生成AI活用の鍵は「サービス」と「インフラ」の融合|コンタクトセンター事例とDCN高品質化技術
カスタマーエクスペリエンス事業部×フューチャーネットワーク事業部の対談から生まれたコラボ記事




カスタマーエクスペリエンス事業部×フューチャーネットワーク事業部の対談から生まれたコラボ記事
「使いやすさ」と「基盤の強さ」の両輪が品質を作る
今回の記事は生成AIの品質に着目したカスタマーエクスペリエンス事業部所属の今井とフューチャーネットワーク事業部所属の村木による共同執筆です。
生成AIの品質を共通の題材にした対談を行いましたが両部署の観点の違い, またそこから生まれる新たな展望が見え, 興味深い内容となりましたので記事に書き起こしました。
- ・1. はじめに
- ・2. サービス観点から見る生成AI活用の高品質ポイント
- ・2.1. ForeSight Voice Miningでの生成AI活用事例
- ・2.2. コンタクトセンター導入時の課題と気をつけたポイント
- ・2.3. 導入した結果わかった音声認識×生成AIの効果
- ・2.4. 生成AI要約を導入したお客様の声
- ・3. ネットワーク観点から見る生成AI活用の高品質ポイント
- ・3.1. 生成AIを用いる上での分散処理について
- ・3.2. 生成AIを用いる上でのネットワーク品質の条件
- ・3.3. 市中のDCN高品質化のための監視技術
- ・3.4. DCN品質向上のための取り組み
- ・4. おわりに:アプリとインフラの連携が生む未来の展望

1. はじめに
近年, 生成AI(Generative AI)は急速に進化し, さまざまな分野でその重要性が増しています。
生成AIとは, データから新しいコンテンツを生成する人工知能の一種であり, テキスト, 画像, 音声, 動画など多岐にわたる生成能力を持っています。
この技術は, 従来のAIとは異なり, 単にデータを分析するだけでなく, 新しいデータを創り出すことができるため, 革新的な可能性を秘めています。
生成AIがもたらす革新は, ビジネスと技術の両面で非常に重要です。
ビジネスにおいては, 生成AIは新しい製品やサービスの開発を加速させ, 顧客体験を向上させることができます。
例えば, カスタマーサポートにおける自動応答システムや, マーケティングキャンペーンの自動生成など, さまざまな応用が考えられます。
技術的な進歩により, 生成AIはますます高精度で効率的になり, その影響は広範囲に及んでいます。
○ビジネスにおける生成AIの応用例
生成AIの応用例としては, 以下のようなものがあります。
- ・広告業界:ターゲット広告のクリエイティブを自動生成することで, 広告効果を最大化
- ・エンターテインメント業界:新しい音楽や映像コンテンツの創出
- ・医療分野:新薬の開発や診断支援
これらの応用例は, 生成AIがもたらす新しいビジネスチャンスの一端に過ぎません。
○弊社の取り組み
弊社では, 生成AIを高品質に活用するために, さまざまな観点から取り組みを行っています。
サービス構築の観点では, 生成AIを活用した新しいサービスの開発に注力しています。
具体的には, コンタクトセンターのシステムに生成AIを導入することで, 業務改善・効率化を図っています。

ネットワークインフラの観点では, 生成AIを高品質に活用するために不可欠な安定したネットワーク環境の研究調査に力を入れています。
生成AIを用いるデータセンターネットワーク(DCN)の監視と最適化に関する研究を進めており, リアルタイムでの異常検知やトラフィック予測を行うことで, ネットワークの品質維持に取り組んでいます。

