NW監視技術「Telemetry」とTelegrafコレクタ、情報分析基盤について
新しいネットワークの監視手法として注目されるTelemetryとその分析基盤をOSSで実現した際の構成例について紹介します。 また後半ではTelegrafコレクタに焦点を当て、前述の分析基盤で起こりがちな課題の解消法も紹介します。




はじめに
こんにちは、NTTテクノクロス 山口です。
今回は、これまでの記事でも度々触れてきたTelemetry技術と、その情報を活用する分析基盤について紹介したいと思います。
TelemetryはStreaming Telemetry とも呼ばれることもありますが、NWの新たな監視手法として注目を集めている技術となります。
また、上記の説明から派生してTelemetry分析基盤に使われる「コレクタ」の1つであるTelegrafに関しても少し深堀りして紹介したいと思います。
■ 目次
| 節番号 | 節タイトル |
| 1 | Telemetryとは |
| 2 | Telemetry分析基盤とTelegrafについて |
| 3 | Telegrafのメリットと課題改善案について |
Telemetryとは
まずTelemetryとは具体的にどのような事ができるのかを以下に示します。
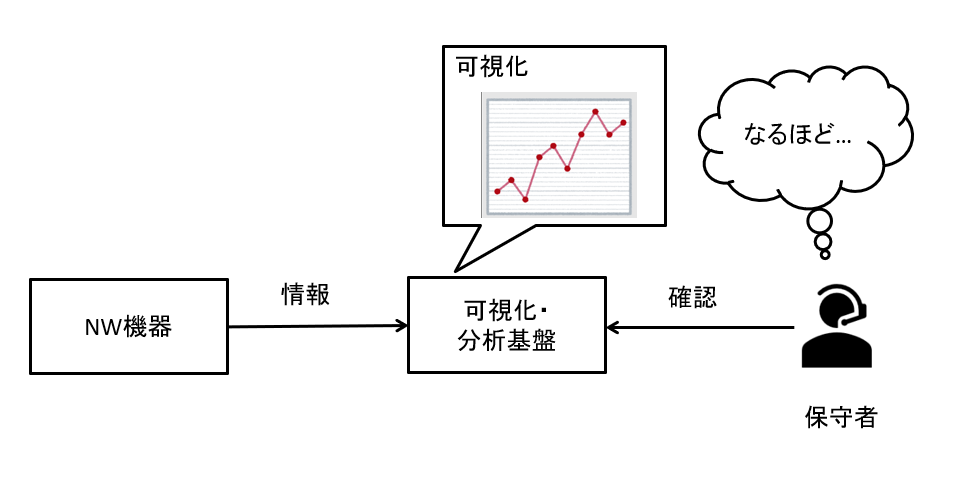
図1 Telemetryでできる事概要
上記図のように、NWを構成するNW機器から定期的に情報を取得し、状態監視ができるようになります。
なおTelemetryと言うと「OpenTelemetry」というキーワードを想起される方もいるかもしれませんが、こちらはサーバ監視やマイクロサービス監視等に使われる技術であり、本記事で取り上げる(Streaming)Telemetryとは別物となります。
