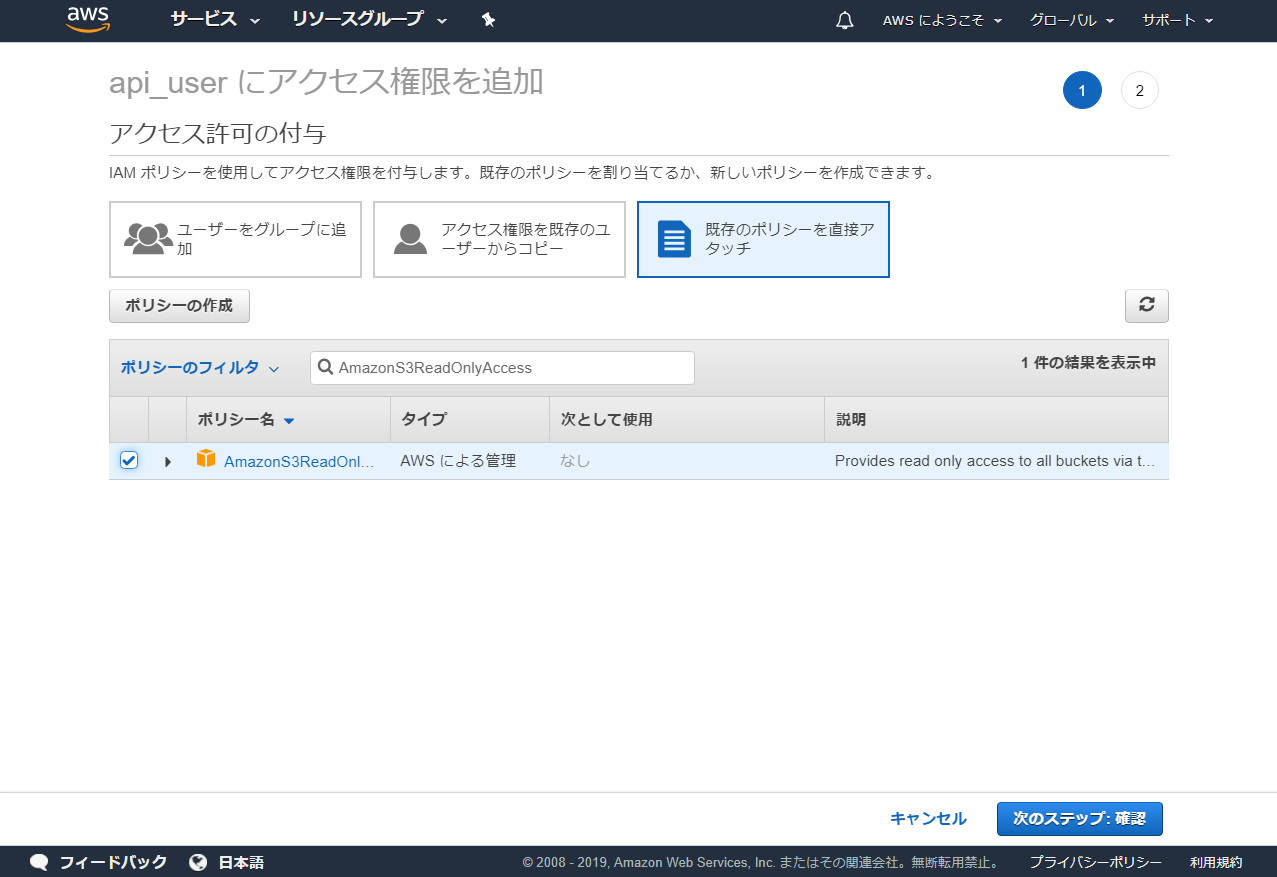
AWS管理者アカウントの手配
第1回で作成した「api_user」に、API実行に必要な権限を追加で割り当てます。上記AWSコンソール画面上の「IAMサービス」の画面で「AmazonS3ReadOnlyAccess」の権限を付与してください。
APIを使ってデータの取得する
1.今回利用するAPI
それではAPIを使って実際にデータを取得していきましょう。
利用しているS3のバケット名(識別名)一覧を取得するために
「AWS.S3.listBuckets」を利用します。
利用しているS3のデータ保存量の推移を調べるために、第2回で利用した
「AWS.CloudWatch.getMetricData」を利用します。
利用しているS3のデータ転送コストを調べるために、第3回で利用した
「AWS.CostExplorer.getCostAndUsage」を利用します。
2.スクリプトの作成
第3回で作成した「get_costexplorer_s3.js」をそのまま利用しますので未作成の方は作成してください。
S3のバケット名一覧を取得するAPI実行スクリプトを作成します。以下の内容をコピーして「s3_listBuckets.js」として保存してください。
const AWS = require('aws-sdk');
//credential情報の読込
AWS.config.loadFromPath('credential.json');
AWS.config.update({ region: "ap-northeast-1"});
//params
const params = {
};
//S3 obj
const s3 = new AWS.S3();
//データを投げる
s3.listBuckets(params, function(err, data) {
if (err) console.log(err, err.stack); // an error occurred
else console.log(JSON.stringify(data)); // successful response
});
利用しているS3のデータ保存量の推移を調べるAPI実行スクリプトを作成します。以下の内容をコピーして「cloudwatch_getMetricData_s3.js」として保存してください。
require('date-utils');
const AWS = require('aws-sdk');
