ローカルLLMサービングを見える化しよう
~ vLLM × Prometheus × Grafana で作る監視ダッシュボード ~




はじめに
みなさんはローカルLLMを複数人で使っていますか?
ローカルLLMとは、ChatGPTのようなクラウドベースのサービスとは違い、企業や個人が自分のパソコンやサーバーなど、手元の環境で動かせる大規模言語モデル(LLM)のことを指します。
こうしたローカル環境では主に個人による利用が中心でしたが、企業内での活用などが進むにつれ、最近ではローカルLLMをクラウド上に展開し、複数人で共有して使うケースも増えてきています。
このようにLLMのクラウド活用が広がり、複数人・複数チームでの共有利用が一般化する中で、次に求められるのが「LLMの監視基盤」です。LLMの監視基盤とは、モデルの動作状況をリアルタイムで把握し、異常の早期発見や運用の最適化を行うための仕組みです。モデルの応答品質や利用状況、誤動作の検知などを見える化する仕組みが、安定運用と継続的な改善の鍵となります。
そこで今回はLLMのサービングエンジンであるvLLMとPrometheusとGrafanaを使った監視基盤の構築をご紹介します。
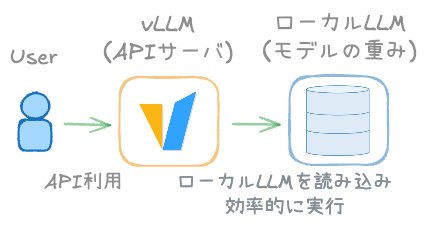
vLLMとは「推論エンジンを持つAPIサーバ」です。
手元に保存したローカルLLMを、vLLMが読み込み、高速かつ効率的に推論を実行します。
アプリケーションはvLLMが提供するOpenAI互換APIを叩くだけで、ローカルLLMを利用できます。
そもそも、なぜ"見える化"が必要?
ChatGPTや他のLLMを使っていて、「ちゃんと返答してる?」「遅くない?」「GPU大丈夫?」と思ったことありませんか?実はLLMの中は結構ブラックボックスでリクエストが詰まっていても気づけなかったり、エラーが静かに発生していたりします。 そこで登場するのが「見える化=監視ダッシュボード」 これがあると、推論状況・リクエスト数・エラー率が一目瞭然です。
vLLMって何がスゴい?でも放っておくと危ない...?
vLLMは高速LLMサービングエンジンです。
特徴はなんといっても「PagedAttention」という効率的なメモリ管理により、
複数クエリを同時に高速処理できることですが、高速とはいえ「落ちない」「詰まらない」わけではありません。
とくに負荷が増えるとメモリ逼迫・エラー多発・レイテンシ上昇などが発生します。
だからこそ、「今の状態がどうなってるか?」をリアルタイムに見えるようにしておくことが重要なんですね。
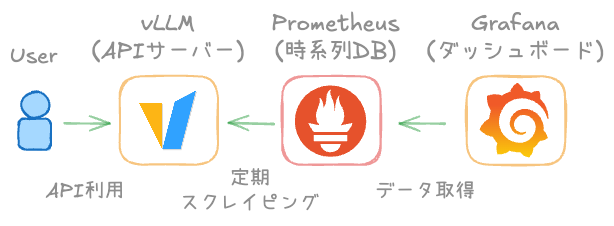
たったこれだけ!vLLM × Prometheus × Grafana の三種の神器
下図とおりシステム構成はとてもシンプルです。