NW機器を監視する方法には上記のTelemetry以外にも、古くからあるSNMPやSyslog監視などがあります。
これらと何が違うかという点を簡単に下記に示します。
| 従来の監視手法 | 従来の監視手法と比較したTelemetryの強み |
| SNMP | SNMPより高頻度に情報を取得することができる |
| Syslog |
TelemetryはJSONで出力可。 |
TelemetryはNW機器に与える負荷が従来の監視手法より軽いと言われており、その分高頻度に情報を収集する事が可能となります。
これはきめ細かな監視ができる事以外に、故障予兆の検知やAIモデル構築用の学習データとしての活用にも期待ができます。
さて、監視をする上での役割という観点では、監視対象の情報を持つ「情報源」と、その情報を取得した上で保管・管理・活用する「情報の活用者」の2つが必要となります。
Telemetry技術を用いた監視では「Pub/Subモデル」を採用しており、情報源を「Publisher」、情報の活用者を「Subscriber」と呼びます。
この構成はPublisherが情報を発行(出力)し、その情報を欲しい人(Subscriber)のみが取得するという動作となります。
よってPublisherはSubscriberからの問い合わせを受けて情報出力するのではなく、決められたタイミングで決められた情報を定期的に出力する、という動きとなります。
定期購読する新聞のようなイメージを持っていただくとよいかと思います。
「Pub/Subモデル」というと、DB(PostgeSQL)にお詳しい方は「ロジカルレプリケーション(LR)」をイメージされる方もいるかと思います。
LRではDB間の連携を目的としており、PublisherとSubscriberのみで実現する構成が基本となりますが、Telemetry技術ではPublisherとSubscriberの間にBrokerという役割を置く事が一般的です。