//credential情報の読込
AWS.config.loadFromPath('credential.json');
//対象のS3名
var bucket_name='sample.s3';//後で修正します
//時刻の設定(1週間分のデータを取得する)
var dt_today = Date.today();
var dt_1weekago = Date.today().remove({"weeks": 1});
var formatted_today = dt_today.toFormat("YYYY-MM-DDTHH24:MI:SSZ");
var formatted_1weekago = dt_1weekago.toFormat("YYYY-MM-DDTHH24:MI:SSZ");
//Metricsの設定
const metric = {
StartTime: dt_1weekago,
EndTime: dt_today,
MetricDataQueries: [
{
Id: "data",
MetricStat: {
Metric: {
Namespace: "AWS/S3",
MetricName: "BucketSizeBytes",
Dimensions: [
{
Name: "BucketName",
Value: bucket_name
},
{
Name: "StorageType",
Value: "StandardStorage"
}
]
},
Period: 86400,
Stat: "Average",
Unit: "Bytes"
}
}
]
};
//cloudwatchの生成+リージョン指定
const cloudwatch = new AWS.CloudWatch({region: 'ap-northeast-1'});
//データを投げる
cloudwatch.getMetricData(metric, (err, data) => {
if (err) console.log(err, err.stack); // error
else console.log(JSON.stringify(data.MetricDataResults,null,null)); // ok
});
3.実行
利用しているS3のバケット名(識別名)一覧の取得
$ node s3_listBuckets.js | jq -r '.Buckets[].Name'
存在するのバケット名が表示されますので、任意の一つのデータを先ほど作成した「cloudwatch_getMetricData_s3.js」の8行目にコピーします。