本記事では, 生成AIを高品質に活用するための具体的なポイントについて, サービス構築とネットワークインフラの両面から詳しくご紹介します。
生成AIの可能性を最大限に引き出し, ビジネスと技術の両面での成功を目指すためのヒントとなれば幸いです。
2. サービス観点から見る生成AI活用の高品質ポイント

2.1. ForeSight Voice Miningでの生成AI活用事例
ForeSight Voice Miningは, お客様とオペレータの通話を音声認識技術によって可視化し, 分析を行うことで, コンタクトセンターの業務改善・効率化を実現するサービスです。
多くのコンタクトセンターでは, 通話終了後にオペレータが通話内容を要約し, 顧客管理システムに登録して管理を行っています。
しかし, 通話の要約作業には以下のような課題がありました。
- ・長時間の通話の場合, 要約に時間がかかる
- ・オペレータごとに要約の粒度が異なる
これらを解決するために, ForeSight Voice Miningに生成AIを連携し, 通話内容を自動要約することで, 要約にかかる時間の削減と要約結果の均質化を実現しています。
2.2. コンタクトセンター導入時の課題と気をつけたポイント
通話の要約を生成AIで実施するにあたり, 当初のプロンプトは「この通話を要約してください」というシンプルなものでした。
最近では生成AIの性能が向上し, このような簡単なプロンプトでも適切に要約してくれます。
しかし, コンタクトセンターへの提案を進める中で, コンタクトセンターが求めているのは「通話をただ要約した結果」ではなく, 「顧客管理システムに登録し, 通話をしていない人でもそのコンタクトセンターにとって重要な内容がひと目で把握できる要約結果」であることがわかりました。
そのため, 要約を実施する際のファーストステップは, そのコンタクトセンターがどのような通話を受けていて, どのように顧客管理システムに登録していて, どのような人がその顧客管理システムを参照するのかを把握することです。
そのうえで適切な内容に通話を要約するプロンプトを試行し, 適切な要約結果になるように調整を行います。
生成AIの優れた点は, ある程度出力のフォーマットを指定することで, そのフォーマットに合った内容を通話の中から見つけて抽出し, まとめてくれることです。
通話の中で重要になる要素はコンタクトセンターごとに異なるため, 導入時にはまずそのコンタクトセンターの業務を理解することがポイントとなります。
2.3. 導入した結果わかった音声認識×生成AIの効果
連携の検討を始めた当初は, 生成AIの精度も低く, 音声認識の誤認識があると誤った要約になってしまうことがありました。
しかし, 連携を進めていく中で, 新たな生成AIが次々と発表され, 当初の想定を上回る効果を得ることができました。
○生成AIが誤認識を補正して要約してくれる
音声認識システムの課題として, 話者の周囲の環境, 声を収録するマイク, 通信環境などにより, 音声認識精度が向上したとしても, リアルタイムでの音声認識精度には限界があります。
しかし生成AIでは会話全体を理解することで, 音声認識システムが誤認識してしまった内容でも, ある程度は意味を推測して正しい音声認識結果として文章を要約してくれることが多いです。

○連続した発話でなくとも意味を理解して適切につなげてくれる
電話での会話では, 電話番号や名前を相手に正確に伝えるために, 連続して発話されずに「090の」「090ですね」「次が1234で」のような形で, 途切れ途切れだったり間にオペレータの復唱が入ることがほとんどです。