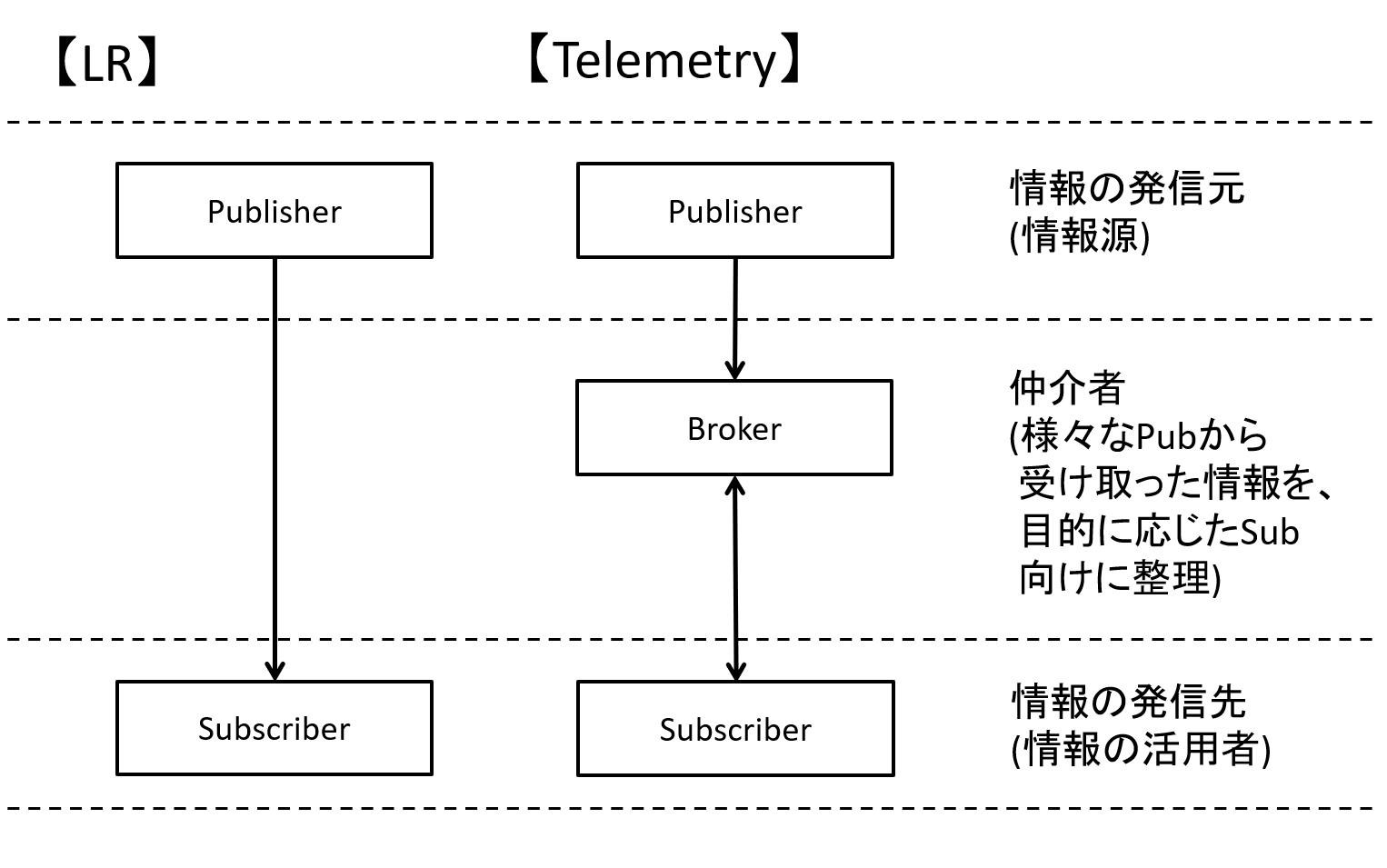
図2 Pub/Subモデルの構成について
Brokerを置く事でPublisher, Subscriberに対して1対N、N:N構成が取れるようになる為、柔軟なスケール性を確保できます。
上記の構成も踏まえた上で、Telemetry分析基盤について次節で触れたいと思います。
Telemetry分析基盤とTelegrafについて
TelemetryはNW機器を管理するベンダ製コントローラ製品でも、状態監視を実現する為に使われていることが多いですが、OSS製品を組み合わせて監視基盤を作る事も可能です。
今回はOSSで実現した際の一例として、以下構成を紹介したいと思います。
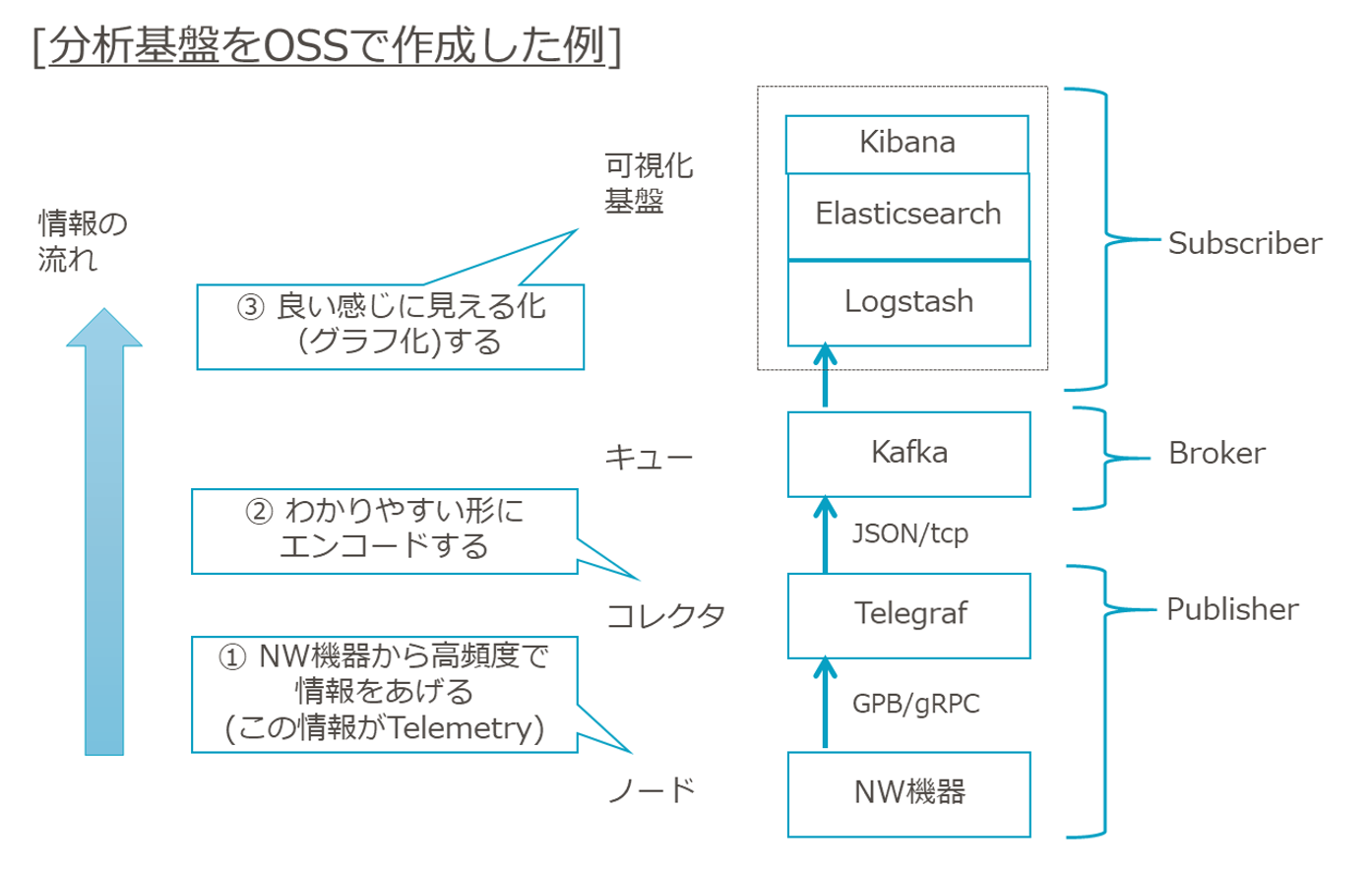
図3 Telemetry分析基盤をOSSで実現した場合の構成例
上記の通り、様々なOSSが使用されています。
下記に各OSSの簡単な説明を示します。
| OSS名 | 制限(代表例) |
| Telegraf | NW機器からの情報を一次受けする「コレクタ」。 役割は後述。 |
| Kafka | 様々な情報を受け取るキューサービス。 |
| Logstash | 取得した情報の加工やフィルタリングを行うコンポーネント。 |
| Elasticsearch | 取得した情報を検索する為の、全文検索エンジン。 |
| Kibana | 取得した情報をグラフ等で見える化するコンポーネント。 |
※ Logstash, Elasticsearch, KibanaはまとめてElastic Stackとも呼ばれる
Publisher, Broker, Subscriberの3つの役割で構成される「Pub/Subモデル」の説明から、やや複雑になったかと思います。