sample1.s3 sample2.s3 sample3.s3
利用しているS3のデータ保存量の推移の取得
$ node cloudwatch_getMetricData_s3.js | jq -r '.[].Timestamps, .[].Values | @csv'
利用しているS3のデータ取得リクエスト回数の取得
$ node get_costexplorer.js | jq -r '.[].Groups[] | select( .Keys[0] == "APN1-Requests-Tier2")| .Metrics.UsageQuantity'
※Tier2は主にGET(データの取得)のリクエスト数です。
4.結果の確認
スクリプト実行時の結果のサンプルを以下に示します。
利用しているS3のデータ保存量の推移の取得
"2019-05-02T15:00:00.000Z","2019-05-01T15:00:00.000Z","2019-04-30T15:00:00.000Z","2019-04-29T15:00:00.000Z","2019-04-28T15:00:00.000Z","2019-04-27T15:00:00.000Z","2019-04-26T15:00:00.000Z" 97147413,99457789,101647554,103762255,105823866,108045482,110226294
利用しているS3のデータ転送コストの取得
{
"Amount": "16454",//データリクエスト回数
"Unit": "Requests"
}
5.結果の分析
上記のデータを加工して、各S3バケット毎のストレージ利用状況を分析します。
分析結果からデータの削除傾向がみられないS3バケットについて、用途を確認します。
データの見方
利用しているS3のデータ取得リクエスト回数
下記のデータから、「sample2.s3」のバケットはほぼ保存されているデータの取得が発生していないことがわかります。
※データの取得が発生しない≒アーカイブに保存しておけさえすればよい。
| S3バケット名 | データ取得リクエスト数(先月分) |
|---|---|
| sample1.s3 | 87325 |
| sample2.s3 | 12 |
| sample3.s3 | 250 |
利用しているS3のデータ保存量の推移
「sample1.s3」と「sample2.s3」についてはデータが減ることがなく常に増加を続けています。