間違えて伝わらないようにするためには重要なことですが, 音声認識結果として見るときには, かなり見づらいものになります。
しかし, 生成AIの進化により, 名前や電話番号が途切れ途切れで認識されていたとしても, 生成AI側が内容を理解してくれることで, 名前や電話番号を人が読みやすいフォーマットに整形して出力してくれます。
そのため, どのお客様からの電話だったのかを把握することができ, 以前の問い合わせとの紐づけや今後のサービス提案方針をより個人にフォーカスしたものにすることができるようになりました。
2.4. 生成AI要約を導入したお客様の声
導入効果としてはさまざまな声をいただきますが, 特に効果があったと考えているのは, 新人オペレータの要約についてです。
コンタクトセンターは人の入れ替わりが激しい業界です。
新人オペレータは応対後の要約を実施する際も, 要約ポイントなどのイメージがあまりついていない場合もあり, 要約をするということに大きなハードルを抱えていることが多かったそうです。
そこに生成AIによる要約を追加したことで, 一旦AIに通話を要約させることで, 自分の応対の中で顧客管理システムにどのようなことをポイントとして登録しなければならないかということがイメージできるようになり, 習熟が早まったとの声をいただきました。
私自身も資格勉強の際, 小論文が出てきたとき, 正解がイメージできず, うまく進めることができなかった経験があります。
参考書などを開いても, 自分の今の状態と一致しているものではなく, 思うように理解が進みませんでした。
しかし自分の回答を生成AIに添削してもらうことで, 自分の経験や状況をベースに課題などを教えてもらうことができ, 一気に理解が進みました。
生成AIにはさまざまな魅力があると思いますが, 私は自分に寄り添った回答をしてくれることが一番の魅力だと感じています。
何か新しいことを始めるとき, 生成AIは最初の一歩の道しるべになってくれると実感しました。
3. ネットワーク観点から見る生成AI活用の高品質ポイント
本章では, 生成AIを活用するにあたってネットワーク観点から高品質を実現するポイントを以下の観点でご紹介します。
- ・生成AIを用いる上での分散処理について
- ・生成AIを用いる上でのネットワーク品質の条件
- ・市中のDCN高品質化のための監視技術
- ・DCN品質向上のための取り組み
生成AIは大きく学習(事前学習/チューニング)と推論のフェーズに分けることができ, 両方を含んだ内容で解説していきます。
3.1. 生成AIを用いる上での分散処理について
推論フェーズについて, サービス利用ユーザが限定される, またはあまり多くない場合はネットワーク観点では問題となることはほぼないと考えられるため, 不特定多数のユーザを持つサービスの場合で考えます。
生成AIの推論はマシンパワー次第ですが, 多数の推論を同時に行うと処理が遅くなる, つまり生成AIからの回答が遅くなるリスクがあります。
回答が遅くなることはユーザストレスとなり, サービス品質が低下してしまいます。
○学習フェーズにおける分散処理
学習のフェーズについては, 生成AIとして代表的なLLM(大規模言語モデル)のモデルサイズはその性能に比例して増加傾向にあり, 1台のサーバに搭載可能なGPUでは学習が不可能, あるいは膨大な時間を要する場合が多いです。
そのため, 学習/推論ともに複数のサーバ/GPUに跨った分散処理の技術が用いられています。
○Megatron-DeepSpeedの紹介
