DPDKの設計モデル ~DPDK入門 第12回~
前回に引き続いDPDKの設計モデルを紹介をしていきます。




DPDK入門
- 2021年03月25日公開
はじめに
こんにちは、NTTテクノクロス株式会社の寺尾です。前回に引き続いDPDKの設計モデルを紹介をしていきます。前回はpipelineモデルの初期化処理、終了処理を解説しました。今回はパケット処理をする3つのスレッドの周期処理に関して解説します。

前回のおさらい
「pipelineモデル」は複雑な処理を複数のスレッドで分担することで、アプリケーションの高速化を実現します。DPDKで扱うパケットはHugepageメモリに格納されるため、処理するパケットを各スレッドで共有する仕組みが必要になります。今回はDPDKのRingライブラリを使ったやり方を紹介します。すでに前回まででRingの作成までは説明しました。以下がそのイメージ図です。
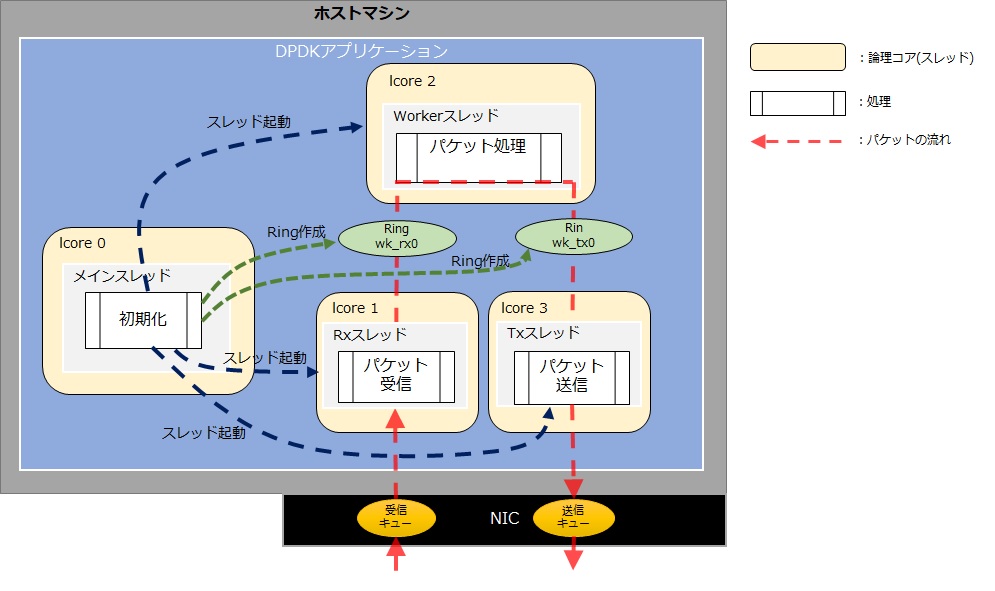 今まではNICの受信キューに対してポーリングでパケットの受信を確認していました。スレッドを複数に分割してもその考え方を変わりません。「Worker」スレッドや「Txスレッド」はRingに対してポーリングでパケットを確認します。今回のアンプルプログラムでは「単純なパケット転送」としましたが、皆さまで機会があれば複雑な処理を書いてみて比べてみて下さい。
今まではNICの受信キューに対してポーリングでパケットの受信を確認していました。スレッドを複数に分割してもその考え方を変わりません。「Worker」スレッドや「Txスレッド」はRingに対してポーリングでパケットを確認します。今回のアンプルプログラムでは「単純なパケット転送」としましたが、皆さまで機会があれば複雑な処理を書いてみて比べてみて下さい。
pipelineモデルのメリット
pipelineモデルを構築するメリットは、パケット処理が複雑な場合でも複数のCPU(スレッド)を使い高速化が実現できることです。今回紹介しているアプリケーションでは単純なパケット転送処理を3つのCPUを使うようにしています。
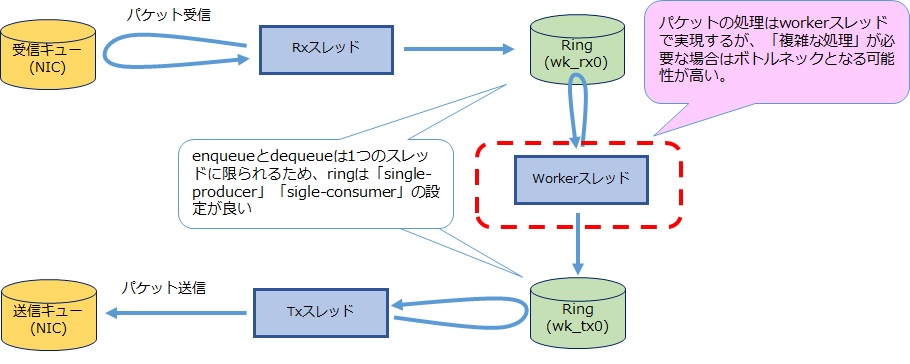
ただし今回のような「単純な転送」では、run-to-completionとあまり差を感じないかもしれません。「より複雑な処理」を実現するときにこのモデルを選択する効果が得られます。run-to-completionモデルではCPUを増やすという方法は取れませんが、pipelineモデルでは複雑な処理に応じて例えば以下のようにworkerを増やすことも可能です。