vLLMでメトリクスを確認する
vLLMのメトリクスはhttps//{vLLMのホスト名}:8000/metricsにアクセスすることで次のように出力されます。
# HELP vllm_num_requests_running Number of requests currently running
# TYPE vllm_num_requests_running gauge
vllm:num_requests_running{engine="0",model_name="qwen3-14B"} 1.0
# HELP vllm_num_requests_waiting Number of requests waiting in the queue
# TYPE vllm_num_requests_waiting gauge
vllm:num_requests_waiting{engine="0",model_name="qwen3-14B"} 0.0
# HELP vllm_gpu_cache_usage_perc GPU KV cache usage percentage
# TYPE vllm_gpu_cache_usage_perc gauge
vllm:gpu_cache_usage_perc{engine="0",model_name="qwen3-14B"} 0.0008610946665948971
# HELP vllm_time_to_first_token_seconds Time to first token (TTFT) in seconds
# TYPE vllm_time_to_first_token_seconds histogram
vllm:time_to_first_token_seconds_bucket{engine="0",le="0.001",model_name="qwen3-14B"} 0.0
vllm:time_to_first_token_seconds_bucket{engine="0",le="0.005",model_name="qwen3-14B"} 0.0
(以下略)
メトリクス(metrics)とは、システムやサービスの状態や性能を数値として測定・記録したものです。
たとえば上記メトリクス中のvllm_num_requests_runningであれば、モデル実行中のリクエスト数が取得できます。
Prometheus、Grafanaの起動
PrometheusとGrafanaはDocker Composeで簡単に起動できます。 まずは、vllmのページから以下のファイルを同じフォルダにダウンロードしましょう。
次に、ダウンロードしたprometheus.yamlを開き、必要に応じて以下のように修正します。
# prometheus.yaml
global:
scrape_interval: 15s
evaluation_interval: 10s
scrape_configs:
- job_name: vllm
static_configs:
- targets:
- '{vLLMのホスト名}:8000' # 必要に応じてここを編集
# プロキシ環境下の場合は必要に応じて追記
# proxy_url: http://proxy.corporate.local:8080
# or 認証が必要なら
# proxy_url: http://USER:PASS@proxy.corporate.local:8080
そして編集内容を保存し、docker compose upコマンドを実行するとPrometheusとGrafanaが起動します。
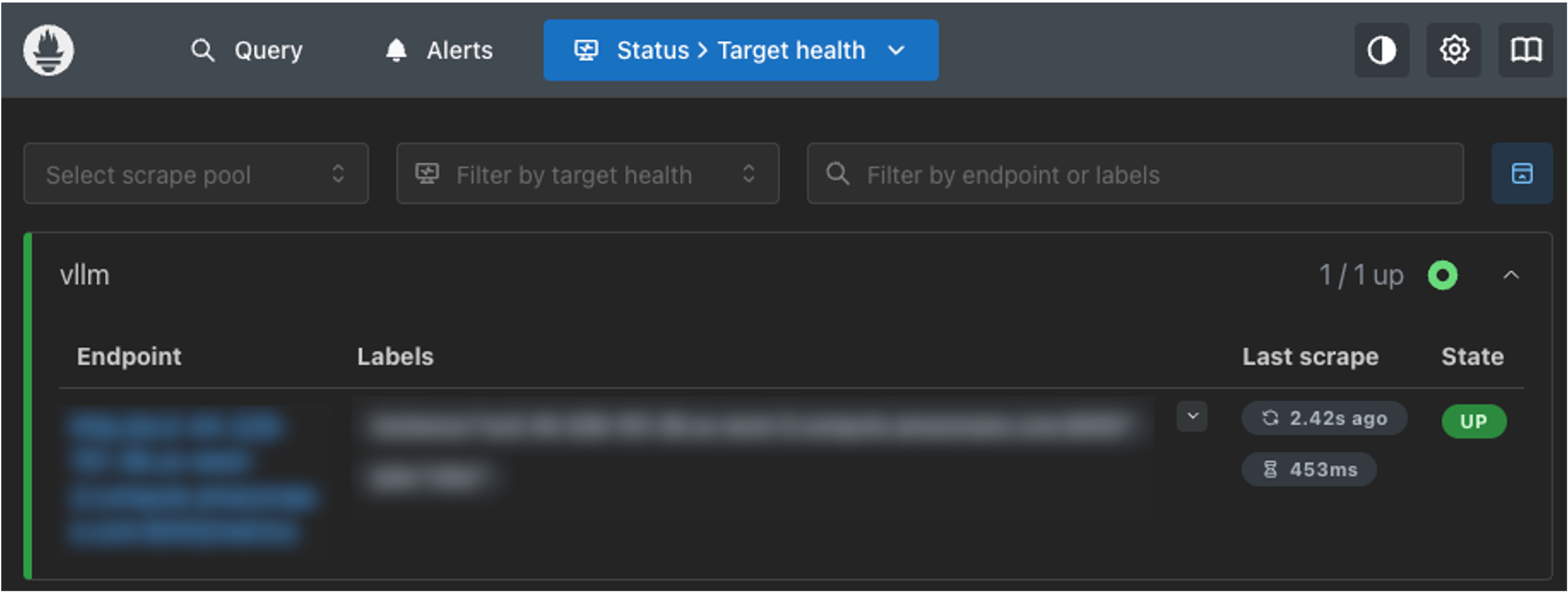
vLLMとPrometheusの接続確認
まずは、vLLMとPrometheusが接続できているか確認します。
http://{Prometheus、Grafanaのホスト名}:9090/targetsにアクセスし、Stateが「UP」になっていればvLLMとの接続が確認できています。
接続できていない場合は、先ほど編集したpromeheus.yamlのtargetsもしくはproxy_urlに誤りがないか確認してください。
PrometheusとGrafanaの接続
次はPrometheusとGrafanaを接続します。
http://{Prometheus、Grafanaのホスト名}:3000/connections/datasources/newにアクセスし、「Add new data source」を選択します。
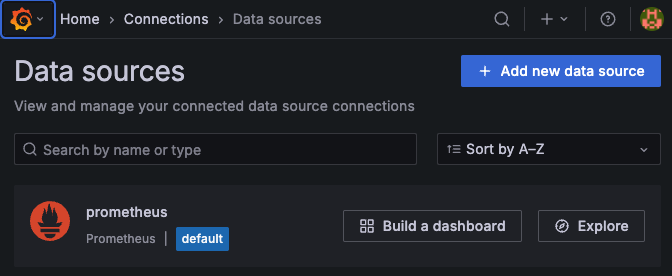
Data Sourceの作成画面では、Prometheus server URL に http://prometheus:9090 を入力し画面下部から「Save & test」を選択し保存します。

ダッシュボードの作成
最後にダッシュボードを作成します。
http://{{Prometheus、Grafanaのホスト名}:3000/dashboard/importにアクセスし、先ほどダウンロードしたgrafana.jsonをアップロードしてください。
以下のようなダッシュボードが表示されます。
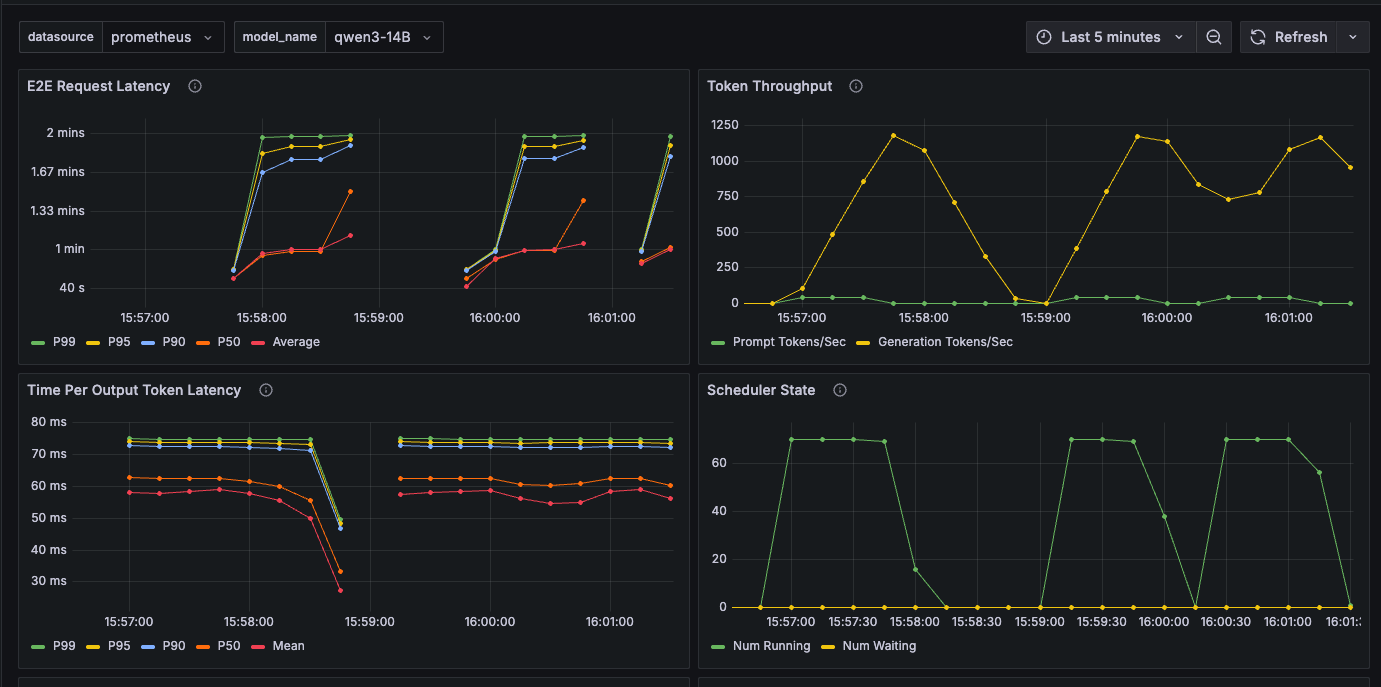
ダッシュボードで丸見えに!推論状況を視覚化するコツ
Grafanaで表示される主要メトリクスはこのようなものです。
| パネル名 | 内容 |
|---|---|
| E2E Request Latency | リクエスト全体の遅延(P50/P90/P95/P99 と平均)を秒で表示。レイテンシの劣化検知に利用。 |