今回は分散処理に用いられる代表的なフレームワークであるMegatron-DeepSpeedをご紹介します。
Megatron-DeepSpeedはMicrosoftが管理している以下を組み合わせたフレームワークです。
学習/推論両方で活用可能な分散処理が提供されています。
- ・Megatron-LM:NVIDIAが開発した大規模Transformerモデルをマルチノードで学習するための基盤
- ・DeepSpeed:Microsoftが開発した大規模モデルの学習/推論効率化のためのソフトウェア
○推論の効率化/高速化
Megatron-DeepSpeedに含まれるDeepSpeedの代表的な効率化/高速化技術をご紹介します。
・DeepSpeed Inference
学習済みモデルを使用して高速に推論を行うための以下のような最適化が含まれています。
- ・DeepFusion:生成AIの計算時には高速化のためにGPUが用いられます。このGPUとホスト側の計算の際にそれぞれのカーネル起動回数を減らし高速化するための技術です。
- ・SBI-GeMM:推論時の小さいバッチサイズにおいてメモリからパラメータの読み取りを高速化する技術です。
- ・モデル並列:Tensor Parallelism/Pipeline Parallelismなどがあります(詳細は以下「学習の効率化/高速化」で解説)。
- ・ZeRO-Inference:GPUメモリの利用を効率化するため, 必要なときに必要なレイヤーのみDRAMやNVMeからGPUメモリにロードして計算する技術です。
- ・Blocked KV Caching:Transformerモデルの計算に必要なKey Valueの値をブロックに分割してキャッシュすることで, 連続したメモリを確保する必要がなくなりメモリ効率を向上させる技術です。
○学習の効率化/高速化
Megatron-DeepSpeedに含まれるMegatron-LMの代表的な効率化/高速化技術をご紹介します。
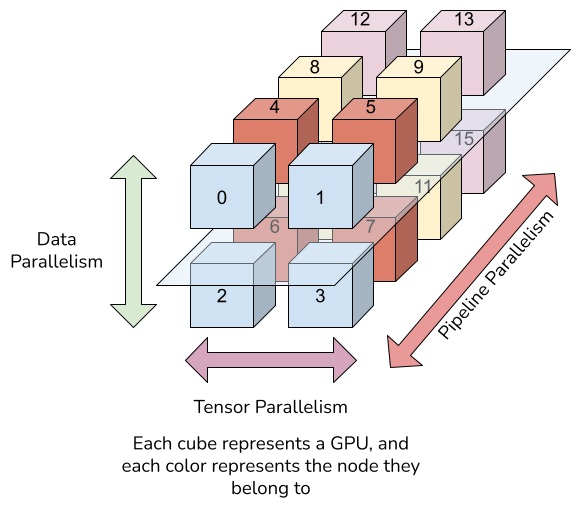
・3D Parallelism
大規模なLLMを学習する際にGPU1つではモデルがGPUメモリに収まらず学習することができない場合があります。こういった場合に複数のGPUメモリにデータやモデルを分割して分散処理するための技術が3D Parallelismです。
3D ParallelismはData Parallel(学習データの分割)+ Tensor Parallel(モデルの分割)+ Pipeline Parallel(モデルのtransformerブロック方向の分割)のことを指します。
- ・DP(Data Parallel):各GPUにロードされたモデルに対してデータセットを分割し渡すことで, 学習時間は論理的には1/N(データ並列数)となり学習時間が高速化できます。
一方でモデル自体の分割は対象としないため, Data Parallelだけでは大規模なLLMには対応できないと考えられます。 - ・TP(Tensor Parallel):行列×行列の演算を並列化し, 各GPUは1/N(テンソル分割数)のテンソルだけを持つ分散処理です。
GPUメモリ制約の解消に役立ちメモリ使用を効率化できますが, 計算グラフに影響しない形で分割する必要があります。 - ・PP(Pipeline Parallel):モデルをレイヤーの束で分割する分散処理です。例として, 32レイヤーあるモデルを4個に分割する場合は1GPUに8レイヤー割り当てられます。
TPと同様にGPUメモリ制約の解消に役立ちメモリ使用を効率化できます。