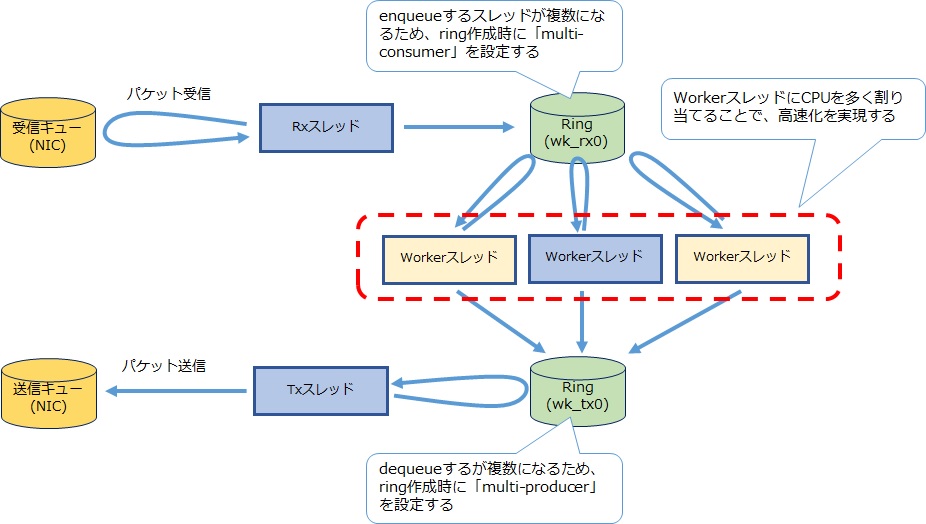
今回はRingを使ってパケットの受け渡していますが、1点注意点があります。Ring作成時に「enqueue処理」「dequeue処理」を複数のスレッドから使うかどうか指定します。特により多くのスレッド数を使う場合は、「multi-producer」「multi-consumer」を指定することが必要になりますので、注意下さい。
pipelineモデルの周期処理
Rxスレッド、workerスレッド、Txスレッドの周期処理の実装方法を解説します。この3つのスレッドはポーリングによりパケットの監視を行い、パケットの受信が確認したら送信処理をするという流れは同じです。送受信先が実際のNICかRingかで異なるところが差分です。以下がシーケンスイメージです。
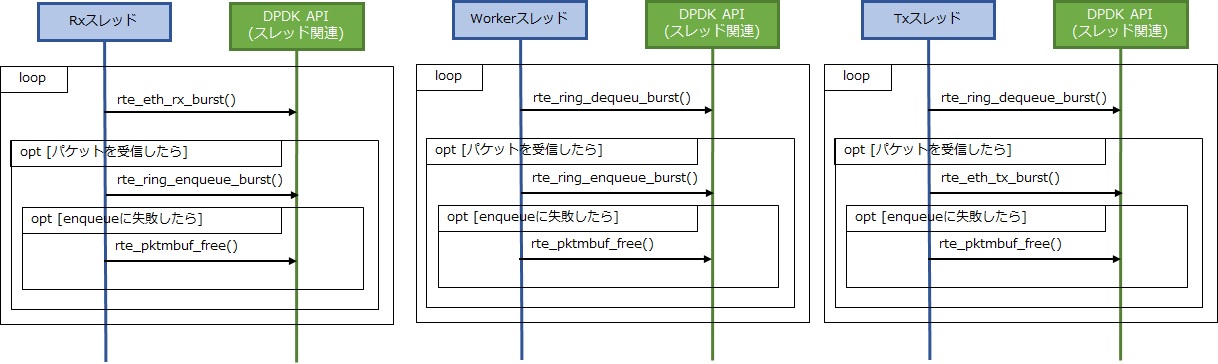
今回新しく登場するインタフェースは、Ringのenqueueとdequeue処理になります。
▼ Ringのenqueue、dequeue処理
struct rte_mbuf *pkts[32]; // パケットバッファ
uint16_t nb_rx, nb_tx;
while (true) {
nb_rx = rte_ring_dequeue_burst(rx_ring, (void*) pkts, 32, NULL);
if (nb_rx <= 0) continue;
nb_tx = rte_ring_enqueue_burst(tx_ring, (void*) pkts, nb_rx, NULL);
if (nb_tx < nb_rx)
for (i = nb_tx; i < nb_rx; i++) rte_pktmbuf_free(pkts[i]);
}
詳細はDPDK公式ページのドキュメントを参照下さい。簡単な説明は以下に記載します。
| 概要 | ringから複数のオブジェクトを最大数までdequeueする。 この関数はring作成時に指定された「multi-consumers」あるいは「single-consumer」動作に応じた処理を行う。 |
||
| 引数 | 型 | パラメータ | 補足 |
| struct rte_ring * | ringポインタ | - | |
| void ** | オブジェクトリスト | 今回のサンプルプログラムではパケットバッファポインタのリストを渡している。 | |