以下でこの構成についてもう少し深堀したいと思います。
最も疑問符が付きやすい点はPublisherのなかに「NW機器」と「コレクタ」の2つが在する事かと思います。
この2つの役割の違いについて説明します。
情報源という観点では監視対象がNW機器である為、情報の出力元としてNW機器はしっくりくるかと思います。
一方、コレクタは言葉だけだとイメージがわかないかと思いますが、役割としては以下があります。
① エンコード
② 複数NW機器の情報取得
③ 情報の一次整形
まず①の「エンコード」ですが、図を見るとコレクタ(telegraf)はGPBで受け取り、JSONで出力しています。
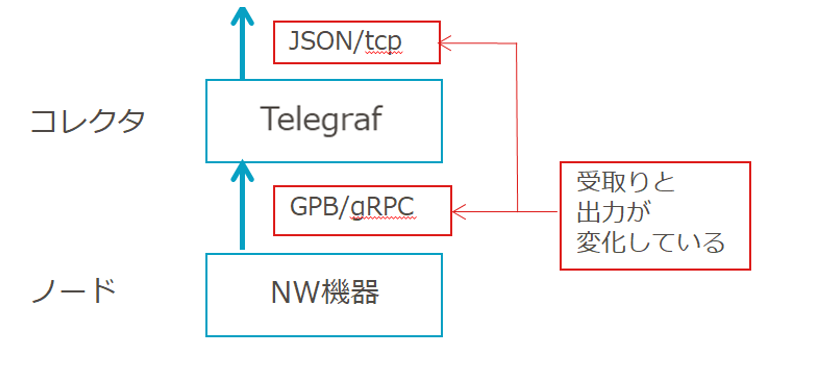
図4 コレクタの入力と出力の形式について
GPBはバイナリのような情報形式と思っていただければ、と思います。
NW機器から直接JSON形式で出力もできる事が多いですが、GPBを使う事でNW機器の情報出力負荷を縮小させることができます。
バイナリのようなデータでは人が見たときにどのようなデータかわからない為、コレクタにより人が見ても理解できる形、かつ構造化されたデータとして変換・エンコードを行います。
次に②の「複数NW機器の情報取得」についてです。
コレクタは複数のNW機器から情報を受け取る事が可能です。
これにより監視対象のNW機器が増えた場合にコレクタを増やさなくても、余力のあるコレクタに情報を上げる、という選択肢がとれるようになります。
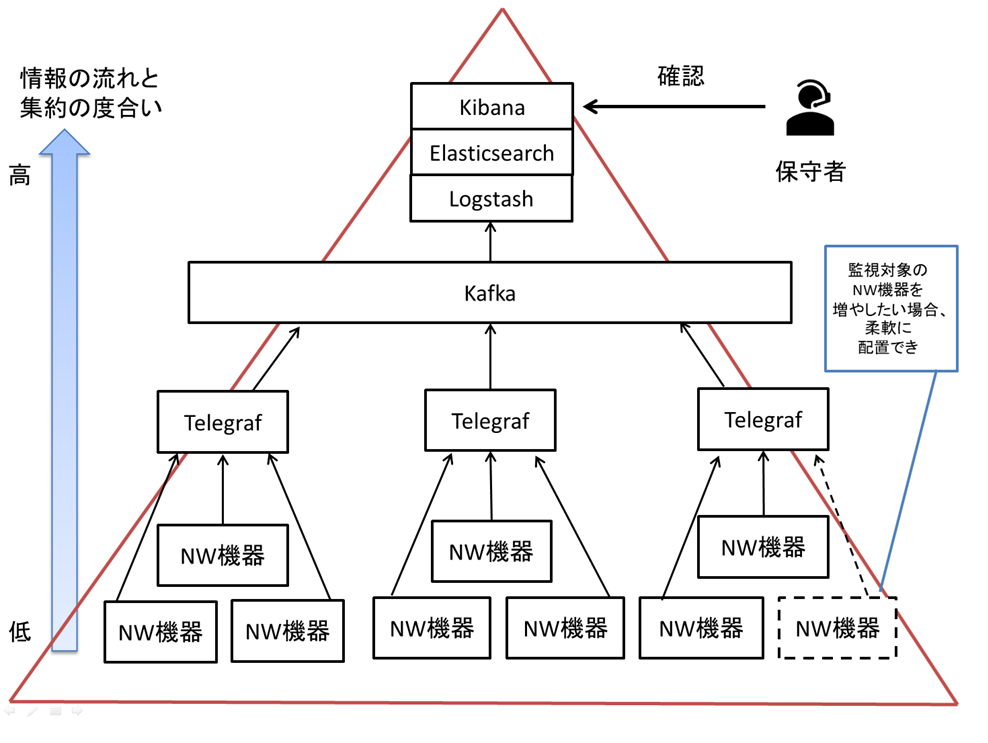
図5 情報の流れと集約度合い
更にNW機器とコレクタの接続方式によりますが、場合によっては複数のNW機器に統一的なTelemetry設定を入れることができます。
上記の接続方式には「Dail-In」と「Dial-Out」の2つがあります。
接続方法の違いは以下のような違いがあります。