ただし, 各GPUごとに担当するレイヤーが異なるため, バッチサイズによってはGPU使用率が下がる可能性があります。 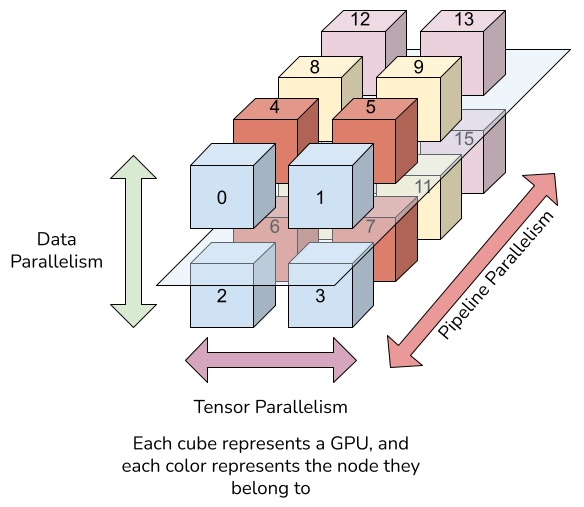
- (出典:A Deep Dive into 3D Parallelism with Nanotron⚡️ | TJ Solergibert)
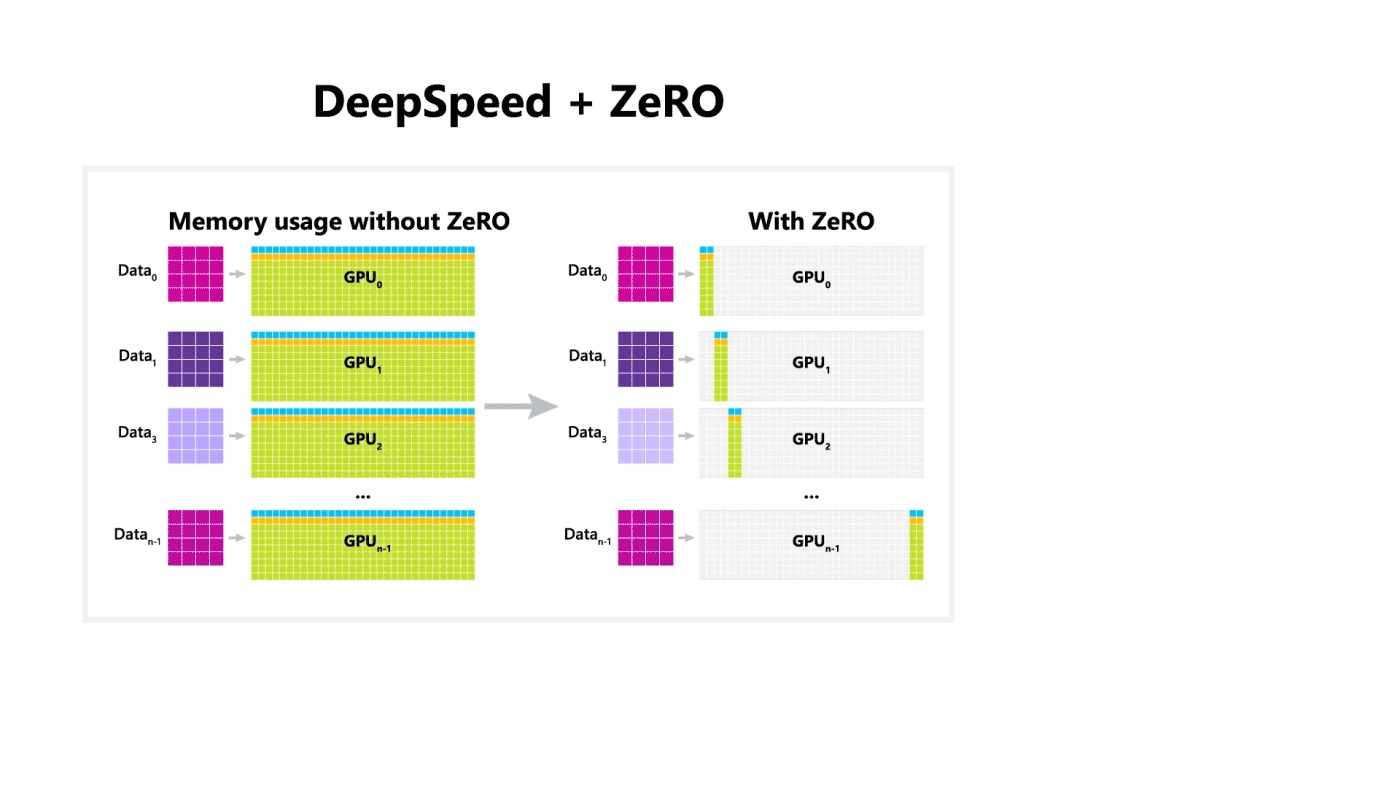
・ZeRO(Zero Redundancy Optimizer)
Megatron-DeepSpeedに含まれるDeepSpeedの代表的な効率化/高速化技術です。
通常データ並列では重複して持つ学習パラメータについて, 重複がないように各GPUに格納することでメモリ使用量を大幅に削減し効率化します。
3.2. 生成AIを用いる上でのネットワーク品質の条件
生成AIに活用されるLLMの学習には, 上記でご紹介した通り複数のノード/GPUに跨った学習や推論が必要となります。
こういった環境にはデータセンターのような大規模な設備が必要となり, 一般的にそのネットワークはDCN(DataCenter Network)と呼ばれます。
○DCNの一般的なネットワーク構成
DCNは大きく以下のようなネットワークで構成されます。
・フロントエンドネットワーク
主にCPU処理がメインとなり外部との通信に用いられるLossyなネットワークです。
- ・推論時には外部から推論用のAPIが呼ばれ, 応答を返却する等に用いられます
- ・学習時にはHugging FaceやS3等の外部ストレージからのモデルやデータセットのダウンロード等に用いられます
・バックエンドネットワーク
主に分散学習等のGPU処理がメインとなり, GPU間通信が行われるLosslessが要求されるネットワークです。
○バックエンドネットワークの高品質化技術
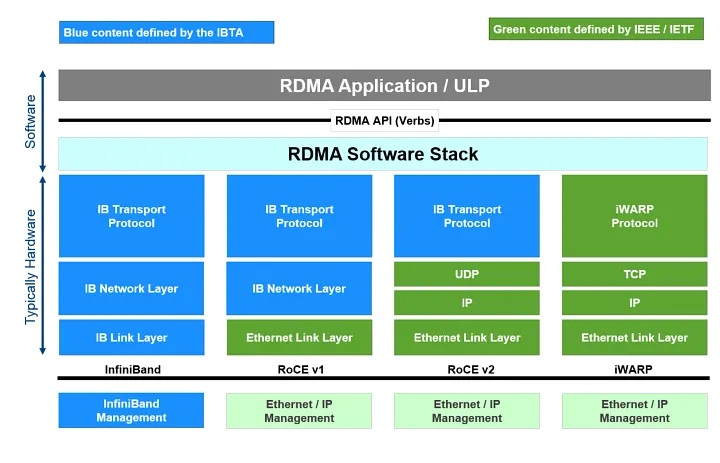
分散処理のような大規模で高速な通信を行う際にはRDMA(Remote Direct Memory Access)という技術が用いられます。
RDMAはメモリから異なるサーバのメモリにOSを経由せずデータ転送を行う技術であり, 高スループット, 低レイテンシの通信を行うことができる技術です。
こういったRDMAを実現する技術ではGo-back-Nというパケットドロップが発生した際にドロップしたパケットのリクエストまで遡って通信を再開する方式が採用されています。
このGo-back-Nは通信負荷が高く性能影響が大きいため, パケットロスによる分散処理への影響が大きくなることから, バックエンドネットワークではLosslessなネットワークが条件として求められています。
分散処理のためのネットワーク高速化の技術として以下の観点でご紹介します。
- ・同一ノード内のネットワーク高速化技術
- ・ノードを跨ったネットワーク高速化
- ・ネットワーク機器での負荷分散による高速化
○同一ノード内のネットワーク高速化技術
NVIDIAが開発した「NVIDIA® NVLink™」「NVIDIA® NVSwitch」をご紹介します。
・NVIDIA® NVLink™
NVIDIAが開発した同一ノード内のGPU間でのデータ通信を効率化する通信規格です。
従来, 同一ノードに存在する複数GPUはPCI Express(PCIe)を用いていましたが, AI学習等の広帯域を要求するアプリケーションのボトルネック解消のため開発されました。
例としてPCIeとNVLinkの帯域幅には以下のような性能差があります。