| unsigned int | オブジェクト数 | ringからdequeuするオブジェクトの数 | |
| unsigned int * | 残留数 | dequeue後に残っているリングのオブジェクトエントリ数を取得する。 取得が不要の場合はNULLを指定する。(outパラメータ) |
|
| 返り値 | 型 | 補足 | |
| unsigned | dequeueしたオブジェクト数 | ||
| 概要 | ringへ複数のオブジェクトをenqueueする。 この関数はring作成時に指定された「multi-producers」あるいは「single-producer」動作に応じた処理を行う。 |
||
| 引数 | 型 | パラメータ | 補足 |
| struct rte_ring * | ringポインタ | - | |
| void ** | オブジェクトリスト | 今回のサンプルプログラムではパケットバッファポインタのリストを渡している。 | |
| unsigned int | オブジェクト数 | ringへenqueuするオブジェクトの数 | |
| unsigned int * | 空きスペース数 | enqueue後のリングの空きエントリ数を取得する。 取得が不要の場合はNULLを指定する。(outパラメータ) |
|
| 返り値 | 型 | 補足 | |
| unsigned | enqueueしたオブジェクト数 | ||
性能チューニング
システムを動かしてる際性能に満足していない場合でも、pipelineモデルであればスレッドを増やすことで高速化をすることができます。そこで問題なのは、どのスレッドをどれくらい増やすべきかを判断する方法です。今回は判断する方法の一例を紹介します。
今回は今まで作成してきたpipelineモデルでパケットジェネレータから送信したパケットを十分に処理できない事象が発生したという問題例で解説します。パケットジェネレータとは、ランダムにパケットを生成したりカスタムしたパケットを作成するための装置です。ソフトウェアでも様々あり、例えばDPDKアプリケーションとしては、Pktgen(※1) があります。
今回パケットジェネレータから100万pps でパケットを送信しが実際に転送できたのは10万ppsだった、という問題に遭遇したとします。pipelineモデルの「どこか」にボトルネックがありますがその箇所を特定しスレッドを増強したいと考えています。各スレッドではログを出しており、以下の事象であることは分かっていますが、どのスレッドを増強すれば良いか分かりますでしょうか?