「sample3.s3」についてはデータ利用量の絶対数が少ない上に、データが削除される(減少する)タイミングがあるため、コスト削減の対象から除外で良さそうです。
| S3バケット名 | 6days ago | 5days ago | 4days ago | 3days ago | 2days ago | 1days ago |
|---|---|---|---|---|---|---|
| sample1.s3 | 2450000087 | 2550000466 | 2650006472 | 3850011344 | 4850746756 | 4877436693 |
| sample2.s3 | 3671698075 | 3760550296 | 3805516650 | 3824921981 | 3916078592 | 4001852006 |
| sample3.s3 | 977045 | 62704 | 27228 | 195963 | 302796 | 815084 |
S3のバケット設定を変更する
データ自動削除
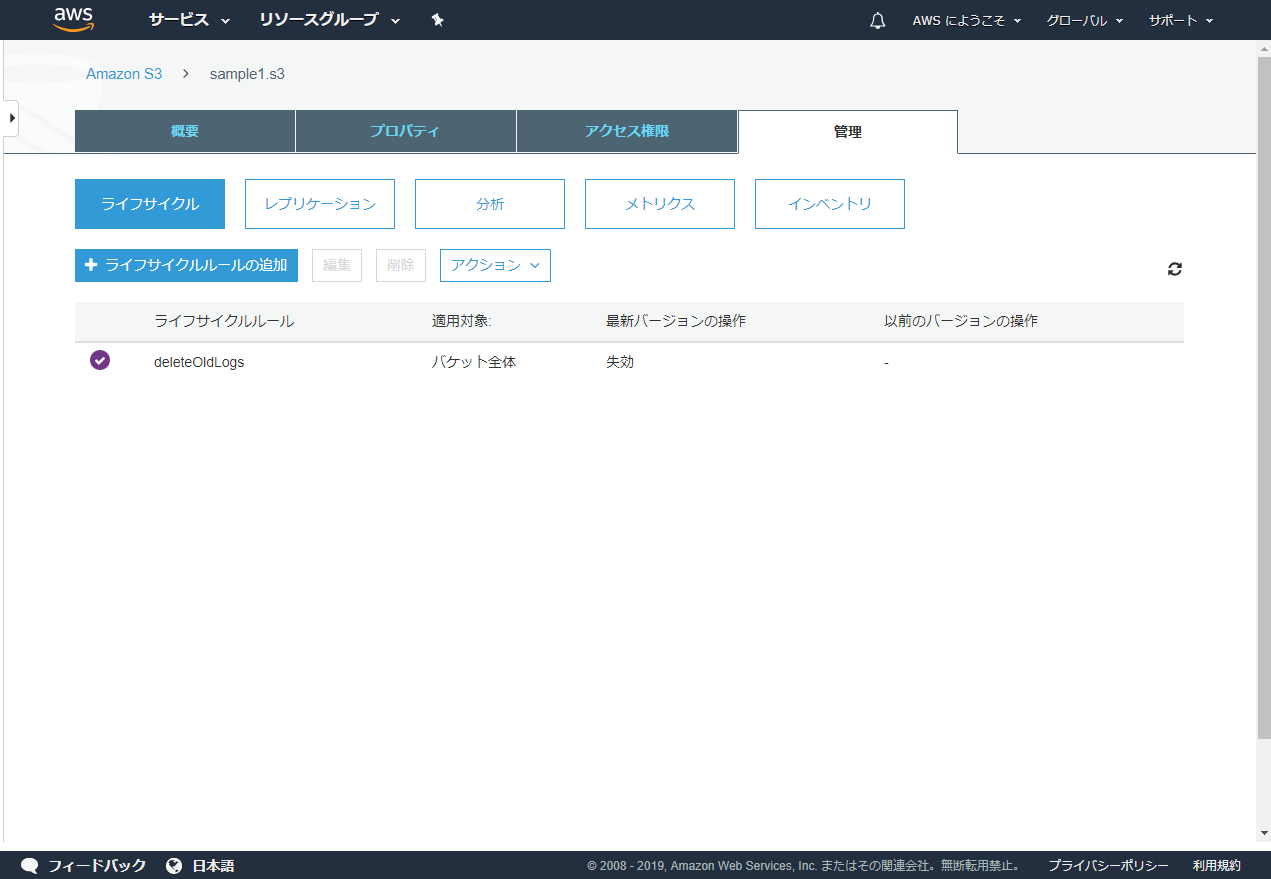
バケット名「sample1.s3」は作業ログや特定期間のみ利用するファイルの保存に利用しており、長く利用されていないファイルを削除する機会がなく、ファイルをアップロードする度にデータが増加していたことがわかりました。
S3の標準機能で利用可能なファイルオブジェクトの有効期限を設定することで、指定期間を過ぎたファイルは自動的に削除する運用とすることとします。
AWSのS3の管理コンソール画面から、対象のバケットをクリックし、「管理」タブ内にある「ライフサイクルルールの追加」ボタンから設定可能です。
Glacier自動移行
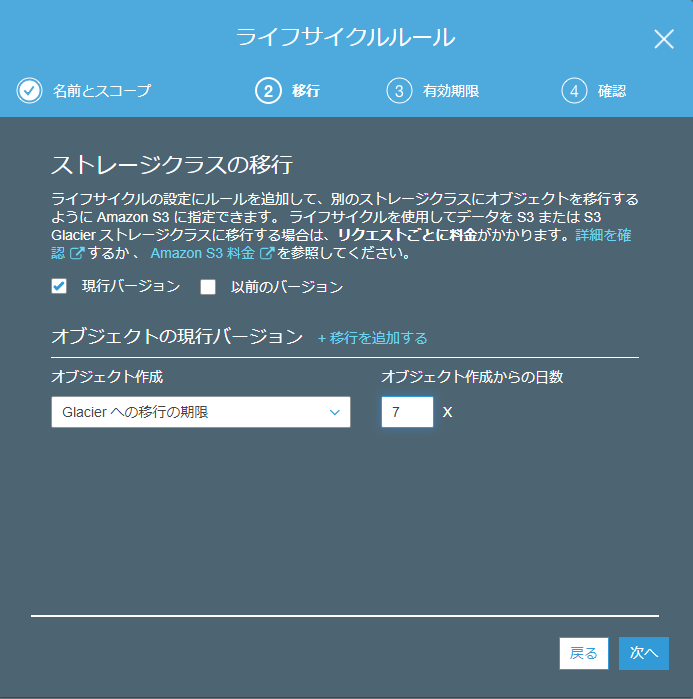
バケット名「sample2.s3」は毎日一定のサイズのデータが増加しており、EC2サーバ上で動作するアプリケーションログを自動で保管しておく用途に利用されていることがわかりました。
データの取得がほぼ存在しないことと、1週間以上前のログを至急解析するケースが稀なこともあり、より安価なGlacierへ1週間以上過ぎたログについては退避する運用とすることとします。
データの自動削除を設定した同じ画面上で、「移行」->「Glacierへの移行の期限」を設定します。





NTTテクノクロス株式会社
ビジネスソリューション事業部
![]()