- ・PCIe5.0が提供する帯域幅:最大で64GB/s
- ・第5世代NVIDIA® NVLink™が提供する帯域幅:最大で1.8TB/s
また, 上記NVLinkを物理的に接続する接続部品はNVIDIA® NVLink™ブリッジとして提供されています。
・NVIDIA® NVSwitch
こちらも同様にNVIDIAが開発した同一ノード内のGPU間でのデータ通信を効率化するための技術で, NVLink専用のスイッチチップです。
NVLinkより多くのGPU接続を可能とし, 大量のGPUの相互接続の面で優れています。
○ノードを跨ったネットワーク高速化
NVIDIAが開発した「NVIDIA® NVLink Switch」, およびRDMAプロトコルの観点でご紹介します。
・NVIDIA® NVLink Switch
NVLink Switchは後述のInfiniBandのスイッチの設計を活用し, NVSwitchチップをベースにしたスイッチングデバイスです。ノードを跨ったGPU間の高性能通信を目的として設計されています。
NVLink Switchは, 単一ネームスペースでの分散処理におけるネットワーク内のGPUを接続するために特別に設計されており, スイッチとして機能します。
NVLink SwitchはMellanoxが開発したSHARP(Scalable Hierarchical Aggregation and Reduction Protocol)プロトコルを利用して最適化とアクセラレーションを行います。
・RDMAプロトコル
DCNでの利用が想定されているRDMAプロトコルをご紹介します。
・InfiniBand
InfiniBandはIBTA(InfiniBand Trade Association)で管理されているネットワーク通信規格です。
超並列のスーパーコンピュータなどで使われるネットワーク技術であり, 分散処理が必要なAI基盤としても用いられています。
InfiniBandはSDN(ソフトウェア定義ネットワーキング)向けに設計されています。
SM(サブネットマネージャ)にSMA(サブネット管理エージェント)によって構成されており, SMがトポロジの検出から最短経路でのルーティング/ロードバランシングまでを自動で行います。
また, RDMAによるメモリ転送が可能でありAI学習といった高スループットを要求する処理のパフォーマンス向上が期待できます。
InfiniBandはEthernetベースのプロトコルとは仕組みが異なっているため, 専用のNIC/ネットワーク機器を調達しネットワーク構築する必要があります。
・RoCE
RoCE(RDMA over Converged Ethernet)はInfiniBand同様IBTA標準に準拠したネットワーク通信規格です。
InfiniBandと異なりEthernetのネットワーク上でRDMAを可能とした技術です。
単一ブロードキャストドメインで動作するイーサネットフレームベースのRoCEv1とIP/UDP上で動作するRoCEv2があります。
InfiniBand同様にRDMAをサポートし高性能な伝送が可能です。
既存のネットワーク機器を流用することも可能ですが, RoCEv2ではDCB(Data Center Bridging)で定義される以下の技術を用いてLosslessネットワークを実現するため(DCQCN), 専用ネットワーク機器を導入することが望ましいです。
- ・PFC(Priority-based Flow Control):IEEE802.1Qbbで定義される仮想リンクの優先度ベースのフロー制御技術