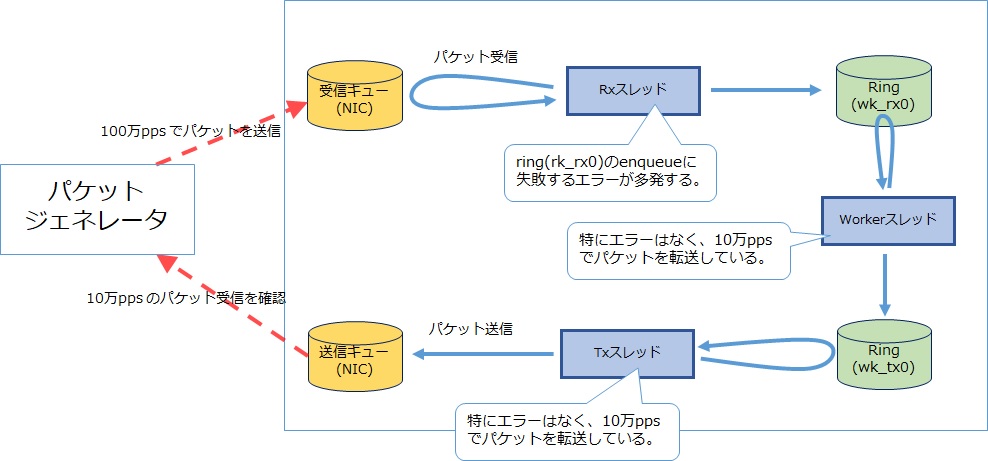
Rxスレッドでエラーが出ているため、そこに問題が起きていると考える人がいるかと思いますが、この場合はその考えは間違っている可能性が高いです。Workerスレッドで十分性能が出ていないことにより、RxスレッドがWorkerスレッドにパケットを渡すことが出来ないと考えるほうが自然です。エラー箇所のほうで、rxスレッドとworkerスレッドで共有しているRing箇所でエラーが出ているかを確認し、最終的に判断します。この場合では、Workerスレッドの性能が10万ppsになっていることにより、パケットジェネレータから100万ppsで送信するパケットのうち90万pps分がrxスレッドで「適切」に破棄している可能性が高いと思います。
pipelineモデルを採用していれば、workerスレッドを10スレッドにすることでこういったボトルネックを解消することが出来るかもしれません。このモデルの長所では、ボトルネックとなる処理に対してダイレクトにCPUのリソースを割り当てることで、システム全体の高速化を実現することができます。ただし、こういった性能チューニングをするためには、このモデルに関しての知識、ソフトウェア上で判断するための情報出力が必要となるため、run to completionモデルより難易度は高いです。システムの要件に合わせて、どのモデルを採用するかを見極める必要があります。
おわりに
今回はDPDKでよく採用される設計モデルを紹介しました。約2年程度かけて12回の記事を執筆し、DPDKのテクニックを紹介させて頂きました。DPDKはネットワーク業界でもマニアックな技術と思いますが、一つ一つは既知の技術の集合体だと思っています。ネットワークに関係なく、高速化に興味がある人が本連載を閲覧して頂ければ幸いです。
本記事の連載に関して何か問い合わせがございましたら、以下に連絡下さい。よろしくお願いします。
本件に関するお問い合わせ
NTTテクノクロス
フューチャーネットワーク事業部
寺尾智之



長年NTTの通信基盤となるネットワーク関連の仕事に従事。 最近では仮想化技術が主流化しており、最新動向を追従する日々。 DPDKに関してはニッチな領域のためか仲間が増えないと感じており、ブログを通した仲間づくりを開始。 横浜生まれだが、巨人ファン。たまに東京ドームに観戦に行くことが楽しみ。
![]()