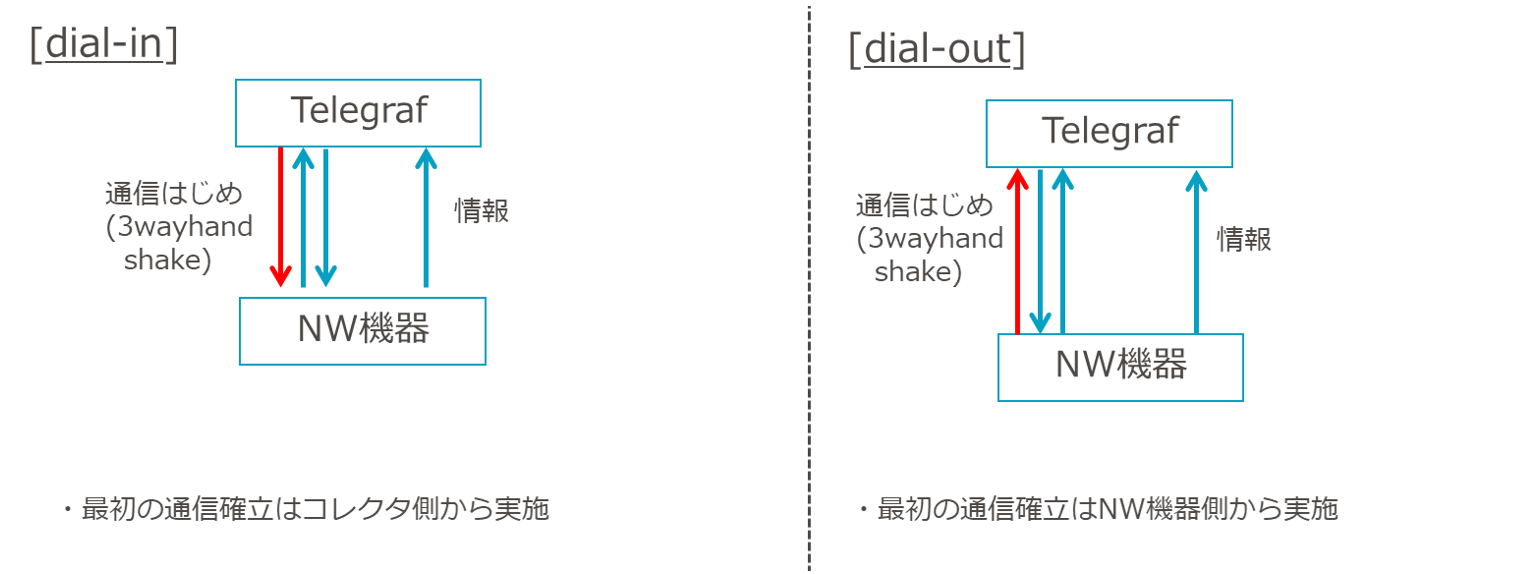
図6 接続方式と通信確立の流れの違い
この接続方式の違いにより、どちらに出力させたい情報を定義するかがかわります。
Telemetryでどのような情報を出力させるかは「センサーパス」と呼ばれる設定を指定しますが、Dail-Inでは先にやり取りを始めるコレクタ側にセンサーパスを指定します。
Dial-OutではNW機器ごとに出力させるセンサーパスを指定します。
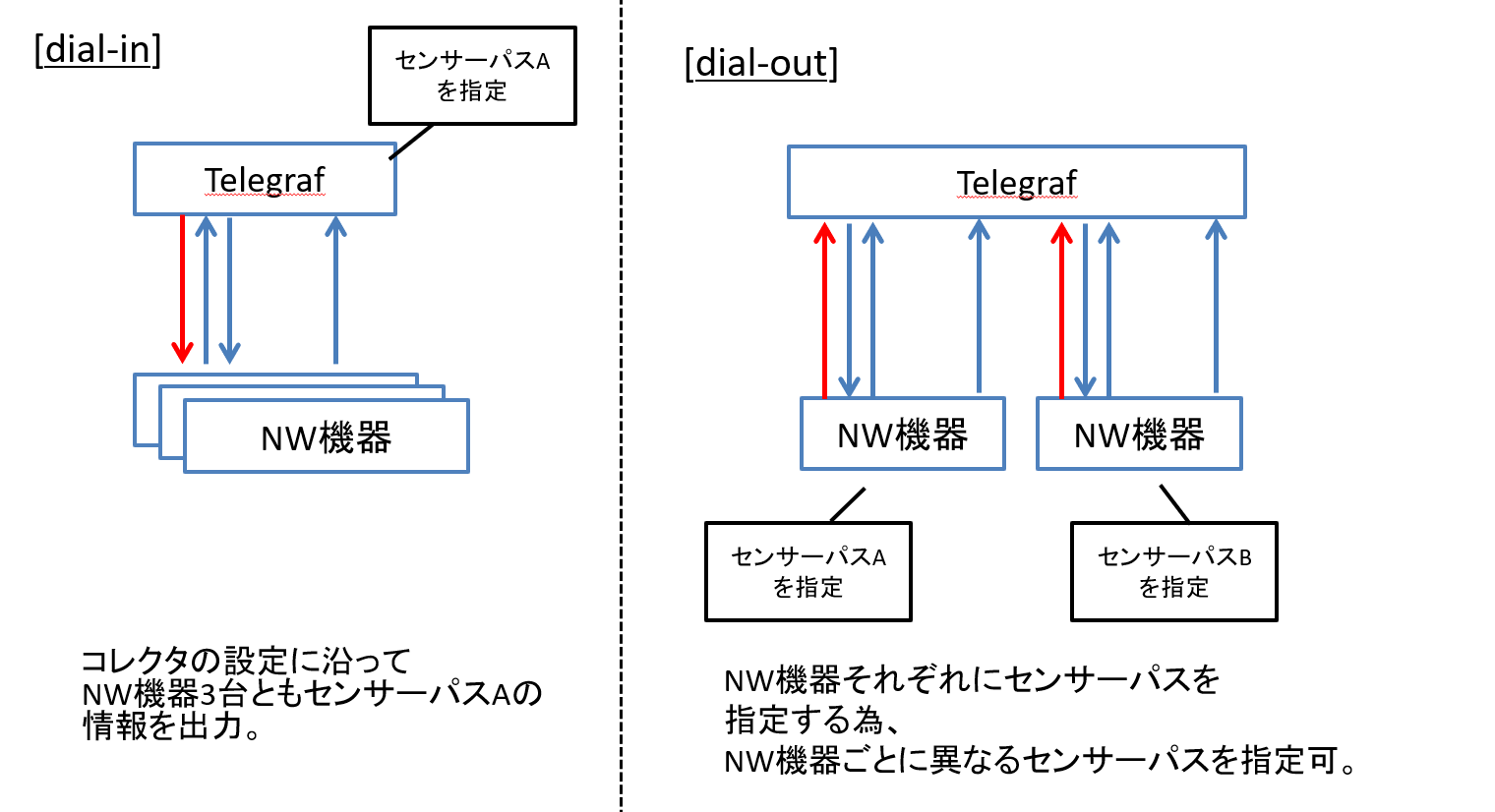
図7 接続方式とセンサーパスの指定について
これは言い換えれば、Dial-Inでは複数のNW機器に同じセンサーパスを統一的に指定することが可能となります。
一方でNW機器ごとに異なる情報を出力させたい場合にはDail-Outの方が良いといえます。
最後に③の「情報の一次整形」ですが、上位に情報を上げる前にこの段階で簡易なデータ整形が可能です。
具体的にはtelegrafの場合、正規表現により一部データを書き換える事などが可能です。
上位になればなるほど整形対象のデータも多くなると想定されるため、この段階で簡易な整形であったり、不要な情報の削ぎ落しをしておくと負荷分散に繋がります。
例えば新聞も、世界各国から様々なニュースが日々届くかと思いますが、すべてを記載するのではなく、インパクトの大きい・重要度の高いニュースに絞って消費者に届けているかと思います。
それと同様のイメージを持っていただけるとわかりやすいのではないかと思います。
なお、今回の構成ではコレクタに「Telegraf」を指定していますが、他にも選択肢はあります。
以下に一例を記載します。
| コレクタ例 | 概要 |
| Pipeline | Ciscoが作成したコレクタ。OSSとして使用可。 |