- ・CN(Congestion Notification):IEEE802.1Qauで定義されるネットワーク機器の輻輳通知と通信抑制技術
また, NICについてはRDMAのためのオフロードが必要なためRoCE対応NICを導入する必要があります。
・Ultra Ethernet
UEC(Ultra Ethernet Consortium)で検討されているネットワーク通信規格です。
RDMAや既存のRoCEよりもHPCやAIネットワークに最適化されたトランスポート層を提供することを目的としています。
マルチパスでのパケットスプレー/セキュリティ等の技術要素が盛り込まれる予定です。
また, InfiniBandやRoCEと異なり, 複雑なチューニングを要しないテレメトリベースの輻輳制御を盛り込む予定です。
物理層は専用のデバイス, L2/L3は既存のEthernet/IPをベース, L4は独自プロトコルを想定しています。
ソフトウェアに関しては既存のCCL/MPIといった並列/分散アプリケーションをサポートする予定です。
2024年12月11日にSynopsysより「Ultra Ethernet IP」/「UALink IP」ソリューションの提供が開始され, 今後も開発が継続する予定です。
・各プロトコルの構造
プロトコル構造としては以下の通りです。InfiniBandは慣れ親しんだEthernetの構造とは異なっていることがわかります。
Ultra EthernetはInfinibandのBTH+を用いず独自構造を検討しているのが特徴となります。
|
プロトコル |
L2 |
L3 |
L4 |
Payload |
CRC |
|
InfiniBand |
LRH |
GRH |
BTH+ |
IB Payload |
ICRC/VCRC |
|
RoCEv1 |
MAC/ET |
- |
BTH+ |
IB Payload |
ICRC/VCRC |
|
RoCEv2 |
MAC/ET |
IP/UDP |
BTH+ |
IB Payload |
ICRC/VCRC |
|
Ultra Ethernet |
MAC/ET |
IP |
UET |
Payload |
- |
○ネットワーク機器での負荷分散による高速化
一般的にネットワークにおいてはルーティングプロトコルによるルート設定, およびECMP等でのマルチパス設定上でのフローによる負荷分散を実施しています。
これは上記で紹介したInfiniBand/RoCEにも一部当てはまる仕組みです。
一方で, DCNにおけるAI学習等ではマウスフローとエレファントフローが混在しており, フローベースの負荷分散では特定のエレファントフローの偏りによる輻輳が発生する可能性があります。
このためAdaptive routingやPacket sprayといったパケットベースの負荷分散の仕組みが検討されています。
・InfiniBand Adaptive Routing
ネットワーク機器において負荷が一番少ないポートからトラフィックを転送することで特定のリンクの輻輳を回避する技術です。
ただしOut-of-Orderが発生するためNICでリオーダーをする必要があります。
・Packet-spray-based LB
RoCE等のEthernetベースプロトコルにおいてもパケットスプレーによる負荷分散技術が存在しています。
InfiniBand同様, パケットの順序性担保には対処が必要であり, ベンダごとにその規格は異なっています。
3.3. 市中のDCN高品質化のための監視技術
これまでご紹介したようにLLMの学習/推論で用いられるネットワークはLosslessが求められており, 通信の分散処理に与える影響は大きいものとなっています。