| Token Throughput | 秒あたりのトークン処理量(プロンプト/生成)で、負荷や処理能力の傾向を把握。 |
| Time Per Output Token Latency | 出力トークン間の間隔(P50〜P99 と平均)。生成の"速さ"を直接確認可能。 |
| Scheduler State | 実行中(RUNNING)と待機(WAITING)のリクエスト数。キュー詰まりの兆候を確認。 |
| Time To First Token (TTFT) | 最初のトークンが出るまでの遅延(P50〜P99 と平均)。応答の初動の速さを評価。 |
| Cache Utilization | vLLM の GPU キャッシュ使用率(%)。キャッシュ逼迫を監視。 |
| Request Prompt Length(ヒートマップ) | プロンプト長の分布と推移。ワークロード特性を把握。 |
| Request Generation Length(ヒートマップ) | 生成長(出力トークン数)の分布と推移。 |
| Finish Reason | 完了理由(EOS 到達/最大長到達など)別の完了件数。トランケーション多発を検知。 |
| Queue Time | リクエストの待ち時間の合計レート(時系列)。キュー滞留の増減を確認。 |
| Requests Prefill and Decode Time | プリフィル/デコード処理時間のレート(時系列)で、どちらがボトルネックかを把握。 |
| Max Generation Token in Sequence Group | シーケンスグループ内の最大生成トークン数のレート。長文生成の負荷傾向を把握。 |
これらのメトリクスを監視することでvLLMの状態を把握し、何かあったときに備えましょう。
まとめ:LLMは"動かす"だけじゃなく"見守る"時代へ
vLLMのような高性能LLMサービングでも、監視なしでは安心できません。
PrometheusとGrafanaによる「見える化」ダッシュボードは、
最小構成ながら非常に強力で、運用の質を大きく向上させてくれます。
もしまだ導入していないなら、まずはローカル環境で試してみるところから始めてみてください。LLMの"中身"が見えると、世界が変わります!
---
※Prometheus® は The Linux Foundation の登録商標です。
※Grafana® は Grafana Labs の登録商標です。
※vLLM™ は vLLM Project の商標です。
※その他記載されている会社名、製品名は、各社の商標または登録商標です。





生成AIの普及に取り組むAIエンジニア。たまに社内ブログも執筆。
休日はスポーツジムで汗を流しつつ、インスタコードという電子楽器で遊んでいる。好物は横浜家系ラーメン。
![]()