| gNMIc | Telegrafと同様、OSSコレクタ。 |
Telegrafの特徴は様々なプラグインがある点です。
なお、TelegrafはDial-In, Dial-Outのどちらも対応可能です。
どちらの接続方式を使うかはNW機器によっても対応できるかどうか差分がある為、やりたいこととあわせてNW機器とコレクタの両方を確認する必要があります。
もう1点、構成に関して触れおきたいのは「kafka」や「Elastic Stack」を指定している点です。
例えば他の構成としてはTelegrafはinfluxDBと合わせて使いやすい為、InfluxDBにデータをためて、Grafanaでデータを可視化するといった案もあると考えます。
ここで意識したいのは「登録する情報」の拡張性という観点です。
現在はTelemetryだけを扱っていますが、将来的にSNMPやSyslogといった他の監視情報も統合的に管理したくなった場合、様々な情報を受け取るキューとして扱われるkafkaは相性が良いと考えます。
また、Syslogのように構造化されていないデータをInfluxDBで扱うのも管理が難しく、LogStashによる加工やElasticsearhによる強力な全文検索が向いていると考えます。
上記は一例ですが、要件に応じてどのような構成とするかは変わってきます。
一方で上記OSS構成でTelemetryを活用する上で課題となりやすい点は以下となります。
| 項番 | 課題 |
| 1 | コンポーネントが多く、どこで想定外動作が起きたか解析に時間を要する。 |
| 2 | 監視対象を増やした際の各コンポーネントへの負荷増加。 |
| 3 | 可視化基盤側のストレージ容量。 |
また、実際のNWに監視基盤を適用するにあたり、NW機器によってTelemetry機能を有していない場合があります。