そのため, 市中ではDCNのネットワークを監視し運用に役立てる仕組みが提案されています。
○Juniper Apstra
データセンターネットワークの構築/運用/監視が自動化できるサービスです。
AIデータセンターネットワークの運用監視化/自動化/監視ソリューションで, RoCEv2に対応しECN/PFCといった設定をGUIから投入可能です。
フロー監視を実施し, ヒートマップやインシデントベースの解析を通じて輻輳を検知します。
RoCEv2を用いたLosslessネットワークの構築にはDCQCNにおけるECN/PFCのデリケートな調整が必要となります。
そのため, ApstraはRoCEv2の混雑メトリックを継続的に監視しスイッチのDCQCNを再設定してDCNを数分間で自動調整しパケットロスを回避します。
○Cisco Nexus Dashboard Insights
データセンター向けのネットワーキングプロビジョニングやインフラストラクチャ管理のサービスです。
アラート, 分析/予測アルゴリズムが組み込まれており, ネットワーキング/コンピューティングコンポーネントから取得したテレメトリデータを利用してネットワークの動作を詳細に把握することができます。
ECNおよびPFCカウンタを使用して, RoCEv2トラフィックの輻輳とパフォーマンスを経時的に可視化することができます。
3.4. DCN品質向上のための取り組み
4. おわりに:アプリとインフラの連携が生む未来の展望
近年, 生成AIを活用したサービスのプラットフォームは, オンプレミス環境からクラウド環境への移行が加速しています。
この変化に伴い, データの保護や通信の安全性に対するお客様の関心は一層高まっており, セキュリティ要件への対応も重要なポイントとなっています。
このような状況において, フューチャーネットワーク事業部が培ってきたネットワーク監視技術を, 生成AIサービスのインフラに適用することで, カスタマーエクスペリエンス部のサービス品質向上に寄与できると, 今回の共同執筆を通じて実感しています。
リアルタイムでのトラフィック監視や異常検知により, セキュリティインシデントの早期発見や, パフォーマンスのボトルネックの特定を実現していきたいと考えています。
また, 生成AIサービスの需要拡大に伴い, レスポンス速度の低下という新たな課題も予想されます。
さらに, 集中型のシステム構成では, 障害発生時の影響範囲が広範に及ぶリスクも抱えています。
こうした課題に対して, 私たちが検討を進めている分散学習のノウハウや, 負荷分散のネットワーク設計技術を活用することで, より堅牢で高速なサービス基盤の構築が実現できると考えています。
今回の合同記事作成を通じて, 部署間の垣根を越えた連携の可能性を実感しました。
サービス提供側の知見とインフラ技術側の専門性を融合させることで, 単独では成し得ない相乗効果が生まれます。
今後も継続的な部署間を越えたコラボレーションを推進し, お客様により高品質で信頼性の高いサービス提供を目指したいと思います。
本件に関するお問い合わせ
NTTテクノクロス
カスタマーエクスペリエンス事業部 第二ビジネスユニット
今井 聡
フューチャーネットワーク事業部 第一ビジネスユニット
村木 遼亮




[著者プロフィール]
カスタマーエクスペリエンス事業部 第二ビジネスユニット
今井 聡(IMAI SATOSHI)
フューチャーネットワーク事業部 第一ビジネスユニット
村木 遼亮(MURAKI RYOUSUKE)
![]()