Telemetry機能を有していないNW機器も監視基盤で統合的に監視したいが、コンポーネントはこれ以上増やしたくないといった考えもあるかと思います。
これらの課題について以下に対応策を記載します。
まず1についてはありきたりとはなりますが、設計・実装・運用の段階でノウハウを集め、整理しておくことが重要となります。
kafkaやElastic StackはOSSの有名どころでもある為、インターネット上にも多くの情報があり、トラブルシュートしやすいかと考えます。
その点で監視基盤の構成であまりマイナーな製品を使わないという点も対策となると考えます。
2については、監視対象のNW機器や情報(センサーパスや頻度)が増えればその分だけ上位のコンポーネントの負荷は増していきます。
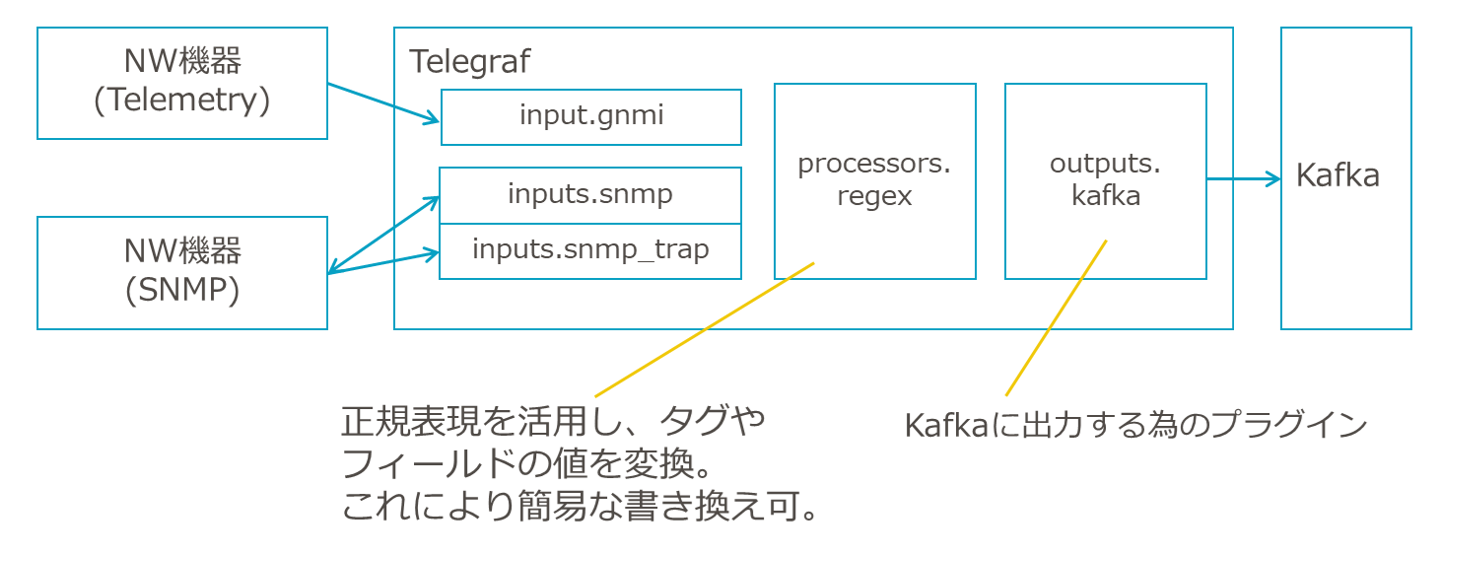
図8 Telegrafを例としたスケール性の必要性について
その為、各コンポーネントでスケール性を意識する事が重要です。
スケールアウト等に対応したOSS等を使用し、各OSS群はスケールアウトしやすいkubernetes等で管理すると良いのではないか、と考えます。
3に関する課題やTelemetry機能のない機器の監視については次節にて一例としてTelegrafでの解決案を紹介します。
Telegrafのメリットと課題改善案について
ストレージ容量削減の対策案の1つに、コレクタで情報を集約する、という案があります。
例えば1分間の平均の値を出力する、といったことがあげられます。
コレクタにTelegrafを使う際に上記を実現するにはaggregatorsプラグインを活用すると良いでしょう。
使う際にはTelegrafのコンフィグファイル(telegraf.conf)に設定を記載します。
上記プラグインでは平均以外にも最小値や最大値、中央値、標準偏差等が取得可能です。
~省略~
[[aggregators.basicstats]]
## The period on which to flush & clear the aggregator.
period = "60s“
## If true, the original metric will be dropped by the
## aggregator and will not get sent to the output plugins.
drop_original = true
## Configures which basic stats to push as fields
stats = ["mean"]
[aggregators.basicstats.tagdrop]
agent_host = ["*"]
~省略~
監視対象のNW機器がTelemetry機能を有していない場合の監視法については、他の方法で監視することになりますが、その中で最も一般的な手法にSNMPがあります。
TelegrafにはSNMPに対応したプラグインがある為、それを活用する事で、telegrafから監視基盤に情報をあげることができます。
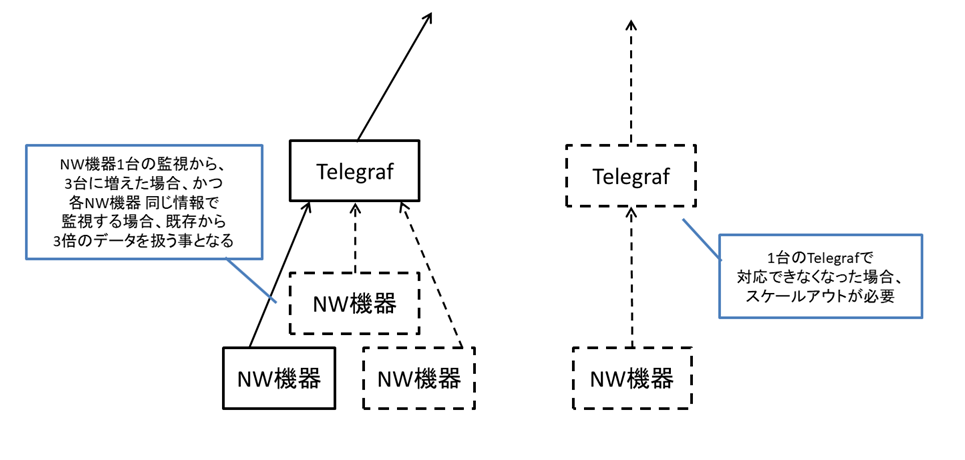
図9 SNMP対応プラグインを入れたTelegrafの構成
このようにTelegrafは必要な運用にあわせて柔軟にプラグインを選択して活用することができます。
前述のもの含め様々なプラグインがあるので、以下にて一部紹介します。
| プラグイン名 | 説明 |
| inputs.gnmi | gNMIを活用する為のもの。TLSサポート。 |
| inputs.cisco_telemetry_mdt | Cisco IOS向けプラグイン。TLSサポート。 |
| inputs.jti_openconfig_telemetry | JunOS向けプラグイン |
| processors.regex | 正規表現で一部データを書き換える為のプラグイン。 |
| outputs.kafka | Kafkaに向けて出力する為のプラグイン |
| outputs.elasticsearch | Elasticsearchに向けて出力する為のプラグイン |
上記プラグインにはciscoやjuniperに向けたプラグインがあります。
これらのユースケースについても少し説明します。
そもそもセンサーパスには以下の2種があります。
| コンフィグの種類 | 説明 |
| ベンダーネイティブコンフィグ | ベンダーごとに作成したコンフィグ。 |
| オープンコンフィグ | 様々なベンダーで同じセンサーパスが指定でき、 同様の情報が取得できる。 |
マルチベンダーなNW機器を使ったNWで情報を収集するにはオープンコンフィグが向いていますが、時にはベンダーネイティブコンフィグを使わざるを得ない場合があります。
例えばベンダーネイティブコンフィグ向けにしかない便利機能が存在したりします。
オープンコンフィグであればある程度はgnmiプラグインで対応できるかと考えます。
一方でベンダーネイティブコンフィグを使いたい場合には上記であげたプラグインを活用すると良いでしょう。
おわりに
「NWコンピューティングの処理高速化技術 第1回」の記事で触れたように
NW障害に向けたNWの強靭化という観点で、NW監視はますます重要となってきています。
NW監視をより充実させる方法として、従来の方法の他に新しい手法のTelemetry技術を活用できると良いと考えます。
なお、TelemetryはNW機器への負荷が従来の方法と比較し小さい、という点を記事の中でも紹介していますが、全く負荷が上がらないというわけではありません。
その為、どのような情報をどういう頻度で取るのか、という整理は従来の監視手法と同様に重要となります。
本件、またはネットワークに関するご質問がございましたら以下にてお問い合わせください。
ここまでご覧いただき、ありがとうございました。
本件に関するお問い合わせ



<<<<著者プロフィール>>>>
フューチャーネットワーク事業部
第一ビジネスユニット
山口 佳輝(YAMAGUCHI YOSHIKI)
NWに関係したシステム開発を担当しています
>>>>>>>>><<<<<<<<<
![]()